Mini-batch
Mii-batch是一种在机器学习中常用的训练算法。它是将大的数据集分成一些小的数据集,每次只用一个小的数据集来训练模型。通常情况下,训练数据集中的数据越多,训练出的模型越准确,但是如果数据集太大,就会导致计算量过大,训练时间过长。因此,使用Mini-batch的方法可以在保证模型训练准确性的同时,降低计算时间和内存的消耗。在mini-batch中,每个小的数据集被称为一个patch,通常情况下,每个batch的大小是相同的。在训练过程中,每个batch都会被输入到模型中进行训练,模型的参数会根据每个batch的误差进行更新。这样,在训练过程中,每个batch都会为模型提供一些不同的信息,从而增强模型的泛化能力。
使用mini-batch的方法可以在保证模型训练准确性的同时,降低计算时间和内存的消耗,同时还可以带来更好的泛化性能。因此,mini-batchi已经成为了深度学习中的一种常用的训川练算法。
链接:https://wenku.csdn.net/answer/7e8ca99bbfd84184b4ba9957911f4ccd
魔法函数
魔法函数指的是Python中的特殊函数,它们以双下划线开头和结尾,如__init__、__str__等。这些函数在Python内部被调用,它们可以实现一些特殊的功能,比如重载运算符、创建对象、打印对象等。
DataLoader与DataSet
DataLoader与DataSet是PyTorch数据读取的核心,是构建一个可迭代的数据装载器,每次执行循环的时候,就从中读取一批Batchsize大小的样本进行训练。
- Dataset:负责可被Pytorch使用的数据集的创建
- Dataloader:向模型中传递数据
链接:Python中的Dataset和Dataloader详解_python_脚本之家
transformers的简介
transformers提供了数千个预先训练好的模型来执行不同模式的任务,如文本、视觉和音频。这些模型可应用于:
- 文本:用于文本分类、信息提取、问题回答、摘要、翻译、文本生成等任务,支持100多种语言。
- 图像:用于图像分类、对象检测和分割等任务。
- 音频:用于语音识别和音频分类等任务。
transformer模型还可以在几种组合模式上执行任务,例如表格问题回答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问题回答。
transformer提供了api,可以快速下载并在给定文本上使用这些预训练的模型,在您自己的数据集上对它们进行微调,然后在我们的模型中心上与社区共享。同时,每个定义架构的python模块都是完全独立的,可以进行修改以进行快速研究实验。
transformer由三个最流行的深度学习库——Jax、PyTorch和TensorFlow——支持,并在它们之间无缝集成。在加载模型进行推理之前,先用一个模型训练它们是很简单的。您可以从模型中心直接在它们的页面上测试我们的大多数模型。我们还提供私有模型托管、版本控制和公共和私有模型的推理API。
链接:Py之transformers:transformers的简介、安装、使用方法、案例应用之详细攻略_python transformers-CSDN博客
torchvision简介
t orchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。以下是torchvision的构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
原文链接:torchvision详细介绍-CSDN博客
torch.no_grad()
torch.no_grad() 是 PyTorch 中的一个上下文管理器,用于在进入该上下文时禁用梯度计算。
这在你只关心评估模型,而不是训练模型时非常有用,因为它可以显著减少内存使用并加速计算。当你在 torch.no_grad() 上下文管理器中执行张量操作时,PyTorch 不会为这些操作计算梯度。这意味着不会在 .grad 属性中累积梯度,并且操作会更快地执行。
Softmax
Softmax是一种激活函数,它可以将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出。Softmax层常常和交叉熵损失函数一起结合使用。
对于二分类问题,我们可以使用Sigmod函数(又称Logistic函数)。将(−∞,+∞)范围内的数值映射成为一个(0,1)区间的数值,一个(0,1)区间的数值恰好可以用来表示概率。对于多分类问题,一种常用的方法是Softmax函数,它可以预测每个类别的概率。
链接:三分钟读懂Softmax函数 - 知乎 (zhihu.com)
随机梯度下降(Stochastic Gradient Descent,SGD)
optim.SGD是PyTorch中的一个优化器,其实现了随机梯度下降(Stochastic Gradient Descent,SGD)算法。在深度学习中,我们通常使用优化器来更新神经网络中的参数,以使得损失函数尽可能地小。
在PyTorch中使用optim.SGD优化器,一般需要指定以下参数:
params:需要更新的参数,通常为模型中的权重和偏置项。lr:学习率,即每次参数更新时的步长。momentum:动量,用来加速模型收敛速度,避免模型陷入局部最优解。dampening:动量衰减,用来控制动量的衰减速度。weight_decay:权重衰减,用来防止模型过拟合,即通过对权重的L2正则化来约束模型的复杂度。nesterov:是否使用Nesterov动量。
torch.nn.CrossEntropyLoss(),交叉损失函数
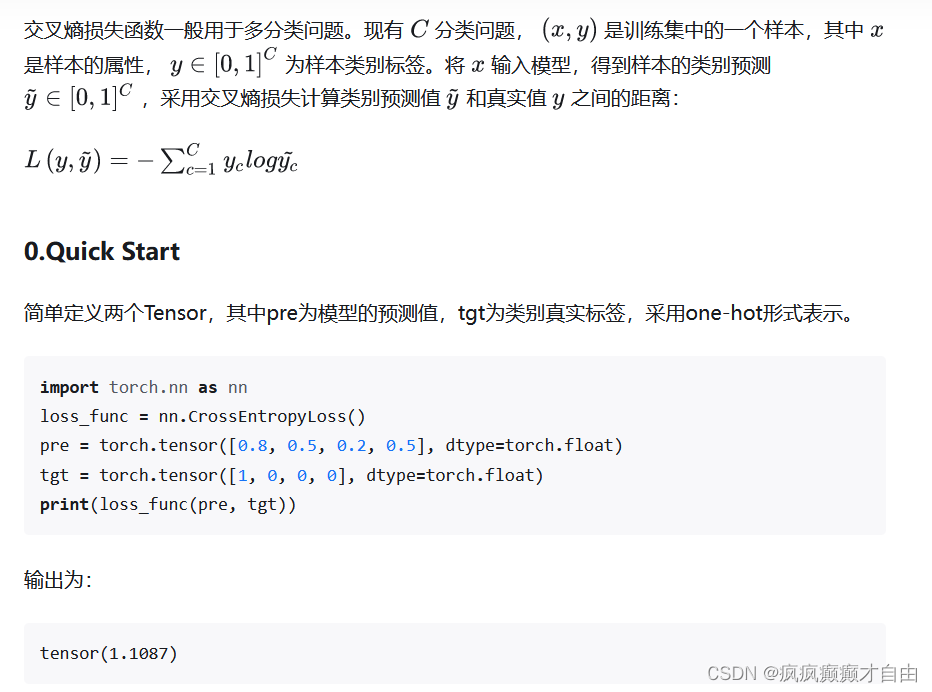
- 交叉熵损失函数会自动对输入模型的预测值进行softmax。因此在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax。
- nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss()。
# Construct loss and optimizer, using PyTorch API
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# Training cycle: forward, backward, update
# 前馈算loss,反馈计算关于loss的梯度,更新是用梯度下降算法利用的梯度进行更新
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
传送门:torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状 - 知乎
Tensor:张量
# In PyTorch, Tensor is the important component in constructing dynamic computational graph
w = torch.tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要计算梯度
# If autograd mechanics are required, the element variable requires_grad of Tensor has to be set to True.
# Tensor:张量(Tensor):是一个多维数组,它是标量、向量、矩阵的高维拓展。
# tensor即张量,它是一种数据结构,用来表示或者编码神经网络模型的输入、输出和模型参数等。Tensor:张量(Tensor):是一个多维数组,它是标量、向量、矩阵的高维拓展。
tensor即张量,它是一种数据结构,用来表示或者编码神经网络模型的输入、输出和模型参数等。









![[算法沉淀记录] 排序算法 —— 归并排序](https://img-blog.csdnimg.cn/direct/6197831ecff54a60b21edb31f9c2120a.png)