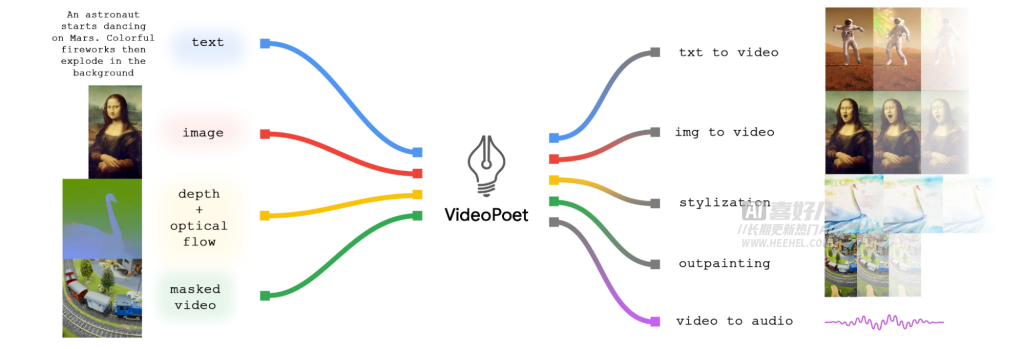
VideoPoet是一种多模态学习模型,本身是一个大型语言模型(LLM),能够理解和处理文本、图像、音频等多种信息,并将其融合到视频生成过程中。它不仅能够根据文字描述生成视频,还能给视频添加风格化效果、修复和扩展视频,甚至从视频中生成音频。此外,VideoPoet还能理解和生成音频,并编写用于视频处理的代码。
这种多模态学习能力使得VideoPoet在视频生成方面更加灵活和强大,能够处理更复杂和多样化的任务。与其他基于扩散模型的生成方法不同,以后可以通过歌词生成视频画面啦,后面不知道用一首歌能不能生成视频。
详细介绍:
https://heehel.com/Google-VideoPoet
演示:
https://sites.research.google/videopoet/
VideoPoet模型默认生成竖屏视频,适应短视频需求。Google Research团队利用Bard编写浣熊旅行故事,并通过VideoPoet生成与故事匹配的视频片段,展示其多样性和创造力。这种结合不同技术的方法为视频制作和故事叙述提供新可能,特别适合短视频和社交媒体内容创作。






![[DP学习] 期望DP](https://img-blog.csdnimg.cn/direct/05675f03a825488aa786850b1cd327aa.png)