目录
PromptBench简介
PromptBench的快速模型性能评估
PromptBench数据集介绍
PromptBench模型介绍
PromptBench模型加载遇到的问题
第一次在M1 Mac上加载模型
vicuna和llama系列模型
PromptBench各个模型加载情况总结
PromptBench的Prompt快速工程
chain of thought
emotion prompt
expert prompt
generated knowledge
least to most
PromptBench对抗性Prompt评估
PromptBench的动态评估
PromptBench总结
大语言模型真是火啊,火到每次我跟别人提到prompt(prangpt)这个单词,都有人纠正我的读法(promout),真讨厌(你看懂我怎么读的了么,不过不重要)。prompt又叫做提示语,在用大语言模型的过程中,是必不可少的输入,它可以是一个问题、一段描述或者一些格式化的文本组合。优化prompt的目的通常是希望模型可以返回更加准确或者有针对性的输出。不知道你有没有听过prompt工程师😳,大概就是要通过各种方式,整一个好的prompt让结果一级棒。不过很多大能们都提到说,prompt engineering只是生成式AI的一个临时状态,毕竟大家还是希望最终形式是跟模型用自然语言沟通,不加条条框框的那种。
不过目前,在大语言模型应用的过程中,prompt工程师还是扮演着一定重要的角色。为了得到更好的结果,如果没办法改变LLM的性能,那只能从Prompt入手,并且需要系统性得在不同模型和数据集上测试其效果和鲁棒性。
23年底的时候,微软出了一个叫做PromptBench的GitHub项目(GitHub - microsoft/promptbench: A unified evaluation framework for large language models),一看就能猜出来这可能是要测prompt的bench mark,也就是看看这个prompt写的好不好(这是一件关于evaluation的事情),项目有关论文:https://arxiv.org/abs/2312.07910。微盘链接:文件分享。本人主要是在家没事干,翻paper的时候看到了这个东西,决定体验一下。看完这篇文章,你不仅能了解一些LLM测试任务中常常使用的数据集,已成为历史LLM的一些模型介绍,Prompt engineers的门门道道。
PromptBench简介
首先,GitHub上作者们是这么描述PromptBench所能提供的功能:
1. 快速模型性能评估:可以快速构建模型、加载数据集和评估模型性能。
2. 快速工程:多种快速工程方法,例如:Few-shot Chain-of-Thought、情绪提示、专家提示等。
3. 评估对抗性提示:集成了提示攻击,使研究人员能够模拟对模型的黑盒对抗性提示攻击并评估其鲁棒性。
4. 动态评估:以减轻潜在的测试数据污染:集成了动态评估框架 DyVal ,动态生成具有受控复杂性的评估样本。
简单看看论文里描述Prompt Bench的框架图(具体如下),可以发现,这个Prompt Bench给大家提供了一些benchmark所需的数据集和模型,看起来是可以直接调用的。

然后我们依次看看这些都是什么东西,以及怎么用。
Promptbench使用python3.9以上的版本,pip安装即可:
pip install promptbench
PromptBench的快速模型性能评估
大家可以直接看这个promptbench的调用方式(model加载part报错了不少):https://github.com/microsoft/promptbench/blob/main/examples/basic.ipynb
import promptbench as pb
print('All supported datasets: ')
print(pb.SUPPORTED_DATASETS)
print('All supported models: ')
print(pb.SUPPORTED_MODELS)可以看到目前可以做测试的数据集和模型有

PromptBench数据集介绍
首先,PromptBench里数据集加载代码如下:
dataset = pb.DatasetLoader.load_dataset("name of the dataset you want to load")
数据集列表打印:['sst2', 'cola', 'qqp', 'mnli', 'mnli_matched', 'mnli_mismatched', 'qnli', 'wnli', 'rte', 'mrpc', 'mmlu', 'squad_v2', 'un_multi', 'iwslt2017', 'math', 'bool_logic', 'valid_parentheses', 'gsm8k', 'csqa', 'bigbench_date', 'bigbench_object_tracking', 'last_letter_concat', 'numersense', 'qasc']
简单扫了一下,主要包括以下三类任务(框架图里也有提及):

- SST-2:二分类情感分析任务,https://huggingface.co/datasets/sst2,标签0,1
- CoLA:判断句子语法正确性,The Corpus of Linguistic Acceptability (CoLA),23种语言学出版物的10657个句子
- QQP:识别两个句子是否语义相似,https://huggingface.co/datasets/merve/qqp
- MRPC:识别两个句子是否语义相似,MRPC Dataset | Papers With Code
- MultiNLI(MNLI):自然语言推理,MultiNLI,433k个句子对(mnli_matched, mnli_mismatched in pb)
- Question-answering NLI(QNLI):自然语言推理,QNLI Dataset | Papers With Code,取自斯坦福问答数据集(SQuAD),由问题-段落对组成,其中段落中的一个句子包含相应问题的答案。
- Winograd NLI(WNLI):自然语言推理,WNLI Dataset | Papers With Code,包含成对的句子,任务是确定第二个句子是否是第一个句子的蕴涵。 该数据集用于训练和评估模型理解句子之间关系的能力。
- Recognizing Textual Entailment(RTE):自然语言推理,RTE Dataset | Papers With Code,识别文本蕴含。
插播. 文本蕴含定义为一对文本之间的有向推理关系,如果人们依据自己的常识认为一个句子A的语义能够由另一个句子B的语义推理得出的话,那么称A蕴含B。
- Massive Multitask Language Understanding(MMLU):阅读理解(选择题),MMLU Dataset | Papers With Code,旨在通过仅在零样本和少样本设置中评估模型来衡量预训练期间获取的知识,更类似于评估人类的方式。 该基准涵盖 STEM、人文、社会科学等领域的 57 个学科。
- SQuAD V2:阅读理解,https://huggingface.co/datasets/squad_v2,段落、问题和答案,模型不仅需要根据问题和段落(上下文信息)回答问题,而且还要确定何时该段落不支持答案并放弃回答。
- Multilingual Corpus from United Nation Documents(UN Multi):多语言平行数据,联合国网站平行语料库,United Nations Parallel Corpus
- IWSLT 2017:多语言平行数据,https://www.tensorflow.org/datasets/community_catalog/huggingface/iwslt2017,["ar-en", "de-en", "en-ar"] in pb
- Math:数学问题答案对,GitHub - hendrycks/math: The MATH Dataset (NeurIPS 2021),包含 12,500 个具有挑战性的竞赛数学问题的新数据集。 每个问题都有完整的分步解决方案,可用于训练模型生成答案推导和解释。
- GSM8K:数学问题答案对,GitHub - openai/grade-school-math,小学数学应用题数据集
- CommonsenseQA(csqa):多项选择题回答数据集,https://huggingface.co/datasets/tau/commonsense_qa
- NummerSense:数值常识推理任务,https://huggingface.co/datasets/numer_sense,屏蔽从常识语料库中挖掘的句子中0-10之间的数字,并评估语言模型是否可以正确预测屏蔽值。
- QASC:问答数据集,Question Answering via Sentence Composition (QASC) Dataset — Allen Institute for AI,9,980个有关小学科学的 8 向多项选择题
- Last letter concat:合并多个单词的最后一个字母,https://huggingface.co/datasets/ChilleD/LastLetterConcat
- BIG-Bench:多任务,GitHub - google/BIG-bench: Beyond the Imitation Game collaborative benchmark for measuring and extrapolating the capabilities of language models,200多个任务,包括传统自然语言处理任务,问答,解答数学,写代码等,具体可以看https://github.com/google/BIG-bench/blob/main/bigbench/benchmark_tasks/keywords_to_tasks.md#summary-table,bool logic & valid parentheses & bigbench_date & bigbench_object_tracking in pb
PromptBench模型介绍
PromptBench里模型加载代码如下(直接跑的话实际上没load出来好几个):
model = pb.LLMModel(model='name of the model you want to load', some parameters)
模型列表打印:['google/flan-t5-large', 'llama2-7b', 'llama2-7b-chat', 'llama2-13b', 'llama2-13b-chat', 'llama2-70b', 'llama2-70b-chat', 'phi-1.5', 'palm', 'gpt-3.5-turbo', 'gpt-4', 'gpt-4-1106-preview', 'gpt-3.5-turbo-1106', 'vicuna-7b', 'vicuna-13b', 'vicuna-13b-v1.3', 'google/flan-ul2']
我们先来看看这些模型有什么:
- Google Flan系列
google/flan-t5-large:论文链接,https://arxiv.org/pdf/2210.11416.pdf;模型地址,https://huggingface.co/google/flan-t5-large。T5模型是2019年Google发布的语言模型,这个flan-t5可以看作是加了基于指令微调的T5,且这里的微调方案是多任务的。文章摘要里是这么描述的:
In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation, RealToxicityPrompts).
简而言之:任务变多,模型变大,在思维链数据(chain-of-thought data)上微调。
google/flan-ul2:论文链接,https://arxiv.org/pdf/2205.05131.pdf。ul2,指的是Unifying Language Learning Paradigms,即统一语言学习范式,具体看文章,回头出讲解。
- llama系列:论文链接:https://arxiv.org/pdf/2302.13971v1.pdf
- gpt系列:论文链接:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf,这个大家肯定很熟悉了。
- vicuna系列:文章链接:Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | LMSYS Org
- Google PaLM:Pathways Language Model (PaLM),文章链接:https://blog.research.google/2022/04/pathways-language-model-palm-scaling-to.html。最近出到PaLM2了,https://ai.google/static/documents/palm2techreport.pdf。
- 微软的phi:模型地址,https://huggingface.co/microsoft/phi-1_5。
PromptBench模型加载遇到的问题
第一次在M1 Mac上加载模型
首先,本人用的是M1 Mac机器,与NVIDIA GPU不兼容,无法使用CUDA加速。于是我的device cuda这种命令是nonono,不过可以放在mps(Metal Performance Shaders)上加速。如果调用模型,除了删掉参数: device='cuda',还需要把promptbench/models/models.py文件中的代码,如果有cuda的地方改成mps。比如:
input_ids = self.tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
cuda改成mps,即
input_ids = self.tokenizer(input_text, return_tensors="pt").input_ids.to("mps")
另外,由于我的硬盘没那么大,下载模型的时候可能会说没空间,如果要删除之前的模型,模型位置在:~/.cache/huggingface/hub/。
vicuna和llama系列模型
'llama2-7b', 'llama2-7b-chat', 'llama2-13b', 'llama2-13b-chat', 'llama2-70b', 'llama2-70b-chat', 'vicuna-7b', 'vicuna-13b', 'vicuna-13b-v1.3'如果直接填进去加载都失败了,然后看了promptbench/models/__init__.py的代码,目测要调用llama或者vicuna模型都需要提前下载的样子。大家可以再多试试!!!万一我说的是错的呢😑。
if model_class == LlamaModel or model_class == VicunaModel:
return model_class(self.model, max_new_tokens, temperature, system_prompt, model_dir)然后我就去下载llama和vicuna了,然后首先你需要下载git-lfs(Git Large File Storage | Git Large File Storage (LFS) replaces large files such as audio samples, videos, datasets, and graphics with text pointers inside Git, while storing the file contents on a remote server like GitHub.com or GitHub Enterprise.),下载了homebrew的朋友可以直接运行下面的代码brew install git-lfs,然后运行git lfs install,如果显示Git LFS initialized说明安装成功。接着,俺下载了一个vicuna项目:https://huggingface.co/lmsys/vicuna-7b-v1.5/tree/main。
llama模型下载现在需要申请许可,就是点files and version,你要申请一下,然后还要去meta官网(https://llama.meta.com/llama-downloads/)上填写一些信息,然后会给你发个邮件告诉你可以用了。

邮件大概长这个样子:

然后我就去下载了Llama-2-7b-hf模型(不要问我为什么meta-llama/Llama-2-7b不可以加载,少了一个config.json文件)
git clone https://huggingface.co/meta-llama/Llama-2-7b-hf
如果你在这一步发现,你没办法下载,就算是输入了你的huggingface的username和密码。因为它说password authentication已经不管用了,那你就试试这个huggingface-cli login。

登陆以后记得还需要输入access token,要提前申请哦!在你的hugging face账户信息里的Access Tokens(如下图)。

加载代码:model = pb.LLMModel(model="model name", model_dir='the file path of your vicuna or llama')
PromptBench各个模型加载情况总结
✅ google/flan-t5-large、google/flan-ul2、phi的调用,改完了mps后,直接修改model name即可
✅ llama系列和vicuna的调用,下载完了模型文件后,修改model name,加入model_dir参数即可
✅ palm模型,需要参数palm_key,申请地址:https://ai.google.dev/tutorials/setup
✅ gpt系列,需要参数openai_key,申请地址:https://platform.openai.com/api-keys
这个key的申请,或多或少需要翻墙之类的。
PromptBench的Prompt快速工程
大家可以直接看prompt engineering的示例代码:https://github.com/microsoft/promptbench/blob/main/examples/prompt_engineering.ipynb
具体有五类:chain of thought,emotion prompt,expert prompt,generated knowledge和least to most。源码的话在这里:https://github.com/microsoft/promptbench/tree/main/promptbench/prompt_engineering。本章节的话大概就是带着大家过一遍这几种工程方式。
chain of thought
chain of thought:简称Cot,文章链接,https://arxiv.org/pdf/2201.11903.pdf。为了提高LLM的推理能力,将推理步骤的内容喂给模型,下图中高亮的部分就是咱们的chains of thought。

chain of thought prompting指在给出从开始到结束的step by step的步骤,而不是给出多个例子让语言模型去理解,更多的是希望帮助“推理”。当任务涉及需要算术、常识和符号推理的复杂推理时,试试CoT, 此时模型需要理解并遵循中间步骤才能得出正确的答案。
emotion prompt
emotion prompt:文章链接,https://arxiv.org/pdf/2307.11760.pdf。大概意思就是你在告诉模型要做什么的时候,还要给它一些Psychology上的提示词,比如,“这个问题对我来说很重要啊。”,“我相信你可以做得很好!”,“这件事情很紧急!”研究人员发现,给出这样的一些emotion以后,LLM的效果有一定的提升。简而言之,咱们需要PUA那个 LLM!!!

expert prompt
expert prompt:看了源代码以后PromptBench里的expert prompt不太像角色扮演,一般提到expert prompt可能指的是告诉LLM你的专长是什么,引导其返回该领域的信息。比如在开始的时候说“我希望你是XX专家”,“我希望你扮演XX角色”,继续PUA那个 LLM!!!
generated knowledge
generate knowledge:文章链接,https://arxiv.org/pdf/2110.08387.pdf。大概就是在回答问题时提供知识(其中包括从语言模型生成知识)作为prompt的附加输入。比如在问答的情景下,除了Question这个输入,Prompt里还有Knowledge这一项。

least to most
least to most:文章链接,https://arxiv.org/pdf/2205.10625.pdf。这个idea来自教育心理学,用于表示使用渐进的提示来帮助学生学习新知识的方式。 然后咱就是应用这种least to most来喂语言模型。 我觉得这个有一些子类似CoT,看起来是CoT的进阶版,因为需要先拆分问题,然后再逐一解决。

PromptBench对抗性Prompt评估
原文还是说的很清楚的,主要分成了character-level,word-level,sentence-level和semantic-level。具体如下图,看了下代码,Semantic就用了textattack包里的wordembeddingdistance来做的。大概是做啥呢,就是大家之前发现如果我们对输入样本做了轻微的改动,模型就可能会犯错,鲁棒性就是有些差了。因此以textbugger为例,通过改变字母,生成稍微有改变的文本,且保留原来的语义信息,虽然不是百分百正确了,但是要的就是这个味儿。

- Textbugger:论文链接,https://arxiv.org/pdf/1812.05271.pdf。

- Deepwordbug:论文链接,https://arxiv.org/pdf/1801.04354.pdf。

- BertAttack:论文链接,https://arxiv.org/pdf/2004.09984.pdf。
- TextFooler:论文链接,https://arxiv.org/pdf/1907.11932.pdf。
- StressTest:论文链接,https://aclanthology.org/C18-1198.pdf。

- StressTest:PromptBench是用的length mismatch来做的stress test。texts = [" and true is true ", " and false is not true ", " and true is true "*5]
- CheckList:论文链接,https://aclanthology.org/2020.acl-main.442.pdf。
PromptBench的动态评估
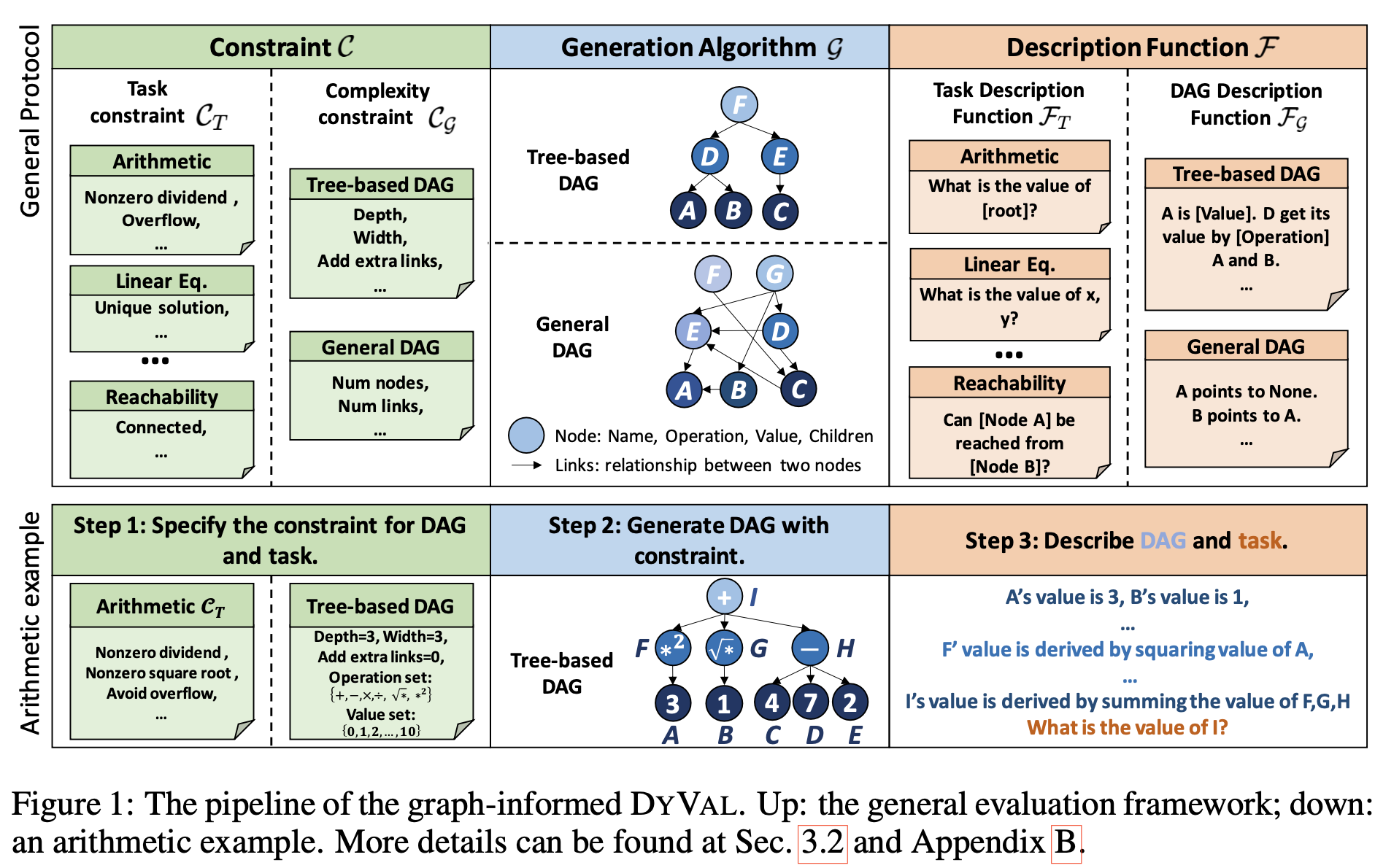
这里的动态评估部分,主要是文章https://arxiv.org/pdf/2309.17167.pdf提出的Dyval的应用,相比于固定的数据来做测试,Dyval是动态实时生成评估样本的。原文是这么描述Dyval的:
DYVAL consists of three components: 1) the generation algorithm G to generate test samples with diversities; 2) the constraint C to modulate sample complexity and validity; and 3) the description function F to translate the generated samples into natural languages.
具体步骤大家去看原文吧!
PromptBench总结
反正我整个用下来,就觉得好像不是那么好用。我的电脑硬盘没那么大,下载模型的时候时常没空间,因此能跑起来就主动暂停,删模型换下一个尝试了,更不用说本人还没有GPU。LLM可真的有够大的,自己玩玩,是玩不动的。总的来说,bench越来越多,model越来越大,prompt也是各种花样。怀念传统NLP,或者说不用LLM的NLP。