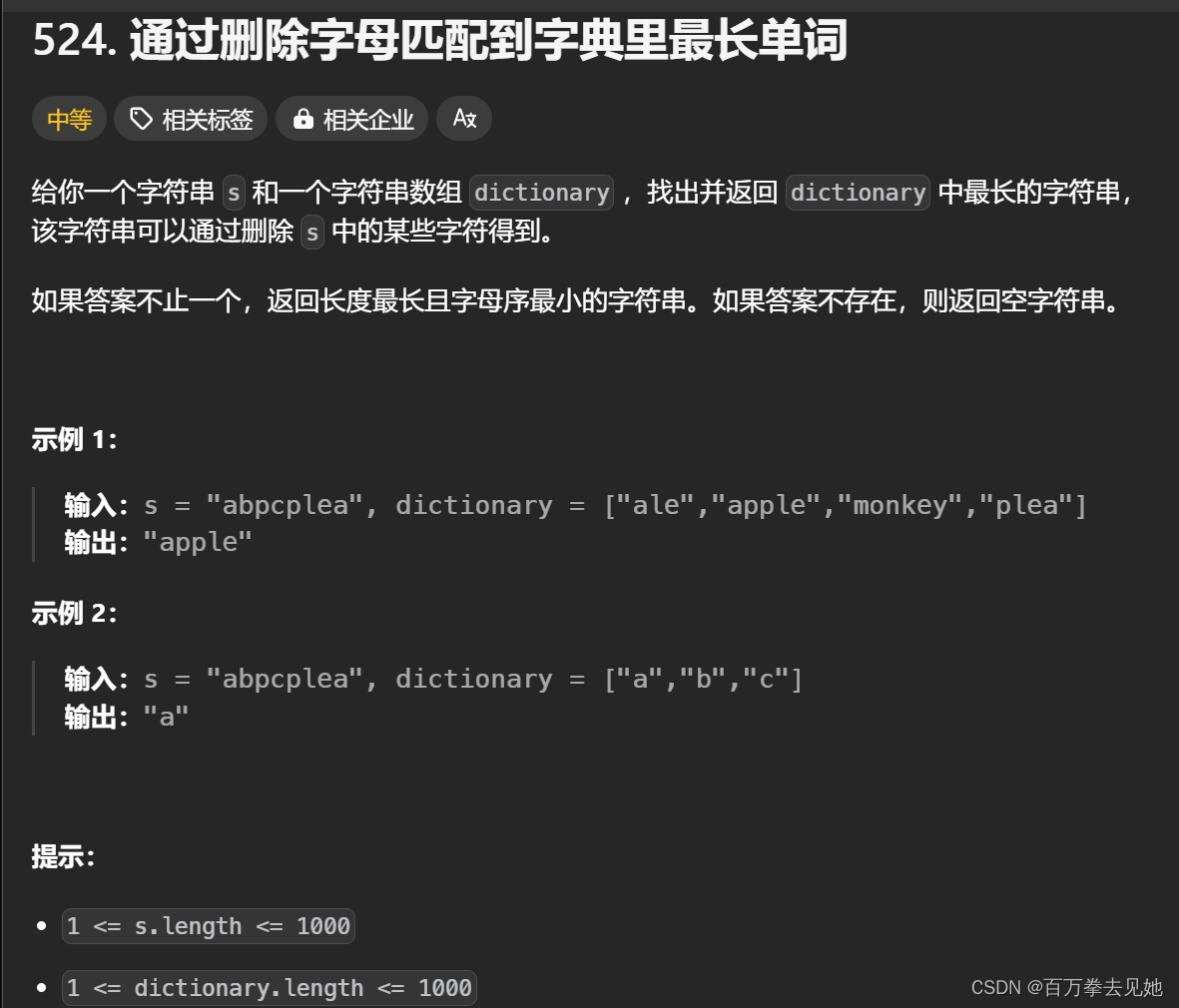
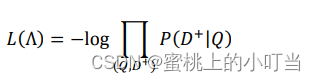一、参考资料
原始论文:[1]
IJCV22 | 已开源 | 华为GhostNet再升级,全系列硬件上最优极简AI网络
二、G-GhostNet相关介绍
G-GhostNet 又称为 GhostNetV1 的升级版,是针对GPU优化的轻量级神经网络。
1. 摘要
GhostNetV1 作为近年来最流行的轻量级神经网络架构,其在ARM和CPU端的应用已经非常广泛。而在GPU和NPU这种并行计算设备上,GhostNetV1 并没有体现出优势。最近,华为诺亚的研究者针对GPU等设备的特点,巧妙引入跨层的廉价操作,减少计算量的同时减少的内存数据搬运,基于此设计了GPU版GhostNet。实验表明,G-GhostNet 在现有GPU设备上达到了速度和精度的最佳平衡。在华为自研NPU昇腾310上,G-GhostNet 的速度比同量级 ResNet 要快30%以上。该论文已被计算机视觉顶级期刊IJCV收录。
2. 引言
关于GhostNetV1网络模型的详细介绍,请参考另一篇博客:通俗易懂理解GhostNetV1轻量级神经网络模型
基于卷积神经网络的推理模型在以计算机视觉为基础的各个终端任务如图像识别、目标检测、实力分割等场景中都有广泛的应用。传统的基础神经网络往往由于规模较大的参数量与计算量,导致各项终端任务无法实时工作。现有的轻量级推理网络(MobileNet, EfficientNet, ShuffleNet)都是针对CPU、ARM等移动设备设计而成,一般以深度可分离卷积为基础,这些网络相比于基于普通卷积的神经网络(ResNet, Inception)具有更少的计算量。但是在GPU等基于大吞吐量设计的处理单元上的表现却不尽人意,推理速度甚至比传统的卷积神经网络更慢。随着硬件基础的提升,云服务器、手机等端侧设备也配备了大量的GPU模块,设计出更适合GPU的推理模型具有重大的学术和商业价值。

回顾一下 GhostNetV1 的架构,GhostNetV1 由Ghost Module搭建而成,Ghost Module 采用普通卷积生成少量特征图,而更多特征图则使用廉价操作(如DWConv)来生成。这样,Ghost Module使用更少计算量更廉价的方式生成了和普通卷积层一样多的特征图。而 DWConv 等廉价操作对于流水线型CPU、ARM等移动设备更友好,对于并行计算能力强的GPU则不太友好。
相同stage之间,不同层的输出特征具有较高的相似性,不同stage之间,特征的相似性较低。因此我们提出一种在同一个stage内进行跨层廉价线性变换,生成Ghost特征的基础网络结构 G-GhostNet。
G-GhostNet 重点关注在GPU设备上能快速推理的卷积神经网络,设计出用更少计算量和参数量达到更高推理速度和更高测试精度的模型,让网络生成与关键特征相似性高的特征。
3. G-Ghost stage

图(a) 是普通卷积神经网络(例如ResNet)的stage,记作Vanilla CNN stage,由n层卷积层
{
L
1
,
L
2
,
⋯
,
L
n
}
\{L_{1},L_{2},\cdots,L_{n}\}
{L1,L2,⋯,Ln} 堆叠而成。给定输入特征图
X
X
X,则第一个block和最后一个block的输出特征图可以表示为:
Y
1
=
L
1
(
X
)
,
Y
n
=
L
n
(
L
n
−
1
(
⋯
L
2
(
Y
1
)
)
)
,
\begin{aligned}Y_1&=L_1(X),\\Y_n&=L_n(L_{n-1}(\cdots L_2(Y_1))),\end{aligned}
Y1Yn=L1(X),=Ln(Ln−1(⋯L2(Y1))),
以 ResNet-34 为例,第2个stage的第一个block和最后一个block的输出特征图,如下图所示。

图(b) 是 G-Ghost 的stage,记作G-Ghost stage,其由主干分支和Ghost分支组成。给定输入特征图
X
∈
R
c
×
h
×
w
X\in\mathbb{R}^{c\times h\times w}
X∈Rc×h×w,主干分支的最后一个block的输出特征图记作
Y
n
c
∈
R
(
1
−
λ
)
c
×
h
×
w
Y_{n}^{c}\in\mathbb{R}^{(1-\lambda)c\times h\times w}
Ync∈R(1−λ)c×h×w,Ghost分支输出的的Ghost特征图记作
Y
n
g
∈
R
λ
c
×
h
×
w
Y_{n}^{g}\in\mathbb{R}^{\lambda c\times h\times w}
Yng∈Rλc×h×w,其中
0
≤
λ
≤
1
0\leq\lambda\leq1
0≤λ≤1,表示Ghost特征图的比例。
Y
n
c
Y_{n}^{c}
Ync 可以表示为:
Y
n
c
=
L
n
′
(
L
n
−
1
′
(
⋯
L
2
′
(
Y
1
)
)
)
,
Y_{n}^{c}=L'_{n}(L'_{n-1}(\cdots L'_{2}(Y_{1}))),
Ync=Ln′(Ln−1′(⋯L2′(Y1))),
其中, L 2 ′ , ⋯ , L n ′ L_2^{\prime},\cdots,L_n^{\prime} L2′,⋯,Ln′ 是以 ( 1 − λ ) × w i d t h (1-\lambda)\times\mathrm{width} (1−λ)×width倍率进行压缩的block。
Y
n
g
Y_n^g
Yng 与第一个block的输出特征图
Y
1
Y_1
Y1类似,可以通过廉价的线性变换
C
C
C得到,表达公式如下:
Y
n
g
=
C
(
Y
1
)
,
Y_n^g=C(Y_1),
Yng=C(Y1),
其中,
C
C
C 表示廉价的线性变换,linear kernels尺寸可以为
1
×
1
1 \times 1
1×1 或者
5
×
5
5 \times 5
5×5 等。
最后,拼接(concat)
Y
n
c
Y_{n}^{c}
Ync 和
Y
n
g
Y_n^g
Yng,得到G-Ghost stage最终的输出:
Y
n
=
[
Y
n
c
,
Y
n
g
]
.
Y_n=[Y_n^c,Y_n^g].
Yn=[Ync,Yng].
图©是在G-Ghost stage 基础上增加mix操作的stage,记作
G-Ghost stage w/ mix
\text{G-Ghost stage w/ mix}
G-Ghost stage w/ mix,mix操作用于增强中间层信息。
G-Ghost stage w/ mix
\text{G-Ghost stage w/ mix}
G-Ghost stage w/ mix利用多个廉价线性变换生成多个Ghost特征图,其原理与G-Ghost stage类似,不再赘述。
4. G-GhostNet
G-GhostNet 由多个G-Ghost stage 堆叠而成,具体网络结构如下表所示。

解释说明
Block,表示传统的残差模块;output,表示输出特征图的尺寸;#out,表示输出特征图的channels。
5. 总结
G-GhostNet 提出的跨层廉价线性变换,可用于不同网络结构中,进一步优化模型运行所需的内存,提升GPU等设备上的运行速度。至此,GhostNet系列网络模型已经打通ARM、CPU、GPU甚至NPU的常用设备,能够在不同硬件需求下达到最佳的速度和精度的平衡。
三、参考文献
[1] Han K, Wang Y, Xu C, et al. GhostNets on heterogeneous devices via cheap operations[J]. International Journal of Computer Vision, 2022, 130(4): 1050-1069.