文章目录
- 关于HashMap的面试问题
- 1、HashMap的底层实现
- 2、HashMap的数组的元素类型
- 3、为什么要使用数组?
- 4、HashMap的数组的初始化长度
- 5、HashMap的映射关系的存储索引index如何计算
- 6、HashMap 为什么使用 &按位与运算代替%模运算?
- 7、为什么要使用hashCode()? 空间换时间
- 8、为什么数组还需要链表?或问如何解决hash或[index]冲突问题?
- 9、hash()函数的作用是什么
- 10、HashMap的数组长度为什么一定要是2的幂次方
- 11、HashMap的数组什么时候扩容?
- 12、如何计算扩容阈值(临界值)?
- 13、loadFactor为什么是0.75,如果是1或者0.1呢有什么不同?
- 14、JDK1.8的HashMap什么时候树化?
- 15、JDK1.8的HashMap什么时候反树化?
- 16、JDK1.8的HashMap为什么要树化?
- 17、JDK1.8的HashMap为什么要反树化?
- 18、作为HashMap的key类型重写equals和hashCode方法有什么要求
- 19、为什么大部分 hashcode 方法使用 31?
- 20、请问已经存储到HashMap中的key的对象属性是否可以修改?为什么?
- 21、所以为什么,我们实际开发中,key的类型一般用String和Integer
- 22、为什么HashMap中的Node或Entry类型的hash变量与key变量加final声明?
- 23、为什么HashMap中的Node或Entry类型要单独存储hash?
- 24、请问已经存储到HashMap中的value的对象属性是否可以修改?为什么?
- 25、如果key是null是如何存储的?
- 26、table[0]中存储的是是否只有key为null的键值对?
关于HashMap的面试问题
1、HashMap的底层实现
答:JDK1.7及其之前的版本是数组+链表,JDK1.8是数组+链表/红黑树
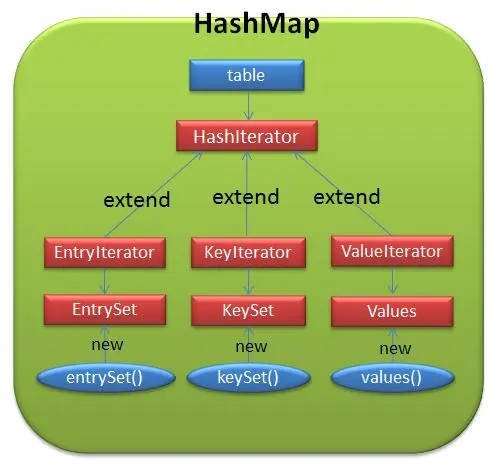
2、HashMap的数组的元素类型
答:java.util.Map$Entry接口类型。
JDK1.7的HashMap中有内部类Entry实现Entry接口
JDK1.8的HashMap中有内部类Node和TreeNode类型实现Entry接口,并且TreeNode是Node的子类。
3、为什么要使用数组?
答:因为数组的访问的效率高或者说,根据[下标]操作效率高f
4、HashMap的数组的初始化长度
答:默认的初始容量值是16,也可以手动指定
5、HashMap的映射关系的存储索引index如何计算
答:hash & table.length-1
6、HashMap 为什么使用 &按位与运算代替%模运算?
答:因为&基于二进制补码的位运算符,效率高,
虽然 hash值 % table.length 和 hash值 & table.length-1的结果一样,但是&效率高。
7、为什么要使用hashCode()? 空间换时间
答:因为hashCode()是一个整数值,可以用来直接计算index,效率比较高,用数组这种结构虽然会浪费一些空间,但是可以提高查询效率。
8、为什么数组还需要链表?或问如何解决hash或[index]冲突问题?
答:为了解决hash和[index]冲突问题
(1)两个不相同的key的hashCode值本身可能相同
(2)两个不相同的key的hashCode值不同,但是经过hash()运算,结果相同
(3)两个hashCode不相同的key,经过hash()运算,结果也不相同,但是通过 hash & table.length-1运算得到的[index]可能相同
那么意味着table[index]下可能需要存储多个Entry的映射关系对象,所以需要链表
9、hash()函数的作用是什么
答:在计算index之前,会对key的hashCode()值,做一个hash(key)再次哈希的运算,这样可以使得Entry对象更加散列的存储到table中
JDK1.8关于hash(key)方法的实现比JDK1.7要简洁。 key.hashCode() ^ key.Code()>>>16; 因为这样可以使得hashCode的高16位信息也能参与到运算中来
10、HashMap的数组长度为什么一定要是2的幂次方
答:因为2的n次方-1的二进制值是前面都0,后面几位都是1,这样的话,与hash进行&运算的结果就能保证在[0,table.length-1]范围内,而且是均匀的。
如果手动指定为一个非2的n次方的数组长度,HashMap是否接收呢?如果不接收怎么处理呢?
会纠正为>=手动指定的长度的最近的一个2的n次方值。
11、HashMap的数组什么时候扩容?
答:JDK1.7版:当要添加新Entry对象时发现(1)size达到threshold(2)table[index]!=null时,两个条件同时满足会扩容
JDK1.8版:当要添加新Entry对象时发现(1)size达到threshold(2)当table[index]下的结点个数达到8个但是table.length又没有达到64。两种情况满足其一都会导致数组扩容
而且数组一旦扩容,不管哪个版本,都会导致所有映射关系重新调整存储位置。
12、如何计算扩容阈值(临界值)?
答:threshold = capacity * loadfactor
capacity = table.length
13、loadFactor为什么是0.75,如果是1或者0.1呢有什么不同?
答:1的话,会导致某个table[index]下面的结点个数可能很长
0.1的话,会导致数组扩容的频率太高
14、JDK1.8的HashMap什么时候树化?
答:当table[index]下的结点个数达到8个但是table.length已经达到64
15、JDK1.8的HashMap什么时候反树化?
答:(1)当删除table[index]下的树结点时,最后这个根结点的左右结点有null,或根结点的左结点的左结点为null,会反树化
(2)当table[index]下的树结点个数少于等于6个后,又重新添加新的映射关系到map中,导致了map重新扩容了,这个时候如果table[index]下面还是小于等于6的个数,那么会反树化
16、JDK1.8的HashMap为什么要树化?
答:因为当table[index]下的结点个数超过8个后,查询效率就低下了,修改为红黑树的话,可以提高查询效率
17、JDK1.8的HashMap为什么要反树化?
答:因为因为当table[index]下树的结点个数少于6个后,使用红黑树反而过于复杂了,此时使用链表既简洁又效率也不错
18、作为HashMap的key类型重写equals和hashCode方法有什么要求
(1)equals与hashCode一起重写
(2)重写equals()方法,但是有一些注意事项;
- 自反性:x.equals(x)必须返回true。
对称性:x.equals(y)与y.equals(x)的返回值必须相等。
传递性:x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)必须为true。
一致性:如果对象x和y在equals()中使用的信息都没有改变,那么x.equals(y)值始终不变。
非null:x不是null,y为null,则x.equals(y)必须为false。
(3)重写hashCode()的注意事项
- 如果equals返回true的两个对象,那么hashCode值一定相同,并且只要参与equals判断属性没有修改,hashCode值也不能修改;
如果equals返回false的两个对象,那么hashCode值可以相同也可以不同;
如果hashCode值不同的,equals一定要返回false;
hashCode不宜过简单,太简单会导致冲突严重,hashCode也不宜过于复杂,会导致性能低下;
19、为什么大部分 hashcode 方法使用 31?
答:因为31是一个不大不小的素数,而且是一个2的n次方-1的一个素数。用这样的一个数来计算,底层使用二进制计算效率会更高,hashCode冲突概率比较低。
20、请问已经存储到HashMap中的key的对象属性是否可以修改?为什么?
答:如果该属性参与hashCode的计算,那么不要修改。因为一旦修改hashCode()已经不是原来的值。
而存储到HashMap中时,key的hashCode()–>hash()–>hash已经确定了,不会重新计算。用新的hashCode值再查询get(key)/删除remove(key)时,算的hash值与原来不一样就不找不到原来的映射关系了。
21、所以为什么,我们实际开发中,key的类型一般用String和Integer
答:因为他们不可变。
22、为什么HashMap中的Node或Entry类型的hash变量与key变量加final声明?
答:因为不希望你修改hash和key值
23、为什么HashMap中的Node或Entry类型要单独存储hash?
答:为了在添加、删除、查找过程中,比较hash效率更高,不用每次重新计算key的hash值
24、请问已经存储到HashMap中的value的对象属性是否可以修改?为什么?
答:可以。因为我们存储、删除等都是根据key,和value无关。
25、如果key是null是如何存储的?
答:会存在table[0]中
26、table[0]中存储的是是否只有key为null的键值对?
不是,还有hashCode值不为0,但是hash(key) & table.length-1 结果是0,也是存在table[0]中。