系列文章导航
第一篇—接口参数的一些弯弯绕绕
第二篇—接口用户上下文的设计与实现
第三篇—留下用户调用接口的痕迹
第四篇—接口的权限控制
第五篇—接口发生异常如何统一处理
第六篇—接口防抖(防重复提交)的一些方式
第七篇—接口限流策略
第八篇—分页接口的设计和优化
本文参考项目源码地址:summo-springboot-interface-demo
一、前言
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。
作为一名从业已达六年的老码农,我的工作主要是开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。
分页查询的需求想必大家都做过吧,很简单,无非就是查询SQL后面加上limit pageNum,pageSize,复杂点的话加个排序。虽说它简单吧,但真正封装过分页组件的同学应该也不多吧,很多时候都是上网copy一份或者拿前辈封装好的。这篇文章呢,我就讲一下我是怎么做分页的,以及分页有哪些需要注意的点。
二、分页组件设计
1. 查询参数
查询的核心参数是:
- pageNum:页码
- pageSize:每页大小
有了这两个参数,就可以进行分页查询了。
2. 返回结果
结果的核心属性是:
- totalItems:查询到的总条数
- totalPages:总页数
- currentPage:当前页
- itemsPerPage:每页条数
- value:分页结果
有了这些返回信息,基本上一个分页表格可以展示了。
这里我使用一个model表示它
/**
* 分页
*
* @param <T>
*/
public class Page<T> {
/**
* 查询到的总条数
*/
private long totalItems;
/**
* 总页数
*/
private long totalPages;
/**
* 当前页,PageNum
*/
private int currentPage;
/**
* 每页条数,PageSize
*/
private int itemsPerPage;
/**
* 分页结果
*/
private List<T> value;
private Page() {
}
public long getTotalItems() {
return totalItems;
}
public void setTotalItems(long totalItems) {
this.totalItems = totalItems;
}
public long getTotalPages() {
return totalPages;
}
public void setTotalPages(long totalPages) {
this.totalPages = totalPages;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getItemsPerPage() {
return itemsPerPage;
}
public void setItemsPerPage(int itemsPerPage) {
this.itemsPerPage = itemsPerPage;
}
public List<T> getValue() {
return value;
}
public void setValue(List<T> value) {
this.value = value;
}
@Override
public String toString() {
return "Page{" + "totalItems=" + totalItems + ", totalPages=" + totalPages + ", currentPage=" + currentPage
+ ", itemsPerPage=" + itemsPerPage + ", value=" + value + '}';
}
}
3. 逻辑完善
(1)空分页
当查询的数据为空时,返回一个空分页
/**
* 返回一个空的分页
*
* @param <T>
* @return
*/
public static <T> Page<T> emptyPage() {
Page<T> result = new Page<T>();
result.setValue(new ArrayList<T>());
return result;
}
(2)假分页
/**
* 根据完整的项目列表创建假分页。
*
* @param list 完整的项目列表,用于分页。
* @param pageNum 要检索的页码。
* @param pageSize 每页的项目数目。
* @return 返回指定页面的Page对象,包含对应的项目列表。
*/
public static <T> Page<T> startPage(List<T> list, int pageNum, int pageSize) {
int totalItems = list.size();
int totalPages = (int)Math.ceil((double)pageNum / pageSize);
// 计算请求页面上第一个项目的索引
int startIndex = (pageNum - 1) * pageSize;
// 确保不会超出列表范围
startIndex = Math.max(startIndex, 0);
// 计算请求页面上最后一个项目的索引
int endIndex = startIndex + pageSize;
// 确保不会超出列表范围
endIndex = Math.min(endIndex, totalItems);
// 从完整列表中提取当前页面的子列表
List<T> pageItems = list.subList(startIndex, endIndex);
// 创建并填充Page对象
Page<T> page = new Page<>();
page.setCurrentPage(pageNum);
page.setItemsPerPage(pageSize);
page.setTotalItems(totalItems);
page.setTotalPages(totalPages);
page.setValue(pageItems);
return page;
}
假分页没什么好说的,就是把数据全部读取到内存中,在内存中进行分页,这个代码不难,网上一搜全是。
(3)真分页
关于真分页,有很多种实现方式,这里我就说一下我常用的PageHelper,使用起来很简单,直接maven引入就行了,不需要额外配置。
maven依赖如下
<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.1</version>
</dependency>
使用方式也很简单
//设置分页参数
PageHelper.startPage(pageNum, pageSize);
//查询用户列表
List<UserDO> list = userRepository.list();
PageHelper 的工作原理基于 MyBatis 拦截器(Interceptor)机制,详细的我就不展开了,这里我主要讲一下分页之后如何设置总条数、总页数等属性。
回到我们的Page类中来,使用PageHelper分页完成之后如获取当前分页的一些属性呢,请看代码
/**
* 真分页数据转换
*
* @param doList 原始DO列表
* @param dtoList 返回值DTO列表
* @param <T>
* @return 分页数据
*/
public static <T> Page<T> resetPage(List doList, List<T> dtoList) {
if (null == doList) {
//如果doList为空,返回空分页
return emptyPage();
}
Page<T> result = new Page();
//获取PageHelper的分页属性
PageInfo<T> pageInfo = new PageInfo(doList);
result.setTotalPages(pageInfo.getPages());
result.setCurrentPage(pageInfo.getPageNum());
result.setItemsPerPage(pageInfo.getPageSize());
result.setTotalItems(pageInfo.getTotal());
//设置返回值列表
result.setValue(dtoList);
return result;
}
核心代码是
PageInfo<T> pageInfo = new PageInfo(doList);,这样可以获取到PageHelper的PageInfo类,PageInfo类中就有我们需要的属性了。
(4)小结一下
我先把完整的Page类代码贴一下
package com.summo.demo.page;
import java.util.ArrayList;
import java.util.List;
import com.github.pagehelper.PageInfo;
/**
* 分页
*
* @param <T>
*/
public class Page<T> {
/**
* 查询到的总条数
*/
private long totalItems;
/**
* 总页数
*/
private long totalPages;
/**
* 当前页,PageNum
*/
private int currentPage;
/**
* 每页条数,PageSize
*/
private int itemsPerPage;
/**
* 分页结果
*/
private List<T> value;
private Page() {
}
/**
* 返回一个空的分页
*
* @param <T>
* @return
*/
public static <T> Page<T> emptyPage() {
Page<T> result = new Page<T>();
result.setValue(new ArrayList<T>());
return result;
}
/**
* 根据完整的项目列表创建假分页。
*
* @param list 完整的项目列表,用于分页。
* @param pageNum 要检索的页码。
* @param pageSize 每页的项目数目。
* @return 返回指定页面的Page对象,包含对应的项目列表。
*/
public static <T> Page<T> startPage(List<T> list, int pageNum, int pageSize) {
int totalItems = list.size();
int totalPages = (int)Math.ceil((double)pageNum / pageSize);
// 计算请求页面上第一个项目的索引
int startIndex = (pageNum - 1) * pageSize;
// 确保不会超出列表范围
startIndex = Math.max(startIndex, 0);
// 计算请求页面上最后一个项目的索引
int endIndex = startIndex + pageSize;
// 确保不会超出列表范围
endIndex = Math.min(endIndex, totalItems);
// 从完整列表中提取当前页面的子列表
List<T> pageItems = list.subList(startIndex, endIndex);
// 创建并填充Page对象
Page<T> page = new Page<>();
page.setCurrentPage(pageNum);
page.setItemsPerPage(pageSize);
page.setTotalItems(totalItems);
page.setTotalPages(totalPages);
page.setValue(pageItems);
return page;
}
/**
* 真分页数据转换
*
* @param doList 原始DO列表
* @param dtoList 返回值DTO列表
* @param <T>
* @return 分页数据
*/
public static <T> Page<T> resetPage(List doList, List<T> dtoList) {
if (null == doList) {
//如果doList为空,返回空分页
return emptyPage();
}
Page<T> result = new Page();
//获取PageHelper的分页属性
PageInfo<T> pageInfo = new PageInfo(doList);
result.setTotalPages(pageInfo.getPages());
result.setCurrentPage(pageInfo.getPageNum());
result.setItemsPerPage(pageInfo.getPageSize());
result.setTotalItems(pageInfo.getTotal());
//设置返回值列表
result.setValue(dtoList);
return result;
}
public long getTotalItems() {
return totalItems;
}
public void setTotalItems(long totalItems) {
this.totalItems = totalItems;
}
public long getTotalPages() {
return totalPages;
}
public void setTotalPages(long totalPages) {
this.totalPages = totalPages;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getItemsPerPage() {
return itemsPerPage;
}
public void setItemsPerPage(int itemsPerPage) {
this.itemsPerPage = itemsPerPage;
}
public List<T> getValue() {
return value;
}
public void setValue(List<T> value) {
this.value = value;
}
@Override
public String toString() {
return "Page{" + "totalItems=" + totalItems + ", totalPages=" + totalPages + ", currentPage=" + currentPage
+ ", itemsPerPage=" + itemsPerPage + ", value=" + value + '}';
}
}
看到这是不是觉得挺简单的,别急,复杂点的在下面。
三、深分页查询性能优化
"深分页查询"通常是指在数据库查询中需要获取结果集很深的页码的数据,例如获取第1000页或更深的数据。在传统的分页查询中,我们通常使用类似于以下的SQL语句:
SELECT * FROM table LIMIT 1000, 20;
这里,LIMIT 1000, 20 表示跳过前1000条记录,然后获取接下来的20条记录。这种查询方式在前几页的数据获取时表现良好,但是随着页码的增大,性能会显著下降。因为数据库需要扫描并跳过大量的行才能到达指定的位置,这个过程十分耗时,尤其很多时候还需要加上排序。
优化的方法有很多,这里我推荐使用如下方式优化
- 对排序字段建索引,如create_time、id等;
- 只查询id字段;
- 根据id反查数据内容;
- 遇到join查询时,也可以使用该方法进行优化,不过麻烦些;
四、分页合理化
但大家可能对分页合理化这个词有点儿陌生,不过应该都遇到过因为它产生的问题。这些问题不会触发明显的错误,所以大家一般都忽视了这个问题。
它的定义:分页合理化通常是指后端在处理分页请求时会自动校正不合理的分页参数,以确保用户始终收到有效的数据响应。
那么啥是分页合理化,我来举几个例子:
1. 举些例子
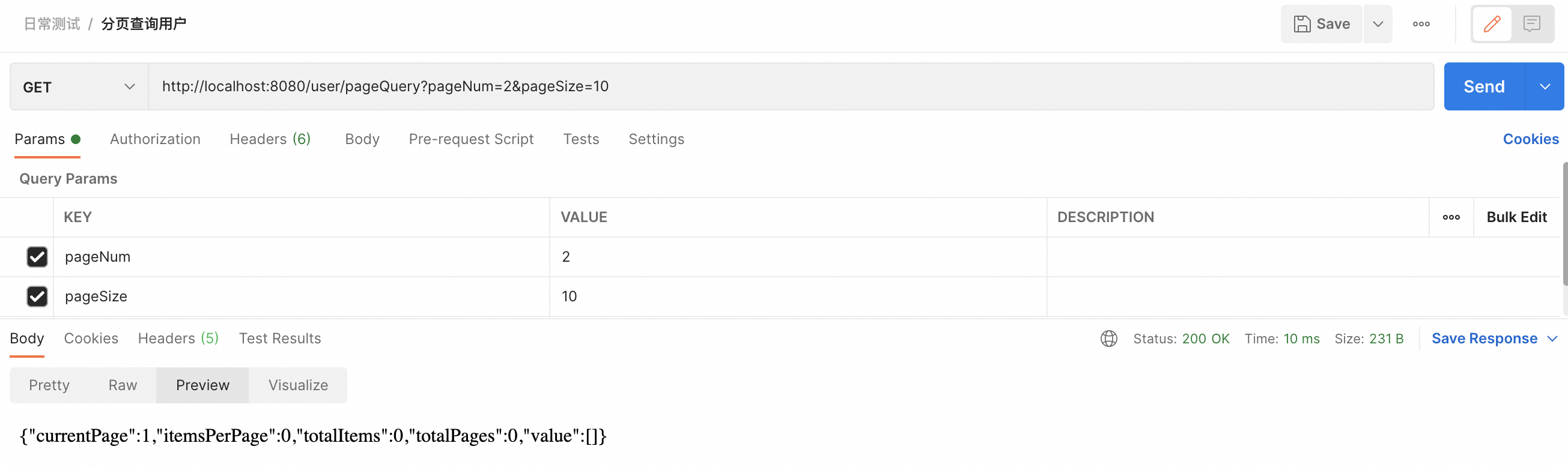
(1)请求页码超出范围
假设数据库中有100条记录,每页展示10条,那么就应该只有10页数据。如果用户请求第11页,不合理化处理可能会返回一个空的数据集,告诉用户没有更多数据。开启分页合理化后,系统可能会返回第10页的数据(即最后一页的数据),而不是一个空集。
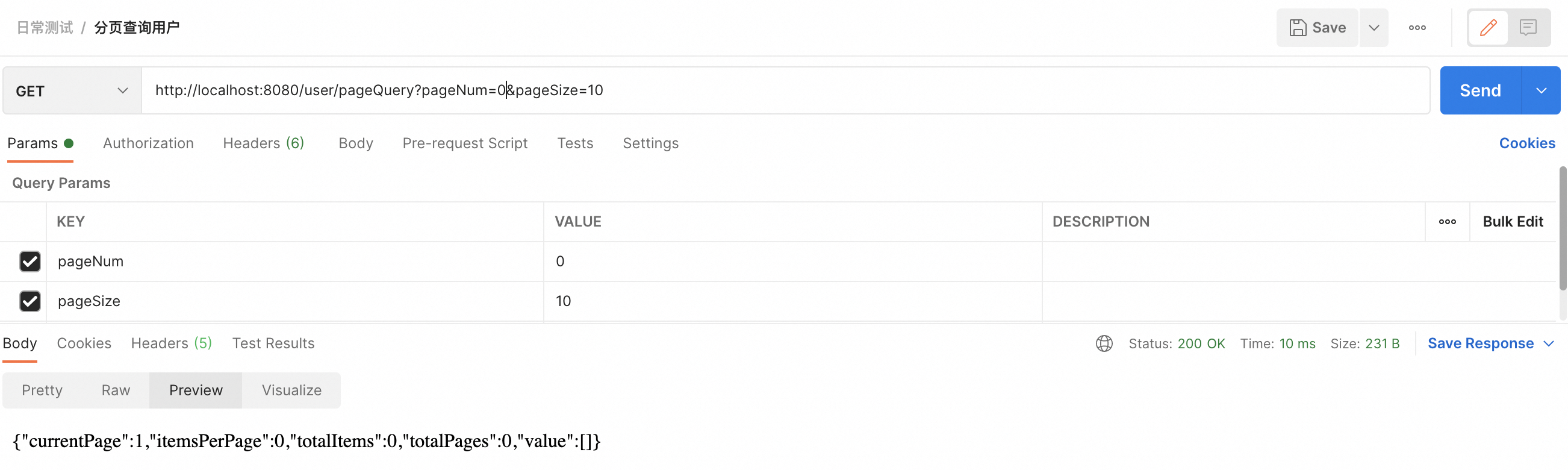
(2)请求页码小于1
用户请求的页码如果是0或负数,这在分页上下文中是没有意义的。开启分页合理化后,系统会将这种请求的页码调整为1,返回第一页的数据。
(3)请求的数据大小小于1
如果用户请求的数据大小为0或负数,这也是无效的,因为它意味着用户不希望获取任何数据。开启分页合理化后,系统可能会设置一个默认的页面大小,比如每页显示10条数据。
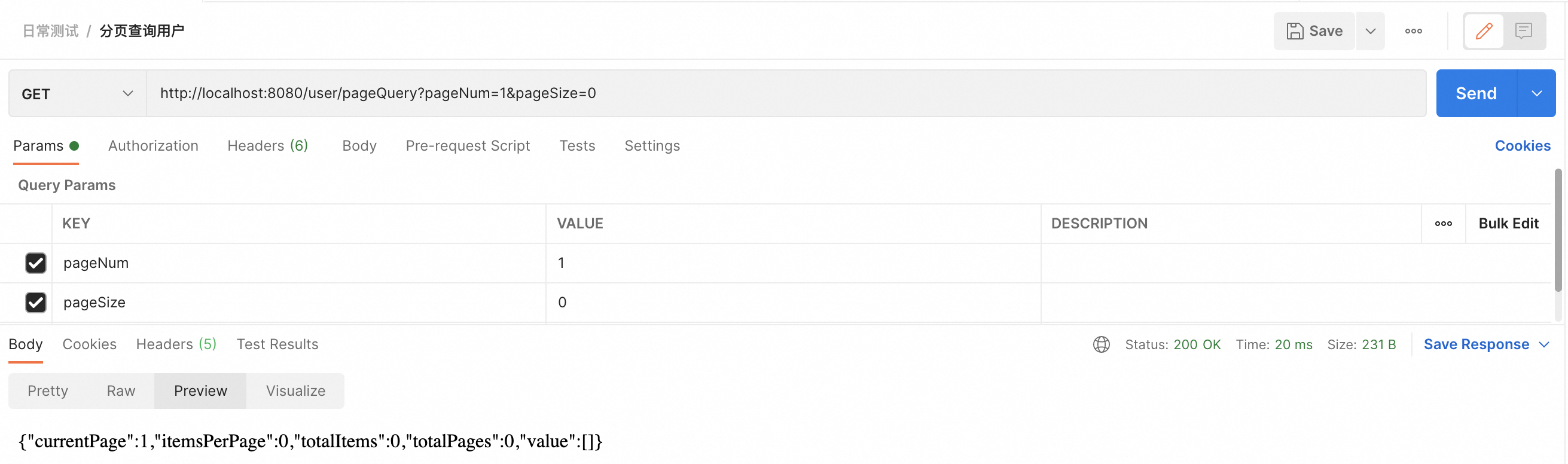
(4)请求的数据大小不合理
如果用户请求的数据大小非常大,比如一次请求1000条数据,这可能会给服务器带来不必要的压力。开启分页合理化后,系统可能会限制页面大小的上限,比如最多只允许每页显示100条数据。
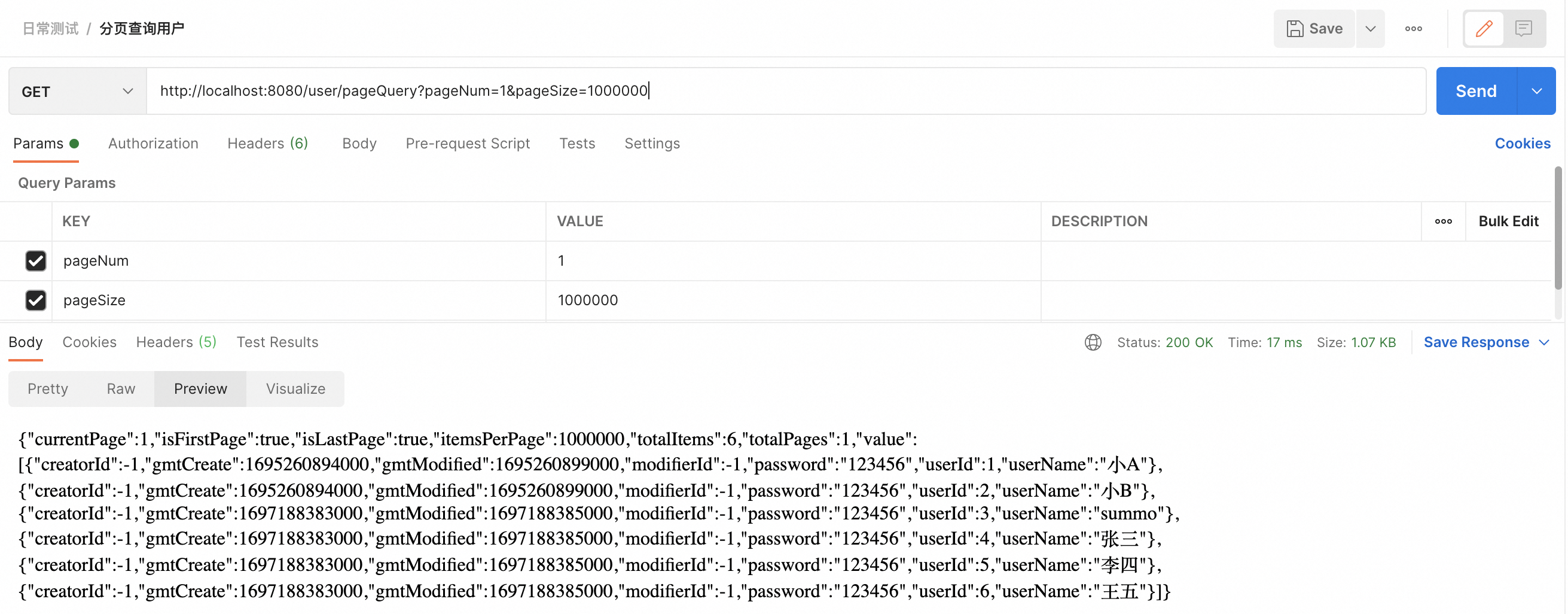
(5)会导致一个BUG
BUG复现
我们先看看前端的分页组件
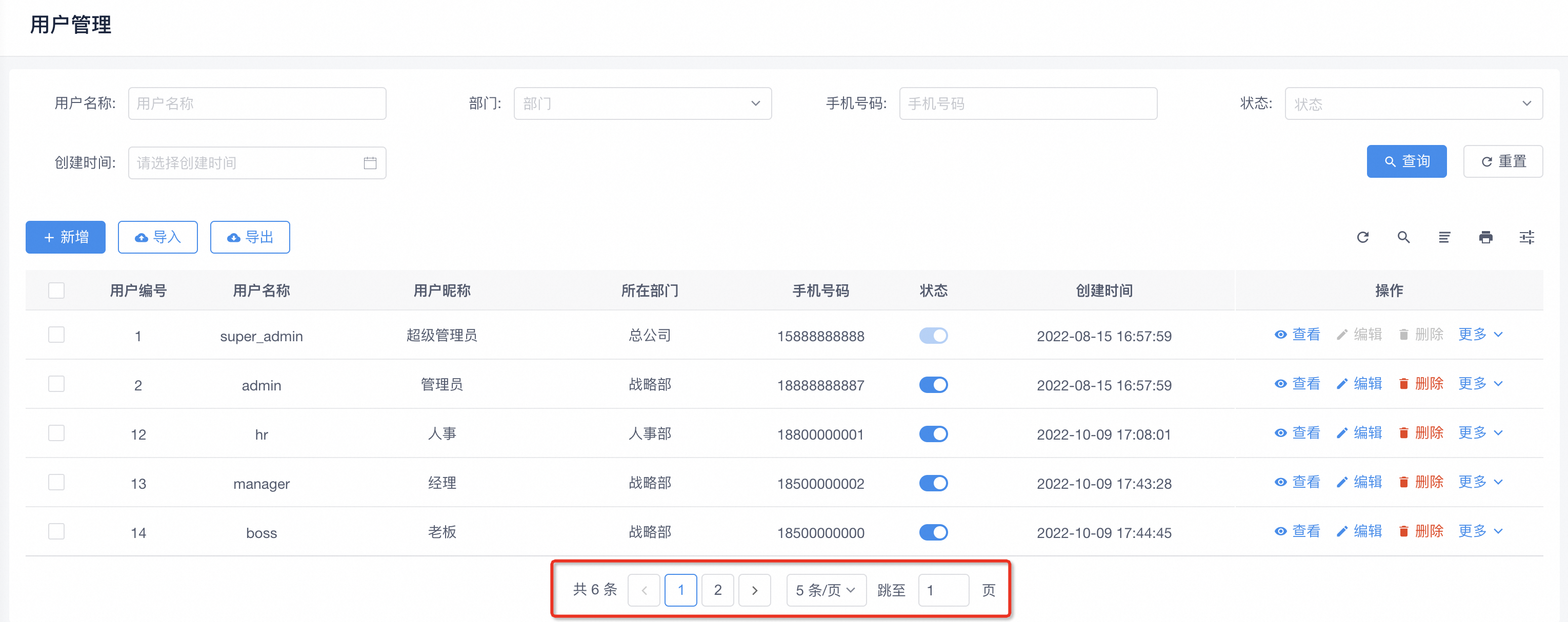
前端的这个分页组件大家应该很常见,它需要两个参数:总行数、每页行数。比如说现在总条数是6条,每页展示5条,那么会有2页,没啥问题对吧。
那么,现在我问一个问题:我们切换到第二页,把第二页仅剩的一条数据给删除掉,会出现什么情况?

理想情况:页码自动切换到第1页,并查询第一页的数据;
真实情况:页码切换到了第1页,但是查询不到数据,这明显就是一个BUG!

BUG分析
1. 用户切换到第二页,前端发起了请求,如:http://localhost:8080/user/pageQuery?pageNum=2&pageSize=5 ,此时第2页有一条数据;
2. 用户删除第2页的唯一数据后,前端发起查询请求,但还是第2页的查询,因为总数据的变化前端只能通过下一次的查询才能知道,但此时数据查询为空;
3. 虽然第二次查询的数据集为空,但是总条数已经变化了,只剩下5条,前端分页组件根据计算得出只剩下一页,所以自动切换到第1页;
可以看出这个BUG是分页查询的一个临界状态产生的,必现、中低频,属于必须修复的那一类。不过这个BUG想甩给前端,估计不行,因为总条数的变化只有后端知道,必须得后端修了。
2. 设置分页合理化
咋一听这个BUG有点儿复杂,但如果你使用的是PageHelper框架,那么修复它非常简单,只需要两行配置。
在application.yml或application.properties中添加
pagehelper.helper-dialect=mysql
pagehelper.reasonable=true
只要加了这两行配置,这个BUG就能解决。因为配置是全局的,如果你只想对单个查询场景生效,那就在设置分页参数的时候,加一个参数,如下:
PageHelper.startPage(pageNumber, pageSize, true);
这个问题我在三个月前单独写过一篇文章分析,想看原理的同学请移步:分页合理化是什么?
五、列表多行合并
1. 举个例子
现有如下表结构,用户表、角色表、用户角色关联表。
一个用户有多个角色,一个角色有可以给多个用户,也即常见的多对多场景。
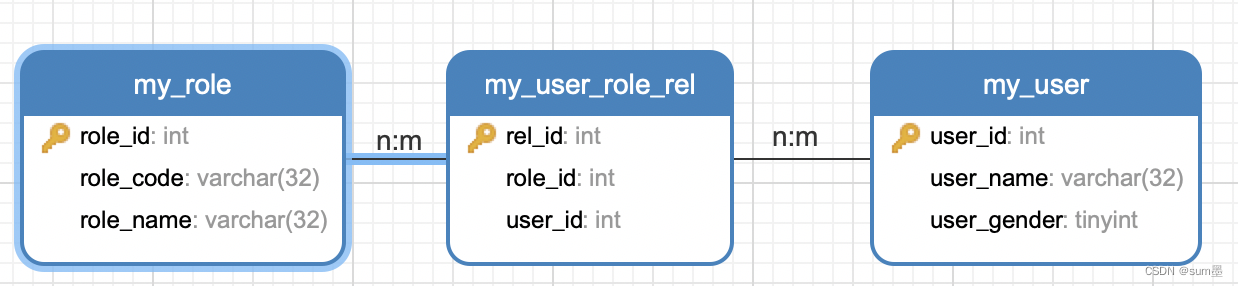
现有这样一个需求,分页查询用户数据,除了用户ID和用户名称字段,还要查出这个用户的所有角色。
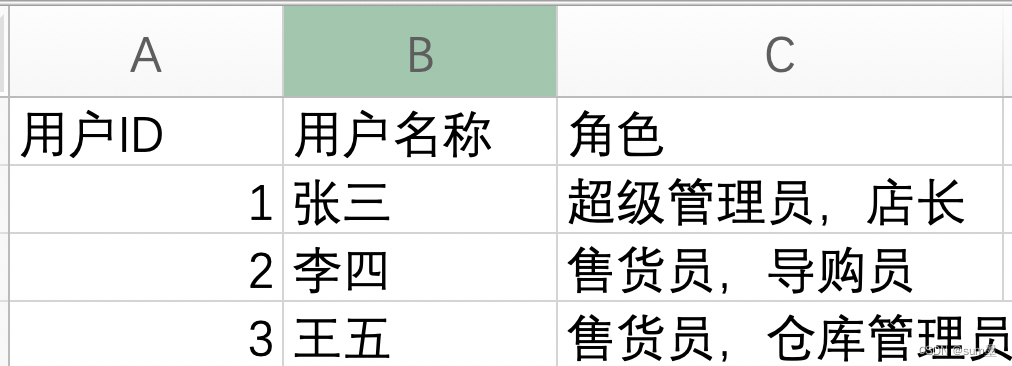
从上面的表格我们可以看出,用户有三个,但每个人的角色不止一个,而且有重复的角色,这里角色的数据从多行合并到了1行。
2. 难点分析
SQL存在的问题:
想使用SQL实现上面的效果不是不可以,但是很复杂且效率低下,尤其这个地方还需要分页,所以为了保证查询效率,我们需要把逻辑放到服务端来写;
服务端存在的问题:
服务端可以把需要的数据都查询出来,然后自己判断整合,首先十分复杂不说,而且这里有个问题:如何在查询条件很复杂的情况下保证分页?
3. 解决方案
核心方案就是使用Mybatis的collection标签自动实现多行合并。
下面是collection标签的一些介绍

常见写法
<resultMap id="ExtraBaseResultMap" type="com.example.mybatistest.entity.UserInfoDO">
<!--
WARNING - @mbg.generated
-->
<result column="user_id" jdbcType="INTEGER" property="userId"/>
<result column="user_name" jdbcType="INTEGER" property="userName"/>
<collection javaType="java.util.ArrayList" ofType="com.example.mybatistest.entity.MyRole"
property="roleList">
<result column="role_id" jdbcType="INTEGER" property="roleId"/>
<result column="role_name" jdbcType="VARCHAR" property="roleName"/>
</collection>
</resultMap>
这个问题我1年前单独写过一篇文章,具体实现请移步:MyBatis实现多行合并(collection标签使用)
六、总结一下
从第一篇的《优化接口设计的思路》系列:第一篇—接口参数的一些弯弯绕绕到今天的《优化接口设计的思路》系列:第八篇—分页接口的设计和优化,这个专栏写了快半年,产量很低,但我自认为质量还行,但是写这篇文章的时候我陷入了纠结:只是介绍怎么分页太水了,但是多行合并和分页合理化我之前就单独写过文章了,现在又拿出来讲岂不是炒冷饭?但是我又转念一想,都是我写的文章,又不是抄袭的,咋不能重新写(水)一篇🤡。那么既然写(水)了,那我就多写(水)一点。
我写文章都是原创,不转载,因为我不想(也不需要)去凑网站的活跃度,想到啥写啥,文章首发基本上都在博客园(园子你还撑得住吗?),然后是掘金(活跃用户高),当然csdn也发(流量多,也不知道是不是机器人)。但你问我写技术软文能不能赚到钱?我不知道,反正我没有赚到过,兴趣使然而已。那写文章一点用也没有吗?也不尽然,有博客的话放在简历上可以加分,具体加多少分,看面试官心情。我写文章的原因在《优化接口设计的思路》系列:第四篇—接口的权限控制的总结部分提到过,但其实还有一个原因:之前实习的时候,部门里有一个大叔在朋友圈晒过一条博客园把他文章上推荐的朋友圈。我当时看到觉得很牛逼,我就想啥时候我也能上。所以我写文章,除了积累知识外,还想上推荐,感觉很装逼。后来真的有文章上了推荐,我却没有发朋友圈。
到现在买房、买车、结婚、生小孩等等所谓人生大事,我一件都还没有办,原因很简单,没钱。按理说“三十而立”,我却越来越迷茫,我不知道哪些事情要先做,哪些事情是重要的,但在写文章的时候却感觉时间过得非常快,我应该是喜欢做这件事,做这件事的时候可以让我暂时忘记前面的那些烦恼,我想我也是幸运的。我看到很多文章说,程序员应该多写文章啊、录视频课啊…总之想办法用知识变现等等,我却想说,先让自己喜欢上做这件事吧,如果不喜欢的话,怎么熬得住文章浏览不过百,怎么扛得住别人恶意的评论,一旦赚不到钱就会怀疑自己做这件事的意义。
有人说现在AI这么牛逼了,你写的这点东西我随便问一下就出来了,而且比你更透彻更正确。那时肯定的,人家大模型学了世界上所有的知识,我才看了几本书,我和AI最大的不同就是:我会写总结,我会扯淡,而大多时候大部分人看文章都是从下往上看的,AI却是慢慢的从头到尾~