引入
之前写过一篇文章将伙伴系统,可以参考:内存池算法简介
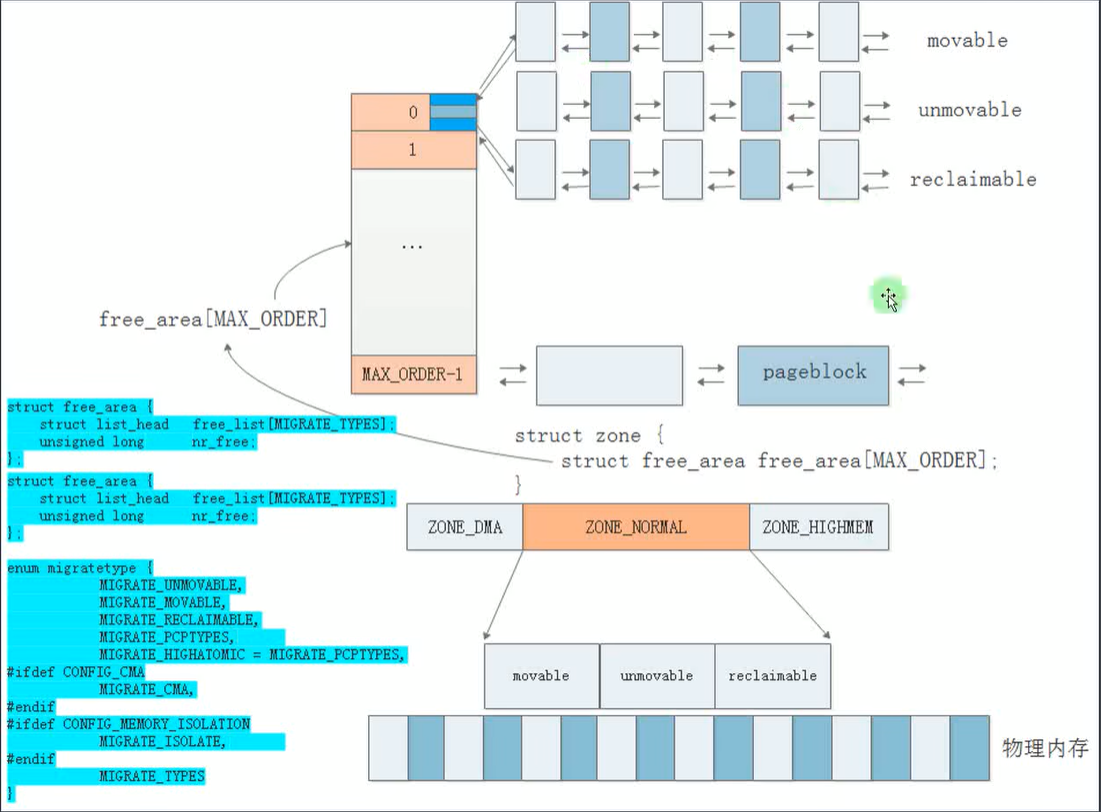

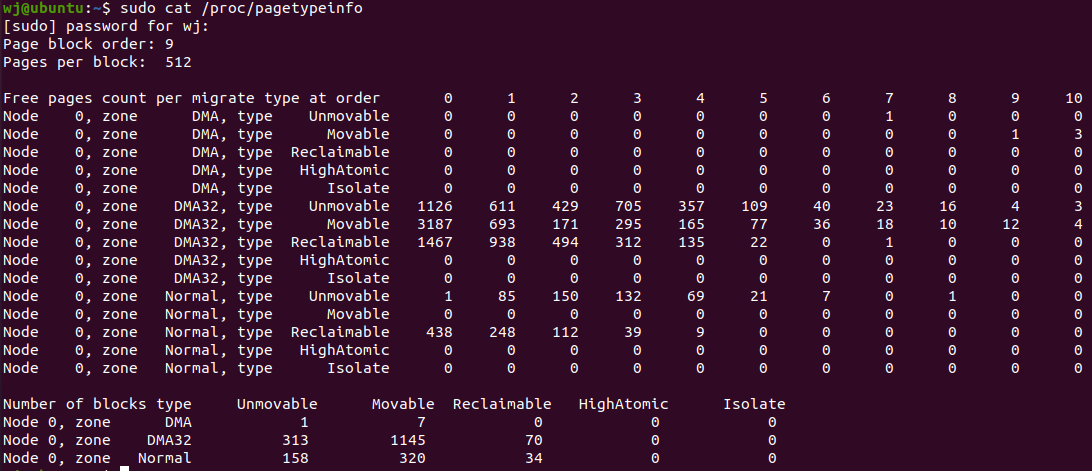
从上面的虚拟机上可以看到,X86系统上,有三个物理内存区,DMA,DMA32,Normal,可以看到阶数为11。
struct page {
atomic_t _mapcount;
atomic_t _refcount;
unsigned long private;
}atomic_t _mapcount; : _mapcount初始值为-1,说明没有发生映射,用户没有使用这块内存,这个时候这块物理页应该在伙伴系统上挂着。
unsigned long private; :这个private 表示当前内存块的大小。page_order =1 代表 2^1
atomic_t _refcount; : 引用计数
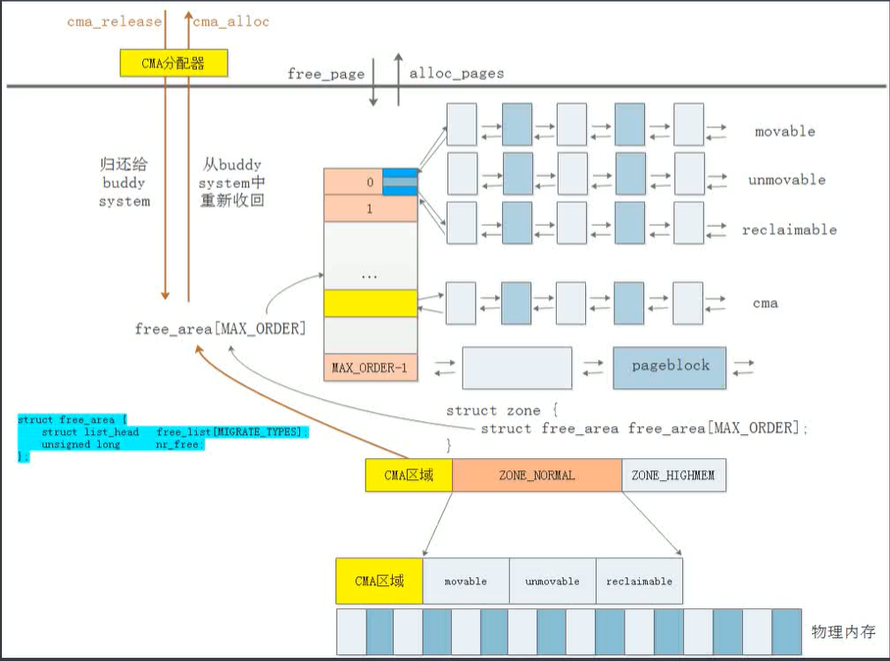
枚举类型:migratetype
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};查看页面类型:cat /proc/pagetypeinfo
可以移动的:用户进程申请的内存
可回收的:文件系统的page cache
不可移动的:内核镜像区的物理内存。内核中很多物理地址,都是fireware中固定好的,是不能改变的,所以要求它所对应的页是不可移动的。
为什么引入迁移类型?
伙伴系统存在的问题:我们知道伙伴系统可以自动的进行页面合并,在很大的程度上可以避免内存碎片。但是也存在一些极端情况,比如,就是某些时候,需要一大块的连续内存,而这个时候物理内存页快已经满足不了。
引入迁移类型目的就是为了改进伙伴系统。
page migratetype :不同类型的页面分类存储
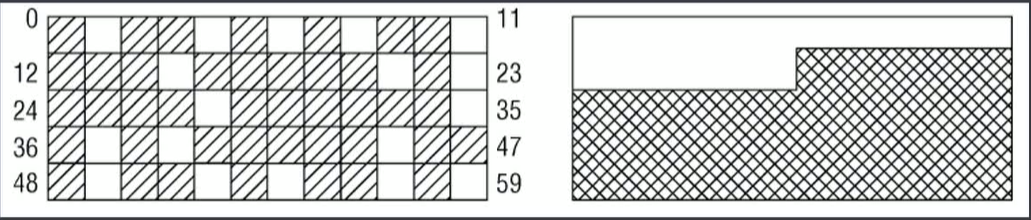
memory compaction :内存碎片整理,如下图所示,假如,我们需要连续4个页,但是现在已经没有连续4个页了,这个时候如果页面都是不可移动的,那么申请内存肯定会失败。
memory compact 的几种方式:COMPACT_PRIO_SYNC_FULL : 以同步的方式压缩和迁移;COMPACT_PRIO_SYNC_LIGHT :压缩同步,迁移异步;COMPACT_PRIO_SYNC_ASYNC,以异步方式压缩和迁移。
什么时候会触发memory compaction? 1.没有申请到内存的时候。2.当内存阈值不够的时候,后台的 kcompaction守护线程 会被唤醒,会执行内存迁移的操作。 3.memory compaction开销是挺大的,对性能有一定的影响。
Linux下可以这样查看,ls /proc/sys/vm | grep compact_memory
Per-CPU页帧缓存
per-cpu页帧缓存也是对伙伴系统的一种完善和补充。
pcp : per CPU pages
单个物理页的申请与释放
struct zone {
long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset __percpu *pageset;
struct free_area free_area[MAX_ORDER];
}____cacheline_internodealigned_in_smp;struct free_area free_area[MAX_ORDER]; 大部份物理页是放在伙伴系统的链表上的。
long lowmem_reserve[MAX_NR_ZONES]; 还有一些预留的页
struct per_cpu_pageset __percpu *pageset; 还有一些缓存页,目的就是为了降低锁的开销,提高性能。每一个CPU都有一个本地的缓存,只缓存单个物理页。
__percpu 关键字是内核提供的一种机制,降低锁的开销,提高性能。怎么实现的?申请内存并不是从伙伴系统上去拿,而是到 per_cpu_pages 结构体中 struct list_head lists 这个链表中去拿,如果拿不到,再才会到伙伴系统中去拿;释放流程:不会释放到伙伴系统中,而是释放到 per_cpu_pages 结构体中 struct list_head lists 这个链表中,这样就避免了多个CPU加锁,去锁的开销,也不用去全局到伙伴系统中去拿内存页了,性能就提高了。

伙伴系统提供的页分配/释放接口:alloc_pages、free_page
头文件 include/linux/gfp.h

static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}参数掩码gfp_mask : 代表在那个区域去找内存?ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM 等?
参数order : 代表伙伴系统的阶数

接下来,来看一下 call-flow。
#ifdef CONFIG_NUMA // 服务器领域用这个
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else //嵌入式系统用这个
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endifstatic inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}static inline struct page *
__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);
VM_WARN_ON(!node_online(nid));
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
return __alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
}mm/page_alloc.c
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask = gfp_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = {
.high_zoneidx = gfp_zone(gfp_mask),
.zonelist = zonelist,
.nodemask = nodemask,
.migratetype = gfpflags_to_migratetype(gfp_mask),
};
if (cpusets_enabled()) {
alloc_mask |= __GFP_HARDWALL;
alloc_flags |= ALLOC_CPUSET;
if (!ac.nodemask)
ac.nodemask = &cpuset_current_mems_allowed;
}
gfp_mask &= gfp_allowed_mask;
lockdep_trace_alloc(gfp_mask);
might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);
if (should_fail_alloc_page(gfp_mask, order))
return NULL;
/*
* Check the zones suitable for the gfp_mask contain at least one
* valid zone. It's possible to have an empty zonelist as a result
* of __GFP_THISNODE and a memoryless node
*/
if (unlikely(!zonelist->_zonerefs->zone))
return NULL;
if (IS_ENABLED(CONFIG_CMA) && ac.migratetype == MIGRATE_MOVABLE)
alloc_flags |= ALLOC_CMA;
/* Dirty zone balancing only done in the fast path */
ac.spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/*
* The preferred zone is used for statistics but crucially it is
* also used as the starting point for the zonelist iterator. It
* may get reset for allocations that ignore memory policies.
*/
ac.preferred_zoneref = first_zones_zonelist(ac.zonelist,
ac.high_zoneidx, ac.nodemask);
if (!ac.preferred_zoneref->zone) {
page = NULL;
/*
* This might be due to race with cpuset_current_mems_allowed
* update, so make sure we retry with original nodemask in the
* slow path.
*/
goto no_zone;
}
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
no_zone:
/*
* Runtime PM, block IO and its error handling path can deadlock
* because I/O on the device might not complete.
*/
alloc_mask = memalloc_noio_flags(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
if (kmemcheck_enabled && page)
kmemcheck_pagealloc_alloc(page, order, gfp_mask);
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}最关键就是这两个函数,导致是走 fastpath ,还是 slowpath
fastpath : 从伙伴系统的空闲链表中获取 page
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);slowpath : 对内存进行整理,迁移,压缩,交换,腾出大块连续的内存
page = __alloc_pages_slowpath(alloc_mask, order, &ac);连续内存分配器:CMA