目录
1 实战内容
2 确定思路
3 代码实操
3.1 实现一个个网页的爬取
3.2 爬取每一个网页的电影详情页url
编辑
3.3 连接链接,针对每个详情页链接进行爬取、汇总内容
3.4 存储在txt文件中
4 结尾:整体代码
1 实战内容
爬取Scrape | Movie中所有电影的详情页的电影名、种类、信息、简介、分数,并将其存储在txt文件中(一个电影一个文件),以电影名命名。
2 确定思路
(一)分析网页,发现网站整体有10个网页,所以先要实现一个个网页的爬取;
(二)对于一个网页,先要得到每个电影的详情页的url;
(三)针对详情页的url,爬取相应内容,并汇总这一个电影的内容
(四)存储。
3 代码实操
3.1 实现一个个网页的爬取
分析网页链接,发现10个网页的链接的不同点只是在于末尾的page数字发生了变化。所以此时直接用f‘ ’构造网页,改变最后一个数字即可。
import requests
import re
if __name__ == '__main__':
base_url = 'https://ssr1.scrape.center'
page = 10
for i in range(1, page+1):
url = f'{base_url}/page/{i}'
response = requests.get(url)
content = response.text
此时得到了每一个网页的内容,之后我们根据内容去获取链接。
3.2 爬取每一个网页的电影详情页url
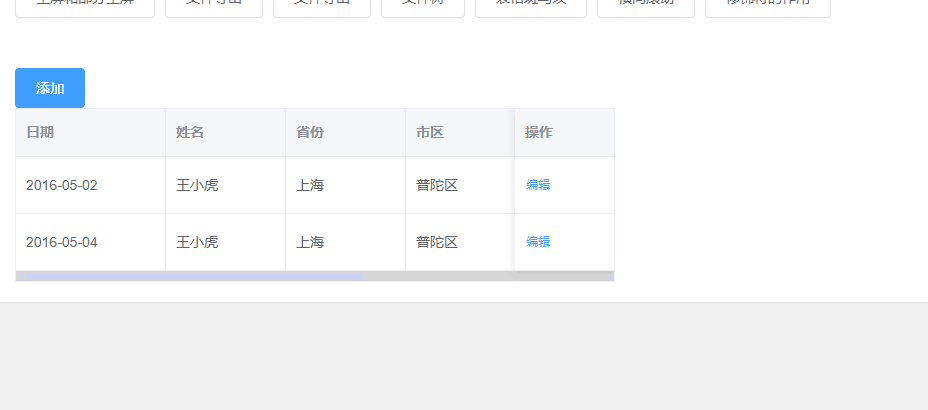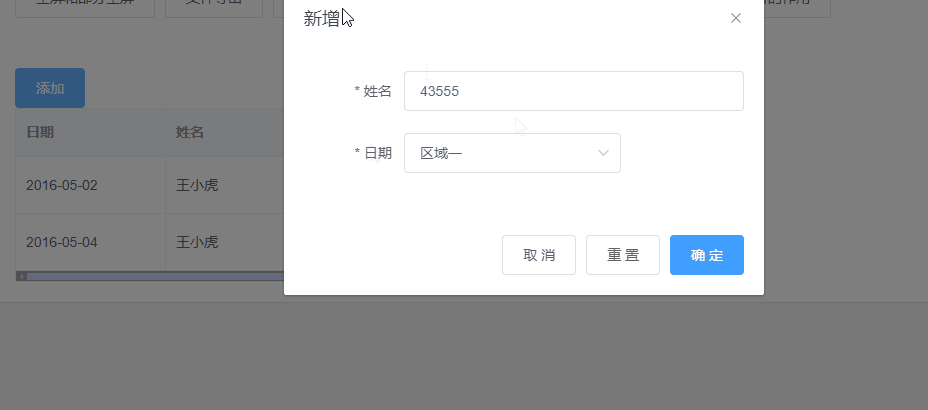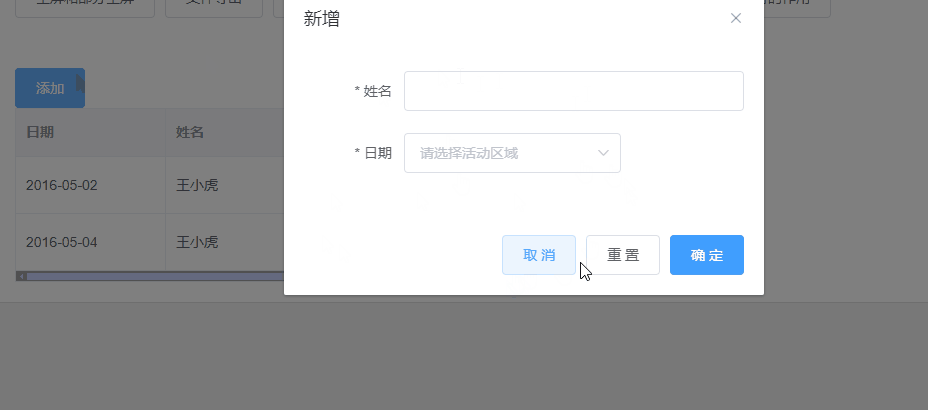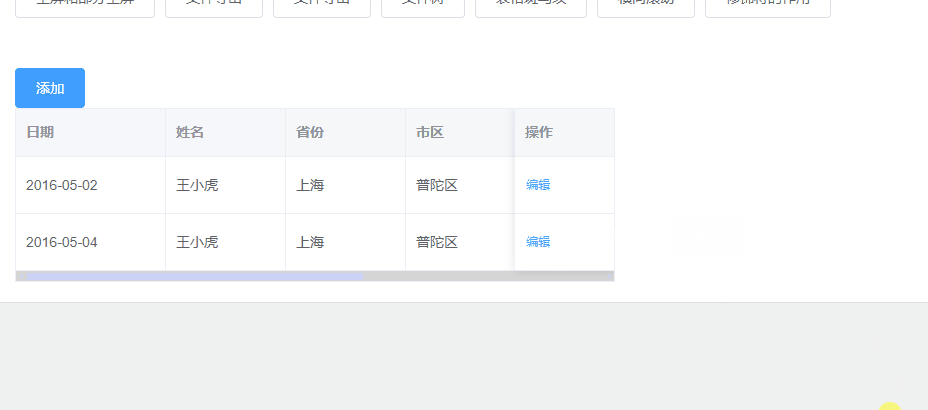
分析网页,发现第一个电影《霸王别姬》的详情页的链接如下:

所以我们的目标就是爬取href中的内容。
这里我们先以爬取一个网页的所有详情页的href为例:
# 定义一个函数scrape_url用于对网页内容进行爬取
def scrape_url(content):
pattern = re.compile('<a.*?href="(.*?)" class="name">')
urls = re.findall(pattern, content)
print(urls)
上面是第一个网页中的链接,我的思路是将所有链接都放在一个列表中,之后直接将这个列表的链接与最初的链接连接起来,依次访问,从而实现第三步,所以之后做出以下更改。
在主函数中添加一个url_list负责存储链接。
import requests
import re
def scrape_url(content, url_list):
pattern = re.compile('<a.*?href="(.*?)" class="name">')
urls = re.findall(pattern, content)
url_list.extend(urls)
return url_list
if __name__ == '__main__':
base_url = 'https://ssr1.scrape.center'
page = 10
url_list = []
for i in range(1, page+1):
url = f'{base_url}/page/{i}'
response = requests.get(url)
content = response.text
url_list = scrape_url(content, url_list)
print(url_list)
3.3 连接链接,针对每个详情页链接进行爬取、汇总内容
连接链接的时候注意多或少一个 /。
此函数在主函数中调用。
def scrape_detail(base_url, url_list):
url_number = len(url_list)
for i in range(url_number):
url = base_url + url_list[i]
response = requests.get(url)
content = response.text
# 用正则表达式爬取相应内容
pattern_title = re.compile('<h2.*?class="m-b-sm">(.*?)</h2>')
pattern_cata = re.compile('<button.*?mini">.*?<span>(.*?)</span>', re.S)
pattern_info = re.compile('<span data-v-7f856186.*?>(.*?)</span>')
pattern_drama = re.compile('<div.*?class="drama">.*?<p.*?>(.*?)</p></div>', re.S)
pattern_score = re.compile('<p.*?class="score.*?>(.*?)</p>',re.S)
title = re.findall(pattern_title, content)
cata = re.findall(pattern_cata, content)
info = re.findall(pattern_info, content)
drama = re.findall(pattern_drama, content)
score = re.findall(pattern_score, content)
# 汇总内容
movie_dict = {
'title': title[0],
'categories': cata,
'info': info,
'drama': drama[0].strip(),
'score': score[0].strip()
}下面将访问第一个详情页的链接之后得到的movie_dict展示:

3.4 存储在txt文件中
我是想直接将这个字典存入txt文件中,所以这里需要用到 json 库。json.dump方法,可以将数据保存为文本格式, ensure_ascii=False,可以保证中文字符在文件中以正常中文文本呈现,不乱码。indent=2,设置JSON数据的结果有两行缩进,更美观。
此函数在scrape_detail中调用.
def save_data(movie_dict, title):
data_path = f'result/{title}.txt'
with open(data_path, 'w', encoding='utf-8') as f:
json.dump(movie_dict, f, ensure_ascii=False, indent=2)
f.close()
这里以访问前三个详情链接的结果展示:

4 结尾:整体代码
import requests
import re
import json
def save_data(movie_dict, title):
data_path = f'result/{title}.txt'
with open(data_path, 'w', encoding='utf-8') as f:
json.dump(movie_dict, f, ensure_ascii=False, indent=2)
f.close()
def scrape_url(content, url_list):
pattern = re.compile('<a.*?href="(.*?)" class="name">')
urls = re.findall(pattern, content)
url_list.extend(urls)
return url_list
def scrape_detail(base_url, url_list):
url_number = len(url_list)
for i in range(url_number):
url = base_url + url_list[i]
response = requests.get(url)
content = response.text
# 用正则表达式爬取相应内容
pattern_title = re.compile('<h2.*?class="m-b-sm">(.*?)</h2>')
pattern_cata = re.compile('<button.*?mini">.*?<span>(.*?)</span>', re.S)
pattern_info = re.compile('<span data-v-7f856186.*?>(.*?)</span>')
pattern_drama = re.compile('<div.*?class="drama">.*?<p.*?>(.*?)</p></div>', re.S)
pattern_score = re.compile('<p.*?class="score.*?>(.*?)</p>',re.S)
title = re.findall(pattern_title, content)
cata = re.findall(pattern_cata, content)
info = re.findall(pattern_info, content)
drama = re.findall(pattern_drama, content)
score = re.findall(pattern_score, content)
# 汇总内容
movie_dict = {
'title': title[0],
'categories': cata,
'info': info,
'drama': drama[0].strip(),
'score': score[0].strip()
}
print(movie_dict)
# 存储数据
save_data(movie_dict, title[0])
if __name__ == '__main__':
base_url = 'https://ssr1.scrape.center'
page = 10
url_list = []
for i in range(1, page+1):
url = f'{base_url}/page/{i}'
response = requests.get(url)
content = response.text
url_list = scrape_url(content, url_list)
scrape_detail(base_url, url_list)本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢,一起加油吧!