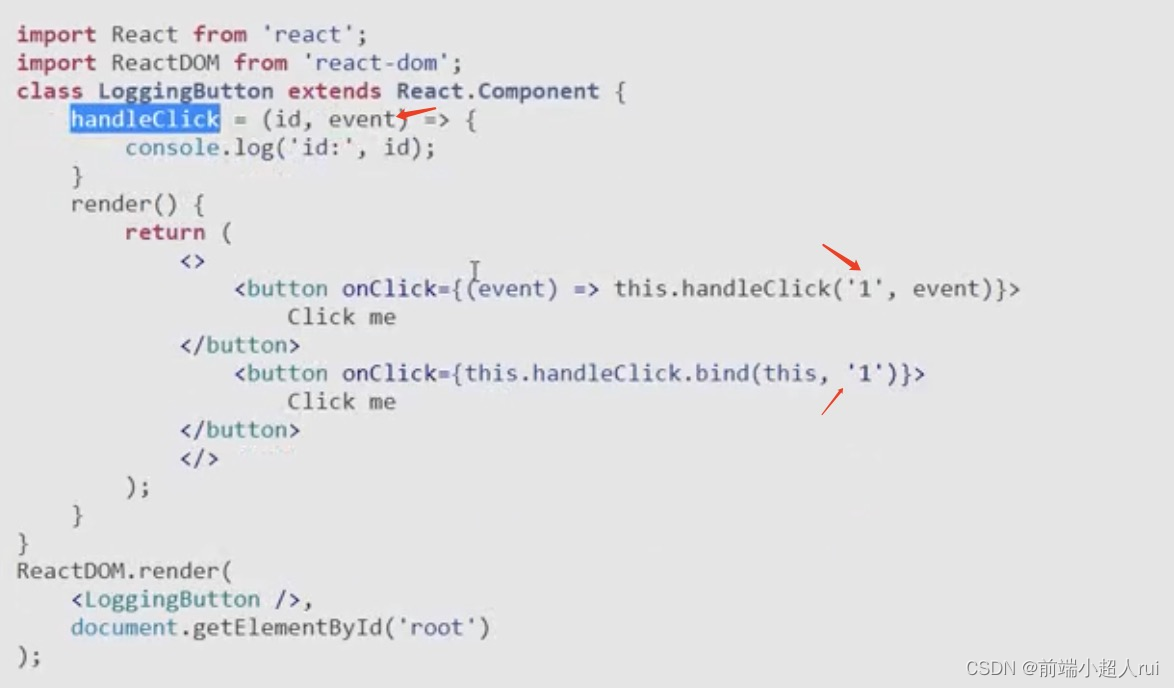
1·数据结构简介
学习数据结构与算法之前,一般是先学数据结构,方便之后学习算法,那么数据结构拆开介绍,就是数据 和 结构,数据,生活中到处都是,结构,就是数据存储的方式,即数据结构可以理解为计算机存储、组织数据的方式,那么我们学习数据结构无非就是学习数据在计算机里面的存储,组织方式,那么为什么需要数据结构,数据结构存在的意义是什么?
在餐厅发餐的时候,人们都有自己的号码牌,轮到自己的号码的时候也就是可以吃饭了,这里数据就是人们点餐的号码,存储的方式就是按照顺序存储,取餐的时候人们按照号码开始取餐,假定没有号码,也就没有了顺序,也就失去了秩序,那么处理发餐问题上的效率就会大打折扣,可以得出结论:数据结构可以提高处理事件的效率。
其实我们接触C语言不久的时候就已经接触过数据结构了,数据结构就是存储数据,组织数据,那你想,存储数据的知识点,我们在前面学过……?
当然是数组了,数组是最基本的数据结构,它可以存储数据吧?可以组织数据吧?数组的章节我们 提到数组存储数据的时候内存空间是连续存储的,所以数组存储数据的方式就是连续存储,这点,我们会应用到之后的顺序表里面。
既然数组已经是数据结构了,为什么要学习其他的数据结构呢?假定这样的场景,我们定义了一个长度为10的数组,可是我们只存储一个数据,于是就浪费了9个数据,后我们又定义了一个长度为2的数组,可我们要存储10个数据,这个数组我们就用不上,也就是浪费空间了,那么我们真正想要的是什么呢?
我们真正想要的是一个能随着我们需求而改变的数据结构,这个时候就会说了,柔性数组呢?柔性数组大小确实是可以随需求的改变而改变,可是柔性数组也是存在条件的,数组是最后的成员,局限性是只能存储一种类型的数据,我们需要的不是一种数据,有时候我们需要多种数据糅合在一起,比如通讯录,那么现在,就进入到基于数组实现的更高级的数据结构里面——线性表。
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是⼀种在实际中⼴泛使 ⽤的数据结构,常⻅的线性表:顺序表、链表、栈、队列、字符串... 线性表在逻辑上是线性结构,也就说是连续的⼀条直线。但是在物理结构上并不⼀定是连续的, 线性表在物理上存储时,通常以数组和链式结构的形式存储。
2·顺序表
顺序表是线性表的一种,底层逻辑是数组,那么它和数组的区别在哪里呢?
可以理解为是苍蝇馆子和米其林餐厅的区别,东西都是一样的,都可以存储东西,但是米其林可以提供其他的配菜,可以实现更多的”功能“,比如数组一次只能存一种数据,顺序表一次可以存储多种数据,顺序表可以通过多种接口的实现,来实现更多的功能,比如对数据进行增删查改。
顺序表分为两种,静态顺序表,动态顺序表。
#define N 7
typedef int Datatype;
struct SeqList
{
Datatype arr[N];//定长数组
int size;//有效数据个数
};这就是静态顺序表的实现,看似平平无奇,实际就确实平平无奇,让人疑惑的可能是为什么对int进行重命名,假定这样一个场景,在一个容器里面全都是int,老板让你把int全部改成float,你是一个一个改吗?倘若只有几十个还好,如果有几千个呢?那就麻烦了,所以我们不妨在int放进容器的时候就对它进行重命名,之后如果更换,就只需要改一个int就行了,所以这里的重命名是为了之后数据类型的易转换。
typedef struct Seqlist
{
Datatype* arr;
int size;//有效数据个数
int capacity;//开辟的空间大小
}SL;这就是动态顺序表的实现,因为是动态的,所以使用指针来指向这块空间是最好的,注意,指针类型是我们可以自己定义的,最基础的就是整型之类的,比如存一些数,高级一点的就是结构体指针,也就是后面的通讯录会用到,我们开辟了空间之后,需要两个计数器,一个是计算里面的有效数据个数,一个是计算开辟的空间大小。
3·顺序表的初始化和销毁
我们创建的动态顺序表里面一共就三个成员,一个指针,两个整型,那么初始化无非就是给NULL或者0:
void SeqlistInit(SL s1)
{
s1.arr = NULL;
s1.size = s1.capacity = 0;
}我们创建一个函数,用来初始化,看似没有问题,实际上当我们调试代码的时候,会发现我们真正需要的结构体并没有被初始化,因为这里我们使用的是传值,实际上初始化的只是临时拷贝的那个结构体,改进方法就是改用传址调用,为了方便起见,后面所有有关顺序表的操作我们都使用传址:
void SeqlistInit(SL* ps)
{
ps->arr = NULL;
ps->size = ps->capacity = 0;
return 0;
}同样为了之后方便实现顺序表通讯录,我们可以让顺序表有关的函数和源代码放在单独的头文件和源文件里面,记得要在头文件里面写上需要用到的其他的头文件。
其实销毁和初始化是大同小异,区别在于销毁需要把空间还给操作系统,因为在销毁之前顺序表已经实现了多种功能,所以我们并不知道现在的指针是否为空,即需要判断一下:
void SeqlistDestroy(SL* ps)
{
assert(ps);
ps->arr = NULL;
free(ps->arr);
ps->capacity = ps->size = 0;
}使用assert的话别忘了引用头文件assert.h,如果不想引用头文件也可以结合if语句进行判断,总之就是要判断就对了,因为返回值是void,所以直接返回就行了,不需要加上返回值。
void SeqlistDestroy(SL* ps)
{
if (ps->arr == NULL)
{
return;
}
//assert(ps);
ps->arr = NULL;
free(ps->arr);
ps->capacity = ps->size = 0;
}4·顺序表的扩容
我们创建好顺序表之后还没有开辟空间,那么在我们插入数据之前可能就会面对两种问题,一是指针指向的空间还没有开辟,二是指针指向的空间大小不够插入数据,这两种情况我们都需要进行扩容:
void SLCheckCapacity(SL* ps)
{
if (ps->capacity == 0)
{
ps->arr = (Datatype*)malloc(4 * sizeof(Datatype));
ps->capacity = 4;
}
if (ps->capacity == ps->size)
{
Datatype* tem = (Datatype*)realloc(ps->arr, 2 * ps->capacity * sizeof(Datatype));
if (tem != NULL)
{
ps->arr = tem;
ps->capacity *= 2;
}
else
{
perror("realloc fail!");
return;
}
}
}在扩容之后,顺序表里面的空间大小也会随着改变,所以我们改变指针指向空间的同时还要改变一下空间计数的大小,有人可能就问了,为什么是两倍两倍的增加空间大小,每插入一个数据的时候就增加一块空间不好吗?仔细想想这样不会浪费空间,但是实际上效率会低下很多,假如插入数据个数多了,几万个,插入一个数据就调用一下这个函数,岂不是浪费了很多时间,至于为什么是二倍,就留个读者自行探索了,二倍是最不容易浪费空间的了。
有人问了,为什么扩容之后,原来的指针不用释放,因为realloc函数会自动释放空间。
5·顺序表的尾部插入/删除
在所有插入数据操作之前,我们都应该判断空间大小是否足够,其次再考虑插入的事,尾部插入数据的时候需要注意,sizeof个数会增加:
void SLPushback(SL* ps, Datatype x)
{
assert(ps);
SLCheckCapacity(ps);
ps->arr[ps->size++] = x;
}这里使用后置++,代码界面看起来就更简洁,要是单独拎出来加加也行,尾插就直接插入数据就行了,没什么太多需要注意的。
那么尾部删除数据怎么操作呢?
有的人可能会说,删除数据我们就把删除的数据置于0,size减减不就行了吗?
实际上,给删除的数据置于0也是给了一个数据,最好的办法就是直接size减减,因为删除即不再使用那个数据,ps->arr[ps->size]是能访问到的最远的数据,size减减之后就访问不了那个数据了,这也是一种删除:
void SLDeleteBack(SL* ps)
{
assert(ps);
ps->size--;
}当然,判断指针是否为空还是很有必要的。
6·顺序表的头部插入/删除
顺序表头部插入的时候,需要注意的有空间大小是否足够,size的增加,移动的循环次数,头部插入的时候需要将所有的数据往后移动一个单位,所以用到while或者for是必不可少的:
void SLPushHead(SL* ps, Datatype x)
{
assert(ps);
SLCheckCapacity(ps);
for (int i = ps->size; i > 0; i--)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[0] = x;
ps->size++;
}我们让数据都往后移动一个单位,所以i从0开始显然不那么可行,于是就从size开始了,整体数据移动完之后,首元素放上我们要插入的数据就行,最后别忘了ps->size++。
头部删除也就是除了第一个数据,其他数据全部往前面移动一个单位,同时size减减,空间大小不变,因为挪动的数据个数少一个,所以循环次数少一次,当然,指针是否为空指针也是不能忘记的:
void SLDeleteHead(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size - 1; i++)
{
ps->arr[i] = ps->arr[i + 1];
}
ps->size--;
}7·顺序表的指定删除/指定位置之前插入
指定删除需要注意的是删除的位置不能为负数,也不能是超过size的位置,删除之后,后面的数据应该往前移动一个单位,size减减,指定位置删除的删法和头删有点像,就是后面的数据依次往前,覆盖了数据就行:
void SLDelete(SL* ps,int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
for (int i = pos; i < ps->size - 1; i++)
{
ps->arr[i] = ps->arr[i + 1];
}
ps->size--;
}多注意循环变量的控制。
指定位置之前插入,类比头插和尾插,先判断空间大小,其次移动数据是必要的,size也是要++的,注意这里的pos是下标哦:
void SLPush(SL* ps, int pos, Datatype x)
{
assert(ps);
assert(pos >= 0 && pos <= ps->size);
SLCheckCapacity(ps);
for (int i = ps->size; i > pos; i--)
{
ps->arr[i] = ps->arr[i - 1];
}
ps->arr[pos] = x;
ps->size++;
}
8·顺序表的打印
打印是很简单的,就是一个for循环的事,我们先加上一下数据:
#include "Seqlist.h"
int main()
{
SL s1;
SeqlistInit(&s1);//初始化
SLPushHead(&s1, 5);
SLPushHead(&s1, 4);
SLPushHead(&s1, 3);
SLPushHead(&s1, 2);
SLPushHead(&s1, 1);
SLPushBack(&s1, 1);
//1 2 3 4 5 1
SLPrint(&s1);
SLPush(&s1, 3, 100);
//1 2 3 100 4 5 1
SLPrint(&s1);
SLDeleteHead(&s1);
//2 3 100 4 5 1
SLPrint(&s1);
SLDelete(&s1, 4);
//2 3 100 5 1
SLPrint(&s1);
SeqlistDestroy(&s1);//销毁
return 0;
}void SLPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->arr[i]);
}
}
最后的结果也是没有问题的。
9·顺序表的查找
查找无非就是进行遍历,最后返回我们要找的数据的下标就行了,遍历就要一个for循环就行了:
int SLFind(SL* ps,Datatype x)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
if (x == ps->arr[i])
{
return i;
}
}
return -1;
}然后结合实际效果看看:
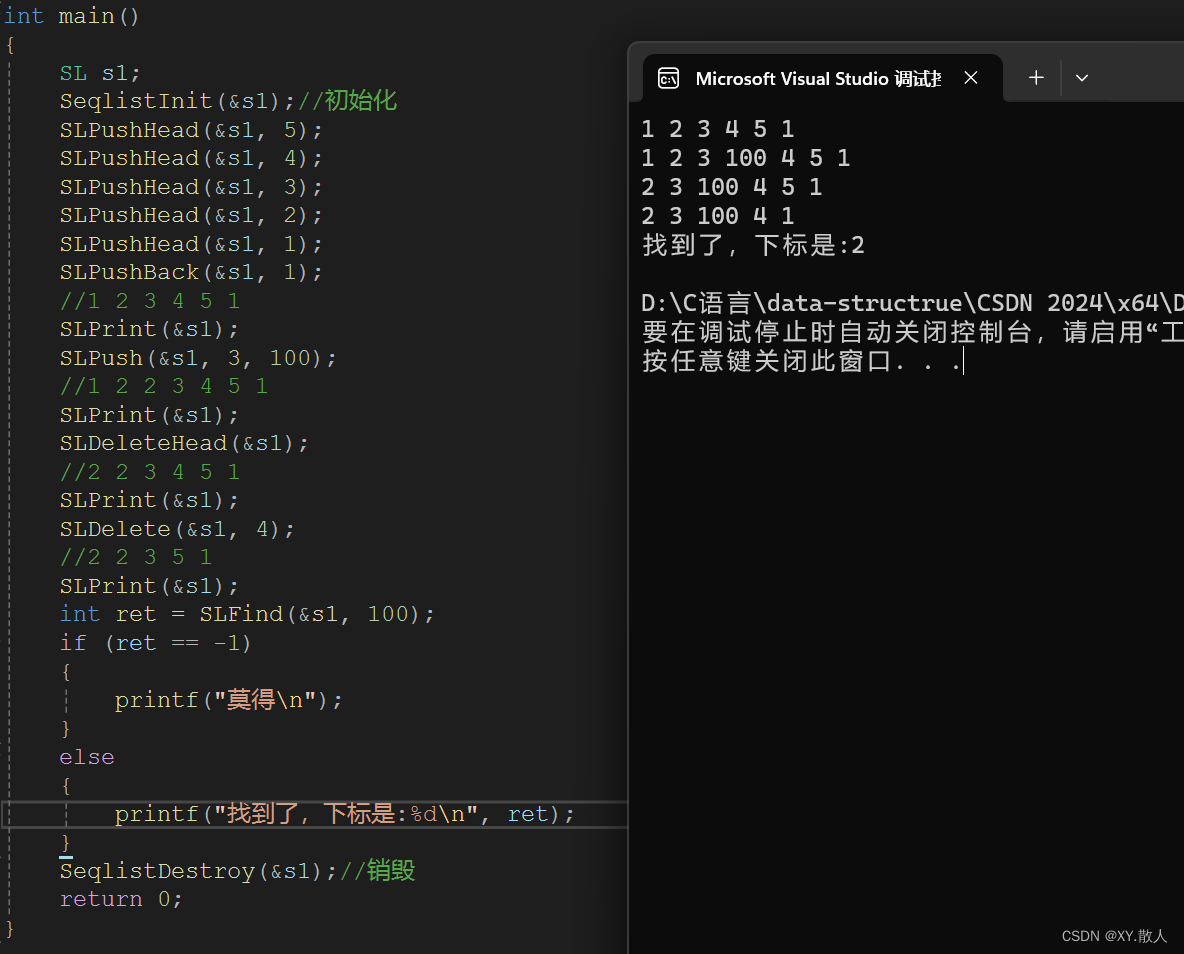
以上就是顺序表的基本功能实现,下一篇介绍顺序表实现通讯录
感谢阅读!