一、慢SQL定义
执行超过1s的SQL为慢SQL
三、慢SQl的风险
-
系统的响应时间延迟,影响用户体验
-
资源占用增加,增高了系统的负载,其他请求响应时间也可能会收到影响。
-
慢SQL占用数据库连接的时间长,如果有大量慢SQL查询同时执行,可能会导致数据库连接池的连接被全部占用,导致数据连接池打满、缓冲区溢出等问题,使数据库无法响应其他请求。(影响业务连续性,系统崩了)
-
还有可能造成锁竞争增加、数据不一致等问题
四、慢SQL是如何引入的
-
缺乏索引/索引未生效,导致数据库全表扫描,会产生大量的IO消耗,产生慢SQL。
-
单表数据量太大,会导致加索引的效果不够明显。
-
SQL语句书写不当,例如join或者子查询过多、in元素过多、limit深分页问题、order by导致文件排序、group by使用临时表等。
-
数据库在刷“脏页”,redo log写满了,导致所有系统更新被堵住,无法写入了。
-
执行SQL的时候,遇到表锁或者行锁,只能等待锁被释放,导致了慢SQL。
五、如何发现慢SQL及高危SQL
- 数据库会将执行慢SQL日志
- 其他的数据库性能监控工具、SQL性能分析工具
- 发现全量SQL,把系统所有SQL采集起来
- 除了执行时长超过1s的慢SQL之外,我们还额外关注了未来可能劣化的慢SQL,这样就需要获取全量SQL,再对其进行分析,筛选出其中风险较大的SQL。我们采取了如下方法
-
基于JVM Sandbox进行SQL流水记录的采集
识别慢SQL的标准
-
根据历史慢SQL治理经验,我们把高危SQL分为以下几类:
-
不符合集团SQL规约的SQL,可能会埋坑,造成线上问题,影响执行效率等。
-
通过对SQL语句分析,发现SQL索引使用不当、造成全表扫描,或者SQL扫描行数过多、出现文件排序等。这种SQL即使当前不是慢SQL,随着表数据量的膨胀,未来也可能发展为慢SQL。
-
SQL执行时间过长,比较容易理解。对慢SQL来说,执行时间越长,风险越高
SQL规约
-
【强制】不要使用count(列名)或count(常量)来替代count(*),count(*)就是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
-
【强制】count(distinct col) 计算该列除NULL之外的不重复数量。注意 count(distinct col1, col2) 如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。
-
【强制】当某一列的值全是NULL时,count(col)的返回结果为0,但sum(col)的返回结果为NULL,因此使用sum()时需注意NPE问题。
-
【强制】使用ISNULL()来判断是否为NULL值。
-
【强制】对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。
-
【强制】在代码中写分页查询逻辑时,若count为0应直接返回,避免执行后面的分页语句。
-
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
-
【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
-
【强制】IDB数据订正(特别是删除或修改记录操作)时,要先select,避免出现误删除,确认无误才能提交执行。
我们使用了Druid SQL Parser进行SQL解析,Druid SQL Parser是阿里巴巴的开源项目,可以将SQL语句解析为语法树,可以解析SQL的各个部分,如SELECT语句、FROM语、WHERE语句等,并且可以方便获取SQL语句的结构信息,如表名、列名、操作符等。通过分析SQL,可以轻松判断SQL是否符合规约
SQL索引


我们重点关注的点如下:
-
使用全表扫描,性能最差,即type="ALL"
-
扫描行数过多,即rows>阈值
-
查询时使用了排序操作,也比较耗时,即Extra包含"Using filesort"
-
索引类型为index,代表全盘扫描了索引的数据,Extra信息为Using where,代表要搜索的列没有被索引覆盖,需要回表,性能较差。
以上几点都可能造成SQL性能的劣化,是我们需要额外关注的高风险sql
六、如何推动治理慢SQL
存量慢SQL治理
存量慢SQL治理的难点在于,历史遗留下的慢SQL可能量级很大,所以要区分慢SQL治理的优先级。我们制定了健康分机制,对SQL分批分级治理。
对慢SQL来说,健康分主要受SQL的执行次数、扫描行数、执行时长影响。另外根据应用中包含慢SQL的数量、平均SQL执行数据等,给应用打出健康分。再根据部门维度汇总,根据应用等级、应用健康分情况等,计算出部门维度的健康分。
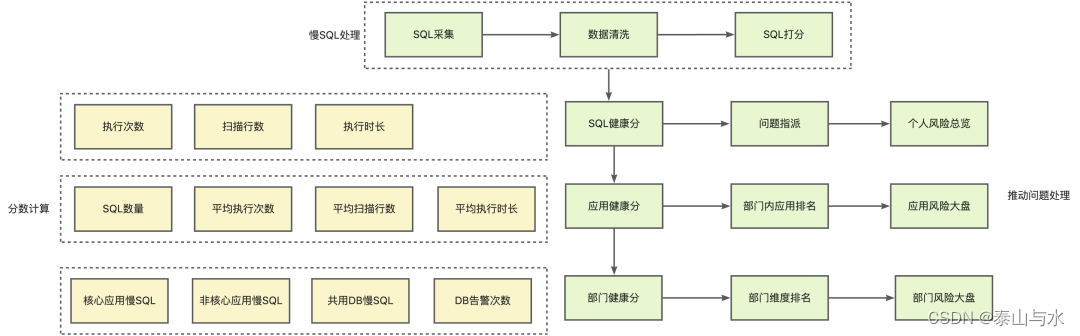
原文链接 SQL高发团队等,进行集中的推进治理SQL高发团队等,进行集中的推进在慢SQL推动治理方面,高危慢SQL,会建立Issue持续追踪,Issue存在超期时间,超期后会影响团队健康分。另外,提供应用维度、部门维度的整体慢SQL风险大盘以及排名,针对重点业务、慢SQL高发团队等,进行集中的推进治理
增量慢SQL治理
我们希望增量慢SQL能在上线前得到解决,即分支内不要引入慢SQL或者风险SQL,我们建立了开发环境下增量慢SQL发现机制,并建立发布前卡点能力。整体流程如下:
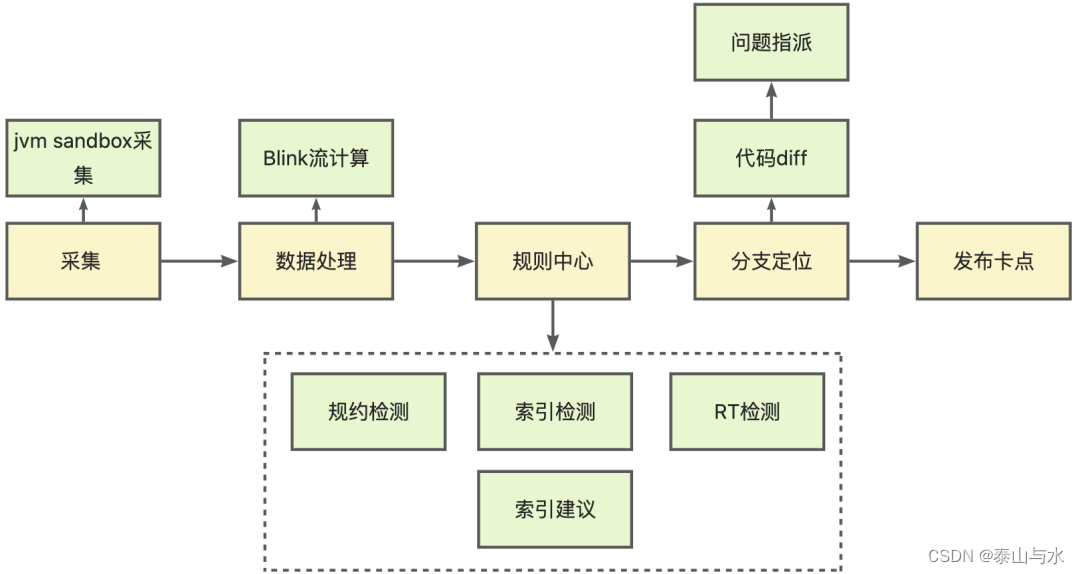
增量慢SQL的修复代价是小于存量慢SQL的,因此这里我们添加了分支定位的能力。同一应用存在多个同学共同开发的情况,有效的分支定位,可以准确指派慢SQL引入人,实现快速推动治理。这里以git上代码改动为切入点,完成了引入慢SQL的sql_map与修改人之间的关系映射,大致逻辑如下:
a. 监听应用部署消息
b. 获取应用信息,拿到git地址
c. 将本次部署分支与master分支做分支diff
d. 解析sql_map文件,获取本次修改的sql内容
e. 记录被修改sql_id与分支的对应关系
f. 根据sql_id查询对应分支
……
这样就可以精准匹配到增量SQL的引入分支,从而指派到开发者,实现了定向问题指派和追踪,并且可以方便完成分支发布前的管控能力。如果存在增量慢SQL,分支发布,合并到master之前,会触发卡点,需要问题解决才能发布
七、学习总结
本篇文章非常优秀,从技术,管理,制度,组织各个层面介绍了如何治理慢SQL,堪称教科书级别的。
技术:标准,风险,原因,自动化
管理:问题识别,问题跟踪到责任人及部门,且配合自动化的工具
制度:慢SQL排名,打分到个人,应用,部门,加上奖惩制度等
组织:公共的团队及监测系统来做治理这件事
八、亮点
- 采集全量SQL的自动化工具,解放dba人工分析慢SQL,极大提升效率
- SQL健康分评价体系
- 流程管理自动化体系
- 提前预警慢SQL及风险SQL自动化检测工具
九、实施思考
上面的方案堪称完美方案,但是大部分公司都不具备完全执行的条件
主要卡点:dba数量都不够,采集工具不具备,流程制度不具备,人力安排不具备
实施慢SQL本身这件事的卡点有那些?
- 业务需求多,业务团队如果是没有出生产事故的情况下,是不愿意主动投入资源做优化的,且优化还有风险
- 慢sql有的是架构不合理,数据结构本身不合理,更本不能单纯通过SQL本身去优化,完成优化涉及的范围面比较大,阻碍大
- 业务团队的技术支持不行,没办法优化慢SQL,优化慢SQL的风险意识不够
- 慢SQL的发现工具不够完善,不能及时高效发现
- 慢SQL的预防,治理及简单规范没有
- 考核本身
如果是一个小公司要执行慢sql治理,核心治理方案怎么制定?
- 慢SQL定义:再小的团队一个架构师,技术经理都能出一个团队范围内的定义
- 慢SQL的风险及如果引入:认知培训及意识培养,小团队能进行
- 慢SQL的发现:通过数据库自带的慢SQL日志发现慢SQL一般效率比较低,可以借鉴一些开源功能,或开发一些简单脚本定时做巡检分析那些慢SQL,比如dba一个季度出一次分析报告给到研发团队
- 研发要么从dba哪里获取慢SQL分析报告,要么有比较友好的入口可以自己检查看,这个比较重要
- 慢sql找到后,安装技术优化排期解决并考核
- 宣讲研发阶段怎么避免慢sql引入,团队知识升级
两三个人的团队都可以按照上面的流程来优化,不一定要非常完善的方案,这样投入产出比不划算,没有完美的方案只有适合的最佳方案;我们公司好几百个系统,研发上千人,dba才20人不到,根本没资源做
核心关键
- 慢sql的第一责任人研发,第二责任人dba,第三责任人sre;
- 慢sql的风险及收益,宣讲培养
- 考核

![[ai笔记11] 论ai韭菜的自我修养](https://img-blog.csdnimg.cn/img_convert/da09c32c54bb4866cc59253137159663.jpeg)