笔记正文
第一模块 C基础知识
考试大纲的要求
(1)掌握数据类型、变量和赋值;
(2)掌握输入和输出;
(3)掌握基本运算符和表达式;
(4)了解简单控制流程及流程图表示的规范。
笔记
C语言数据类型
C语言中,数据类型可分为:基本数据类型,枚举类型(enum),派生类型,空类型(void)四大类。
注意:C语言基本数据类型,三个空填整型、实型、字符型,两个空填整型和实型,其中实型也可改为浮点型。
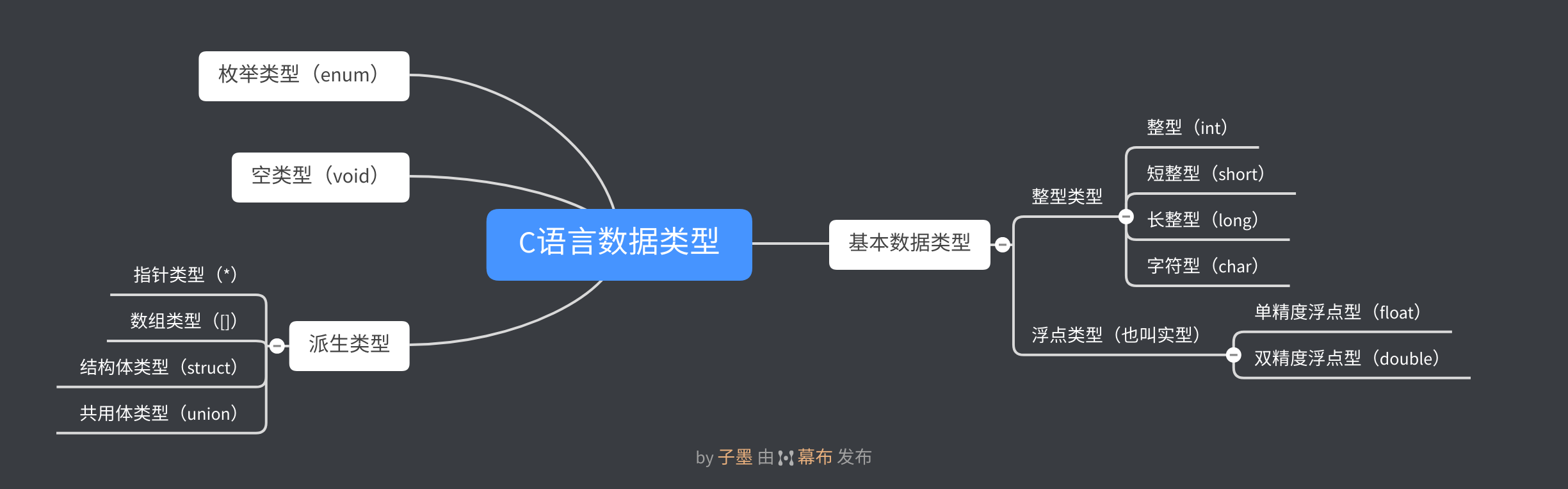
C语言数据类型基本数据类型整型类型整型(int)短整型(short)长整型(long)浮点类型(也叫实型)单精度浮点型(float)双精度浮点型(double)字符类型(char)(也可看做整型)枚举类型(enum)空类型(void)派生类型指针类型(*)数组类型([])结构体类型(struct)共用体类型(union)
C语言数据类型的存储空间和值的范围
| 类型 | 存储空间(字节) | 值的范围 |
|---|---|---|
| int | 4 | -2147483648~2147483647,即-231~231-1 |
| short | 2 | -32768~32767,即-215~215-1 |
| char | 1 | -128~127,即-27~27-1 |
| float | 4 | 有效数字6位,范围:0以及1.2x10-38~3.4x1038 |
| double | 8 | 有效数字15位,范围:0以及2.3x10-308~1.7x10308 |
标识符
- 标识符是给常量或者变量起的名字。
- C语言标识符规范:标识符可以是字母(
A~Z,a~z)、数字(0~9)、下划线_组成的字符串,并且第一个字符必须是字母或下划线
注意事项
- 标识符不能是C语言关键字;
- 标识符不能重复定义;
- 标识符大小写敏感;
- 标识符长度不要太长;
- 标识符最好见名知意。
C语言常量
程序运行过程中,值不会改变的量,一般用来给变量赋值,直接放在等号的右边(这样的常量也叫字面量),如int a = 120;float b = 0.1234;// 等号左边的a,b是变量(标识符),等号右边的整数和小数是字面量。
符号常量
用编译预处理语句(不是C语言的语句)声明的常量叫符号常量,如:#define 标识符 常量值,这样的常量在编译前,定义的标识符就会被预处理,整体替换为后面的常量值。
字面量
字面量通常是直接写在赋值(=)号右边的常量。
-
整型常量:整数,通常指十进制整数,
由0-9的数字组成,可带正负号
,如
6,+100,-3等。
- 八进制整型常量:八进制整数,以0开头,由0-7的数字组成,可带正负号,如
-01,011,+077等; - 十进制整型常量:通常意义上的整型常量;
- 十六进制整型常量:十六进制整数,以0x开头,由0-9的数字和字母a-f组成,可带正负号,如
0x17a,-0xffff,+0xabc123,0XabA1(字母可大写,可大小写混合); - 注意:C语言中没有二进制整型常量。
- 八进制整型常量:八进制整数,以0开头,由0-7的数字组成,可带正负号,如
-
实型常量:小数,一般不考虑进制,即默认为十进制小数,当小数点前一位只有0时,可以省略0,即
0.121还可以表示为.121;同理指数形式也可省略,0.2e3还可以表示为.2e3。
- 十进制小数形式:由数字和小数点组成,可带正负号,如
0.123,+6.24,-3.2等; - 指数形式:以字母e代表10为底的指数,指数只能是整数(即e3表示10的3次方,e-5表示10的-5次方),如
12.3e-5,3.1e10,+1e0,,1.2e3; - 注意:指数形式,当小数点前面只有0,且e前没有整数时,0不可省略,如
0.e5,如果省略就变成了.e5,是错误的
- 十进制小数形式:由数字和小数点组成,可带正负号,如
-
字符常量:用
单撇号
括起来的
字符
,通常只有一个字符,转义字符除外。
- 普通字符:用单撇号括起来的一个字符,如
‘a’,‘3’,‘A’,‘$’,‘ ’,'"'等 - 转义字符:以\开头的字符,如
'\n','\t','\\','\'',‘\"’等。 - 八进制字符(属于转义字符的一种):用单撇号括起来的以\开头,由0-7的数字组成的串,最多只有三位数字,理解的时候转换为十进制所对应的ASCII码所对应的字符即可,如:
'\041','\040' - 十六进制字符(属于转义字符的一种):用单撇号括起来的以\x开头,由0-9的数字和a-z的字母组成的串,最多只有两位,理解的时候转换为十进制所对应的ASCII码所对应的字符即可,如:
'\x28','\x29'
- 普通字符:用单撇号括起来的一个字符,如
-
字符串常量:用双撇号括起来的零个或者多个字符(可以是上面的字符常量组成),如
"abd","sdf123",“1”等。
字符常量——转义字符表
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一个反斜线字符’‘’ | 092 |
| ’ | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| ? | 代表一个问号 | 063 |
| \0 | 空字符(NUL) | 000 |
| \ddd | 1到3位八进制数所代表的任意字符 | 三位八进制 |
| \xhh | 十六进制所代表的任意字符 | 两位十六进制 |
C语言变量
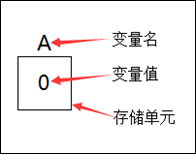
程序运行过程中,值可以改变的量。
- 变量会占据内存中一定的存储单元;
- 使用变量之前必须先定义;
- 变量名和变量值是完全不同的两个概念;
- 变量定义的一般形式为:数据类型 变量名;
- 可以同时定义多个类型相同的变量:数据类型 变量名, 变量名, 变量名…;
- 变量名必须满足标识符的规范;
- 数据类型必须是C语言数据类型;
- 如果定义了变量未赋值就使用,那么该变量的值将不可预测。
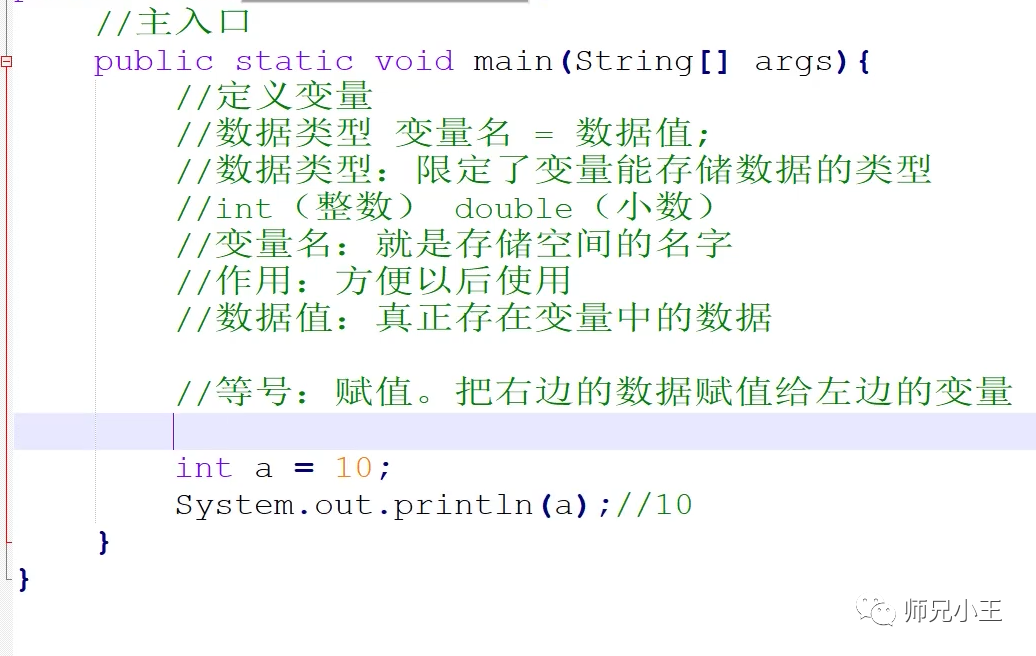
给变量赋值的方式
-
先定义后赋值。
-
定义的同时赋值。
注意:变量在定义中不允许连续赋值,如:
int a = b = c = 3;是错误的语句,但是已经定义好的变量允许连续赋值。#include <stdio.h> int main() { // 示例代码——定义变量,并给变量赋值 int a; a = 2;// 先定义后赋值 double b = -.14;// 定义的同时赋值 int c,d; c = d = a = 5;// 已经定义好了的变量可以连续赋值 return 0; }
C语言输入与输出
C语言没有输入输出语句
C语言的输入输出操作都需要依赖库函数,常用的输入输出函数是scanf()和printf(),使用时需要先引入头文件#include<stdio.h>。
C语言printf()函数
格式化输出函数。
函数原型:
int printf(const char *format, ...)
用法:printf(“格式控制字符串”, 输出表列)
功能:将变量转化为“格式控制字符串”所规定格式的数据,然后输出到终端中。
格式字符串是以%开头的字符串,在%后面跟有各种格式字符,以说明输出数据的类型、形式、长度、小数位数等,一般形式为[标志][输出最小宽度][.精度][长度]类型,(注意:[]表示可省略的项)。
-
类型:
格式字符 意义 d 以十进制形式输出带符号整数(正数不输出符号) o 以八进制形式输出无符号整数(不输出前缀0) x,X 以十六进制形式输出无符号整数(不输出前缀Ox) u 以十进制形式输出无符号整数 f 以小数形式输出单、双精度实数 e,E 以指数形式输出单、双精度实数 g,G 以%f或%e中较短的输出宽度输出单、双精度实数 c 输出单个字符 s 输出字符串 -
标志:
标 志 意义 - 结果左对齐,右边填空格 + 输出符号(正号或负号) 空格 输出值为正时冠以空格,为负时冠以负号 # 对c、s、d、u类无影响; 对o类,在输出时加前缀o; 对x类,在输出时加前缀0x; 对e、g、f 类当结果有小数时才给出小数点。 -
输出最小宽度
用十进制整数来表示输出的最少位数。若实际位数多于定义的宽度,则按实际位数输出,若实际位数少于定义的宽度则补以空格或0。
-
精度
精度格式符以“.”开头,后跟十进制整数。
-
长度
长度格式符为h、l两种,h表示按短整型量输出,l表示按长整型量输出。
-
printf()函数实例#include <stdio.h> int main() { int a = 15; double b = 123.1234567; double c = 12345678.1234567; char d = 'p'; printf("a=%d\n", a); printf("a(%%d)=%d, a(%%5d)=%5d, a(%%o)=%o, a(%%x)=%x\n\n", a, a, a, a); // %% 可以输出 % printf("b=%f\n", b); printf("b=%-8.2f\n", b); // 左对齐,占8格,四舍五入后精确到小数点后两位 printf("b(%%f)=%f, b(%%lf)=%lf, b(%%5.4lf)=%5.4lf, b(%%e)=%e\n\n", b, b, b, b); printf("c=%f\n", c); printf("c(%%lf)=%lf, c(%%f)=%f, c(%%8.4lf)=%8.4lf\n\n", c, c, c); printf("d=%c\n", d); printf("d(%%c)=%c, d(%%8c)=%8c\n", d, d); return 0; } /*输出结果*/ /* a=15 a(%d)=15, a(%5d)= 15, a(%o)=17, a(%x)=f b=123.125457 b=123.13 b(%f)=123.125457, b(%lf)=123.125457, b(%5.4lf)=123.1255, b(%e)=1.231255e+02 c=12345678.123457 c(%lf)=12345678.123457, c(%f)=12345678.123457, c(%8.4lf)=12345678.1235 d=p d(%c)=p, d(%8c)= p */
C语言scanf()函数
格式化输入函数。
函数原型:
int scanf(const char *format, ...)
用法:scanf("输入控制符", 输入参数)
功能:将从键盘输入的字符转化为“输入控制符”所规定格式的数据,然后存入以输入参数的值为地址的变量中。
输入控制符几乎与printf()一模一样。
注意:输入参数接收的是地址,在某些情况下,请注意使用&运算符。
小结printf()和scanf()
细节很多,不用全部熟记,熟记下面的注意事项即可;
- 控制符中,%d、%f、%s、%c 最常用,功能分别是输出整数、实数、字符串和字符;
printf()使用时需注意转义字符有特殊的含义;scanf()在某些情况下,使用时需注意使用&运算符;- 编译器不会检查输入和输出的参数数目与控制符数目是否一致;
scanf()函数的双引号内,除了“输入控制符”外尽量什么都不要写,否则读入可能跟预想不一样;- 使用
scanf()函数输入字符串时,要注意,scanf()读到第一个空格、或者Tab或者回车符就会结束读入;- 在某些情况下可能会遇到
scanf()和printf()的返回值,所以特别说明一下,返回值的意义,用scanf()读取几个数据,则scanf()的返回值为几,printf()同理,用printf()输出几个数据,则printf()的返回值为几。
printf()函数拓展问题,请思考下面的程序输出结果是?
#include <stdio.h>
int main() {
int i = 1;
printf("i=%d,i++=%d,++i=%d",i,i++,++i);
return 0;
}
C语言其他输入输出函数
getchar(),输入单个字符,常用来去掉scanf()缓存的回车符。putchar(),输出单个字符。gets(),输入字符串,可以输入含空格的字符串。puts(),输出字符串。
C语言基本运算符
算术运算符
下表显示了 C 语言支持的所有算术运算符。假设变量 A 的值为 3,变量 B 的值为 20,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 23 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -17 |
| * | 把两个操作数相乘 | A * B 将得到 60 |
| / | 分子除以分母 | B / A 将得到 6(整型 / 整型 最后的结果还是整型,所以没有小数部分) |
| % | 取模运算符,整除后的余数 | B % A 将得到 2 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 4 |
| – | 自减运算符,整数值减少 1 | A-- 将得到 2 |
注意:
B = A++、B = A--先赋值后运算,B = ++A、B = --A先运算后赋值
关系运算符
下表显示了 C 语言支持的所有关系运算符。假设变量 A 的值为 10,变量 B 的值为 20,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (A == B) 为假。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (A > B) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 | (A >= B) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 | (A <= B) 为真。 |
逻辑运算符
下表显示了 C 语言支持的所有关系逻辑运算符。假设变量 A 的值为 1,变量 B 的值为 0,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
赋值运算符
下表列出了 C 语言支持的赋值运算符:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 | C = A + B 将把 A + B 的值赋给 C |
| += | 加且赋值运算符,把右边操作数加上左边操作数的结果赋值给左边操作数 | C += A 相当于 C = C + A |
| -= | 减且赋值运算符,把左边操作数减去右边操作数的结果赋值给左边操作数 | C -= A 相当于 C = C - A |
| *= | 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋值给左边操作数 | C *= A 相当于 C = C * A |
| /= | 除且赋值运算符,把左边操作数除以右边操作数的结果赋值给左边操作数 | C /= A 相当于 C = C / A |
| %= | 求模且赋值运算符,求两个操作数的模赋值给左边操作数 | C %= A 相当于 C = C % A |
其他运算符 sizeof & 三元
| 运算符 | 描述 | 实例 |
|---|---|---|
| sizeof() | 返回变量或者类型的大小。 | sizeof(a) 将返回 4,其中 a 是整数。 sizeof(double) 将返回 8 |
| & | 返回变量的地址。 | &a; 将给出变量的地址。 |
| * | 指向一个变量或取指针所指向内存地址的值。 | int *a = &b; 将指向一个变量。b = *a:将取出a指向地址的变量值赋值给b。 |
| 条件表达式 ? X : Y ; | 条件表达式 | 如果条件为真 ? 则值为 X : 否则值为 Y |
C语音中的运算符优先级
运算符的优先级确定表达式怎么计算,最终会影响到表达式的值。某些运算符比其他运算符有更高的优先级,例如,乘除运算符具有比加减运算符更高的优先级。
下表将按运算符优先级从高到低列出各个运算符,具有较高优先级的运算符出现在表格的上面,具有较低优先级的运算符出现在表格的下面。在表达式中,较高优先级的运算符会优先被计算。
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀运算符 | () [] -> . ++ - - | 从左到右 |
| 一元运算符 | + - ! ~ ++ - - (type)* & sizeof | 从右到左 |
| 乘除运算符 | * / % | 从左到右 |
| 加减运算符 | + - | 从左到右 |
| 关系运算符 | < <= > >= | 从左到右 |
| 相等运算符 | == != | 从左到右 |
| 条件运算符 | ?: | 从右到左 |
| 赋值运算符 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号运算符 | , | 从左到右 |
C语言表达式
表达式(Expression)和语句(Statement)的概念在C语言中并没有明确的定义:
- 表达式可以看做一个计算的公式(字面理解是表达某种含义的式子),往往由数据、变量、运算符等组成,例如
3*4+5、a=c=d等,表达式的结果必定是一个值; - 语句的范围更加广泛,不一定是计算,不一定有值,可以是某个操作、某个函数、选择结构、循环等。
划重点:
- 表达式必须有一个执行结果,这个结果必须是一个值,例如
3*4+5的结果 17,a=c=d=10的结果是10,printf("hello")的结果是 5(printf()函数的返回值是成功打印的字符的个数)。 - 以分号;结束的往往称为语句,而不是表达式,例如
3*4+5;、a=c=d;等; - 语句不一定以分号结束,比如
if语句,for语句
自动类型转换
一个表达式中出现不同类型间的混合运算,较低类型将自动向较高类型转换,这个自动转换的过程就叫自动类型转换。
不同数据类型之间的差别在于数据的表示范围及精度上,一般情况下,数据的表示范围越大、精度越高,其类型也越“高级”。
赋值运算中如果左值精度比右值精度低,将会出现截断,会导致精度丢失。
当函数调用时,所传实参与形参类型不一致时,也会把实参自动转换为形参类型后再赋值(类型以形参为准)。
强制类型转换
C 语言提供了可显式指定类型转换的语法支持,通常称之为强制类型转换。
(目标类型) 表达式
算法流程图
基本符号
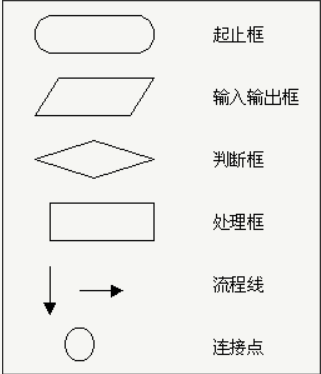
顺序结构基本流程图
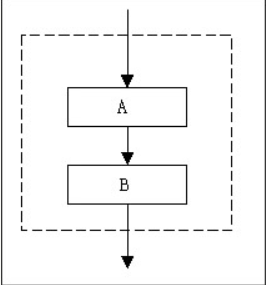
选择结构基本流程图
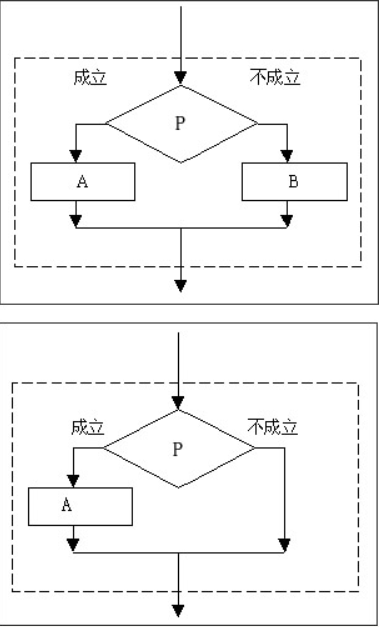
循环结构基本流程图
画流程图的步骤
- 写算法描述。
- 转换为图(需要按照实际情况组合顺序结构,循环结构,选择结构对应的基本流程图)。
实例:判断闰年,画法一
算法描述:
1. 从键盘输入year年份
2. 判断year是否满足year % 4 == 0 && year % 100 != 0
3. 是,输出year是闰年
4. 不是,判断year是否满足year % 100 == 0 && year % 400 == 0
5. 是,输出year是闰年,否则输出year不是闰年
流程图:
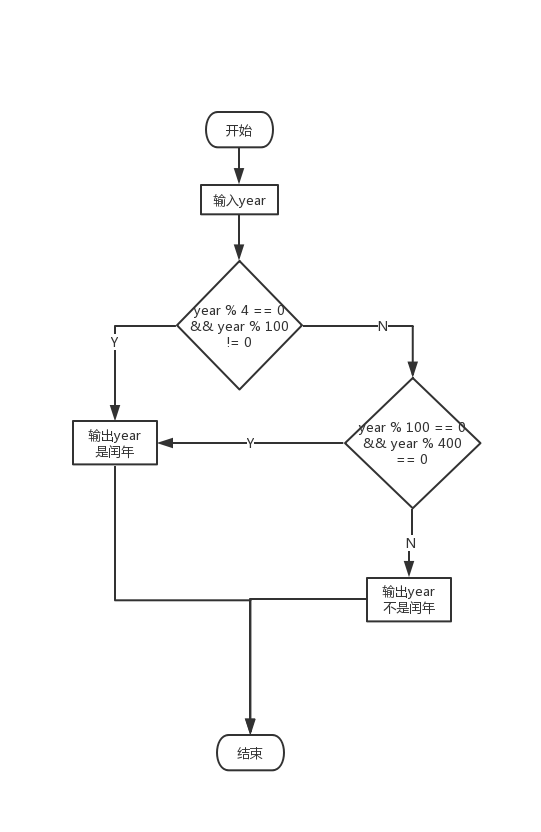
流程图
代码实现:
#include <stdio.h>
int main() {
int year;
scanf("%d", &year);
if (year % 4 == 0 && year % 100 != 0) {
printf("%d 是闰年", year);
} else if (year % 100 == 0 && year % 400 == 0) {
printf("%d 是闰年", year);
} else {
printf("%d 不是闰年", year);
}
return 0;
}
实例:判断闰年,画法二
算法描述:
主流程:
1. 从键盘输入year年份
2. 判断是否闰年,若是,输出year是闰年,否则输出输出year不是闰年
子流程:判断是否闰年:参数是输入年份
1. 判断year是否满足year % 4 == 0 && year % 100 != 0
2. 是,返回1
3. 不是,判断year是否满足year % 100 == 0 && year % 400 == 0
4. 是,返回1,否则返回0
流程图:
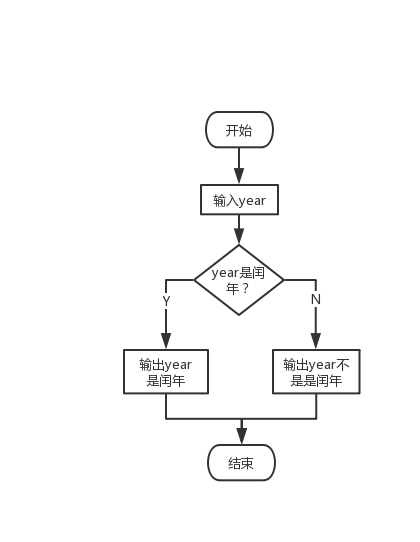
主流程图
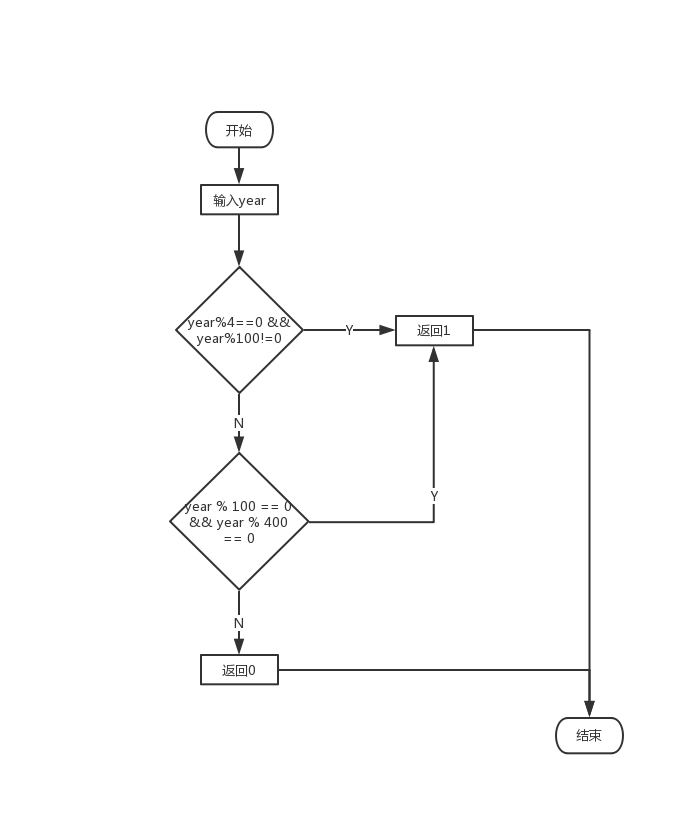 子流程图
子流程图
代码实现:
#include <stdio.h>
#include <stdbool.h>
bool isLeapYear(int year);
int main() {
int year;
scanf("%d", &year);
if (isLeapYear(year)) {
printf("%d 是闰年", year);
} else {
printf("%d 不是闰年", year);
}
return 0;
}
bool isLeapYear(int year) {
if (year % 4 == 0 && year % 100 != 0) {
return 1;
}
if (year % 100 == 0 && year % 400 == 0) {
return 1;
}
return 0;
}
第二模块 选择结构程序设计
考试大纲的要求
(1)掌握关系运算符;
(2)掌握逻辑运算符;
(3)掌握布尔表达式求值;
(4)掌握if语句;
(5)掌握switch语句;
(6)理解分支结构的流程图表示。
笔记
C语言逻辑真假
非0为真(true),0为假(false)。
在关系和逻辑表达式中,若表达式为真则值取1,否则值取0。
关系运算符
C 语言提供的关系运算符有: >(大于)、>=(大于等于)、<(小于)、<=(小于等于)、==(等于)和 !=(不等于)6 种二元关系运算符。
在以上 6 种关系运算符中,前 4 个的优先级高于最后两个。
由关系运算符组成的式子为关系表达式,如 a > b 即为关系表达式,在 C 语言中,同逻辑表达式一样,关系表达式的值也为逻辑值,即布尔型(bool),取值为真或假。
关系运算符一般不能连用,如果连用将表达不同的含义,如:
#include <stdio.h>
int main() {
int a = 1;
int b = 2;
int c = 3;
int d = a <= b <= c;// a <= b <= c不是表达b的值在[a,b]之间,而是a先和b比较,a<=b所以表达式的值是1,然后1与c比较,1<=c,右值是1,然后赋给左值,所以d的值是1
// 如果要表达b的值在[a,c]之间应该是b >= a && b <= c
printf("%d",d);
return 0;
}
逻辑运算符
- 与运算(&&):参与运算的两个表达式都为真时,结果才为真,否则为假;
- 或运算(||):参与运算的两个表达式只要有一个为真,结果就为真;两个表达式都为假时结果才为假;
- 非运算(!):参与运算的表达式为真时,结果为假;参与运算的表达式为假时,结果为真。
逻辑运算符和关系运算符与其他运算符的优先级
赋值运算符(=) < &&和|| < 关系运算符 < 算术运算符 < 非(!)
布尔表达式求值
- 确定运算符优先级
- 确定运算符结合方向
- 得出值(布尔表达式的值只可能是0或者1)
if语句
// 形式1——表达式的值不为0,就执行操作1(操作1可包含多条语句),否则什么都不做,往下继续执行
if (表达式) {
操作1
}
// 形式2——表达式的值不为0,就执行语句(只有一条语句),否则什么都不做,往下继续执行
if (表达式) 语句;
if else语句
// 形式1——表达式的值不为0,就执行操作1,否则执行操作2(操作1,2可包含多条语句)
if (表达式) {
操作1
} else {
操作2
}
// 形式二——表达式的值不为0,就执行语句1,否则执行语句2(语句1,2只能是单条语句)
if (表达式) 语句1;
else 语句2
并列的if else语句
/* 如果表达式1的值不为0,就执行操作1
否则判断表达式2的是否为0,如果不为0,执行操作2
否则判断表达式3的值是否为0,如果不为0,执行操作3,
...
否则判断表达式n的值是否为0,如果不为0,执行操作n,
否则执行操作n+1
注意,操作1~n+1中只有一个可以执行*/
if (表达式1) {
操作1
} else if (表达式2) {
操作2
} else if (表达式3) {
操作3
} ...else if (表达式n) {
操作n
} else {
操作n+1
}
嵌套的if else语句
/*如果表达式1的值不为0,判断表达式2的值是否为0,如果表达式2的值为0,执行操作1,否则判断表达式3的值是否为0,如果不为0,执行操作2,否则执行操作3*/
if (表达式1) {
if (表达式2) {
操作1
}
} else {
if (表达式3) {
操作2
} else {
操作3
}
}
注意:多种形式的
if、if else、并列的if else、嵌套的if else等可以相互组合和嵌套,但是不建议嵌套太多层,那样会减低程序的可阅读性。
switch语句
一个 switch 语句允许测试一个变量等于多个值时的情况。每个值称为一个 case,且被测试的变量会对每个 switch case 进行检查。
switch 语句的语法:
switch(expression){
case constant-expression :
statement(s);
break; /* 可选的 */
case constant-expression :
statement(s);
break; /* 可选的 */
/* 可以有任意数量的 case 语句 */
default : /* 可选的 */
statement(s);
}
switch 语句必须遵循下面的规则:
- switch 语句中的 expression 是一个常量表达式,必须是一个整型(char本质上属于整型)或枚举类型。
- 在一个 switch 中可以有任意数量的 case 语句。每个 case 后跟一个要比较的值和一个冒号。
- case 的 constant-expression 必须与 switch 中的变量具有相同的数据类型,且必须是一个常量或字面量。
- 当被测试的变量等于 case 中的常量时,case 后跟的语句将被执行,直到遇到 break 语句为止。
- 当遇到 break 语句时,switch 终止,控制流(可理解为程序的执行过程)将跳转到 switch 语句后的下一行。
- 不是每一个 case 都需要包含 break。如果 case 语句不包含 break,控制流将会 继续执行 后续的 case,直到遇到 break 为止。
- 一个 switch 语句可以有一个可选的 default,一般出现在 switch 的结尾。default 可用于在上面所有 case 都不为真时执行一个任务。default 中的 break 语句不是必需的。
第三模块 循环控制
考试大纲的要求
(1)掌握for循环;
(2)掌握while循环;
(3)掌握do-while循环;
(4)理解循环结构的流程图表示。
笔记
for循环
for 循环允许编写一个执行指定次数的循环控制结构。
for 循环的语法:
for ( init; condition; increment )
{
statement(s);
}
for 循环的控制流:
- init 会首先被执行,且只会执行一次。这一步允许您声明并初始化任何循环控制变量。您也可以不在这里写任何语句,只要有一个分号出现即可。
- 接下来,会判断 condition。如果为真,则执行循环主体。如果为假,则不执行循环主体,且控制流会跳转到紧接着 for 循环的下一条语句。
- 在执行完 for 循环主体后,控制流会跳回上面的 increment 语句。该语句允许您更新循环控制变量。该语句可以留空,只要在条件后有一个分号出现即可。
- 条件再次被判断。如果为真,则执行循环,这个过程会不断重复(循环主体,然后增加步值,再然后重新判断条件)。在条件变为假时,for 循环终止。
while循环
只要给定的条件为真,C 语言中的 while 循环语句会重复执行一个目标语句。
while 循环的语法:
while(condition)
{
statement(s);
}
statement(s) 可以是一个单独的语句,也可以是几个语句组成的代码块。
condition 可以是任意的表达式,当为任意非零值时都为 true。当条件为 true 时执行循环。 当条件为 false 时,退出循环,程序流将继续执行紧接着循环的下一条语句。
do…while循环
不像 for 和 while 循环,它们是在循环头部测试循环条件。在 C 语言中,do…while 循环是在循环的尾部检查它的条件。
do…while 循环与 while 循环类似,但是 do…while 循环会确保至少执行一次循环。
do…while 循环的语法:
do
{
statement(s);
}while( condition );
注意,条件表达式出现在循环的尾部,所以循环中的 statement(s) 会在条件被测试之前至少执行一次。
如果条件为真,控制流会跳转回上面的 do,然后重新执行循环中的 statement(s)。这个过程会不断重复,直到给定条件变为假为止。
死循环
如果循环控制流中条件表达式的值永远为true,称为死循环,通常是应该避免的。
常见死循环:
// for形式死循环
for(;;) {
}
for(;1;) {
}
// while形式死循环
while(1) {
}
// do...while形式死循环
do{
}while(1);
三种循环语句比较
while、do...while和for三种循环在具体的使用场合上有区别,具体如下:
- 在知道循环次数的情况下更适合使用for循环;
- 在不知道循环次数的情况下适合使用while或者do-while循环,如果有可能一次都不循环应使用while循环,如果至少循环一次应使用do-while循环;
- 从本质上讲,
while,do...while和for循环之间可以相互转换。
多重循环(循环嵌套)
有时候一个循环有可能满足不了需求,或者说使用起来不太方便,如:遍历二维数组时,这个时候我们就需要用到多重循环,多重循环就是在循环结构(含有循环语句的结构就叫循环结构)的循环体中又出现循环结构。
使用break语句跳出循环
break 语句,可以跳出循环,还可以跳出 switch。
break 语句不能用于循环语句和 switch 语句之外的任何其他语句中。
在没有循环结构的情况下,break不能用在单独的if else语句中。
在多层循环中,一个break语句只跳出当前循环。
使用break语句,可以跳出死循环。
使用continue语句结束循环
continue 的用法十分简单,其作用为结束本次循环,即跳过循环体中下面尚未执行的语句,然后进行下一次是否执行循环的判定。
continue和break的区别
continue 语句和 break 语句的区别是,continue 语句只结束本次循环,而不是终止整个循环。
break 语句则是结束整个循环过程,不再判断执行循环的条件是否成立。
而且,continue 只能在循环语句中使用,即只能在 for、while 和 do…while 中使用,除此之外 continue 不能在任何语句中使用。
第四模块 数组的使用
考试大纲的要求
(1)掌握一维数组;
(2)掌握二维数组;
(3)理解字符数组与字符串。
笔记
数组
数组是在内存中连续存储的具有相同类型的一组数据的集合
一维数组
语法:
类型说明符 数组名[正整数常量表达式];
例如:
int a[5];
表示定义了一个整型数组,数组名为 a,定义的数组称为数组 a。数组名 a 除了表示该数组之外,还表示该数组的首地址。
此时数组 a 中有 5 个元素,每个元素都是 int 型变量,而且它们在内存中的地址是连续分配的。也就是说,int 型变量占 4 字节的内存空间,那么 5 个int型变量就占 20 字节的内存空间,而且它们的地址是连续分配(物理相邻)的。
元素就是变量,数组中习惯上称为元素。
定义数组时,需要指定数组中元素的个数。方括号中的正整数常量表达式就是用来指定元素的个数。数组中元素的个数又称数组的长度。
C语音通过给每个数组元素进行编号的方式访问数组中的元素。数组元素的编号又叫下标,访问数组中第5个元素的方式应该是a[4]。
因为数组中的下标是从 0 开始的。
一维数组初始化:
-
定义数组时给所有元素赋初值,这叫“完全初始化”。例如:
int a[5] = {1, 2, 3, 4, 5};
通过将数组元素的初值依次放在一对花括号中,初始化之后,a[0]=1;a[1]=2;a[2]=3;a[3]=4;a[4]=5,即从左到右依次赋给每个元素。需要注意的是,初始化时各元素间是用逗号隔开的,不是用分号。
-
可以只给一部分元素赋值,这叫“不完全初始化”。例如:
int a[5] = {1, 2};
定义的数组 a 有 5 个元素,但花括号内只提供两个初值,这表示只给前面两个元素 a[0]、a[1] 初始化,而后面三个元素都没有被初始化。值得注意的是,不完全初始化时,没有被初始化的元素自动为 0。
需要注意的是,“不完全初始化”和“完全不初始化(未初始化,即只声明了但未赋值)”不一样。如果“完全不初始化”,即只定义int a[5];而不初始化,那么各个元素的值就不是0了,所有元素的值都是不确定值。
数组跟变量一样必须先定义,然后使用。
通常用for循环语句遍历数组。
常见错误1:
# include <stdio.h>
int main() {
int a[5];
a[5] = {1, 2, 3, 4, 5};// 错误的原因是,只有在定义时才可以用大括号初始化
return 0;
}
常见错误2:
# include <stdio.h>
int main() {
int a[5] = {1, 2, 3, 4, 5, 6};// 错误的原因初始化数组超过了数组本身的大小
return 0;
}
常见错误3:
# include <stdio.h>
int main() {
int a[5] = {};// 初始化大括号里面不能什么都不填
return 0;
}
二维数组
二维数组在逻辑上是数组的数组,即二维数组的每个元素是一个一维数组(一行),在物理上是一维数组,即所有的元素都是连续存储的。从直观上来看,二维数组就是线性代数中的矩阵。
语法:
类型说明符 数组名[正整数常量表达式1][正整数常量表达式2];
例如:
int a[3][4];
在这个定义的二维数组中,共包含3 * 4个元素,即12个元素。接下来,通过一张图来观察二维数组a的元素分布情况,如图所示:
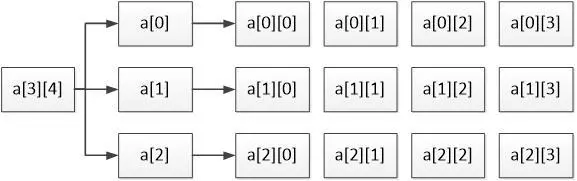
通过另一张图来观察二维数组a的逻辑结构和存储结构:
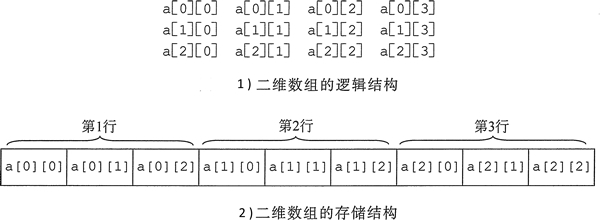
同一维数组类似,对数组元素的访问也是用下标,指定行下标(常量表达式)和列下标(常量表达式),行下标和列下标都是从0开始的:
a[0][0]; //为0行0列元素,注意与习惯上区分开,习惯上的第1对应下标0
a[2][1]; //为2行1列元素
a[1][1+2]; //为1行3列元素
二维数组的初始化:
-
先定义,后赋值,在显式赋值之前,二维数组的各数据元素是随机值(不确定)。
// 先定义 int a[2][3]; // 后赋初值 a[0][0]=1; a[0][1]=2; a[0][2]=3; a[1][0]=4; a[1][1]=5; a[1][2]=6; -
在定义二维数组的同时,采用初始化列表的形式对其元素赋初值。
// 分行给出初始化数据,且每行的初始化数据个数等于列数,这一行代码相当于上面的七行代码 int a[2][3]={{1,2,3},{4,5,6}}; // 由于初始化列表中明确给出了两行数据,故定义该数组时,其第一维的大小可省略,编译器能间接算出该数组的行数为 2,故依然可以确定其空间大小,因此,在对二维数组进行初始化时,其第一维的大小可以省略,即写成如下形式: // int a[][3]={{l,2,3},{4,5,6}}; // 等价于不分行写法,前提是 数组元素的个数(行数 × 列数)= 大括号后面的初始值个数 // int a[2][3]={l,2,3,4,5,6}; // 同样可以省略第一维的大小 // int a[][3]={l,2,3,4,5,6}; // 如果数组元素的个数(行数 × 列数)不等于 大括号后面的初始值个数 // int a[][3]={l,2,3,4,5,6,7}; // 这就相当于 // int a[3][3] = {l,2,3,4,5,6,7,0,0}; // 第一维大小可省略 // 也相当于 // int a[3][3] = {l,2,3,4,5,6,7,0}; // 第一维大小可省略 // 还相当于 // int a[3][3] = {{l,2,3},{4,5,6},{7,0,0}}; // 第一维大小可省略 // 同时相当于 // int a[3][3] = {{l,2,3},{4,5,6},{7}}; // 第一维大小可省略 // 最后,还可以相当于先定义,后赋值的形式,这里省略相关代码 // 注:某行一行初始值如未写全,那么该行元素,后面的元素会自动被赋予初值0 -
二维数组初始化常见错误
int a[2][] = {{l,2,3},{4,5,6}}; //错误。不能省略第二维大小 int a[][] = {{l,2,3}, {4,5,6}}; //错误。不能省略第二维大小 int a[][3]; //错误。没有提供初始化列表时,两维的大小都必须显式给出 int a[2][3] = {{l,2,3},{4,5,6},{7,8,9}}; //错误。初始行数多于数组行数
通常使用双层for循环,遍历二维数组
字符数组与字符串
字符数组
用来存放字符的数组称为字符数组。字符数组的各个元素依次存放字符串的各字符,字符数组的数组名代表该数组的首地址,这为处理字符串中个别字符和引用整个字符串提供了极大的方便。字符数组的定义形式与前面介绍的整型数组相同。
语法:
char c[6];
在定义时进行初始化赋值:
// 长度可省略
char c[6]={'c', ' h ', 'i', 'n', 'a' , '\0' };
先定义后赋值:
char c[6];
c[0]= 'c',c[1]= 'h',c[2]= 'i',c[3]= 'n',c[4]= 'a',c[5]= '\0';
其中,‘\0’为字符串结束符。如果不对c[5]赋任何值,‘\0’会由编译器自动添加。
如果如果大括号里面的元素个数小于数组的长度,则只将大括号中的字符赋给数组中前面的元素,剩下的内存空间编译器会自动用 ‘\0’ 填充。
字符数组也可采用字符串常量的赋值方式,例如:
char a[]={"china"};// 长度是6,因为最后还有一个结束符'\0'
// 等价形式
// char a[] = "china";/ 同理,长度是6
scanf %s输入字符数组时,不需要取地址,因为数组名本身就是地址常量。
char a[10];
scanf("%s",a);// scanf %s不能输入带有空格的字符串,会被截断,如果字符串中可能带有空格(回车,tab)字符,用gets函数输入
可以用for循环(其他循环也可以)加printf %c形式输出字符数组的内容,也可以直接用printf %s格式输出字符数组内容。
char a[] = "china";
// for循环加printf %c形式输出
int i;
for (i = 0;i < sizeof(a);i++) {
printf("%c",a[i]);
}
// 直接用printf %s格式输出字符数组
printf("%s",a);
字符串
C语言中没有字符串这种数据类型,但是可以通过char的数组来替代;
字符串一定是一个char的数组,但char的数组未必是字符串;
数字0(和字符‘\0’等价)结尾的char数组就是一个字符串,但如果char数组没有以数字0结尾,那么就不是一个字符串,只是普通字符数组,所以字符串是一种特殊的char的数组。
内存中字符串以字符数组的形式存在,而数组以指针常量(地址常量)的形式存在,即数组首地址是个很关键的因素。
正是由于数组都是以指针常量的形式存在,所以C语言没有办法对数组的大小进行检查,所以通常,数组越界错误编译器是不会指出来的,但是也有部分高级的编译器会指出warning。
字符串操作函数
常用的字符串操作函数如下:

使用字符串操作函数注意事项:
- 使用前需要先引入头文件
#include<string.h>; strlen()获取字符串的长度,在字符串长度中是不包括‘\0’而且汉字和字母的长度是不一样的;strcmp()在比较的时候会把字符串先转换成ASCII码再进行比较,返回的结果为0,表示s1和s2的ASCII码相等,返回结果为1,表示s1比s2的ASCII码大,返回结果为-1,表示s1比s2的ASCII码小;strcpy()拷贝之后会覆盖s1原来的字符串且s1不能是字符串常量;- s,s1,s2均为字符指针类型(即可以传递的实参为字符指针,字符数组,字符串常量)。
第五模块 函数的使用
考试大纲的要求
(1)掌握函数的原型声明、调用及返回;
(2)掌握函数参数;
(3)理解变量存储特性。
笔记
函数
函数是学习 C 语言的重点。C 语言的主体和核心,一个是函数,另一个是指针。
简单来说,一个函数就是实现一个功能模块。
每个 C 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。主函数main()的功能是程序入口。
函数声明告诉编译器函数的名称、返回类型和参数。函数定义提供函数的实际主体。
语法:
return_type function_name( parameter list )
{
body of the function
}
在 C 语言中,函数由一个函数头和一个函数主体组成。下面列出一个函数的所有的组成部分:
- 返回类型:一个函数可以返回一个值。return_type 是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type 是 void(即返回值为空,不返回任何值)。
- 函数名称:这是函数的实际名称。函数名和参数列表一起构成了函数签名。
- 参数:参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
- 函数主体:函数主体包含一组定义函数执行任务的语句。
- 函数名必须满足标识符的规范。
实例:
#include <stdio.h>
#include <stdbool.h>
bool isLeapYear(int year);// 函数声明,函数功能是,判断传入的年份是不是闰年,如果是返回1(真),否则返回0(假)
int main() {
int year;
scanf("%d", &year);
if (isLeapYear(year)) {// 这里的year是实参,因为这里在调用函数
printf("%d 是闰年", year);
} else {
printf("%d 不是闰年", year);
}
return 0;
}
bool isLeapYear(int year) {// 函数头,bool是函数返回值类型,返回值通常用来控制程序逻辑走向,这里的year是函数参数,形参
// 下面是函数体
if (year % 4 == 0 && year % 100 != 0) {
return 1;
}
if (year % 100 == 0 && year % 400 == 0) {
return 1;
}
return 0;
}
递归函数
一个函数总会在某种情况下调用它本身,这样的函数叫递归函数,递归函数通常可以把问题简化,但是初学者难以理解。
递归函数设计的两个原则:
- 把大问题转换为子问题(找递推关系式)
- 递归出口
比如:要求10的阶乘,10的阶乘不好求,因为规模太大了,那我们就想,如果数据规模小一点,变成9的阶乘呢?会不会好求一点呢,然后9的阶乘也不好求,规模还是太大了,那8的阶乘呢?以此类推,最后到1的阶乘,就很好办了,1的阶乘就是1,这就到了递归出口了,这个时候再倒回去,把10的阶乘求出来
代码实现:
#include <stdio.h>
int fac(int n);
int main() {
printf("%d",fac(5));// 大于等于15的阶乘会溢出
return 0;
}
int fac(int n) {
if (n <= 1) {// 递归出口
return 1;
}
return n * fac(n - 1);// 递推关系式
}
变量存储特性
局部变量
定义在函数体内部的变量(函数的形参也是局部变量),就是局部变量,每次调用函数局部变量都会被初始化,每次离开函数,局部变量就被销毁,回收空间。
局部变量的作用范围是从定义的位置开始到函数体结束。
全局变量
定义在函数体外部的变量,就是全局变量。
全局变量的作用范围是从定义的位置开始到本文件结束。
static
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
实例:
#include <stdio.h>
/* 函数声明 */
void func1(void);
static int count = 10; /* 全局变量 - static 是默认的 */
int main() {
while (count--) {
func1();
}
return 0;
}
void func1(void) {
/* 'thingy' 是 'func1' 的局部变量 - 只初始化一次
* 每次调用函数 'func1' 'thingy' 值不会被重置。
*/
static int thingy = 5;
thingy++;
printf(" thingy 为 %d , count 为 %d\n", thingy, count);
}
输出结果:
thingy 为 6 , count 为 9
thingy 为 7 , count 为 8
thingy 为 8 , count 为 7
thingy 为 9 , count 为 6
thingy 为 10 , count 为 5
thingy 为 11 , count 为 4
thingy 为 12 , count 为 3
thingy 为 13 , count 为 2
thingy 为 14 , count 为 1
thingy 为 15 , count 为 0
第六模块 指针的使用
考试大纲的要求
(1)理解指针的声明与初始化;
(2)理解指针与数组;
(3)理解字符串与指针。
笔记
指针
指针是学习 C 语言的另一个重点。C 语言的主体和核心,一个是函数,另一个是指针。
每一个变量都有一个内存位置,每一个内存位置都定义了 & 运算符访问的地址,它表示了在内存中的一个地址。而指针的本质就是地址。
printf %p可以直接输出地址(也就是指针)。
指针变量是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。就像使用其他变量或常量一样,必须在使用指针存储其他变量地址之前,对其进行声明。指针变量通常简称为指针。
语法:
type *var-name;
type 是指针的基类型,它必须是一个有效的 C 数据类型,var-name 是指针变量的名称。用来声明指针的星号 * 与乘法中使用的星号是相同的。但是,在这个语句中,星号是用来指定一个变量是指针。
int *ip; /* 一个整型的指针 */
double *dp; /* 一个 double 型的指针 */
float *fp; /* 一个浮点型的指针 */
char *ch; /* 一个字符型的指针 */
所有实际数据类型,不管是整型、浮点型、字符型,还是其他的数据类型(如:结构体类型),对应指针的值的类型都是一样的,都是一个代表内存地址的长的十六进制数(即:所有指针变量所占用的空间都是一个字节)。
不同数据类型的指针之间唯一的不同是,指针所指向的变量或常量的数据类型不同。
如何使用指针?
使用指针时会频繁进行以下几个操作:定义一个指针变量、把变量地址赋值给指针、访问指针变量中可用地址的值。这些是通过使用一元运算符 * 来返回位于操作数所指定地址的变量的值。下面的实例涉及到了这些操作:
#include <stdio.h>
int main() {
int var = 20; /* 实际变量的声明 */
int *ip; /* 指针变量的声明 */
ip = &var; /* 在指针变量中存储 var 的地址 */
printf("Address of var variable: %p\n", &var);
/* 在指针变量中存储的地址 */
printf("Address stored in ip variable: %p\n", ip);
/* 使用指针访问值 */
printf("Value of *ip variable: %d\n", *ip);
return 0;
}
实例执行结果:不同终端(计算机)输出的地址值可能不同
Address of var variable: 0x7fff7f351a94
Address stored in ip variable: 0x7fff7f351a94
Value of *ip variable: 20
C 中的 NULL 指针
在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
NULL 指针是一个定义在标准库中的值为零的常量。有点类似字符串的结束符。
指针变量相关运算和相关概念
| 概念 | 描述 |
|---|---|
| 指针的算术运算 | 可以对指针进行四种算术运算:++(指向下一个位置)、–(指向上一个位置)、+(往后移)、-(往前移) |
| 指针数组 | 可以定义用来存储指针的数组。 |
| 指向指针的指针(双重指针) | C 允许指向指针的指针。 |
| 传递指针给函数 | 通过引用或地址传递参数,使传递的参数在调用函数中可以被改变。 |
| 从函数返回指针 | C 允许函数返回指针到局部变量、静态变量和动态内存分配。 |
指针与数组
数组名就是地址常量(指针常量)。
字符串与字符指针
字符串通常是字符数组。
char name[] = "aaa";
字符指针通常是指向字符型变量的指针,但C语言还支持直接使用一个字符指针指向字符串。
char *str = "hello C language";
字符数组和指向字符串的字符指针的差别:
一句话:字符数组存放在全局数据区或栈区,可读可写。指向字符串的字符指针所指向的字符串存放在常量区,只读不能写。
char *str = "hello";
str[1] = 'a';// 错误,尝试修改常量
char *str2 = "world";
str = str2;// 正确,str是指针变量,可以修改指针变量的指向
char a[] = "hello world";
a[0] = 'b';// 正确,字符数组的元素可读可写
a = str2;// 错误,a为指针常量,不能修改指向的内存地址
第七模块 结构体
考试大纲的要求
(1)理解结构体变量;
(2)了解结构体数组;
(3)了解结构体与指针;
(4)了解链表的使用。
笔记
结构体
C 数组允许定义可存储相同类型数据项的变量,结构体是 C 编程中另一种用户自定义的可用的数据类型,它允许存储不同类型的数据项。
结构体用于表示一条记录,比如学生成绩,一条学生成绩信息需要包括:学生姓名(字符数组)、学号(整型),数学成绩(单精度或双精度浮点型),英语成绩(单精度或双精度浮点型),C语言成绩(单精度或双精度浮点型),总分(单精度或双精度浮点型),平均分(单精度或双精度浮点型)。
语法:定义结构体,必须使用 struct 关键字
struct tag {
member-list
member-list
member-list
...
} variable-list ;
tag 是结构体标识符(别名)。
member-list 是标准的变量定义,比如 int i; 或者 float f,或者其他有效的变量定义。
variable-list 结构变量,定义在结构的末尾,最后一个分号之前,您可以指定一个或多个结构变量。下面是声明 Score 结构的方式:
struct Score {
int stu_num;
char stu_name[10];
double math;
double english;
double c;
double avg;
double sum;
} someonedScore;
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。以下为实例:
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//同时又声明了结构体变量s1
//这个结构体并没有标明其标签
struct {
int a;
char b;
double c;
} s1;
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//结构体的标签被命名为SIMPLE,没有声明变量
struct SIMPLE {
int a;
char b;
double c;
};
//用SIMPLE标签的结构体,另外声明了变量t1、t2、t3(结构体指针)
struct SIMPLE t1, t2[20], *t3;
//也可以用typedef创建新类型,这个考纲没有要求,大概看看了解以下
typedef struct {
int a;
char b;
double c;
} Simple2;
//现在可以用Simple2作为类型声明新的结构体变量
Simple2 u1, u2[20], *u3;
如果两个结构体互相包含,则需要对其中一个结构体进行不完整声明,如下所示:
struct B; //对结构体B进行不完整声明
//结构体A中包含指向结构体B的指针
struct A {
struct B *partner;
//other members;
};
//结构体B中包含指向结构体A的指针,在A声明完后,B也随之进行声明
struct B {
struct A *partner;
//other members;
};
结构体变量的初始化:
#include <stdio.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book = {"C 语言", "RUNOOB", "编程语言", 123456};
int main() {
printf("title : %s\nauthor: %s\nsubject: %s\nbook_id: %d\n", book.title, book.author, book.subject, book.book_id);
}
访问结构体成员:
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; /* 声明 Book1,类型为 Books */
struct Books Book2; /* 声明 Book2,类型为 Books */
/* Book1 详述 */
strcpy(Book1.title, "C Programming");
strcpy(Book1.author, "Nuha Ali");
strcpy(Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* Book2 详述 */
strcpy(Book2.title, "Telecom Billing");
strcpy(Book2.author, "Zara Ali");
strcpy(Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 输出 Book1 信息 */
printf("Book 1 title : %s\n", Book1.title);
printf("Book 1 author : %s\n", Book1.author);
printf("Book 1 subject : %s\n", Book1.subject);
printf("Book 1 book_id : %d\n", Book1.book_id);
/* 输出 Book2 信息 */
printf("Book 2 title : %s\n", Book2.title);
printf("Book 2 author : %s\n", Book2.author);
printf("Book 2 subject : %s\n", Book2.subject);
printf("Book 2 book_id : %d\n", Book2.book_id);
return 0;
}
指向结构体的指针:
struct Books *struct_pointer;// 声明指针变量
struct_pointer = &Book1;// 初始化指针
struct_pointer->title;// 使用指向该结构的指针访问结构的成员
实例:
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* 函数声明 */
void printBook(struct Books *book);
int main() {
struct Books Book1; /* 声明 Book1,类型为 Books */
struct Books Book2; /* 声明 Book2,类型为 Books */
/* Book1 详述 */
strcpy(Book1.title, "C Programming");
strcpy(Book1.author, "Nuha Ali");
strcpy(Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* Book2 详述 */
strcpy(Book2.title, "Telecom Billing");
strcpy(Book2.author, "Zara Ali");
strcpy(Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 通过传 Book1 的地址来输出 Book1 信息 */
printBook(&Book1);
/* 通过传 Book2 的地址来输出 Book2 信息 */
printBook(&Book2);
return 0;
}
void printBook(struct Books *book) {
printf("Book title : %s\n", book->title);
printf("Book author : %s\n", book->author);
printf("Book subject : %s\n", book->subject);
printf("Book book_id : %d\n", book->book_id);
}
结构体数组:
本质上就是个数组,只不过数组中的元素变成了结构体变量,用法同数组一样,使用下标访问数组元素。
链表
链表是一种常见的基础数据结构,结构体指针在这里得到了充分的利用。链表可以动态的进行存储分配,也就是说,链表是一个功能极为强大的数组,他可以在节点中定义多种数据类型,还可以根据需要随意增添,删除,插入节点。链表都有一个头指针,一般以head来表示,存放的是一个地址。链表中的节点分为两类,头结点和一般节点,头结点是没有数据域的。链表中每个节点都分为两部分,一个数据域,一个是指针域。说到这里你应该就明白了,链表就如同车链子一样,head指向第一个元素:第一个元素又指向第二个元素;……,直到最后一个元素,该元素不再指向其它元素,它称为“表尾”,它的地址部分放一个“NULL”(表示“空地址”),链表到此结束。
实例:
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node *next;
} LinkList;
LinkList *creat(int n) { // 创建链表
LinkList *head, *node, *end;//定义头节点,普通节点,尾部节点;
head = (LinkList *) malloc(sizeof(LinkList));//分配地址
end = head; //若是空链表则头尾节点一样
int i = 0;
for (; i < n; i++) {
node = (LinkList *) malloc(sizeof(LinkList));
scanf("%d", &node->data);
end->next = node;
end = node;
}
end->next = NULL;//结束创建
return head;
}
void change(LinkList *list, int n) {//修改链表中第n个节点的值
LinkList *t = list;
int i = 0;
while (i < n && t != NULL) {
t = t->next;
i++;
}
if (t != NULL) {
puts("输入要修改的值");
scanf("%d", &t->data);
} else {
puts("节点不存在");
}
}
void delet(LinkList *list, int n) {//删除链表中第n个节点
LinkList *t = list, *in;
int i = 0;
while (i < n && t != NULL) {
in = t;
t = t->next;
i++;
}
if (t != NULL) {
in->next = t->next;
free(t);
} else {
puts("节点不存在");
}
}
void insert(LinkList *list, int n) {// 在链表中第n个节点之后插入一个节点
LinkList *t = list, *in;
int i = 0;
while (i < n && t != NULL) {
t = t->next;
i++;
}
if (t != NULL) {
in = (LinkList *) malloc(sizeof(LinkList));
puts("输入要插入的值");
scanf("%d", &in->data);
in->next = t->next;//填充in节点的指针域,也就是说把in的指针域指向t的下一个节点
t->next = in;//填充t节点的指针域,把t的指针域重新指向in
} else {
puts("节点不存在");
}
}
void print(LinkList *h) {// 输出链表
while (h->next != NULL) {
h = h->next;
printf("%d ", h->data);
}
puts("");
}
int main() {
puts("创建具有5个节点的链表");
LinkList *head = creat(5);// 创建具有5个节点的链表
puts("输出链表");
print(head);// 输出链表
puts("删除链表第3个节点");
delet(head,3);// 删除链表第3个节点
puts("输出删除链表第3个节点之后的链表");
print(head);// 输出删除链表第3个节点之后的链表
puts("在链表的第4个节点之后插入一个节点");
insert(head,4);// 在链表的第4个节点之后插入一个节点
puts("输出插入节点之后的链表");
print(head);// 输出插入节点之后的链表
puts("修改链表第2个节点的值");
change(head,2);// 修改第2个节点的值
puts("输出修改了第2个节点的值之后的链表");
print(head);// 输出修改了第2个节点的值之后的链表
return 0;
}
输出结果:
创建具有5个节点的链表
1 2 3 4 5
输出链表
1 2 3 4 5
删除链表第3个节点
输出删除链表第3个节点之后的链表
1 2 4 5
在链表的第4个节点之后插入一个节点
输入要插入的值
6
输出插入节点之后的链表
1 2 4 5 6
修改链表第2个节点的值
输入要修改的值
7
输出修改了第2个节点的值之后的链表
1 7 4 5 6