| 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
问题描述
使用 Flink 向 Hudi 表中写入数据,使用 Spark SQL 的 Shell 查询 Hudi 表(使用的是 Hudi HMS Catalog 统一管理和同步 Hudi 表的元数据),结果在 Spark 中只能查询到打开 Shell 之前表中的数据,之后通过 Flink 写入的数据不可见,但重新打开一个新的 Spark SQL Shell,就可以看到了。
原因分析
这个问题并不是一个 Bug, 在 Hudi 的 Issues 列表中有反馈和讨论:https://github.com/apache/hudi/issues/7452,简单说就是:Spark SQL 的 Shell 所启动的 Session 会 cache 一些表和文件的元数据,在只通过 Spark SQL 这一个“渠道”操作 Hudi 表时是不会有问题的,但这里 Flink 对 Hudi 表的操作完全不在 Spark SQL 的“感知”范围内,Spark SQL 会继续使用自己 Cache 中已经过期的元数据数据,所以没有及时反映出 Flink 对 Hudi 表数据的更改。
解决方法
有两种方法可以“修正”这个问题:
-
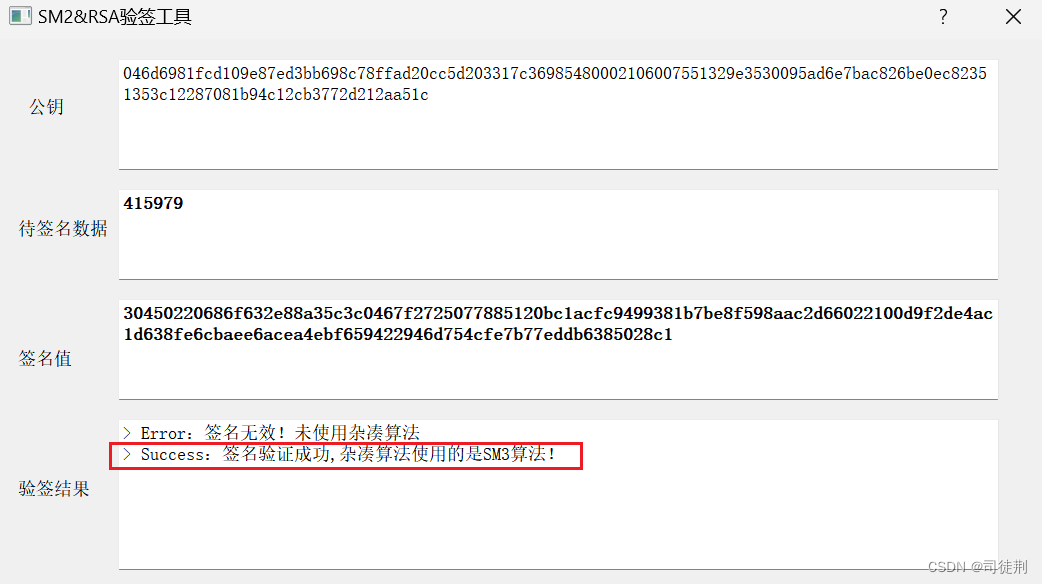
显式地执行一次 refresh table 操作 ,但这个方法不态实用,除非我们在编写 SQL 时能确定应在何时 refresh。下图是一个测试:

-
显式地设置
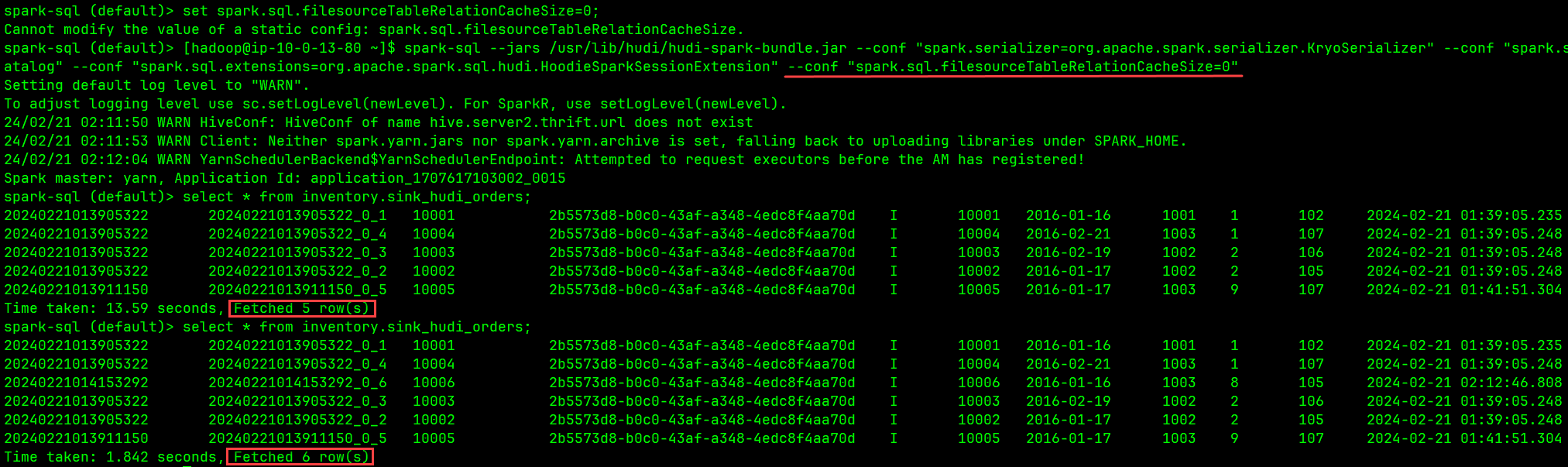
spark.sql.filesourceTableRelationCacheSize=0,禁止 Spark 缓存相关的元数据,这个是持续生效的,但需要提醒的是该配置项为静态配置,不能在 SQL 中用 set 语句设置,只能在启动 Spark SQL Shell 时通过--conf参数配置,就像这样:spark-sql --jars /usr/lib/hudi/hudi-spark-bundle.jar \ --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sqlatalog" \ --conf "spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension" \ --conf "spark.sql.filesourceTableRelationCacheSize=0"下图是一个测试:

![[论文阅读] 空间熵图像增强算法(Spatial Entropybased Contrast Enhancement in DCT)](https://img-blog.csdnimg.cn/direct/14c9418f39f94db4a516afb528790393.png)




![洛谷 P1028 [NOIP2001 普及组] 数的计算](https://img-blog.csdnimg.cn/direct/6694d515c8194bfab3b6322f90adefed.png)