DBSCAN密度聚类介绍 样本点 样本集合 半径 邻域 核心对象 边界点 密度直达 密度可达 密度相连
- 简介
- 概念定义
- 原理
- DBSCAN的优点
- DBSCAN的缺点
- 小尝试
- 制作不易,感谢三连,谢谢啦
简介
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法,用于将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。该算法将簇定义为密度相连的点的最大集合,利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。
概念定义
-
xi:为每一个样本点

-
D:样本集合,包含所有样本点

-
半径:以样本点为中心画圆的半径
-
邻域:对于给定的对象,其ε-邻域是指与该对象距离不超过ε的所有对象的集合。
-
核心对象:如果一个对象的邻域(通常称为ε-邻域)内至少有MinPts个对象(包括该对象本身),则该对象被称为核心对象。

-
密度直达:样对于样本集合D中的两个点p和q,如果存在一个点的序列p1, p2, …, pn,其中p1 = p, pn = q,并且对于序列中的任意点pi (1 ≤ i < n),pi+1都是从pi密度可达的,那么我们说点q是从点p密度可达的。
-
密度可达:如果你可以从点p通过一系列的核心对象到达点q(即沿着由核心对象组成的路径走),那么点q就是从点p密度可达的。这种关系并不是对称的,也就是说,即使q从p密度可达,也不意味着p从q密度可达。
-
密度相连在DBSCAN中,如果点q从点p密度可达,并且点s也从点p密度可达,那么点q和点s就被认为是密度相连的。这种关系是对称的,即如果q和s是密度相连的,那么s和q也是密度相连的。
原理
- 首先,选择一个核心对象。然后对核心点的邻域内的每个点进行评估,以确定它是否在邻域内有n个对象。如果该点满足标准,它将成为另一个核心点,集群将扩展。如果一个点不满足标准,它成为边界点。随着过程的继续,算法开始发展成为核心点“a”是“b”的邻居,而“b”又是“c”的邻居,以此类推。当集群被边界点包围时,这个聚类簇已经搜索完全,因为在距离内没有更多的点。选择一个新的随机点,并重复该过程以识别下一个簇。
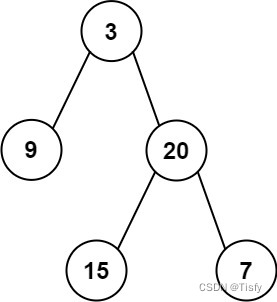
- 他就和我们遍历二叉树或者N叉树一样,把所有的点都进行深度遍历,把符合要求的点添加到当前的簇内,找不到新的边界点就去接着遍历整个点集合D。
DBSCAN的优点
- 不需要像KMeans那样预先确定集群的数量
- 对异常值不敏感
- 能将高密度数据分离成小集群
- 可以聚类非线性关系(聚类为任意形状)
DBSCAN的缺点
- 很难在不同密度的数据中识别集群
- 难以聚类高维数据
- 对极小点的参数非常敏感
小尝试
from sklearn.cluster import DBSCAN
import numpy as np
# 输入数据
X = np.array([(1,1), (1,2), (2,1), (8,8), (8,9), (9,8), (15,15)])
# 创建DBSCAN对象,设置半径和最小样本数
dbscan = DBSCAN(eps=2, min_samples=3)
# 进行聚类
labels = dbscan.fit_predict(X)
# 输出聚类结果
for i in range(max(labels)+1):
print(f"Cluster {i+1}: {list(X[labels==i])}")
print(f"Noise: {list(X[labels==-1])}")
- 结果为
Cluster 1: [array([1, 1]), array([1, 2]), array([2, 1])]
Cluster 2: [array([8, 8]), array([8, 9]), array([9, 8])]
Noise: [array([15, 15])]
- 其中聚集为两个簇Cluster 1和Cluster 2和一个干扰点