近年来,在独立分布假设的前提下,机器学习模型的表现越来越好。但在实际应用场景中,数据本身却具有很强的异质性和差异性,这就对模型的泛化能力产生了较高的要求。为了解决分布外泛化问题,稳定学习应运而生。12月28日,智源《稳定学习年度研究进展》系列报告在线上展开,本次报告邀请了崔鹏、禹含、林勇、何玥、刘家硕、张奇、陈瀚雄、王啸、张兴璇9位学者,就稳定学习(Stable Learning)这个话题,给出了精彩的报告。
(整理/牛梦琳)

本期是一年一度的《稳定学习年度研究进展》系列报告,由清华大学崔鹏教授主持。崔鹏首先介绍了本次报告的背景并总结了2022年一年来学者们在稳定学习方向整体的思考,由清华和香港科技大学的四位博士生给出了相关方法论的研究进展,来自复旦,meta,北航和清华的四位学者则是聚焦稳定学习在NLP,Graph,RS,CV方向的前沿应用工作,对年度工作进展做出了总结。智源社区将公开部分精华内容整理如下:
关于分布外泛化和稳定学习的一些思考
清华大学教授 崔鹏
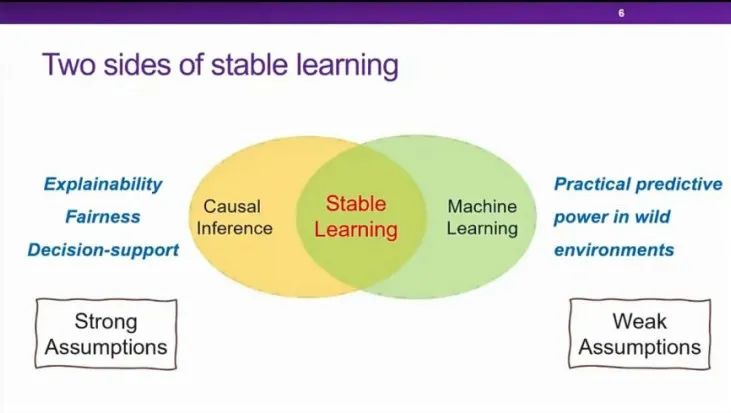
稳定学习针对的是机器学习的基础问题——Out of Distribution(OOD,分布外泛化)问题。在机器学期的基本范式中,存在基本的独立性假设,即Ptest=Ptrain,但在实际应用中,这个假设很难得到保证,此时就会产生OOD问题。OOD问题可以分为Ptest部分已知和Ptest完全未知两种情况,在真实开放的场景应用中,大部分似乎Ptest都是完全未知的。
为了解决这个问题,稳定学习将原本基于假设的Data Fitting 思路,转变为了Finding Invariance (寻找不变性)思路,来寻找不随环境数据变化的最稳定的结构。目前,稳定学习的大致研究路径有两条:一条是找到比不变性更强的结构来保证不变性:根据Peter Bühlmann提出的统计学方式图,很多人认为从统计的角度讲,Causal是最本质的一种结构,如果将Causal的思想融入机器学习的研究,是否可以解决部分机器学习的稳定性问题。
沿着这个思路,学者们从17年开始研究Machine Learning和Causal Inference之间的交叉关系,稳定学习就是在机器学习的框架下,注入一些Causal Inference的底层思想。今年,崔鹏教授和斯坦福大学的教授Susan Athey一起发表了《Stable learning establishes some common ground between causal inference and machine learning》,对稳定学习的提出和思路做了一个总结性的描述。另一条路径是从变化中寻找不变性(Finding invariance from variance),即根据数据中的异质性寻找数据的不变性。
2022年,学者们对稳定学习有了一些新的思考。比如关于稳定学习的定位问题:稳定学习应该针对OOD问题,输入单独的训练分布,应用多种测试分布,并以稳定性表现为优化目标。由此,很多课题组正在试图解决一些开放性问题,
最后,针对稳定学习的一些外延问题,崔鹏分享了两个观点:
一、无论是大模型还是OOD Generalization的学习机制,都是为了更好地解决真实、开放环境下的实际问题所探索出的技术路径,二者并不冲突;在OOD Generalization学习机制基础上引入超大规模参数和训练数据,是解决大模型偏见、进一步提升模型智能水平的可能路径之一。
二、关于决策和预测问题,决策的效果取决于预测的准确性,决策的本质是分布外可泛化的预测模型。
稀疏约束下的稳定学习方法
清华大学计算机系博士生 禹含
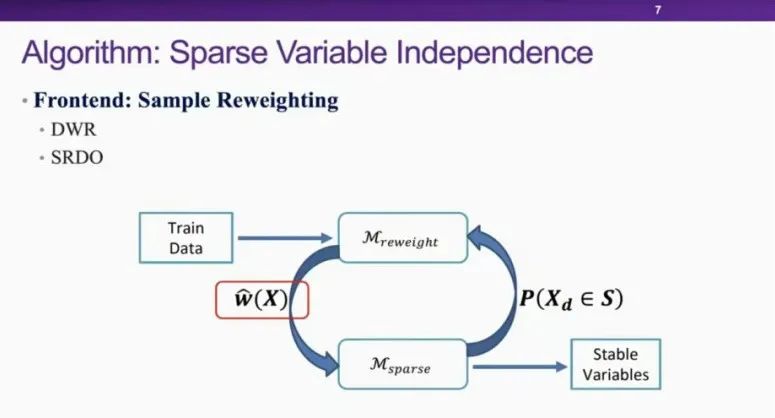
本报告主要围绕着如何利用稀疏约束实现一个更好的稳定学习。禹含的目标问题是Covariate-Shift Generalization问题。他首先讲解了相关的稳定学习背景知识,给出了Minimal Stable Variable Set和Weighting function的定义,并将问题转化为寻找Minimal Stable Variable Set,理论上,如果能找到使得Covariates完美互相独立的Weighting function,就可以选出Minimal Stable Variable Set。但在实际应用中,完美独立的情况并不容易达到。为了放松完美独立性的要求,禹含小组引入了稀疏约束(Sparsity constraint)。
随后禹含介绍了他们的算法Sparse Variable Independence。这个算法可以记为SVI,大致分为前端和后端两个模块,前端通过DWR,SRDO算法完成Sample Reweighting的工作,后端通过STG算法,主要负责Sparsity Learning。前端向后端输出Weighting function,后端则将数据属于Minimal Stable Variable Set的概率反馈给前端。通过前后端的迭代,来促使前端做更好的Sample Reweighting。为了说明他们的方法,禹含展示了他们在模拟和现实数据两个方面进行的实验,实验结果显示,无论是在线性还是非线性情况下,SVI的效果都是最好的,并且,样本量对SVI的影响也远远小于对其他算法的影响。他们的现实数据实验是关于房价预测和收入的预测,也都进一步证实了SVI算法的有效性。
一种针对分布偏移鲁棒的
通用样本加权方法
香港科技大学博士生 林勇

林勇介绍的方法可以简称为MAPLE,这种方法比较通用,可以随意替换模型,而加权的方法始终有效。他们讨论的问题主要也是OOD问题,比如区分奶牛和骆驼,传统机器学习方法往往比较依赖背景,而当背景出现混淆时,会出现很多虚假特征(spurious feature),模型就很难进行区分了。
为了解决这个问题,林勇的团队提出了MAPLE方法。他首先抛出了一个有意思的观测结果:应该存在一种样本加权使得模型输出Y不受虚假特征的影响。随后他给出了一个通用的数学证明,说明在理论上,只要给每个样本一个合适的加权,就能使得Y完全独立于虚假特征。为了以较低的代价找到这个加权方法,他们利用了深度学习中Invariant Risk Minimization(IRM)和Distributional Robust Optimization(DRO)的方法。首先他们将数据分成训练集和验证集,然后将优化模型分为两层,内层利用训练集找出比较好的sample reweighting模型并进行优化,外层利用验证集判断内层的模型是否用到了虚假特征。他们的方法在图像数据集(如CMNIST)上得到了较好的验证。
MAPLE方法可以很好地应用于深度学习模型,解决了IRM和DRO在大模型中效果显著变差的问题,而且对prior knowledge的要求也很低,虽然会有额外的计算开销,但总体是一种通用的样本加权方法。
通过随机样本加权实现协变量偏移泛化
清华大学计算机系博士生 何玥

何玥报告的方法希望通过引入随机性来解决模型的泛化性的问题。他首先介绍了问题背景,然后解释了什么事协变量偏移泛化以及他们的研究方法,最后给出了相应的实验结果。由于真实数据的异质性和不确定性要求机器模型具有泛化能力,而传统的机器学习模型对训练分布和测试分布独立同分布的假设具有很强的依赖性,而这个假设并不适用于许多现实应用场景,所以就产生了OOD问题。
为了解决这个问题,何玥的工作聚焦于协变量偏移泛化问题。协变量偏移问题认为,测试分布与训练分布的变化仅体现在协变量偏移上,在这样的假设下,理论上人们就可以利用其中的不变性来实现模型在分布变化时的稳定表现。当然,由于真实案例的复杂性,考虑到模型的计算代价,搭建代价等,模型错估几乎是不能避免的。而模型错估和协变量偏移问题,就有可能导致模型在有限的训练集中学到虚假特征。
何玥的团队给出了不变变量集合的定义,并尝试建立基于不变变量集合的稳定预测模型。他们通过重要性样本加权的方法,定义随机加权分布族,通过实验,他们发现,在一定的假设下,不变变量在分布族中的稳定性要好于变化变量。然后他们引入不变性约束来寻找这些不变变量。而在实际应用中,他们提出了RSW的算法,在每一步迭代时,都随机采样部分加权分布,并进行单步优化。通过这样迭代的方式完成学习。他们的方法计算较简单,复杂度低,比较通用,并在模拟实验和实际应用中,表现出了较好的稳定性。
异质数据下的模型分布稳定性保证
清华大学计算机系博士生 刘家硕

刘家硕的报告也是聚焦于OOD问题,现实中的数据很难有环境标签,在这种情况下,他们希望探索分析模型分布稳定性的理论性框架。他们的问题定位在能否从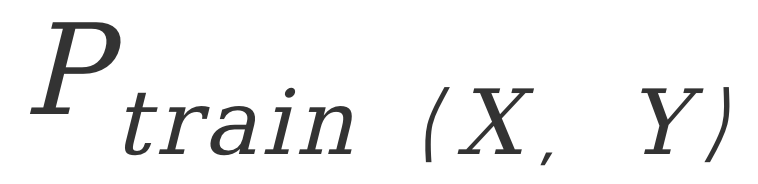 泛化到未知的
泛化到未知的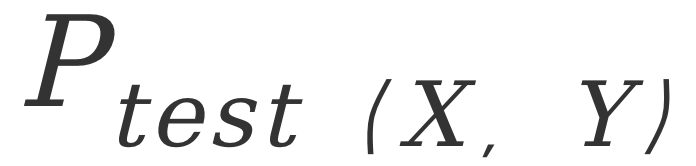 ,以及能多大程度地泛化。经验上,可以通过简单的加权方法,或者学习一些比较好的环境来支撑不变学习,以及分布鲁棒优化方法,但是这些方法都存在难以忽视的问题。所以,本次报告的重点在于,如何仅利用训练数据来刻画泛化能力,以及如何度量这种泛化能力。
,以及能多大程度地泛化。经验上,可以通过简单的加权方法,或者学习一些比较好的环境来支撑不变学习,以及分布鲁棒优化方法,但是这些方法都存在难以忽视的问题。所以,本次报告的重点在于,如何仅利用训练数据来刻画泛化能力,以及如何度量这种泛化能力。
为了介绍分布稳定性的定义,刘家硕首先给出了子群体的概念,然后通过找到与 分布在预测机制方面差异最大的子群体来定义分布稳定性,给出了相应的量化标准,并证明了分布稳定性在一定的特殊条件下与严格的不变性等价。但是当
分布在预测机制方面差异最大的子群体来定义分布稳定性,给出了相应的量化标准,并证明了分布稳定性在一定的特殊条件下与严格的不变性等价。但是当 任意可变时,刘家硕认为问题是不可解的,因此要给
任意可变时,刘家硕认为问题是不可解的,因此要给 一个基于Expansion Function的假设。在设计算法时,他们将分布稳定性的指标加入到了目标函数中,然后估计和优化这个指标。他们的实验结果显示,通过控制他们的指标,可以得到较好的测试准确性,且他们的方法优于DRO的方法。
一个基于Expansion Function的假设。在设计算法时,他们将分布稳定性的指标加入到了目标函数中,然后估计和优化这个指标。他们的实验结果显示,通过控制他们的指标,可以得到较好的测试准确性,且他们的方法优于DRO的方法。
NLP模型虚假相关性研究
复旦大学计算科学技术学院教授 张奇
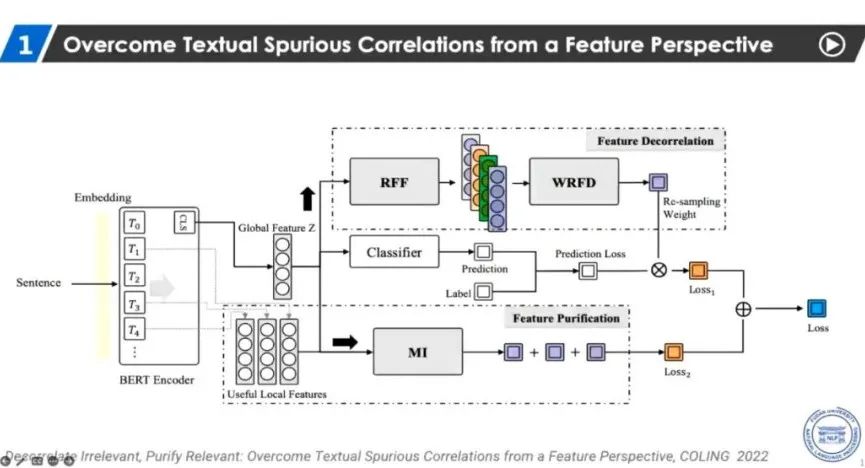
张奇的报告主要从应用的角度进行了讨论。他主要介绍了在NLP领域关于虚假相关性的两篇论文。目前,各类自然语言处理算法快速发展,在很多任务上甚至超越了人类。但是这些算法在实际应用中的效果却不尽如人意。他们也用归因方法对线上的一些模型做了可视化分析,并且发现数据集合中的偏差可能会引起模型学习到虚假的观点。数据集的偏差广泛存在于NLU任务当中,如否定线索、词汇重叠等。
张奇从《WINOGRANDE:An Adversarial Winograd Schema Challenge at Scale》(2020 AAAI best classic paper)这项工作开始关注数据集中的偏差问题,这项工作侧重于背景知识的分类问题,并且通过实验发现,对数据不做任何处理时,模型的识别效果非常好,但对数据进行偏置消除(Debias)处理之后,模型但识别能力就会降低。
目前NLP领域的偏置消除方法通常采用二阶段方法,张奇也希望能够引进例如前面报告中所提到的一些新的方法进行研究。2022年,他们尝试了从特征角度进行偏置消除。首先,他们工作的大致思路是首先去除特征的相关性,然后对特征进行提纯,以保证与任务相关的特征能够保留下来。他们的实验结果显示出了与原始的BERT-base相比较好的提升。他们的第二项工作则采用了另一种方式,首先,假设在选取特征的过程中尽量保留所有的特征;但对特征的分布进行变化,从而消除相关性。在这种变化下,之前的工作可以得到较大的提升。
Causal Factorization Machine
for Robust Recommendation
Meta研究员 陈瀚雄

陈瀚雄的工作主要是为了提升推荐模型Factorization Machine(FMs)的稳定性,使模型在训练集和测试机分布不一致的情况下也能够提供比较有效的推荐结果。一些研究表明,模型利用causal feature进行决策时,决策结果往往比较稳定,这是由于causal feature本身具有一定的稳定性。因此陈瀚雄等人选择了causal feature来帮助模型提高稳定性。并且在应用场景下,他们选取的是个性化的causal feature,以此来满足不同用户对于推荐的需求。
随后,陈瀚雄简单介绍了FMs模型,并给出了选取Causal Feature的数学方法,最后展示了他们的方法最终的Loss函数。
他们的实验使用了RentTheRunWay、Post和MovieLens三种数据集,FM模型则使用了DeepFM、FNFM和AFM几种经典的FMs模型。以N@K和H@K为推荐指标,并使用drop rate衡量模型的稳健性。实验结果表明,在各指标上都是他们的模型表现较好,并且在选择causal feature时引入个性化,也可以提升模型的推荐性能,并且保证模型的稳定性。
图神经网络的分布外泛化初探
北京航空航天大学副教授 王啸
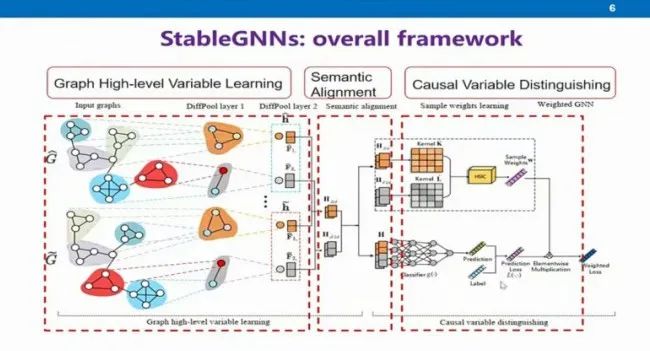
王啸的工作继承了稳定学习的思想,将稳定学习的技术与图神经网络进行结合,来解决图数据的分布外泛化问题。真实场景中有很多图的数据,不同数据上又存在很多不同类型的应用。网络数据需要有好的表示,随着深度学习的发展,图神经网络应运而生。图神经网络的基本思想,是在图的拓扑结构上,对节点信息进行传播和聚合。图神经网络也需要假设训练集与测试集同分布,这就导致模型有可能学习到虚假的相关性,于是引出了图上的OOD问题。
王啸的工作主要考虑解决两个问题:
一、如何学习到高层的子图级别的表示;
二,如何区分这些表示与标签的相关性。
他们采取Diffpool的思路,通过类似pooling的形式学习到不同子图级别的高层语义表示。然后进一步证明了在这种学习下,每张图的语义表示是可以对齐的。接下来他们引入了稳定学习Sample Reweighting的思想,对每个图进行加权,并将这个权重添加到训练的损失函数中进行训练,这个权重就可以用来去除不同高层语义之间的相关性。最后使用去除了相关性的高层语义进行预测。
他们分别对生成的数据集和分子数据集进行了实验。将他们的模型与现有的其他模型结合之后,他们发现,在不同的Correlation degree下,模型的性能都会有一定的提升。并且相关性越大,提升空间越大。这就表明现有的模型很可能学习到了虚假相关性。王啸等人也利用分子数据集做了可视化的解释,并且对图的节点级别的分布外泛化问题也进行了一定的探索。
NICO竞赛2022
大规模分布外泛化图像识别
清华大学计算机系博士生 张兴璇
张兴璇的报告主要介绍了今年举办的NICO竞赛的情况,包括竞赛的设计以及参赛情况。他们观测到,在计算机视觉领域,很多针对OOD问题的benchmark本身是具有局限性的,人们希望训练好的深度模型在任意的测试集上都能有较好的表现,但由于已有OOD数据集的局限性,或者benchmark在设计时的局限性,现有的benchmark无法真正全面地实现这一目标。所以张兴璇等人提出了一种新的benchmark的方式,希望能够在多个测试集上测试现有的方法,来实现真正的对于OOD问题的解决方案。
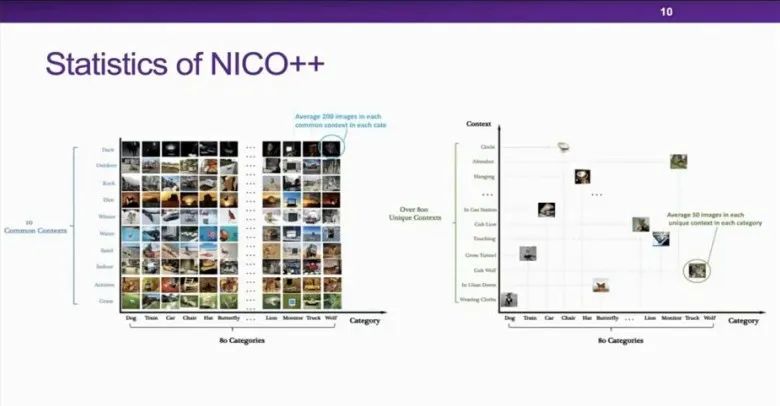
竞赛是基于今年新提出的NiCO++数据集。这是一个针对视觉领域OOD问题设计的数据集,他们引入了环境(Contexts)的概念,并要求环境具有物理意义,比如图片的背景、识别物体的形态、颜色等;NICO++还引入了common context和unique context的概念,使得NICO++数据集的适用性更为广泛。他们还从covariate shift和concept shift的角度提出了对OOD数据集的评估方式。经过比较NICO/NICO++和现有的其他OOD数据集,可以发现NICO/NICO++在各方面表现都更有优势。
基于NICO++,张兴璇等人举办了NICO Challenge竞赛。竞赛依附于ECCV2022 workshop,分为Common Context Generalization和Hybrid Context Generalization两个track,提供了大量的训练数据和测试数据,并给出了一份OOD的指导帮助参赛者快速入门。竞赛共有178个队伍参加,并拥有超过4000份结果提交。目前,他们的团队仍在完善NICO++,NICO Challenge2023预计将于2023年3月份举办。
总结
在互动环节,崔鹏针对线上观众对讲解内容中样本重加权以及变量独立问题的提问展开了讲解,并重点解释了稳定学习实现的路径以及与Casual Inference的关系。最后,崔鹏做了活动总结。他认为本次活动中各位优秀的讲者对稳定学习的方法和应用给出了完整且详细的介绍,观众们也给出了非常有启发性的反馈。
更多内容 尽在智源社区