文章目录
- 1. Lambda 表达式
- 为什么使用 Lambda 表达式
- 从匿名类到 Lambda 的转换
- Lambda 表达式语法
- 语法格式一:无参,无返回值,Lambda 体只需一条语句
- 语法格式二:Lambda 需要一个参数
- 语法格式三:Lambda 只需要一个参数时,参数的小括号可以省略
- 语法格式四:Lambda 需要两个参数,并且有返回值
- 语法格式五:当 Lambda 体只有一条语句时,return 与大括号可以省略
- 语法格式六:多条语句
- 2. 函数式接口
- 什么是函数式接口
- 自定义函数式接口
- 常用的函数式接口
- 1. 消费式Consumer<T>
- 2. 功能式Function<T, R>
- 3.预测Predicate<T>
- 4.供给/提供Supplier<T>
- 3. 方法引用与构造器引用
- 方法引用
- 构造器引用
- 数组引用
- 4. Stream API
- 什么是 Stream
- Stream 的操作三个步骤
- - 创建 Stream
- - 中间操作
- - 终止操作(终端操作)
- 创建 Stream
- 由数组创建流
- 由值创建流
- 由函数创建流:创建无限流
- Stream 的中间操作
- 筛选与切片
- filter(Predicate p)
- distinct()
- limit(long maxSize)
- skip(long n)
- 映射
- map(Function f)
- mapToDouble(ToDoubleFunction f)
- mapToInt(ToIntFunction f)
- mapToLong(ToLongFunction f)
- flatMap(Function f)
- 排序
- Stream 的终止操作
- 查找与匹配
- allMatch(Predicate p) 检查是否匹配所有元素
- anyMatch(Predicate p) 检查是否至少匹配一个元素
- noneMatch(Predicate p) 检查是否没有匹配所有元素
- findFirst() 返回第一个元素终端操作会从流的流水线生成结果。
- findAny() 返回当前流中的任意元素
- 归约
- count() |返回流中元素总数
- max(Comparator c) 返回流中最大值
- min(Comparator c)返回流中最小值
- forEach(Consumer c) 内部迭代
- reduce(T iden, BinaryOperator b) 可以将流中元素反复结合起来,得到一个值。返回 T
- 收集
- 1、toList
- 2、toMap
- 3、toSet
- 4、counting
- 5、summingInt
- 6、minBy
- 7、joining
- 8、groupingBy
- 1.orElse(null)
- 2.orElseGet(null)
- orElse(null)和orElseGet(null)区别:
- 并行流和串行流
- 5. 新时间日期 API
- 使用 LocalDate、LocalTime、LocalDateTime
- 6. java8其他新特性
1. Lambda 表达式
为什么使用 Lambda 表达式
Lambda 是一个匿名函数,我们可以把 Lambda 表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。可以写出更简洁、更 灵活的代码。作为一种更紧凑的代码风格,使 Java的语言表达能力得到了提升。
从匿名类到 Lambda 的转换
//原来的匿名内部类
@Test
public void test1(){
Comparator<String> com = new Comparator<String>(){
@Override
public int compare(String o1, String o2) {
return Integer.compare(o1.length(), o2.length());
}
};
TreeSet<String> ts = new TreeSet<>(com);
TreeSet<String> ts2 = new TreeSet<>(new Comparator<String>(){
@Override
public int compare(String o1, String o2) {
return Integer.compare(o1.length(), o2.length());
}
});
}
//现在的 Lambda 表达式
@Test
public void test2(){
Comparator<String> com = (x, y) -> Integer.compare(x.length(), y.length());
TreeSet<String> ts = new TreeSet<>(com);
}
List<Employee> emps = Arrays.asList(
new Employee(101, "张三", 18, 9999.99),
new Employee(102, "李四", 59, 6666.66),
new Employee(103, "王五", 28, 3333.33),
new Employee(104, "赵六", 8, 7777.77),
new Employee(105, "田七", 38, 5555.55)
);
Lambda 表达式语法
Lambda 表达式在Java 语言中引入了一个新的语法元
素和操作符。这个操作符为 “->” , 该操作符被称
为 Lambda 操作符或剪头操作符。它将 Lambda 分为
两个部分:
左侧:指定了 Lambda 表达式需要的所有参数
右侧:指定了 Lambda 体,即 Lambda 表达式要执行
的功能。
语法格式一:无参,无返回值,Lambda 体只需一条语句
// 语法格式一:无参数,无返回值
@Test
public void test1(){
int num = 0;
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("Hello World!" + num);
}
};
r.run();
System.out.println("-------------------------------");
Runnable r1 = () -> System.out.println("Hello Lambda!");
r1.run();
}
语法格式二:Lambda 需要一个参数
Consumer<String> con = (x) -> System.out.println(x);
语法格式三:Lambda 只需要一个参数时,参数的小括号可以省略
Consumer<String> con = x -> System.out.println(x);
语法格式四:Lambda 需要两个参数,并且有返回值
Comparator<Integer> com = (x, y) -> {
System.out.println("函数式接口");
return Integer.compare(x, y);
}
语法格式五:当 Lambda 体只有一条语句时,return 与大括号可以省略
Consumer<String> con = (x,y) -> x + y;
语法格式六:多条语句
Comparator<Integer> com = (x, y) -> {
System.out.println("函数式接口");
return Integer.compare(x, y);
}
2. 函数式接口
什么是函数式接口
- 只包含一个抽象方法的接口,称为函数式接口。
- 你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda
表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方
法上进行声明)。 - 我们可以在任意函数式接口上使用 @FunctionalInterface 注解,
这样做可以检查它是否是一个函数式接口,同时 javadoc 也会包
含一条声明,说明这个接口是一个函数式接口。
自定义函数式接口
@FunctionalInterface
public interface MyNumberf{
public double getValue();
}
//函数式接口中使用泛型:
public interface MyFunc<T>{
public T getValue(T t);
}
@FunctionalInterface
public interface MyFunction {
int apply(int x, int y);
}
MyFunction add = (x, y) -> x + y;
int result = add.apply(5, 3);
System.out.println(result); // 输出8
MyFunction multiply = (x, y) -> x * y;
result = multiply.apply(5, 3);
System.out.println(result); // 输出15
常用的函数式接口
1. 消费式Consumer
- 源码解析
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*/
void accept(T t);
/**
* andThen()方法用于将两个Consumer对象串联起来,实现多个操作的
* 连续执行。该方法的语法格式为consumer1.andThen(consumer2),
* 其中consumer1和consumer2分别为两个Consumer对象。
*
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
- 使用实例
Consumer<String> consumer1 = s -> System.out.println("consumer1: " + s);
Consumer<String> consumer2 = s -> System.out.println("consumer2: " + s);
Consumer<String> consumer3 = consumer1.andThen(consumer2);
consumer3.accept("hello world");
输出:
consumer1: hello world
consumer2: hello world
2. 功能式Function<T, R>
- 源码解析
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*/
R apply(T t);
/**
* compose()方法用于将两个Function对象串联起来,实现多个操作
* 的连续执行,并返回一个新的Function对象。该方法的语法格式为
* function1.compose(function2),其中function1和function2分别
* 为两个Function对象。
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* andThen()方法与compose()方法类似,但它先执行当前Function对象
* 的操作,再执行参数Function对象的操作,并返回一个新的
* Function对象。该方法的语法格式为function1.andThen(function2)
* ,其中function1和function2分别为两个Function对象。
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* identity()方法是一个静态方法,返回一个恒等函数,即输入参数和
* 输出结果都相同的函数。该方法的语法格式为Function.identity()
*/
static <T> Function<T, T> identity() {
return t -> t;
}
}
- 使用实例
Function<Integer, Integer> function1 = x -> x + 1;
Function<Integer, Integer> function2 = x -> x * 2;
Function<Integer, Integer> function3 = function1.compose(function2);
int result3 = function3.apply(5);
System.out.println(result3); // 输出11
Function<Integer, Integer> function4 = function1.andThen(function2);
int result4 = function4.apply(5);
System.out.println(result4); // 输出12
Function<String, String> function = Function.identity();
String str = function.apply("hello");
System.out.println(str); // 输出hello
输出:
11
12
hello
3.预测Predicate
- 源码解析
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*/
boolean test(T t);
/**
* and()方法用于将两个Predicate对象组合起来,并返回一个新的Predicate对象,
* 实现多个条件的同时满足。该方法的语法格式为predicate1.and(predicate2),
* 其中predicate1和predicate2分别为两个Predicate对象。
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
/**
* negate()方法用于对Predicate对象进行取反操作,并返回一个新的Predicate对象。
* 该方法的语法格式为predicate.negate(),其中predicate为原始的Predicate对象
*/
default Predicate<T> negate() {
return (t) -> !test(t);
}
/**
* or()方法与and()方法类似,但它实现多个条件的任意一个满足即可。该方法的语法格式为predicate1.or(predicate2),
* 其中predicate1和predicate2分别为两个Predicate对象。
*/
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
/**
*
*/
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
- 使用实例
Predicate<String> predicate1 = s -> s.startsWith("hello");
Predicate<String> predicate2 = s -> s.endsWith("world");
Predicate<String> predicate3 = predicate1.and(predicate2);
boolean result3 = predicate3.test("hello world");
System.out.println(result3); // 输出true
Predicate<String> predicate4 = predicate1.or(predicate2);
boolean result4 = predicate4.test("hello world");
System.out.println(result4); // 输出false
Predicate<String> negatedPredicate = predicate1.negate();
boolean result = negatedPredicate.test("hello world");
System.out.println(result); // 输出false
Predicate<String> predicate = Predicate.isEqual("hello world");
boolean result1 = predicate.test("hello world");
boolean result2 = predicate.test("hello java");
System.out.println(result1); // 输出true
System.out.println(result2); // 输出false
4.供给/提供Supplier
- 源码解析
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
* @return a result
*/
T get();
}
- 使用实例
Supplier<Double> supplier = Math::random;
double value = supplier.get();
3. 方法引用与构造器引用
方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致!)方法引用:使用操作符“::”
将方法名和对象或类的名字分隔开来。 如下三种主要使用情况:
- 对象::实例方法
- 类::静态方法
- 类::实例方法
(x) -> System.out.println(x);
//等同于
System::println;
构造器引用
格式: ClassName::new
与函数式接口相结合,自动与函数式接口中方法兼容。
可以把构造器引用赋值给定义的方法,与构造器参数
列表要与接口中抽象方法的参数列表一致!
Function<Integer,MyClass> func = (n) -> new MyClass(n);
//等同于
Function<Integer,MyClass> func1 = MyClass::new;
数组引用
格式: type[] :: new
Function<Integer,Integer[]> func = (n) -> new Integer[n];
Function<Integer,Integer[]> func = Integer[]::new;
4. Stream API
Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一
个则是 Stream API(java.util.stream.*)。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对
集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。
使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数
据库查询。也可以使用 Stream API 来并行执行操作。简而言之,
Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是 Stream
流(Stream) 到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
“集合讲的是数据,流讲的是计算
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream 的操作三个步骤
- 创建 Stream
一个数据源(如:集合、数组),获取一个流
- 中间操作
一个中间操作链,对数据源的数据进行处理
- 终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果
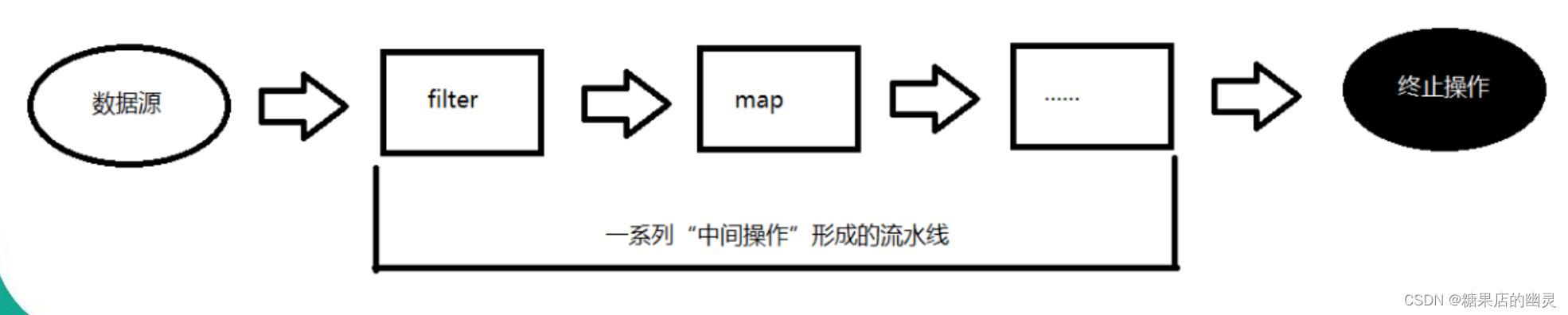
创建 Stream
- default Stream stream() : 返回一个顺序流
- default Stream parallelStream() : 返回一个并行流
由数组创建流
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
static Stream stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
由值创建流
可以使用静态方法 Stream.of(), 通过显示值创建一个流。它可以接收任意数量的参数。
public static<T> Stream<T> of(T... values) //: 返回一个流
由函数创建流:创建无限流
可以使用静态方法 Stream.iterate() 和Stream.generate(), 创建无限流。
- 迭代
public static Stream iterate(final T seed, final
UnaryOperator f)- 生成
public static Stream generate(Supplier s) :
Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水 线上触发终止操作,否则中间操作不会执行任何的处理!
而在终止操作时一次性全部处理,称为“惰性求值”。
筛选与切片
| 方法 | 描述 |
|---|---|
| filter(Predicate p) | 接收 Lambda , 从流中排除某些元素。 |
| distinct() | 筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量。 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n)互补 |
filter(Predicate p)
distinct()
limit(long maxSize)
skip(long n)
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.Setter;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
public class TestFort {
public static void main(String[] args) {
List<User> userList = getUserList();
System.out.println(userList);
System.out.println("=======================filter=========================");
//1、filter:输出ID大于6的user对象
List<User> filetrUserList = userList.stream().filter(user -> user.getId() > 6).collect(Collectors.toList());
filetrUserList.forEach(System.out::println);
System.out.println("=======================distinct=========================");
//2、distinct:去重
List<String> distinctUsers = userList.stream().map(User::getCity).distinct().collect(Collectors.toList());
distinctUsers.forEach(System.out::println);
System.out.println("=======================limit=========================");
//3、limit:取前5条数据
userList.stream().limit(5).collect(Collectors.toList()).forEach(System.out::println);
System.out.println("=======================skip=========================");
//4、skip:跳过第几条取后几条
userList.stream().skip(7).collect(Collectors.toList()).forEach(System.out::println);
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
@Data
@AllArgsConstructor
class User {
int id;
String name;
int age;
String city;
}
映射
| 方 法 | 描 述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
map(Function f)
mapToDouble(ToDoubleFunction f)
mapToInt(ToIntFunction f)
mapToLong(ToLongFunction f)
flatMap(Function f)
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.Setter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
public class TestFort {
public static void main(String[] args) {
List<User> userList = getUserList();
System.out.println(userList);
System.out.println("=======================map=========================");
//1、map
List<String> mapUserList = userList.stream().map(user -> user.getName() + "用户").collect(Collectors.toList());
mapUserList.forEach(System.out::println);
System.out.println("=======================mapToDouble=========================");
//2、mapToDouble
DoubleStream mapToDoubleList = userList.stream().map(user -> user.getAge()).mapToDouble(x ->x.doubleValue());
mapToDoubleList.forEach(System.out::println);
/*3、flatMap:数据拆分一对多映射
*使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流
*/
userList.stream().flatMap(user -> Arrays.stream(user.getCity().split(","))).forEach(System.out::println);
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
@Data
@AllArgsConstructor
class User {
int id;
String name;
int age;
String city;
}
排序
| 方 法 | 描 述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparator comp) | 产生一个新流,其中按比较器顺序排序 |
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.Setter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
public class TestFort {
public static void main(String[] args) {
List<User> userList = getUserList();
System.out.println(userList);
System.out.println("=======================sorted-com=========================");
//1、sorted:排序,根据id倒序
userList.stream().sorted(Comparator.comparing(User::getId).reversed()).collect(Collectors.toList()).forEach(System.out::println);
System.out.println("=======================sorted=========================");
userList.stream().sorted().collect(Collectors.toList()).forEach(System.out::println);
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
@Data
@AllArgsConstructor
class User {
int id;
String name;
int age;
String city;
}
Stream 的终止操作
查找与匹配
| 方 法 | 描 述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。 |
| findAny() | 返回当前流中的任意元素 |
allMatch(Predicate p) 检查是否匹配所有元素
anyMatch(Predicate p) 检查是否至少匹配一个元素
noneMatch(Predicate p) 检查是否没有匹配所有元素
findFirst() 返回第一个元素终端操作会从流的流水线生成结果。
findAny() 返回当前流中的任意元素
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.Setter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
public class TestFort {
public static void main(String[] args) {
List<User> userList = getUserList();
System.out.println(userList);
System.out.println("=======================matchAll + anyMatch + noneMatch=========================");
//1、allMatch:检查是否匹配所有元素
boolean matchAll = userList.stream().allMatch(user -> "北京".equals(user.getCity()));
System.out.println("matchAll :" + matchAll);
//2、anyMatch:检查是否至少匹配一个元素
boolean matchAny = userList.stream().anyMatch(user -> "北京".equals(user.getCity()));
System.out.println("anyMatch :" + matchAny);
//3、noneMatch:检查是否没有匹配所有元素,返回boolean
boolean nonaMatch = userList.stream().noneMatch(user -> "云南".equals(user.getCity()));
System.out.println("noneMatch :" + nonaMatch);
//4、findFirst:返回第一个元素
User firstUser = userList.stream().findFirst().get();
User firstUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findFirst().get();
System.out.println("firstUser :" + firstUser + ";" + "firstUser1 :" + firstUser1);
//5、findAny:将返回当前流中的任意元素
User findUser = userList.stream().findAny().get();
User findUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findAny().get();
System.out.println("findUser :" + findUser + ";" + "findUser1 :" + findUser1);
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
@Data
@AllArgsConstructor
class User {
int id;
String name;
int age;
String city;
}
归约
| 方 法 | 描 述 |
|---|---|
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。相反,Stream API 使用内部迭代——它帮你把迭代做了) |
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional |
count() |返回流中元素总数
max(Comparator c) 返回流中最大值
min(Comparator c)返回流中最小值
forEach(Consumer c) 内部迭代
reduce(T iden, BinaryOperator b) 可以将流中元素反复结合起来,得到一个值。返回 T
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.Setter;
import java.util.*;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
public class TestFort {
public static void main(String[] args) {
List<User> userList = getUserList();
System.out.println(userList);
System.out.println("=======================归约=========================");
//1、count:返回流中元素总数
long count = userList.stream().filter(user -> user.getAge() > 20).count();
System.out.println("count : " + count);
//2、max:最大值
int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId();
System.out.println("max id : " + max);
//3、min:最小值
int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId();
System.out.println("min id : " + min);
//4、forEach:遍历流
userList.stream().forEach(user -> System.out.println(user));
userList.stream().filter(user -> "上海".equals(user.getCity())).forEach(System.out::println);
System.out.println("reduce:");
//5、reduce:将流中元素反复结合起来,得到一个值
Optional reduce = userList.stream().reduce((user, user2) -> {
user.name = user.name + user2.name;
return user;
});
if(reduce.isPresent()) System.out.println(reduce.get());
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
@Data
@AllArgsConstructor
class User {
int id;
String name;
int age;
String city;
}
收集
| 方 法 | 描 述 |
|---|---|
| collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集操作(如收 集到 List、Set、Map)。但是 Collectors实用类提供了很多静态 方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toList | List | 把流中元素收集到List |
| List emps= list.stream().collect(Collectors.toList()); | ||
| toSet | Set | 把流中元素收集到Set |
| Set emps= list.stream().collect(Collectors.toSet()); | ||
| toCollection | Collection | 把流中元素收集到创建的集合 |
| Collectionemps=list.stream().collect(Collectors.toCollection(ArrayList::new)); | ||
| counting | Long | 计算流中元素的个数 |
| long count = list.stream().collect(Collectors.counting()); | ||
| summingInt | Integer | 对流中元素的整数属性求和 |
| inttotal=list.stream().collect(Collectors.summingInt(Employee::getSalary)); | ||
| averagingInt | Double | 计算流中元素Integer属性的平均值 |
| doubleavg= list.stream().collect(Collectors.averagingInt(Employee::getSalary)); | ||
| summarizingInt | IntSummaryStatistics | 收集流中Integer属性的统计值。如:平均值 |
| IntSummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary)); | ||
| joining | String | 连接流中每个字符串 |
| String str= list.stream().map(Employee::getName).collect(Collectors.joining()); | ||
| maxBy | Optional | 根据比较器选择最大值 |
| Optionalmax= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary))); | ||
| minBy | Optional | 根据比较器选择最小值 |
| Optional min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary))); | ||
| reducing | 归约产生的类型 | 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 |
| inttotal=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum)); | ||
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果转换函数 |
| inthow= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); | ||
| groupingBy | Map<K, List> | 根据某属性值对流分组,属性为K,结果为V |
| Map<Emp.Status, List> map= list.stream().collect(Collectors.groupingBy(Employee::getStatus)); | ||
| partitioningBy | Map<Boolean, List> | 根据true或false进行分区 |
| Map<Boolean,List>vd= list.stream().collect(Collectors.partitioningBy(Employee::getManage)); |
Collector:结果收集策略的核心接口,具备将指定元素累加存放到结果容器中的能力;并在Collectors工具中提供了Collector接口的实现类
1、toList
将用户ID存放到List集合中
//1.toList
List<Integer> idList = userList.stream().map(User::getId).collect(Collectors.toList());
System.out.println(idList);
2、toMap
//2.toMap id name 以key value形式保存
Map<Integer,String> userMap = userList.stream().collect(Collectors.toMap(User::getId,User::getName));
System.out.println(userMap);
3、toSet
//3.toSet
Set<String> userCitySet = userList.stream().map(user -> user.getCity()).collect(Collectors.toSet());
System.out.println(userCitySet);
4、counting
符合条件的用户总数
long count = userList.stream().filter(user -> user.getId()>1).collect(Collectors.counting());
5、summingInt
对结果元素即用户ID求和
Integer sumInt = userList.stream().filter(user -> user.getId()>2).collect(Collectors.summingInt(User::getId)) ;
6、minBy
筛选元素中ID最小的用户
User maxId = userList.stream().collect(Collectors.minBy(Comparator.comparingInt(User::getId))).get() ;
7、joining
将用户所在城市,以指定分隔符链接成字符串;
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));
8、groupingBy
按条件分组,以城市对用户进行分组;
Map<String,List<User>> groupCity = userList.stream().collect(Collectors.groupingBy(User::getCity));
1.orElse(null)
表示如果一个都没找到返回null(orElse()中可以塞默认值。如果找不到就会返回orElse中设置的默认值)
/**
* Return the value if present, otherwise return {@code other}.
*
* @param other the value to be returned if there is no value present, may
* be null
* @return the value, if present, otherwise {@code other}
* 返回值,如果存在,否则返回其他
*/
public T orElse(T other) {
return value != null ? value : other;
}
2.orElseGet(null)
表示如果一个都没找到返回null(orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中设置的默认值)
orElse() 接受类型T的 任何参数,而orElseGet()接受类型为Supplier的函数接口,该接口返回类型为T的对象
/**
* Return the value if present, otherwise invoke {@code other} and return
* the result of that invocation.
*
* @param other a {@code Supplier} whose result is returned if no value
* is present
* @return the value if present otherwise the result of {@code other.get()}
* @throws NullPointerException if value is not present and {@code other} is
* null
* 返回值如果存在,否则调用其他值并返回该调用的结果
*/
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
orElse(null)和orElseGet(null)区别:
1、当返回Optional的值是空值null时,无论orElse还是orElseGet都会执行
2、而当返回的Optional有值时,orElse会执行,而orElseGet不会执行
package com.lyzdfintech.loongeasy.testengine;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.Setter;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
public class TestStream {
public static void main(String[] args) {
List<UserP> list = new ArrayList<>();
//定义三个用户对象
UserP UserP1 = new UserP();
UserP1.setUserName("admin");
UserP1.setAge(16);
UserP1.setSex("男");
UserP UserP2 = new UserP();
UserP2.setUserName("root");
UserP2.setAge(20);
UserP2.setSex("女");
UserP UserP3 = new UserP();
UserP3.setUserName("admin");
UserP3.setAge(18);
UserP3.setSex("男");
UserP UserP4 = new UserP();
UserP4.setUserName("admin11");
UserP4.setAge(22);
UserP4.setSex("女");
//添加用户到集合中
list.add(UserP1);
list.add(UserP2);
list.add(UserP3);
list.add(UserP4);
/*
在集合中查询用户名包含admin的集合
*/
List<UserP> UserPList = list.stream().filter(UserP -> UserP.getUserName().contains("admin")
&& UserP.getAge() <= 20).collect(Collectors.toList());
System.out.println(UserPList);
/*
在集合中查询出第一个用户名为admin的用户
*/
Optional<UserP> UserP = list.stream().filter(UserPTemp -> "admin".equals(UserPTemp.getUserName())).findFirst();
System.out.println(UserP);
/*
orElse(null)表示如果一个都没找到返回null(orElse()中可以塞默认值。如果找不到就会返回orElse中设置的默认值)
orElseGet(null)表示如果一个都没找到返回null(orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中设置的默认值)
orElse()和orElseGet()区别:在使用方法时,即使没有值 也会执行 orElse 内的方法, 而 orElseGet则不会
*/
//没值
UserP a = list.stream().filter(UserPT-> UserPT.getAge() == 12).findFirst().orElse(getMethod("a"));
UserP b = list.stream().filter(UserPT11-> UserPT11.getAge() == 12).findFirst().orElseGet(()->getMethod("b"));
//有值
UserP c = list.stream().filter(UserPT2-> UserPT2.getAge() == 16).findFirst().orElse(getMethod("c"));
UserP d = list.stream().filter(UserPT22-> UserPT22.getAge() == 16).findFirst().orElseGet(()->getMethod("d"));
System.out.println("a:"+a);
System.out.println("b:"+b);
System.out.println("c:"+c);
System.out.println("d:"+d);
}
public static UserP getMethod(String name){
System.out.println(name + "执行了方法");
return null;
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Setter
class UserP{
String userName;
int age;
String sex;
}
[UserP(userName=admin, age=16, sex=男), UserP(userName=admin, age=18, sex=男)]
Optional[UserP(userName=admin, age=16, sex=男)]
a执行了方法
b执行了方法
c执行了方法
a:null
b:null
c:UserP(userName=admin, age=16, sex=男)
d:UserP(userName=admin, age=16, sex=男)
Process finished with exit code 0
并行流和串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分
别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并
行操作。Stream API 可以声明性地通过 parallel() 与
sequential() 在并行流与顺序流之间进行切换。
5. 新时间日期 API
使用 LocalDate、LocalTime、LocalDateTime
LocalDate、LocalTime、LocalDateTime 类的实 例是不可变的对象,分别表示使用 ISO-8601日
历系统的日期、时间、日期和时间。它们提供 了简单的日期或时间,并不包含当前的时间信 息。也不包含与时区相关的信息。
| 方法 | 描述 | 示例 |
|---|---|---|
| now() | 静态方法,根据当前时间创建对象 | LocalDate localDate = LocalDate.now();LocalTime localTime = LocalTime.now();LocalDateTime localDateTime = LocalDateTime.now(); |
| of() | 静态方法,根据指定日期/时间创建对象 | LocalDate localDate = LocalDate.of(2016, 10, 26);LocalTime localTime = LocalTime.of(02, 22, 56);LocalDateTime localDateTime = LocalDateTime.of(2016, 10, 26, 12, 10, 55); |
| plusDays, plusWeeks,plusMonths, plusYears | 向当前 LocalDate 对象添加几天、几周、几个月、几年 | |
| minusDays, minusWeeks,minusMonths, minusYears | 从当前 LocalDate 对象减去几天、几周、几个月、几年 | |
| plus, minus | 添加或减少一个 Duration 或 Period | |
| withDayOfMonth,withDayOfYear,withMonth,withYear | 将月份天数、年份天数、月份、年份 修 改 为 指 定 的 值 并 返 回 新 的LocalDate 对象 | |
| getDayOfMonth | 获得月份天数(1-31),getDayOfYear 获得年份天数(1-366),getDayOfWeek 获得星期几(返回一个DayOfWeek枚举值) | |
| getMonth | 获得月份, 返回一个 Month 枚举值 | |
| getMonthValue | 获得月份(1-12) | |
| getYear | 获得年份 | |
| until | 获得两个日期之间的 Period 对象,或者指定 ChronoUnits 的数字 | |
| isBefore, isAfter | 比较两个 LocalDate | |
| isLeapYear | 判断是否是闰年 |