难度参考
难度:困难
分类:单调栈
难度与分类由我所参与的培训课程提供,但需 要注意的是,难度与分类仅供参考。且所在课程未提供测试平台,故实现代码主要为自行测试的那种,以下内容均为个人笔记,旨在督促自己认真学习。
题目
请根据每日气温列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用0来代替。
示例1:
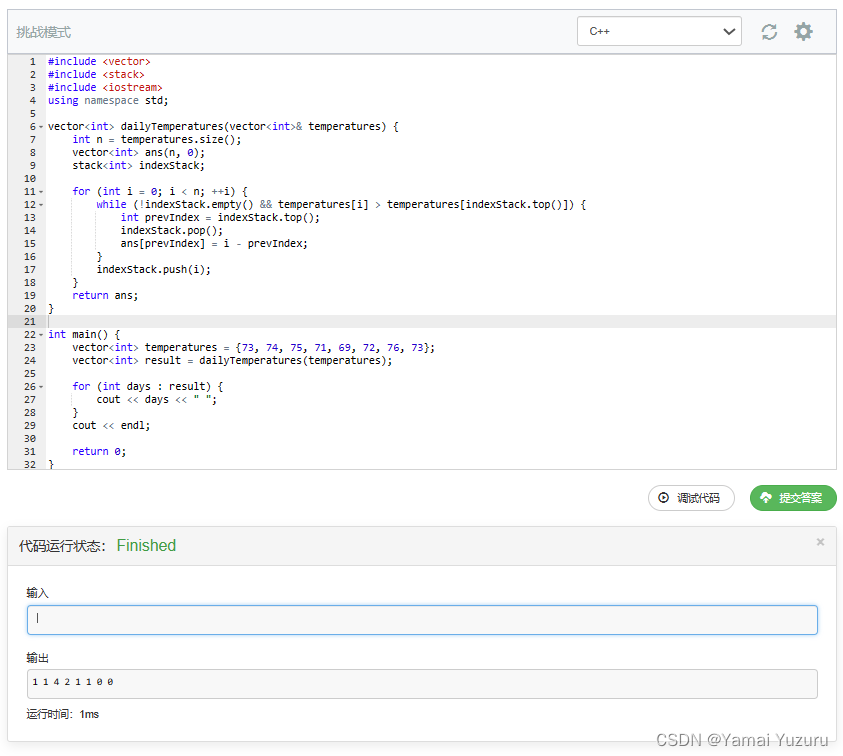
输入: temperatures =[73,74,75,71,69,72,76,73]
输出:[1,1,4,2,1,1≥0,0]
提示:气温列表长度的范围是[1,30000]。每个气温的值的均为华氏度,都是在[30,100]范围内的整数。
思路
初始化:创建一个栈来保存温度的索引,这样我们可以通过索引快速定位到温度值。同时,创建一个结果数组,其初始值全部为0,表示默认情况下没有更高的气温(或者说需要等待的天数为0)。
遍历温度列表:对于温度列表中的每一个元素,我们进行以下操作:
a. 检查栈:在将当前元素的索引添加到栈之前,我们需要检查栈顶元素。如果栈不为空且当前元素代表的温度大于栈顶元素索引对应的温度,那么我们找到了一个更高的气温。
b. 更新结果和清理栈:当我们找到一个更高的温度时,计算当前索引与栈顶索引的差值,这个差值就是栈顶索引位置需要等待的天数,以观测到更高的气温。然后将栈顶元素弹出。重复这个过程,直到栈为空或者栈顶元素代表的温度大于等于当前温度。
c. 索引入栈:将当前温度的索引入栈。这意味着对于后面的温度,如果有更高的温度出现,可以通过这个索引计算出需要等待的天数。
返回结果:遍历完成后,结果数组中存储的就是对应位置需要等待的天数,以观测到更高的气温。返回这个结果数组。
示例
假设你在一座城市里的连续几天里观测温度,你记录下来的温度如下:
温度列表: [73, 74, 75, 71, 69, 72, 76, 73]想象你有一堆小纸条,每个纸条上写着一天的温度和这一天是第几天。你的目标是对于每一天,找出需要等待多少天才能得到一个更高的温度。
初始:
栈状态
--------
null
--------
ans数组
[0, 0, 0, 0, 0, 0, 0, 0]1. 你从第一天开始,手里拿着第一天的纸条(73度),因为还没有其他的纸条来比较,你就把它放在桌子上。
栈状态
--------
0
--------
ans数组
[0, 0, 0, 0, 0, 0, 0, 0]2. 第二天,你拿着第二天的纸条(74度)。你回头看桌子上的纸条,发现74度比73度高。这意味着,从第一天起,只需等待1天就会有更高的温度。于是,你在第一天的纸条上记下“等待1天”,然后把73度的纸条收走,把74度的纸条放在桌子上。(73度就是第0张纸条,74就是第1张纸条,温度列表中的[73, 74, 75, 71, 69, 72, 76, 73]以此类推)
栈状态
--------
1
--------
ans数组
[1, 0, 0, 0, 0, 0, 0, 0]3. 第三天,你拿着第三天的纸条(75度)。同样,你比较它和桌子上的纸条,发现75度比74度高。这意味着第二天之后,也只需等待1天就会有更高的温度。你在第二天的纸条上记下“等待1天”,收走74度的纸条,放下75度的纸条。
栈状态
--------
2
--------
ans数组
[1, 1, 0, 0, 0, 0, 0, 0]4. 接下来是71度和69度的两天,这两天的温度都没有超过桌子上的75度,所以你把这两天的纸条都放在桌子上,等待未来的某一天比它们高的温度。
栈状态
--------
2,3
--------
ans数组
[1, 1, 0, 0, 0, 0, 0, 0]栈状态
--------
2,3,4
--------
ans数组
[1, 1, 0, 0, 0, 0, 0, 0]5. 第六天,温度是72度。你查看桌子上的纸条,首先发现69度,72度比它高,所以你在69度的纸条上记下“等待1天”,然后收走它。接着,你看到71度的纸条,72度也比它高,所以你在71度的纸条上记下“等待2天”,然后收走它。现在,桌子上只剩下75度的纸条,而72度比它低,所以你把72度的纸条也放在桌子上。
栈状态
--------
2,5
--------
ans数组
[1, 1, 0, 2, 1, 0, 0, 0]6. 第七天,温度是76度,这一天的温度比桌子上所有的纸条都要高。所以你依次将每张纸条拿起,记下等待的天数(对75度是4天,对72度是1天),然后将它们都收走。最后,你把76度的纸条放在桌子上。
栈状态
--------
6
--------
ans数组
[1, 1, 4, 2, 1, 1, 0, 0]7. 最后一天,温度是73度,但是这是最后一天了,我们不需要再记录更高温度的等待天数了,因为已经没有更多的天数了。
栈状态
--------
6,7
--------
ans数组
[1, 1, 4, 2, 1, 1, 0, 0]通过这个过程,你为每一天都记录了需要等待更高温度的天数,最终得到的结果就是:[1, 1, 4, 2, 1, 1, 0, 0]。
梳理
这个方法之所以有效,归根到底是因为它利用了一个叫做"单调栈"的数据结构来优化查找过程。下面是几个关键点来解释为什么这样做能够实现目标:
1. 单调性:栈用于维护温度的索引,这些索引对应的温度是单调递减的。这意味着栈顶的温度总是最小的。这样做的好处是,当你遍历到一个新的温度时,只需要与栈顶元素比较,就可以知道是否存在一个更高的温度。如果新的温度更高,那么栈顶元素及所有比新温度低的元素都可以找到一个更高的温度,因此可以计算等待天数并更新`ans`数组。
2. 有效地找到更高的温度:当你遇到一个比栈顶温度高的新温度时,这说明你找到了从栈顶索引对应的天数起,第一个更高的温度。因为栈是递减的,所以栈中所有低于新温度的日子都会被连续弹出,直到遇到一个比新温度更高的日子或栈为空。这样,对于每个被弹出的日子,你都可以确定它们等待更高温度的确切天数,这是通过计算当前温度的索引与被弹出的索引之间的差来实现的。
3. 避免重复比较:通过仅将尚未找到更高温度的日子的索引放入栈中,我们避免了对每个新日子进行全面比较。这种方法只比较那些有可能在未来遇到更高温度的日子,从而大大减少了比较的次数。
4. 时间复杂度优化:由于每个元素最多被压入栈一次,且从栈中弹出一次,遍历温度列表和处理栈的操作的总时间复杂度为O(n),其中n是温度列表的长度。这比一个简单的嵌套循环(时间复杂度为O(n^2))要高效得多。
综上所述,通过使用单调栈,我们能够高效地为每一天找到等待更高温度的天数。这种方法充分利用了"先进后出"的栈特性和温度之间的相对单调性,优化了查找过程,确保了整个算法的效率和有效性。

代码
#include <vector> // 引入vector库,用于存储温度数据和结果数组
#include <stack> // 引入stack库,用于实现单调栈
#include <iostream> // 引入iostream库,用于输入输出
using namespace std;
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size(); // 获取输入温度数组的长度
vector<int> ans(n, 0); // 初始化结果数组,大小与输入数组相同,默认值为0
stack<int> indexStack; // 存储温度索引的单调栈
for (int i = 0; i < n; ++i) { // 遍历温度数组
while (!indexStack.empty() && temperatures[i] > temperatures[indexStack.top()]) {
// 当栈不为空且当前温度高于栈顶温度时,进行循环
// 获取栈顶元素(较低温度的索引)
int prevIndex = indexStack.top();
indexStack.pop(); // 弹出栈顶元素
ans[prevIndex] = i - prevIndex; // 计算当前天数与更高温度天数的差值,存储到结果数组中
}
indexStack.push(i); // 将当前温度的索引入栈
}
return ans; // 返回结果数组
}
int main() {
vector<int> temperatures = {73, 74, 75, 71, 69, 72, 76, 73}; // 定义温度数组
vector<int> result = dailyTemperatures(temperatures); // 调用函数获取结果数组
for (int days : result) { // 遍历结果数组
cout << days << " "; // 输出每个元素(表示所需的天数)
}
cout << endl;
return 0;
}-
时间复杂度:
O(n)。 -
空间复杂度:
O(n)。
打卡









![[创业之路-88/管理者与领导者-128]:企业运行分层模型、研发管理全视野](https://img-blog.csdnimg.cn/direct/f8afbb0f6ca34aec89f4079f1a12e00c.png)