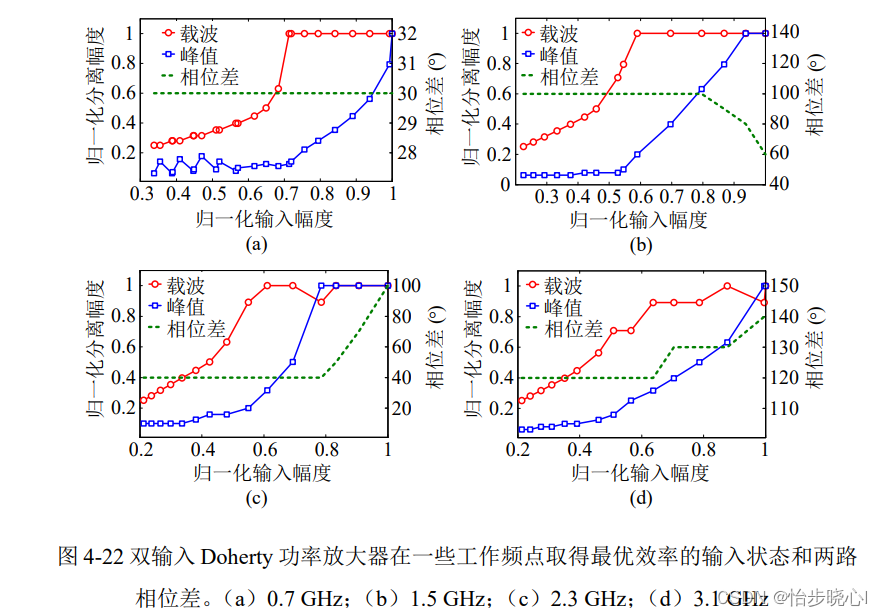
C++项目 – 高并发内存池(五)释放内存过程
文章目录
- C++项目 -- 高并发内存池(五)释放内存过程
- 一、Thread Cache释放内存
- 1.完善FreeList功能
- 2.Thread Cache释放内存
- 二、Central Cache释放内存
- 三、Page Cache释放内存
- 四、释放内存过程联调
- 五、代码实现
一、Thread Cache释放内存
1.完善FreeList功能
- 当一块内存块释放时,我们将其归还给对应的Thread Cache的freeList,当前freeList的长度如果达到了一定值,我们就可以将一段list归还给central cache管理,以减少内存碎片,因此FreeList类需要增加统计链表长度的成员及接口;
PopRange用于批量从FreeList中取走size个对象;
//自由链表类,用于管理切分好的小内存块
class FreeList {
public:
void Push(void* obj) {
assert(obj);
//头插
NextObj(obj) = _freeList;
_freeList = obj;
_size++;
}
//范围插入
void PushRange(void* start, void* end, size_t size) {
assert(start);
assert(end);
NextObj(end) = _freeList;
_freeList = start;
_size += size;
}
void* Pop() {
assert(_freeList);
//头删
void* obj = _freeList;
_freeList = NextObj(obj);
_size--;
return obj;
}
//批量取走对象
void PopRange(void* start, void* end, size_t size) {
assert(size >= _size);
start = _freeList;
end = start;
for (size_t i = 0; i < size - 1; i++) {
end = NextObj(end);
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
_size -= size;
}
bool Empty() {
return _freeList == nullptr;
}
//用于实现thread cache从central cache获取内存的慢开始算法
size_t& MaxSize() {
return _maxSize;
}
size_t Size() {
return _size;
}
private:
void* _freeList = nullptr;
size_t _maxSize = 1;
size_t _size = 0;
};
2.Thread Cache释放内存
Deallocate函数用于将释放的内存块插入到对应的Thread Cache的自由链表中,如果自由链表的长度超过了一次批量申请内存块的数量,就调用ListTooLong函数归还一段链表给Central Cache;
void ThreadCache::Deallocate(void* obj, size_t size) {
assert(obj);
assert(size <= MAX_BYTES);
//找该对象对应的freeList的桶,直接插入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(obj);
//当链表的长度大于一次批量申请的内存块的数量时,就归还一段list给central cache
if (_freeLists[index].Size() > _freeLists[index].MaxSize()) {
ListTooLong(_freeLists[index], size);
}
}
ListTooLong函数用于从当前自由链表中取出MaxSize长度的链表,归还到CentralCache的对应Span中:
void ThreadCache::ListTooLong(FreeList& list, size_t size) {
void* start = nullptr;
void* end = nullptr;
//从list中取出MaxSize长度的链表
list.PopRange(start, end, list.MaxSize());
//归还给CentralCache的对应span
CentralCache::GetInstance()->ReleaseListToSpan(start, size);
}
二、Central Cache释放内存
- 从central cache获取内存块到thread cache的时候,要更新span的
_useCount参数;
//从CentralCache获取一定数量的内存对象给ThreadCache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size) {
//先根据对象size获取对应的spanList下标
size_t index = SizeClass::Index(size);
//每个线程访问spanList时需要加锁
_spanLists[index]._mtx.lock();
//获取非空的span
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freeList);
//从span中获取batchNum个对象,若不够,就有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1; // 实际拿到的对象数量
while (i < batchNum - 1 && NextObj(end) != nullptr) {
end = NextObj(end);
actualNum++;
i++;
}
//在span中去掉这一段对象
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
//更新span->_useCount参数
span->_useCount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
- 在Page Cache中加入页号与Span的映射关系;
- 在central cache向page cache申请span的时候,申请下了span就立即将该span的
_isUse属性设为true,避免后面page cache合并span的时候出现线程安全问题;
Span* CentralCache::GetOneSpan(SpanList& spanList, size_t size) {
//先检查该SpanList有没有未分配的Span
Span* it = spanList.Begin();
while (it != spanList.End()) {
if (it->_freeList != nullptr) {
return it;
}
else {
it = it->_next;
}
}
//先把central cache 的桶锁解掉,这样如果其他线程释放对象回来,就不会被阻塞
spanList._mtx.unlock();
//SpanList中没有空闲的Span,需要向page cache申请
//在此处加上page cache的全局锁,NewSpan的所有操作都是加锁进行的
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//更新_isUse属性
span->_isUse = true;
PageCache::GetInstance()->_pageMtx.unlock();
//从page cache获取到了新的span,需要进行切分
//无需在此加上桶锁,因为该span还没有放到spanList中,其他线程访问不到
//计算span大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageID << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
//把大块内存切成自由链表链接起来
//先切一块下来做头,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
while (start < end) {
NextObj(tail) = start;
tail = start;
start += size;
}
//在span挂载到spanList之前加上桶锁
spanList._mtx.lock();
spanList.PushFront(span);
return span;
}
ReleaseListToSpan函数用于将归还回来的内存块链表挂载回span;- 判断内存块属于哪一页,页的起始地址除以8k为页号,两页之间的任意地址除以8k也是该地址所属的页号;
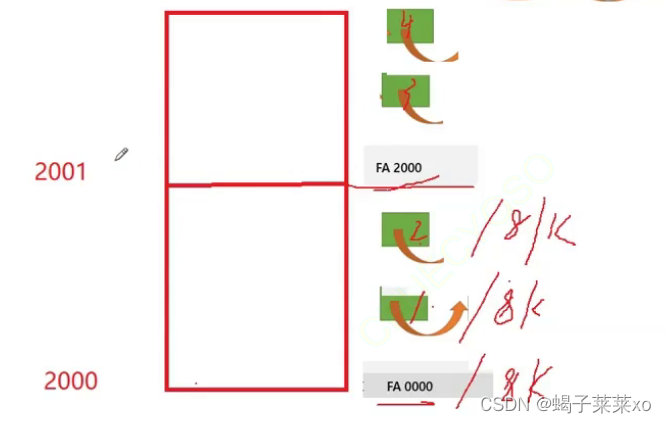
- 查找内存块对象对应的span,头插到对应的span中;
- 更新span的useCount,如果useCount变为0,就说明所有内存块都已经归还,就可以将该span归还给page cache;
- 归还page cache的时候也涉及解除central cache的桶锁,因为这之后的操作与该桶无关了,其他的线程也有可能在这个桶申请和释放内存,因此需要解除桶锁;
- page cache的锁直接加在
ReleaseSpanToPageCache之外;
- 判断内存块属于哪一页,页的起始地址除以8k为页号,两页之间的任意地址除以8k也是该地址所属的页号;
void CentralCache::ReleaseListToSpan(void* start, size_t byte_size) {
size_t index = SizeClass::Index(byte_size);
_spanLists[index]._mtx.lock();
//该段list的尾部指针已经置空,遍历到空指针就停止
while (start) {
//将内存块对象挂载到对应的span上
void* next = NextObj(start);
//获取该对象对应的span
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freeList;
span->_freeList = start;
//更新_useCount
span->_useCount--;
//说明该span的小块内存都回收了
//这个span就可以回收给page cache,由page cache去做前后页的合并
if (span->_useCount == 0) {
_spanLists[index].Erase(span);
span->_prev = nullptr;
span->_next = nullptr;
span->_freeList = nullptr;
//释放span给page cache的时候,使用page cache的锁就可以了
//将桶锁先解除,方便其他线程在该桶上申请和释放内存
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}
三、Page Cache释放内存
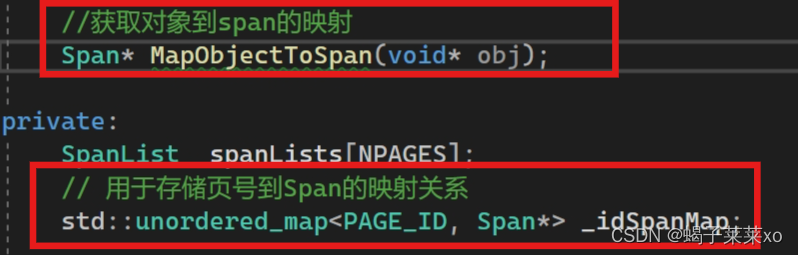
- PageCache类中增加一个哈希表
_idSpanMap成员,用于存储页号到Span的映射关系;
在NewSpan函数切分Span的时候,将切分后的两个Span的页号与Span的映射关系都加入到_idSpanMap中;
MapObjectToSpan函数用于获取对象到span的映射关系;
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
//先检查第k个桶里面有没有span
if (!_spanLists[k].Empty()) {
//有就返回
return _spanLists[k].PopFront();
}
//没有就需要检查后面的桶有没有更大的span,如果有可以拆分
for (size_t i = k + 1; i < NPAGES; i++) {
if (!_spanLists[i].Empty()) {
Span* nspan = _spanLists[i].PopFront();
Span* kspan = new Span;
//在nspan头部且下一个k页的span
//kspan返回
//nspan剩下的部分挂载到相应的桶上
kspan->_pageID = nspan->_pageID;
kspan->_n = k;
nspan->_pageID += k;
nspan->_n -= k;
_spanLists[nspan->_n].PushFront(nspan);
//存储nspan的首尾页号与Span的关系,方便page cache回收内存时进行合并查找
_idSpanMap[nspan->_pageID] = nspan;
_idSpanMap[nspan->_pageID + nspan->_n - 1] = nspan;
//存储kspan每一页的页号与span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kspan->_n; i++) {
_idSpanMap[kspan->_pageID + i] = kspan;
}
return kspan;
}
}
//走到这里说明没有更大的span了,需要向堆申请一个128页的大块内存
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageID = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[NPAGES - 1].PushFront(bigSpan);
//此时需要将_spanLists中的128页的内存切分,递归调用一下
return NewSpan(k);
}
Span* PageCache::MapObjectToSpan(void* obj) {
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end()) {
return ret->second;
}
else {
//应该是一定能够获取到的
//如果获取不到就是出现了问题
assert(false);
return nullptr;
}
}
ReleaseSpanToPageCache函数用于释放空闲span回到page cache,并合并相邻的span;- 通过
_idSpanMap获取页号与span的映射关系,将处于空闲状态,并且页号相邻的span合并成更大的span,这样可以减少内存碎片; - 使用span的_useCount属性来判断span是否被使用会造成线程安全问题,因为一个span被分到central cache但是好没有被切分时,他的_useCount依然是0;
- 因此需要使用_isUse属性来判断,在span被分给central cache后,就将_isUse置为true;
- 不断地向前向后合并;
- 通过
void PageCache::ReleaseSpanToPageCache(Span* span) {
//对span前后的相邻页进行合并,缓解内存碎片的问题
//向前合并
while (1) {
//前一页的id
PAGE_ID prevId = span->_pageID - 1;
//从map中寻找页号与span的映射
auto ret = _idSpanMap.find(prevId);
//前面的页号没有,不合并
if (ret == _idSpanMap.end()) {
break;
}
//前面相邻页的span在使用,不合并
Span* prevSpan = ret->second;
if (prevSpan->_isUse == true) {
break;
}
//合并超出128页的span没法管理,不合并
if (prevSpan->_n + span->_n > NPAGES - 1) {
break;
}
//合并前面的span
span->_pageID = prevSpan->_pageID;
span->_n += prevSpan->_n;
delete prevSpan;
}
//向后合并
while (1) {
PAGE_ID nextId = span->_pageID + span->_n;
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end()) {
break;
}
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true) {
break;
}
if (nextSpan->_n + span->_n > NPAGES - 1) {
break;
}
span->_n += nextSpan->_n;
_spanLists[nextSpan->_n].Erase(nextSpan);
delete nextSpan;
}
//将合并好的span挂载到对应的哈希桶,更新isUse
_spanLists[span->_n].PushFront(span);
span->_isUse = true;
_idSpanMap[span->_pageID] = span;
_idSpanMap[span->_pageID + span->_n - 1] = span;
}
四、释放内存过程联调
void TestConcurrentAlloc1() {
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
void* p4 = ConcurrentAlloc(7);
void* p5 = ConcurrentAlloc(8);
void* p6 = ConcurrentAlloc(7);
void* p7 = ConcurrentAlloc(8);
cout << p1 << endl;
cout << p2 << endl;
cout << p3 << endl;
cout << p4 << endl;
cout << p5 << endl;
cout << p6 << endl;
cout << p7 << endl;
ConcurrentFree(p1, 6);
ConcurrentFree(p2, 8);
ConcurrentFree(p3, 1);
ConcurrentFree(p4, 7);
ConcurrentFree(p5, 8);
ConcurrentFree(p6, 7);
ConcurrentFree(p7, 8);
}
- 能最终释放内存,并合并成128页的大块span
多线程测试
void MultiThreadAlloc1() {
std::vector<void*> v;
for (int i = 0; i < 7; i++) {
void* ptr = ConcurrentAlloc(5);
v.push_back(ptr);
}
for (auto e : v) {
ConcurrentFree(e, 5);
}
}
void MultiThreadAlloc2() {
std::vector<void*> v;
for (int i = 0; i < 7; i++) {
void* ptr = ConcurrentAlloc(16);
v.push_back(ptr);
}
for (auto e : v) {
ConcurrentFree(e, 16);
}
}
void TestMultiThread() {
std::thread t1(Alloc1);
std::thread t2(Alloc2);
t1.join();
t2.join();
}
- 多线程联调,并行监视
五、代码实现
Common.h
#pragma once
//公共头文件
#include <iostream>
#include <vector>
#include <assert.h>
#include <thread>
#include <mutex>
#include <algorithm>
#include <unordered_map>
using std::cout;
using std::endl;
using std::vector;
static const size_t MAX_BYTES = 256 * 1024; //ThreadCache能分配对象的最大字节数
static const size_t NFREELIST = 208; //central cache 最大的哈希桶数量
static const size_t NPAGES = 129; //page cache 哈希桶的数量
static const size_t PAGE_SHIFT = 13; //页与字节的转换
#ifdef _WIN32
#include<windows.h>
#else
//linux
#endif
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#elif
//linux
#endif
//直接去堆上申请空间
inline static void* SystemAlloc(size_t kpage) {
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
#endif // _WIN32
if (ptr == nullptr) {
throw std::bad_alloc();
}
return ptr;
}
// 访问obj的前4 / 8字节地址空间
static void*& NextObj(void* obj) {
return *(void**)obj;
}
//自由链表类,用于管理切分好的小内存块
class FreeList {
public:
void Push(void* obj) {
assert(obj);
//头插
NextObj(obj) = _freeList;
_freeList = obj;
_size++;
}
//范围插入
void PushRange(void* start, void* end, size_t size) {
assert(start);
assert(end);
NextObj(end) = _freeList;
_freeList = start;
_size += size;
}
void* Pop() {
assert(_freeList);
//头删
void* obj = _freeList;
_freeList = NextObj(obj);
_size--;
return obj;
}
//批量取走对象
void PopRange(void*& start, void* end, size_t size) {
assert(_size >= size); /// ???????? _size >= size
start = _freeList;
end = start;
for (size_t i = 0; i < size - 1; i++) {
end = NextObj(end);
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
_size -= size;
}
bool Empty() {
return _freeList == nullptr;
}
//用于实现thread cache从central cache获取内存的慢开始算法
size_t& MaxSize() {
return _maxSize;
}
size_t Size() {
return _size;
}
private:
void* _freeList = nullptr;
size_t _maxSize = 1;
size_t _size = 0;
};
// 管理对齐和哈希映射规则的类
class SizeClass {
public:
//对齐规则
// 整体控制在最多10%左右的内碎片浪费
// [1,128] 8byte对齐 freelist[0,16)
// [128+1,1024] 16byte对齐 freelist[16,72)
// [1024+1,8*1024] 128byte对齐 freelist[72,128)
// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
//RoundUp的子函数,根据对象大小和对齐数,返回对象对齐后的大小
static inline size_t _RoundUp(size_t size, size_t align) {
//if (size % align == 0) {
// return size;
//}
//else {
// return (size / align + 1) * align;
//}
//使用位运算能够得到一样的结果,但是位运算的效率很高
return ((size + align - 1) & ~(align - 1));
}
//计算当前对象size字节对齐之后对应的size
static inline size_t RoundUp(size_t size) {
assert(size <= MAX_BYTES);
if (size <= 128) {
//8字节对齐
return _RoundUp(size, 8);
}
else if (size <= 1024) {
//16字节对齐
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024) {
//128字节对齐
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024) {
//1024字节对齐
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024) {
//8KB字节对齐
return _RoundUp(size, 8 * 1024);
}
else {
assert(false);
}
return -1;
}
//Index的子函数,用于计算映射的哈希桶下标
static inline size_t _Index(size_t size, size_t alignShift) {
//if (size % align == 0) {
// return size / align - 1;
//}
//else {
// return size / align;
//}
//使用位运算能够得到一样的结果,但是位运算的效率很高
//使用位运算需要将输入参数由对齐数改为对齐数是2的几次幂、
return ((size + (1 << alignShift) - 1) >> alignShift) - 1;
}
//计算对象size映射到哪一个哈希桶(freelist)
static inline size_t Index(size_t size) {
assert(size <= MAX_BYTES);
//每个区间有多少个哈希桶
static int groupArray[4] = { 16, 56, 56, 56 };
if (size <= 128) {
return _Index(size, 3);
}
else if (size <= 1024) {
//由于前128字节不是16字节对齐,因此需要减去该部分,单独计算16字节对齐的下标
//再在最终结果加上全部的8字节对齐哈希桶个数
return _Index(size - 128, 4) + groupArray[0];
}
else if (size <= 8 * 1024) {
return _Index(size - 1024, 7) + groupArray[0] + groupArray[1];
}
else if (size <= 64 * 1024) {
return _Index(size - 8 * 1024, 10) + groupArray[0] + groupArray[1] + groupArray[2];
}
else if (size <= 256 * 1024) {
return _Index(size - 64 * 1024, 13) + groupArray[0] + groupArray[1] + groupArray[2] + groupArray[3];
}
else {
assert(false);
}
return -1;
}
//thread cache一次从central cache中获取多少内存块
static size_t NumMoveSize(size_t size) {
//一次获取的内存块由对象的大小来决定
assert(size > 0);
//将获取的数量控制在[2, 512]
size_t num = MAX_BYTES / size;
if (num < 2) {
num = 2;
}
if (num > 512) {
num = 512;
}
return num;
}
//计算central cache一次向page cache获取多少页的span
static size_t NumMovePage(size_t size) {
assert(size > 0);
//先计算该对象一次申请内存块的上限值
size_t num = NumMoveSize(size);
//计算上限的空间大小
size_t npage = num * size;
//转换成page单位
npage >>= PAGE_SHIFT;
if (npage == 0) {
npage = 1;
}
return npage;
}
};
struct Span
{
PAGE_ID _pageID = 0; // 大块内存起始页的页号
size_t _n = 0; // 页的数量
Span* _next = nullptr; // 双向链表的结构
Span* _prev = nullptr;
size_t _objSize = 0; // 切好的小对象的大小
size_t _useCount = 0; // 切好小块内存,被分配给thread cache的计数
void* _freeList = nullptr; // 切好的小块内存的自由链表
bool _isUse = false; // 是否在被使用
};
class SpanList {
public:
SpanList() {
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
void Insert(Span* pos, Span* newSapn) {
assert(pos);
assert(newSapn);
Span* prev = pos->_prev;
prev->_next = newSapn;
newSapn->_prev = prev;
newSapn->_next = pos;
pos->_prev = newSapn;
}
void Erase(Span* pos) {
assert(pos);
assert(pos != _head);
//不用释放空间
Span* prev = pos->_prev;
Span* next = pos->_next;
prev->_next = next;
next->_prev = prev;
}
Span* Begin() {
return _head->_next;
}
Span* End() {
return _head;
}
bool Empty() {
return _head->_next == _head;
}
void PushFront(Span* newSapn) {
Insert(Begin(), newSapn);
}
Span* PopFront() {
Span* front = _head->_next;
Erase(front);
return front;
}
private:
Span* _head; //头节点
public:
std::mutex _mtx; //桶锁
};
ThreadCache.h
#pragma once
#include "Common.h"
class ThreadCache {
public:
//申请和释放对象内存
void* Allocate(size_t size);
void Deallocate(void* obj, size_t size);
//从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t alignSize);
//自由链表过长时,回收一段链表到中心缓存
void ListTooLong(FreeList& list, size_t size);
private:
FreeList _freeLists[NFREELIST];
};
//声明_declspec(thread)后,会为每一个线程创建一个单独的拷贝
//使用_declspec(thread)声明了ThreadCache*指针变量,则该指针在该线程中会创建一份单独的拷贝
//pTLSThreadCache指向的对象在本线程内是能够全局访问的,但是无法被其他线程访问到,这就做到了多线程情景下的无锁访问
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
ThreadCache.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "ThreadCache.h"
#include "CentralCache.h"
void* ThreadCache::Allocate(size_t size) {
assert(size <= MAX_BYTES);
//获取对齐后的大小及对应的哈希桶下标
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty()) {
//若对应的freeList桶不为空,直接pop一个内存块给该对象
return _freeLists[index].Pop();
}
else {
//否则需要从CentralCache获取内存空间
return ThreadCache::FetchFromCentralCache(index, alignSize);
}
}
void ThreadCache::Deallocate(void* obj, size_t size) {
assert(obj);
assert(size <= MAX_BYTES);
//找该对象对应的freeList的桶,直接插入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(obj);
//当链表的长度大于一次批量申请的内存块的数量时,就归还一段list给central cache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize()) {
ListTooLong(_freeLists[index], size);
}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size) {
void* start = nullptr;
void* end = nullptr;
//从list中取出MaxSize长度的链表
list.PopRange(start, end, list.MaxSize());
//归还给CentralCache的对应span
CentralCache::GetInstance()->ReleaseListToSpan(start, size);
}
void* ThreadCache::FetchFromCentralCache(size_t index, size_t alignSize) {
//慢开始算法
//计算当前从Central Cache中获取内存块的最大数量
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(alignSize));
//如果MaxSize未达上限,就将MaxSize + 1
if (batchNum == _freeLists[index].MaxSize()) {
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, alignSize);
assert(actualNum >= 1);
if (actualNum == 1) {
//如果最终获取的数量为1,直接返回给对象
assert(start == end);
return start;
}
else {
//如果最终获取的数量多于一个,则返回第一个给对象,剩下的插入freeList里
_freeLists[index].PushRange(NextObj(start), end, actualNum - 1); // 批量插入
//NextObj(start) = nullptr;
return start;
}
}
CentralCache.h
#pragma once
#include "Common.h"
#include "PageCache.h"
//饿汉单例模式
class CentralCache {
public:
static CentralCache* GetInstance() {
return &_sInstance;
}
//从CentralCache获取一定数量的内存对象给ThreadCache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
//获取一个非空的Sapn
Span* GetOneSpan(SpanList& spanList, size_t size);
//归还一段list到对应的span
void ReleaseListToSpan(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
//构造函数私有化
CentralCache()
{}
//不生成默认拷贝构造
CentralCache(const CentralCache&) = delete;
static CentralCache _sInstance;
};
CentralCache.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "CentralCache.h"
//单例模式静态成员的定义
CentralCache CentralCache::_sInstance;
//从CentralCache获取一定数量的内存对象给ThreadCache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size) {
//先根据对象size获取对应的spanList下标
size_t index = SizeClass::Index(size);
//每个线程访问spanList时需要加锁
_spanLists[index]._mtx.lock();
//获取非空的span
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freeList);
//从span中获取batchNum个对象,若不够,就有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1; // 实际拿到的对象数量
while (i < batchNum - 1 && NextObj(end) != nullptr) {
end = NextObj(end);
actualNum++;
i++;
}
//在span中去掉这一段对象
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
//更新span->_useCount参数
span->_useCount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
Span* CentralCache::GetOneSpan(SpanList& spanList, size_t size) {
//先检查该SpanList有没有未分配的Span
Span* it = spanList.Begin();
while (it != spanList.End()) {
if (it->_freeList != nullptr) {
return it;
}
else {
it = it->_next;
}
}
//先把central cache 的桶锁解掉,这样如果其他线程释放对象回来,就不会被阻塞
spanList._mtx.unlock();
//SpanList中没有空闲的Span,需要向page cache申请
//在此处加上page cache的全局锁,NewSpan的所有操作都是加锁进行的
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//更新_isUse属性
span->_isUse = true;
PageCache::GetInstance()->_pageMtx.unlock();
//从page cache获取到了新的span,需要进行切分
//无需在此加上桶锁,因为该span还没有放到spanList中,其他线程访问不到
//计算span大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageID << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
//把大块内存切成自由链表链接起来
//先切一块下来做头,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
while (start < end) {
NextObj(tail) = start;
tail = start;
start += size;
}
//在span挂载到spanList之前加上桶锁
spanList._mtx.lock();
spanList.PushFront(span);
return span;
}
void CentralCache::ReleaseListToSpan(void* start, size_t byte_size) {
size_t index = SizeClass::Index(byte_size);
_spanLists[index]._mtx.lock();
//该段list的尾部指针已经置空,遍历到空指针就停止
while (start) {
//将内存块对象挂载到对应的span上
void* next = NextObj(start);
//获取该对象对应的span
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freeList;
span->_freeList = start;
//更新_useCount
span->_useCount--;
//说明该span的小块内存都回收了
//这个span就可以回收给page cache,由page cache去做前后页的合并
if (span->_useCount == 0) {
_spanLists[index].Erase(span);
span->_prev = nullptr;
span->_next = nullptr;
span->_freeList = nullptr;
//释放span给page cache的时候,使用page cache的锁就可以了
//将桶锁先解除,方便其他线程在该桶上申请和释放内存
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}
PageCache.h
#pragma once
#include "Common.h"
//单例模式
class PageCache {
public:
static PageCache* GetInstance() {
return &_sInstance;
}
std::mutex _pageMtx; //全局锁
//获取一个k页的Span
Span* NewSpan(size_t k);
//获取对象到span的映射
Span* MapObjectToSpan(void* obj);
//释放空闲span回到page cache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
private:
SpanList _spanLists[NPAGES];
// 用于存储页号到Span的映射关系
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
PageCache() {}
PageCache(const PageCache&) = delete;
static PageCache _sInstance;
};
PageCache.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "PageCache.h"
PageCache PageCache::_sInstance;
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
//先检查第k个桶里面有没有span
if (!_spanLists[k].Empty()) {
//有就返回
return _spanLists[k].PopFront();
}
//没有就需要检查后面的桶有没有更大的span,如果有可以拆分
for (size_t i = k + 1; i < NPAGES; i++) {
if (!_spanLists[i].Empty()) {
Span* nspan = _spanLists[i].PopFront();
Span* kspan = new Span;
//在nspan头部且下一个k页的span
//kspan返回
//nspan剩下的部分挂载到相应的桶上
kspan->_pageID = nspan->_pageID;
kspan->_n = k;
nspan->_pageID += k;
nspan->_n -= k;
_spanLists[nspan->_n].PushFront(nspan);
//存储nspan的首尾页号与Span的关系,方便page cache回收内存时进行合并查找
_idSpanMap[nspan->_pageID] = nspan;
_idSpanMap[nspan->_pageID + nspan->_n - 1] = nspan;
//存储kspan每一页的页号与span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kspan->_n; i++) {
_idSpanMap[kspan->_pageID + i] = kspan;
}
return kspan;
}
}
//走到这里说明没有更大的span了,需要向堆申请一个128页的大块内存
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageID = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[NPAGES - 1].PushFront(bigSpan);
//此时需要将_spanLists中的128页的内存切分,递归调用一下
return NewSpan(k);
}
Span* PageCache::MapObjectToSpan(void* obj) {
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end()) {
return ret->second;
}
else {
//应该是一定能够获取到的
//如果获取不到就是出现了问题
assert(false);
return nullptr;
}
}
void PageCache::ReleaseSpanToPageCache(Span* span) {
//对span前后的相邻页进行合并,缓解内存碎片的问题
//向前合并
while (1) {
//前一页的id
PAGE_ID prevId = span->_pageID - 1;
//从map中寻找页号与span的映射
auto ret = _idSpanMap.find(prevId);
//前面的页号没有,不合并
if (ret == _idSpanMap.end()) {
break;
}
//前面相邻页的span在使用,不合并
Span* prevSpan = ret->second;
if (prevSpan->_isUse == true) {
break;
}
//合并超出128页的span没法管理,不合并
if (prevSpan->_n + span->_n > NPAGES - 1) {
break;
}
//合并前面的span
span->_pageID = prevSpan->_pageID;
span->_n += prevSpan->_n;
delete prevSpan;
}
//向后合并
while (1) {
PAGE_ID nextId = span->_pageID + span->_n;
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end()) {
break;
}
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true) {
break;
}
if (nextSpan->_n + span->_n > NPAGES - 1) {
break;
}
span->_n += nextSpan->_n;
_spanLists[nextSpan->_n].Erase(nextSpan);
delete nextSpan;
}
//将合并好的span挂载到对应的哈希桶,更新isUse
_spanLists[span->_n].PushFront(span);
span->_isUse = true;
_idSpanMap[span->_pageID] = span;
_idSpanMap[span->_pageID + span->_n - 1] = span;
}