论文地址:https://arxiv.org/pdf/2103.06495.pdf
代码地址:https://github.com/FangShancheng/ABINet
前言
OCR技术经历了是从传统方法到深度学习方法的一个过程,所以在这里我也简述一下传统的OCR技术方法。传统OCR方法在简单场景下效果良好,但在复杂场景、不同字体、光照条件变化等情况下可能面临挑战。近年来,随着深度学习的发展,基于神经网络的端到端OCR系统逐渐崭露头角,取得了在多种场景下更优越的性能。传统的OCR(Optical Character Recognition,光学字符识别)系统通常包括以下主要步骤:
图像预处理:
灰度化: 将彩色图像转换为灰度图像,简化后续处理。
二值化: 将灰度图像转换为二值图像,通过设定阈值将像素划分为前景(字符)和背景。
去噪: 对图像进行降噪操作,去除一些不必要的细节和干扰。
文本区域检测:
连通区域分析: 通过识别连通区域,找到潜在的文本区域。
边缘检测: 利用边缘检测算法寻找文本的轮廓。
文本分割:
将图像中的文本区域切分成单个字符或单词。
特征提取:
对每个字符或单词提取特征,常用的特征包括垂直投影、水平投影、梯度等。
字符识别:
使用机器学习或模板匹配等方法对提取的字符特征进行识别。
常见的方法包括模板匹配、k-最近邻(k-NN)、支持向量机(SVM)等。
后处理:
对识别结果进行后处理,可能包括纠错、合并或分割字符等操作。
输出结果:
将最终的识别结果输出为文本或其他格式。
在此之前,我做了了一个先CNN再RNN的seq2seq的中文识别的项目练手,当时的目的是为了学习一下seq2seq模型技术,详情可看之前发布的笔记
ABINet介绍
这是一个端到端深度学习场景文本识别网络,利用语言模型帮助场景文本识别,提出了一种基于双向特征表示的双向完形填空网络语言模型(BCN),重点解决低质量图像的文本识别问题。该网络通过明确的语言建模、新型双向完形填空式网络(BCN)、迭代修正等技术,有效处理隐式语言建模、单向特征表示和噪声输入等问题。此外,引入一种基于迭代预测集成的自训练方法,能够从未标记的图像中学习。实验证明,在低质图像上表现优越,在多个基准数据集上取得了SOTA性能,同时通过自训练显著提升了在人类水平识别上的性能。
该网络结构主要关注场景文本识别中如何充分利用语言知识,并指出在端到端深度神经网络中建模语言规则的挑战。
显式语言建模: 通过阻断视觉模型和语言模型之间的梯度流,使得语言的建模过程更为明确。这有助于克服隐式语言建模的局限性,使网络更清晰地学习语言规则。
双向完形填空网络(BCN): 提出了一种新型的语言模型,即双向完形填空网络。该模型基于双向特征表示,使得模型能够更全面地理解文本上下文的语义信息,克服了传统单向特征表示的局限性。
语言模型迭代修正: 引入了一种迭代修正的执行方式,以有效减轻噪声输入对语言模型的影响。这意味着网络能够通过多次迭代不断调整和修正语言模型,逐渐提升对于噪声输入的鲁棒性。
这些创新性的方法共同构成了一种全新的场景文本识别网络,旨在充分利用语言知识,提高对复杂场景文本的识别性能。该网络在多个性能指标上超越了传统方法,并在处理噪声输入、双向特征表示等方面取得了显著的改进。
小辉问:能不能详细讲讲显式语言建模和隐式语言建模,显式和隐式经常听到,但是不是很理解,也介绍一下吧。
小G答:
显式语言建模与隐式语言建模:
1、显式语言建模:
定义明确: 显式语言建模是指在模型中直接引入对语言结构或规则的明确建模。这可以通过特定的网络层、损失函数、或者嵌入来实现。
例子: 在显式语言建模中,可以使用传统的自然语言处理(NLP)技术,如规则引擎、语法分析等,将语言结构直接纳入模型,以帮助模型理解和处理语言信息。
优点: 直观、可解释性强,人为定义的语言规则可以直接影响模型的行为,提高可控性。
2、隐式语言建模:
通过学习获取: 隐式语言建模是指让模型通过学习大量数据来获取语言结构和规律,而非直接引入人为定义的规则。在深度学习中,这通常通过神经网络内部学习到的表示来实现。
例子: 利用深度学习模型(如循环神经网络、Transformer)对大规模语料进行训练,模型通过学习语言数据的统计特性,自动学到语法结构和语义信息。
优点: 更加灵活,适应性强,能够从数据中学到更复杂的语言模式,适用于不同领域和任务。
显式和隐式:
在深度学习中,显式(Explicit)和隐式(Implicit)通常用于描述模型对特定信息的处理方式。
1、显式:
定义明确: 显式方法直接建模或处理目标信息,将其纳入模型的计算过程,并在模型中有明确的表示。这通常通过直接引入相关的特征、规则、或者模型参数来实现。
清晰可见: 相关信息在网络结构或损失函数中的表示是明显可见的,可以通过查看模型的架构或参数来理解模型对该信息的处理过程。
直接控制: 显式方法让我们能够更直接地控制模型对特定信息的处理,提供更多的可解释性和可控性。
2、隐式:
通过学习获取: 隐式方法则通过让模型自己学习目标信息,而非直接引入明确的表示或规则。这可能通过网络的内部学习、嵌入空间、或其他方式实现。
不直观: 对于观察者而言,模型对目标信息的处理方式并不直接可见或清晰,因为这些信息可能以模型内部的参数状态、激活模式等形式存在。
灵活性: 隐式方法通常更加灵活,因为它们可以根据数据自动调整学习到的特征,适应不同任务和数据分布。
显式与隐式的比较:
1、显式的优势:
可解释性: 由于明确引入了语言结构或规则,显式方法通常更容易解释和理解。
可控性: 可以直接通过修改规则或结构来调整模型的行为。
2、隐式的优势:
灵活性: 隐式方法更灵活,能够从大量数据中学到复杂的模式,适应性强。
自适应: 不需要人工干预,模型可以自适应不同的任务和领域。
模型详解

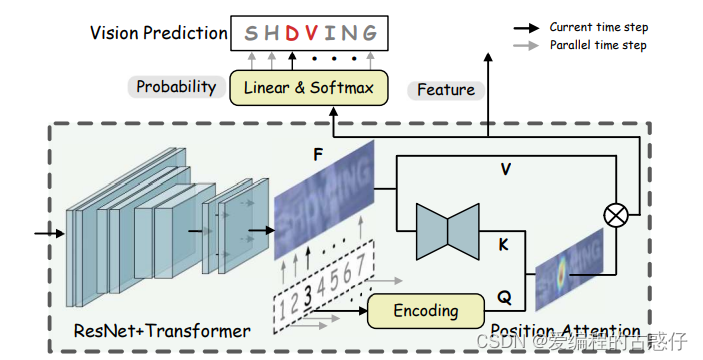
从上图不难看出模型主要分为3部分:视觉模型,语言模型和融合部分。
1、首先输入图像到视觉模型,提取图像特征以及输出预测结果;
2、将视觉模型的预测结果送入语言模型来提取语言特征并预测结果;
3、将视觉模型的视觉特征和语言模型的语言特征进行融合来得到融合的预测结果;
4、融合的预测结果再送入语言模型,迭代地进行细化,以得到最终的预测结果。

BaseVision:这是一个视觉模型的基础部分。它包括了一个ResTranformer,这个ResTranformer包含了一个ResNet和一个Transformer。
ResTranformer:这个部分将ResNet(一个经典的图像分类模型)和Transformer(用于处理序列数据的模型)结合起来,以实现对图像和语言的联合处理。这个结构可以处理输入图像并产生视觉特征,然后将这些特征传递给Transformer来与语言信息进行交互。
ResNet:这是一个残差网络,用于提取图像的特征。它包含了几个残差块(BasicBlock),每个残差块包含了卷积层(Conv2d)和批归一化层(BatchNorm2d)。
Transformer:这是一个用于处理序列数据的模型,通常用于自然语言处理。这里的Transformer被用于对视觉特征进行进一步处理,并将其与语言信息结合起来。
BCNLanguage:这是一个处理语言信息的部分。它包括一个简单的线性投影层(Linear)来将语言信息投影到与视觉特征相同的维度,并且使用了TransformerDecoder来进一步处理语言信息。
BaseAlignment:这是一个对齐模块,用于将视觉和语言信息对齐,以便进行联合训练或联合推理。它包括一个线性投影层(w_att)来对视觉和语言信息进行加权融合,以及一个用于分类的线性层(cls)。
综上所述,这个网络结构通过将ResNet和Transformer相结合,实现了对图像和语言信息的联合处理,从而能够在视觉和语言任务上取得良好的性能。
视觉模型
组成:
视觉模型由两部分组成:主干网(backbone)和位置注意力模块。
主干网采用了 ResNet(残差网络)作为特征提取网络,用于从输入图像中提取视觉特征。
位置注意力模块基于 Transformer 单元,用于序列建模网络,将主干网提取的特征转换为字符概率序列。
工作原理:
对于输入图像 x,通过主干网提取特征,得到大小为 H×W×C 的特征图,其中 H 和 W 分别表示图像的高度和宽度, C 表示特征的通道数。具体公式如下
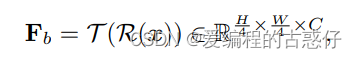
位置注意力模块基于查询范式(query paradigm),将视觉特征转换为字符概率。这意味着它根据字符的位置对特征进行编码,并将其转换为字符的概率序列。具体地,通过位置编码将字符的顺序信息嵌入到特征中,并使用 Transformer 单元对特征序列进行建模,最终得到每个字符的概率预测。

总体而言,该视觉模型利用了 ResNet 和 Transformer 单元的强大特性,通过主干网提取图像特征,然后通过位置注意力模块将这些特征转换为字符概率序列,从而实现对图像中文本的识别。
语言模型(BCN)
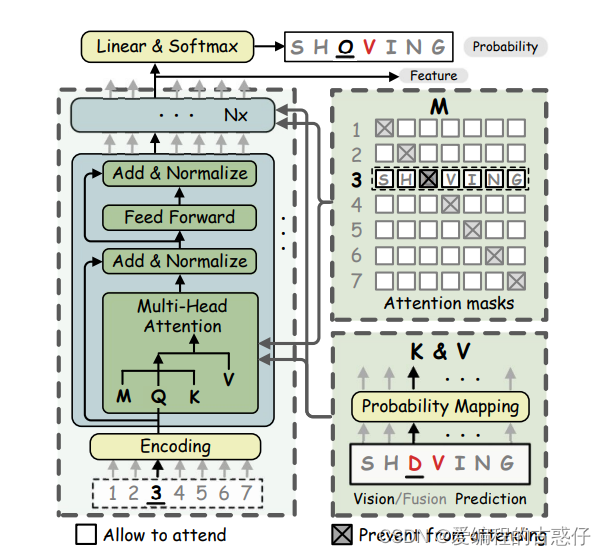
BCN(Bidirectional Context Network)是一个变种的 L 层 Transformer 解码器。每一层 BCN 都由多头注意力和前馈网络组成,接着是残差连接和层归一化。与普通的 Transformer 不同,字符向量被输入到多头注意力模块而不是网络的第一层。此外,多头注意力模块中的注意力 mask 被设计成屏蔽当前字符自身,避免泄露信息。BCN 的注意力操作相关公式如下:

其中,Q是字符顺序的位置编码,在第一层是位置编码,在最后一层是前一层的输出。K,V是从字符概率 P(yi)获得的,而 Wl是线性映射矩阵。M是注意力 mask 矩阵,用于防止当前字符自身进行注意力计算。将 BCN 层堆叠成深层架构后,文本 y 的双向表示 Fl就确定了。
BCN 通过以填空方式指定注意力 mask,能够更优雅地学习到比单向表示更强大的双向表示。此外,由于采用了类似 Transformer 的架构,BCN 可以独立并行地进行计算,并且比集成模型更高效,因为只需要一半的计算量和参数。
小辉问:能不能说说attention mask?
小G答:在Transformer模型中,注意力掩码主要用于确保在解码器部分生成目标序列时不会看到未来的信息。这是因为在解码器中,模型需要逐步生成目标序列的每个元素,并且在每个时间步只能访问已生成的部分。因此,注意力掩码用于限制模型在自注意力计算中只能关注当前和之前的位置,而不能访问未来位置的信息。
需要注意的是,通常情况下只有解码器部分会使用注意力掩码。但是在某些情况下,例如在BERT等双向预训练语言模型中,也会在编码器部分使用注意力掩码,以确保模型在预训练阶段不能“看到”整个输入序列的信息,从而避免信息泄漏。
融合模块
该模型通过门控机制来进行最终决策,以使视觉特征和语言特征保持一致。门控机制是一种常见的技术,用于动态地调节两个输入之间的权重,以产生合成的输出。在这里,门控机制的目的是确定视觉特征和语言特征在最终决策中的贡献程度。具体来说,门控机制的公式如下所示:
![]()
其中:
G 是门控向量,表示视觉特征和语言特征的权重;
σ 是sigmoid激活函数,用于确保门控向量中的值在0和1之间;
[Fv,Fl] 表示将视觉特征Fv和语言特征 Fl连接起来,形成一个合并的特征向量;
Wf是一个权重矩阵,用于将合并的特征向量映射到门控向量的维度上。
然后,使用门控向量G 来计算合成特征Ff
![]()
其中,⊙ 表示逐元素相乘,用于将门控向量应用于视觉特征和语言特征,以生成最终的合成特征。
迭代矫正
Transformer的并行预测需要噪声输入,噪声输入通常是视觉预测或视觉特征的近似值。具体而言,如模型架构图中,在双向表示下,P(“O”)的期望条件为“SH-WING”。但是由于环境的模糊和遮挡,VM得到的实际情况是“SH-VING”,其中“V”成为噪声,损害了预测的置信度。VM中的错误预测越多,对LM影响就会越大。
为了解决噪声输入的问题,我们提出迭代LM,LM重复执行M次,对y进行不同的分配。对于第一次迭代,yi=1是VM的概率预测。在后续迭代中,yi≥2为上次迭代中融合模型的概率预测。通过这种方法,LM能够迭代校正视觉预测。
另一个观察结果是基于Transformer的方法通常存在长度不对齐的问题,即如果字符数与ground truth不对齐,Transformer很难纠正视觉预测。填充掩码是用来过滤文本长度以外的上下文的固定格式,这让填充掩码在实现上不可避免的会造成长度无法对齐的问题。我们的迭代LM可以缓解这一问题,通过将视觉特征和语言特征多次融合,逐步细化预测的文本长度。
模型训练





![[深度学习] 卷积神经网络“卷“在哪里?](https://img-blog.csdnimg.cn/direct/468fb6de5e9d4190868dbb2d6298fbf7.png)