Open-Set Text Recognition via Character-Context Decoupling
Abstract
- 开放集文本识别任务是一个新兴的挑战,在评估过程中需要额外的识别新字符的能力。我们认为,当前方法性能有限的一个主要原因是上下文信息对单个字符视觉信息的混淆效应。在开放集场景下,上下文信息中的顽固性偏差可能会传递到视觉信息中,从而影响分类性能。本文提出了一个字符-上下文解耦框架,通过分离上下文信息和字符视觉信息来缓解这一问题。语境信息可以分解为时间信息和语言信息。在这里,模拟字符顺序和单词长度的时间信息被一个分离的时间注意模块隔离。通过解耦上下文锚定机制将建模n-gram和其他语言统计的语言信息分离。各种定量和定性实验表明,我们的方法在 open-set, zero-shot, and close-set 文本识别数据集上取得了令人满意的性能。
Introduction
-
文本识别是一项研究得很好的任务,在各种应用中得到了广泛的应用。大多数现有的文本识别方法都假设测试集中的字符被训练集覆盖。此外,还假设训练集和测试集之间的上下文信息是一致的。如果不重新训练模型,这些方法不适用于识别未见过的字符。然而,随着语言的发展,在某一时期某一地区会频繁出现一些新奇的符号(如生僻字符、表情符号、外来文字符等)。例如,由于全球化,在场景文本图像中经常可以看到外国字符。
-
因此,当出现“新字符”时,如果模型需要重新训练,这是不可行的。该任务被定义为开放集文本识别任务[Towards open-set text recognition via label-to-prototype learning],是 open-set 识别的一个特定领域[Toward open set recognition],也是鲁棒模式识别的一个典型案例[Towards robust pattern recognition: A review]。目前,一些基于视觉匹配的文本识别方法能够识别文本行中的新字符[Zero-shot Chinese text recognition via matching class embedding,Adaptive text recognition through visual matching.]。
-
然而,这些开放集文本识别方法容易受到从训练集中捕获的上下文信息的影响。这一现象可以在显著性图(下图)【GitHub - MisaOgura/flashtorch: Visualization toolkit for neural networks in PyTorch! Demo -->】中看到,文献[On vocabulary reliance in scene text recognition]也观察到了这一现象。在这种情况下,每个字符的特征表示总是与语言信息混合在一起。这可能有利于训练和评估之间的上下文信息偏差可以忽略不计的场景,因为一些字符(例如“0”和“O”)很难仅通过字符视觉信息(字形形状)来区分。然而,在开放集场景下,上下文信息可能严重偏离训练集。因此,现有模型可能会根据训练集错误地将一个字符“纠正”为更适合上下文的错误字符。
-

-
每个时间戳的“显著区域”示意图,显示了模型所处的位置。基础模型(上)倾向于从上下文中寻求帮助,而我们的框架(下)更侧重于局部特征。
-
-
为了减轻上下文信息对开放集文本识别的影响,我们提出了一个字符-上下文解耦框架,允许字符视觉信息和上下文信息的显式分离。
语境信息进一步分解为时间信息和语言信息。一般来说,时间信息对单词中字符的数量和顺序进行建模,而语言信息对n-gram和其他语言统计进行建模。在此基础上,引入分离时间注意模块(DTA)对时间信息进行建模,并将其从视觉特征中分离出来。此外,还提出了一种解耦上下文锚定机制(DCA)来“explain away”字符视觉信息中的语言信息。综上所述,我们的框架减少了训练集上下文信息对视觉特征的混淆效应,使其不容易受到开放集场景下难以处理的上下文信息偏差的影响。本文的主要贡献总结如下:- 提出了一个字符-上下文解耦框架,该框架通过减少上下文信息对词级样本中小说字符视觉表示的影响来改进词级开放集文本识别。
- 提出了一种分离的时间注意力模块,减少了时间信息对视觉特征提取器的影响。
- 提出了一种解耦上下文锚点机制,实现了语言信息与视觉特征提取器的分离。
Related Work
- 开放集文本识别作为开放集识别的一个特定领域,是一项需要模型识别测试集单词的任务,这些测试集单词可能包含训练集中未见的新字符。已经提出了一些方法来解决这个问题。Wan等[Adaptive text recognition through visual matching]提出将单词图像的视觉特征与字形图像进行匹配,并使用类聚合器对匹配结果进行采样。由于字形图像和相似图的大小增长,他们的方法在大规模字符集上不能很好地扩展。另一方面,OSOCR[Towards open-set text recognition via label-to-prototype learning]使用ProtoCNN从单个字形生成类中心,并将类中心与单词图像的序列化视觉特征进行匹配。基于字符的原型生成设计允许通过对标签集进行小批量处理来降低训练成本,因此可以应用于更大的标签集。然而,这些方法并没有提供有效的方法来分离上下文信息,从而限制了开集词级识别的性能。[On vocabulary reliance in scene text recognition]也研究了上下文信息的影响,这表明无rnn的方法也容易产生上下文信息偏差。因此,我们提出了一个框架,将上下文信息从字符视觉信息中分离出来,以提高开放集视觉匹配的准确性。
- 传统的close set 文本识别任务可以看作是一种特殊情况,即测试集没有新字符。在大多数传统的文本识别方法中,类中心大多在线性分类器中被建模为权重,而视觉信息和上下文信息被一起建模,没有明确的分离。最近,更多的方法选择采用专门的后处理成型模块[Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,Towards accurate scene text recognition with semantic reasoning networks]来建模上下文信息。
- zero-shot 字符识别任务是开放集文本识别的另一种特殊情况。许多方法建议用唯一的结构表示(例如,偏旁部首或笔画序列)对每个字符进行编码以进行预测。最近,一些方法展示了韩语字符识别和全词识别的能力。尽管这些方法在处理大型标签集时表现相当好,但它们需要特定于语言的字符结构表示,因此只能使用相应的语言。相反,像[Cross-modal prototype learning for zeroshot handwriting recognition]这样的无结构方法只需要每个字符的字体模板(或打印样本)。这种方法有利于那些对字符构成知之甚少的场景,例如,古代甲骨文文字。我们的方法遵循无结构方案,并通过引入字符-上下文解耦进一步实现可靠的单词识别能力。
Proposed Method
- 在这项工作中,我们提出了一个字符-上下文解耦框架(如下图所示),通过使用分离的时间注意力模块和解耦的上下文锚定机制分离和隔离字符视觉信息和上下文信息,来减少开放场景下上下文信息偏差的影响。框架及其优化首先在3.1节中制定。然后,3.2节将详细解释不太直观的解耦上下文锚机制。最后,开放集字符-上下文解耦网络(OpenCCD)作为3.3节中框架的一个示例实现。
-

-
我们提出的字符-上下文解耦框架的实现。在该框架中,首先使用DSBN-Res45 Network提取样本和字符模板的视觉表示,然后使用Detached Temporal Attention模块预测单词长度并对每个时间戳的视觉特征 x [ t ] x_{[t]} x[t] 进行采样。视觉预测是通过将原型(注意力减少的模板特征)与开放集分类器匹配来实现的。最后,使用解耦上下文锚定模块对视觉预测进行调整,在开放集场景下,当存在难以处理的语言信息时,不进行调整。
-
Character-Context Decoupling Framework
-
该框架以样本(词级图像) img 和字符集 E 作为输入,输出预测词 y ^ : ( y ^ [ 0 ] ; . . . ; y ^ [ t ] ) \hat y:(\hat y_{[0]};...;\hat y _{[t]}) y^:(y^[0];...;y^[t]) 在给定样本和字符集的最大概率下,
-
y ^ = a r g max y P ( y ∣ x , E ; θ ) , ( 1 ) \hat y=arg\max_yP(y|x,E;\theta),(1) y^=argymaxP(y∣x,E;θ),(1)
-
其中 x 是样本中所有字符的视觉特征表示。为了书写方便,我们省略了 E 和 θ。在我们的框架中,我们利用总概率定律,将 P ( y ∣ x ) P(y|x) P(y∣x) 展开,预测长度为 l,
-
P ( y ∣ x ) = ∑ l = 1 m a x L P ( l ∣ x ) P ( y ∣ x , l ) , ( 2 ) P(y|x)=\sum_{l=1}^{maxL}P(l|x)P(y|x,l),(2) P(y∣x)=l=1∑maxLP(l∣x)P(y∣x,l),(2)
-
其中 maxL 是单词的最大长度。与大多数现有的文本识别框架使用词尾、分割或空白来处理长度不同,我们的框架明确地预测了长度。 P ( y ∣ x ; l ) P (y|x;l) P(y∣x;l) 可以通过提出的解耦上下文锚定机制(详见3.2节)进一步分解为上下文预测和视觉预测;
-
P ( y ∣ x , l ) = ∏ i = 1 l P ( y [ t ] ∣ x [ t ] ) ∏ l = 1 l ∫ c ∈ C [ t ] P ( y [ t ] ∣ c ) P ( c ∣ x , l ) P(y|x,l)=\prod_{i=1}^lP(y_{[t]}|x_{[t]})\prod_{l=1}^l\int^{c\in C_{[t]}}P(y_{[t]}|c)P(c|x,l) P(y∣x,l)=i=1∏lP(y[t]∣x[t])l=1∏l∫c∈C[t]P(y[t]∣c)P(c∣x,l)
-
其中,c 为字符的共同 “语境 ” (语言信息),x 为输入图像中所有字符的视觉信息建模, x [ t ] x_{[t]} x[t] 对应第 t 个字符的字符视觉信息。因此,优化目标将是最大化基真标记序列 y ∗ y^∗ y∗ 的对数似然 l o g P ( y ∗ ∣ x ) logP(y^∗|x) logP(y∗∣x),
-

-
其中 Llen、Lvis 和 Lctx 是三个对数似然项对应的交叉熵损失。步骤(a)成立,因为只有在正确预测长度的情况下才能预测正确的标签。
-
Decoupled Context Anchor Mechanism
-
在这项工作中,我们提出了一种解耦上下文锚定机制来建模和分离语言信息 c 在每个时间戳 t 上对字符 y [ t ] y_{[t]} y[t] 的影响。
-

-
解耦上下文锚机制的因果图
-
-
假设1 (A1)我们假设语言信息在所有时间戳上都是输入视觉信息和预测输出的共同原因(见上图).我们将样本图像建模为标签 y 的“渲染”结果。同样,我们假设标签(单词)是根据语言信息 c 生成的,使标签 y 成为 c 的因果结果。因此,语言上下文 c 和字符级视觉信息 x [ t ] x_{[t]} x[t] 是影响时间戳 t , y [ t ] y_{[t]} y[t]概率的仅有的两个直接因素。
- P ( y [ t ] ∣ x [ t ] , x , y [ t − 1 ] , . . . , y [ 0 ] , l , c ) = P ( y [ t ] ∣ x [ t ] , c ) ; ( 5 ) P(y_{[t]} |x_{[t]},x,y_{[t−1]},...,y_{[0]},l,c) = P(y_{[t]}|x_{[t]},c);(5) P(y[t]∣x[t],x,y[t−1],...,y[0],l,c)=P(y[t]∣x[t],c);(5)
-
假设2 (A2)给定字符 y [ t ] y_{[t]} y[t],字符的形状(字符视觉信息)与其上下文(语言信息)是独立的,即:
-

-
这个假设意味着语言信息不会影响单词的“样式”(字体、颜色、背景等),这在样式和内容随机匹配的大多数合成数据集中通常成立。
-
-
Theorem 1: The Anchor Property of Context(定理1:上下文的锚定属性):给定假设A1,给定图像x及其长度l, P ( y ∣ x ; l ) P(y|x;l) P(y∣x;l),可以写成所有时间戳的“锚定预测”的乘积,即:
-
P ( y ∣ x ; l ) = ∏ t = 1 l ∫ c ∈ C [ t ] P ( y [ t ] ∣ x [ t ] ; c ) P ( c ∣ x ; l ) ; P (y|x;l) = \prod ^l_{t=1}\int^{c\in C_{[t]}} P(y_{[t]}|x_{[t]};c) P (c|x;l); P(y∣x;l)=t=1∏l∫c∈C[t]P(y[t]∣x[t];c)P(c∣x;l);
-
在这里,积分项可以解释为“锚定预测” P ( y [ t ] ∣ x [ t ] ; c ) P(y_{[t]} |x_{[t]};c) P(y[t]∣x[t];c) 覆盖所有可能的上下文 c,这类似于隐藏锚机制。因此,我们称这个定理为上下文的锚属性。
-
-
Theorem 2: The Separable Property of Linguistic Information and Character Visual Information(定理2:语言信息与文字视觉信息的可分离性):假设A2,字符视觉信息对标签 P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t]) 的影响和语言信息 P ( y [ t ] ∣ c ) P(y_{[t]} |c) P(y[t]∣c) 的影响与上下文预测 P ( y [ t ] ∣ x [ t ] ; c ) P(y_{[t]} |x_{[t]};c) P(y[t]∣x[t];c) 是可分离的,
-
其中, P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t]) 表示 $y_{[t]} $对字符视觉信息 x [ t ] x_{[t]} x[t] 的预测概率, P ( y [ t ] ∣ c ) P(y_{[t]} |c) P(y[t]∣c) 表示语言信息引起的影响, P ( y [ t ] ) P(y_{[t]}) P(y[t]) 表示字符在训练集上的频率。该定理的证明见附录b。该定理表明,在特定条件下,字符视觉信息和语言信息对预测的影响是可以明确分离的。
-
直观地, P ( y [ t ] ∣ c ) P(y_{[t]} |c) P(y[t]∣c) “explains away”了来自基于视觉的预测 P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t]) 的语言信息。这种行为发生在我们的框架在训练期间的反向传播过程中,其中 Lctx 和 Lvis 的梯度被累积以更新特征提取器。这就是 Lctx 需要反向传播的原因,也使得 Lctx 成为一个正则化项,通过反向传播来增强网络的某些属性。这一特性将其与切割梯度的“两次查看”机制[Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,Towards accurate scene text recognition with semantic reasoning networks]区别开来。
-
Theorem 3: Decoupled Context Anchor Mechanism(定理3:解耦上下文锚机制):结合定理1和定理2,我们有解耦上下文锚机制,
-
该机制进一步允许在单词层面上明确分离语言信息和字符视觉信息,这为在训练集中学习到的语言信息建模和分离提供了一种方法,从而使特征提取器更多地关注字符视觉信息,而较少受到训练集语言信息的影响。考虑到定理1中揭示的锚属性和定理2的解耦性质,我们称这种机制为解耦上下文锚机制。


OpenCCD Network
-
在本节中,将给出开集字符-上下文解耦网络(OpenCCD,上文图)作为我们提出的框架的示例实现。这里,字符集 E : ( E v ; E c ) E:(E_v;E_c) E:(Ev;Ec) 由 Noto 字体 E v E_v Ev 的字形和字符 E c E_c Ec 的语义嵌入组成。该网络首先使用 DSBN 层构建的45层ResNet (Res45-DSBN)提取单词图像 img 和字形 E v E_v Ev 的视觉特征。它共享符号和单词图像之间的卷积层,同时保留特定于任务的批处理统计信息。三个层次的词特征( F l ; F m ; F h F_l;F_m;F_h Fl;Fm;Fh )和字形的最新特征映射 F h g F_h^g Fhg。原型(类中心) W v W_v Wv 是通过对 F h g F^g_h Fhg 应用几何注意而生成的。在训练过程中,我们在每次迭代中对 E v E_v Ev 进行小批量处理,以达到合理的训练速度。在评估过程中,整个数据集的视觉原型 W v W_v Wv 被预先缓存,因此原型生成产生很少的额外成本。
-
接下来,使用分离时间注意(DTA)模块来预测单词 P ( l ∣ x ) P(l|x) P(l∣x) 的长度,并引爆最大可能长度为 l ^ \hat l l^。然后DTA模块对有序字符级视觉特征x进行采样 ( x [ 0 ] ; . . . ; x [ l ^ ] ) (x_{[0]};...;x_{[\hat l]}) (x[0];...;x[l^]) 从特征映射Fh。然后由 open-set 分类器生成基于视觉的预测 P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t])。对于close-set 场景,语言信息导向的预测 P ( y [ t ] ∣ c ) P(y_{[t]} |c) P(y[t]∣c) 是通过解耦上下文锚(DCA)模块产生的。对于语言信息难以处理的开集场景, P ( y [ t ] ∣ c ) P(y_{[t]}|c) P(y[t]∣c) 被视为均匀分布,相当于只使用视觉预测。
-

-
拟议的分离式时间注意力模块。我们在时态注意力模块中分离出序列建模,并将卷积特征的梯度与时态注意力图进行归零。这里,GAP 表示全局平均池化。
-
-
Detached Temporal Attention: 在OpenCCD中,提出了分离时间注意模块(上图)来预测序列长度 P(l|x)。它还通过注意图A对特征图Fh中的字符进行排序和采样。该模块利用 FPN 对输入特征图中的全局时间信息进行建模,并将其解码为 A 和 P ( l ∣ x ) P(l|x) P(l∣x)。由于时间信息与单个字符形状(字符视觉信息)无关,该模块通过切割梯度w.r.t. $ P(l|x)$ 和A,将其从输入视觉特征映射中分离出来。然后,模块根据注意图 A 和最可能的长度 l ^ \hat l l^ ,将输入视觉特征映射 F h F_h Fh 分割为单个字符的视觉特征 x,只允许字符视觉信息通过 x 反向传播到 F h F_h Fh。 P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t]) 是将原型与字符级特征 x [ t ] x_{[t]} x[t] 进行比较得到的,
-

-
其中 ∣ x [ t ] ∣ |x_{[t]} | ∣x[t]∣ 为 x[t] 的L2-Norm,“[UNK]” 表示未知字符,α 为可训练的拒绝相似阈值。 S i m ( x [ t ] ; y [ t ] ) Sim (x_{[t]};y_{[t]}) Sim(x[t];y[t]) 定义为
-
S i m ( x [ t ] , y [ t ] ) : = max w v ∈ ψ ( y t ) ( c o s ( w v , x [ t ] ) ) Sim(x_{[t]},y_{[t]}):=\max_{w_v\in \psi(y_{t})}(cos(w_v,x_{[t]})) Sim(x[t],y[t]):=wv∈ψ(yt)max(cos(wv,x[t]))
-
其中 ψ \psi ψ 返回与标签 y[t] 相关的所有原型 ψ ( y [ t ] ) ⊂ W v \psi(y_{[t]}) ⊂ W_v ψ(y[t])⊂Wv,每个原型 w v w_v wv 对应字符 y [ t ] y_{[t]} y[t] 的一个 “案例”。
-
-
Decoupled Context Anchor : 我们没有采用变分自动编码器来估计语言信息的分布,也没有用 MonteCarlo 来估计积分,而是用预测的上下文 c ^ \hat c c^ 来近似积分,这与传统的锚机制类似,只使用具有最大预测可能性的锚、
-
∫ c ∈ C [ t ] P ( y [ t ] ∣ c ) P ( c ∣ x , l ) ≈ P ( y [ t ] ∣ c ^ ) \int^{c\in C_{[t]}}P(y_{[t]}|c)P(c|x,l)≈P(y_{[t]}|\hat c) ∫c∈C[t]P(y[t]∣c)P(c∣x,l)≈P(y[t]∣c^)
-
结合公式 21,在时间戳 t 处出现预测字符的概率近似为
-
P ( y [ t ] ∣ x ) ≈ P ( y [ t ] ∣ x [ t ] ) P ( y [ t ] ∣ c ^ ) P(y_{[t]}|x)≈P(y_{[t]}|x_{[t]})P(y_{[t]}|\hat c) P(y[t]∣x)≈P(y[t]∣x[t])P(y[t]∣c^)
-
-
由于语言信息大多与标签相关,因此我们从预测标签而非特征图中估计语言信息 c ^ \hat c c^。更具体地说,该模块重新使用估计的字符概率分布 Y ∈ ( 0 ; 1 ) l × M : ( P ( Y [ 0 ] ∣ x [ 0 ] ) ; . . . ; P ( y [ l ] ∣ x [ l ] ) ) Y \in (0; 1)^{l×M} : (P(Y_{[0]}|x_{[0]}); ...; P(y_{[l]} |x_{[l]})) Y∈(0;1)l×M:(P(Y[0]∣x[0]);...;P(y[l]∣x[l])) 来处理每个时间戳 t 上的字符视觉信息,而 P ( y [ t ] ∣ x [ t ] ) : ( P ( y [ t ] 0 ∣ x [ t ] ) ; . . . ; P ( y [ t ] M ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) : (P(y^0 _{[t]} |x_{[t]});...; P(y^M_{[t]} |x_{[t]}) P(y[t]∣x[t]):(P(y[t]0∣x[t]);...;P(y[t]M∣x[t]) 是时间戳 t 上所有字符的概率分布。然后,利用应用于字符嵌入期望值的 4 层 Transformer 编码器 ,对 c ^ \hat c c^ 进行估计、
-
c ^ = T r a n s ( Y E c ) \hat c=Trans(YE_c) c^=Trans(YEc)
-
其中, E c ∈ R M × C E_c \in R^{M×C} Ec∈RM×C 是训练集中所见字符的语义嵌入,因此 Y E c Y E_c YEc 表示期望值。Trans 表示 4 层变换器编码器。最后,$P(Y_{[t]} |\hat c) $ 是通过比较字符嵌入 E c E_c Ec 和 c ^ \hat c c^ 来估计的、其中,σ 是软最大函数。
-
P ( Y [ t ] ∣ c ^ ) = σ ( c ^ E c T ) [ t ] P(Y_{[t]}|\hat c)=σ(\hat cE^T_c)_{[t]} P(Y[t]∣c^)=σ(c^EcT)[t]
-
-
优化 由于公式 12 将积分简化为标准分类问题,公式 4 中的 Lctx 可以像 Llen 和 Lvis 一样作为交叉熵损失来实现。因此,OpenCCD 可以通过三个等权重的交叉熵损失进行优化。
Experiments
- 这项工作基于 OSOCR ,我们发布了代码[https://github.com/lancercat/VSDF] 和数据集[https://www.kaggle.com/vsdf2898kaggle/osocrtraining]。我们在所有三种情况下的基准上进行了实验:开集词级识别、零镜头字符识别和传统的闭集词级识别基准。此外,我们还对开集词级识别进行了消减研究。我们使用 AdaDelta 优化器,学习率设定为 10-2,每 200k 次迭代递减一次。对于单词识别任务,我们提供了一个 "大型 "网络,以获得更接近 SOTA 方法的速度-性能权衡曲线,其中大型网络在 ResNet45-DSBN 主干网中有更多的潜通道。
Open-Set Text Recognition
-
我们使用一组中文文本识别数据集作为训练集,并使用 OSOCR 的 MLT 日文子集作为测试集,所有模型都经过了 200k 次迭代训练。下表 和 SOTA 方法的定量性能和定性样本见后文图 。结果表明,与 OSOCR 相比,整体性能有了明显提高。
-

-
开放文本识别数据集的详细性能分析。性能数据以字符准确率(上)/行准确率(下)的方式列出。
-
-
该模型对新字符(下图中黄色文本)(如独特的 Kanjis 和 Kanas)具有一定程度的鲁棒性。
-

-
开放集文本识别任务的结果示例。图中显示了在 “假名(Kana)”、"唯一汉字(Unique Kanji) "和 "共享汉字(Shared Kanji (close-set))"情况下的定性性能。每组的结果用两行表示,上行显示成功案例,下行显示失败案例。白色文本表示看到的字符,黄色表示新字符,红色表示识别错误,绿色表示正确结果,紫色块表示拒绝结果。
-
-
结果表明,形状接近的字符是最主要的错误来源。造成这种现象的原因可能是用硬标签(与软标签相反)将所有负面类别推向相同的位置,这在细粒度分类中也有提及。模糊、文本艺术可能是失败案例的另一个主要原因,这在意料之中,因为语言信息在开放集场景下是难以处理的,因此无法用于恢复视觉上无法区分的字符。
Ablative Study
-
我们对开放集文本识别挑战进行了消减研究,以验证解耦字符视觉信息和上下文信息的效果。在本节中,我们在同一台服务器上对所有消减模型进行训练,以尽量减少混杂因素。结果(下图 )显示,利用分离时空注意力模块分离时空信息可以提高开集识别性能。此外,利用 "解耦上下文锚点 "机制进一步分离语言信息也能提高识别性能。
-

-
拟议模块的消融研究。X 轴表示总迭代次数,Y 轴表示测试集准确率。应用每个模块后都能获得稳定的性能提升(红色:基本模型;绿色:分离字符视觉信息;蓝色:两者都分离)。
-
-
直观地看,测试集准确率曲线显示,这两种建议的方法在大多数迭代中都能带来稳定的性能提升。曲线的不稳定性是由行准确度指标造成的,其中一个错误的字符可能会影响整行的准确度。我们进一步进行了配对 t 检验,从数量上验证了性能改进的稳健性。使用 DTA 模块分离时间信息的 t 值为 2.00,p 值为 0.06;而使用 DCA 分离语言信息的 t 值为 5.87,p 值为 1.54 × 10-5。p 值表明,我们可以拒绝这两种方法的 “双侧”(无改进)零假设。因此,有强有力的证据表明,DTA 和 DCA 都能稳健地提高开放集识别性能。
-
下图 显示了我们的模型与基础模型的定性比较结果。与基础模型相比,我们的框架通过分离语言信息和字符视觉信息,在应对语言信息偏差方面表现出了良好的鲁棒性。
-

-
我们的方法与基础方法的比较。绿色表示预测正确,红色表示预测错误。黄色表示新字符,白色表示见过的字符。
-
Conventional Benchmarks
-
由于缺乏开放的文本识别基准,我们采用了两个研究较好的特例来对泛化能力和单词识别能力进行参考比较。在此,我们坚持使用每个相应社区中最常用的协议来训练、评估和衡量性能。
-
zero-shot 识别 按照业界的通用协议,我们在 HWDB 和 CTW 数据集上按照【Radical aggregation network for few-shot offline handwritten Chinese character recognition】进行了 zero-shot 识别基准测试。由于训练集的规模较小,我们对模型进行了 50k 次迭代训练。如下表 所示,与现有方法相比,我们的方法具有显著的性能优势。
-

-
HWDB 和 CTW 数据集的 zero-shot 字符识别准确率。* 表示需要 "online trajectory "数据。
-
-
下图中的定性样本显示了对风格多样性、轻微模糊和其他干扰因素的一定稳健性。这也表明,一些退化现象,如模糊或低对比度,并不一定会造成永久性的信息损失,只要有足够多的分布良好的训练数据,就可以逆转。我们将开放集单词识别与这一挑战之间的鲁棒性差异部分归因于潜在的特定语言 "图像风格 "偏差,这种偏差是由不同相机、不同相应地区的拍照习惯等因素造成的。
-

-
Zero-shot 汉字识别基准的结果示例。左边的数字表示用于训练的不同类别的数量。绿色表示正确的识别结果,红色表示错误的识别结果,紫色块表示拒绝的识别结果。注意,白色不表示见过的字符,所有测试字符均为新字符。
-
-
与 SOTA zero-shot 字符识别方法相比,这些实验证明了合理的泛化能力。这也证明了我们选择数据驱动的潜在表示法,而不是偏旁部首序列等模型驱动的表示法[Zeroshot handwritten Chinese character recognition with hierarchical decomposition embedding, Zero-shot Chinese character recognition with stroke-level decomposition]是正确的。
我们的方法不需要字符结构方面的知识,因此可用于识别不知道或不适用这类知识的字形和其他连字符。 -
Close-Set Benchmarks 最后,我们在传统的 close-set 基准上进行了实验,将该方法与 SOTA 文本识别方法的性能和速度进行了比较。我们报告了无词典性能(下表 )和基于词典的性能 [Adaptive text recognition through visual matching]。更具体地说,模型是在 MJ 和 ST 上按照 SOTA 方法的主流技术进行训练的。评估中使用了 IIIT5k 、SVT 、ICDAR 2003 、ICDAR 2013 和 CUTE 。由于训练集较大,我们的模型进行了 800k 次迭代训练。
-

-
在传统密集基准上的性能。* 表示字符级注释,+ 表示多批次评估。
-
-
我们首先将我们的方法与其他开放集文本识别方法进行了比较,这些方法在下表 中报告了它们在基于词库的基准测试中的表现,同时还与一些流行的封闭集识别方法进行了比较。结果表明,与其他开放集方法相比,我们的方法保持了合理的封闭集性能。
-

-
c 表示close-set 方法,∗ 表示使用了 MJ 和 ST 以外的数据集。
-
-
在这一基准上,我们的方法与 SOTA 密集方法的性能也很接近。其次,使用无字典协议进行的比较如上上表所示,尽管性能略低于重型 SOTA 密集识别方法,以换取更快的速度,但我们的方法与轻量级文本识别方法相比表现出了竞争力。按照社区惯例[What is wrong with scene text recognition model comparisons? dataset and model analysis, Scene text recognition from two-dimensional perspective],运行速度被用来衡量方法的成本。在配备 RTX 2070 移动 GPU(7 TFlops)的笔记本电脑上,我们的方法可以达到 67 FPS 的单批处理速度和 255 FPS 的多批处理速度,而仅使用 2.5 GiB Vram。这证明我们的模型在传统任务中是一种具有竞争力的轻量级方法。
Limitations
- 尽管我们的方法在所有测试场景中都表现出了合理的性能,但仍然存在一些局限性。在框架方面,我们做了一些强有力的假设。首先,我们假设视觉特征提取器可以通用于新的语言。尽管与基于激进派的方法相比,我们的方法显示出了更好的语内转移能力,但假设其具有强大的语际转移能力未免有些强人所难。这些局限性可能是造成 Kanas 和 Unique Kanjis 之间性能差距的原因。在实现方面,我们的方法使用较小的输入(32 ∗ 128 个补丁),并且缺乏有效的修正模块 。这导致有效的文本区域非常小,从而限制了倾斜和弯曲样本的性能。我们将在下一步工作中讨论如何解决这些限制。
Conclusion
- 在本文中,我们提出了用于开集文本识别的字符-上下文解耦框架,该框架理论上合理,实验上可行。具体来说,消融研究和对比实验验证了我们的实现是一种有效的开集文本识别方法,也是一种在闭集场景下可用于生产的轻量级文本识别方法。
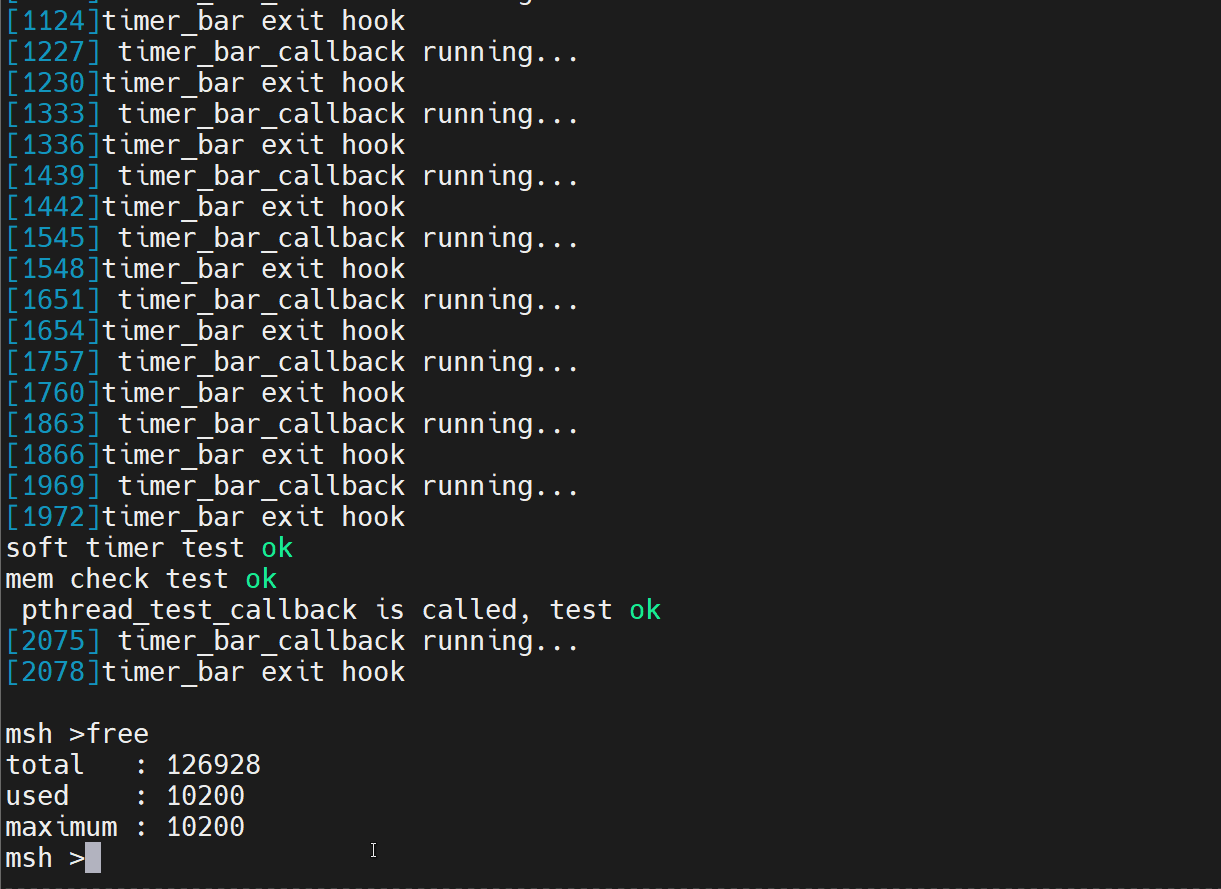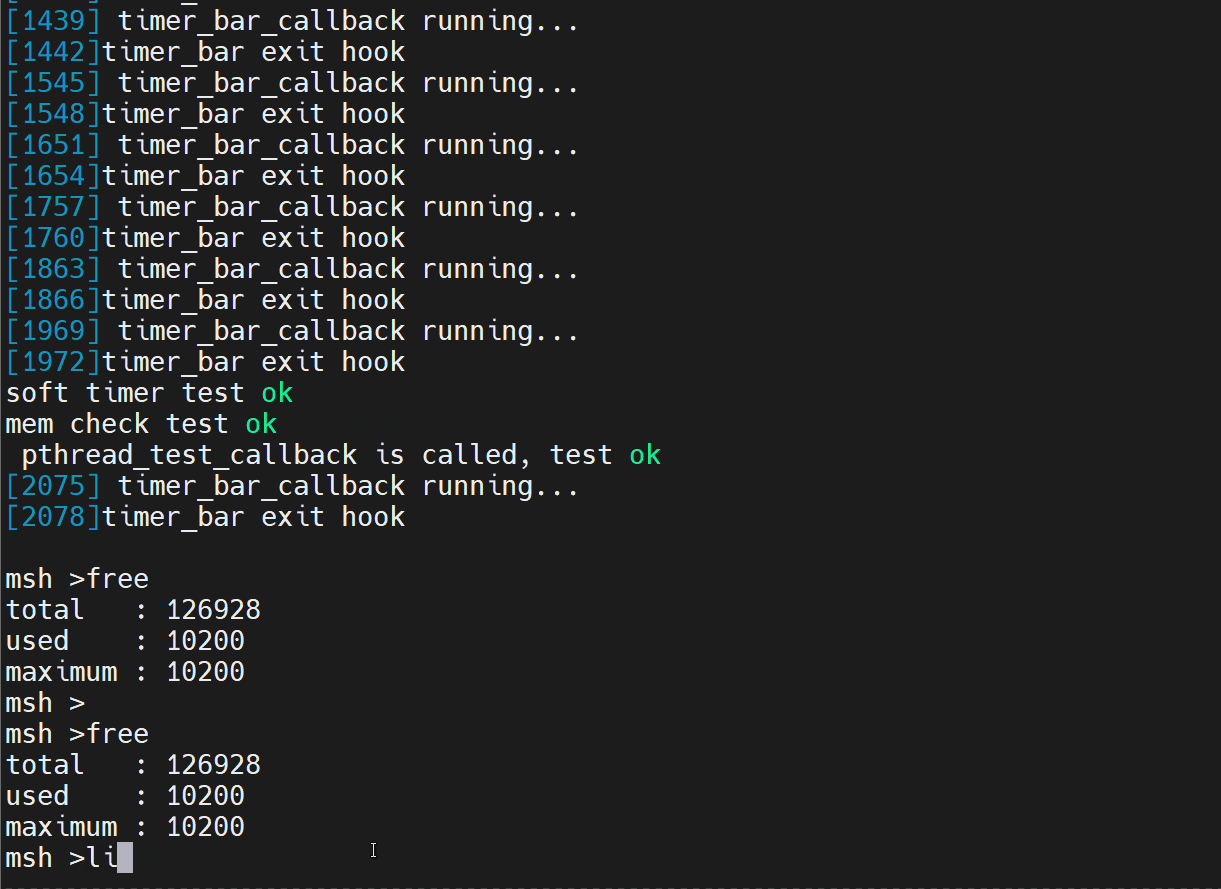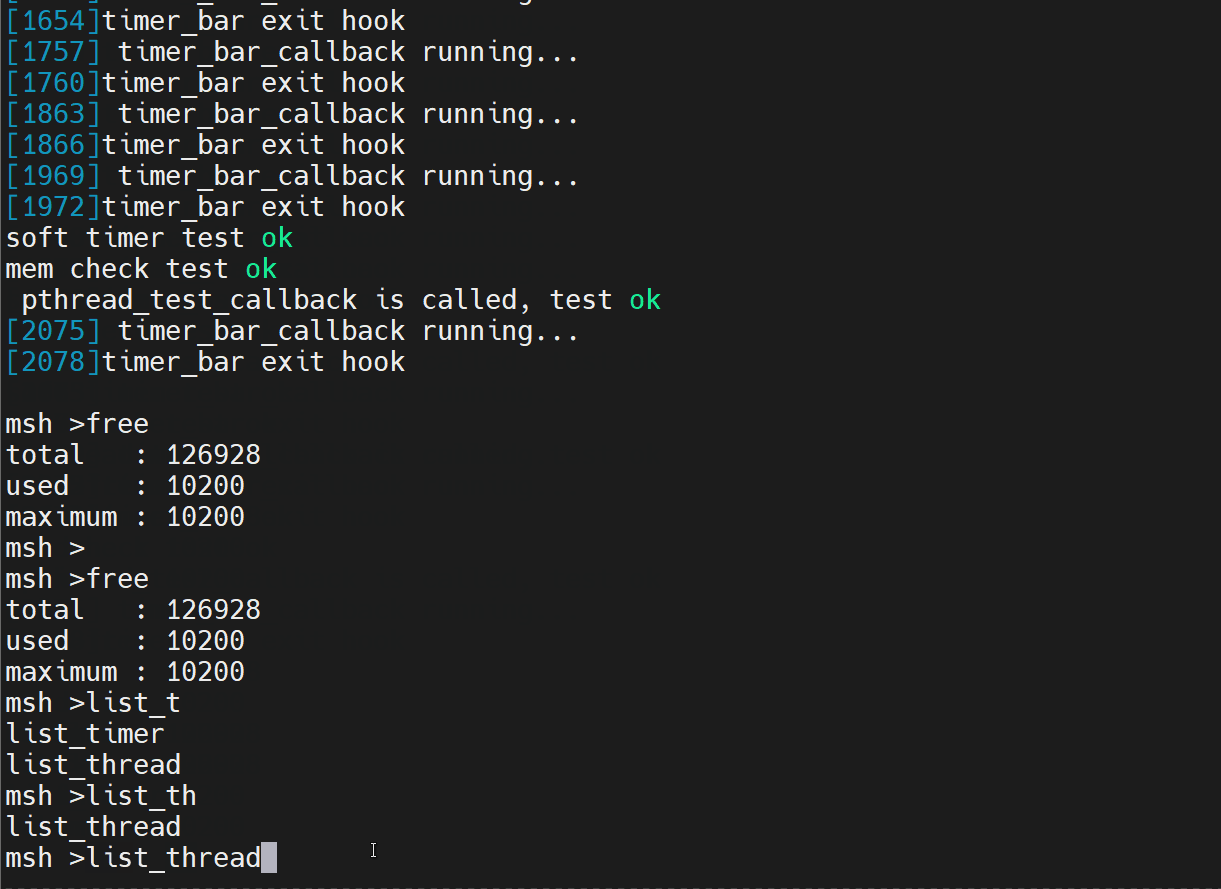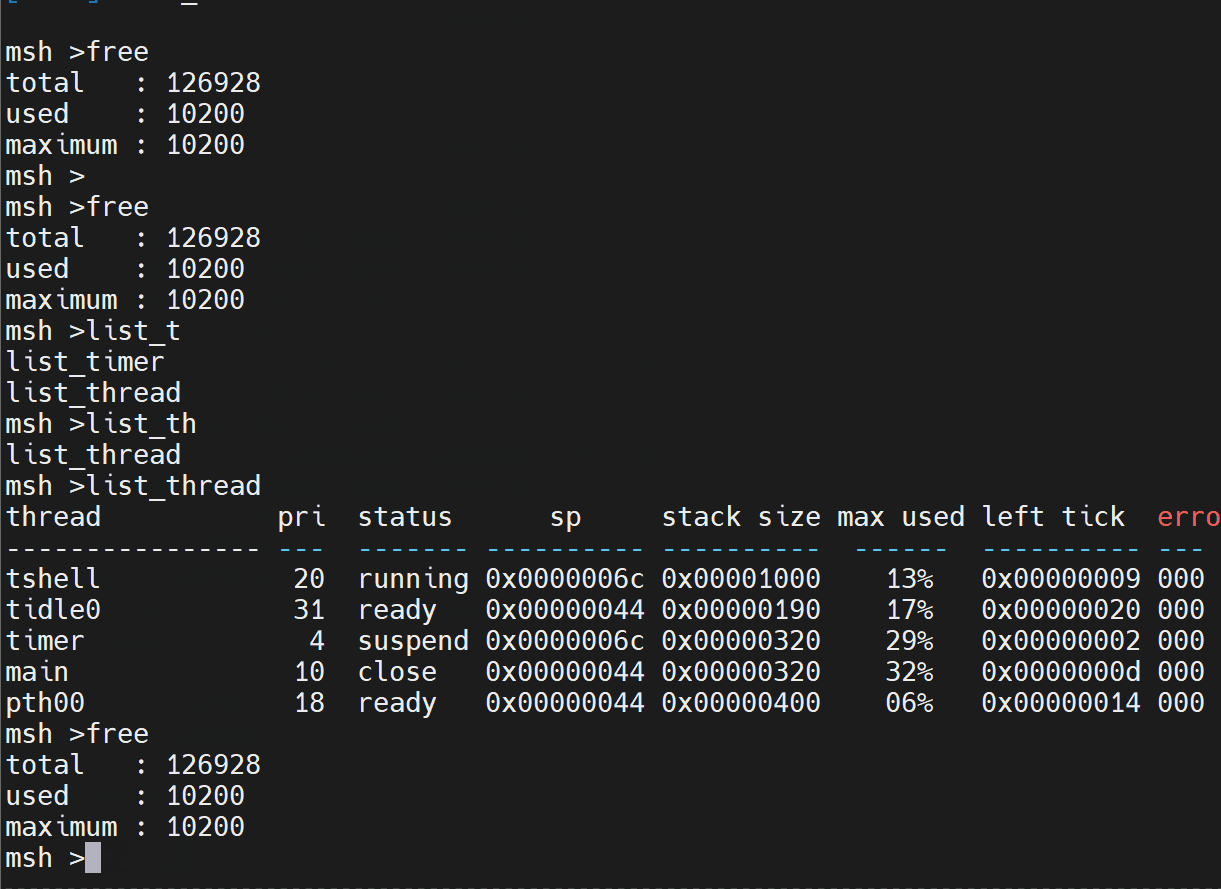
- mstsc
A. Proof of Theorem 1
- 假设 1 (A1) 我们假设语言信息是输入视觉信息和所有时间戳预测输出的共同原因. 我们将样本图像建模为标签 y 的 "渲染 "结果。此外,我们假设标签(单词)是根据语言信息 c 生成的,因此标签 y 是 c 的因果结果。因此,语言上下文 c 和字符级视觉信息
x
[
t
]
x_{[t]}
x[t] 是影响时间戳 t 上 $ y_{[t]}$ 出现概率的唯一两个直接因素、
-

-
其中,我们将 y [ t ] y_{[t]} y[t] 的前缀表示为 (a) 中的 P r e [ t ] Pre_{[t]} Pre[t]。
-

-
这里,(a) 是通过应用假设 A1 的公式 16 得出的。积分项可以解释为在所有可能的上下文 c 中 "锚定预测 " P ( y [ t ] ∣ x [ t ] ; c ) P(y_{[t]} |x_{[t]} ; c) P(y[t]∣x[t];c) 的集合,这类似于隐藏锚机制[HAM: Hidden anchor mechanism for scene text detection.]。因此,我们称该定理为上下文的锚属性。
-
B. Proof of Theorem 2
-
假设 2 (A2) 给定字符 y[t] 时,字符的形状(字符视觉信息)和上下文(语言信息)是独立的,即
-
定理 2:语言信息与字符视觉信息的可分离特性:鉴于假设 A2 成立,字符视觉信息对标签 P ( y [ t ] ∣ x [ t ] ) P(y_{[t]} |x_{[t]}) P(y[t]∣x[t]) 的影响和 P ( y [ t ] ∣ c ) P(y_{[t]} |c) P(y[t]∣c) 的影响可以从上下文预测 P ( y [ t ] ∣ x [ t ] ; c ) P(y_{[t]} |x_{[t]} ; c) P(y[t]∣x[t];c) 中分离出来:
-
这里, Y \mathcal{Y} Y 是字符集。步骤 (a) 和 (b) 是利用假设 A2 中的公式 18 得出的。步骤 © 是通过对 P ( x [ t ] ∣ y [ t ] ′ ) P(x_{[t]} |y ' _{[t]} ) P(x[t]∣y[t]′) 应用贝叶斯规则并取消 x [ t ] x_{[t]} x[t] 而得出的。虽然 ∑ y [ t ] ′ Y P r ( y [ t ] ′ ; x [ t ] ; c ) \sum ^{\mathcal{Y}}_{y'_{[t]}}Pr(y'_{[t]} ; x_{[t]}; c) ∑y[t]′YPr(y[t]′;x[t];c) 不是一个常数,可能随时间戳 t 的变化而变化,但在某个时间戳 t,它对所有标签 $ y’_{[t]}$ 都是相同的,因此,尽管常数因子可能会变化,步骤(d)仍然成立。



C. Proof of Theorem 3
-
结合定理 1 和定理 2,我们就得到了解耦上下文锚机制、
-
由于视觉预测不受语言信息(即 c)的影响,因此可以将其从积分中剔除、
-
β ( y ) = α ∏ 1 l P ( y t ) \beta(y)=\frac{\alpha}{\prod_1^l}P(y_t) β(y)=∏1lαP(yt)
-
是与词相关的字符频率项。在训练过程中,β(y ∗ ) 只与标签相关联,因此对于某个标签来说是常数,不会产生梯度。在评估过程中,由于字典和字符频率都是未知的,因此假定字符频率是统一的,这样对于所有长度为 l 的词来说,β(y) 都是一个常数 α ∣ C e v a l ∣ l \frac α{|C_{eval}|^l} ∣Ceval∣lα。因此,为了书写方便,我们省略了 β。
-

D. An Engineering Perspective of OpenCCD
- 主要论文更强调框架的理论部分,而我们则从工程角度介绍了 OpenCCD 框架,其重点是如何实施,而不是每个模块做什么。
D.1. DSBN-Res45
- 在这项工作中,DSBN-Res45(下图 )用于将单词图像和字形编码为相应的视觉特征。DSBN-Res45 主干网是 中使用的 45 层 ResNet 的改进版。在这里,我们用重新实现的 DSBN 层取代了它的所有批量规范层。这一调整是为了减轻单词图像域和字形域之间偏差的影响。具体来说,该网络对单词级图像和字形图像使用同一组卷积核,同时使用特定域的批次统计数据对每个特定域进行归一化处理。常规模型的布局与最初的 DAN 实现类似,大型模型只是在骨干网中增加了更多的潜通道,具体的网络布局等细节可参见发布的代码。该模块是基础模型的一部分,在消融研究的所有模型中都会用到。
-

-
The DSBN-Res45 backbone.
-
D.2. Prototype Generation
- 原型生成过程如下图所示,对于每个类别,框架首先通过主干提取每个字形的相应视觉特征。然后通过注意力模块(Attn Module)应用空间注意力,将特征图缩减为单一特征。具体来说,该模块首先通过卷积层估计前景/背景注意力掩码,然后将特征图缩小并归一化为相应的原型。与文献[Towards open-set text recognition via label-to-prototype learning]相同,一个标签可能拥有不止一个原型,因为每个字符可能有不同的 “情况”,例如 "N "和 “n”。该模块也是基础模型的一部分,在消融研究的所有模型中都会用到。
-

-
The prototype generation process.
-
D.3. Data, Training, and Evaluation
- 大多数实验(基于词典的近集实验除外)的训练、评估和模型现已发布到 Kaggle【https://www.kaggle.com/vsdf2898kaggle/osocrtraining】上。对于开放集任务,训练数据集由以下数据集聚合而成: RCTW 、MLT2019 数据集的中文和拉丁文子集 、LSVT 、ART 和 CTW 。训练字符集包含 3755 个ire-1 简体中文字符、52 个拉丁字符和 10 个数字。垂直样本和包含训练字符集以外字符的样本均从训练集中删除(包含传统汉字的样本也被删除)。评估数据集包含来自 MLT-2019 数据集日语子集的 4009 幅水平图像,测试字符集包含评估集中出现的 1460 个字符,加上 "未知 "类共 1461 个不同类别。对于近集模型,我们使用了与 DAN 完全相同的数据集,后者采用了最常用的 MJ -ST 组合作为训练集。对于 zero-shot 字符识别任务,我们沿用了 OSOCR 中的拆分方法,并遵循了 HCCR 的协议。
- 在训练过程中,与 OSOCR 一样,每次迭代都会使用标签采样器对字符子集进行采样。对于单词级任务,该模型处理数据的方法与 DAN 相似。具体来说,该模型采用 32*128 RGB 片段,在训练和测试过程中,图像会根据长宽比调整大小,并以 0 为中心填充为 32*128。所有单词级评估均采用通用的无字典协议。在字符识别任务中,尽管为了加快速度将剪辑大小设置为 32*64,但模型仍像处理单词图像一样处理字符图像。在所有三个任务中,我们都使用 Notofont 作为字形提供者,每个字符都被渲染并居中为 32*32 的二进制片段。训练过程与 DAN 基本相同,只是增加了一个原型生成过程。
- 在评估方面,最流行的评估协议–"行精确度 "被用来衡量社区的单词识别性能。字符准确率(1-NED)也被用作开放集单词识别任务的补偿,以直观地了解每个字符的识别质量。对于 zero-shot 汉字识别任务,字准确率和行准确率是相同的数字,社区称之为准确率。
E. Extra Details
E.1. Notations
- 我们制作了一个符号表(下表 ),收录了本文中使用的所有符号。在大多数情况下,帽子(^)表示最大可能预测值,星号(∗)表示 GT。粗体符号表示向量,大写字母表示矩阵、集合或分布。
-

-
论文中首次出现的重要注释及其简要说明。
-
E.2. About Related Work
- 尽管提出的解耦上下文锚机制(DCA)使用 Transformer 对上下文信息进行建模,但这项工作与基于 Transformer 的方法[Transformer text recognition with deep learning algorithm, Scene text recognition via transformer, Text recognition in images based on transformer with hierarchical attention ]并无直接关系。从结构上看,我们方法中的变换器是 BERT 式 Transformer 编码器,[Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition, Towards accurate scene text recognition with semantic reasoning networks]也使用了这种编码器,而前者使用的是 GPT 式 Transformer 解码器。从目的上讲,这项工作中的 Transformer 是作为正则化项使用的(这也是我们反向传播到特征编码器的直接原因)。相反,后者通过切割梯度流将 Transformer 用作后处理模块(注意,[Towards accurate scene text recognition with semantic reasoning networks] 没有在论文中说明这一点,但你可以从他们正式发布的代码中看到)。基于 Transformer 的传统方法直接将 CNN 特征解码为预测序列。因此,DCA 模块在结构和动机上都有所不同。