一、python lightning
python lightning是个好东西,但不见得那么友好。
GPT4给我讲解了他的用法:

二、anomalib的思路
1、 创建一个Lightning Module。
首先,在src\anomalib\models\components\base\anomaly_module.py中,
class AnomalyModule(pl.LightningModule, ABC):
"""AnomalyModule to train, validate, predict and test images.
Acts as a base class for all the Anomaly Modules in the library.
"""
def __init__(self) -> None:
super().__init__()
logger.info("Initializing %s model.", self.__class__.__name__)
self.save_hyperparameters()
self.model: nn.Module
self.loss: nn.Module
self.callbacks: list[Callback]
self.image_threshold: BaseThreshold
self.pixel_threshold: BaseThreshold
self.normalization_metrics: Metric
self.image_metrics: AnomalibMetricCollection
self.pixel_metrics: AnomalibMetricCollection
def forward(self, batch: dict[str, str | torch.Tensor], *args, **kwargs) -> Any: # noqa: ANN401
"""Perform the forward-pass by passing input tensor to the module.
Args:
batch (dict[str, str | torch.Tensor]): Input batch.
*args: Arguments.
**kwargs: Keyword arguments.
Returns:
Tensor: Output tensor from the model.
"""
del args, kwargs # These variables are not used.
return self.model(batch)
def validation_step(self, batch: dict[str, str | torch.Tensor], *args, **kwargs) -> STEP_OUTPUT:
"""To be implemented in the subclasses."""
raise NotImplementedError
def predict_step(
self,
batch: dict[str, str | torch.Tensor],
batch_idx: int,
dataloader_idx: int = 0,
) -> STEP_OUTPUT:
"""Step function called during :meth:`~lightning.pytorch.trainer.Trainer.predict`.
By default, it calls :meth:`~lightning.pytorch.core.lightning.LightningModule.forward`.
Override to add any processing logic.
Args:
batch (Any): Current batch
batch_idx (int): Index of current batch
dataloader_idx (int): Index of the current dataloader
Return:
Predicted output
"""
del batch_idx, dataloader_idx # These variables are not used.
return self.validation_step(batch)
。。。以下省略定义了一堆类似 def forward的虚函数,都有待于他的之类去实现。
这里就要说一下,在python中,也有类似c++中虚函数的概念吗?
GPT给了我回答,是的。只不过,在c++中,虚函数需要明确指出,但是在python中,在Python中实现类似C++虚函数的行为,主要依靠方法重写(Override)。当子类重写了父类的方法时,无论是通过对象直接调用该方法,还是通过父类的接口调用,实际执行的都是子类中重写的方法。这使得我们可以在子类中改变或扩展在父类中定义的行为,这与C++中虚函数的目的是一致的。
所以我们看一下,在我们自己搞的Ddad类中,如何重写了AnomalyModule类的一些方法。
在src\anomalib\models\image\ddad\lightning_model.py中,
class Ddad(MemoryBankMixin, AnomalyModule):
"""Ddad: a Patch Distribution Modeling Framework for Anomaly Detection and Localization.
。。。省略
@staticmethod
def configure_optimizers() -> None:
"""Ddad doesn't require optimization, therefore returns no optimizers."""
return
def on_train_epoch_start (self)-> None:
print("----------------------------------------on_train_epoch_start")
def prepare_data(self) -> None:
print("----------------------------------------prepare_data")
def training_step(self, batch: dict[str, str | torch.Tensor], *args, **kwargs) -> None:
print("---------------training_step")
"""Perform the training step of Ddad. For each batch, hierarchical features are extracted from the CNN.
Args:
batch (dict[str, str | torch.Tensor]): Batch containing image filename, image, label and mask
args: Additional arguments.
kwargs: Additional keyword arguments.
Returns:
Hierarchical feature map
"""
del args, kwargs # These variables are not used.
self.model.feature_extractor.eval()
embedding = self.model(batch["image"])
self.embeddings.append(embedding.cpu())
def fit(self) -> None:
"""Fit a Gaussian to the embedding collected from the training set."""
logger.info("Aggregating the embedding extracted from the training set.")
embeddings = torch.vstack(self.embeddings)
logger.info("Fitting a Gaussian to the embedding collected from the training set.")
self.stats = self.model.gaussian.fit(embeddings)
def validation_step(self, batch: dict[str, str | torch.Tensor], *args, **kwargs) -> STEP_OUTPUT:
"""Perform a validation step of PADIM.
Similar to the training step, hierarchical features are extracted from the CNN for each batch.
Args:
batch (dict[str, str | torch.Tensor]): Input batch
args: Additional arguments.
kwargs: Additional keyword arguments.
Returns:
Dictionary containing images, features, true labels and masks.
These are required in `validation_epoch_end` for feature concatenation.
"""
del args, kwargs # These variables are not used.
batch["anomaly_maps"] = self.model(batch["image"])
return batch
return 0你看,重写了training_step、fit、validation_step等重要函数。
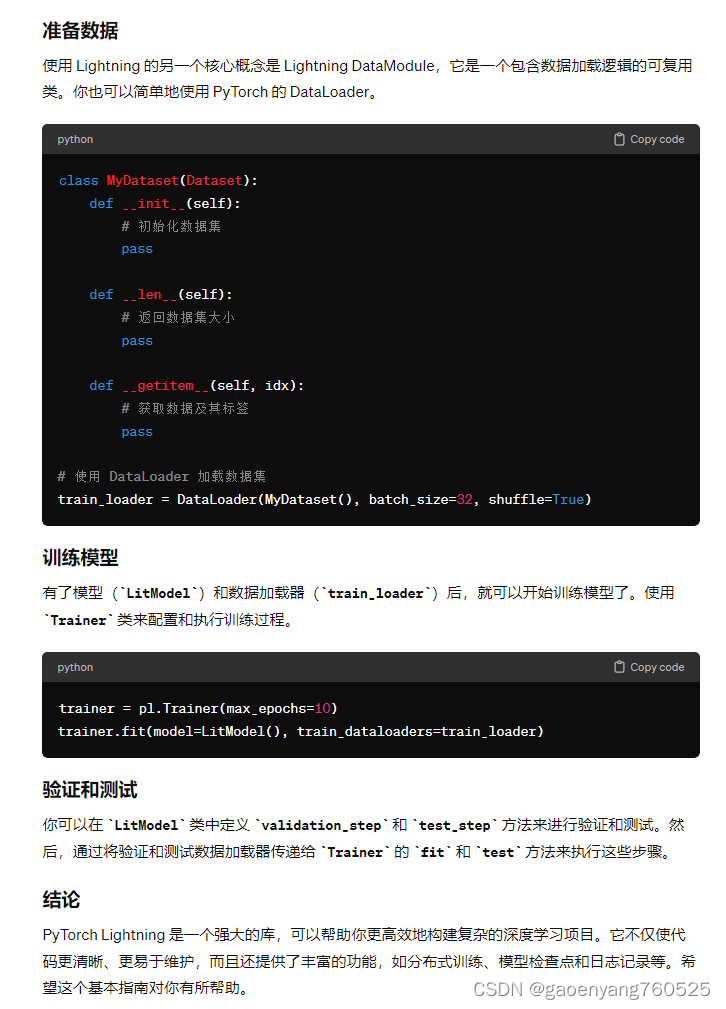
2、 准备数据
在src\anomalib\data\base\dataset.py中,定义了Dataset的一个之类AnomalibDataset,如下:
class AnomalibDataset(Dataset, ABC):
"""Anomalib dataset.
Args:
task (str): Task type, either 'classification' or 'segmentation'
transform (A.Compose): Albumentations Compose object describing the transforms that are applied to the inputs.
"""
def __init__(self, task: TaskType, transform: A.Compose) -> None:
super().__init__()
self.task = task
self.transform = transform
self._samples: DataFrame
def __len__(self) -> int:
"""Get length of the dataset."""
return len(self.samples)
def subsample(self, indices: Sequence[int], inplace: bool = False) -> "AnomalibDataset":
"""Subsamples the dataset at the provided indices.
Args:
indices (Sequence[int]): Indices at which the dataset is to be subsampled.
inplace (bool): When true, the subsampling will be performed on the instance itself.
Defaults to ``False``.
"""
assert len(set(indices)) == len(indices), "No duplicates allowed in indices."
dataset = self if inplace else copy.deepcopy(self)
dataset.samples = self.samples.iloc[indices].reset_index(drop=True)
return dataset
@property
def is_setup(self) -> bool:
"""Checks if setup() been called."""
return hasattr(self, "_samples")
@property
def samples(self) -> DataFrame:
"""Get the samples dataframe."""
if not self.is_setup:
msg = "Dataset is not setup yet. Call setup() first."
raise RuntimeError(msg)
return self._samples
@samples.setter
def samples(self, samples: DataFrame) -> None:
"""Overwrite the samples with a new dataframe.
Args:
samples (DataFrame): DataFrame with new samples.
"""
# validate the passed samples by checking the
assert isinstance(samples, DataFrame), f"samples must be a pandas.DataFrame, found {type(samples)}"
expected_columns = _EXPECTED_COLUMNS_PERTASK[self.task]
assert all(
col in samples.columns for col in expected_columns
), f"samples must have (at least) columns {expected_columns}, found {samples.columns}"
assert samples["image_path"].apply(lambda p: Path(p).exists()).all(), "missing file path(s) in samples"
self._samples = samples.sort_values(by="image_path", ignore_index=True)
@property
def has_normal(self) -> bool:
"""Check if the dataset contains any normal samples."""
return 0 in list(self.samples.label_index)
@property
def has_anomalous(self) -> bool:
"""Check if the dataset contains any anomalous samples."""
return 1 in list(self.samples.label_index)
def __getitem__(self, index: int) -> dict[str, str | torch.Tensor]:
"""Get dataset item for the index ``index``.
Args:
index (int): Index to get the item.
Returns:
dict[str, str | torch.Tensor]: Dict of image tensor during training. Otherwise, Dict containing image path,
target path, image tensor, label and transformed bounding box.
"""
image_path = self._samples.iloc[index].image_path
mask_path = self._samples.iloc[index].mask_path
label_index = self._samples.iloc[index].label_index
image = read_image(image_path)
item = {"image_path": image_path, "label": label_index}
if self.task == TaskType.CLASSIFICATION:
transformed = self.transform(image=image)
item["image"] = transformed["image"]
elif self.task in (TaskType.DETECTION, TaskType.SEGMENTATION):
# Only Anomalous (1) images have masks in anomaly datasets
# Therefore, create empty mask for Normal (0) images.
mask = np.zeros(shape=image.shape[:2]) if label_index == 0 else cv2.imread(mask_path, flags=0) / 255.0
mask = mask.astype(np.single)
transformed = self.transform(image=image, mask=mask)
item["image"] = transformed["image"]
item["mask_path"] = mask_path
item["mask"] = transformed["mask"]
if self.task == TaskType.DETECTION:
# create boxes from masks for detection task
boxes, _ = masks_to_boxes(item["mask"])
item["boxes"] = boxes[0]
else:
msg = f"Unknown task type: {self.task}"
raise ValueError(msg)
return item
def __add__(self, other_dataset: "AnomalibDataset") -> "AnomalibDataset":
"""Concatenate this dataset with another dataset.
Args:
other_dataset (AnomalibDataset): Dataset to concatenate with.
Returns:
AnomalibDataset: Concatenated dataset.
"""
assert isinstance(other_dataset, self.__class__), "Cannot concatenate datasets that are not of the same type."
assert self.is_setup, "Cannot concatenate uninitialized datasets. Call setup first."
assert other_dataset.is_setup, "Cannot concatenate uninitialized datasets. Call setup first."
dataset = copy.deepcopy(self)
dataset.samples = pd.concat([self.samples, other_dataset.samples], ignore_index=True)
return dataset
def setup(self) -> None:
"""Load data/metadata into memory."""
if not self.is_setup:
self._setup()
assert self.is_setup, "setup() should set self._samples"
@abstractmethod
def _setup(self) -> DataFrame:
"""Set up the data module.
This method should return a dataframe that contains the information needed by the dataloader to load each of
the dataset items into memory.
The DataFrame must, at least, include the following columns:
- `split` (str): The subset to which the dataset item is assigned (e.g., 'train', 'test').
- `image_path` (str): Path to the file system location where the image is stored.
- `label_index` (int): Index of the anomaly label, typically 0 for 'normal' and 1 for 'anomalous'.
- `mask_path` (str, optional): Path to the ground truth masks (for the anomalous images only).
Required if task is 'segmentation'.
Example DataFrame:
+---+-------------------+-----------+-------------+------------------+-------+
| | image_path | label | label_index | mask_path | split |
+---+-------------------+-----------+-------------+------------------+-------+
| 0 | path/to/image.png | anomalous | 1 | path/to/mask.png | train |
+---+-------------------+-----------+-------------+------------------+-------+
Note:
The example above is illustrative and may need to be adjusted based on the specific dataset structure.
"""
raise NotImplementedError
重写了__len__、__getitem__等重要函数。最终,通过def _setup(self) -> DataFrame:
获得了DataFrame如下

最后,在src\anomalib\data\base\datamodule.py的AnomalibDataModule 类中,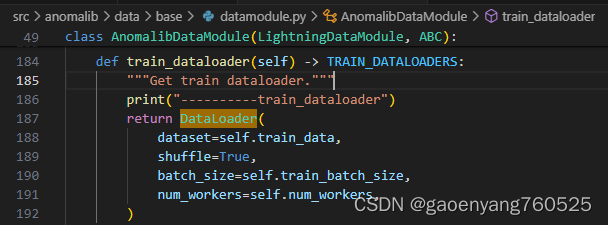
后来,这个train_dataloader就被自动调用了。至于怎么被自动调用的,我还没看明白
欢迎留言指点一下。