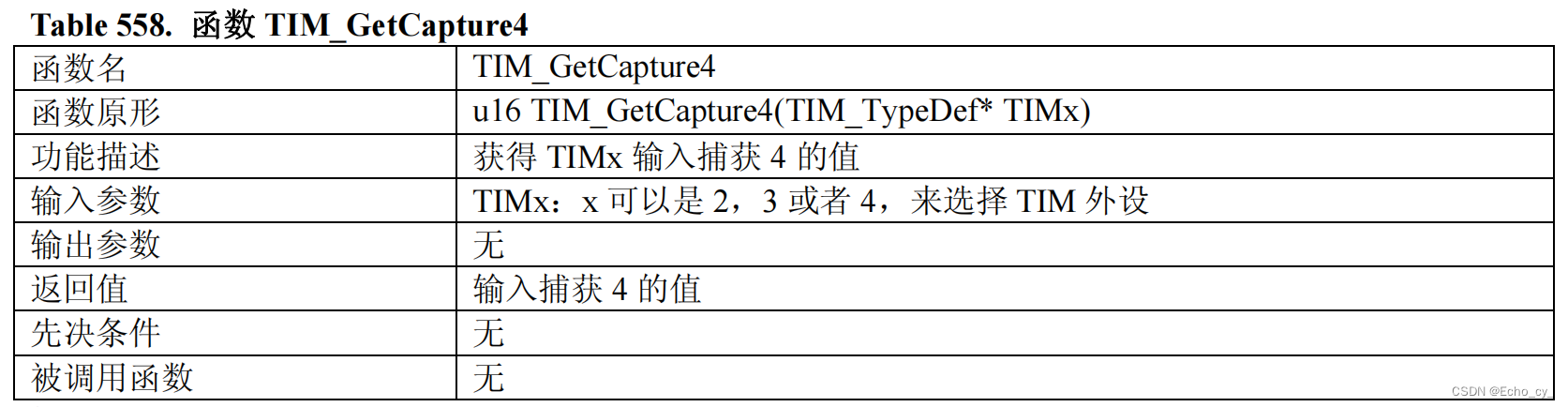
1.使用hanlp抽取法人名称、企业名称等信息
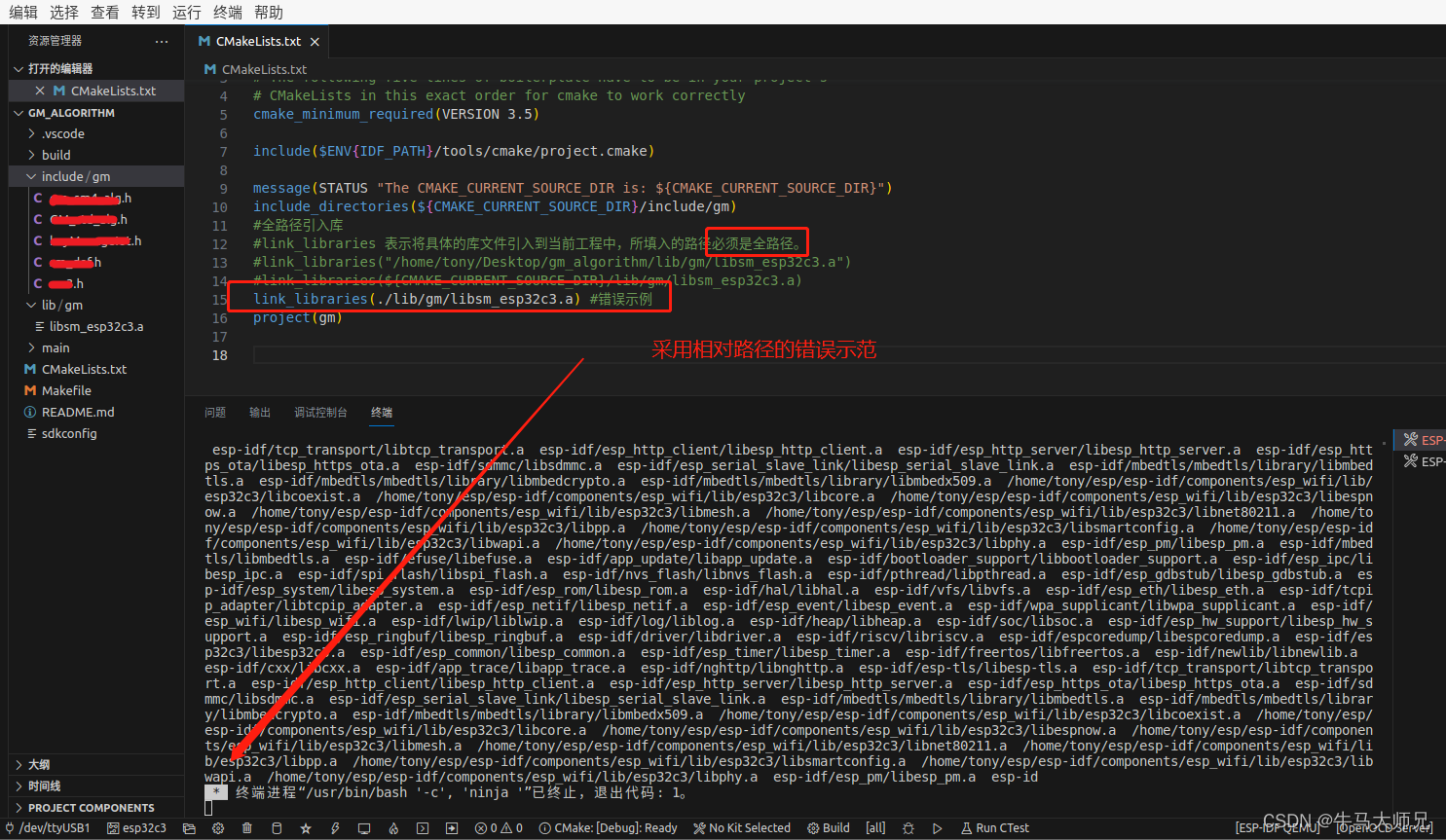
# -*- coding: utf-8 -*-
from pyhanlp import *
text1="1998年11月11日,马化腾和同学张志东在广东省深圳市正式注册成立“深圳市腾讯计算机系统有限公司”,之后许晨晔、陈一丹、曾李青相继加入。当时公司的业务是拓展无线网络寻呼系统,为寻呼台建立网上寻呼系统,这种针对企业或单位的软件开发工程是所有中小型网络服务公司的最佳选择。"
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg(text1)
print(term_list)
rmlist= []
complist=[]
for term in term_list:
if(term.nature=="nr"):
rmlist.append(term.word)
if(term.nature=='nt'):
complist.append(term.word)
print(rmlist)
print(complist) 问题:使用term.nature.name=="nr",保错AttributeError: 'com.hankcs.hanlp.corpus.tag.Nature' object has no attribute 'name',使用使用term.nature=="nr",最终结果为空
问题解决:暂无

2.使用hanlp提取关键词信息
from pyhanlp import *
document = "程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。"
print(HanLP.extractKeyword(document, 2)) 问题:
正确结果应为:
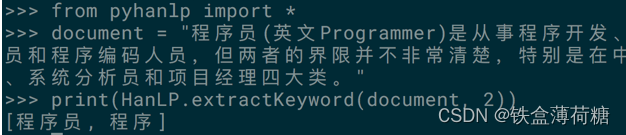
但执行结果为:
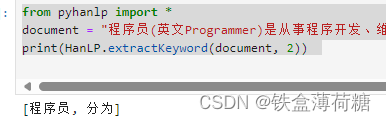
问题解决:暂无
3.基于hanlp的句法分析案例
from pyhanlp import *
# 依存句法分析
sentence = HanLP.parseDependency("1998年11月11日,马化腾和同学张志东在广东省深圳市正式注册成立“深圳市腾讯计算机系统有限公司”。")
print(sentence)
for word in sentence.iterator(): # 通过dir()可以查看sentence的方法
print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA))
print()
# 也可以直接拿到数组,任意顺序或逆序遍历
word_array = sentence.getWordArray()
for word in word_array:
print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA))
print()
# 还可以直接遍历子树,从某棵子树的某个节点一路遍历到虚根
CoNLLWord = JClass("com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord")
head = word_array[12]
while head.HEAD:
head = head.HEAD
if (head == CoNLLWord.ROOT):
print(head.LEMMA)
else:
print("%s --(%s)--> " % (head.LEMMA, head.DEPREL)) 4.基于模板完成事件抽取
(1)依赖包:pyhanlp
(2)组件如何安装、使用
1. 触发词:安装、配置、使用
2. 抽取类型:时间抽取
(3)匹配模板
1. .*?安装配置:(.*?)[。]
2. .*?使用:(.*?)[。]
(4)核心代码
#核心代码:
if word == '安装' or word == '配置':
pattern = re.compile('.*?安装配置:(.*?)[。]') # 查找数字
for sentence in data:
# print(sentence.decode('utf-8'))
res = re.findall(pattern,sentence.decode('utf-8'))
if len(res):
result.append(res)