爬虫专栏:http://t.csdnimg.cn/WfCSx
前言
在前一章中,我们了解了 Ajax 的分析和抓取方式,这其实也是 JavaScript 动态渲染的页面的一种情形,通过直接分析 Ajax,我们仍然可以借助 requests 或 urllib 来实现数据爬取。
不过 JavaScript 动态渲染的页面不止 Ajax 这一种。比如中国青年网(详见 国内_新闻频道_中国青年网),它的分页部分是由 JavaScript 生成的,并非原始 HTML 代码,这其中并不包含 Ajax 请求。比如 ECharts 的官方实例(详见 http://echarts.baidu.com/demo.html),其图形都是经过 JavaScript 计算之后生成的。再有淘宝这种页面,它即使是 Ajax 获取的数据,但是其 Ajax 接口含有很多加密参数,我们难以直接找出其规律,也很难直接分析 Ajax 来抓取。
为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。这样我们就不用再去管网页内部的 JavaScript 用了什么算法渲染页面,不用管网页后台的 Ajax 接口到底有哪些参数。
Python 提供了许多模拟浏览器运行的库,如 Selenium、Splash、PyV8、Ghost 等。本章中,我们就来介绍一下 Selenium 和 Splash 的用法。有了它们,就不用再为动态渲染的页面发愁了。
Selenium 的使用
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。本节中,就让我们来感受一下它的强大之处吧。
1. 准备工作
本节以 Chrome 为例来讲解 Selenium 的用法。在开始之前,请确保已经正确安装好了 Chrome 浏览器并配置好了 ChromeDriver。另外,还需要正确安装好 Python 的 Selenium 库,详细的安装和配置过程可以参考Python爬虫请求库安装#1-CSDN博客
2. 基本使用
准备工作做好之后,首先来大体看一下 Selenium 有一些怎样的功能。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
运行代码后发现,会自动弹出一个 Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页。
此时在控制台的输出结果如下:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=Python&rsv_pq=c94d0df9000a72d0&rsv_t=07099xvun1ZmC0bf6eQvygJ43IUTTUOl5FCJVPgwG2YREs70GplJjH2F%2BCQ&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=87&rsv_sug4=87
[{'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598', 'domain': '.baidu.com', 'path': '/', 'httpOnly': False, 'name': 'BDORZ', 'expiry': 1491688071.707553}, {'secure': False, 'value': '22473_1441_21084_17001', 'domain': '.baidu.com', 'path': '/', 'httpOnly': False, 'name': 'H_PS_PSSID'}, {'secure': False, 'value': '12883875381399993259_00_0_I_R_2_0303_C02F_N_I_I_0', 'domain': '.www.baidu.com', 'path': '/', 'httpOnly': False, 'name': '__bsi', 'expiry': 1491601676.69722}]
<!DOCTYPE html><!--STATUS OK-->...</html>
源代码过长,在此省略。可以看到,我们得到的当前 URL、Cookies 和源代码都是浏览器中的真实内容。
所以说,如果用 Selenium 来驱动浏览器加载网页的话,就可以直接拿到 JavaScript 渲染的结果了,不用担心使用的是什么加密系统。
下面来详细了解一下 Selenium 的用法。
3. 声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。另外,也支持无界面浏览器 PhantomJS。
此外,我们可以用如下方式初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()这样就完成了浏览器对象的初始化并将其赋值为 browser 对象。接下来,我们要做的就是调用 browser 对象,让其执行各个动作以模拟浏览器操作。
4. 访问页面
我们可以用 get() 方法来请求网页,参数传入链接 URL 即可。比如,这里用 get() 方法访问淘宝,然后打印出源代码,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()运行后发现,弹出了 Chrome 浏览器并且自动访问了淘宝,然后控制台输出了淘宝页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们可以实现浏览器的驱动并获取网页源码,非常便捷。
4. 查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码。
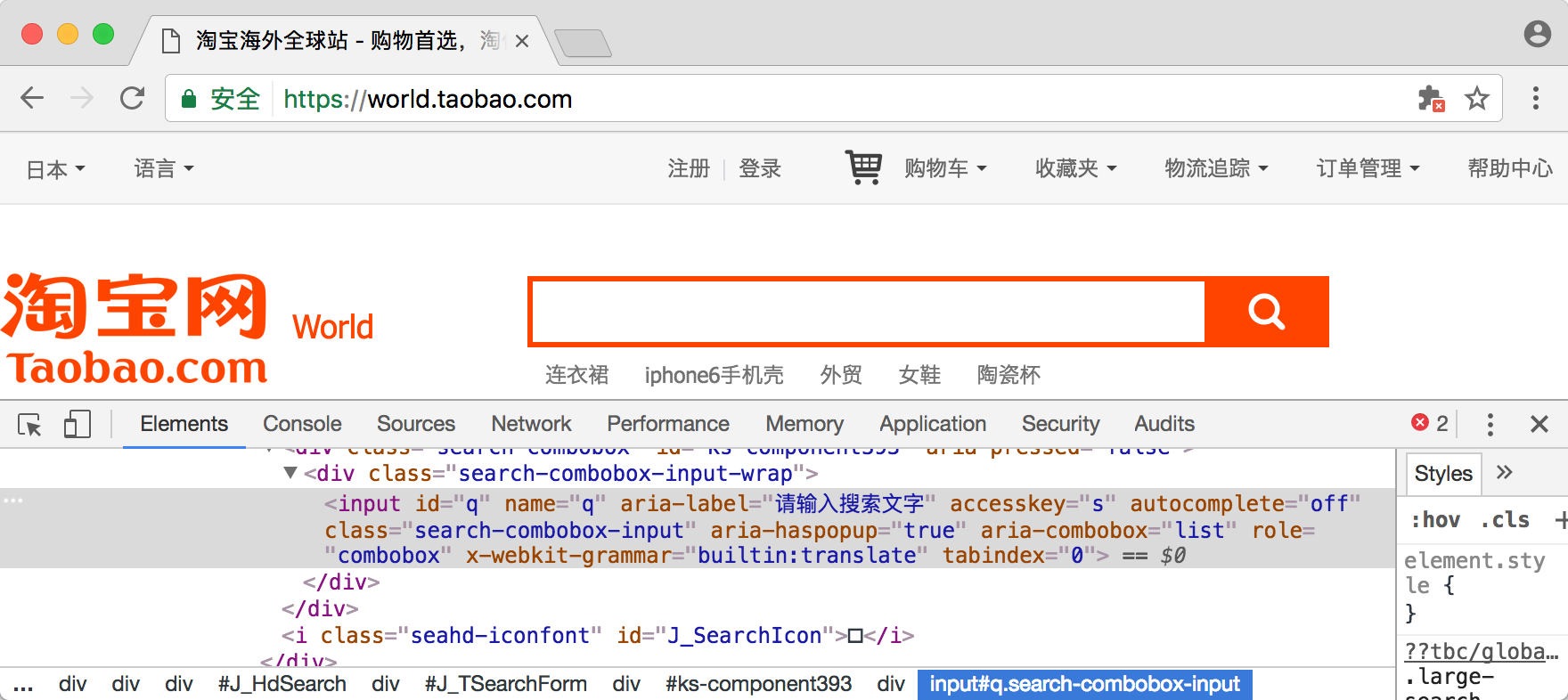
可以发现,它的 id 是 q,name 也是 q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_element_by_name() 是根据 name 值获取,find_element_by_id() 是根据 id 获取。另外,还有根据 XPath、CSS 选择器等获取的方式。
我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()这里我们使用 3 种方式获取输入框,分别是根据 ID、CSS 选择器和 XPath 获取,它们返回的结果完全一致。运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")> <selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")> <selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.5649563096161541-1")>
可以看到,这 3 个节点都是 WebElement 类型,是完全一致的。
这里列出所有获取单个节点的方法:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
另外,Selenium 还提供了通用方法 find_element(),它需要传入两个参数:查找方式 By 和值。实际上,它就是 find_element_by_id() 这种方法的通用函数版本,比如 find_element_by_id(id) 就等价于 find_element(By.ID, id),二者得到的结果完全一致。我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()实际上,这种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
多个节点
如果查找的目标在网页中只有一个,那么完全可以用 find_element() 方法。但如果有多个节点,再用 find_element() 方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用 find_elements() 这样的方法。注意,在这个方法的名称中,element 多了一个 s,注意区分。
比如,要查找淘宝左侧导航条的所有条目。
就可以这样来实现:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-1")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-2")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-3")>...<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-16")>]
这里简化了输出结果,中间部分省略。
可以看到,得到的内容变成了列表类型,列表中的每个节点都是 WebElement 类型。
也就是说,如果我们用 find_element() 方法,只能获取匹配的第一个节点,结果是 WebElement 类型。如果用 find_elements() 方法,则结果是列表类型,列表中的每个节点是 WebElement 类型。
这里列出所有获取多个节点的方法:
find_elements_by_id find_elements_by_name find_elements_by_xpath find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name find_elements_by_css_selector
当然,我们也可以直接用 find_elements() 方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
结果是完全一致的。
6. 节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()
这里首先驱动浏览器打开淘宝,然后用 find_element_by_id() 方法获取输入框,然后用 send_keys() 方法输入 iPhone 文字,等待一秒后用 clear() 方法清空输入框,再次调用 send_keys() 方法输入 iPad 文字,之后再用 find_element_by_class_name() 方法获取搜索按钮,最后调用 click() 方法完成搜索动作。
通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍 :7. WebDriver API — Selenium Python Bindings 2 documentation。
7. 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明 ActionChains 对象并将其赋值为 actions 变量,然后通过调用 actions 变量的 drag_and_drop() 方法,再调用 perform() 方法执行动作,此时就完成了拖曳操作:
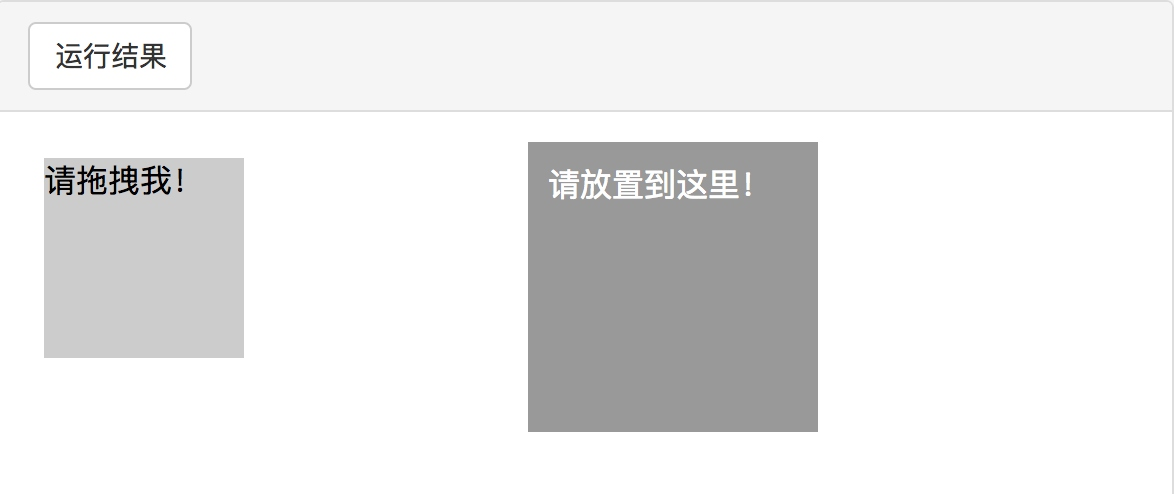
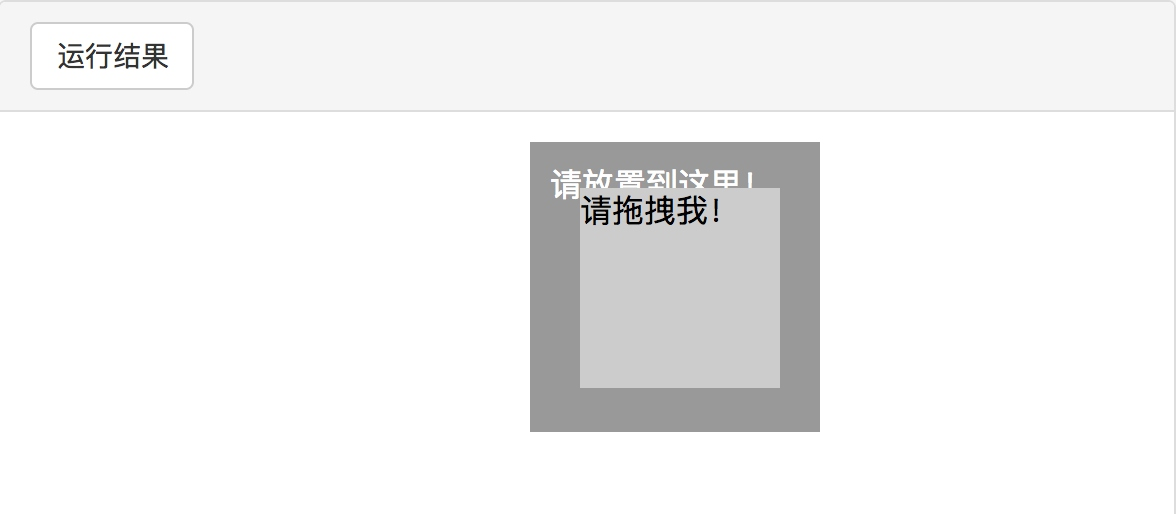
以上两图分别为在拖曳前和拖曳后的结果。
更多的动作链操作可以参考官方文档的动作链介绍:7. WebDriver API — Selenium Python Bindings 2 documentation。
8. 执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
这里就利用 execute_script() 方法将进度条下拉到最底部,然后弹出 alert 提示框。
所以说有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。
9. 获取节点信息
前面说过,通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery 等)来提取信息了。
不过,既然 Selenium 已经提供了选择节点的方法,返回的是 WebElement 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
接下来,就看看通过怎样的方式来获取节点信息吧。
获取属性
我们可以使用 get_attribute() 方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
运行之后,程序便会驱动浏览器打开知乎页面,然后获取知乎的 logo 节点,最后打印出它的 class。
控制台的输出结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="e08c0f28d7f44d75ccd50df6bb676104", element="0.7236390660048155-1")> zu-top-link-logo
通过 get_attribute() 方法,然后传入想要获取的属性名,就可以得到它的值了。
获取文本值
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于 Beautiful Soup 的 get_text() 方法、pyquery 的 text() 方法,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)
这里依然先打开知乎页面,然后获取 “提问” 按钮这个节点,再将其文本值打印出来。
控制台的输出结果如下:
提问
获取 ID、位置、标签名、大小
另外,WebElement 节点还有一些其他属性,比如 id 属性可以获取节点 id,location 属性可以获取该节点在页面中的相对位置,tag_name 属性可以获取标签名称,size 属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)
这里首先获得 “提问” 按钮这个节点,然后调用其 id、location、tag_name、size 属性来获取对应的属性值。
10. 切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。示例如下:
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
控制台输出:
NO LOGO <selenium.webdriver.remote.webelement.WebElement (session="4bb8ac03ced4ecbdefef03ffdc0e4ccd", element="0.13792611320464965-2")> RUNOOB.COM
这里还是以前面演示动作链操作的网页为实例,首先通过 switch_to.frame() 方法切换到子 Frame 里面,然后尝试获取子 Frame 里的 logo 节点(这是不能找到的),如果找不到的话,就会抛出 NoSuchElementException 异常,异常被捕捉之后,就会输出 NO LOGO。接下来,重新切换回父级 Frame,然后再次重新获取节点,发现此时可以成功获取了。
所以,当页面中包含子 Frame 时,如果想获取子 Frame 中的节点,需要先调用 switch_to.frame() 方法切换到对应的 Frame,然后再进行操作。
11. 延时等待
在 Selenium 中,get() 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待
当使用隐式等待执行测试的时候,如果 Selenium 没有在 DOM 中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
在这里我们用 implicitly_wait() 方法实现了隐式等待。
显式等待
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
这里首先引入 WebDriverWait 这个对象,指定最长等待时间,然后调用它的 until() 方法,传入要等待条件 expected_conditions。比如,这里传入了 presence_of_element_located 这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是 ID 为 q 的节点搜索框。
这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为 element_to_be_clickable,也就是可点击,所以查找按钮时查找 CSS 选择器为.btn-search 的按钮,如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载出来的。
控制台的输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.5642646294074107-1")> <selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.5642646294074107-2")>
可以看到,控制台成功输出了两个节点,它们都是 WebElement 类型。
如果网络有问题,10 秒内没有成功加载,那就抛出 TimeoutException 异常,此时控制台的输出如下:
TimeoutException Traceback (most recent call last)
<ipython-input-4-f3d73973b223> in <module>()
7 browser.get('https://www.taobao.com/')
8 wait = WebDriverWait(browser, 10)
----> 9 input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。表中列出了所有的等待条件。
等待条件及其含义
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出,传入定位元组,如 (By.ID, 'p') |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it frame | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现 Alert |
更多详细的等待条件的参数及用法介绍可以参考官方文档:7. WebDriver API — Selenium Python Bindings 2 documentation。
12. 前进后退
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
这里我们连续访问 3 个页面,然后调用 back() 方法回到第二个页面,接下来再调用 forward() 方法又可以前进到第三个页面。
13. Cookies
使用 Selenium,还可以方便地对 Cookies 进行操作,例如获取、添加、删除 Cookies 等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
首先,我们访问了知乎。加载完成后,浏览器实际上已经生成 Cookies 了。接着,调用 get_cookies() 方法获取所有的 Cookies。然后,我们添加一个 Cookie,这里传入一个字典,有 name、domain 和 value 等内容。接下来,再次获取所有的 Cookies。可以发现,结果就多了这一项新加的 Cookie。最后,调用 delete_all_cookies() 方法删除所有的 Cookies。再重新获取,发现结果就为空了。
控制台的输出如下:
[{'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888849ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry': 1494196091.403418}]
[{'secure': False, 'value': 'germey', 'domain': '.www.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'name'}, {'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888849ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry': 1494196091.403418}]
[]
通过以上方法来操作 Cookies 还是非常方便的。
14. 选项卡管理
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://python.org')
控制台输出如下:
['CDwindow-4f58e3a7-7167-4587-bedf-9cd8c867f435', 'CDwindow-6e05f076-6d77-453a-a36c-32baacc447df']
首先访问了百度,然后调用了 execute_script() 方法,这里传入 window.open() 这个 JavaScript 语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用 window_handles 属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用 switch_to_window() 方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用 switch_to_window() 方法,再执行其他操作即可。
15. 异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
首先,演示一下节点未找到的异常,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.find_element_by_id('hello')
这里首先打开百度页面,然后尝试选择一个并不存在的节点,此时就会遇到异常。
运行之后控制台的输出如下:
NoSuchElementException Traceback (most recent call last)
<ipython-input-23-978945848a1b> in <module>()
3 browser = webdriver.Chrome()
4 browser.get('https://www.baidu.com')
----> 5 browser.find_element_by_id('hello')
可以看到,这里抛出了 NoSuchElementException 异常,这通常是节点未找到的异常。为了防止程序遇到异常而中断,我们需要捕获这些异常,示例如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
这里我们使用 try except 来捕获各类异常。比如,我们对 find_element_by_id() 查找节点的方法捕获 NoSuchElementException 异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。
控制台的输出如下:
No Element
关于更多的异常类,可以参考官方文档::7. WebDriver API — Selenium Python Bindings 2 documentation。
现在,我们基本对 Selenium 的常规用法有了大体的了解。使用 Selenium,处理 JavaScript 不再是难事。