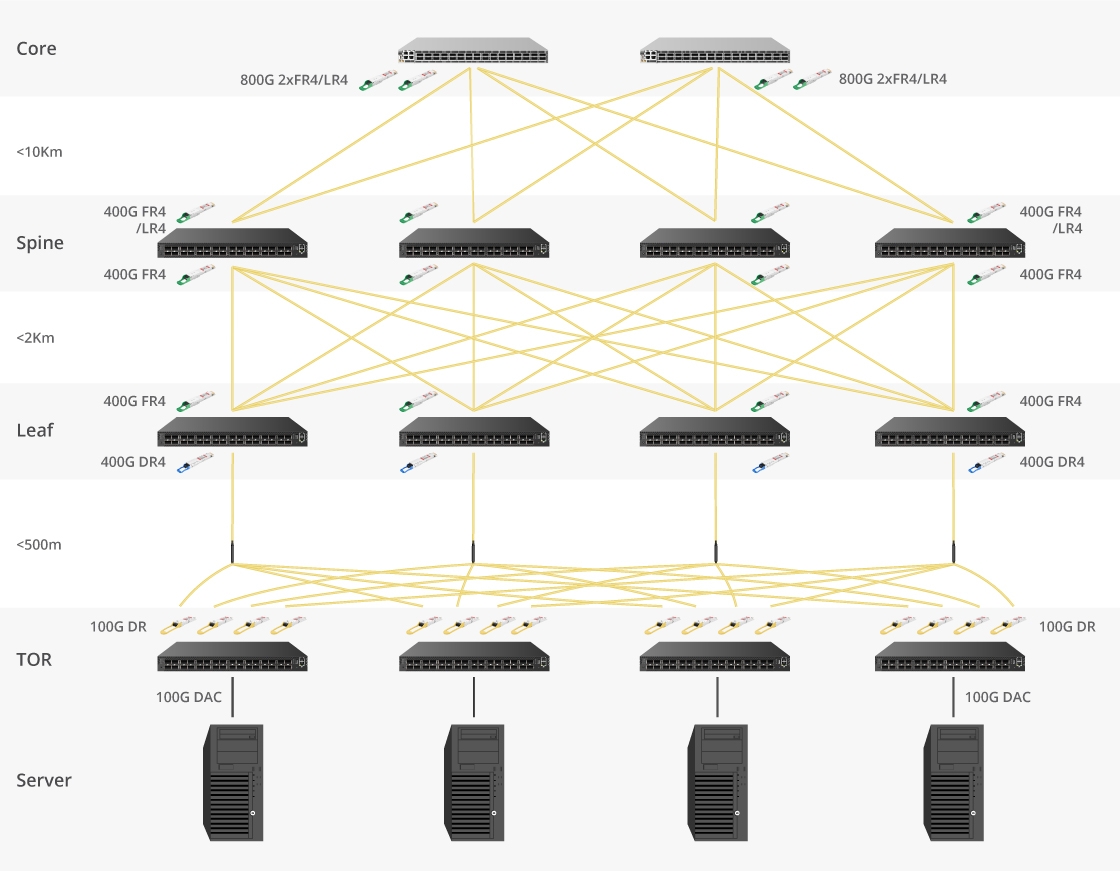
摘要
如何从大量未标注文本中获取词级别的信息有两个主要挑战,使用何种优化目标能有效地学习文本表示,如何有效地将学习到的表示迁移到目标任务。针对这些问题,本文提出一种无监督预训练和有监督微调的组合的半监督方法,具体为:
- 采用两阶段训练过程,首先使用语言建模目标在大量未标注数据上学习模型的初始参数,随后使用有监督目标微调预训练模型以适应目标任务
- 模型架构使用Transformer,其在处理文本中的长期依赖关系时提供了更有结构的记忆
- 在微调过程中,采用特定任务输入转换,使预训练模型的架构在最小的改变的同时进行有效的微调
框架
无监督预训练
给定无标签的tokens序列 U = { u 1 , … , u n } U=\{ u_1,\dots,u_n \} U={u1,…,un},使用标准的语言模型目标最大化似然:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(U)=\textstyle\sum_{i}logP(u_i|u_{i-k},\dots,u_{i-1};\Theta) L1(U)=∑ilogP(ui∣ui−k,…,ui−1;Θ)
其中
k
k
k为上下文窗口的大小,条件概率
P
P
P使用参数为
Θ
\Theta
Θ的神经网络进行建模,参数使用随机梯度下降训练。 本文使用多层多头自注意力Transformer解码器作为语言模型,之后通过逐位置前馈网络产生目标token的输出分布:
h
0
=
U
W
e
+
W
p
h
l
=
t
r
a
n
s
f
o
r
m
e
r
_
b
l
o
c
k
(
h
l
−
1
)
∀
∈
[
1
,
n
]
P
(
u
)
=
s
o
f
t
m
a
x
(
h
n
W
e
T
)
h_0=UW_e+W_p\\h_l=transformer\_block(h_{l-1})\forall \in [1,n]\\P(u)=softmax(h_nW^T_e)
h0=UWe+Wphl=transformer_block(hl−1)∀∈[1,n]P(u)=softmax(hnWeT)
其中 U = ( u − k , … , u − 1 ) U=(u_{−k},\dots,u_{−1}) U=(u−k,…,u−1)是token的上文向量, n n n是transformer层数, W e W_e We是token embedding矩阵, W p W_p Wp是position embedding矩阵。
有监督微调
使用上述等式中的目标预训练模型后,接下来将参数适应到有监督的目标任务。假设有一个有标签数据集
C
C
C,其中每个实例包含一个输入tokens序列
x
1
,
…
,
x
m
x^1,\dots,x^m
x1,…,xm, 以及标签
y
y
y。输入tokens序列首先通过预训练模型进行处理,然后得到Transformer最后一层的输出
h
l
m
h^m_l
hlm,然后将其输入到一个附加的参数为
W
y
W_y
Wy的线性输出层来预测最终结果
y
y
y:
P
(
y
∣
x
1
,
…
,
x
m
)
=
s
o
f
t
m
a
x
(
h
l
m
W
y
)
P(y|x^1,\dots,x^m)=softmax(h^m_lW_y)
P(y∣x1,…,xm)=softmax(hlmWy)
对应的优化目标为:
L
2
(
C
)
=
∑
(
x
,
y
)
l
o
g
P
(
y
∣
x
1
,
…
,
x
m
)
L_2(C)=\sum_{(x,y)}logP(y|x^1,\dots,x^m)
L2(C)=(x,y)∑logP(y∣x1,…,xm)
此外,将预训练语言建模目标作为微调的辅助目标有助于收敛,以及改进监督模型的泛化。故优化目标定义为:
L
3
(
C
)
=
L
2
(
C
)
+
λ
∗
L
1
(
C
)
L_3(C)=L_2(C)+\lambda*L_1(C)
L3(C)=L2(C)+λ∗L1(C)
特定任务输入转换

对于某些任务,如文本分类,可以直接按照上述描述对模型进行微调。但另外一些任务,如问题回答或文本蕴含,其具有结构化输入(有序的句子对,文档、问题和答案的三元组)。因为预训练模型是在连续的文本序列上训练的,所以需要一些修改才能将其应用到这些任务上。
故采用遍历式方法,将结构化输入转换为预训练模型可以处理的有序序列,这避免了在不同任务之间对架构进行改变,如上图。所有的转换都添加随机初始化的开始和结束token ( < s > , < e > ) (<s>,<e>) (<s>,<e>)。具体转换方式如下:
- 文本蕴含:对于蕴含任务,将前提 p p p和假设 h h h的token序列用一个分割符token( $ )串联在一起
- 相似度:对于相似性任务,被比较的两个句子没有固定的顺序。故修改输入序列,使其包含两种顺序的句子(每句都用分割符token( $ )串联),并独立处理每个序列,以生成两个序列表示 h l m h^m_l hlm。这些表示在输入线性输出层之前按元素相加
- 问题回答和常识推理:这些任务会给出一个上下文文档 z z z,一个问题 q q q,和一组可能的答案 { a k } \{ a_k \} {ak}。用分割符token( $ )将文档上下文和问题及每个可能的答案串联,得到 [ z ; q ; [z;q; [z;q; $; a k ] a_k] ak]。每一个这样的序列都用模型独立处理,然后通过softmax归一化从而得到每个可能答案的输出分布
实验配置
无监督预训练
使用BooksCorpus、1B Word Benchmark数据集进行语言模型预训练,GPT在这个语料库上达到了非常低的词级困惑度,为18.4。详细训练配置如下:
- 在batch size为64,token长度为512的连续序列上训练100个epoch
- 对输入序列使用一个40000词的BPE分词
- 采用原始transformer架构
- 采用12层带有带有masked self-attention heads(768隐层维度、12个attention heads)的transformer解码器,使用3072维度的position-wise feed-forward networks
- 使用了可学习的位置嵌入,而不是正余弦版本
- 使用Adam优化器,最大学习率为2.5e-4,学习率在前2000次更新中从0开始线性增加,并使用余弦退火调度降到0
- 模型中大量使用了layerNorm,所以权重采用简单的初始化
- 残差、嵌入和注意力采用0.1的dropout正则化
- 激活函数使用高斯误差线性单元(GELU)
- 使用ftfy库来清理BooksCorpus中的原始文本,标准化一些标点和空白,并使用spaCy为tokenizer
微调细节
微调过程复用无监督预训练的超参数设置,并添加一个dropout为0.1的线性分类器。对于大多数任务,使用6.25e-5的学习率和32的batchsize及3个epoch。使用线性学习率衰减调度,预热超过0.2%的训练,λ为0.5。
微调实验
本文对一系列的监督任务进行实验,包括自然语言推断、问题回答、语义相似性和文本分类。

如上图,不同实验使用的不同数据集配置。
Natural Language Inference
自然语言推断(NLI)任务,即文本蕴含识别。目标为读取一对句子并判断它们之间的关系,可以是蕴含、矛盾或中性。实验在五个来源各异的数据集上进行评估,包括图像字幕(SNLI)、转录语音、流行小说和政府报告(MNLI)、维基百科文章(QNLI)、科学考试(SciTail)或新闻文章(RTE)。

上图为GPT和以前最先进方法在不同NLI任务上的结果。观察到GPT在五个数据集中的四个上显著优于baseline,在MNLI上达到最高1.5%的绝对改进,在SciTail上达到5%的改进,在QNLI上达到5.8%的改进,在SNLI上达到0.6%的改进,超过了以前的最好结果。这表明GPT在处理多个句子、语言歧义方面的优越能力。
Question answering and commonsense reasoning
单句和多句推理的任务有问题回答和常识推理。实验使用最近发布的RACE数据集,该数据集包含来自中学和高中考试的英语段落以及相关问题。此外,还在StoryCloze Test上进行评估,该任务涉及从两个选项中选择故事的正确结局。

如上图,GPT显著优于之前的最佳结果,在Story Cloze上提高了8.9%,在RACE上整体提高了5.7%。这证明了GPT处理长范围上下文的能力。
Semantic Similarity
语义相似性任务涉及预测两个句子是否在语义上等同,挑战在于识别概念的重述,理解否定,以及处理句法歧义。实验使用了三个数据集来完成这个任务,微软释义语料库(MRPC)(从新闻源收集)、Quora问题对(QQP)数据集、语义文本相似性基准(STS-B)。

如上图,GPT在三个语义相似性任务中的两个任务上获得了最先进的结果,在STS-B上的绝对增益为1个点。在QQP上的性能差距显著,比单任务BiLSTM + ELMo + Attn的结果提高了4.2%。
Classification
分类任务在语言可接受性语料库(CoLA)和斯坦福情感树库(SST-2)上进行评估。CoLA包含了专家对一个句子是否符合语法的判断,这测试了训练模型的内在语言偏见。
GPT在CoLA上获得了45.4的分数,比之前最好的结果35.0有一个特别大的提高,表明GPT学习到了内在语言偏见。在SST-2上达到了91.3%的准确度,这与最先进的结果相当。实验还在GLUE基准测试上取得了72.8的总分,这比以前最好的68.9要好很多。
分析
Impact of number of layers transferred
实验观察了从无监督预训练转移不同层数到监督目标任务的影响。

如上图左描绘了转移不同层数再MultiNLI和RACE上表现,观察到每个transformer层都提供了进一步的性能提升,这表明预训练模型中的每一层都包含有用的功能来解决目标任务。
Zero-shot Behaviors
为了理解为什么预训练transformer有效。假设transformer更加结构化的注意力记忆相比于LSTM在特征转移后对于语言建模能力更有帮助。故设计了一系列使用底层生成模型执行任务而无需监督微调的启发式解决方案。
如上图右,观察到这些启发式解决方案的性能在训练过程中稳步增加,这表明生成式预训练支持学习各种任务相关的功能。还观察到LSTM在零样本性能中表现出更高的方差,这表明Transformer架构的归纳偏见在特征转移中起到了帮助。
Ablation studies
实验进行了三种不同的消融研究。

如上图:
- 检查了GPT在微调期间没有辅助LM目标的性能。观察到辅助目标在NLI任务和QQP上有所帮助,表明更大的数据集从辅助目标中受益,但小数据集则没有
- 通过将GPT与单层2048单元LSTM比较,分析Transformer的效果。观察到当使用LSTM而不是Transformer时,平均分数下降了5.6。只有一个MRPC数据集时,LSTM的表现超过了Transformer
- 将transformer架构与没有预训练的模型进行比较。观察到缺乏预训练会损害所有任务的性能,导致与完整模型相比下降了14.8%
reference
Alec, R. , Karthik, N. , Tim, S. , & Ilya, S. . (2023). Improving Language Understanding
by Generative Pre-Training.