目录
七、智能推荐系统处理
7.1 常用的推荐系统算法
7.2 如何实现推荐
7.3 基于飞桨实现的电影推荐模型
7.3.1 电影数据类型
7.3.2 数据处理
7.3.4 数据读取器
7.3.4 网络构建
7.3.4.1用户特征提取
7.3.4.2 电影特征提取
7.3.4.3 相似度计算
7.3.4.4 网络模型完整代码
7.3 根据推荐案例的思考
七、智能推荐系统处理
7.1 常用的推荐系统算法
常用的推荐系统算法实现方案有三种:
-
协同过滤推荐(Collaborative Filtering Recommendation):该算法的核心是分析用户的兴趣和行为,利用共同行为习惯的群体有相似喜好的原则,推荐用户感兴趣的信息。兴趣有高有低,算法会根据用户对信息的反馈(如评分)进行排序,这种方式在学术上称为协同过滤。协同过滤算法是经典的推荐算法,经典意味着简单、好用。协同过滤算法又可以简单分为两种:
a)基于用户的协同过滤:根据用户的历史喜好分析出相似兴趣的人,然后给用户推荐其他人喜欢的物品。假如小李,小张对物品A、B都给了十分好评,那么可以认为小李、小张具有相似的兴趣爱好,如果小李给物品C十分好评,那么可以把C推荐给小张,可简单理解为“人以类聚”。
基于用户 初始选择 后续选择 系统推荐 小李 AB C 小张 AB C b)基于物品的协同过滤:根据用户的历史喜好分析出相似物品,然后给用户推荐同类物品。比如小李对物品A、B、C给了十分好评,小王对物品A、C给了十分好评,从这些用户的喜好中分析出喜欢A的人都喜欢C,物品A、C是相似的,如果小张给了A好评,那么可以把C也推荐给小张,可简单理解为“物以群分”。
基于物品 初始选择 后续选择 系统推荐 小李 ABC 小王 AC 小张 A C -
基于内容过滤推荐(Content-based Filtering Recommendation):基于内容的过滤是信息检索领域的重要研究内容,是更为简单直接的算法,该算法的核心是衡量出两个物品的相似度。首先对物品或内容的特征作出描述,发现其相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。比如,小张对物品A感兴趣,而物品A和物品C是同类物品(从物品的内容描述上判断),可以把物品C也推荐给小张。
-
组合推荐(Hybrid Recommendation):以上算法各有优缺点,比如基于内容的过滤推荐是基于物品建模,在系统启动初期往往有较好的推荐效果,但是没有考虑用户群体的关联属性;协同过滤推荐考虑了用户群体喜好信息,可以推荐内容上不相似的新物品,发现用户潜在的兴趣偏好,但是这依赖于足够多且准确的用户历史信息。所以,实际应用中往往不只采用某一种推荐方法,而是通过一定的组合方法将多个算法混合在一起,以实现更好的推荐效果,比如加权混合、分层混合等。具体选择哪种方式和应用场景有很大关系。
7.2 如何实现推荐
以电影推荐为例:
如果能将用户A的原始特征转变成一种代表用户A喜好的特征向量,将电影1的原始特征转变成一种代表电影1特性的特征向量。那么,我们计算两个向量的相似度,就可以代表用户A对电影1的喜欢程度。据此,推荐系统可以如此构建:
假如给用户A推荐,计算电影库中“每一个电影的特征向量”与“用户A的特征向量”的余弦相似度,根据相似度排序电影库,取 Top k的电影推荐给A。

这样设计的核心是两个特征向量的有效性,它们会决定推荐的效果。
基于以上思路,可以将电影推荐网络模型设计如下:
- 将用户信息和电影信息的各类数据提取为向量(通过embedding,分别得到ID,性别,职业等等的特征向量)
- 再将各个类别的特征向量进行整合计算(全连接),综合得到每个用户的特征向量(200维)和每个电影的特征向量(200维),
- 将两个特征向量进行比较(余弦相似度),得到预测评分
- 将预测评分和实际评分进行比较并使得分差收敛,从而完成网络训练
最终在完成模型训练时,将获得所有用户和电影的特征向量,正是基于这些向量,我们可以比较用户和电影的特征相似度,从而进行推荐。所以我们并不是直接使用网络来进行电影推荐。

7.3 基于飞桨实现的电影推荐模型
7.3.1 电影数据类型
本次实践我们采用ml-1m电影推荐数据集,它是GroupLens Research从MovieLens网站上收集并提供的电影评分数据集。包含了6000多位用户对近3900个电影的共100万条评分数据,评分均为1~5的整数,其中每个电影的评分数据至少有20条。该数据集包含三个数据文件,分别是:
- users.dat:存储用户属性信息的文本格式文件。
- movies.dat:存储电影属性信息的文本格式文件。
- ratings.dat:存储电影评分信息的文本格式文件。
- posters:包含部分电影海报图像。
- new_rating.txt:存储包含海报图像的新评分数据文件。
用户信息、电影信息和评分信息包含的内容如下表所示。
| 用户信息 | UserID | Gender | Age | Occupation |
|---|---|---|---|---|
| 样例 | 1 | F【M/F】 | 1 | 10 |
| 电影信息 | MovieID | Title | Genres | PosterID |
|---|---|---|---|---|
| 样例 | 1 | Toy Story | Animation| Children's|Comedy | 1 |
| 评分信息 | UserID | MovieID | Rating |
|---|---|---|---|
| 样例 | 1 | 1193 | 5【1~5】 |
其中部分数据并不具有真实的含义,而是编号。年龄编号和部分职业编号的含义如下表所示。
| 年龄编号 | 职业编号 |
|---|---|
|
|
海报对应着尺寸大约为180*270的图片,每张图片尺寸稍有差别。

从样例的特征数据中,我们可以分析出特征一共有四类:
- ID类特征:UserID、MovieID、Gender、Age、Occupation,内容为ID值,前两个ID映射到具体用户和电影,后三个ID会映射到具体分档。
- 列表类特征:Genres,每个电影有多个类别标签。如果将电影类别编号,使用数字ID替换原始类别,特征内容是对应几个ID值的列表。
- 图像类特征:Poster,内容是一张180×270的图片。
- 文本类特征:Title,内容是一段英文文本。
因为特征数据有四种不同类型,所以构建模型网络的输入层预计也会有四种子结构。
7.3.2 数据处理
用户数据处理:
import numpy as np
def get_usr_info(path):
# 性别转换函数,M-0, F-1
def gender2num(gender):
return 1 if gender == 'F' else 0
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立用户信息的字典
use_info = {}
max_usr_id = 0
#按行索引数据
for item in data:
# 去除每一行中和数据无关的部分
item = item.strip().split("::")
usr_id = item[0]
# 将字符数据转成数字并保存在字典中
use_info[usr_id] = {'usr_id': int(usr_id),
'gender': gender2num(item[1]),
'age': int(item[2]),
'job': int(item[3])}
max_usr_id = max(max_usr_id, int(usr_id))
return use_info, max_usr_id
usr_file = "./work/ml-1m/users.dat"
usr_info, max_usr_id = get_usr_info(usr_file)
print("用户数量:", len(usr_info))
print("最大用户ID:", max_usr_id)
print("第1个用户的信息是:", usr_info['1'])
------------------------------------------------------------------------------
用户数量: 6040
最大用户ID: 6040
第1个用户的信息是: {'usr_id': 1, 'gender': 1, 'age': 1, 'job': 10}
电影数据处理:
def get_movie_info(path):
# 打开文件,编码方式选择ISO-8859-1,读取所有数据到data中
with open(path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
# 建立三个字典,分别用户存放电影所有信息,电影的名字信息、类别信息
movie_info, movie_titles, movie_cat = {}, {}, {}
# 对电影名字、类别中不同的单词计数
t_count, c_count = 1, 1
# 初始化电影名字和种类的列表
titles = []
cats = []
count_tit = {}
# 按行读取数据并处理
for item in data:
item = item.strip().split("::")
v_id = item[0]
v_title = item[1][:-7]
cats = item[2].split('|')
v_year = item[1][-5:-1]
titles = v_title.split()
# 统计电影名字的单词,并给每个单词一个序号,放在movie_titles中
for t in titles:
if t not in movie_titles:
movie_titles[t] = t_count
t_count += 1
# 统计电影类别单词,并给每个单词一个序号,放在movie_cat中
for cat in cats:
if cat not in movie_cat:
movie_cat[cat] = c_count
c_count += 1
# 补0使电影名称对应的列表长度为15
v_tit = [movie_titles[k] for k in titles]
while len(v_tit)<15:
v_tit.append(0)
# 补0使电影种类对应的列表长度为6
v_cat = [movie_cat[k] for k in cats]
while len(v_cat)<6:
v_cat.append(0)
# 保存电影数据到movie_info中
movie_info[v_id] = {'mov_id': int(v_id),
'title': v_tit,
'category': v_cat,
'years': int(v_year)}
return movie_info, movie_cat, movie_titles
movie_info_path = "./work/ml-1m/movies.dat"
movie_info, movie_cat, movie_titles = get_movie_info(movie_info_path)
print("电影数量:", len(movie_info))
ID = 1
print("原始的电影ID为 {} 的数据是:".format(ID), data[ID-1])
print("电影ID为 {} 的转换后数据是:".format(ID), movie_info[str(ID)])
print("电影种类对应序号:'Animation':{} 'Children's':{} 'Comedy':{}".format(movie_cat['Animation'],
movie_cat["Children's"],
movie_cat['Comedy']))
print("电影名称对应序号:'The':{} 'Story':{} ".format(movie_titles['The'], movie_titles['Story']))
--------------------------------------------------------------------------------
电影数量: 3883
原始的电影ID为 1 的数据是: 1::Toy Story (1995)::Animation|Children's|Comedy
电影ID为 1 的转换后数据是: {'mov_id': 1, 'title': [1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'category': [1, 2, 3, 0, 0, 0], 'years': 1995}
电影种类对应序号:'Animation':1 'Children's':2 'Comedy':3
电影名称对应序号:'The':26 'Story':2 评分数据处理:
def get_rating_info(path):
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 创建一个字典
rating_info = {}
for item in data:
item = item.strip().split("::")
# 处理每行数据,分别得到用户ID,电影ID,和评分
usr_id,movie_id,score = item[0],item[1],item[2]
if usr_id not in rating_info.keys():
rating_info[usr_id] = {movie_id:float(score)}
else:
rating_info[usr_id][movie_id] = float(score)
return rating_info
# 获得评分数据
#rating_path = "./work/ml-1m/ratings.dat"
rating_info = get_rating_info(rating_path)
print("ID为1的用户一共评价了{}个电影".format(len(rating_info['1'])))
-------------------------------------------------------------------------------
ID为1的用户一共评价了53个电影海报数据处理:
from PIL import Image
import matplotlib.pyplot as plt
# 使用海报图像和不使用海报图像的文件路径不同,处理方式相同
use_poster = True
if use_poster:
rating_path = "./work/ml-1m/new_rating.txt"
else:
rating_path = "./work/ml-1m/ratings.dat"
with open(rating_path, 'r') as f:
data = f.readlines()
# 从新的rating文件中收集所有的电影ID
mov_id_collect = []
for item in data:
item = item.strip().split("::")
usr_id,movie_id,score = item[0],item[1],item[2]
mov_id_collect.append(movie_id)
# 根据电影ID读取图像
poster_path = "./work/ml-1m/posters/"
# 显示mov_id_collect中第几个电影ID的图像
idx = 1
poster = Image.open(poster_path+'mov_id{}.jpg'.format(str(mov_id_collect[idx])))
plt.figure("Image") # 图像窗口名称
plt.imshow(poster)
plt.axis('on') # 关掉坐标轴为 off
plt.title("poster with ID {}".format(mov_id_collect[idx])) # 图像题目
plt.show()7.3.4 数据读取器
首先,构造一个函数,把读取并处理后的数据整合到一起,即在rating数据中补齐用户和电影的所有特征字段。
def get_dataset(usr_info, rating_info, movie_info):
trainset = []
# 按照评分数据的key值索引数据
for usr_id in rating_info.keys():
usr_ratings = rating_info[usr_id]
for movie_id in usr_ratings:
trainset.append({'usr_info': usr_info[usr_id],
'mov_info': movie_info[movie_id],
'scores': usr_ratings[movie_id]})
return trainset
dataset = get_dataset(usr_info, rating_info, movie_info)
print("数据集总数据数:", len(dataset))
--------------------------------------------------------------------------
数据集总数据数: 1000209接下来构建数据读取器函数load_data():
import random
use_poster = False
def load_data(dataset=None, mode='train'):
# 定义数据迭代Batch大小
BATCHSIZE = 256
data_length = len(dataset)
index_list = list(range(data_length))
# 定义数据迭代加载器
def data_generator():
# 训练模式下,打乱训练数据
if mode == 'train':
random.shuffle(index_list)
# 声明每个特征的列表
usr_id_list,usr_gender_list,usr_age_list,usr_job_list = [], [], [], []
mov_id_list,mov_tit_list,mov_cat_list,mov_poster_list = [], [], [], []
score_list = []
# 索引遍历输入数据集
for idx, i in enumerate(index_list):
# 获得特征数据保存到对应特征列表中
usr_id_list.append(dataset[i]['usr_info']['usr_id'])
usr_gender_list.append(dataset[i]['usr_info']['gender'])
usr_age_list.append(dataset[i]['usr_info']['age'])
usr_job_list.append(dataset[i]['usr_info']['job'])
mov_id_list.append(dataset[i]['mov_info']['mov_id'])
mov_tit_list.append(dataset[i]['mov_info']['title'])
mov_cat_list.append(dataset[i]['mov_info']['category'])
mov_id = dataset[i]['mov_info']['mov_id']
if use_poster:
# 不使用图像特征时,不读取图像数据,加快数据读取速度
poster = Image.open(poster_path+'mov_id{}.jpg'.format(str(mov_id)))
poster = poster.resize([64, 64])
if len(poster.size) <= 2:
poster = poster.convert("RGB")
mov_poster_list.append(np.array(poster))
score_list.append(int(dataset[i]['scores']))
# 如果读取的数据量达到当前的batch大小,就返回当前批次
if len(usr_id_list)==BATCHSIZE:
# 转换列表数据为数组形式,reshape到固定形状
usr_id_arr = np.array(usr_id_list)
usr_gender_arr = np.array(usr_gender_list)
usr_age_arr = np.array(usr_age_list)
usr_job_arr = np.array(usr_job_list)
mov_id_arr = np.array(mov_id_list)
mov_cat_arr = np.reshape(np.array(mov_cat_list), [BATCHSIZE, 6]).astype(np.int64)
mov_tit_arr = np.reshape(np.array(mov_tit_list), [BATCHSIZE, 1, 15]).astype(np.int64)
if use_poster:
mov_poster_arr = np.reshape(np.array(mov_poster_list)/127.5 - 1, [BATCHSIZE, 3, 64, 64]).astype(np.float32)
else:
mov_poster_arr = np.array([0.])
scores_arr = np.reshape(np.array(score_list), [-1, 1]).astype(np.float32)
# 返回当前批次数据
yield [usr_id_arr, usr_gender_arr, usr_age_arr, usr_job_arr], \
[mov_id_arr, mov_cat_arr, mov_tit_arr, mov_poster_arr], scores_arr
# 清空数据
usr_id_list, usr_gender_list, usr_age_list, usr_job_list = [], [], [], []
mov_id_list, mov_tit_list, mov_cat_list, score_list = [], [], [], []
mov_poster_list = []
return data_generator
# 声明数据读取类
dataset = MovieLen(False)
# 定义数据读取器
train_loader = dataset.load_data(dataset=dataset.train_dataset, mode='train')
# 迭代的读取数据, Batchsize = 256
for idx, data in enumerate(train_loader()):
usr, mov, score = data
print("打印用户ID,性别,年龄,职业数据的维度:")
for v in usr:
print(v.shape)
print("打印电影ID,名字,类别数据的维度:")
for v in mov:
print(v.shape)
break
----------------------------------------------------------------------------------
##Total dataset instances: 1000209
##MovieLens dataset information:
usr num: 6040
movies num: 3883
打印用户ID,性别,年龄,职业数据的维度:
(256,)
(256,)
(256,)
(256,)
打印电影ID,名字,类别数据的维度:
(256,)
(256, 6)
(256, 1, 15)
(1,)7.3.4 网络构建
7.3.4.1用户特征提取
用户特征网络主要包括:
- 将用户ID数据映射为向量表示,通过全连接层得到ID特征。
- 将用户性别数据映射为向量表示,通过全连接层得到性别特征。
- 将用户职业数据映射为向量表示,通过全连接层得到职业特征。
- 将用户年龄数据影射为向量表示,通过全连接层得到年龄特征。
- 融合ID、性别、职业、年龄特征,得到用户的特征表示。
在用户特征计算网络中,我们对每个用户数据做embedding处理,然后经过一个全连接层,激活函数使用ReLU,得到用户所有特征后,将特征整合,经过一个全连接层得到最终的用户数据特征,该特征的维度是200维,用于和电影特征计算相似度。
1. 提取用户特征。首先分别对用户不同类别的数据(ID, 性别,职业,年龄)使用embedding提取特征向量,下面以提取ID特征为例,其他类别处理方式类似。
# 自定义一个用户ID数据
usr_id_data = np.random.randint(0, 6040, (2)).reshape((-1)).astype('int64')
print("输入的用户ID是:", usr_id_data)
USR_ID_NUM = 6040 + 1
# 定义用户ID的embedding层和fc层
usr_emb = Embedding(num_embeddings=USR_ID_NUM,
embedding_dim=32,
sparse=False)
usr_fc = Linear(in_features=32, out_features=32)
usr_id_var = paddle.to_tensor(usr_id_data)
usr_id_feat = usr_fc(usr_emb(usr_id_var))
usr_id_feat = F.relu(usr_id_feat)
print("用户ID的特征是:", usr_id_feat.numpy(), "\n其形状是:", usr_id_feat.shape)
------------------------------------------------------------------------------------
输入的用户ID是: [404 55]
用户ID的特征是: [[0.02347164 0. 0.00114313 0. 0. 0.01086394
0. 0. 0. 0.01131915 0.02601143 0.0191745
0. 0. 0. 0.03315771 0. 0.
0.0051814 0.01694535 0. 0.02378889 0.00864096 0.02959694
0.0082613 0. 0.02341099 0. 0. 0.
0. 0.0023096 ]
[0.03071208 0. 0. 0.00296267 0.01383776 0.
0. 0. 0.00759998 0.00332768 0.00829613 0.0228811
0. 0.01196356 0. 0.01992911 0.01161416 0.00963254
0. 0.01359453 0.00222658 0.03191457 0. 0.02897926
0. 0. 0.03653618 0. 0. 0.00512143
0. 0. ]]
其形状是: [2, 32]2. 融合用户所有特征。有两种方式实现:
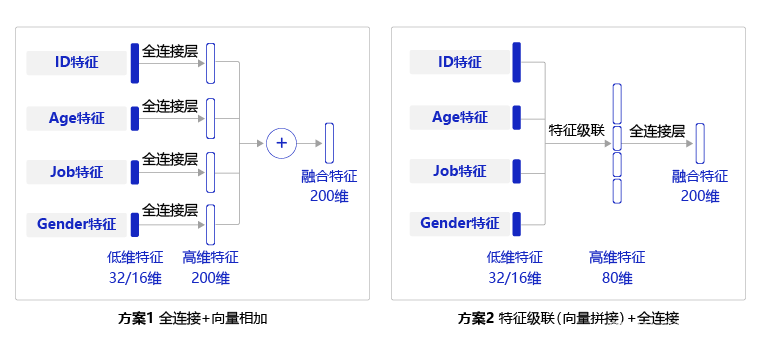
2.1 每个特征使用一个全连接层:
每个特征向量通过全连接层统一扩展为200的维度,再进行相加
FC_ID = Linear(in_features=32, out_features=200)
FC_JOB = Linear(in_features=16, out_features=200)
FC_AGE = Linear(in_features=16, out_features=200)
FC_GENDER = Linear(in_features=16, out_features=200)
# 收集所有的用户特征
_features = [usr_id_feat, usr_job_feat, usr_age_feat, usr_gender_feat]
_features = [k.numpy() for k in _features]
_features = [paddle.to_tensor(k) for k in _features]
id_feat = F.tanh(FC_ID(_features[0]))
job_feat = F.tanh(FC_JOB(_features[1]))
age_feat = F.tanh(FC_AGE(_features[2]))
genger_feat = F.tanh(FC_GENDER(_features[-1]))
# 对特征求和
usr_feat = id_feat + job_feat + age_feat + genger_feat
print("用户融合后特征的维度是:", usr_feat.shape)
----------------------------------------------------------------------
用户融合后特征的维度是: [2, 200]2.2 使用一个全连接层
上述实现中需要对每个特征都使用一个全连接层,实现较为复杂,一种简单的替换方式是,先将每个用户特征沿着长度维度进行级联,然后使用一个全连接层获得整个用户特征向量,两种方式的对比见下图:
usr_combined = Linear(in_features=80, out_features=200)
# 收集所有的用户特征
_features = [usr_id_feat, usr_job_feat, usr_age_feat, usr_gender_feat]
print("打印每个特征的维度:", [f.shape for f in _features])
_features = [k.numpy() for k in _features]
_features = [paddle.to_tensor(k) for k in _features]
# 对特征沿着最后一个维度级联
usr_feat = paddle.concat(_features, axis=1)
usr_feat = F.tanh(usr_combined(usr_feat))
print("用户融合后特征的维度是:", usr_feat.shape)
---------------------------------------------------------------------------
打印每个特征的维度: [[2, 32], [2, 16], [2, 16], [2, 16]]
用户融合后特征的维度是: [2, 200]7.3.4.2 电影特征提取
与用户特征提取类似。
7.3.4.3 相似度计算
得到用户特征和电影特征后,我们还需要计算特征之间的相似度。可以通过余弦相似度来计算。
def similarty(usr_feature, mov_feature):
res = F.cosine_similarity(usr_feature, mov_feature)
res = paddle.scale(res, scale=5)
return usr_feat, mov_feat, res
# 使用上文计算得到的用户特征和电影特征计算相似度
usr_feat, mov_feat, _sim = similarty(usr_feat, mov_feat)
print("相似度得分是:", np.squeeze(_sim.numpy()))7.3.4.4 网络模型完整代码
class Model(nn.Layer):
def __init__(self, use_poster, use_mov_title, use_mov_cat, use_age_job):
super(Model, self).__init__()
# 将传入的name信息和bool型参数添加到模型类中
self.use_mov_poster = use_poster
self.use_mov_title = use_mov_title
self.use_usr_age_job = use_age_job
self.use_mov_cat = use_mov_cat
# 获取数据集的信息,并构建训练和验证集的数据迭代器
Dataset = MovieLen(self.use_mov_poster)
self.Dataset = Dataset
self.trainset = self.Dataset.train_dataset
self.valset = self.Dataset.valid_dataset
self.train_loader = self.Dataset.load_data(dataset=self.trainset, mode='train')
self.valid_loader = self.Dataset.load_data(dataset=self.valset, mode='valid')
""" define network layer for embedding usr info """
USR_ID_NUM = Dataset.max_usr_id + 1
# 对用户ID做映射,并紧接着一个Linear层
self.usr_emb = Embedding(num_embeddings=USR_ID_NUM, embedding_dim=32, sparse=False)
self.usr_fc = Linear(in_features=32, out_features=32)
# 对用户性别信息做映射,并紧接着一个Linear层
USR_GENDER_DICT_SIZE = 2
self.usr_gender_emb = Embedding(num_embeddings=USR_GENDER_DICT_SIZE, embedding_dim=16)
self.usr_gender_fc = Linear(in_features=16, out_features=16)
# 对用户年龄信息做映射,并紧接着一个Linear层
USR_AGE_DICT_SIZE = Dataset.max_usr_age + 1
self.usr_age_emb = Embedding(num_embeddings=USR_AGE_DICT_SIZE, embedding_dim=16)
self.usr_age_fc = Linear(in_features=16, out_features=16)
# 对用户职业信息做映射,并紧接着一个Linear层
USR_JOB_DICT_SIZE = Dataset.max_usr_job + 1
self.usr_job_emb = Embedding(num_embeddings=USR_JOB_DICT_SIZE, embedding_dim=16)
self.usr_job_fc = Linear(in_features=16, out_features=16)
# 新建一个Linear层,用于整合用户数据信息
self.usr_combined = Linear(in_features=80, out_features=200)
""" define network layer for embedding usr info """
# 对电影ID信息做映射,并紧接着一个Linear层
MOV_DICT_SIZE = Dataset.max_mov_id + 1
self.mov_emb = Embedding(num_embeddings=MOV_DICT_SIZE, embedding_dim=32)
self.mov_fc = Linear(in_features=32, out_features=32)
# 对电影类别做映射
CATEGORY_DICT_SIZE = len(Dataset.movie_cat) + 1
self.mov_cat_emb = Embedding(num_embeddings=CATEGORY_DICT_SIZE, embedding_dim=32, sparse=False)
self.mov_cat_fc = Linear(in_features=32, out_features=32)
# 对电影名称做映射
MOV_TITLE_DICT_SIZE = len(Dataset.movie_title) + 1
self.mov_title_emb = Embedding(num_embeddings=MOV_TITLE_DICT_SIZE, embedding_dim=32, sparse=False)
self.mov_title_conv = Conv2D(in_channels=1, out_channels=1, kernel_size=(3, 1), stride=(2,1), padding=0)
self.mov_title_conv2 = Conv2D(in_channels=1, out_channels=1, kernel_size=(3, 1), stride=1, padding=0)
# 新建一个FC层,用于整合电影特征
self.mov_concat_embed = Linear(in_features=96, out_features=200)
user_sizes = [200] + self.fc_sizes
acts = ["relu" for _ in range(len(self.fc_sizes))]
self._user_layers = []
for i in range(len(self.fc_sizes)):
linear = Linear(
in_features=user_sizes[i],
out_features=user_sizes[i + 1],
weight_attr=paddle.ParamAttr(
initializer=nn.initializer.Normal(
std=1.0 / math.sqrt(user_sizes[i]))))
self.add_sublayer('linear_user_%d' % i, linear)
self._user_layers.append(linear)
if acts[i] == 'relu':
act = nn.ReLU()
self.add_sublayer('user_act_%d' % i, act)
self._user_layers.append(act)
#电影特征和用户特征使用了不同的全连接层,不共享参数
movie_sizes = [200] + self.fc_sizes
acts = ["relu" for _ in range(len(self.fc_sizes))]
self._movie_layers = []
for i in range(len(self.fc_sizes)):
linear = nn.Linear(
in_features=movie_sizes[i],
out_features=movie_sizes[i + 1],
weight_attr=paddle.ParamAttr(
initializer=nn.initializer.Normal(
std=1.0 / math.sqrt(movie_sizes[i]))))
self.add_sublayer('linear_movie_%d' % i, linear)
self._movie_layers.append(linear)
if acts[i] == 'relu':
act = nn.ReLU()
self.add_sublayer('movie_act_%d' % i, act)
self._movie_layers.append(act)
# 定义计算用户特征的前向运算过程
def get_usr_feat(self, usr_var):
""" get usr features"""
# 获取到用户数据
usr_id, usr_gender, usr_age, usr_job = usr_var
# 将用户的ID数据经过embedding和Linear计算,得到的特征保存在feats_collect中
feats_collect = []
usr_id = self.usr_emb(usr_id)
usr_id = self.usr_fc(usr_id)
usr_id = F.relu(usr_id)
feats_collect.append(usr_id)
# 计算用户的性别特征,并保存在feats_collect中
usr_gender = self.usr_gender_emb(usr_gender)
usr_gender = self.usr_gender_fc(usr_gender)
usr_gender = F.relu(usr_gender)
feats_collect.append(usr_gender)
# 选择是否使用用户的年龄-职业特征
if self.use_usr_age_job:
# 计算用户的年龄特征,并保存在feats_collect中
usr_age = self.usr_age_emb(usr_age)
usr_age = self.usr_age_fc(usr_age)
usr_age = F.relu(usr_age)
feats_collect.append(usr_age)
# 计算用户的职业特征,并保存在feats_collect中
usr_job = self.usr_job_emb(usr_job)
usr_job = self.usr_job_fc(usr_job)
usr_job = F.relu(usr_job)
feats_collect.append(usr_job)
# 将用户的特征级联,并通过Linear层得到最终的用户特征
usr_feat = paddle.concat(feats_collect, axis=1)
user_features = F.tanh(self.usr_combined(usr_feat))
#通过3层全链接层,获得用于计算相似度的用户特征和电影特征
for n_layer in self._user_layers:
user_features = n_layer(user_features)
return user_features
# 定义电影特征的前向计算过程
def get_mov_feat(self, mov_var):
""" get movie features"""
# 获得电影数据
mov_id, mov_cat, mov_title, mov_poster = mov_var
feats_collect = []
# 获得batchsize的大小
batch_size = mov_id.shape[0]
# 计算电影ID的特征,并存在feats_collect中
mov_id = self.mov_emb(mov_id)
mov_id = self.mov_fc(mov_id)
mov_id = F.relu(mov_id)
feats_collect.append(mov_id)
# 如果使用电影的种类数据,计算电影种类特征的映射
if self.use_mov_cat:
# 计算电影种类的特征映射,对多个种类的特征求和得到最终特征
mov_cat = self.mov_cat_emb(mov_cat)
mov_cat = paddle.sum(mov_cat, axis=1, keepdim=False)
mov_cat = self.mov_cat_fc(mov_cat)
feats_collect.append(mov_cat)
if self.use_mov_title:
# 计算电影名字的特征映射,对特征映射使用卷积计算最终的特征
mov_title = self.mov_title_emb(mov_title)
mov_title = F.relu(self.mov_title_conv2(F.relu(self.mov_title_conv(mov_title))))
mov_title = paddle.sum(mov_title, axis=2, keepdim=False)
mov_title = F.relu(mov_title)
mov_title = paddle.reshape(mov_title, [batch_size, -1])
feats_collect.append(mov_title)
# 使用一个全连接层,整合所有电影特征,映射为一个200维的特征向量
mov_feat = paddle.concat(feats_collect, axis=1)
mov_features = F.tanh(self.mov_concat_embed(mov_feat))
for n_layer in self._movie_layers:
mov_features = n_layer(mov_features)
return mov_features
# 定义个性化推荐算法的前向计算
def forward(self, usr_var, mov_var):
# 计算用户特征和电影特征
usr_feat = self.get_usr_feat(usr_var)
mov_feat = self.get_mov_feat(mov_var)
#通过3层全连接层,获得用于计算相似度的用户特征和电影特征
for n_layer in self._user_layers:
user_features = n_layer(user_features)
for n_layer in self._movie_layers:
mov_features = n_layer(mov_features)
# 根据计算的特征计算相似度
res = F.cosine_similarity(user_features, mov_features)
# 将相似度扩大范围到和电影评分相同数据范围
res = paddle.scale(res, scale=5)
return usr_feat, mov_feat, res7.3 根据推荐案例的思考
-
Deep Learning is all about “Embedding Everything”。不难发现,深度学习建模是套路满满的。任何事物均用向量的方式表示,可以直接基于向量完成“分类”或“回归”任务;也可以计算多个向量之间的关系,无论这种关系是“相似性”还是“比较排序”。在深度学习兴起不久的2015年,当时AI相关的国际学术会议上,大部分论文均是将某个事物Embedding后再进行挖掘,火热的程度仿佛即使是路边一块石头,也要Embedding一下看看是否能挖掘出价值。直到近些年,能够Embedding的事物基本都发表过论文,Embeddding的方法也变得成熟,这方面的论文才逐渐有减少的趋势。
-
在深度学习兴起之前,不同领域之间的迁移学习往往要用到很多特殊设计的算法。但深度学习兴起后,迁移学习变得尤其自然。训练模型和使用模型未必是同样的方式,中间基于Embedding的向量表示,即可实现不同任务交换信息。例如本章的推荐模型使用用户对电影的评分数据进行监督训练,训练好的特征向量可以用于计算用户与用户的相似度,以及电影与电影之间的相似度。对特征向量的使用可以极其灵活,而不局限于训练时的任务。
-
网络调参:神经网络模型并没有一套理论上可推导的最优规则,实际中的网络设计往往是在理论和经验指导下的“探索”活动。例如推荐模型的每层网络尺寸的设计遵从了信息熵的原则,原始信息量越大对应表示的向量长度就越长。但具体每一层的向量应该有多长,往往是根据实际训练的效果进行调整。所以,建模工程师被称为数据处理工程师和调参工程师是有道理的,大量的精力花费在处理样本数据和模型调参上。