转载至我的博客 https://www.infrastack.cn ,公众号:架构成长指南
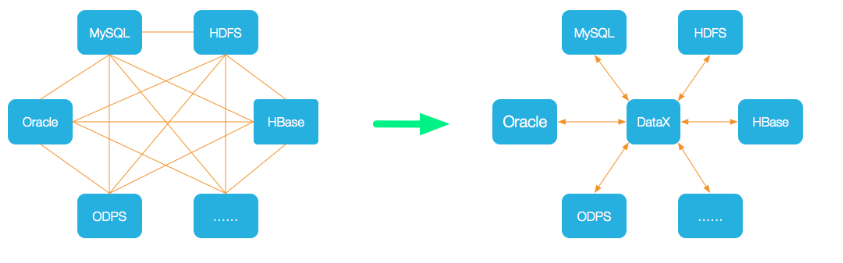
今天给大家分享一个阿里开源的数据同步工具DataX,在Github拥有14.8k的star,非常受欢迎,官网地址:https://github.com/alibaba/DataX
什么是 Datax?
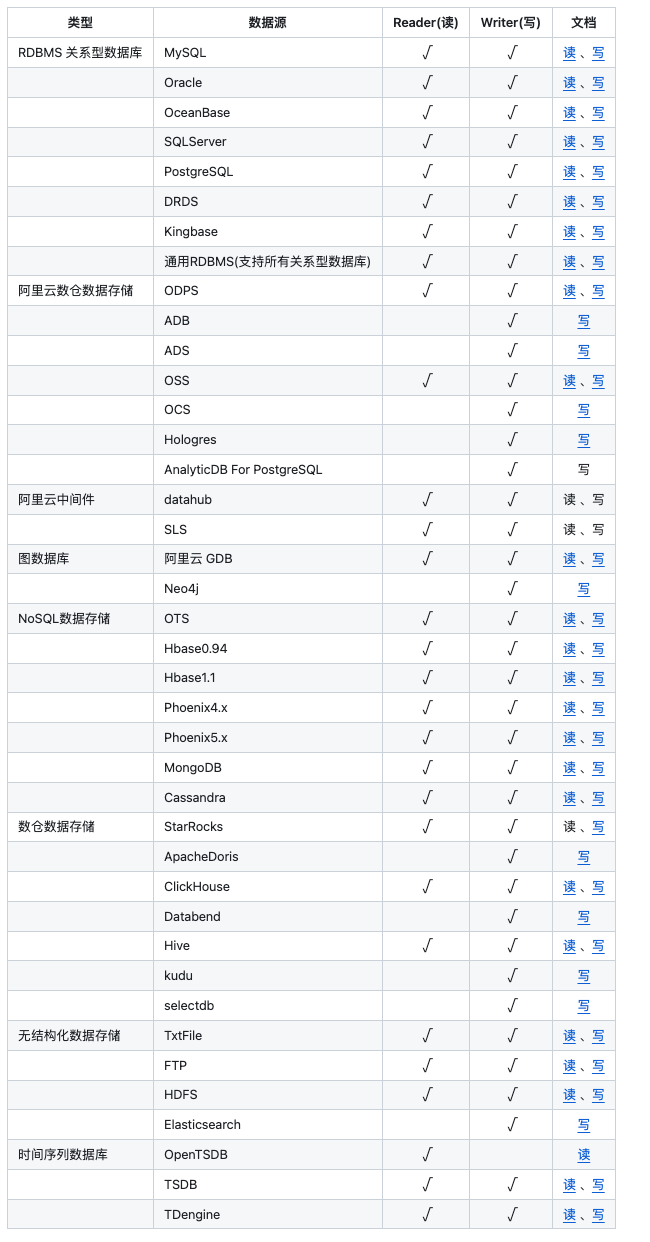
DataX 是阿里云 DataWorks数据集成 的开源版本,使用Java 语言编写,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
应用场景有那些?
- 数据仓库同步:DataX 可以帮助将数据从一个数据仓库(如关系型数据库、大数据存储系统等)同步到另一个数据仓库,实现数据的迁移、备份或复制。
- 数据库迁移:当我们需要将数据从一个数据库平台迁移到另一个数据库平台时,DataX 可以帮助完成数据的转移和转换工作
- 数据集成与同步:DataX 可以用作数据集成工具,用于将多个数据源的数据进行整合和同步。它支持多种数据源,包括关系型数据库、NoSQL 数据库、文件系统等,可以将这些数据源的数据整合到一个目标数据源中。
- 数据清洗与转换:DataX 提供了丰富的数据转换能力,可以对数据进行清洗、过滤、映射、格式转换等操作。这对于数据仓库、数据湖和数据集市等数据存储和分析平台非常有用,可以帮助提高数据质量和一致性。
- 数据备份与恢复:DataX 可以用于定期备份和恢复数据。通过配置定时任务,可以将数据从源端备份到目标端,并在需要时进行数据恢复。
DataX支持那些数据源?
架构设计

DataX作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 开源版本支持单机多线程模式完成同步作业运行,如下图
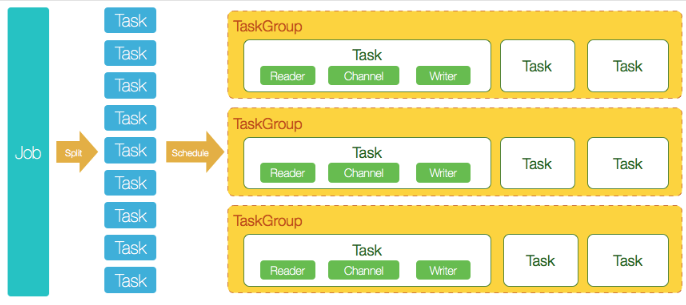
- DataX完成单个数据同步的作业,称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张表的mysql数据同步到odps里面。 DataX的调度决策是:
- Job根据分表切分成了100个Task。
- 根据20个并发,DataX计算需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责5个并发共计运行25个Task。
如何使用 Datax?
点击datax 下载,下载后解压至本地某个目录,如下图

用例说明
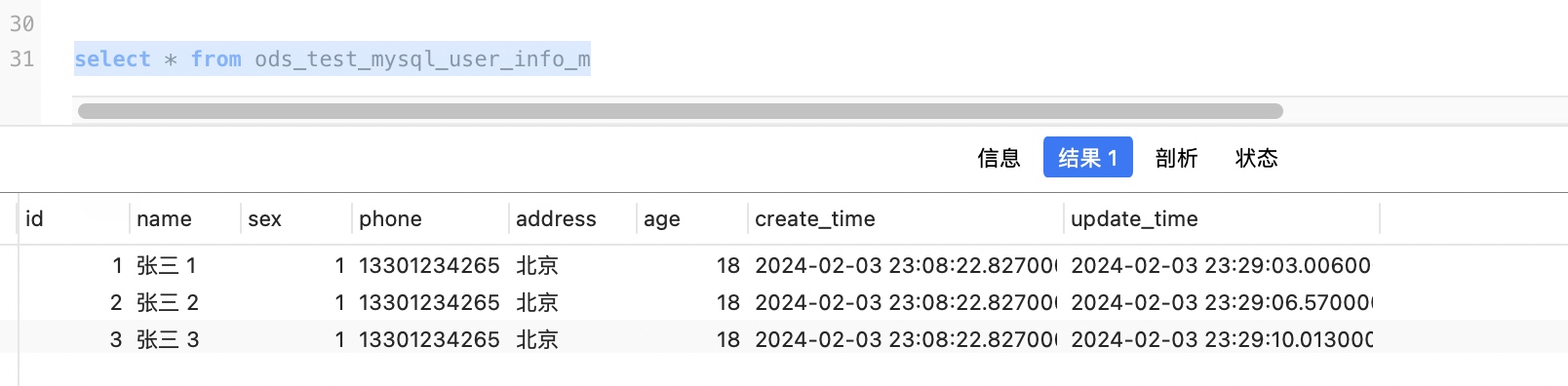
这里为了方便演示,我们同步MySQL的user_info表至MySQL的ods_test_mysql_user_info_m,同步条件为更新时间字段,如下
在实际工作中你可以选择不同类型的数据源测试
drop table ods_test_mysql_user_info_m
CREATE TABLE `user_info` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(50) NOT NULL COMMENT '名称',
`sex` tinyint NOT NULL COMMENT '性别 1男 2女',
`phone` varchar(11) COMMENT '手机',
`address` varchar(1000) COMMENT '地址',
`age` int COMMENT '年龄',
`create_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) COMMENT '创建时间',
`update_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='用户信息表';
CREATE TABLE `ods_test_mysql_user_info_m` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(50) NOT NULL COMMENT '名称',
`sex` tinyint NOT NULL COMMENT '性别 1男 2女',
`phone` varchar(11) COMMENT '手机',
`address` varchar(1000) COMMENT '地址',
`age` int COMMENT '年龄',
`create_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) COMMENT '创建时间',
`update_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='用户信息数仓表';
在user_info表中插入数据如下

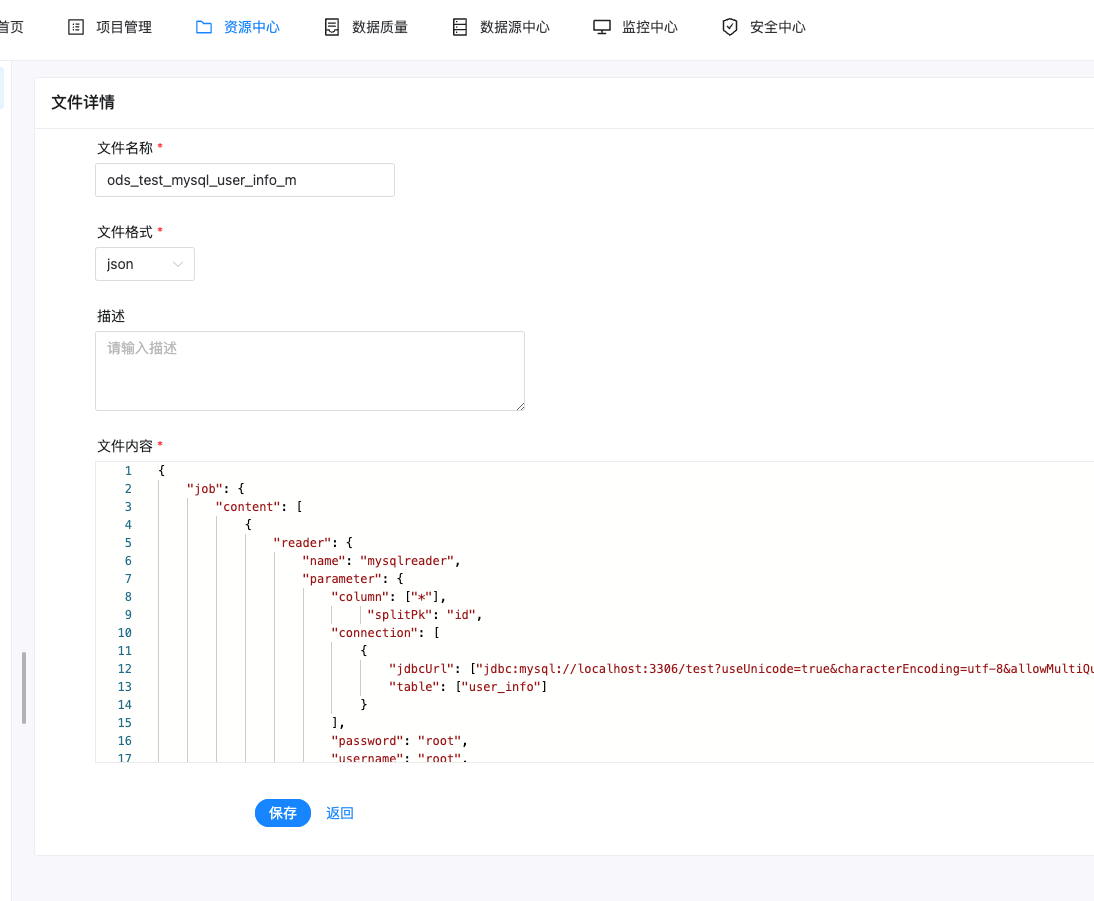
创建作业的配置文件(json格式)
在 datax 的 script 目录,创建ods_test_mysql_user_info_m.json文件,配置如下,mysqlreader表示读取端,mysqlwriter表示写入端
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name","sex","phone","address","age","create_time","update_time"],
"splitPk": "id",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false"],
"table": ["user_info"]
}
],
"password": "root",
"username": "root",
"where": "update_time > '${updateTime}' "
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"column": ["id","name","sex","phone","address","age","create_time","update_time"],
"connection": [
{
"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"table": ["ods_test_mysql_user_info_m"]
}
],
"username": "root",
"password": "root",
"preSql": [],
"session": [
"set session sql_mode='ANSI'"
]
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
创建执行脚本
为了更贴合实际,写一个调度脚本sync.sh支持动态参数来执行任务
#!/bin/bash
## 执行示例 sh /Users/weizhao.dong/Documents/soft/datax/datax-script/call.sh /Users/weizhao.dong/Documents/soft/datax/datax-script/dwd_g2park_inout_report_s.json 1
jsonScript=$1
echo '执行脚本:'$jsonScript
interval=$2
echo "时间间隔(分钟):"$interval
now_time=$(date '+%Y-%m-%d %H:%M:%S')
echo "当前时间:"$now_time
update_time=$(date -v -${interval}M '+%Y-%m-%d %H:%M:%S')
#linux 更新时间获取
#update_time=$(date -d "${now_time} $interval minute ago" +"%Y-%m-%d %H:%M:%S")
echo "更新时间:"$update_time
#执行
python3 /Users/weizhao.dong/Documents/soft/datax/bin/datax.py $jsonScript -p "-DupdateTime='${update_time}'"
假设我们要执以上ods_test_mysql_user_info_m.json脚本,并且同步十分钟之前的数据,如下
./sync.sh ods_test_mysql_user_info_m.json 10
测试
执行./sync.sh ods_test_mysql_user_info_m.json 10进行同步

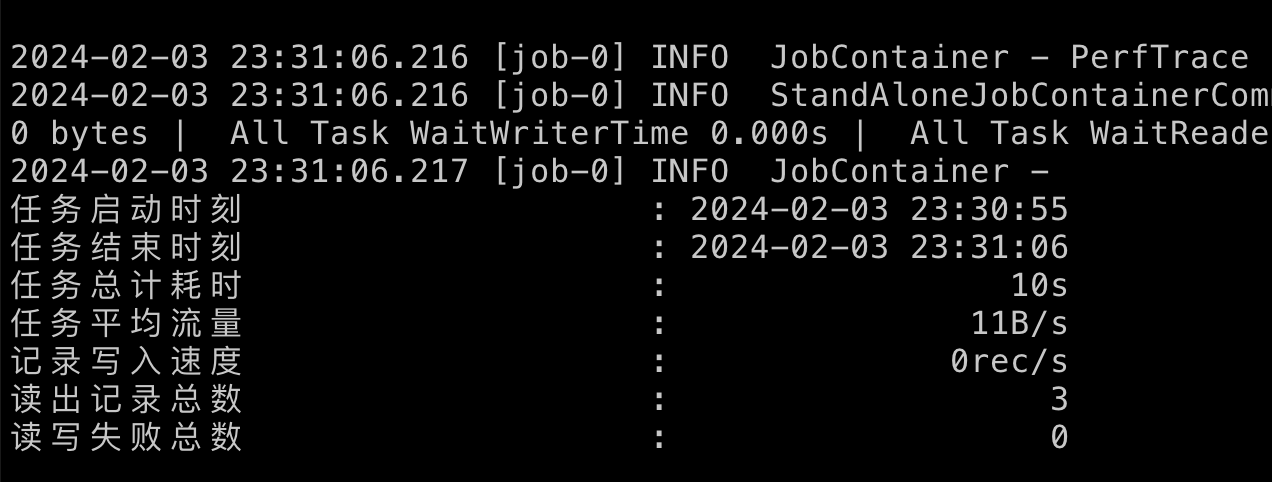
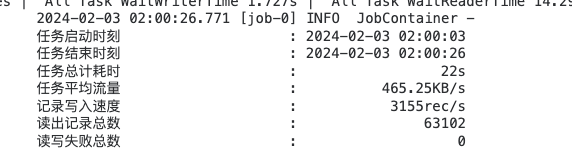
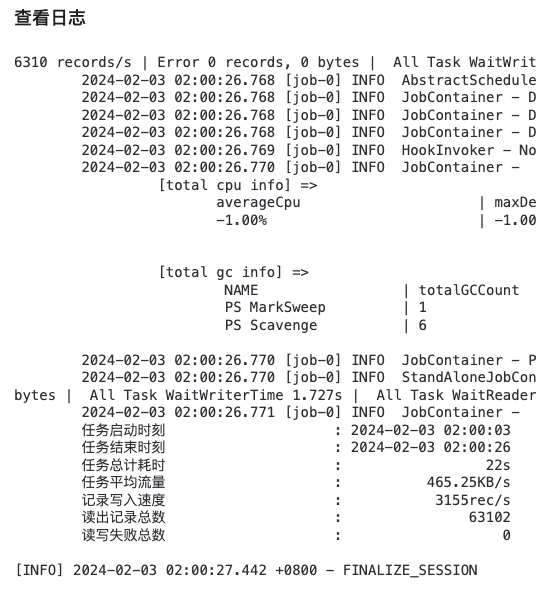
以上结果可能有些人有疑问,就三条数据执行时间为 10s,其实这个 10s主要是初始化时间,耗时过长,同步的数据量多了优势就体现出来了,以下为实际生产同步数据结果,可以看到同步63102条耗时22s
推荐用法
以上我们只是通过一个简单的示例来演示了dataX如何使用,如果只是一次性同步,没问题,但是如果是周期性进行同步,有以下几种方式推荐
crontab调度
这种方式是最简单的,可以使用操作系统中的crontab定时调度,通过crontab -e编辑corn 任务,添加对应脚本即可
海豚调度器
在种方式在大数据领域用的比较多,典型场景就是 mysql 同步到数仓,海豚调度器内置了 datax 并且提供了图形化配置界面,配置起来非常方便
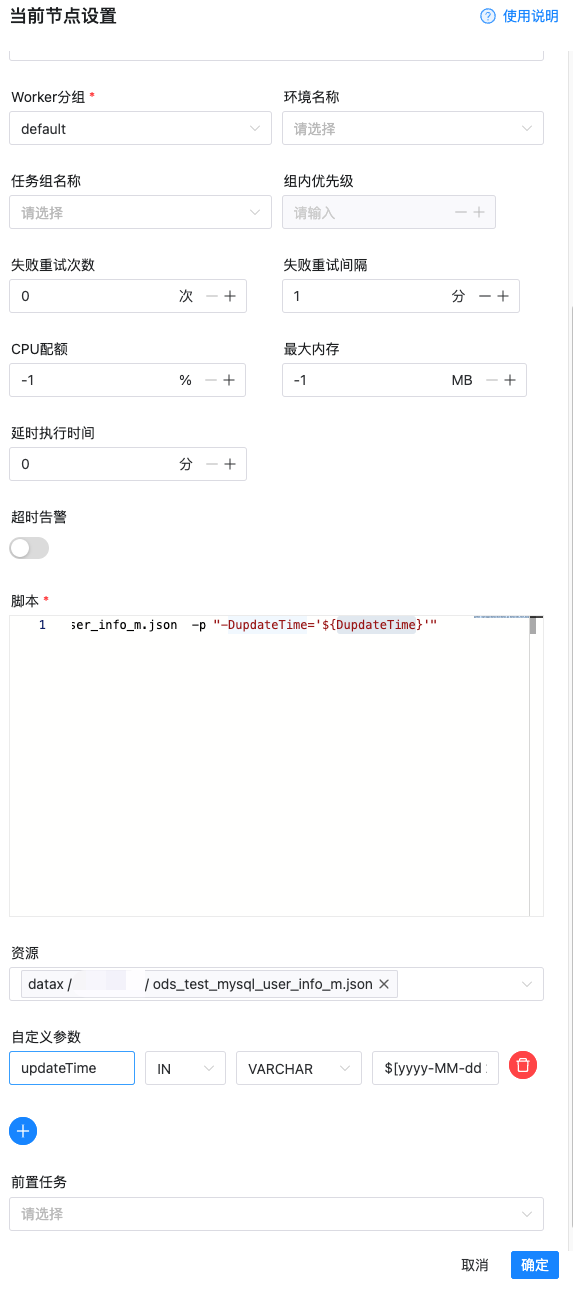
同时每次执行都有记录,并且都有对应的日志
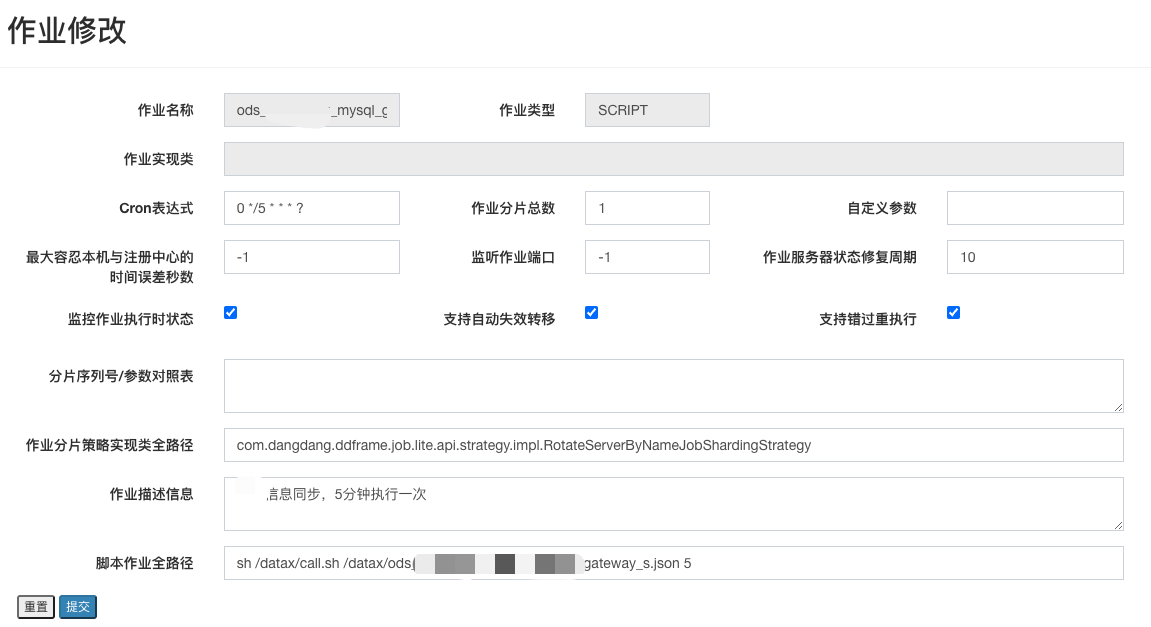
定时任务框架(elasticjob/xxl-job)
在我们实际使用的业务系统定时调度框架都支持调度 shell 脚本,通过传入对应参数也可执行
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。