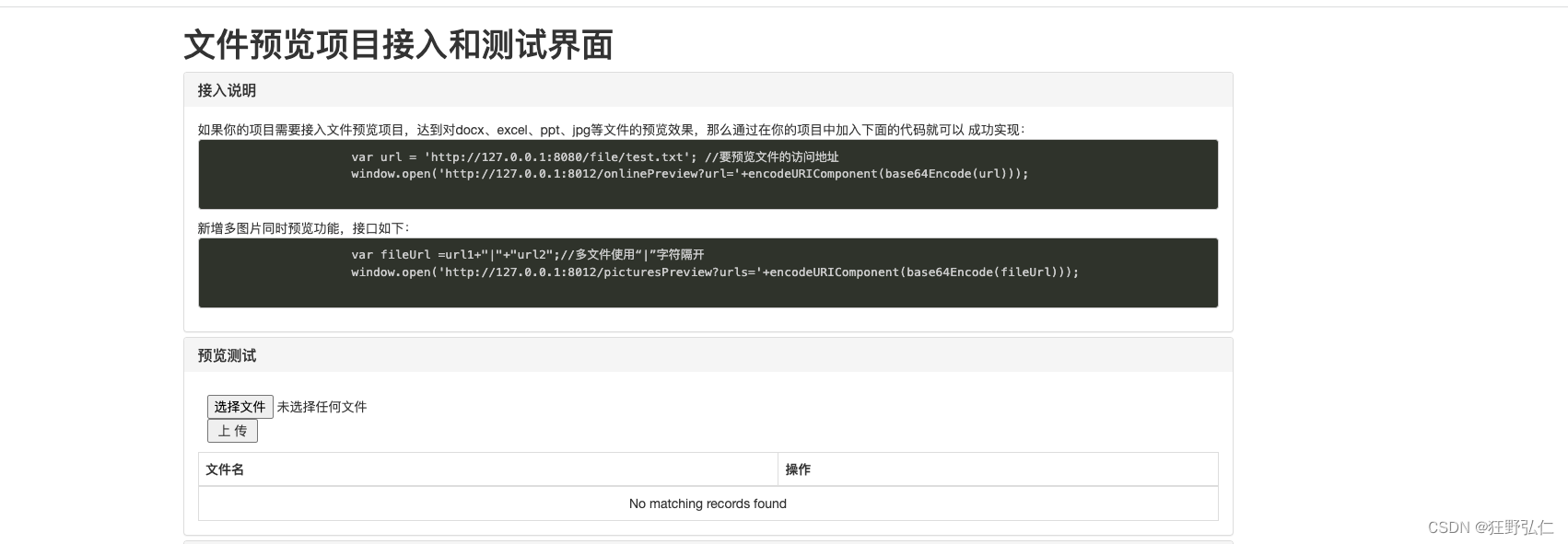
摘要:本次就和大家聊一聊深度学习中的概率。
本文分享自华为云社区《【MindSpore易点通】深度学习中的概率》,作者: chengxiaoli。
为什么会用到概率呢?因为在深度学习中经常会需要处理随机的数据,或者包含随机性的任务,随机性也来自非常多的方面,所以在存在不确定性的情况下,都需要用到概率。本次就和大家聊一聊深度学习中的概率。
随机变量
首先我们来认识下随机变量。变量我们应该都很熟悉,例如在Python语言中,变量会关联并表示一个固定的值;那么随机变量也很好理解,就是可以随机的表示不同值的变量,例如x1和x2都是随机变量X可能取到的值,这种情况而言,一个随机变量只是对可能状态的描述,并且这个描述必须搭配一个概率分布来表达每个取值的可能性。
随机变量可以可以分为两种情况:连续的和离散的。连续的随机变量伴随着实数值;离散的随机变量拥有有限或者可数无限多的状态,这些状态并不一定是整数形式,也可以是一些被命名的状态而没有数值。这也是连续随机变量和离散随机变量的区别。
概率分布
介绍完了随机变量,那么随机变量如何表示呢?答案是概率分布。概率分布就是用来表示连续随机变量或者离散随机变量其中一段中,每个可能取到的值的可能性大小,描述概率分布的方式也取决于随机变量是连续的还是离散的。下面我们就分析这两种情况下的概率分布。
连续型随机变量:当我们面对的是连续型随机变量时,这时会用到概率密度函数,那么什么是概率密度函数呢,我们假设一个函数P,那么P需要满足以下三个条件。
·p的定义范围必须是X所有可能状态的集合;
·p(x)≥0,但并不一定要p(x)≤1;
·∫p(x)d(x)=1。
连续型随机变量的概率密集型函数p(x)不会直接给出不同状态下的概率,而是通过计算p(x)所在区域面积的值表示概率,因此可以对概率密度函数求积分计算出特定状态下的真实概率质量。x落在集合S中的概率可以通过对这个集合积分得到,那么在单变量的例子中,x落在[a,b]的概率则是∫[a,b]p(x)d(x)。
离散型随机变量:如果我们面对的是离散型变量的概率分布,那么就可以用概率质量函数进行计算,这里用大写P表示。一般每一个随机变量都会有一个不同的概率质量函数,并且必须根据随机变量推断出所使用的概率质量函数。
概率质量函数把随机变量可以取得的每一个值映射到随机变量取得该状态的概率,X=x的概率用P(x)进行表示。
·P(x)=1表示X=x是一定发生的;
·P(x)=0表示X=x是不可能发生的。
概率质量函数可以同时作用在多个随机变量。多个变量的概率分布也可以称为联合概率分布。P(X=x,Y=y)表示的X=x和Y=y同时发生的概率,这也可以简写为P(x,y)。
如果函数P是随机变量X的概率质量函数,函数需要满足以下三个条件。
·P的定义范围必须是X所有可能状态的集合;
·0≤P(x)≤1,不可能发生的事件概率为0,一定发生的概率为1;
·∑P(x)=1,保障某一个状态概率不会大于1。
假设一个离散型随机变量X有k个不同的取值,我们可以假设X属于均匀分布的,也就是取得每一个值的可能性是相同的,因此推断出概率质量函数为:
P(X=xi)=1/k
该函数对所有的i都成立,符合成为概率质量函数的条件。
边缘概率:在我们知道一组变量的联合概率分布,但是想要了解其中一个子集的概率分布。这种定义在子集上的概率分布被称为边缘概率计算。
假设有离散型随机变量x和y,并且我们知道P(x,y),如果我们需要计算P(x),那么可以通过求和的办法进行计算。将X=x时,Y=y1、y2、…yi…yn的概率累加求出来。
总结
本次内容给大家分享了深度学习中的概率,分析了概率的两种分布类型:连续型和离散型,以及两种概率分布函数要满足的条件和计算方法。
点击关注,第一时间了解华为云新鲜技术~







![[iOS]砸壳](https://img-blog.csdnimg.cn/ce1e0757566b4342b48ca606cbf7dde1.png)