准备工作
这是Numpy数据处理的示例演绎系列文章的第四篇,我的前三篇文章为:
政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(一)![]() https://blog.csdn.net/snowdenkeke/article/details/136125773政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(二)
https://blog.csdn.net/snowdenkeke/article/details/136125773政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(二)![]() https://blog.csdn.net/snowdenkeke/article/details/136127590政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(三)—— 数组的操作
https://blog.csdn.net/snowdenkeke/article/details/136127590政安晨:【示例演绎】【Python】【Numpy数据处理】快速入门(三)—— 数组的操作![]() https://blog.csdn.net/snowdenkeke/article/details/136130381小伙伴们准备好环境后,咱们这就开始。
https://blog.csdn.net/snowdenkeke/article/details/136130381小伙伴们准备好环境后,咱们这就开始。
概述
NumPy提供了许多常用函数,用于数值计算、统计、线性代数等领域,以下是一些常用的NumPy函数的简单介绍:
-
np.array():用于创建一个数组。
-
np.linspace():返回在指定间隔内的等间隔数字。
-
np.zeros():返回一个全零的数组。
-
np.ones():返回一个全一的数组。
-
np.eye():返回一个单位矩阵。
-
np.random.rand():返回一个指定形状的随机数组。
-
np.arange():返回一个指定间隔和步长的数组。
-
np.reshape():用于改变数组的形状。
-
np.transpose():用于转置数组。
-
np.dot():用于两个数组的点积运算。
-
np.sum():计算数组元素的和。
-
np.mean():计算数组元素的平均值。
-
np.max():返回数组中的最大值。
-
np.min():返回数组中的最小值。
-
np.std():计算数组元素的标准差。
-
np.var():计算数组元素的方差。
这只是一些常用的NumPy函数的简要介绍,NumPy还提供了很多其他的函数和方法,这些函数其实是数组对象内置的方法,可以根据具体需求来选择使用,咱们介绍和函数相关的几个概念,并对部分常用函数做示例性讲解,简单介绍。
常量
说起常量,我们首先会想到圆周率、自然常数、欧拉常数等。的确,NumPy的常量包括np.pi(圆周率)、np.e(自然常数)、np.euler_gamma(欧拉常数),此外还包括np.nan(非数字)和np.inf(无穷大)这两个特殊值,NumPy的特殊值还有正负无穷大、正负零等,但因为很少用到,这里就不进行重点介绍。
NumPy有两个很有趣的特殊值:np.nan和np.inf。
nan是Not a Number的简写,意为非数字;inf是infinity的简写,意为无穷大。其代码如下:
a = np.array([1, 2, np.nan, np.inf])
a.dtype
a[0] = np.nan
a[1] = np.inf
a
# 两个np.nan不相等
a[0] == a[2]
# 两个np.inf则相等
a[1] == a[3]
# 判断一个数组元素是否是np.nan
np.isnan(a[0])
# 判断一个数组元素是否是np.inf
np.isinf(a[1]) 以下代码演示了在数组相邻的两个元素之间插入它们的算术平均值,尽管数组元素包含np.nan,但这不影响数值计算:
a = np.array([9, 3, np.nan, 5, 3])
a = np.repeat(a,2)[:-1]
a[1::2] += (a[2::2]-a[1::2])/2
a演绎如下:

命名空间
在Numpy中,实现同样的功能,一个函数却有两种写法;有时以为某个函数可以有两种写法,但用起来却会出错。归纳起来,这些困惑有以下三种类型:
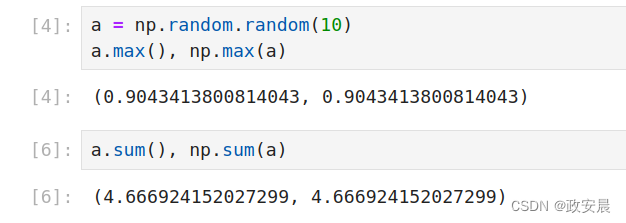
(1)都是求和、求极值,下面这两种写法有什么区别吗?
a = np.random.random(10)
a.max(), np.max(a)
a.sum(), np.sum(a)演绎:
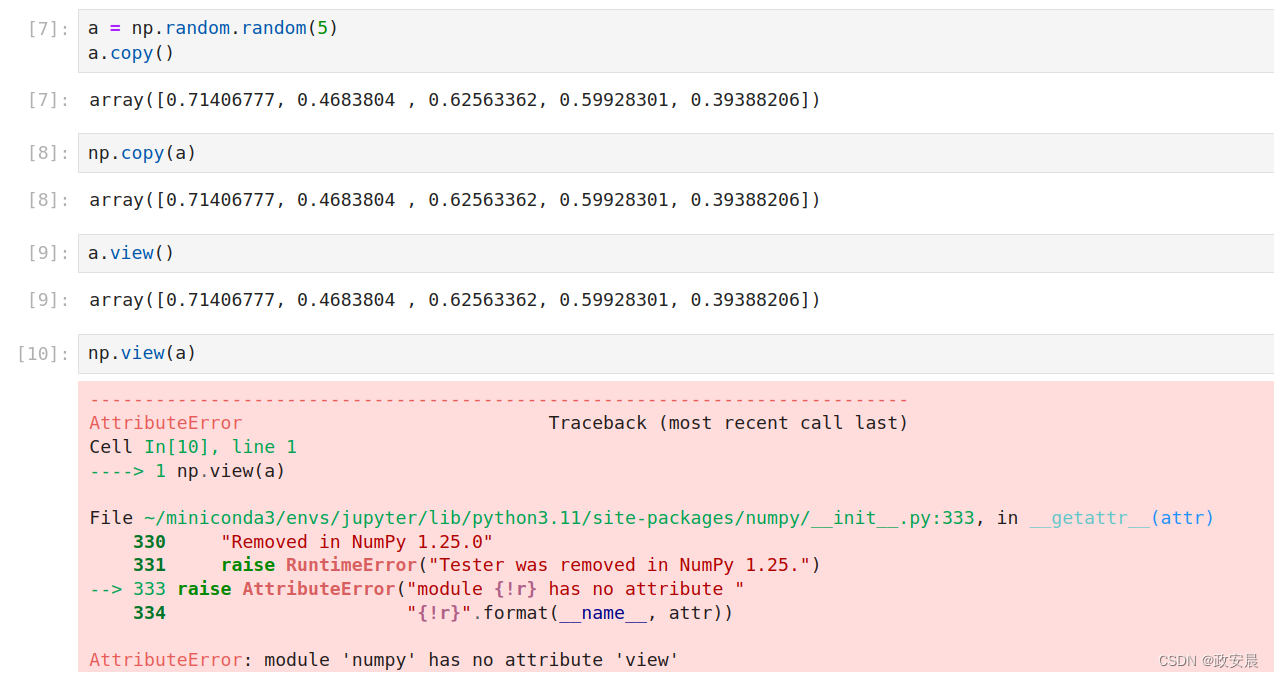
(2)同样是复制,为什么深复制copy( )两种写法都行,而浅复制view( )则只有数组的方法?
a = np.random.random(5)
a.copy()
np.copy(a)
a.view()
# 这种会报错
np.view(a)
演绎:
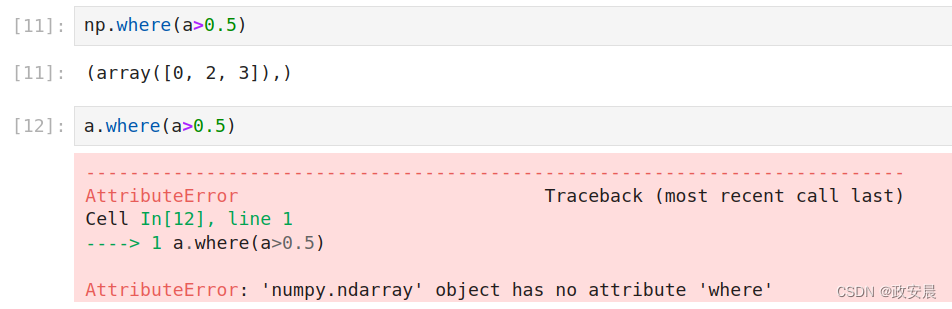
(3)为什么where( )不能作为数组ndarray的函数,必须作为NumPy的函数?
np.where(a>0.5)
a.where(a>0.5)演绎:
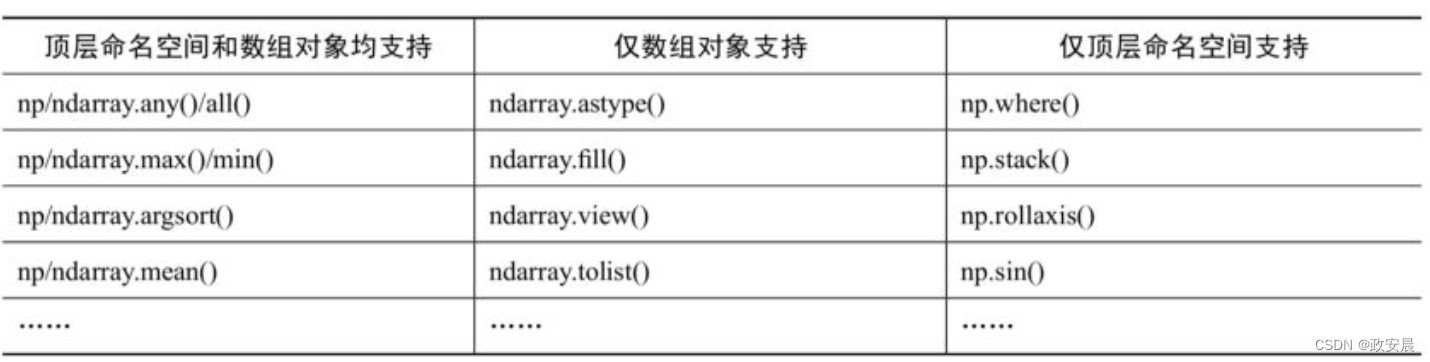
以上这些差异取决于函数在不同的命名空间是否有映射,数组的大部分函数在顶层命名空间有映射,因此可以有两种写法,但数组的一小部分函数没有映射到顶层命名空间,所以只能有一种写法。而顶层命名空间的大部分函数,也都只有一种写法。
下表所示的是常用函数和命名空间的关系:
数学函数
如果不熟悉NumPy,Python程序员一般都会选择使用math模块来解决数学问题。
但实际上NumPy的数学函数比math模块更加方便,而且NumPy的数学函数可以广播到数组的每一个元素上,也就是说,如果用np.sqrt( )对数组arr开方,返回的是数组arr中每个元素的平方根组成的新数组。
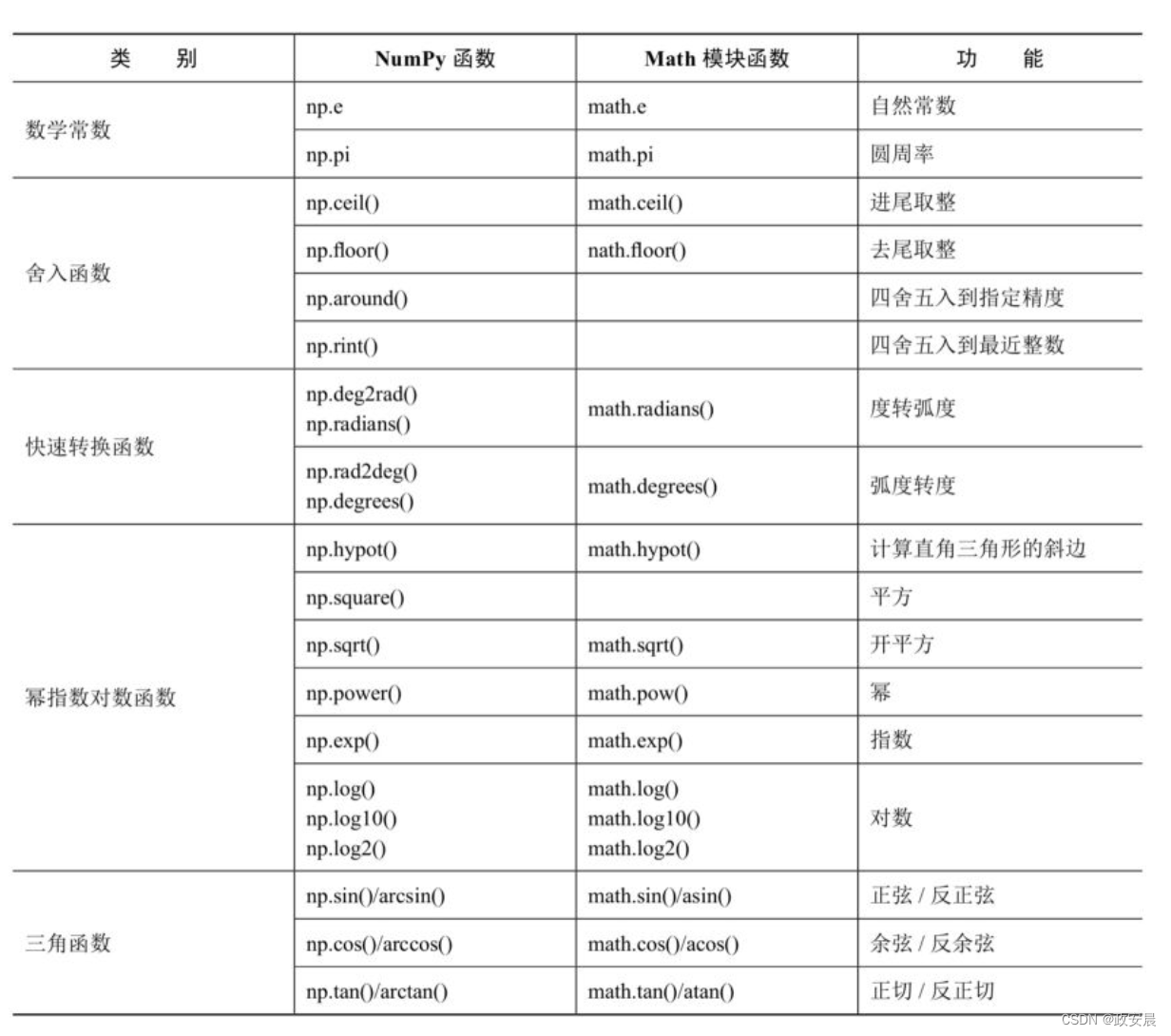
下面把NumPy和math模块的数学函数罗列在一个表格中,分成了数学常数、舍入函数、快速转换函数、幂指数对数函数和三角函数这5类:
(其他如求和、求差、求积的函数被归类到下一小节的统计函数中。)
下面的代码演示的是一些常用数学函数:
import numpy as np
import math
# 两个模块的自然常数相等
math.e == np.e
# 两个模块的圆周率相等
math.pi == np.pi
np.ceil(5.3)
np.ceil(-5.3)
np.floor(5.8)
np.floor(-5.8)
np.around(5.87, 1)
np.rint(5.87)
np.degrees(np.pi/2)
np.radians(180)
# 求平面上任意两点的距离
np.hypot(3,4)
np.power(3,1/2)
np.log2(1024)
np.exp(1)
#正弦、余弦函数的周期是2π
np.sin(np.radians(30))
np.sin(np.radians(150))
# 反正弦、反余弦函数的周期则是π
np.degrees(np.arcsin(0.5))小伙伴们可以自己尝试一下。
统计函数
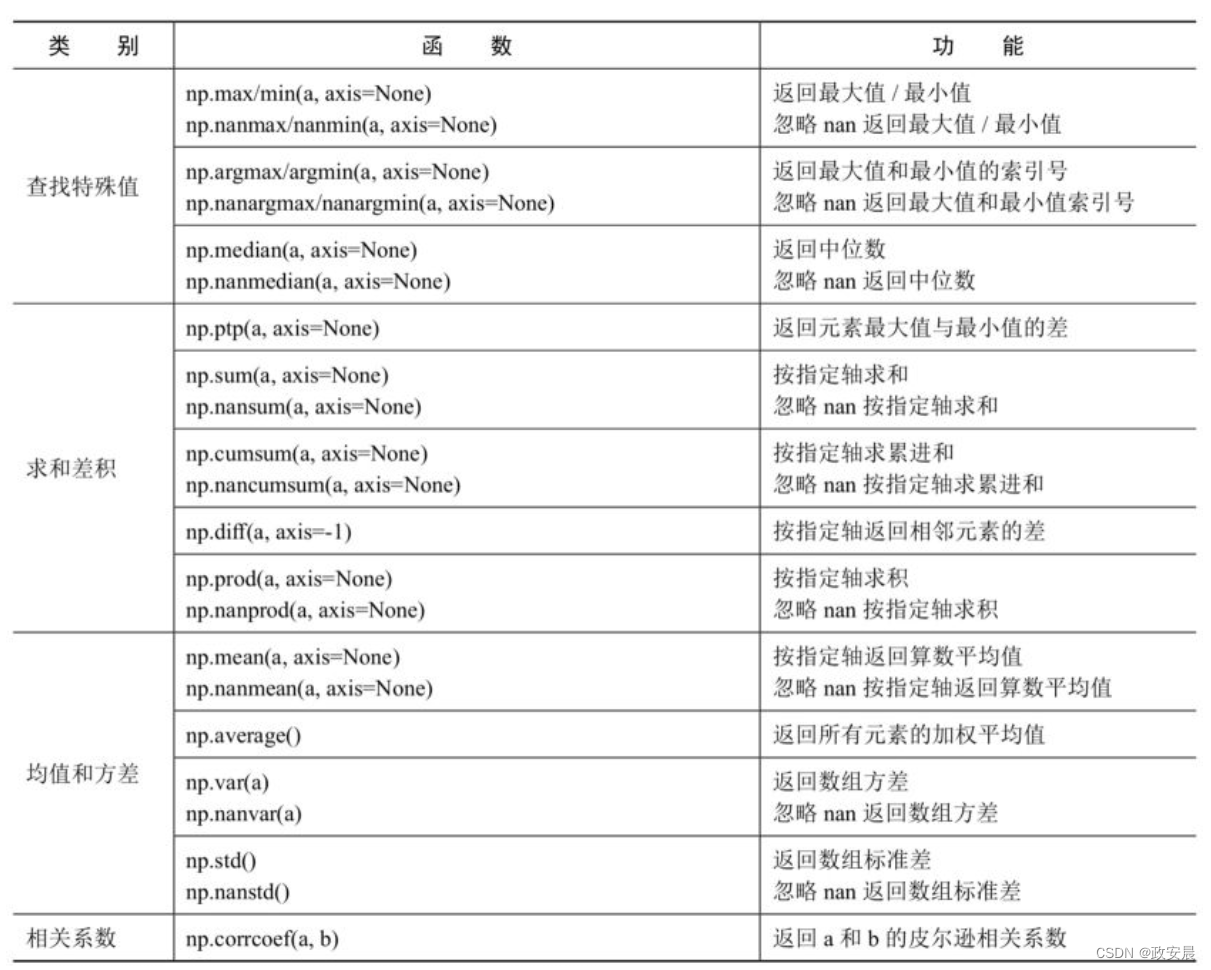
NumPy的统计函数有很多,并且很多函数还同时提供了忽略nan(缺值或无效值)的形式。常用的统计函数大致上可以分成查找特殊值、求和差积、均值和方差以及相关系数这4类,详细说明如下表所示:
在实际应用中,我们所获得的数据远没有想象中的那么理想,存在缺值或无效值是常态。
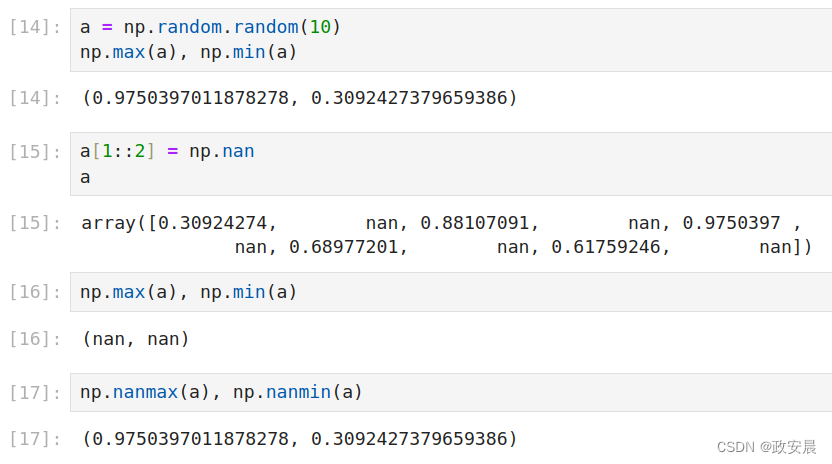
假定用np.nan表示无效值,一旦数据中存在无效值,对一个函数而言,是否忽略无效值将会得到完全不同的结果。下面先以求最大值和最小值为例,演示忽略np.nan的必要性。
a = np.random.random(10)
np.max(a), np.min(a)
# 将索引号为1、3、5、7、9的元素设置为np.nan
a[1::2] = np.nan
a
# 此时,min()函数和max()函数失效了
np.max(a), np.min(a)
# 必须使用nanmax()函数和nanmin()函数
np.nanmax(a), np.nanmin(a) 演绎如下:
方差和标准差是衡量数据离散程度最重要且最常用的指标,也是统计学上最重要的分析工具和手段,方差是各个数据与其算术平均值的离差平方和的平均值,方差的算术平方根,即为标准差。统计学上,方差和标准差使用比较频繁,下面来演示一下。
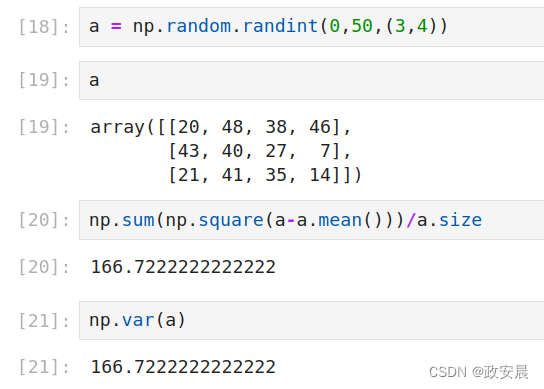
a = np.random.randint(0,50,(3,4))
# 用方差定义求方差
np.sum(np.square(a-a.mean()))/a.size
# 直接用方差函数求方差,与用方差定义求方差的结果相同
np.var(a)
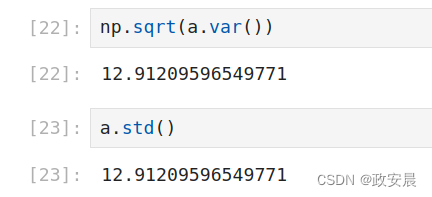
# 对方差求算术平方根就是标准差
np.sqrt(a.var())
# 直接用标准差函数求标准差,与对方差求算术平方根的结果相同
a.std() 示例演绎(方差):
示例演绎(标准差):
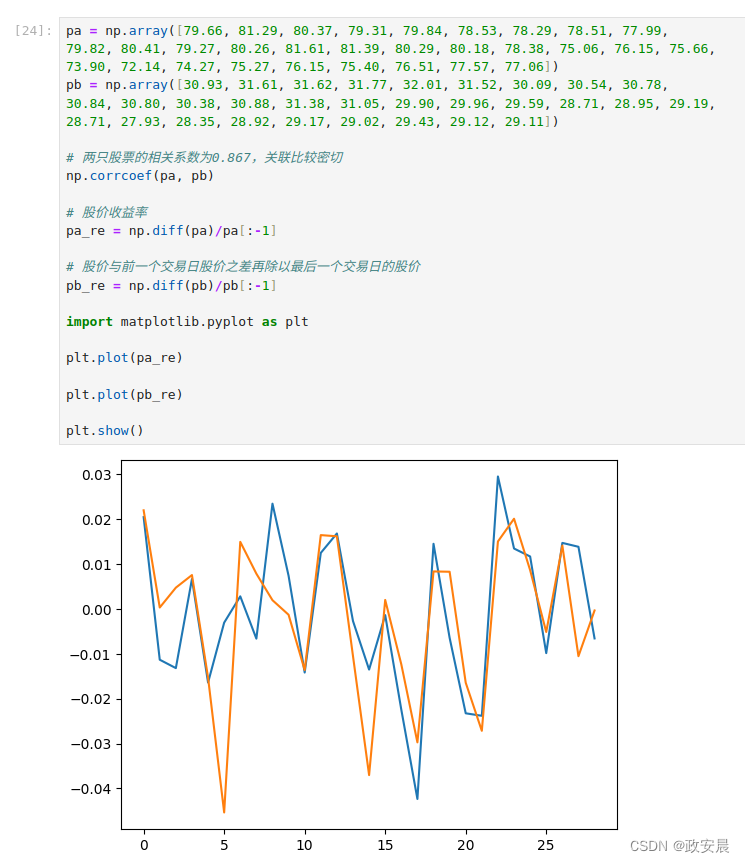
以下例子综合运用统计函数,来分析两只股票的关联关系和收益率。
pa和pb是两只股票连续30个交易日的股价数组,每日股价收益率定义为当日股价与前一个交易日股价之差再除以最后一个交易日的股价。
pa = np.array([79.66, 81.29, 80.37, 79.31, 79.84, 78.53, 78.29, 78.51, 77.99,
79.82, 80.41, 79.27, 80.26, 81.61, 81.39, 80.29, 80.18, 78.38, 75.06, 76.15, 75.66,
73.90, 72.14, 74.27, 75.27, 76.15, 75.40, 76.51, 77.57, 77.06])
pb = np.array([30.93, 31.61, 31.62, 31.77, 32.01, 31.52, 30.09, 30.54, 30.78,
30.84, 30.80, 30.38, 30.88, 31.38, 31.05, 29.90, 29.96, 29.59, 28.71, 28.95, 29.19,
28.71, 27.93, 28.35, 28.92, 29.17, 29.02, 29.43, 29.12, 29.11])
# 两只股票的相关系数为0.867,关联比较密切
np.corrcoef(pa, pb)
# 股价收益率
pa_re = np.diff(pa)/pa[:-1]
# 股价与前一个交易日股价之差再除以最后一个交易日的股价
pb_re = np.diff(pb)/pb[:-1]
import matplotlib.pyplot as plt
plt.plot(pa_re)
plt.plot(pb_re)
plt.show()演绎如下:
插值函数
数据插值是数据处理过程中经常用到的技术,常用的插值有一维插值、二维插值、高阶插值等,常见的算法有线性插值、B样条插值、临近插值等。
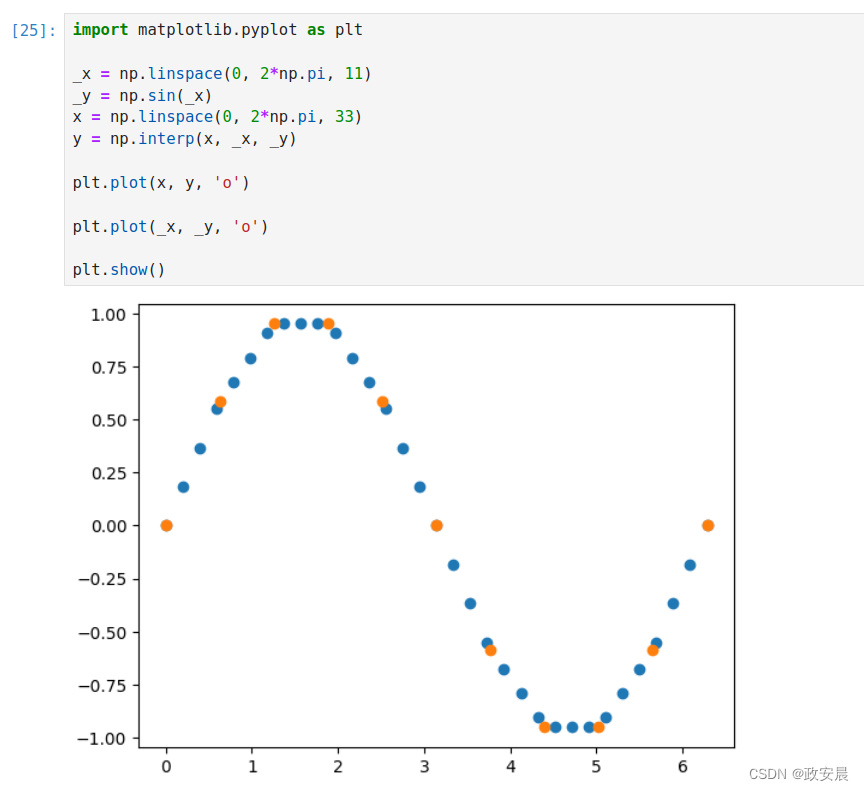
下面用一个实例来演示NumPy一维线性插值函数的使用方法。
假定_x和_y是原始的样本点x坐标和y坐标构成的数组,总数只有11个点。如果想在_x的值域范围内插值更多的点,如增加到33个点,就需要在_x的值域范围内生成33个点的x坐标构成的数组x,再利用插值函数np.interp( )得到对应的33个点的y坐标构成的数组y。
代码如下:
import matplotlib.pyplot as plt
_x = np.linspace(0, 2*np.pi, 11)
_y = np.sin(_x)
x = np.linspace(0, 2*np.pi, 33)
y = np.interp(x, _x, _y)
plt.plot(x, y, 'o')
plt.plot(_x, _y, 'o')
plt.show()演绎如下:
多项式拟合函数
拟合与插值看起来有一些相似,所以初学者比较容易混淆,实际上二者是完全不同的概念,拟合又称回归,是指已知某函数的若干离散函数值,通过调整该函数中若干待定系数,使得该函数与已知离散函数值的误差达到最小。
多项式拟合是最常见的拟合方法。
对函数f(x),我们可以使用一个k阶多项式去近似。
f(x)≈g(x)=a0+a1x+a2x2+a3x3+…+axxk通过选择合适的系数(最佳系数),可以使函数f(x)和g(x)之间的误差达到最小。
最小二乘法被用于寻找多项式的最佳系数。NumPy提供了一个非常简单易用的多项式拟合函数np.polyfit( ),只需要输入一组自变量的离散值,和一组对应的函数f(x),并指定多项式次数k,就可以返回一组最佳系数,函数np.poly1d( ),则可以将一组最佳系数转成函数g(x)。
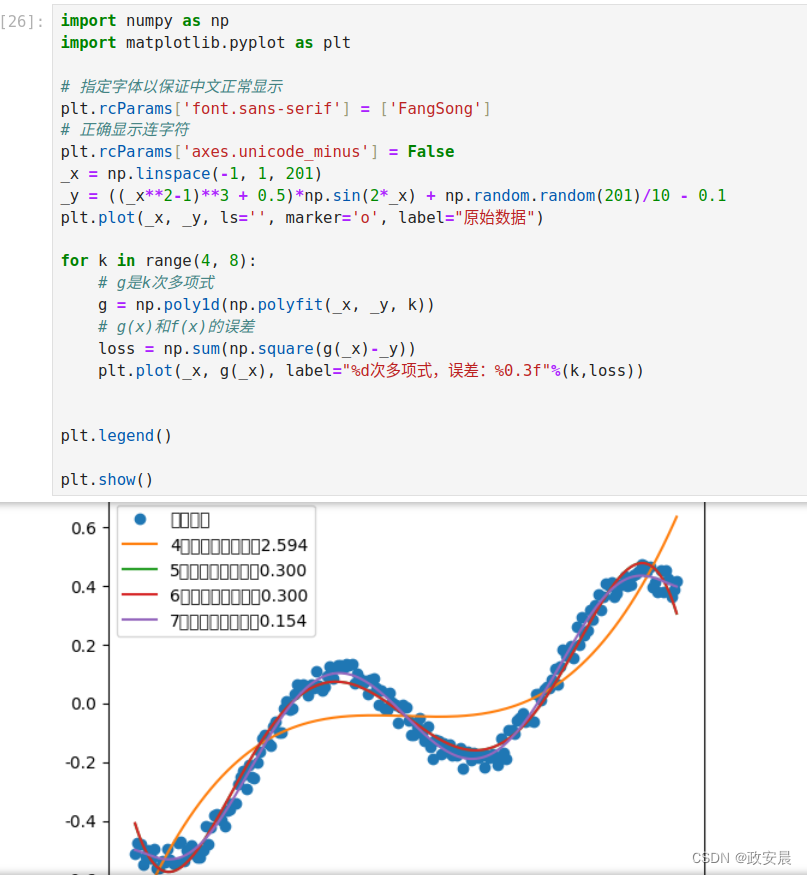
下述代码首先生成了原始数据点_x和_y,然后分别用4次、5次、6次和7次多项式去拟合原始数据,并计算出每次拟合的误差。
import numpy as np
import matplotlib.pyplot as plt
# 指定字体以保证中文正常显示
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
_x = np.linspace(-1, 1, 201)
_y = ((_x**2-1)**3 + 0.5)*np.sin(2*_x) + np.random.random(201)/10 - 0.1
plt.plot(_x, _y, ls='', marker='o', label="原始数据")
for k in range(4, 8):
# g是k次多项式
g = np.poly1d(np.polyfit(_x, _y, k))
# g(x)和f(x)的误差
loss = np.sum(np.square(g(_x)-_y))
plt.plot(_x, g(_x), label="%d次多项式,误差:%0.3f"%(k,loss))
plt.legend()
plt.show()演绎如下:
这篇咱们先到这里,关于Numpy的函数方法部分就是这些了,下次咱们启动其它主题。
![BulingBuling - 《工作中的焦虑》 [ Anxiety at Work ]](https://img-blog.csdnimg.cn/direct/c3861bfa92ea411a95d4c185585997a0.png)