目录
六、自然语言处理
6.1 词向量 (Word Embedding)
6.1.1 词向量的生成过程
6.1.2 word2vec介绍
6.1.3 word2vec:skip-gram算法的实现
6.2 句向量 - 情感分析
6.2.1 LSTM (Long Short-Term Memory)介绍
6.2.2 基于飞桨实现的情感分析模型
6.3 BERT
六、自然语言处理
计算机如何理解并处理人类语言?答案是通过词向量。
6.1 词向量 (Word Embedding)
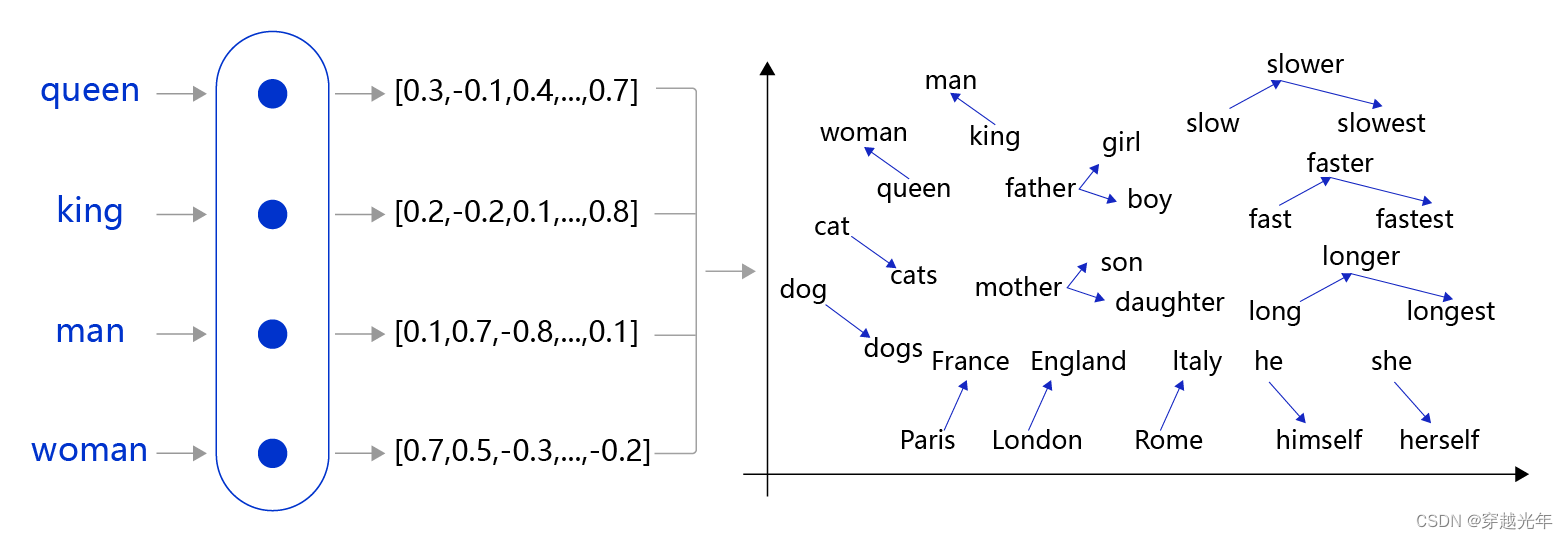
在自然语言处理任务中,词向量(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
具体来说,词向量(其实对于中文来说是字向量)是基于语料通过某种算法(比如word2vec),使得语料中的每个词对应一个N维向量,这个向量就是词向量,如 “我” 这个词可以用 [0.1, 2.0, 1.6, ...] 这个向量来表示,这个向量是结合该词在语料中的上下文的词语通过计算得来,能反应上下文的关系。词向量技术将自然语言中的词转化为稠密向量(减少计算维度),并且使得相近的词有相似的向量表示,方便后续在向量的基础上做运算,进一步挖掘文本之间的潜在关系。
6.1.1 词向量的生成过程
词向量一般按如下过程生成:
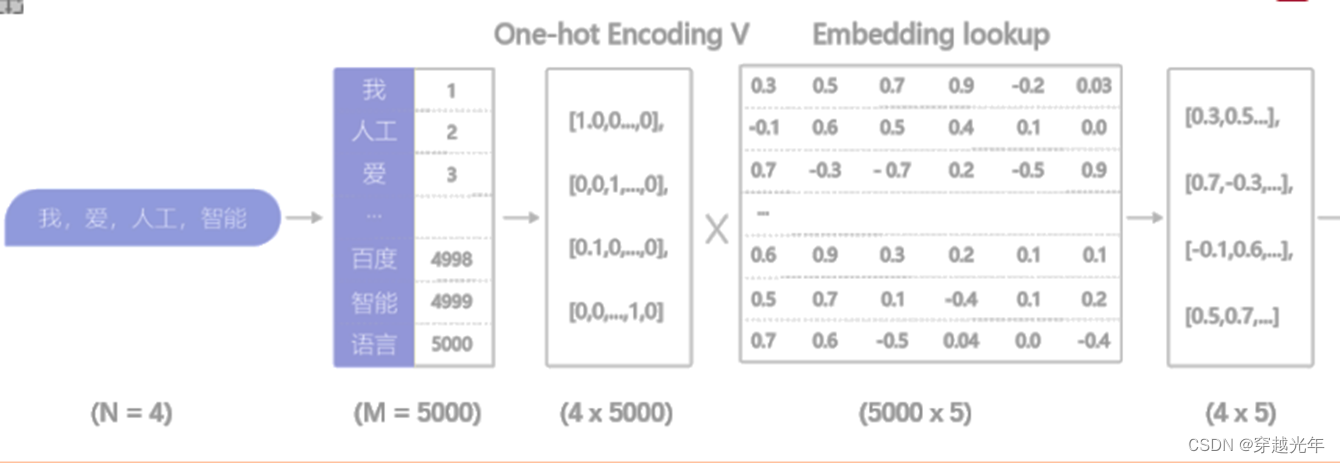
1. 将词变成数字(这样计算机才能处理):将词表(语料)中的词转换成id(id从0到N),一般id 0给出现频率最高的词,之后根据词的出现频率从高到低,id从小到大。词表的长度为M
2. 将词表中所有的词变成用id来表示,这样一段话就变成了一串连续的数字
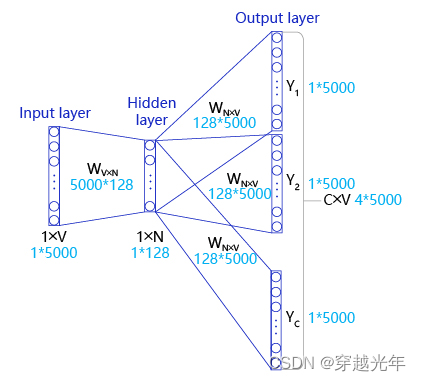
3. 将这一串数字作为输入,通过词向量算法(比如word2vec),来计算出词向量网络参数(Embedded lookup),这个词向量网络参数的维度是 M x L,M是词表长度,L是自定义的词向量维度(这个维度可以是任意大小,但实际应用中会定义成比输入维度小很多,方便后续运算。根据大量经验值,这个值一般设为300效果最好)。
4. 利用训练好的词向量网络参数来获取词的词向量,词的数量为N(比如对于,我,爱,人工,智能,这4个词,N为4)
- 词向量网络的输入端:输入数据是以one-hot向量方式表示的某个词活多个词,如[1,0,0,0...],[0,0,1,0...],因此输入端向量的维度 N x M,N是词的数量,M是词表的长度。
- [N, M] x [M, L] = [N, L]
- 词向量网络的输出端:输出端得到的即为这些词的词向量,维度为 N x L。
那么要如何得到词向量网络参数(Embdded lookup)?就是通过不同的词向量算法来训练网络并获取。
获得词向量的经典算法包括LSA, word2vec, Glove等等. 关于word2vec的可以参考这篇文章(其中对词向量也有比较好的说明):词向量:word2vec - 简书
6.1.2 word2vec介绍
2013年,Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。word2vec包含两个经典模型:CBOW(Continuous Bag-of-Words)和Skip-gram,如图所示。
- CBOW:通过上下文的词向量推理中心词。
- Skip-gram:根据中心词推理上下文。
假设有一个句子“Pineapples are spiked and yellow”,两个模型的推理方式如下:
-
在CBOW中,先在句子中选定一个中心词,并把其它词作为这个中心词的上下文。如 图所示,把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。在学习过程中,使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如“Spiked → pineapple”,从而达到学习语义信息的目的。

-
在Skip-gram中,同样先选定一个中心词,并把其他词作为这个中心词的上下文。如 图所示,把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。不同的是,在学习过程中,使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如“pineapple → Spiked”, 从而达到学习语义信息的目的。
一般来说,CBOW比Skip-gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文average的方式进行训练,每个训练step会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好,原因是skip-gram不会刻意回避生僻字(CBOW结构中输入中存在生僻字时,生僻字会被其它非生僻字的权重冲淡)。
6.1.3 word2vec:skip-gram算法的实现
实际情况中,vocab_size通常很大(几十万甚至几百万),要处理一个非常大的矩阵运算(计算过程非常缓慢,需要消耗大量的内存)。为了缓解这个问题,通常采取负采样(negative_sampling) 的方式来近似模拟多分类任务。就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
使用飞桨实现Skip-gram
流程如下:
-
数据处理:选择需要使用的数据,并做好必要的预处理工作。
-
网络定义:使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
-
网络训练:将准备好的数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
-
网络评估:使用测试集合测试训练好的神经网络,看看训练效果如何。
在实现的过程中,通常会让模型接收3个tensor输入:
-
代表中心词的tensor:假设我们称之为center_words V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
-
代表目标词的tensor:假设我们称之为target_words T,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
-
代表目标词标签的tensor:假设我们称之为labels L,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
- 用V去查询W0的到H1(用中心词正向算出的词向量),用T去查询W1得到H2(用目标词反向算出的词向量),分别得到两个形状为[batch_size, embedding_size]的tensor。
- 将H1, H2这两个tensor进行点积运算,最终得到一个形状为[batch_size]的tensor
- 使用sigmoid函数作用在O上,将上述点积的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息L训练这个模型即可。
在结束模型训练之后,一般使用W0作为最终要使用的词向量,用W0的向量表示。通过向量点乘的方式,计算不同词之间的相似度。
Skip-gram模型构建和训练完整代码如下:
# 下载语料用来训练word2vec
def download():
# 可以从百度云服务器下载一些开源数据集(dataset.bj.bcebos.com)
corpus_url = "https://dataset.bj.bcebos.com/word2vec/text8.txt"
# 使用python的requests包下载数据集到本地
web_request = requests.get(corpus_url)
corpus = web_request.content
# 把下载后的文件存储在当前目录的text8.txt文件内
with open("./text8.txt", "wb") as f:
f.write(corpus)
f.close()
download()
# 读取text8数据
def load_text8():
with open("./text8.txt", "r") as f:
corpus = f.read().strip("\n")
f.close()
return corpus
corpus = load_text8()
# 对语料进行预处理(分词)
def data_preprocess(corpus):
# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,
# 以便对语料进行归一化处理(Apple vs apple等)
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
corpus = data_preprocess(corpus)
print(corpus[:50])
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):
# 首先统计每个不同词的频率(出现的次数),使用一个词典记录
word_freq_dict = dict()
for word in corpus:
if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
# 将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前
# 一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlp
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
# 构造3个不同的词典,分别存储,
# 每个词到id的映射关系:word2id_dict
# 每个id出现的频率:word2id_freq
# 每个id到词的映射关系:id2word_dict
word2id_dict = dict()
word2id_freq = dict()
id2word_dict = dict()
# 按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
for word, freq in word_freq_dict:
curr_id = len(word2id_dict)
word2id_dict[word] = curr_id
word2id_freq[word2id_dict[word]] = freq
id2word_dict[curr_id] = word
return word2id_freq, word2id_dict, id2word_dict
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(50), word2id_dict.items()):
print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))
---------------------------------------------------------------
there are totoally 253854 different words in the corpus
word the, its id 0, its word freq 1061396
word of, its id 1, its word freq 593677
word and, its id 2, its word freq 416629
word one, its id 3, its word freq 411764
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):
# 使用一个循环,将语料中的每个词替换成对应的id,以便于神经网络进行处理
corpus = [word2id_dict[word] for word in corpus]
return corpus
corpus = convert_corpus_to_id(corpus, word2id_dict)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
---------------------------------------------------------------
17005207 tokens in the corpus
[5233, 3080, 11, 5, 194, 1, 3133, 45, 58, 155, 127, 741, 476, 10571, 133, 0, 27349, 1, 0,
# 使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
corpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
# 构造数据,准备模型训练
# max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
# negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
# 一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3, negative_sample_num = 4):
# 使用一个list存储处理好的数据
dataset = []
# 从左到右,开始枚举每个中心点的位置
for center_word_idx in range(len(corpus)):
# 以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定
window_size = random.randint(1, max_window_size)
# 当前的中心词就是center_word_idx所指向的词
center_word = corpus[center_word_idx]
# 以当前中心词为中心,左右两侧在window_size内的词都可以看成是正样本
positive_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))
positive_word_candidates = [corpus[idx] for idx in range(positive_word_range[0], positive_word_range[1]+1) if idx != center_word_idx]
# 对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练
for positive_word in positive_word_candidates:
# 首先把(中心词,正样本,label=1)的三元组数据放入dataset中,
# 这里label=1表示这个样本是个正样本
dataset.append((center_word, positive_word, 1))
# 开始负采样
i = 0
while i < negative_sample_num:
negative_word_candidate = random.randint(0, vocab_size-1)
if negative_word_candidate not in positive_word_candidates:
# 把(中心词,正样本,label=0)的三元组数据放入dataset中,
# 这里label=0表示这个样本是个负样本
dataset.append((center_word, negative_word_candidate, 0))
i += 1
return dataset
corpus_light = corpus[:int(len(corpus)*0.2)]
dataset = build_data(corpus_light, word2id_dict, word2id_freq)
for _, (center_word, target_word, label) in zip(range(50), dataset):
print("center_word %s, target %s, label %d" % (id2word_dict[center_word],
id2word_dict[target_word], label))
-----------------------------------------------------------------------
center_word anarchism, target originated, label 1
center_word anarchism, target kdepim, label 0
center_word anarchism, target mahoney, label 0
#训练数据准备好后,把训练数据都组装成mini-batch,并准备输入到网络中进行训练,代码如下
# 构造mini-batch,准备对模型进行训练
# 我们将不同类型的数据放到不同的tensor里,便于神经网络进行处理
# 并通过numpy的array函数,构造出不同的tensor来,并把这些tensor送入神经网络中进行训练
def build_batch(dataset, batch_size, epoch_num):
# center_word_batch缓存batch_size个中心词
center_word_batch = []
# target_word_batch缓存batch_size个目标词(可以是正样本或者负样本)
target_word_batch = []
# label_batch缓存了batch_size个0或1的标签,用于模型训练
label_batch = []
for epoch in range(epoch_num):
# 每次开启一个新epoch之前,都对数据进行一次随机打乱,提高训练效果
random.shuffle(dataset)
for center_word, target_word, label in dataset:
# 遍历dataset中的每个样本,并将这些数据送到不同的tensor里
center_word_batch.append([center_word])
target_word_batch.append([target_word])
label_batch.append(label)
# 当样本积攒到一个batch_size后,我们把数据都返回回来
# 在这里我们使用numpy的array函数把list封装成tensor
# 并使用python的迭代器机制,将数据yield出来
# 使用迭代器的好处是可以节省内存
if len(center_word_batch) == batch_size:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
center_word_batch = []
target_word_batch = []
label_batch = []
if len(center_word_batch) > 0:
yield np.array(center_word_batch).astype("int64"), \
np.array(target_word_batch).astype("int64"), \
np.array(label_batch).astype("float32")
for _, batch in zip(range(10), build_batch(dataset, 128, 3)):
print(batch)
break
#定义skip-gram训练网络结构
#使用paddlepaddle的2.0.0版本
#一般来说,在使用paddle训练的时候,我们需要通过一个类来定义网络结构,这个类继承了paddle.nn.layer
class SkipGram(nn.Layer):
def __init__(self, vocab_size, embedding_size, init_scale=0.1):
# vocab_size定义了这个skipgram这个模型的词表大小
# embedding_size定义了词向量的维度是多少
# init_scale定义了词向量初始化的范围,一般来说,比较小的初始化范围有助于模型训练
super(SkipGram, self).__init__()
self.vocab_size = vocab_size
self.embedding_size = embedding_size
# 使用Embedding函数构造一个词向量参数
# 这个参数的大小为:[self.vocab_size, self.embedding_size]
# 数据类型为:float32
# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样
self.embedding = Embedding(
num_embeddings = self.vocab_size,
embedding_dim = self.embedding_size,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(
low=-init_scale, high=init_scale)))
# 使用Embedding函数构造另外一个词向量参数
# 这个参数的大小为:[self.vocab_size, self.embedding_size]
# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样
self.embedding_out = Embedding(
num_embeddings = self.vocab_size,
embedding_dim = self.embedding_size,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(
low=-init_scale, high=init_scale)))
# 定义网络的前向计算逻辑
# center_words是一个tensor(mini-batch),表示中心词
# target_words是一个tensor(mini-batch),表示目标词
# label是一个tensor(mini-batch),表示这个词是正样本还是负样本(用0或1表示)
# 用于在训练中计算这个tensor中对应词的同义词,用于观察模型的训练效果
def forward(self, center_words, target_words, label):
# 首先,通过self.embedding参数,将mini-batch中的词转换为词向量
# 这里center_words和eval_words_emb查询的是一个相同的参数
# 而target_words_emb查询的是另一个参数
center_words_emb = self.embedding(center_words)
target_words_emb = self.embedding_out(target_words)
# 我们通过点乘的方式计算中心词到目标词的输出概率,并通过sigmoid函数估计这个词是正样本还是负样本的概率。
word_sim = paddle.multiply(center_words_emb, target_words_emb)
word_sim = paddle.sum(word_sim, axis=-1)
word_sim = paddle.reshape(word_sim, shape=[-1])
pred = F.sigmoid(word_sim)
# 通过估计的输出概率定义损失函数,注意我们使用的是binary_cross_entropy_with_logits函数
# 将sigmoid计算和cross entropy合并成一步计算可以更好的优化,所以输入的是word_sim,而不是pred
loss = F.binary_cross_entropy_with_logits(word_sim, label)
loss = paddle.mean(loss)
# 返回前向计算的结果,飞桨会通过backward函数自动计算出反向结果。
return pred, loss
# 开始训练,定义一些训练过程中需要使用的超参数
batch_size = 512
epoch_num = 3
embedding_size = 200
step = 0
learning_rate = 0.001
#定义一个使用word-embedding查询同义词的函数
#这个函数query_token是要查询的词,k表示要返回多少个最相似的词,embed是我们学习到的word-embedding参数
#我们通过计算不同词之间的cosine距离,来衡量词和词的相似度
#具体实现如下,x代表要查询词的Embedding,Embedding参数矩阵W代表所有词的Embedding
#两者计算Cos得出所有词对查询词的相似度得分向量,排序取top_k放入indices列表
def get_similar_tokens(query_token, k, embed):
W = embed.numpy()
x = W[word2id_dict[query_token]]
cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
indices = np.argpartition(flat, -k)[-k:]
indices = indices[np.argsort(-flat[indices])]
for i in indices:
print('for word %s, the similar word is %s' % (query_token, str(id2word_dict[i])))
# 通过我们定义的SkipGram类,来构造一个Skip-gram模型网络
skip_gram_model = SkipGram(vocab_size, embedding_size)
# 构造训练这个网络的优化器
adam = paddle.optimizer.Adam(learning_rate=learning_rate, parameters = skip_gram_model.parameters())
# 使用build_batch函数,以mini-batch为单位,遍历训练数据,并训练网络
for center_words, target_words, label in build_batch(
dataset, batch_size, epoch_num):
# 使用paddle.to_tensor,将一个numpy的tensor,转换为飞桨可计算的tensor
center_words_var = paddle.to_tensor(center_words)
target_words_var = paddle.to_tensor(target_words)
label_var = paddle.to_tensor(label)
# 将转换后的tensor送入飞桨中,进行一次前向计算,并得到计算结果
pred, loss = skip_gram_model(
center_words_var, target_words_var, label_var)
# 程序自动完成反向计算
loss.backward()
# 程序根据loss,完成一步对参数的优化更新
adam.step()
# 清空模型中的梯度,以便于下一个mini-batch进行更新
adam.clear_grad()
# 每经过100个mini-batch,打印一次当前的loss,看看loss是否在稳定下降
step += 1
if step % 1000 == 0:
print("step %d, loss %.3f" % (step, loss.numpy()[0]))
# 每隔10000步,打印一次模型对以下查询词的相似词,这里我们使用词和词之间的向量点积作为衡量相似度的方法,只打印了5个最相似的词
if step % 10000 ==0:
get_similar_tokens('movie', 5, skip_gram_model.embedding.weight)
get_similar_tokens('one', 5, skip_gram_model.embedding.weight)
get_similar_tokens('chip', 5, skip_gram_model.embedding.weight)
----------------------------------------------------------------------------
step 9000, loss 0.241
step 10000, loss 0.244
for word movie, the similar word is movie
for word movie, the similar word is amigaos
step 19000, loss 0.181
step 20000, loss 0.137
for word movie, the similar word is movie
for word movie, the similar word is rosenberg
step 29000, loss 0.229
step 30000, loss 0.276
for word movie, the similar word is movie
for word movie, the similar word is canals
step 199000, loss 0.163
step 200000, loss 0.091
for word movie, the similar word is movie
for word movie, the similar word is watching
6.2 句向量 - 情感分析
人类自然语言具有高度的复杂性,相同的对话在不同的情景,不同的情感,不同的人演绎,表达的效果往往也会迥然不同。例如"你真的太瘦了",当你聊天的对象是一位身材苗条的人,这是一句赞美的话;当你聊天的对象是一位肥胖的人时,这就变成了一句嘲讽。
简单的说,我们可以将情感分析(sentiment classification)任务定义为一个分类问题,即指定一个文本输入,机器通过对文本进行分析、处理、归纳和推理后自动输出结论,如图1所示。
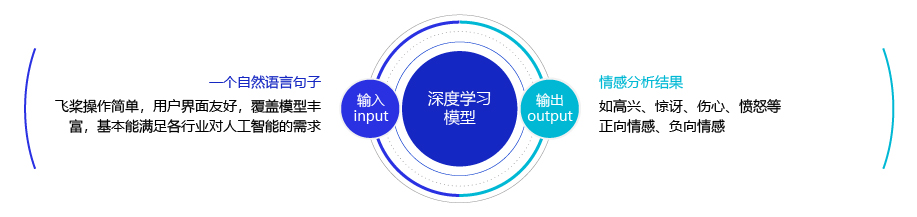
通常情况下,人们把情感分析任务看成一个三分类问题
-
正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
-
负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
-
其他: 其他类型的情感。
上面我们刚学习了通过把每个单词转换成向量的方式,可以完成单词语义计算任务。那么我们自然会联想到,是否可以把每个自然语言句子也转换成一个向量表示,并使用这个向量表示完成情感分析任务呢?
在日常工作中有一个非常简单粗暴的解决方式:就是先把一个句子中所有词的embedding进行加权平均,再用得到的平均embedding作为整个句子的向量表示。然而由于自然语言变幻莫测,我们在使用神经网络处理句子的时候,往往会遇到如下两类问题:
-
变长的句子: 自然语言句子往往是变长的,不同的句子长度可能差别很大。然而大部分神经网络接受的输入都是张量,长度是固定的,那么如何让神经网络处理变长数据成为了一大挑战。
-
组合的语义: 自然语言句子往往对结构非常敏感,有时稍微颠倒单词的顺序都可能改变这句话的意思,比如:
你等一下我做完作业就走。
我等一下你做完工作就走。
我不爱吃你做的饭。
你不爱吃我做的饭。
我瞅你咋地。
你瞅我咋地。
因此,我们需要找到一个可以考虑词和词之间顺序(关系)的神经网络,用于更好地实现自然语言句子建模。目前大多数成功的自然语言模型都建立在对句子的序列化建模上。两个经典的序列化建模模型是:
- 循环神经网络(Recurrent Neural Network,RNN)
- 长短时记忆网络(Long Short-Term Memory,LSTM)
RNN相当于将神经网络单元进行了横向连接,处理前一部分输入的RNN单元不仅有正常的模型输出,还会输出“记忆”传递到下一个RNN单元。而处于后一部分的RNN单元,不仅仅有来自于任务数据的输入,同时会接收从前一个RNN单元传递过来的记忆输入,这样就使得整个神经网络具备了“记忆”能力。但RNN对“记忆”能力的设计是比较粗糙的,当网络处理的序列数据过长时,累积的内部信息就会越来越复杂,直到超过网络的承载能力,通俗的说“事无巨细的记录,总有一天大脑会崩溃”。
为了解决这个问题,科学家巧妙的设计了一种记忆单元,称之为“长短时记忆网络(Long Short-Term Memory,LSTM)”。利用LSTM我可以把词向量进一步提炼为句向量,步骤是先获取一段文本的词向量,再将词向量按顺序输入给LSTM,最终LSTM会输出一个向量,即为这段文本的句向量。
6.2.1 LSTM (Long Short-Term Memory)介绍
短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构。LSTM则更复杂,它是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图。每个网络模块中都含一线(记忆线)三门(遗忘门,输入门,输出门)。每个模块代表一个时刻。
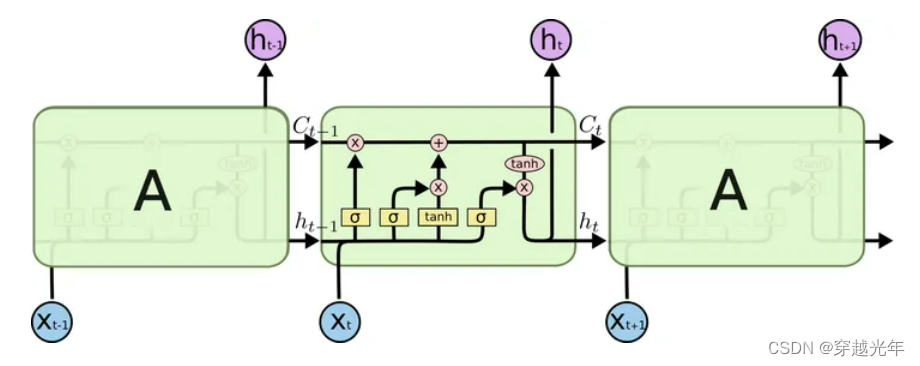
LSTM在每个处理单元内部,加入了输入门、输出门和遗忘门的设计,三者有明确的任务分工:
- 输入门:控制有多少输入信号会被融合;
- 遗忘门:控制有多少过去的记忆会被遗忘;
- 输出门:控制多少处理后的信息会被输出;
三者的作用与人类的记忆方式有异曲同工之处,即:
- 与当前任务无关的信息会直接过滤掉,如非常专注的开车时,人们几乎不注意沿途的风景;
- 过去记录的事情不一定都要永远记住,如令人伤心或者不重要的事,通常会很快被淡忘;
- 根据记忆和现实观察进行决策,如开车时会结合记忆中的路线和当前看到的路标,决策转弯或不做任何动作。
下面对模块内部分别介绍。
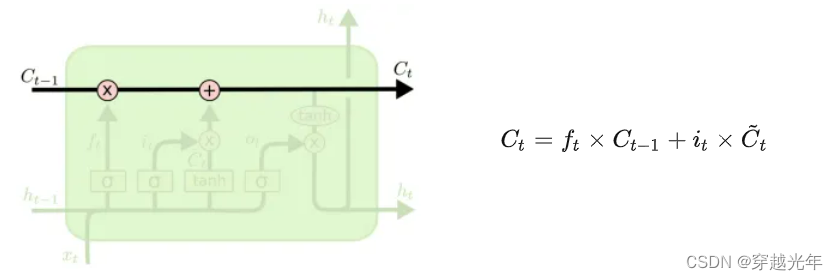
记忆线(Ct):相当于一条记忆传送带,上面放置了从 0 到 t 时刻的语言输入的信息
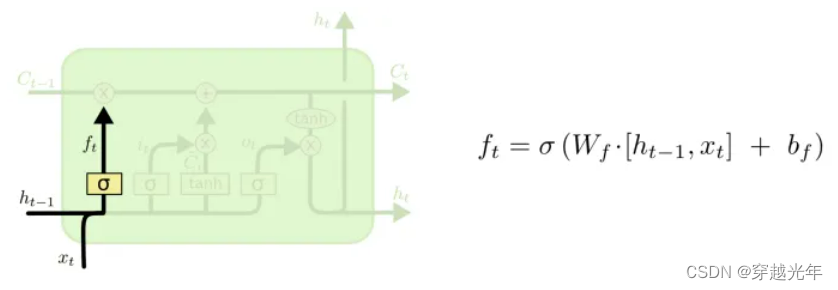
遗忘门(ft): 用来决定把记忆传送带上哪些信息给剔除掉,用来确保记忆线上的信息不会过于冗余和复杂。遗忘门的输入是当前时刻的输入和上一时刻的输出。
输入门(it):输入门是来决定将哪些新的信息放到记忆线上,它的输入也是当前时刻的输入和上一时刻的输出。
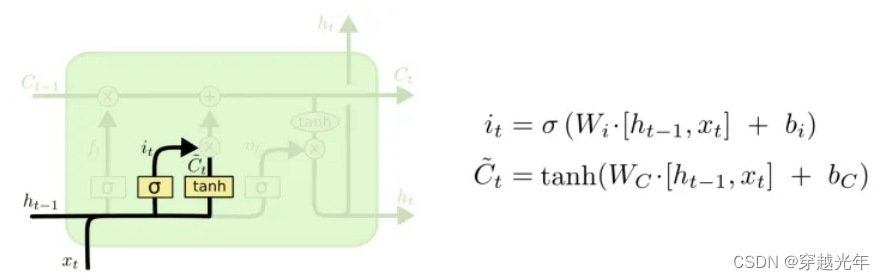
输出门(Ot):输出门决定本时刻的输出,它的输入也是当前时刻的输入和上一时刻的输出。最终它会和记忆线进行运算得到当前时刻的输出ht。

6.2.2 基于飞桨实现的情感分析模型
首先,需要下载语料用于模型训练和评估效果。我们使用的是IMDB的电影评论数据,这个数据集是一个开源的英文数据集,由训练数据和测试数据组成。每个数据都分别由若干小文件组成,每个小文件内部都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向(是正向还是负向),数据集下载的代码如下:
def download():
# 通过python的requests类,下载存储在
# https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz的文件
corpus_url = "https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz"
web_request = requests.get(corpus_url)
corpus = web_request.content
# 将下载的文件写在当前目录的aclImdb_v1.tar.gz文件内
with open("./aclImdb_v1.tar.gz", "wb") as f:
f.write(corpus)
f.close()
download()
#将数据集加载到程序中,并打印一小部分数据观察一下数据集的特点,代码如下
def load_imdb(is_training):
data_set = []
# aclImdb_v1.tar.gz解压后是一个目录
# 我们可以使用python的rarfile库进行解压
# 训练数据和测试数据已经经过切分,其中训练数据的地址为:
# ./aclImdb/train/pos/ 和 ./aclImdb/train/neg/,分别存储着正向情感的数据和负向情感的数据
# 我们把数据依次读取出来,并放到data_set里
# data_set中每个元素都是一个二元组,(句子,label),其中label=0表示负向情感,label=1表示正向情感
for label in ["pos", "neg"]:
with tarfile.open("./aclImdb_v1.tar.gz") as tarf:
path_pattern = "aclImdb/train/" + label + "/.*\\.txt$" if is_training \
else "aclImdb/test/" + label + "/.*\\.txt$"
path_pattern = re.compile(path_pattern)
tf = tarf.next()
while tf != None:
if bool(path_pattern.match(tf.name)):
sentence = tarf.extractfile(tf).read().decode()
sentence_label = 0 if label == 'neg' else 1
data_set.append((sentence, sentence_label))
tf = tarf.next()
return data_set
train_corpus = load_imdb(True)
test_corpus = load_imdb(False)
for i in range(5):
print("sentence %d, %s" % (i, train_corpus[i][0]))
print("sentence %d, label %d" % (i, train_corpus[i][1]))
-----------------------------------------------------------------------------
sentence 0, Zentropa has much in common with The Third Man, another noir-like film set among the rubble of postwar Europe.
sentence 0, label 1
sentence 1, Zentropa is the most original movie
sentence 1, label 1
#在自然语言处理中,需要先对语料进行切词,这里我们可以使用空格把每个句子切成若干词的序列
def data_preprocess(corpus):
data_set = []
for sentence, sentence_label in corpus:
# 这里有一个小trick是把所有的句子转换为小写,从而减小词表的大小
# 一般来说这样的做法有助于效果提升
sentence = sentence.strip().lower()
sentence = sentence.split(" ")
data_set.append((sentence, sentence_label))
return data_set
train_corpus = data_preprocess(train_corpus)
test_corpus = data_preprocess(test_corpus)
print(train_corpus[:5])
print(test_corpus[:5])
-------------------------------------------------------------------------------------
[(['zentropa', 'has', 'much', 'in', 'common', 'with', 'the',
[(['previous', 'reviewer', 'claudio', 'carvalho', 'gave',
#在经过切词后,需要构造一个词典,把每个词都转化成一个ID,以便于神经网络训练
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):
word_freq_dict = dict()
for sentence, _ in corpus:
for word in sentence:
if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
word2id_dict = dict()
word2id_freq = dict()
# 一般来说,我们把oov和pad放在词典前面,给他们一个比较小的id,这样比较方便记忆,并且易于后续扩展词表
word2id_dict['[oov]'] = 0
word2id_freq[0] = 1e10
word2id_dict['[pad]'] = 1
word2id_freq[1] = 1e10
for word, freq in word_freq_dict:
word2id_dict[word] = len(word2id_dict)
word2id_freq[word2id_dict[word]] = freq
return word2id_freq, word2id_dict
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):
data_set = []
for sentence, sentence_label in corpus:
# 将句子中的词逐个替换成id,如果句子中的词不在词表内,则替换成oov
# 这里需要注意,一般来说我们可能需要查看一下test-set中,句子oov的比例,
# 如果存在过多oov的情况,那就说明我们的训练数据不足或者切分存在巨大偏差,需要调整
sentence = [word2id_dict[word] if word in word2id_dict \
else word2id_dict['[oov]'] for word in sentence]
data_set.append((sentence, sentence_label))
return data_set
train_corpus = convert_corpus_to_id(train_corpus, word2id_dict)
test_corpus = convert_corpus_to_id(test_corpus, word2id_dict)
print("%d tokens in the corpus" % len(train_corpus))
print(train_corpus[:5])
print(test_corpus[:5])
-------------------------------------------------------------------------------
25000 tokens in the corpus
[([22216, 41, 76, 8, 1136, 17, 2, 874, 979, 167,
[([868, 2313, 29392, 0, 442, 3, 76, 138, 20739, 5,
#把原始语料中的每个句子通过截断和填充,转换成一个固定长度的句子,并将所有数据整理成mini-batch,用于训练模型
# 编写一个迭代器,每次调用这个迭代器都会返回一个新的batch,用于训练或者预测
def build_batch(word2id_dict, corpus, batch_size, epoch_num, max_seq_len, shuffle = True, drop_last = True):
# 模型将会接受的两个输入:
# 1. 一个形状为[batch_size, max_seq_len]的张量,sentence_batch,代表了一个mini-batch的句子。
# 2. 一个形状为[batch_size, 1]的张量,sentence_label_batch,每个元素都是非0即1,代表了每个句子的情感类别(正向或者负向)
sentence_batch = []
sentence_label_batch = []
for _ in range(epoch_num):
#每个epoch前都shuffle一下数据,有助于提高模型训练的效果
#但是对于预测任务,不要做数据shuffle
if shuffle:
random.shuffle(corpus)
for sentence, sentence_label in corpus:
sentence_sample = sentence[:min(max_seq_len, len(sentence))]
if len(sentence_sample) < max_seq_len:
for _ in range(max_seq_len - len(sentence_sample)):
sentence_sample.append(word2id_dict['[pad]'])
sentence_sample = [[word_id] for word_id in sentence_sample]
sentence_batch.append(sentence_sample)
sentence_label_batch.append([sentence_label])
if len(sentence_batch) == batch_size:
yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")
sentence_batch = []
sentence_label_batch = []
if not drop_last and len(sentence_batch) > 0:
yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")
for batch_id, batch in enumerate(build_batch(word2id_dict, train_corpus, batch_size=3, epoch_num=3, max_seq_len=30)):
print(batch)
break
-----------------------------------------------------------------------------
(array([[[ 3589],
[ 161],
[ 7],
[ 3],
[ 56],
[ 139],
[ 18],
[ 6],
# 定义一个用于情感分类的网络实例,SentimentClassifier
class SentimentClassifier(paddle.nn.Layer):
def __init__(self, hidden_size, vocab_size, embedding_size, class_num=2, num_steps=128, num_layers=1, init_scale=0.1, dropout_rate=None):
# 参数含义如下:
# 1.hidden_size,表示embedding-size,hidden和cell向量的维度
# 2.vocab_size,模型可以考虑的词表大小
# 3.embedding_size,表示词向量的维度
# 4.class_num,情感类型个数,可以是2分类,也可以是多分类
# 5.num_steps,表示这个情感分析模型最大可以考虑的句子长度
# 6.num_layers,表示网络的层数
# 7.dropout_rate,表示使用dropout过程中失活的神经元比例
# 8.init_scale,表示网络内部的参数的初始化范围,长短时记忆网络内部用了很多Tanh,Sigmoid等激活函数,\
# 这些函数对数值精度非常敏感,因此我们一般只使用比较小的初始化范围,以保证效果
super(SentimentClassifier, self).__init__()
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.class_num = class_num
self.num_steps = num_steps
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.init_scale = init_scale
# 声明一个LSTM模型,用来把每个句子抽象成向量
self.simple_lstm_rnn = paddle.nn.LSTM(input_size=hidden_size, hidden_size=hidden_size, num_layers=num_layers)
# 声明一个embedding层,用来把句子中的每个词转换为向量
self.embedding = paddle.nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_size, sparse=False,
weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform(low=-init_scale, high=init_scale)))
# 声明使用上述语义向量映射到具体情感类别时所需要使用的线性层
self.cls_fc = paddle.nn.Linear(in_features=self.hidden_size, out_features=self.class_num,
weight_attr=None, bias_attr=None)
# 一般在获取单词的embedding后,会使用dropout层,防止过拟合,提升模型泛化能力
self.dropout_layer = paddle.nn.Dropout(p=self.dropout_rate, mode='upscale_in_train')
# forwad函数即为模型前向计算的函数,它有两个输入,分别为:
# input为输入的训练文本,其shape为[batch_size, max_seq_len]
# label训练文本对应的情感标签,其shape维[batch_size, 1]
def forward(self, inputs):
# 获取输入数据的batch_size
batch_size = inputs.shape[0]
# 本实验默认使用1层的LSTM,首先我们需要定义LSTM的初始hidden和cell,这里我们使用0来初始化这个序列的记忆
init_hidden_data = np.zeros(
(self.num_layers, batch_size, self.hidden_size), dtype='float32')
init_cell_data = np.zeros(
(self.num_layers, batch_size, self.hidden_size), dtype='float32')
# 将这些初始记忆转换为飞桨可计算的向量,并且设置stop_gradient=True,避免这些向量被更新,从而影响训练效果
init_hidden = paddle.to_tensor(init_hidden_data)
init_hidden.stop_gradient = True
init_cell = paddle.to_tensor(init_cell_data)
init_cell.stop_gradient = True
# 对应以上第2步,将输入的句子的mini-batch转换为词向量表示,转换后输入数据shape为[batch_size, max_seq_len, embedding_size]
x_emb = self.embedding(inputs)
x_emb = paddle.reshape(x_emb, shape=[-1, self.num_steps, self.embedding_size])
# 在获取的词向量后添加dropout层
if self.dropout_rate is not None and self.dropout_rate > 0.0:
x_emb = self.dropout_layer(x_emb)
# 对应以上第3步,使用LSTM网络,把每个句子转换为语义向量
# 返回的last_hidden即为最后一个时间步的输出,其shape为[self.num_layers, batch_size, hidden_size]
rnn_out, (last_hidden, last_cell) = self.simple_lstm_rnn(x_emb, (init_hidden, init_cell))
# 提取最后一层隐状态作为文本的语义向量,其shape为[batch_size, hidden_size]
last_hidden = paddle.reshape(last_hidden[-1], shape=[-1, self.hidden_size])
# 对应以上第4步,将每个句子的向量表示映射到具体的情感类别上, logits的维度为[batch_size, 2]
logits = self.cls_fc(last_hidden)
return logits
#模型训练
paddle.seed(0)
random.seed(0)
np.random.seed(0)
# 定义训练参数
epoch_num = 5
batch_size = 128
learning_rate = 0.0001
dropout_rate = 0.2
num_layers = 1
hidden_size = 256
embedding_size = 256
max_seq_len = 128
vocab_size = len(word2id_freq)
# 实例化模型
sentiment_classifier = SentimentClassifier(hidden_size, vocab_size, embedding_size, num_steps=max_seq_len, num_layers=num_layers, dropout_rate=dropout_rate)
# 指定优化策略,更新模型参数
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.999, parameters= sentiment_classifier.parameters())
# 定义训练函数
# 记录训练过程中的损失变化情况,可用于后续画图查看训练情况
losses = []
steps = []
def train(model):
# 开启模型训练模式
model.train()
# 建立训练数据生成器,每次迭代生成一个batch,每个batch包含训练文本和文本对应的情感标签
train_loader = build_batch(word2id_dict, train_corpus, batch_size, epoch_num, max_seq_len)
for step, (sentences, labels) in enumerate(train_loader):
# 获取数据,并将张量转换为Tensor类型
sentences = paddle.to_tensor(sentences)
labels = paddle.to_tensor(labels)
# 前向计算,将数据feed进模型,并得到预测的情感标签和损失
logits = model(sentences)
# 计算损失
loss = F.cross_entropy(input=logits, label=labels, soft_label=False)
loss = paddle.mean(loss)
# 后向传播
loss.backward()
# 更新参数
optimizer.step()
# 清除梯度
optimizer.clear_grad()
if step % 100 == 0:
# 记录当前步骤的loss变化情况
losses.append(loss.numpy()[0])
steps.append(step)
# 打印当前loss数值
print("step %d, loss %.3f" % (step, loss.numpy()[0]))
#训练模型
train(sentiment_classifier)
# 保存模型,包含两部分:模型参数和优化器参数
model_name = "sentiment_classifier"
# 保存训练好的模型参数
paddle.save(sentiment_classifier.state_dict(), "{}.pdparams".format(model_name))
# 保存优化器参数,方便后续模型继续训练
paddle.save(optimizer.state_dict(), "{}.pdopt".format(model_name))
#模型评估
def evaluate(model):
# 开启模型测试模式,在该模式下,网络不会进行梯度更新
model.eval()
# 定义以上几个统计指标
tp, tn, fp, fn = 0, 0, 0, 0
# 构造测试数据生成器
test_loader = build_batch(word2id_dict, test_corpus, batch_size, 1, max_seq_len)
for sentences, labels in test_loader:
# 将张量转换为Tensor类型
sentences = paddle.to_tensor(sentences)
labels = paddle.to_tensor(labels)
# 获取模型对当前batch的输出结果
logits = model(sentences)
# 使用softmax进行归一化
probs = F.softmax(logits)
# 把输出结果转换为numpy array数组,比较预测结果和对应label之间的关系,并更新tp,tn,fp和fn
probs = probs.numpy()
for i in range(len(probs)):
# 当样本是的真实标签是正例
if labels[i][0] == 1:
# 模型预测是正例
if probs[i][1] > probs[i][0]:
tp += 1
# 模型预测是负例
else:
fn += 1
# 当样本的真实标签是负例
else:
# 模型预测是正例
if probs[i][1] > probs[i][0]:
fp += 1
# 模型预测是负例
else:
tn += 1
# 整体准确率
accuracy = (tp + tn) / (tp + tn + fp + fn)
# 输出最终评估的模型效果
print("TP: {}\nFP: {}\nTN: {}\nFN: {}\n".format(tp, fp, tn, fn))
print("Accuracy: %.4f" % accuracy)
# 加载训练好的模型进行预测,重新实例化一个模型,然后将训练好的模型参数加载到新模型里面
saved_state = paddle.load("./sentiment_classifier.pdparams")
sentiment_classifier = SentimentClassifier(hidden_size, vocab_size, embedding_size, num_steps=max_seq_len, num_layers=num_layers, dropout_rate=dropout_rate)
sentiment_classifier.load_dict(saved_state)
# 评估模型
evaluate(sentiment_classifier)借助相同的思路,我们可以很轻易的解决文本相似度计算问题,假设给定两个句子:
句子1:我不爱吃烤冷面,但是我爱吃冷面
句子2:我爱吃菠萝,但是不爱吃地瓜
同样使用LSTM网络,把每个句子抽象成一个向量表示,通过计算这两个向量之间的相似度,就可以快速完成文本相似度计算任务。在实际场景里,我们也通常使用LSTM网络的最后一步hidden结果,将一个句子抽象成一个向量,然后通过向量点积,或者cosine相似度的方式,去衡量两个句子的相似度。
6.3 BERT
大名鼎鼎的BERT,全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。BERT论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,表现非常惊艳。
BERT在训练过程中,不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是使用了基于掩盖的语言模型(Masked Language Model, MLM),即随机对输入序列中的某些位置进行遮蔽,然后通过模型来对其进行预测,以生成深度的双向语言表征。
BERT在预训练时使用的是大量的无标注的语料(比如随手可见的一些文本,它是没有标注的)。所以它在预训练任务设计的时候,一定是要考虑无监督来做,因为是没有标签的。
对于无监督的目标函数来讲,有两组目标函数比较受到重视,
第一种是 AR模型,auto regressive,自回归模型。只能考虑单侧信息,典型的就是GPT。
另一种是AE模型,auto encoding,自编码模型。从损坏的输入数据中预测重建原始数据,可以使用上下文的信息。BERT使用的就是AE。这种方式可以让模型根据上下文充分的预测缺失信息。
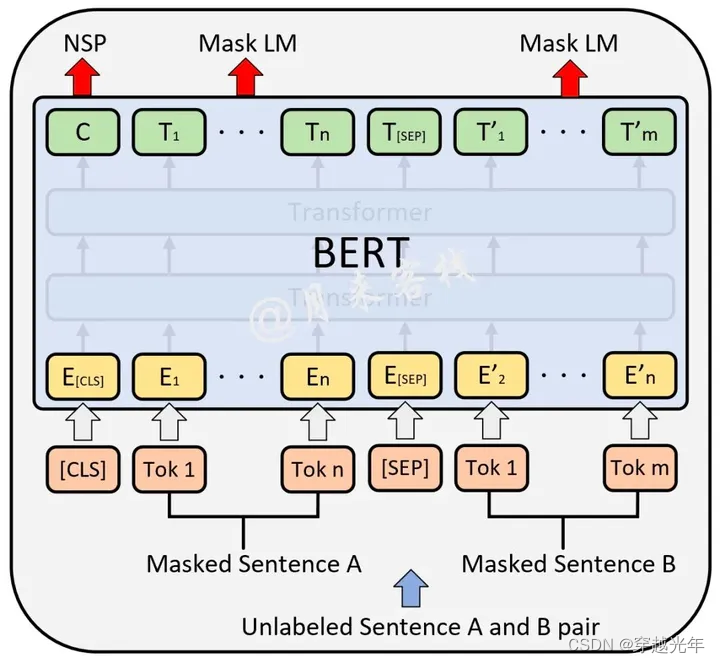
如上图所示便是ML和NSP这两个任务在BERT预训练时的输入输出示意图,其中最上层输出的在预训练时用于NSP中的分类任务;其它位置上的,则用于预测被掩盖的Token。
对于BERT来说,如果单从网络结构上来说的话,感觉并没有太大的创新,这也正如作者所说“BERT整体上就是由多层的Transformer Encoder堆叠所形成”,并且所谓的“Bidirectional”其实指的也就是Transformer中的self-attention机制。真正让BERT表现出色的应该是基于MLM和NSP这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。
辅助阅读:BERT原理与NSP和MLM - 知乎






![[Java][算法 滑动窗口]Day 03---LeetCode 热题 100---08~09](https://img-blog.csdnimg.cn/direct/a5a604495a964d8e9768e5917c5f0b70.png)