论文题目:CoPL: Contextual Prompt Learning for Vision-Language Understanding
论文链接:https://arxiv.org/abs/2307.00910
提示学习(Prompt Learning)在近几年的快速发展,激活了以Transformer为基础的大型语言模型(LLM)的性能涌现。这一技术范式迅速在多模态学习等领域进行迁移,例如在CLIP跨模态对齐模型中加入可学习的Prompt,就可以在多种下游任务展现出通用性能,且具有一定的泛化能力。但这种简单的提示方法仍具有局限性,主要分为两个方面,其一是使用全局视觉特征作为提示输入可能会导致模型缺乏关注图像中前景对象的注意力能力。此外,在将提示送入到下游模块时,现有的方法对所有提示设置的权重完全相同,直观上思考,应该根据不同输入图像的内容来重新调整这一权重。
基于这两方面的局限,本文介绍一篇发表在人工智能顶级会议AAAI 2024上的文章,本文提出了一种称为上下文提示学习(Contextual Prompt Learning)的框架CoPL,CoPL可以更精确的实现提示信息与图像局部特征的对齐,为了使学习到的提示能够更好的适应到不同的下游任务中,作者设计了一种动态提示机制,从提取图像上下文特征的角度来对提示进行加权处理。本文的实验在包含few-shot和out-of-distribution等多种任务设置上进行,实验结果表明,CoPL在多模态提示学习领域已达SOTA性能。
01. 引言
传统的视觉分类任务通常需要在包含大规模类别的数据集上进行训练,例如ImageNet和OpenImages等。但是当模型在遇到一些训练分布之外的特殊图像时,就无法做出合理的预测,这种方法因为缺乏泛化性一直被学术界所诟病。研究人员开始探索如何将特定领域的知识注入到已有的模型中,使其具有一定的扩展能力。CoOp[1]方法是这一领域的先行工作,其通过引入NLP领域中提示学习的思想,通过训练可学习的提示向量来保留句子和标签之间的语义关系。但后来的一些工作指出,基于CoOp的方法具有灾难性知识遗忘的特点,同时仅采用模型的全局特征来生成提示,提示无法很好的适应到特定的下游任务中。
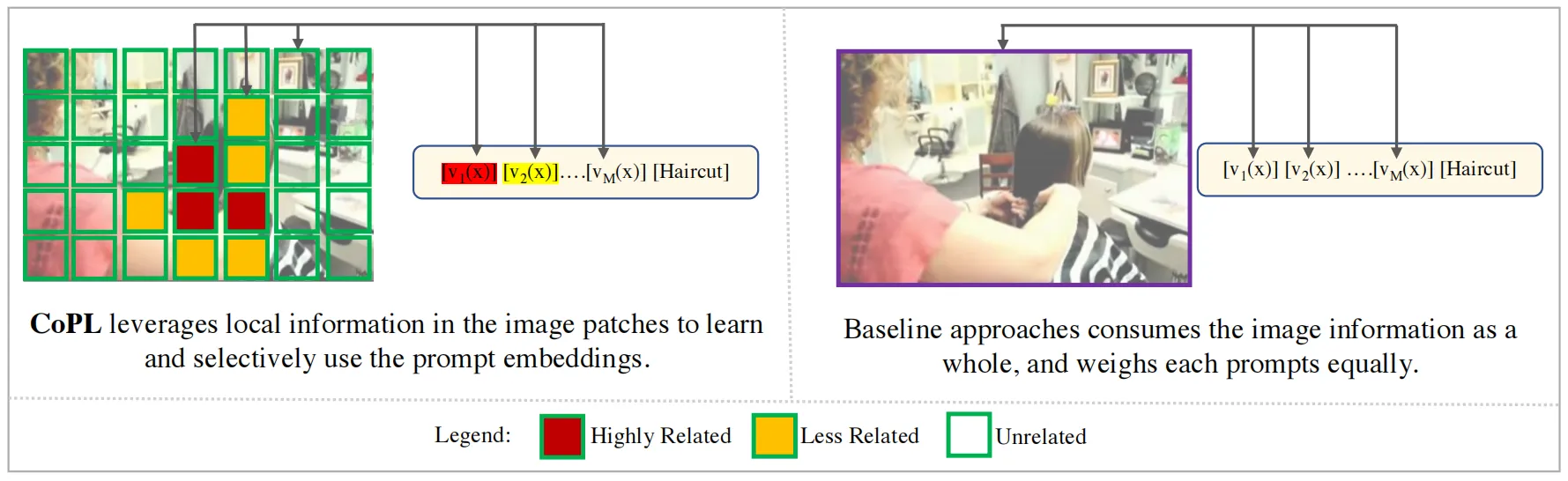
本文首先分析了现有框架的缺陷,相应的提出了一种上下文提示学习的改进框架CoPL,CoPL的关键思想是将提示与局部图像上下文进行对齐,如果仅使用全局特征,模型在很多few-shot和分布外的测试样本上很容易受到噪声的影响。如上图所示,CoPL首先确定图像局部上下文与哪些提示在语义上更相关,然后计算得到更合适的提示权重,通过拟合上下文信息到提示中,CoPL产生的特征会具有更强的鲁棒性和通用性。
02. 本文方法
2.1 原始CLIP模型

2.2 CoOp和CoCoOp

2.3 上下文提示学习CoPL
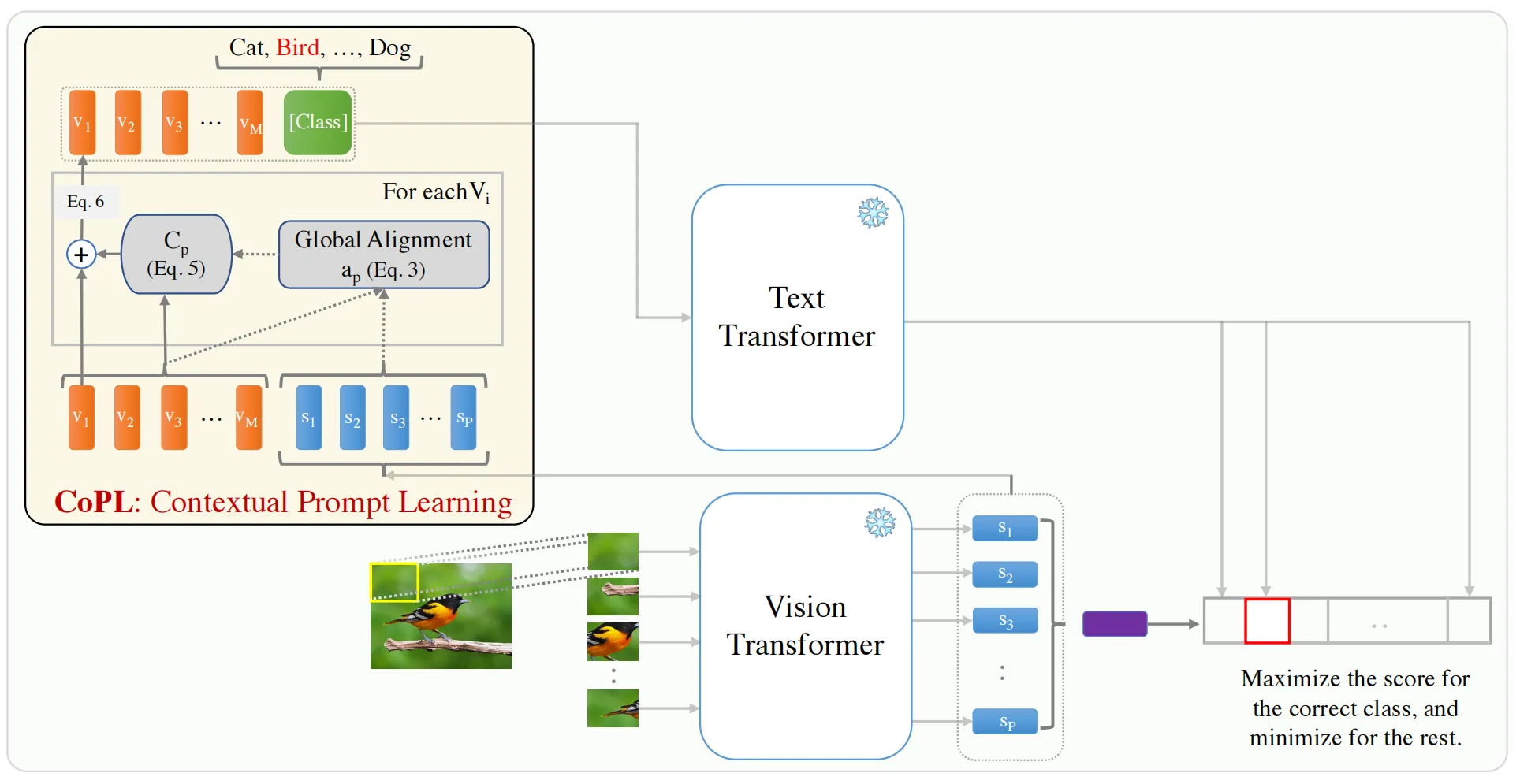
虽然CoCoOp相比CoOp在性能方面已经获得了较大的提升,但其仍有很大的改进空间,由于 CoCoOp 使用全局特征向量来更新提示向量,因此其很难关注到图像中的局部感兴趣区域。此外,在将meta-net生成的条件向量附加到提示向量上时,CoCoOp没有体现不同区域的提示重要性。为了解决这些问题,本文提出了一种CoPL方法,CoPL方法的整体框架如下图所示。

03. 实验效果
本文的实验在11个不同复杂度的图像分类数据集上进行,这些数据集主要包含通用分类数据集,例如ImageNet和Caltech-101,以及细粒度类别数据集:OxfordPets、StanfordCars、Flowers102、Food101和 FGVCAircraft。还有一些特殊领域中的标准数据集,例如场景识别、动作分类、纹理和卫星图像识别数据集。作者也选取了一些常见的CoOp变体方法作为baseline对比方法,包括CoCoOp、KgCoOp和ProGrad等。
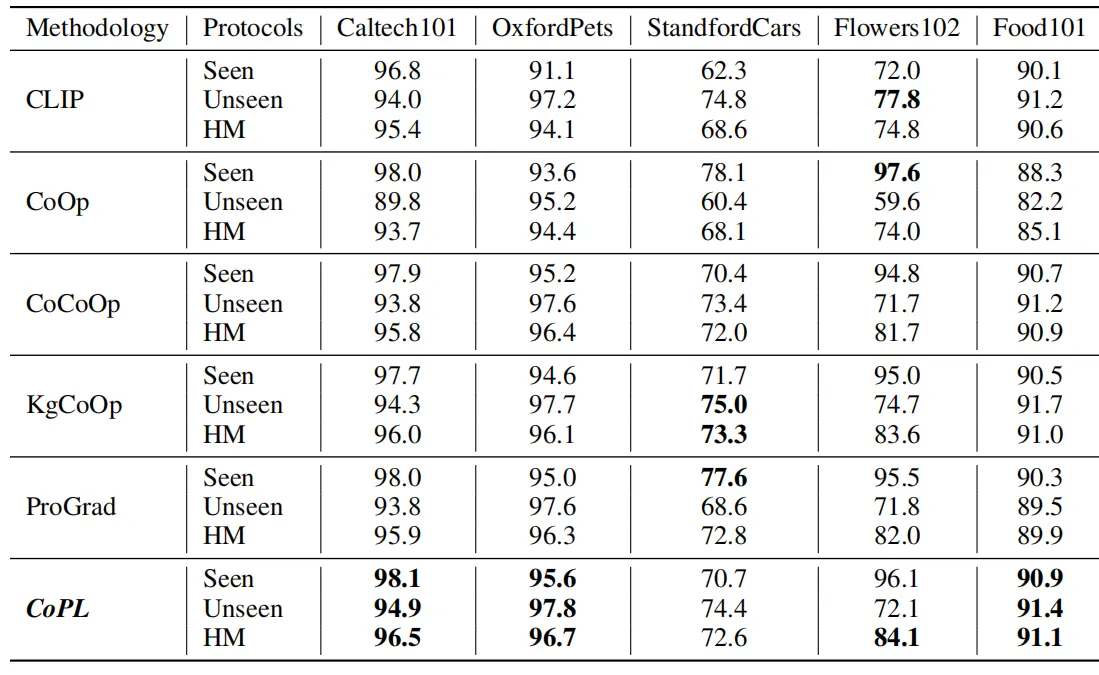
上表展示了本文方法在上述几种数据集上的性能表现,本文作者提到,CoOp方法的主要缺点之一是其在训练分布之外的样本上表现不佳,无法很好的泛化到一些unseeen的类别上。本文的方法对这一方面进行了改进,如上表所示,CoPL在绝大多数数据集上的unseen子集上均获得了更好的分类精度。此外,我们还可以观察到,CoOp方法相比原始的CLIP方法性能有所下降,这也证明了其具有灾难性遗忘的问题。
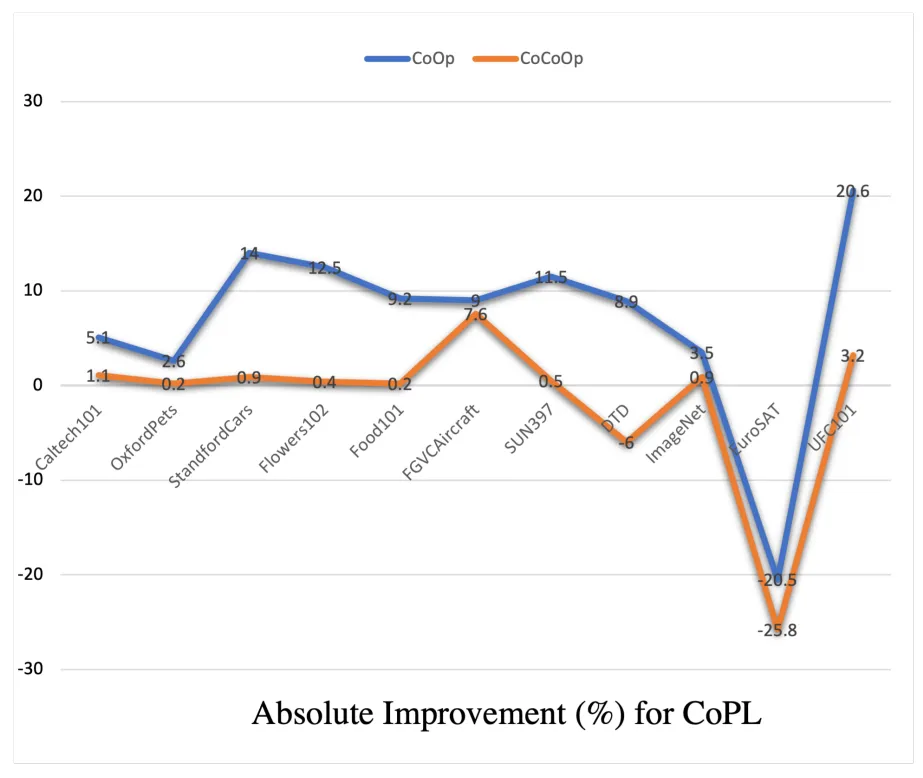
此外,作者在上图中进一步分析了本文提出的CoPL相比CoOp和CoCoOp方法在unseeen类别上的性能提升效果。可以看到,在行为识别数据集UCF101上,CoPL实现了将近20.6%的性能增益,而在其他语义信息较少的数据集,例如纹理数据集等,CoPL也可以得到一定的性能增益,这表明本文方法的出发点是正确的,通过对图像局部区域的注意力特征进行上下文建模,可以使得到的动态提示向量包含更多与下游任务相关的语义信息。

除了常规分类任务之外,本文作者还重点探索了本文方法在零样本(zero-shot)分类任务上的性能,如上表所示,首先将实验方法在简单的Caltech101数据集上进行训练,随后测试其在其他数据集上的性能,以评估方法的零样本迁移能力。从上表中可以看出,CoPL方法在大多数数据集上的表现都优于CoCoOp。虽然Caltech101是通用对象分类数据集,但是CoPL仍然能够将知识迁移到DTD数据集上来执行纹理识别任务。
04. 总结
本文作者首先对现有基于提示的图像分类方法的缺陷进行了分析,即这些方法无法很好的关注到图像的局部关键信息。本文提出另一种全新的多模态提示学习方法CoPL,CoPL通过动态学习提示权重并将生成的提示向量与局部图像进行特征对齐来解决上述问题。作者通过在包含11个不同的数据集和场景中进行了完整的视觉分类实验,包括zero-shot、few-shot等不同的实验设置。实验结果表明,经过CoPL方法处理后的多模态对齐特征,具有良好的下游任务适应能力。
参考
[1] Zhou, K.; Yang, J.; Loy, C. C.; and Liu, Z. 2022b. Learning to Prompt for Vision-Language Models. Int. J. Comput. Vis., 130(9): 2337–2348.
[2] Zhou, K.; Yang, J.; Loy, C. C.; and Liu, Z. 2022a. Conditional Prompt Learning for Vision-Language Models. In CVPR.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区

![【sgCreateTableColumn】自定义小工具:敏捷开发→自动化生成表格列html代码(表格列生成工具)[基于el-table-column]](https://img-blog.csdnimg.cn/direct/1ce75f457fb24b5ba540809aedce0013.gif)