Python算法题集_二叉树的层序遍历
- 题102:二叉树的层序遍历
- 1. 示例说明
- 2. 题目解析
- - 题意分解
- - 优化思路
- - 测量工具
- 3. 代码展开
- 1) 标准求解【DFS递归】
- 2) 改进版一【BFS迭代】
- 3) 改进版二【BFS迭代+循环】
- 4. 最优算法
本文为Python算法题集之一的代码示例
题102:二叉树的层序遍历
1. 示例说明
-
给你二叉树的根节点
root,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。示例 1:
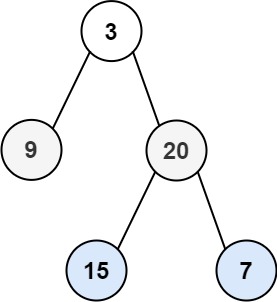
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例 2:
输入:root = [1] 输出:[[1]]示例 3:
输入:root = [] 输出:[]提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
- 树中节点数目在范围
2. 题目解析
- 题意分解
- 本题为对二叉树进行层序遍历,每层从左到右列出节点值
- 基本的设计思路是深度优先算法【DFS(Depth-First Search)】、广度有限算法【BFS(Breadth-First Search)】
- 优化思路
-
通常优化:减少循环层次
-
通常优化:增加分支,减少计算集
-
通常优化:采用内置算法来提升计算速度
-
分析题目特点,分析最优解
-
本地需要采用
DFS进行路径长度计算 -
可以考虑在递归函数中使用可变量【通过引用传递】
-
可以考虑在递归函数中返回最大值【通过值传递】
-
- 测量工具
- 本地化测试说明:LeetCode网站测试运行时数据波动很大,因此需要本地化测试解决这个问题
CheckFuncPerf(本地化函数用时和内存占用测试模块)已上传到CSDN,地址:Python算法题集_检测函数用时和内存占用的模块- 本题本地化超时测试用例自己生成,详见【最优算法章节】
3. 代码展开
1) 标准求解【DFS递归】
使用深度优先算法,在递归中传入层级参数,将节点值从左到右保存到结果中
性能良好,超过91%
import CheckFuncPerf as cfp
class Solution:
def levelOrder_base(self, root):
if not root:
return []
result = []
def dfsTraversal(ilevel, root):
if len(result) < ilevel:
result.append([])
result[ilevel - 1].append(root.val)
if root.left:
dfsTraversal(ilevel + 1, root.left)
if root.right:
dfsTraversal(ilevel + 1, root.right)
dfsTraversal(1, root)
return result
aroot = generate_symmetry_binary_tree(ilen)
aSolution = Solution()
result = cfp.getTimeMemoryStr(Solution.levelOrder_base, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result'][4]))
# 运行结果
函数 levelOrder_base 的运行时间为 174.03 ms;内存使用量为 2720.00 KB 执行结果 = [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
2) 改进版一【BFS迭代】
使用列表结构【list】作为队列,先进先出实现BFS遍历,填充每层节点
独孤求败,超越99%
import CheckFuncPerf as cfp
class Solution:
def levelOrder_ext1(self, root):
if not root:
return []
result = []
stack_tree = [(root, 1)]
while stack_tree:
node, depth = stack_tree.pop(-1)
if len(result) < depth:
result.append([])
result[depth - 1].append(node.val)
if node.right:
stack_tree.append((node.right, depth + 1))
if node.left:
stack_tree.append((node.left, depth + 1))
return result
aroot = generate_symmetry_binary_tree(ilen)
aSolution = Solution()
result = cfp.getTimeMemoryStr(Solution.levelOrder_ext1, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result'][4]))
# 运行结果
函数 levelOrder_ext1 的运行时间为 183.02 ms;内存使用量为 2156.00 KB 执行结果 = [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
3) 改进版二【BFS迭代+循环】
使用列表结构【list】作为堆栈,后进先出实现BFS遍历,填充每层节点,效率不如队列结果
马马虎虎,超过79%
import CheckFuncPerf as cfp
class Solution:
def levelOrder_ext2(self, root):
if not root:
return []
result = []
queue_tree = [root]
while queue_tree:
ilen = len(queue_tree)
tmp = []
for iIdx in range(ilen):
tmproot = queue_tree.pop(0)
tmp.append(tmproot.val)
if tmproot.left:
queue_tree.append(tmproot.left)
if tmproot.right:
queue_tree.append(tmproot.right)
result.append(tmp)
return result
aroot = generate_binary_tree(ilen, imode)
aSolution = Solution()
result = cfp.getTimeMemoryStr(Solution.diameterOfBinaryTre_ext2, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result']))
# 运行结果
函数 diameterOfBinaryTre_ext2 的运行时间为 425.10 ms;内存使用量为 0.00 KB 执行结果 = 102
4. 最优算法
根据本地日志分析,最优算法为第1种方式【DFS递归】levelOrder_base
ilen = 18
def generate_symmetry_binary_tree(ilevel):
if ilevel <= 0:
return None
root = TreeNode(ilevel)
left = generate_symmetry_binary_tree(ilevel - 1)
right = generate_symmetry_binary_tree(ilevel - 1)
root.left = left
root.right = right
return root
aroot = generate_symmetry_binary_tree(ilen)
aSolution = Solution()
result = cfp.getTimeMemoryStr(Solution.levelOrder_base, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result'][4]))
result = cfp.getTimeMemoryStr(Solution.levelOrder_ext1, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result'][4]))
result = cfp.getTimeMemoryStr(Solution.levelOrder_ext2, aSolution, aroot)
print(result['msg'], '执行结果 = {}'.format(result['result'][4]))
# 算法本地速度实测比较
函数 levelOrder_base 的运行时间为 174.03 ms;内存使用量为 2720.00 KB 执行结果 = [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
函数 levelOrder_ext1 的运行时间为 183.02 ms;内存使用量为 2156.00 KB 执行结果 = [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
函数 levelOrder_ext2 的运行时间为 7326.64 ms;内存使用量为 3916.00 KB 执行结果 = [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
一日练,一日功,一日不练十日空
may the odds be ever in your favor ~