代码随想录算法训练营第十七天|Leetcode110 平衡二叉树、Leetcode257 二叉树的所有路径、Leetcode404 左叶子之和
- ● Leetcode110 平衡二叉树
- ● 解题思路
- ● 代码实现
- ● Leetcode257 二叉树的所有路径
- ● 解题思路
- ● 代码实现
- ● Leetcode404 左叶子之和
- ● 解题思路
- ● 代码实现
● Leetcode110 平衡二叉树
题目链接:Leetcode110 平衡二叉树
视频讲解:代码随想录|平衡二叉树
题目描述:给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
示例 1:
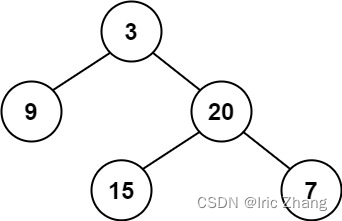
输入:root = [3,9,20,null,null,15,7]
输出:true
示例 2:
输入:root = [1,2,2,3,3,null,null,4,4]
输出:false
示例 3:
输入:root = []
输出:true
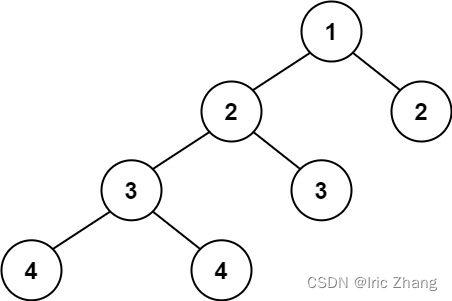
● 解题思路
方法一:递归
使用递归解决二叉树遍历问题仍然需要遵循递归三部曲:
(1)明确递归函数的参数和返回值:
根据平衡二叉树定义
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
我们需要获取左右子树的高度,然后对其做差才能判断二叉树是否为平衡二叉树。因此我们自定义一个获取二叉树高度的函数,返回值为二叉树高度int,传入参数必然是传入根节点Treenode* root;
int getHeight(TreeNode* root)
(2)确定递归终止条件:
当传入结点为空时,递归就需要向上返回;
//终止条件
if(!root) return 0;
(3)确定单层递归的逻辑:
在之前的文章中已经讨论过对于高度和深度使用哪种遍历方式最优,因为我们需要将子树的平衡结果返回给上一结点,所以我们必然需要先遍历左右结点随后中结点才能达到目的,因此我们在单层递归中使用后序遍历。
我们需要先获取以左右结点为根的子树高度,随后对其做差取绝对值和1进行比较,只有result <= 1时才是平衡二叉树。
倘若在某一处子树的返回值为-1时,即已经可以证明整个二叉树一定不是平衡二叉树,直接返回即可。
方法二:迭代
首先,我们需要使用栈模拟二叉树的后序遍历自定义获取二叉树高度的函数,帮助我们获取每一个结点的高度;
然后在主函数中使用栈遍历每一个结点判断是否为平衡二叉树。
看图感悟过程吧。
● 代码实现
方法一:递归
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int getHeight(TreeNode* root)
{
//终止条件
if(!root) return 0;
//左
int leftHeight = getHeight(root->left);
if(leftHeight == -1) return -1;
//右
int rightHeight = getHeight(root->right);
if(rightHeight == -1) return -1;
//中
int result;
if(abs(rightHeight - leftHeight) > 1) result = -1;
else
{
result = 1 + max(leftHeight, rightHeight);
}
return result;
}
bool isBalanced(TreeNode* root) {
return getHeight(root) == -1 ? false : true;
}
};
方法二:迭代
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
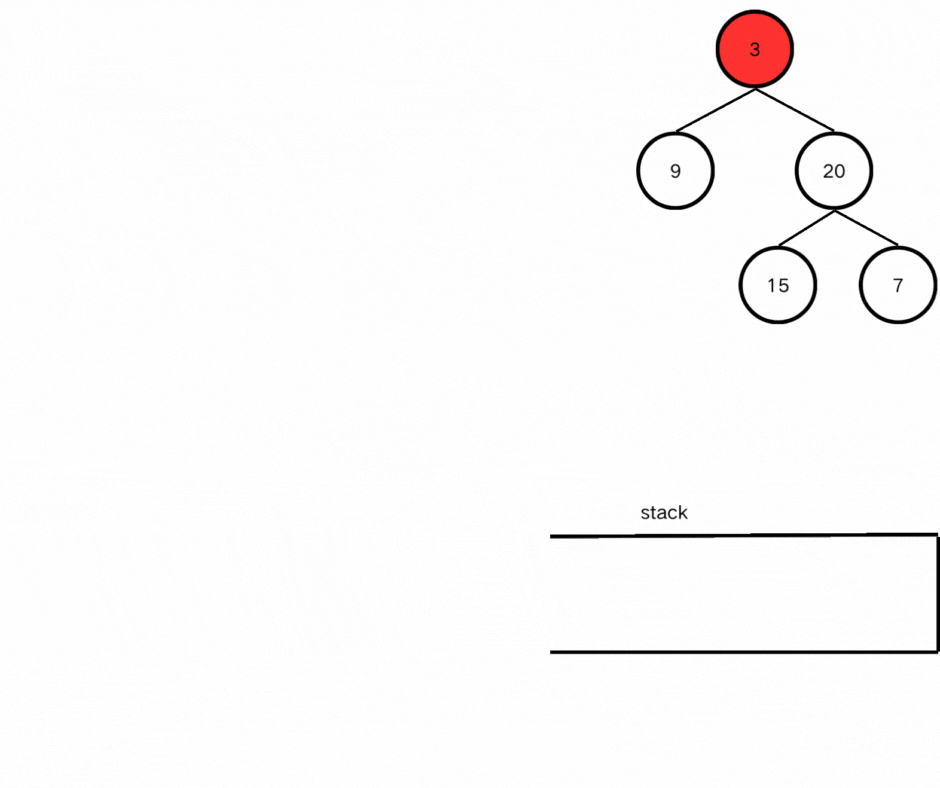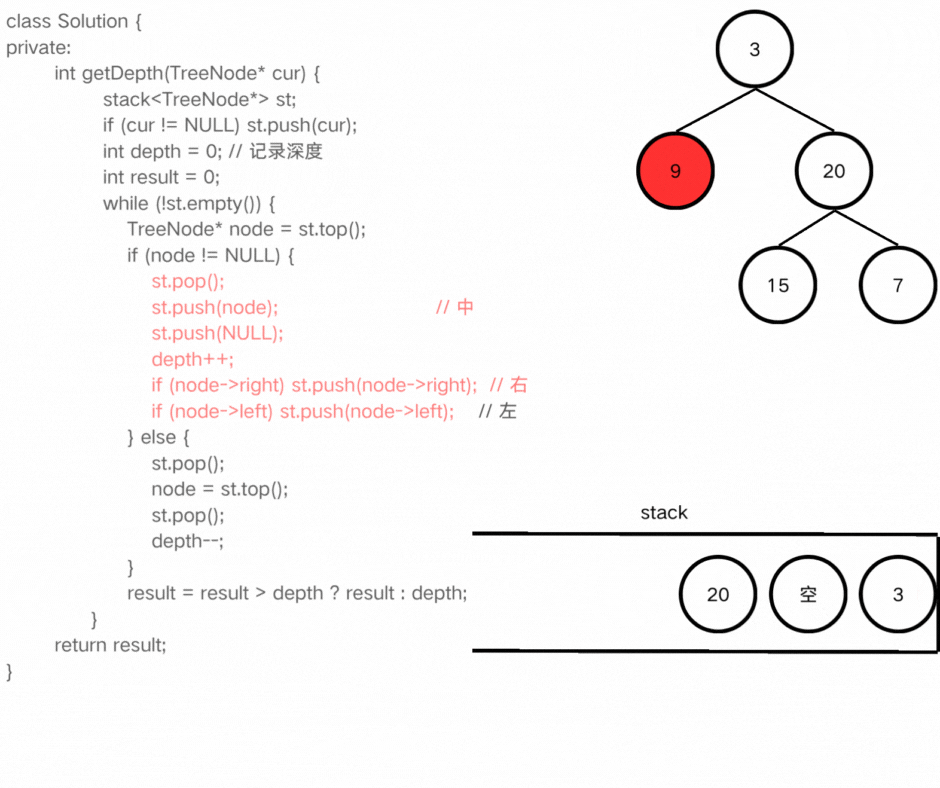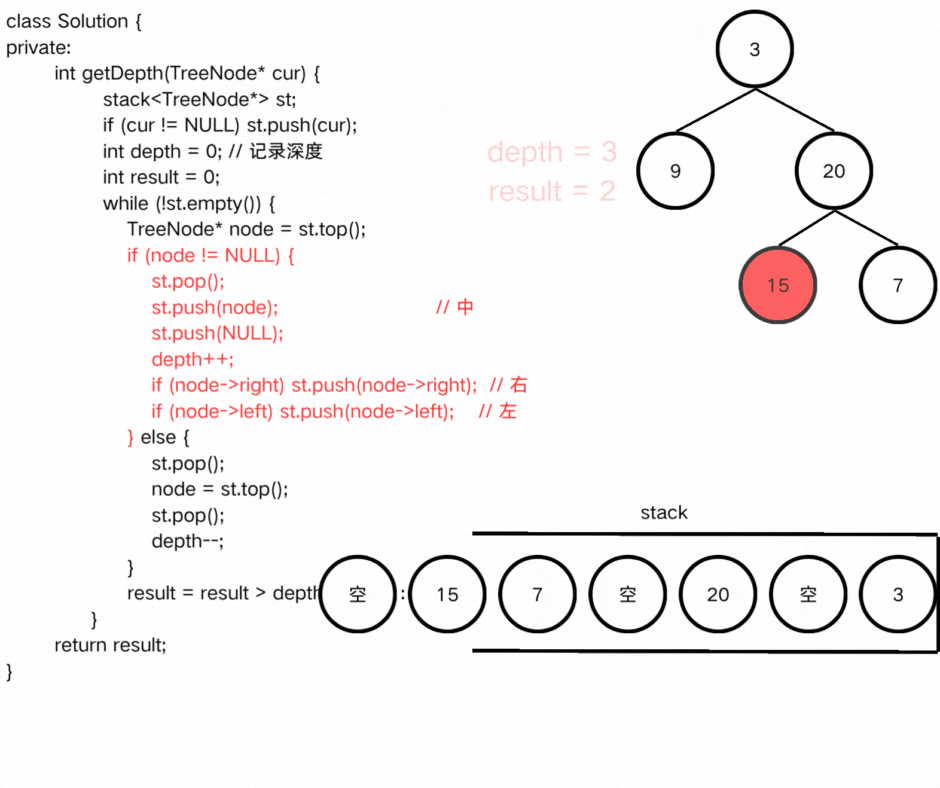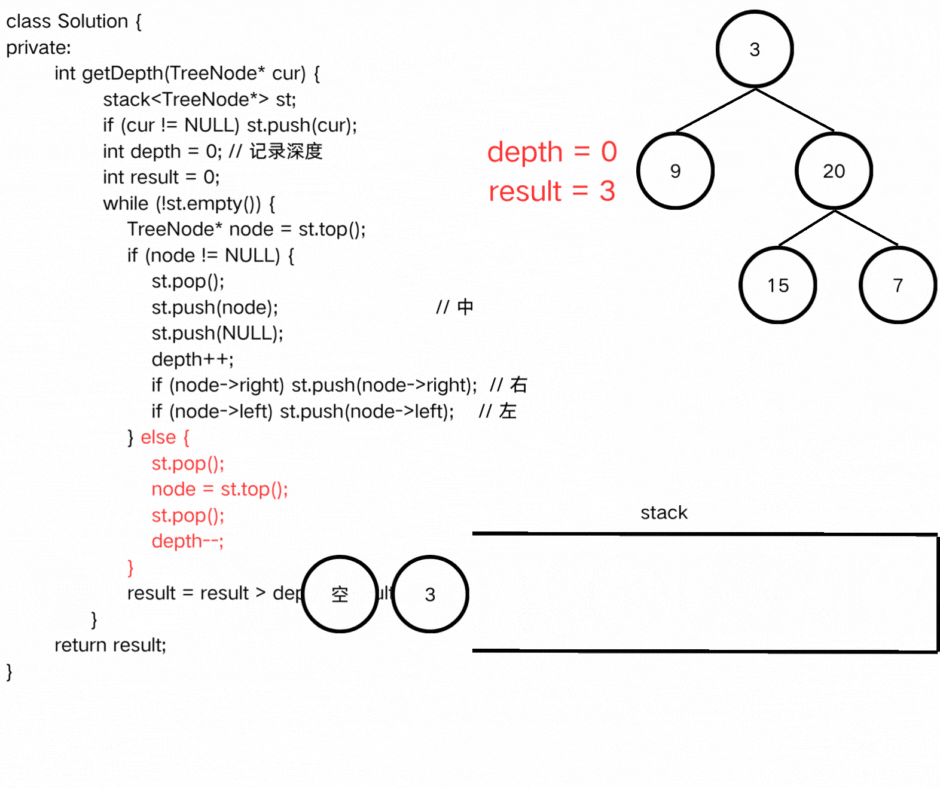
int getHeight(TreeNode* node)
{
stack<TreeNode*> st;
if(node) st.push(node);
int depth = 0, result = 0;
while(!st.empty())
{
TreeNode* node = st.top();
if(node)
{
st.pop();
st.push(node);
st.push(nullptr);
depth++;
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
}
else
{
st.pop();
node = st.top();
st.pop();
depth--;
}
result = result > depth ? result : depth;
}
return result;
}
bool isBalanced(TreeNode* root) {
if(!root) return true;
stack<TreeNode*> st;
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top(); st.pop();
int leftHeight = getHeight(node->left);
int rightHeight = getHeight(node->right);
if(abs(rightHeight - leftHeight) > 1) return false;
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
}
return true;
}
};
● Leetcode257 二叉树的所有路径
题目链接:Leetcode257 二叉树的所有路径
视频讲解:代码随想录|二叉树的所有路径
题目描述:给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
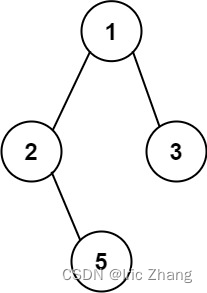
示例 1:
输入:root = [1,2,3,null,5]
输出:[“1->2->5”,“1->3”]
示例 2:
输入:root = [1]
输出:[“1”]
● 解题思路
方法一:递归
本题需要使用回溯进行解决,因为当我们遍历完一条完成路径之后,需要通过回溯才能重新进入另外一条路径,和迷宫是一个道理。
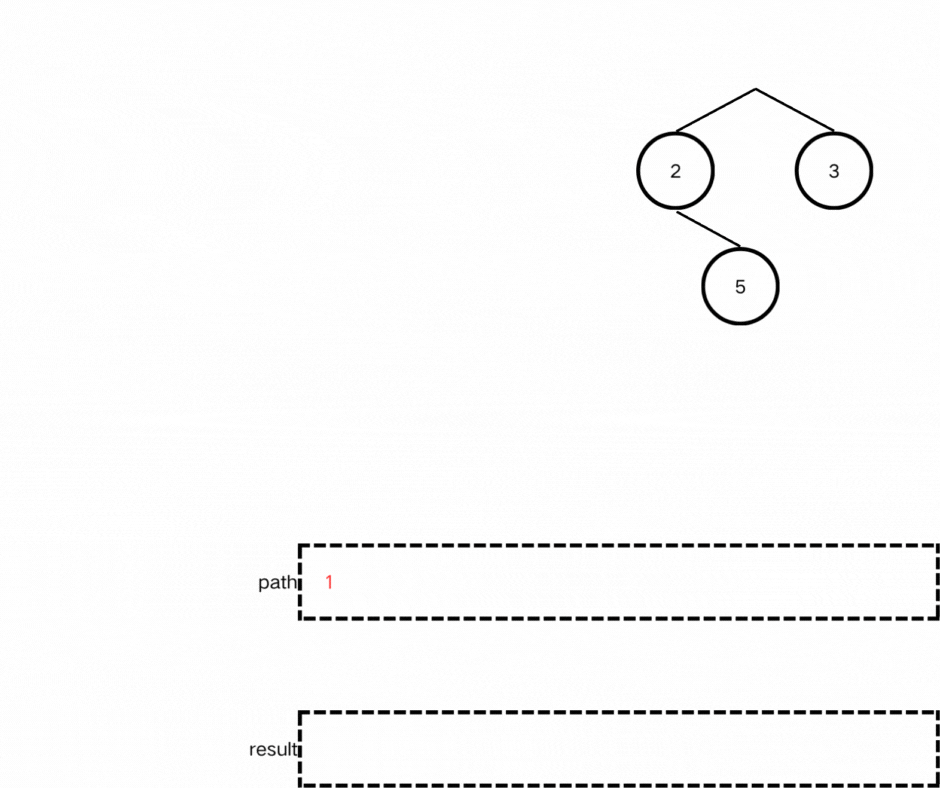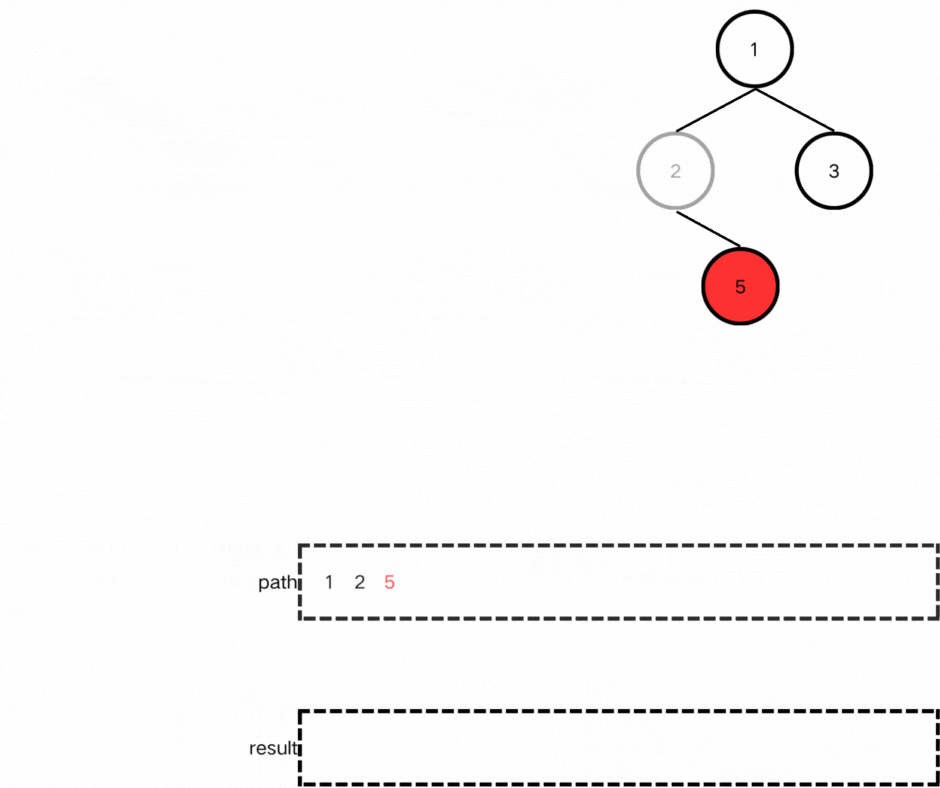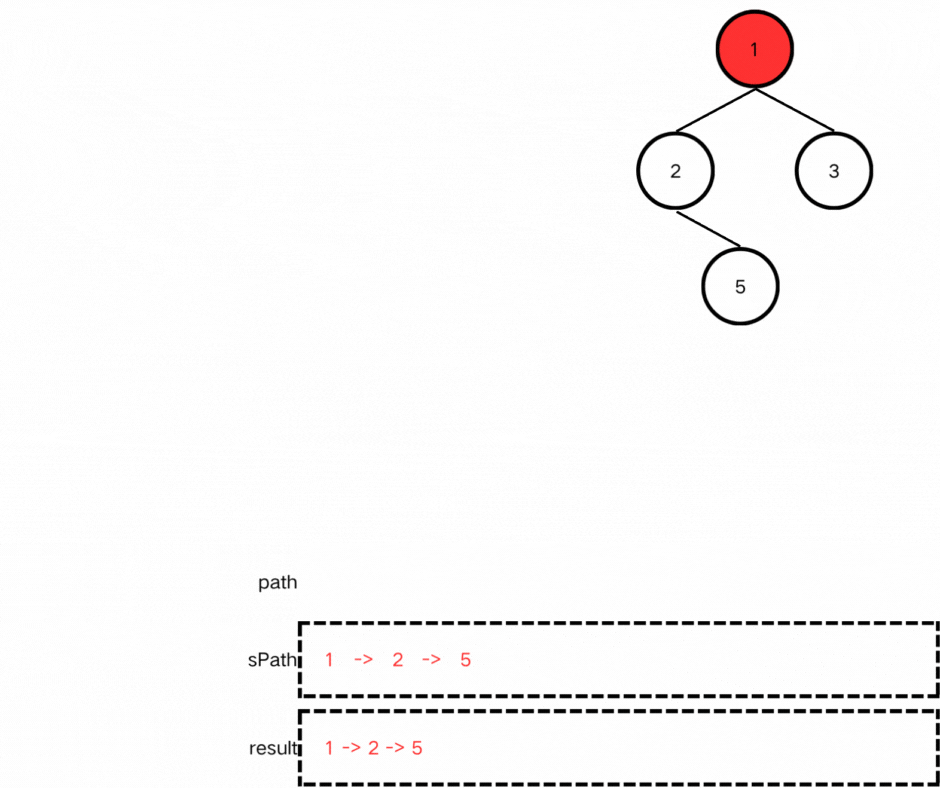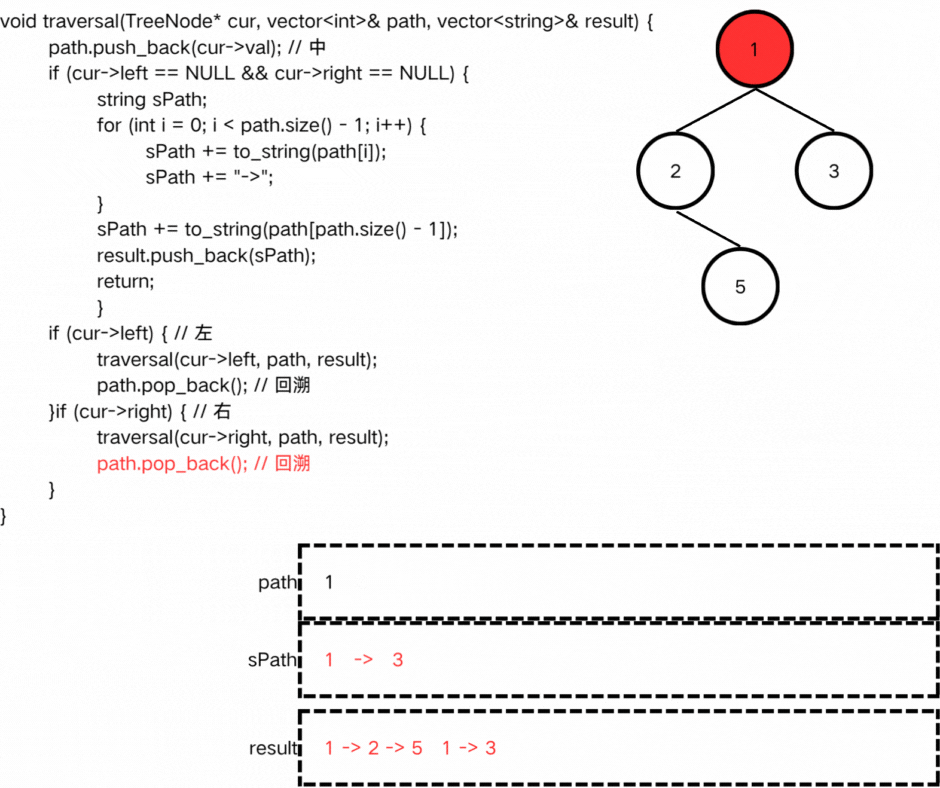
(1)确定递归函数参数和返回值:
该函数不需要返回值,传入参数需要包括遍历结点,存储路径的容器path以及存储最终结果的容器result;
void traversal(TreeNode* node, vector<int>& path, vector<string>& result)
(2)确定终止条件:
我们需要记录从根结点开始的每一条路径,在这里我们不需要遍历到空结点,因此当遍历到叶子结点时递归终止;
if(!node->left && !node->right)
{
//将路径结点的值转化为string类型
string sPath;
for(int i = 0; i < path.size() - 1; i++) //将前n - 1个元素转换为"val->"字符串形式
{
sPath += to_string(path[i]);
sPath += "->";
}
sPath += to_string(path[path.size() - 1]); //加入叶子结点
result.push_back(sPath); //将转换后的字符串插入result中
return;
}
(3)确定单层递归逻辑:
我们需要从根结点不断向下遍历获取二叉树的路径,因此前序遍历更合适。
但需要注意,对于中的处理需要放在终止条件之前,因为如果将其放在终止条件之后,无法在path中加入叶子结点,就没办法返回正确结点。
方法二:迭代
我们使用一个栈保存树遍历的结点,另一个栈保存遍历的路径。
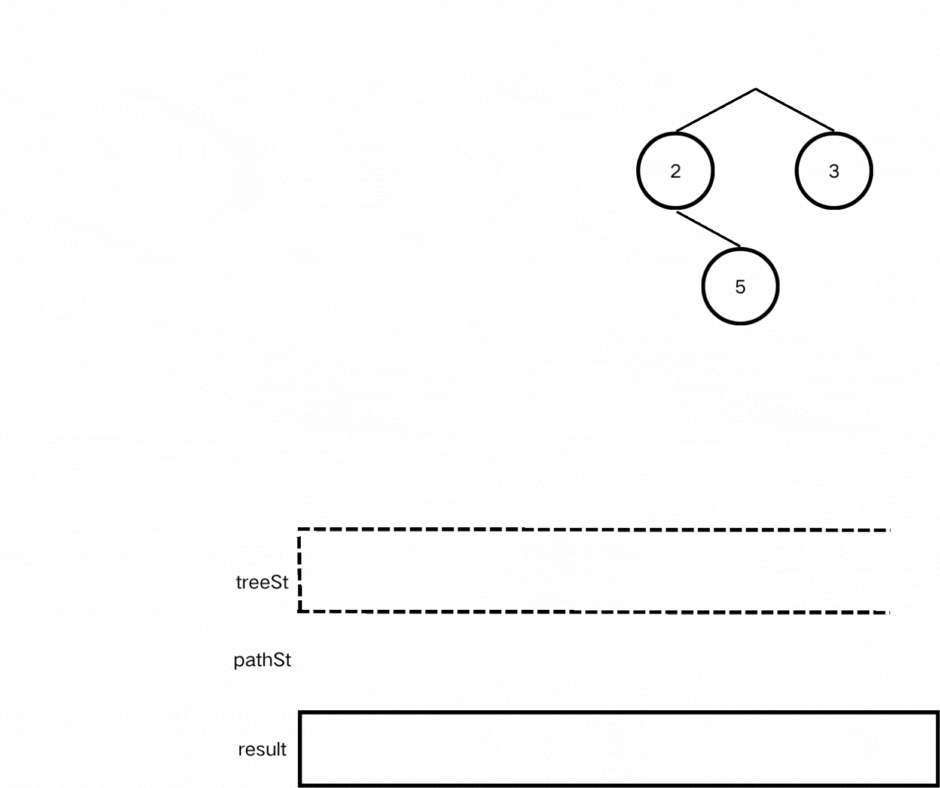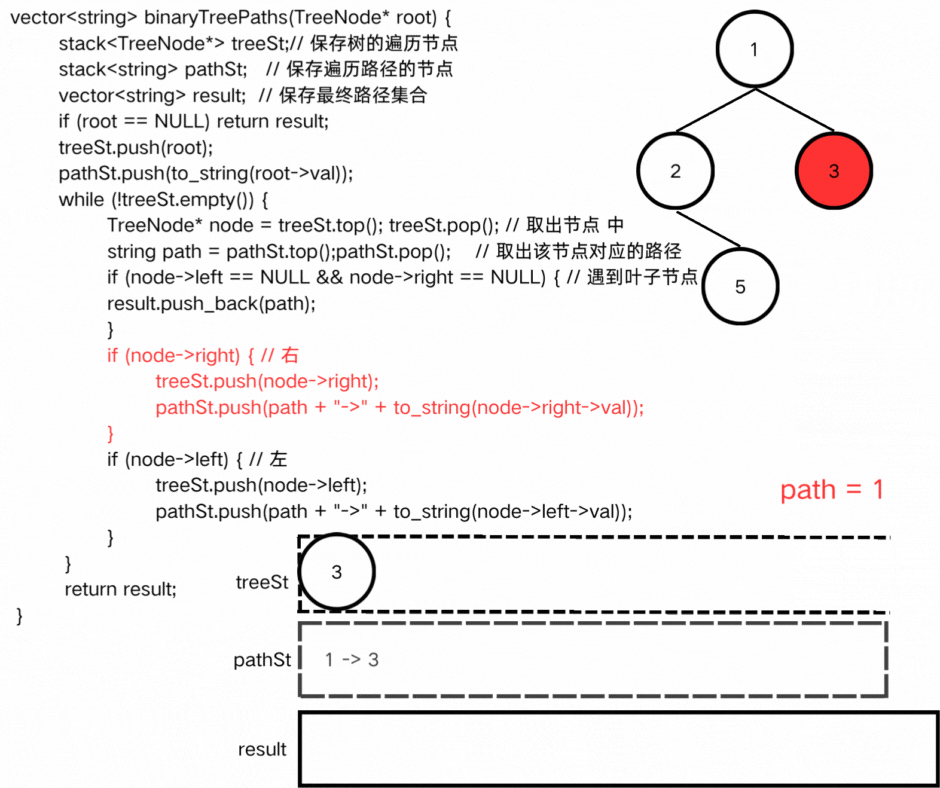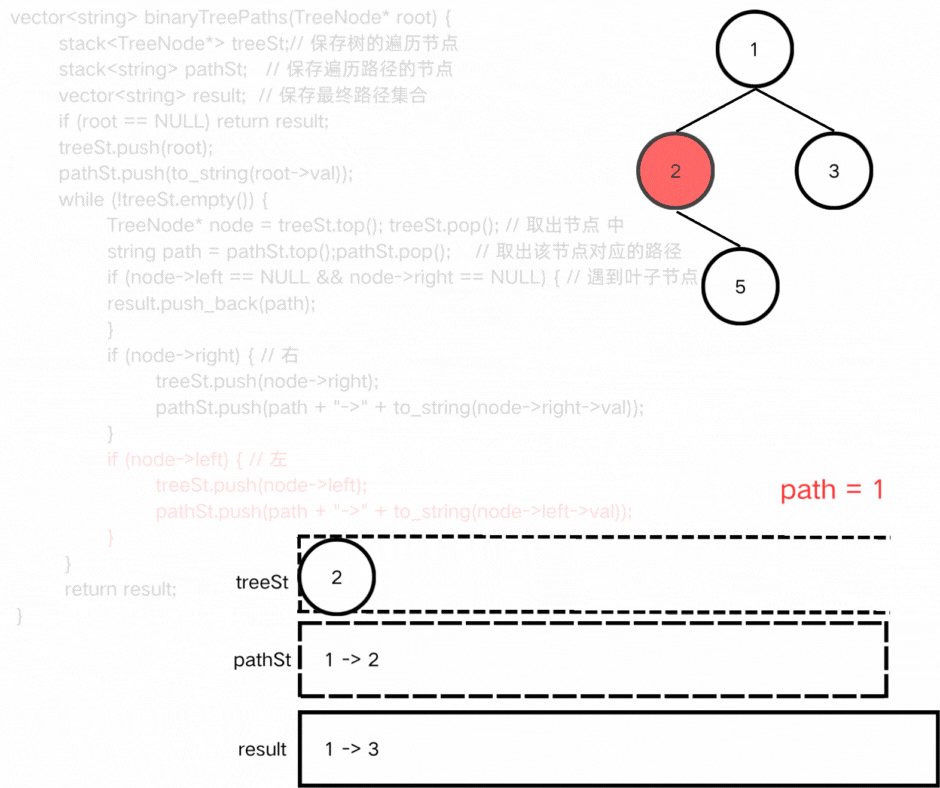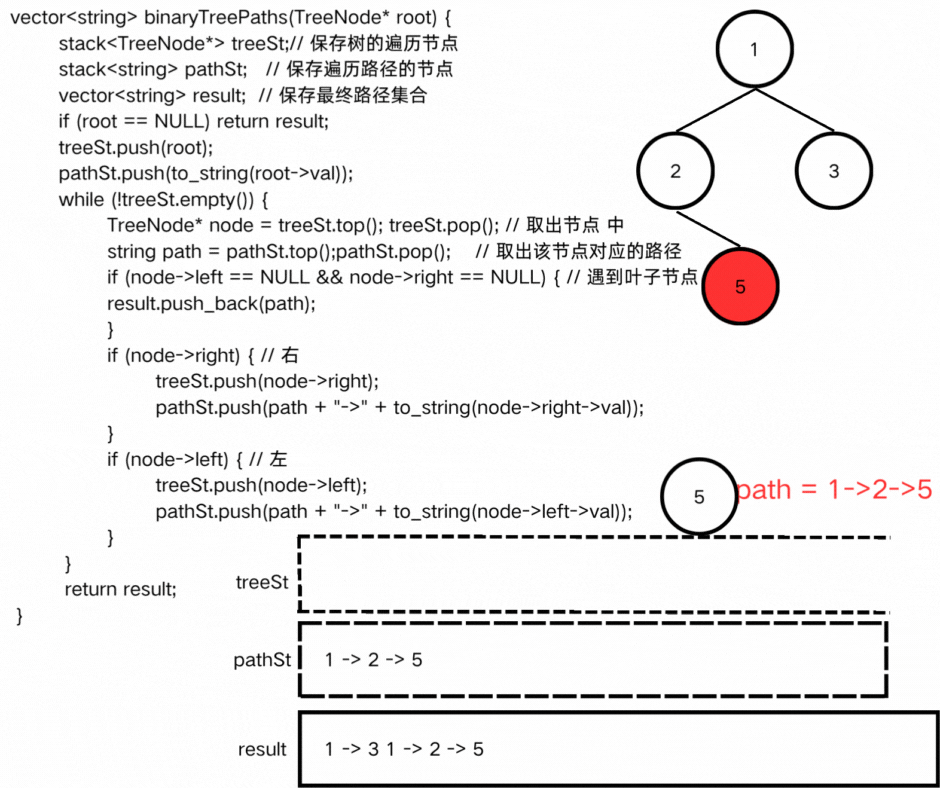
● 代码实现
方法一:递归
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* node, vector<int>& path, vector<string>& result)
{
path.push_back(node->val);//中
if(!node->left && !node->right)
{
//将路径结点的值转化为string类型
string sPath;
for(int i = 0; i < path.size() - 1; i++) //将前n - 1个元素转换为"val->"字符串形式
{
sPath += to_string(path[i]);
sPath += "->";
}
sPath += to_string(path[path.size() - 1]); //加入叶子结点
result.push_back(sPath); //将转换后的字符串插入result中
return;
}
//左
if(node->left)
{
traversal(node->left, path, result); //递归
path.pop_back(); //回溯
}
//右
if(node->right)
{
traversal(node->right, path, result); //递归
path.pop_back(); //回溯
}
}
vector<string> binaryTreePaths(TreeNode* root) {
vector<int> path; //存放一条路径
vector<string> result; //将路径全部放在返回结果
if(!root) return result;
traversal(root, path, result);
return result;
}
};
上面的能够充分体现了回溯,对其进行简化:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* node, string path, vector<string>& result)
{
//中
path += to_string(node->val);
//终止条件
if(!node->left && !node->right)
{
result.push_back(path);
return;
}
//左
if(node->left) traversal(node->left, path + "->", result);
//右
if(node->right) traversal(node->right, path + "->", result);
}
vector<string> binaryTreePaths(TreeNode* root) {
string path; //存放一条路径
vector<string> result; //将路径全部放在返回结果
if(!root) return result;
traversal(root, path, result);
return result;
}
};
以上代码就难以看出来回溯,简洁代码传参的path需要使用string path,不能使用引用,否则无法达到回溯的效果;简洁代码中的回溯就隐藏在traversal(cur->left, path + “->”, result);中的 path + “->”。 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
我们可以将简洁代码展开,只将path += "->"展开到函数无法达到回溯,因为我们使用的拷贝赋值,而不是引用,因此需要将"->"分别pop_back()出来。
解释:
参数使用的是 string path,这里并没有加上引用& ,即本层递归中为path + 该节点数值,但该层递归结束,上一层path的数值并不会受到任何影响。
vector<int>& path是会拷贝地址的,所以本层递归逻辑如果有path.push_back(cur->val); 就一定要有对应的 path.pop_back()
那为什么不去定义一个 string& path 这样的函数参数呢,然后也可能在递归函数中展现回溯的过程,但关键在于,path += to_string(cur->val); 每次是加上一个数字,这个数字如果是个位数,那好说,就调用一次path.pop_back(),但如果是 十位数,百位数,千位数呢? 百位数就要调用三次path.pop_back(),才能实现对应的回溯操作,这样代码实现就太冗余了。
所以第一个代码版本中才使用 vector 类型的path,这样能体现代码中回溯的操作。vector类型的path,不管每 路径收集的数字是几位数,总之一定是int,所以就一次 pop_back就可以。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void traversal(TreeNode* node, string path, vector<string>& result)
{
//中
path += to_string(node->val);
//终止条件
if(!node->left && !node->right)
{
result.push_back(path);
return;
}
//左
if(node->left)
{
path += "->";
traversal(node->left, path, result);
path.pop_back(); //回溯">"
path.pop_back(); //回溯"-"
}
//右
if(node->right)
{
path += "->";
traversal(node->right, path, result);
path.pop_back(); //回溯">"
path.pop_back(); //回溯"-"
}
}
vector<string> binaryTreePaths(TreeNode* root) {
string path; //存放一条路径
vector<string> result; //将路径全部放在返回结果
if(!root) return result;
traversal(root, path, result);
return result;
}
};
方式二:迭代
class Solution {
public:
vector<string> binaryTreePaths(TreeNode* root) {
stack<TreeNode*> treeSt;// 保存树的遍历节点
stack<string> pathSt; // 保存遍历路径的节点
vector<string> result; // 保存最终路径集合
if (root == NULL) return result;
treeSt.push(root);
pathSt.push(to_string(root->val));
while (!treeSt.empty()) {
TreeNode* node = treeSt.top(); treeSt.pop(); // 取出节点 中
string path = pathSt.top();pathSt.pop(); // 取出该节点对应的路径
if (node->left == NULL && node->right == NULL) { // 遇到叶子节点
result.push_back(path);
}
if (node->right) { // 右
treeSt.push(node->right);
pathSt.push(path + "->" + to_string(node->right->val));
}
if (node->left) { // 左
treeSt.push(node->left);
pathSt.push(path + "->" + to_string(node->left->val));
}
}
return result;
}
};
● Leetcode404 左叶子之和
题目链接:Leetcode404 左叶子之和
视频讲解:代码随想录|左叶子之和
题目描述:给定二叉树的根节点 root ,返回所有左叶子之和。
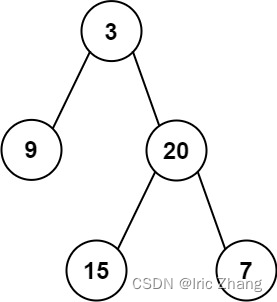
示例 1:
输入: root = [3,9,20,null,null,15,7]
输出: 24
解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
示例 2:
输入: root = [1]
输出: 0
● 解题思路
方法一:递归
(1)确定函数参数和返回值:
对于返回左叶子之和,返回值为整数int,传入参数为根结点即可;
(2)确定递归终止条件:
当传入结点为空或者传入结点为叶子结点的时候,就没有继续向下递归的必要;
(3)确定单层遍历逻辑:
我们首先需要明确遍历到哪?
如果我们遍历到叶子结点的时候,我们无法将叶子结点的值返回给其父结点,因此我们只需要遍历到其父结点,通过node->left->left(right)是否为空判断叶子结点即可。
因为我们需要将左右子树的左叶子之和返回给其父结点,因此需要先对左右遍历,然后在处理中时将左右子树的左叶子结点加和返回给自身即可,因此其单层遍历逻辑使用后序遍历。
方法二:迭代
对于迭代,使用前中后序均可。只需要判断是否为左叶子结点后将其值累加即可。
● 代码实现
方法一:递归
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
//终止条件
TreeNode* node = root;
if(!node) return 0;
if(!node->left && !node->right) return 0;
//左
int leftValue = sumOfLeftLeaves(node->left);
if(node->left && !node->left->left && !node->left->right)
{
leftValue = node->left->val;
}
//右
int rightVale = sumOfLeftLeaves(node->right);
//中
int sum = leftValue + rightVale;
return sum;
}
};
方法二:迭代
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
if(!root) return 0;
stack<TreeNode*> st;
int result = 0;
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top(); st.pop();
//中
if(node->left && !node->left->left && !node->left->right)
{
result += node->left->val;
}
//左
if(node->left) st.push(node->left);
//右
if(node->right) st.push(node->right);
}
return result;
}
};