GPDB - 高可用 - FTS机制(一):探测成功
作为GreenPlum高可用的核心功能,FTS(Fault Tolerance Server)进程负责故障检测。该进程是master上的一个子进程,可以快速检测到primary或者mirror是否宕机,并及时让primary/mirror进行故障切换。如果fts挂掉了,master还会再重新fork出一个。本文说说FTS的工作机制。
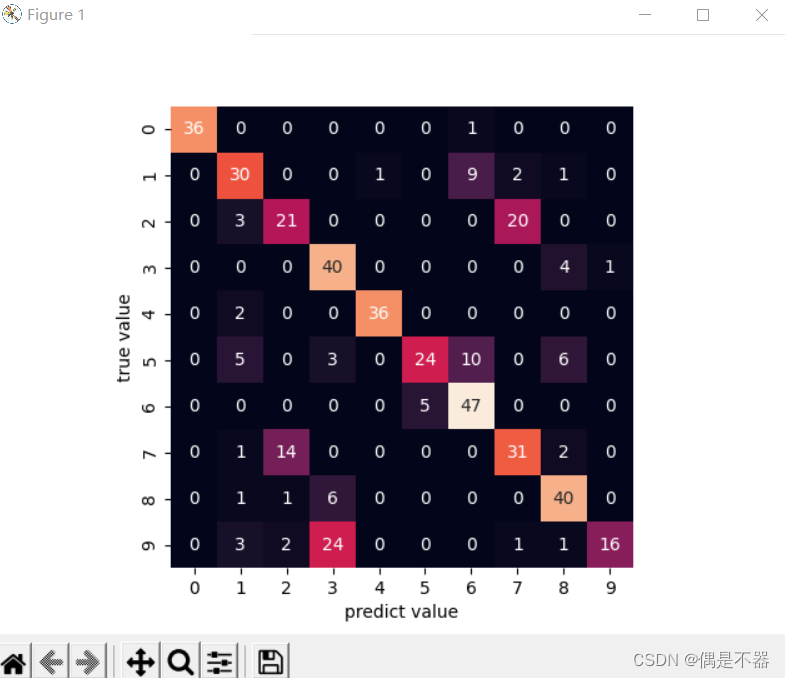
1、gp_segment_configuration
说起FTS,就不得不提下系统表gp_segment_configuration。该系统表存有集群segment的相关信息。
dbid | 唯一标识segment。Master为1,然后primary节点按照content递增;接着是mirror按照content递增;最后是standby master |
content | 数据库节点的标识ID,segment的primary和mirror相同。Master节点为-1,数据节点:0-N |
role | 节点当前的角色,primary或者mirror。p:表示primary,m:表示mirror |
preferred_role | 节点被定义的角色,primary或者mirror |
mode | 主备同步状态。s:表示已同步;n:表示不同步 Master总是n,standby master segment总是s,但并不表示他们之间的同步状态,使用gp_stat_replication来看他们之间是否同步 |
status | u:表示正常,d:表示节点down掉 |
port | 子节点的端口 |
hostname | 子节点所在机器的hostname |
address | 子节点所在机器的IP |
datadir | 实例的data目录 |
FTS probe进程,即master端探测进程探测集群状态时,向primary发送探测消息,消息内容格式为:"%s dbid=%d contid=%d",分别为:message_type、dbid、content。其中message_type为:
/* Queries for FTS messages */
#define FTS_MSG_PROBE "PROBE"
#define FTS_MSG_SYNCREP_OFF "SYNCREP_OFF"
#define FTS_MSG_PROMOTE "PROMOTE"2、FTS_PROBE_SUCCESS
FtsWalRepMessageSegments->FtsWalRepInitProbeContext在一个探测周期前初始化Probe内存上下文时将ftsInfo->state设置为FTS_PROBE_SEGMENT;当探测周期中ftsReceive接收到primary发来的探测信息后,表示探测成功,然后将状态改为FTS_PROBE_SUCCESS。然后processRetry根据反馈的信息决定是否进行重试。
3、primary接收到PROBE消息后的动作

FTS进程向primary的ftshandler进程发送PROBE探测消息,fts进程接收到消息后,由HandleFtsMessage进行处理:
1)进行校验,确保接收到正确的探测消息和本segment匹配以确定探测的primary就是它
2)通过HandleFtsWalRepProbe函数处理PROBE消息
3)HandleFtsWalRepProbe函数得到primary和mirror状态后,通过SendFtsResponse将状态FtsResponse发送给master端的fts进程
3.1 FtsResponse响应消息
typedef struct FtsResponse
{
bool IsMirrorUp;//mirror是否在线
bool IsInSync;//primary和mirror状态是否是流复制(sync)状态
bool IsSyncRepEnabled;//是否开启同步复制
bool IsRoleMirror;//角色是否是mirror
bool RequestRetry;//是否需要重试
} FtsResponse;3.2 FtsResponse响应消息的获取
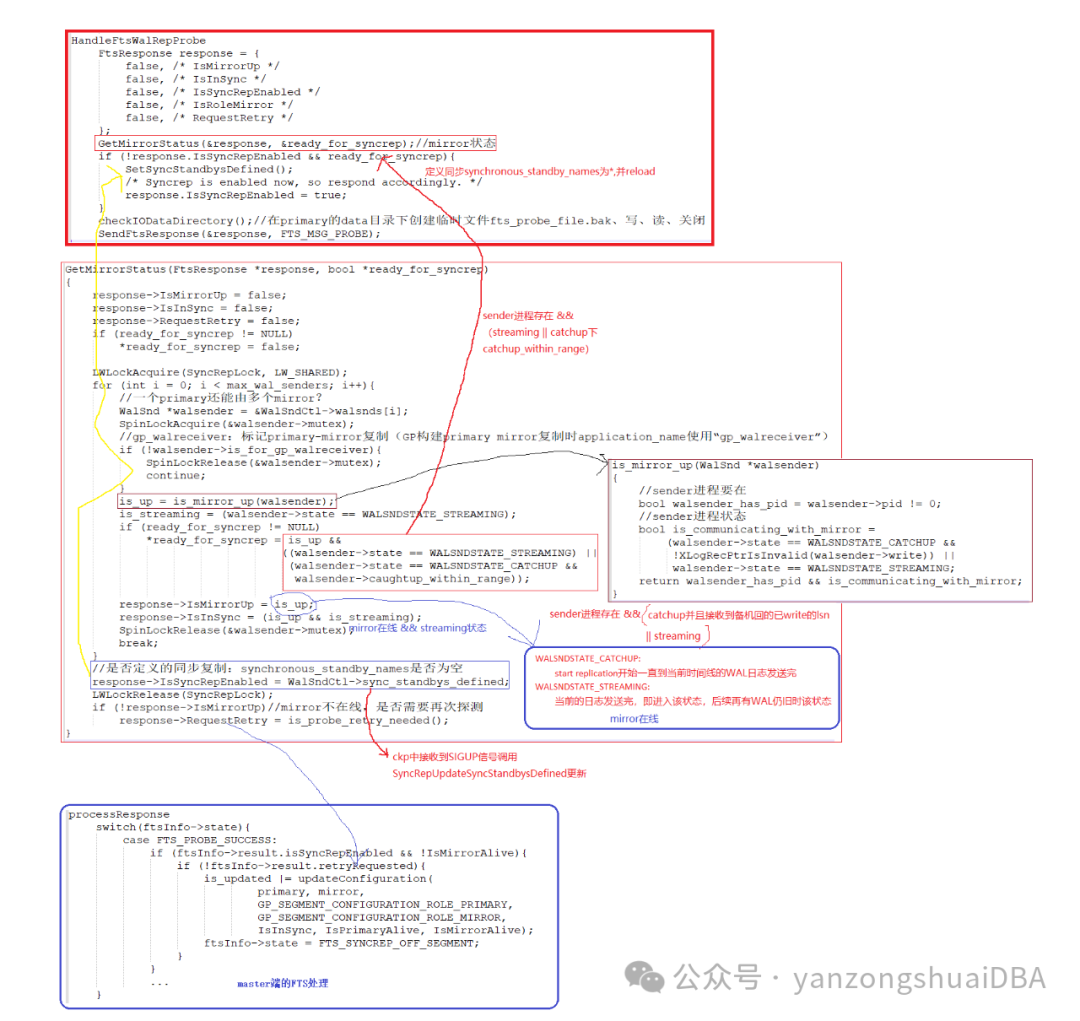
1)GetMirrorStatus获取mirror状态,即获取response的IsMirrorUp、IsInSync和RequestRetry的状态:
IsMirrorUp:sender进程在线,并且处于streaming状态或者catchup状态(接收到mirror回复已write的lsn位置)
IsInSync:IsMirrorUp并且处于streaming状态
RequestRetry:3.3节
IsSyncRepEnabled:是否定义了同步复制
2)IsMirrorUp并且sender处于streaming状态或caughtup_within_range状态,则HandleFtsWalRepProbe函数定义synchronous_standby_names为*即开启同步
3.3 FTSReplicationStatus
gp_replication.c在共享内存维护一个全局变量FTSRepStatusCtl来记录mirror是否一直处于crash重启状态,用于判断mirror状态为down时是否需要重试:
/*
* Each GPDB primary-mirror pair has a FTSReplicationStatus in shared memory.
*
* Mainly used to track replication process for FTS purpose.
*
* This struct is protected by its 'mutex' spinlock field. The walsender
* and FTS probe process will access this struct.
*/
typedef struct FTSReplicationStatus
{
NameData name; /* The slot's identifier, ie. the replicaton application name */
slock_t mutex; /* lock, on same cacheline as effective_xmin */
bool in_use; /* is this slot defined */
/*
* For GPDB FTS purpose, if the the primary, mirror replication keeps crash
* continuously and attempt to create replication connection too many times,
* FTS should mark the mirror down.
* If the connection established, clear the attempt count to 0.
* See more details in FTSGetReplicationDisconnectTime.
*/
uint32 con_attempt_count;
/*
* Records time, either during initialization or due to disconnection.
* This helps to detect time passed since mirror didn't connect.
*/
pg_time_t replica_disconnected_at;
} FTSReplicationStatus;
typedef struct FTSReplicationStatusCtlData
{
/*
* This array should be declared [FLEXIBLE_ARRAY_MEMBER], but for some
* reason you can't do that in an otherwise-empty struct.
*/
FTSReplicationStatus replications[1];
} FTSReplicationStatusCtlData;
extern FTSReplicationStatusCtlData *FTSRepStatusCtl;con_attempt_count和replica_disconnected_at的意义:
1)sender进程退出时标记con_attempt_count+1,replica_disconnected_at当前时间
WalSndKill:sender进程退出时标记
if (MyWalSnd->is_for_gp_walreceiver)
FTSReplicationStatusMarkDisconnectForReplication(application_name);
|-- replication_status = RetrieveFTSReplicationStatus(app_name, true);
|-- FTSReplicationStatusMarkDisconnect(replication_status);
|-- replication_status->con_attempt_count += 1;
|-- replication_status->replica_disconnected_at = (pg_time_t) time(NULL);2)FTSReplicationStatusUpdateForWalState更新状态时
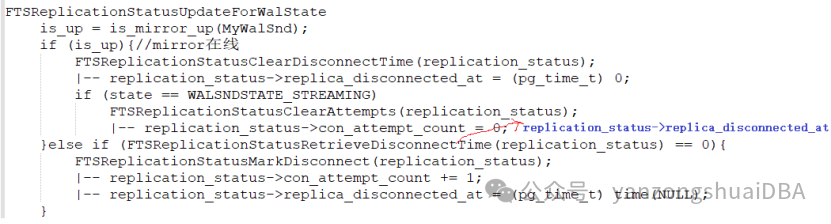
1)Sender进程退出时con_attempt_count+1,replica_disconnected_at为退出时时间;
2)再次构建复制连接后,mirror起来了,将replica_disconnected_at置为0,但此时还未到达streaming状态,此时sender进程又挂掉了:con_attempt_count再+1
3)多次没有到达streaming状态就又挂掉了,持续处于重启状态,那么con_attempt_count值就会大于1,也就是说conn_attempt_count表示在达到streaming状态前,建立复制连接的次数;replica_disconnected_at表示最近一次断开连接时的时间,到streaming状态后就置为0了。
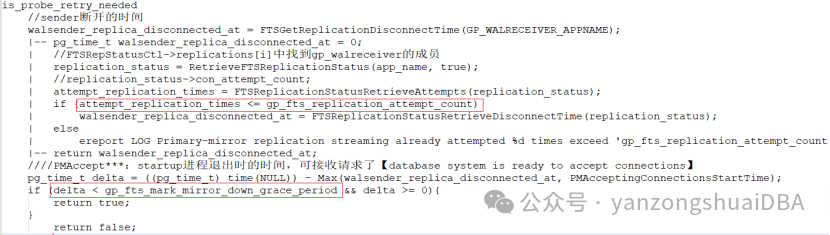
正常情况deta不可能为负数,因为is_probe_retry_needed函数执行时的时间是实时获取,此时断开时间:要么已断开得到时间,要么还没断开。为负数只能是deta1或者deta2太久远了,导致数据类型溢出,那么此时可能是超过gp_fts_mark_mirror_down_grace_period值的。
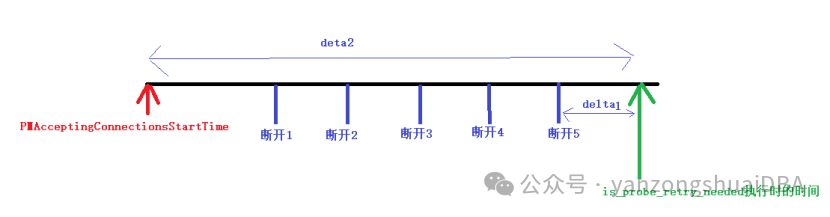
Primary端is_probe_retry_needed判断:
1)到达streaming状态前重启次数<=gp_fts_replication_attempt_count时,此时距上次断开的时间deta1 <= gp_fts_mark_mirror_down_grace_period则需要重试;否则不重试,反馈master后标记mirror down。
2)到达streaming状态前重启次数>gp_fts_replication_attempt_count时(重启次数太多了,需要看此时距离最开始的时间),此时距离接收连接时过了deta2时间 <= gp_fts_mark_mirror_down_grace_period则需要重试;否则不重试,反馈master后标记mirror down
3)Master端fts进程接收探测反馈后:若不在重试,则更新gp_segment_configuration系统表,标记mirror down
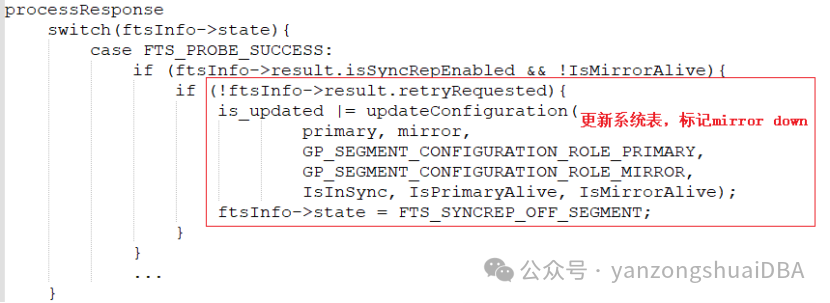
3.4 repl_catchup_within_range
默认1。对于Greenplum数据库主镜像,控制活跃从节点的更新。 如果walsender尚未处理的WAL段文件数超过此值,Greenplum数据库将更新活跃从节点。如果段文件的数量不超过该值,则Greenplum数据库会阻止更新,以允许walsender处理文件。 如果已处理所有WAL段,则更新活动主站

1)XLogSendPhysical发送WAL日志发送后WalSndIsCatchupWithinRange判断是否追上:若当前已sync到磁盘的WAL所在文件号 - 当前已发送的WAL所在段文件号 > repl_catchup_within_range,则WalSndCaughtUpWithinRange为false,否则为true。
2)发送完,若WalSndCaughtUpWithinRange为true(认为在这个范围上追上),WalSndSetCaughtupWithinRange将walsnd->caughtup_within_range设置为true
3)如何做到段文件的数量不超过该值(范围内追上),则Greenplum数据库会阻止更新?返回第3.2节开头的图示:ready_for_syncrep为true,定义为同步复制,那么就需要mirror同步到mirror返回primary后才可更新。也就是说,repl_catchup_within_range变量和primary和mirror的同步复制有关