随着LLMs的发展,其支持的上下文长度越来越长。仅一年时间,GPT-4就从一开始的4K、8K拓展到了128k。
128k什么概念?相当于一本300页厚的书。这是当初只支持512个tokens的BERT时代不敢想象的事情。

随着上下文窗口长度的增加,可以提供更丰富的语义信息,从而减少LLM的出错率和“幻觉”发生的可能性,提升用户体验。
但现有的构建长上下文LLMs的工作主要集中在上下文扩展方面,即位置编码扩展和长文本的持续训练。
而清华团队转而关注长上下文对齐的角度,即指令微调LLMs处理长文本提示,提供了一种全面的方法——LongAlign。
瞄准上下文对齐中缺乏长指令跟随数据集、训练效率低下以及缺乏强大的评估基准等挑战,作者构建了多样化的长指令数据集、采用了高效的训练策略,以及开发针对长上下文指令跟随能力的评估基准LongAlign-chat。
实验结果显示,LongAlign在长上下文任务中的表现显著优于现有方法,提升幅度高达30%。不仅如此,LongAlign还保持了模型在处理短、通用任务的能力,没有出现性能退化。
论文标题:
LongAlign: A Recipe for Long Context Alignment of Large Language Models
论文链接为:
https://arxiv.org/pdf/2401.18058.pdf
GitHub链接为:
https:github.com/THUDM/LongAlign
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
LongAlign方法概述
大型语言模型需要有效地处理长上下文,这要求在类似长度的输入序列上进行指令微调。为了解决这一问题,作者提出了LongAlign——一种针对长上下文对齐的数据、训练和评估基准。
1. 数据集构建:多源长文本数据的采集与自指导生成
长指令数据通常涉及大量的上下文材料,例如书籍、广泛的文件或冗长的代码,配以需要根据材料进行总结、推理或计算的任务查询。
因此作者首先从9个不同的来源收集长篇文章和文件,包括书籍、百科全书、学术论文、代码等。然后,使用Claude 2.1根据给定的长篇背景生成任务和答案。为了创造多样化的生成任务,还在提示中加入了任务类型描述,例如总结、信息抽取、推理等查询。因此最终的提示包括长篇文档和任务类型的提示,如下图所示:

最终为10,000个冗长的文本创造了任务和答案,其中10%为中文。这些数据的长度范围为8,000到64,000,由于汉字的压缩率较高,作者使用ChatGLM tokenizer进行测量。
2. 训练策略:打包策略与排序批处理的应用
为了确保模型在SFT后仍能处理长文本和短文本(具有一般能力),作者将长指令数据与一般指令数据集混合训练。但由于短数据太多而长数据相对较少,形成长尾分布。如下图左边部分所示,大多数数据长度在0-8k范围内,其余数据在8k-64k长度区间中分布相对均匀。

在这种分布下,在训练过程中,一个数据批次通常含有大部分短文本,但也包括一些较长的文本,需要更多的计算时间,导致相当长的空闲时间。因此作者采用了打包策略和排序批处理策略来提高多GPU训练环境下的训练效率。
打包策略
通过将不同长度的数据拼接在一起,直到达到最大长度,然后将打包好的数据分批处理。如图 3右上所示,这种方法有效地减少了每个批次中的空闲时间。
但是打包策略会导致偏向于较长序列和包含更多目标标记的序列。
考虑到将个序列打包到一个由个打包组成的批次中,第个打包包含索引为的序列,则满足。设表示第i个序列中个目标标记的总损失总和。如果每个序列权重相等,则损失应该为:
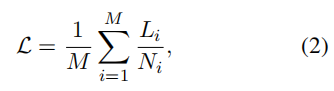
在装箱条件下计算的损失是:
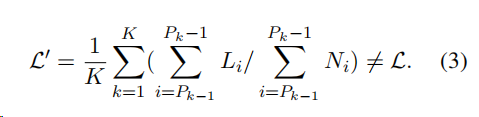
相对于公式2,公式3相当于在损失中为序列分配权重即偏向于具有更多目标标记和较小包的序列。
为了平衡打包训练中不同序列对损失的贡献,作者还提出了一种损失加权方法。通过来缩放第i个序列的损失,并将缩放后的损失在每个包上求和,而损失值不变:
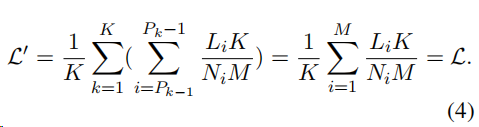
有序批处理
为了确保每个批次中的序列长度相似,作者使用长度对数据进行排序,并为每个批次选择一组连 续但不重复的数据,如上图右下角所示。该方法将长度相似的序列分组,以减少批内空闲时间。
3. 新的长上下文评估基准:LongBench-Chat
现有的评估LLMs的长上下文理解能力的基准并不侧重于评估其在长上下文下遵循指令的能力。
为此,作者开发了LongBench-Chat基准,包括50个长上下文真实世界查询, 长度从10k到100k不等,涵盖各种关键用户密集型场景,如文档问答、摘要和编码。其中40个任务为英文,10个任务为中文。
本基准由博士生注释,使用GPT-4作为评分器根据注释的真实结果和少样本评分示例对机器生成的回答进行评分。
GPT-4评估可靠吗?
为了验证使用GPT-4作为评估器的可靠性,作者计算了多名人类专家判断与机器评估之间的相关性,如下表所示:
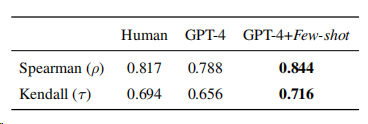
在少样本提示的情况下,GPT-4与人类标注的关联不仅一致,而且超过了标注者之间的一致性,证明了这种指标在LongBench-Chat上的可靠性。
另外使用GPT-4+少样本获得的总体平均分与人类专家给出的分数平均相差不到0.1。
对于GPT-4的评分对回答长度存在显著偏差的担忧并不存在,它甚至会给过长的回答进行惩罚。
其他大模型在LongBench-Chat基准上的表现
作者报告了当前长上下文 (16k+)微调模型(对话模型)在LongBench-Chat测试结果,模型包含API商业模型以及开源模型,如下图所示:
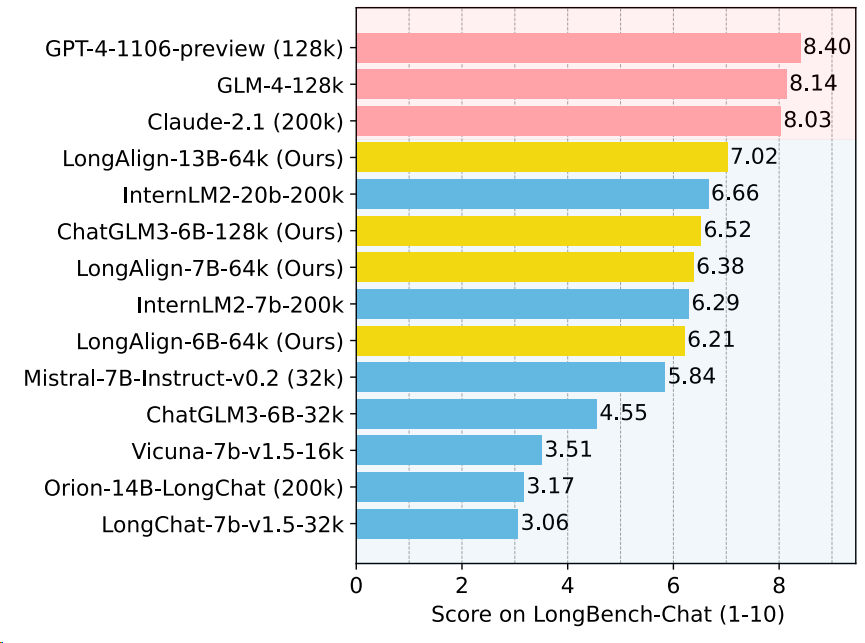
结果显示,当前开源模型的性能仍然明显落后于商业模型,这些模型之间的规模差异也是造成这种差距的一大原因。此外,长度不超过32k的模型在LongBench-Chat上表现较差,表明完成长任务需要更长的上下文窗口。
而作者提出的使用LongAlign训练的模型LongAlign-13B-64k打败了大部分开源模型,仅次于几个商业模型。
实验设计
作者从三个方面验证LongAlign方法的有效性:
-
数据量与多样性对长文本任务性能的影响
-
长指令数据对短文本处理能力的影响
-
训练策略对模型性能的具体贡献
数据
训练数据中短指令数据使用ShareGPT,长指令数据包括4个:LongAlign-0k、LongAlign-5k和LongAlign-10k,根据上文提到的数据构建过程构建的0个、5,000个和10,000个LongAlign数据;而LongAlpaca-12k则来自LongAlpaca数据集中的12,000个数据。
基础模型
基础模型选用ChatGLM3-6B、Llama-2-7B和Llama-2-13B,考虑到它们的8,000和4,000的上下文窗口,作者进行上下文扩展,将它们的上下文窗口扩展到64,000,得到ChatGLM3-6B-64k,Llama-2-7B-64k和Llama-2-13B-64k。
评估基准
对于长文本任务,使用本文提出的LongBench-Chat来评估模型的长文本对齐能力,并选用LongBench中的单文档问答、多文档问答和摘要生成几项任务来测试模型的长文本理解能力。
由于对齐模型通常会产生较长的回答,作者不使用原始指标(ROUGE、F1)来评分模型的回答,而是使用GPT-4根据其与LongBench上的真实答案的对齐程度对模型的输出进行评分。
对于短文本任务,使用MT-Bench多轮对话基准测试,来衡量模型遵循短指令的能力。
实验结果与讨论
1. 数据的影响
更多的长指令数据提高了长任务的性能,而不会损害短任务的性能

▲ChatGLM3-6B-64k在训练不同数量和类型的长指令数据后的性能。
如上表所示,通过比较LongAlign-0k、LongAlign-5k和LongAlign-10k的性能,随着长指令数据量的增加,模型在所有长任务上的表现都有所提升。
而模型在短任务上的性能并未因长指令的增加而改变,与仅在短指令上训练时相当。
此外,LongAlign-0k在长任务中的表现不佳,这表明仅对基础模型进行上下文扩展并不足以保证在下游长任务中获得良好性能。在SFT过程中,需要加入大量涵盖不同长度的长数据。
除此之外,作者还进行了“大海捞针”实验,以测试模型在长为1k-60k的不同长度长文本上信息提取的能力。如下图所示
大海捞针(Needle in A HayStack):通过将关键信息随机插入一段长文本的不同位置,形成LLM的Prompt,测试大模型是否能从长文本中提取出关键信息。
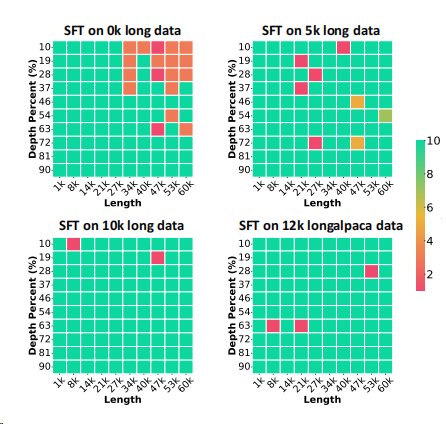
▲试Chat-GLM3-6B-64k在不同组合的长数据与ShareGPT混合训练下的性能
结果显示,更多的长数据增强了模型对长文本中不同位置的信息利用能力,从而降低了模型的检索错误。
多样的长指令数据有助于提高模型的遵循指令能力
LongAlign-10k在长指令和短指令任务上表现更佳,优于LongAlpaca-12k,尤其在LongBench-Chat和MTBench上,说明多样的长指令数据有助于提高模型的遵循指令能力。
然而,在LongBench其他任务上,LongAlpaca-12k略胜一筹。这主要是因为LongAlpaca-12k在2WikiMQA和NarrativeQA数据集上的表现更佳,这些数据集与LongAlpaca-12k的指令数据来源相似。
2. 训练策略对模型性能的具体贡献
作者分别比较了朴素方法打包、有序批处理的训练效率和下游任务效果。如下图和表所示:

▲不同训练方法下在8个A800 80G的GPU上的训练时间(小时)
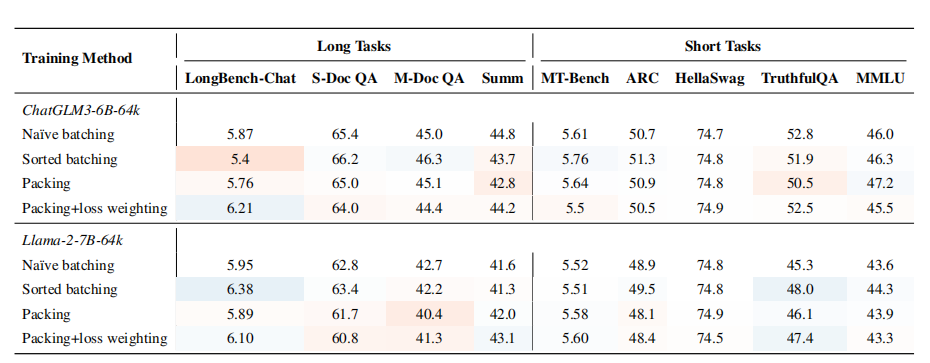
▲ChatGLM3-6B-64k和Llama-2-7B-64k在不同的训练方法下的表现
-
打包和有序批处理使训练效率提高一倍。
-
使用这两种高效方法训练的模型在长任务和短任务上的表现与朴素批处理的训练相当。
-
这两种训练方法的效果因不同的模型而异。例如,使用打包+损失加权训练的ChatGLM3-6B模型在LongBench-Chat上显示出显著更好的性能,而对于Llama-2-7B,排序批处理表现最佳。
-
在打包训练中加入损失加权策略在LongBench-Chat上的表现能力可以提高5%至10%。然而对其他任务的性能影响微乎其微且不稳定。
作者认为,这主要是因为在没有使用损失加权的情况下,不同长度的指令数据对损失的贡献存在差异。较长的数据往往对损失贡献更大。这种不自然的加权偏差可能对模型训练产生不利影响,导致训练不稳定,偏离最佳学习轨迹。
3. LongAlign的可扩展性
作者还探索了在LongAlign框架上的两个扩展方向:更大的模型大小和更长的上下文窗口。如下表所示:

与7B规模的模型相比,13B模型在LongBench-Chat任务上显示出了10%的改进,创造了开源模型的新记录。这表明该对齐方法能够有效地扩展到更大规模的模型。
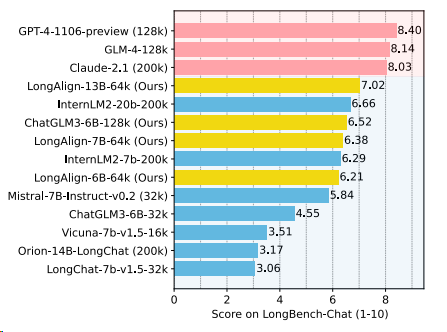
▲排行榜
作者还使用人工标注构建了长度达到128k的SFT数据, 并成功地使用打包训练与损失加权对ChatGLM3-6B模型在128k上下文窗口下进行对齐,得到了ChatGLM3-6B-128k模型,相比32K模型,更长的上下文窗口显著提高模型的性能
结论
LongAlign提供了一种全面的方法来解决大型语言模型(LLM)在处理长上下文时的挑战。
通过构建多样化的长指令数据集、采用高效的训练策略,以及开发针对长上下文指令跟随能力的评估基准LongAlign-chat,LongAlign在长上下文任务中的表现显著优于现有方法,提升幅度高达30%。此外,LongAlign还保持了模型在处理短、通用任务的能力,没有出现性能退化。
LongAlign在长上下文对齐方面取得显著成果,但仍需面对数据集不全面和训练框架限制等挑战:
-
现有数据集主要涵盖问答、摘要和推理等类别,缺少对多轮对话、角色扮演等任务的覆盖,导致LLM在这些任务上的表现不佳。
-
未来研究需探索更先进的训练框架和强化学习微调方法,在更长序列和更大规模模型上的长上下文对齐。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!