水善利万物而不争,处众人之所恶,故几于道💦
文章目录
- 概念
- 注意:
- 应用
概念
因为RDD是可分区的,每个分区在不同的节点上运行,如果想要对某个值进行全局累加,就需要将每个task中的值取到然后进行累加,而各个Executor之间是不能相互读取对方数据的,所以就没办法在task里面进行最终累加结果的输出,所以就需要一个全局统一的变量来处理。
用下面的代码举例:
@Test
def test(): Unit = {
import org.apache.spark.{SparkConf, SparkContext}
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[4]")
val sc = new SparkContext(conf)
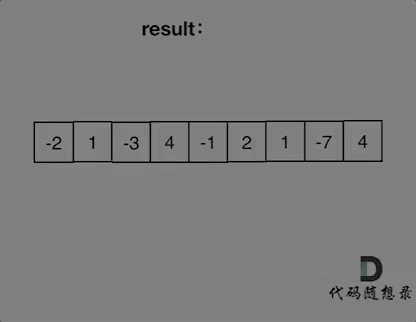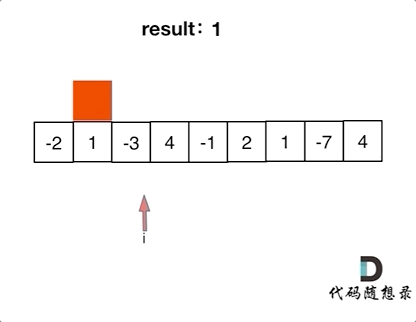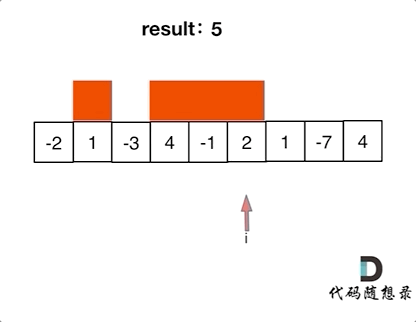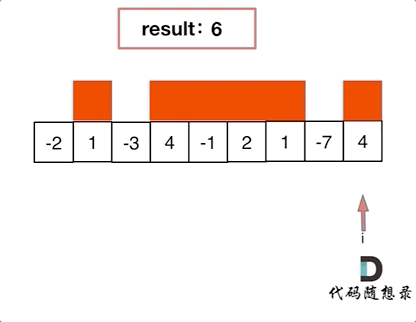
var sum = 0
val rdd = sc.parallelize(List(10,20,30,40,60))
rdd.foreach(x=>{
sum+=x
})
println(sum)
}
以上代码的输出结果是 0
分析:因为函数体外的代码是在Driver端执行的,函数体内的代码是在task里面执行的,而上述代码中创建sum变量是在Driver端创建的,函数体内的代码sum+=x是在task里面执行的,task里面对sum进行了累加,然后在Driver端打印sum的值,打印出来的还是Driver端sum的初始值0
以下代码是用累加器实现的相同功能
@Test
def test(): Unit = {
import org.apache.spark.{SparkConf, SparkContext}
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[4]")
val sc = new SparkContext(conf)
// 创建累加器从sparkContext中
val acc = sc.longAccumulator("sumAcc")
val rdd = sc.parallelize(List(10,20,30,40,60))
// rdd.foreach(x=>{
// sum+=x
// })
// 将要累加的变量放到累加器中
rdd.foreach(x=>{acc.add(x)})
// 打印累加器的值
println(acc.value)
}
上面代码的输出结果是160
分析:上述代码中从SparkContext中创建了longAccumulator累加器,起名为sumAcc,然后在task中执行累加的时候调用改累加器的add()方法将要累加的变量加入到累加器中,最后在driver端调用累加器的value方法取出累加器的值,所以就会得出160
总结:
累加器的创建:val acc = sc.longAccumulator(“sumAcc”)
向累加器中添加数据:acc.add(x)
取出累加器中的数据:acc.value
注意:
- Executor端不要获取累加器的值,那样取到的那个值不是累加器最终的累加结果,因为累加器是一个分布式共享的写变量
- 使用累加器时(也就是向累加器中添加要累加的变量的时候)要将其放在行动算子中。因为在行动算子中这个累加器的值可以保证绝对可靠,如果在转换算子中使用累加器,假如这个spark应用程序有多个job,每个job执行的时候都会执行一遍转换算子,那么这个累加器就会被累加多次,这个值也就不准确了。所以累加器要在行动算子中使用。
应用
累加器在某些场景下可以避免shuffle。spark中自带的累加器有三个longAccumulator()、doubleAccumulator()和collectionAccumulator[](),比较常用的是collectionAccumulator[]()
我们用累加器实现WordCount
下面是正常的WordCount代码:
def main(args: Array[String]): Unit = {
import org.apache.spark.{SparkConf, SparkContext}
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("datas/wc.txt")
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.map((_, 1))
rdd3.reduceByKey(_ + _).collect().foreach(println)
Thread.sleep(100000000)
}
结果:
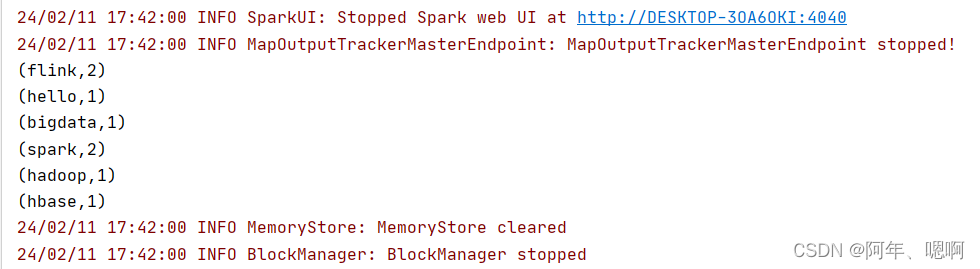 查看web页面:
查看web页面:
下面用collectionAccumulator[]()累加器实现,用累加器替换掉reduceByKey
def main(args: Array[String]): Unit = {
import org.apache.spark.{SparkConf, SparkContext}
val conf: SparkConf = new SparkConf().setAppName("SparkCoreStudy").setMaster("local[*]")
val sc = new SparkContext(conf)
// 定义集合累加器,并声明累加器中存放的元素类型 可变的map,可变就是可以直接在原来的集合上修改不会返回新的集合
val acc = sc.collectionAccumulator[mutable.Map[String,Int]]("accNum")
val rdd1 = sc.textFile("datas/wc.txt")
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.map((_, 1))
// rdd3.reduceByKey(_ + _).collect().foreach(println)
// 遍历每个二元元组
rdd3.foreachPartition(it=>{
// 定义一个map用来存放一个分区的累加结果
val resMap = mutable.Map[String,Int]()
// 遍历分区的每个元素(hadoop,1)
it.foreach(y=>{
// 从resMap中取这个元素的key看有没有,没有的话返回0
val num = resMap.getOrElse(y._1, 0)
// 将取到的数和元素的标记1累加
val num2 = num+y._2
// 写回到map中
resMap.put(y._1,num2)
})
// 将每个分区的累加结果添加到累加器中
acc.add(resMap)
})
// println(rdd4.collect())
// 在driver端取到累加器的结果,这个结果是Java类型的list
val res = acc.value
// 添加 scala.collection.JavaConverters._ 用里面的asScala将Java类型的list转为Scala类型
import scala.collection.JavaConverters._
val scalaList = res.asScala
// 将list里面的map压掉,剩下()元组
val flatten = scalaList.flatten
// 以元组的key分组
val grouped = flatten.groupBy(_._1)
// 得出每个分组内的次数和
val res_end = grouped.map(x => {
// 将元组中的第二个次数来一次map然后sum,取出每个单词的频率
val sum = x._2.map(y => y._2).sum
(x._1, sum)
})
res_end.foreach(println)
Thread.sleep(100000000)
}
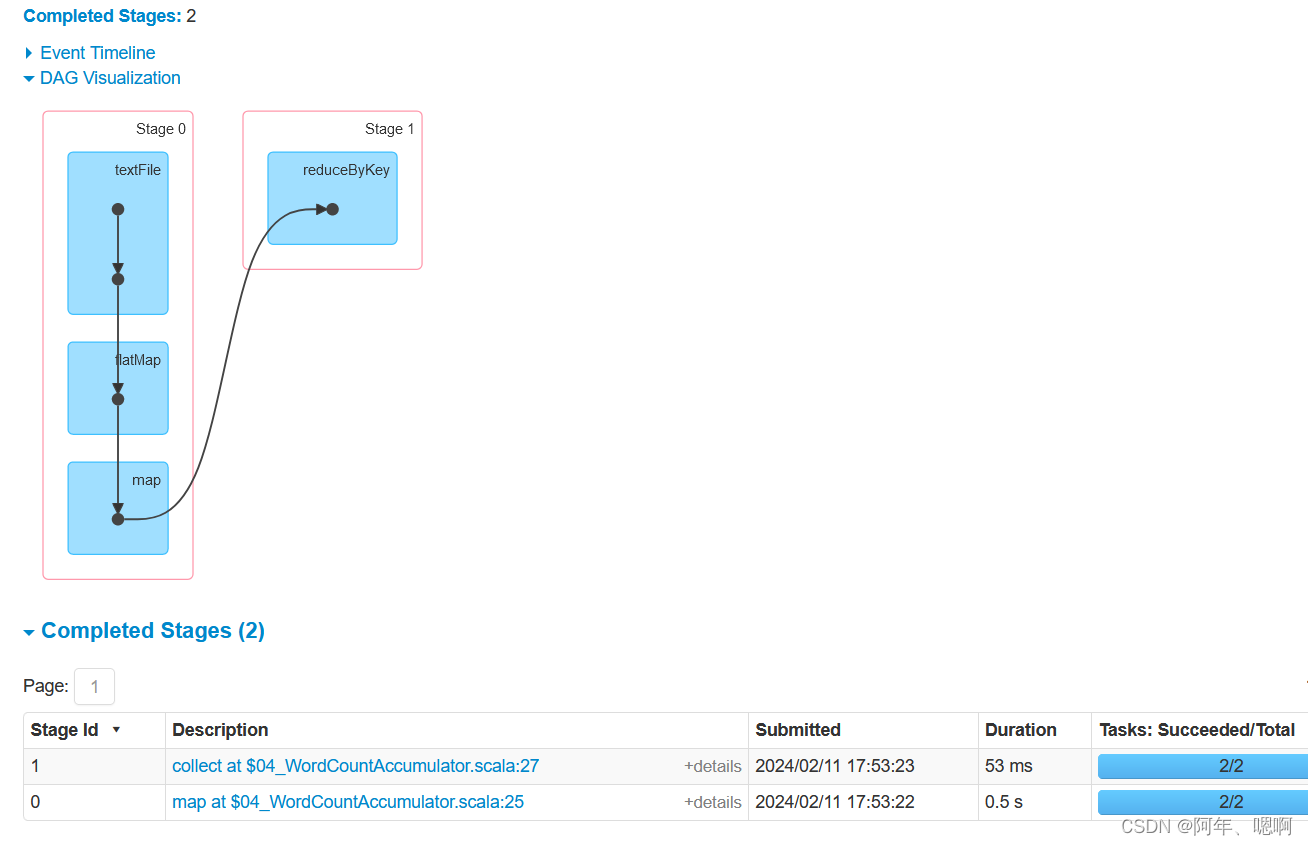
结果:
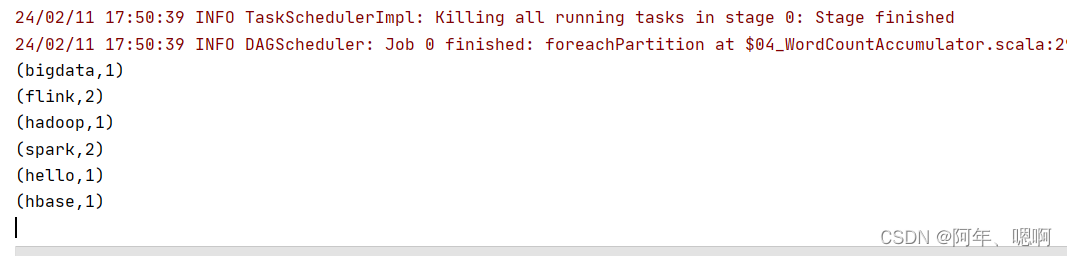 查看web页面:
查看web页面:
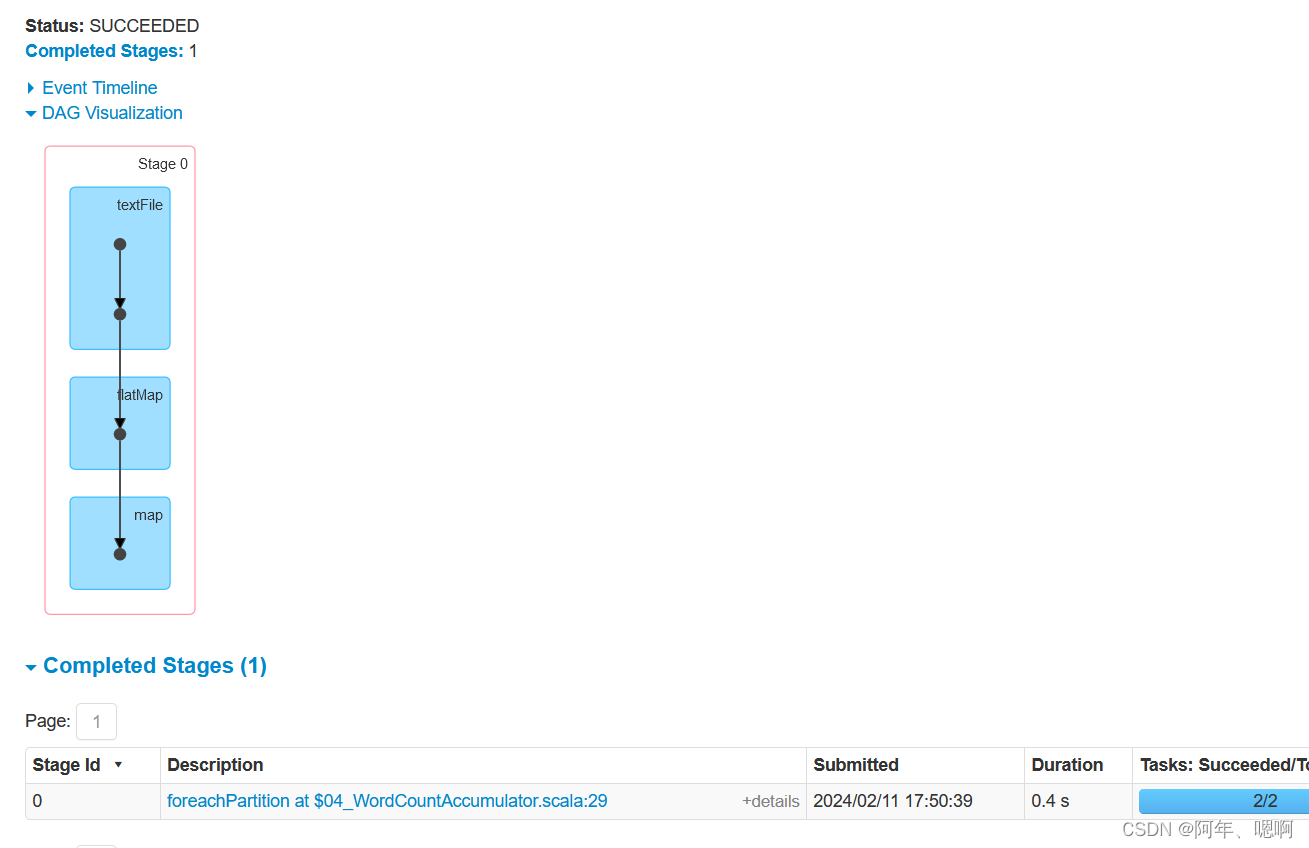
通过对比两次的web页面可以发现,使用reduceByKey会有一次shuffle,使用累加器替换掉reduceByKey实现相同的功能,没有产生shuffle,因此累加器在某些聚合场景下可以避免掉shuffle从而在一定程度上提高性能