近年来,人工智能模型的公平性问题受到了越来越多的关注,尤其是在医学领域,因为医学模型的公平性对人们的健康和生命至关重要。高质量的医学公平性数据集对促进公平学习研究非常必要。现有的医学公平性数据集都是针对分类任务的,而没有可用于医学分割的公平性数据集,但是医学分割与分类一样都是非常重要的医学AI任务,在某些场景分割甚至优于分类, 因为它能够提供待临床医生评估的器官异常的详细空间信息。
在本文中,我们提出了第一个用于医学分割的公平性数据集,名为Harvard-FairSeg,包含10,000个患者样本。此外,我们提出了一种公平的误差界限缩放方法,通过使用最新的Segment Anything Model(SAM),以每个身份组的上界误差为基础重新加权损失函数。为了促进公平比较,我们利用了一种新颖的评估公平性在分割任务的标准,叫做equity-scaled segmentation performance。通过全面的实验,我们证明了我们的方法要么具有优越性,要么与最先进的公平学习模型在公平性能上相当。
在这里和大家分享一波我们ICLR 2024中稿的工作 “Harvard FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling”
在本次工作中, 我们提出了第一个研究医疗分割算法的公平性的大型数据集 并且提出了方法尝试提升不同组别的公平性 (让不同组别的准确率接近)。

论文题目:
Harvard FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling
文章地址:
https://arxiv.org/abs/2311.02189
代码地址: GitHub - Harvard-Ophthalmology-AI-Lab/Harvard-FairSeg: [ICLR 24] Harvard FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling
数据集网站:
https://ophai.hms.harvard.edu/datasets/harvard-fairseg10k/
数据集下载链接:https://drive.google.com/drive/u/1/folders/1tyhEhYHR88gFkVzLkJI4gE1BoOHoHdWZ
Harvard-Ophthalmology-AI-Lab主页:
https://ophai.hms.harvard.edu/datasets (我们致力于提供高质量公平性数据集 更多公平性数据集 请点击Lab的数据集)
01. 背景
随着人工智能在医学影像诊断中的应用日益增多,确保这些深度学习模型的公平性并深入探究在复杂的现实世界情境中可能出现的隐藏偏见变得至关重要。遗憾的是,机器学习模型可能无意中包含了与医学图像相关的敏感属性(如种族和性别),这可能影响模型区分异常的能力。这一挑战促使人们在机器学习和计算机视觉领域进行了大量的努力,以调查偏见、倡导公平性,并推出新的数据集。
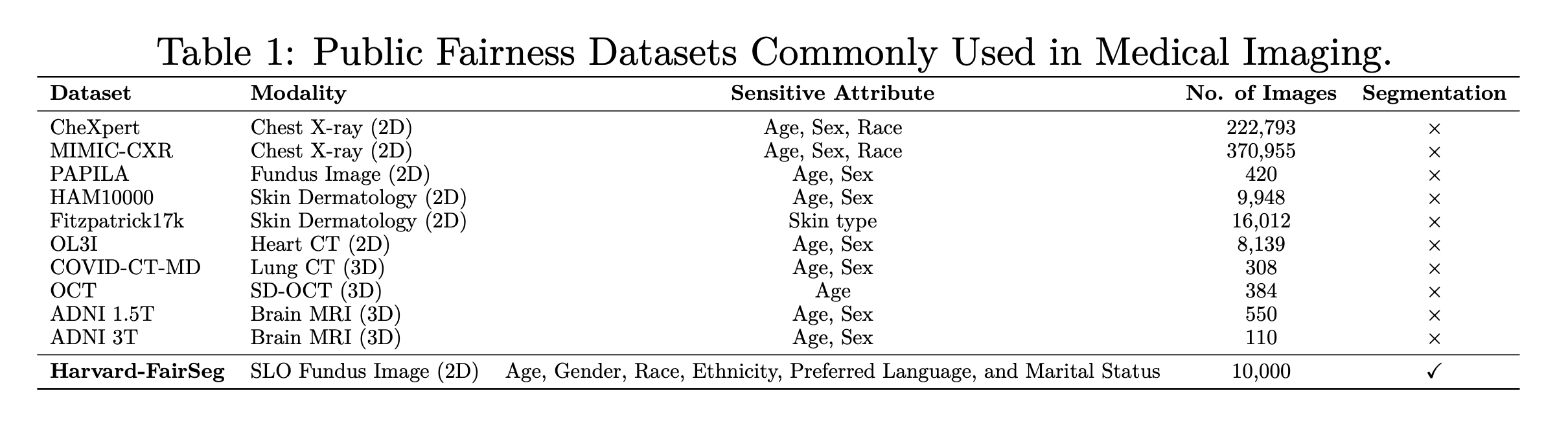
截至目前,只有少数公共公平性数据集被提出用于研究公平性分类,主要的是,这些数据集中的大多数都只是表格数据,因此不适合开发需要影像数据的公平计算机视觉模型。对计算机视觉公平性的缺失尤其令人关注,特别是考虑到依赖此类数据的深度学习模型的影响力日益增强。在医学影像领域,只有少数数据集被用于公平学习。然而,这些数据集大多没有专门为公平性建模而设计(目前仅有的医疗图像数据集我们列在了table 1)。它们通常只包含有限范围的敏感属性,如年龄、性别和种族,因此限制了检查不同人群公平性的范围。此外,它们也缺乏全面的基准测试框架。更重要的是,尽管这些先前的数据集和方法为医学分类提供了解决方案,但它们忽视了医学分割这一更为关键的领域。
然而,为公平学习创建这样一个新的大型数据集面临着多重挑战。首先,缺乏大规模、高质量的医学数据以及手工像素级注释,这些都需要大量劳动力和时间来收集和标注。其次,现有提升公平性的方法主要是为医学分类设计的,当适应分割任务时,其性能仍然存疑。同样不确定的是,分割任务中存在的不公平是否可以通过算法有效地缓解。最后,评估医学分割模型公平性的评判标准 (evaluation metric)仍然难以捉摸。此外,将现有为分类设计的公平性指标适应到分割任务上也可能存在挑战。
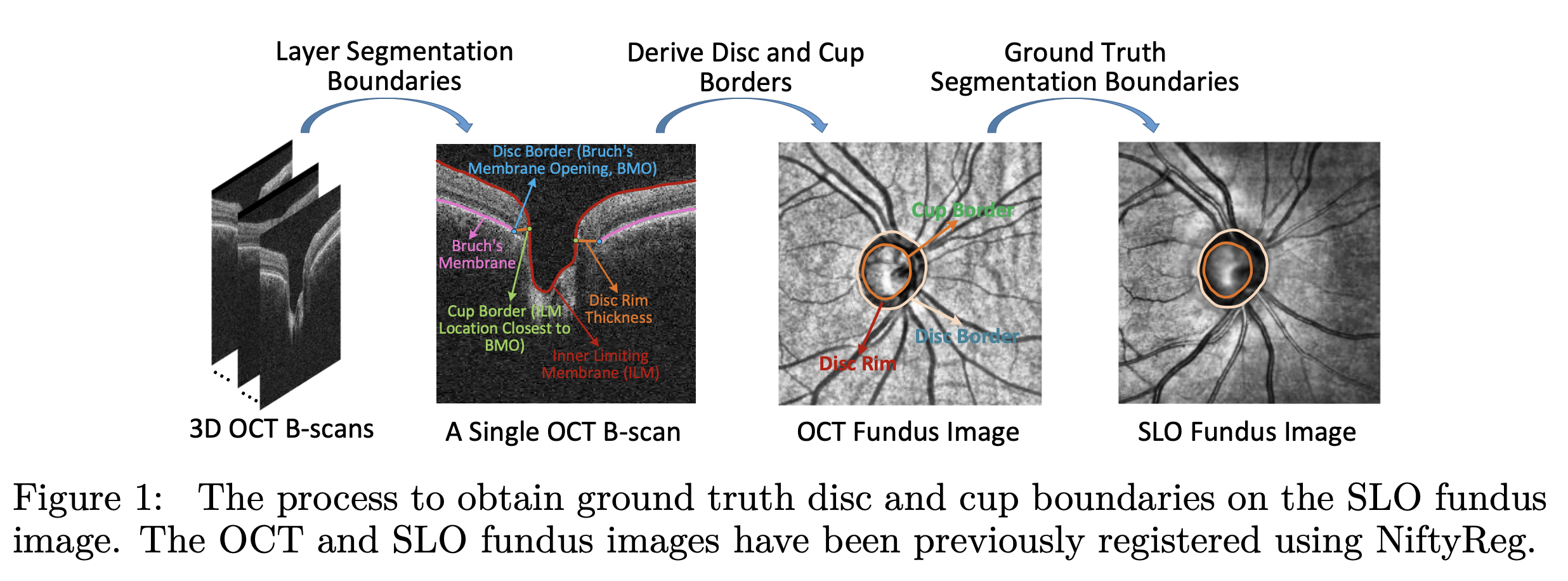
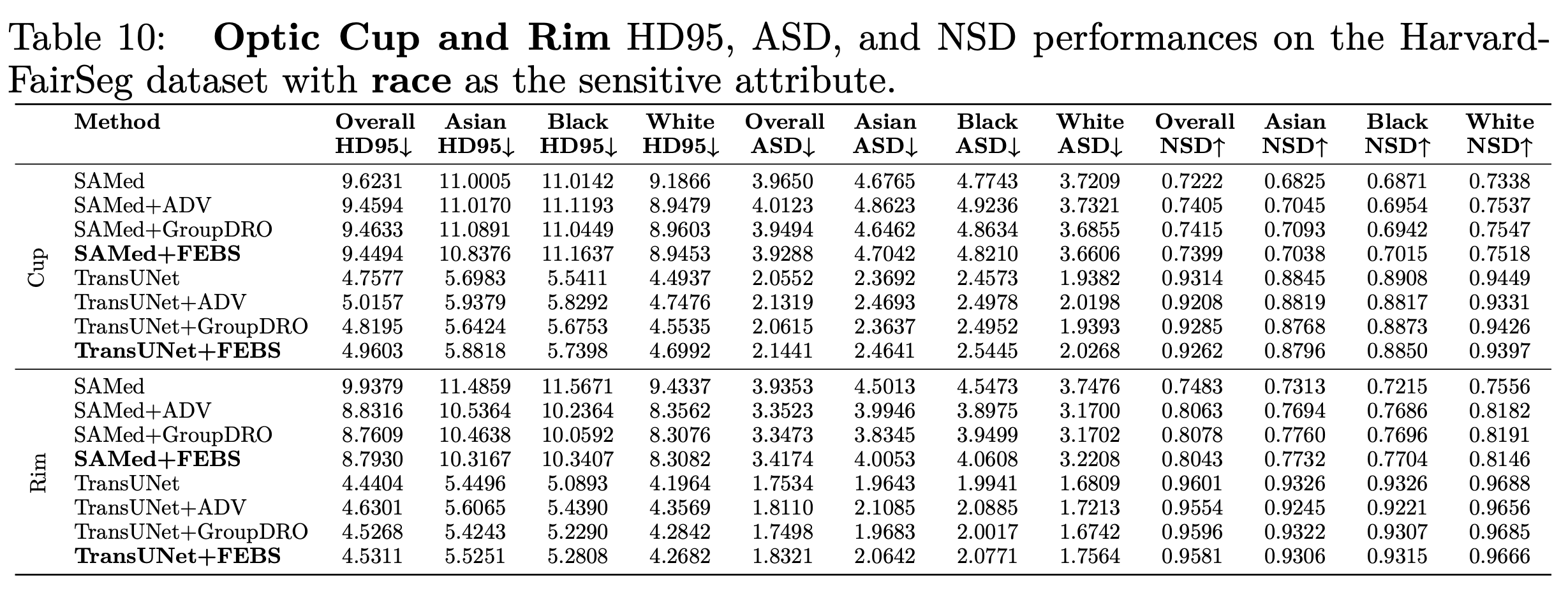
为了解决这些挑战,我们提出了第一个大规模医学分割领域的公平性数据集, Harvard-FairSeg。该数据集旨在用于研究公平性的cup-disc segmentation,从SLO眼底图像中诊断青光眼,如图1所示。青光眼是全球不可逆盲目的主要原因之一,在40-80岁年龄段的患病率为3.54%,大约影响了8000万人。尽管其重要性,早期青光眼通常无症状,这强调了及时进行专业检查的必要性。对cup-disc的准确分割对于医疗专业人员早期诊断青光眼至关重要。值得注意的是,与其他群体相比,黑人患青光眼的风险加倍,然而这一人群的分割准确率通常最低。
这激励我们整理一个数据集,以研究分割公平性问题我们提出的Harvard-FairSeg数据集的亮点如下:
(1)医学分割领域第一个公平性学习数据集。该数据集提供了SLO眼底成像数据的cup-disc分割;
(2)该数据集配备了从现实医院临床情景中收集的六种敏感属性,用于研究公平性学习问题;
(3)我们在我们提出的新数据集上评估了多个SOTA公平性学习算法,并使用包括Dice和IoU在内的多种分割性能指标进行了评估。
如何获得大量的高质量分割标注:
本研究中测试的对象来自于一家大型学术眼科医院,时间跨度为2010年至2021年。本研究将发布三种类型的数据:(1)SLO眼底扫描图像;(2)患者人口统计信息 包含了六种不同的属性;(3)由OCT机器自动标注以及由专业医疗从业者手工评级的像素级标注如何获得大量高质量分割标注一直是医疗分割的很重要分体。
我们新颖的通过把 cup 和disc区域的像素标注首先从OCT机器获得,其中disc边界在3D OCT中被分割为Bruch’s膜开口,由OCT制造商软件实现,cup边界被检测为内限膜(ILM)与导致最小表面积的平面之间的交叉点和disc边界在平面上的交叉点。大致上,cup边界可以被认为是ILM上最靠近视盘边界的位置,即被定义为Bruch’s膜开口。由于Bruch’s膜开口和内限膜与背景之间的高对比度,它们很容易被分割。因此因为OCT制造商软件利用了3D信息,利用oct机器对cup和disc的分割通常是可靠的。相比之下,眼底照片上的2Dcup和disc分割可能因包括衰减的成像信号和血管阻塞等各种因素而具有挑战性。
然而,由于OCT机器相当昂贵且在初级保健中较少见,因此我们提议将这些注释从3D OCT迁移到2D SLO眼底图片,以在初级保健领域的早期青光眼筛查中产生更广泛的影响。具体来说,我们首先使用NiftyReg工具将SLO眼底图像与OCT衍生的眼底图像(OCT眼底)对齐随后,将NiftyReg的仿射度量应用于OCT眼底图像的cup-disc掩码,使其与SLO眼底图像对齐。这一过程有效地产生了大量高质量的SLO眼底掩码注释,避免了劳动密集型的手工像素标注过程。
值得注意的是,这种medical registration的操作在现实世界场景中展示了相当高的精确度,我们的经验观察表明,medical registration成功率大约为80%。在这一自动化过程之后,生成的掩码经过严格审查,并由五名医学专业人员小组手动评级,以确保cup-disc区域的精确标注,并排除位置错误的cup或disc掩码和registration失败的情况。
数据特征:我们的Harvard-FairSeg数据集包含来自10,000名受试者的10,000个样本。我们将数据分为包含8,000个样本的训练集和包含2,000个样本的测试集。数据集的平均年龄为60.3 ± 16.5岁。在该数据集中,包含了六个敏感属性,用于深入的公平性学习研究,这些属性包括年龄、性别、种族、民族、首选语言和婚姻状况。在种族人口统计学上,数据集包括来自三个主要群体的样本:亚洲人,有919个样本;黑人,有1,473个样本;白人,有7,608个样本。在性别方面,女性占受试者的58.5%,其余为男性。民族分布以90.6%的非西班牙裔,3.7%的西班牙裔和5.7%的未说明。在首选语言方面,92.4%的受试者首选英语,1.5%首选西班牙语,1%首选其他语言,5.1%未确定。从婚姻状况的角度来看,57.7%的人已婚或有伴侣,27.1%是单身,6.8%经历过离婚,0.8%法律上分居,5.2%是丧偶,2.4%未说明。
我们的提升公平性的方法Fair Error-Bound Scaling:
我们假设获得较小整体Dice损失的样本组意味着模型对该特定组的样本学习得更好,因此,这些样本组需要较小的权重。相反,整体Dice损失较大的样本组(即难处理的案例)可能导致更差的泛化能力并引起更多的算法偏差,这需要为这些样本组分配较大的学习权重。因此,我们提出了一种新的公平误差界限缩放方法,用于在训练过程中缩放不同人群组之间的Dice损失。我们首先定义预测像素得分和真实目标之间的标准Dice损失表示为:
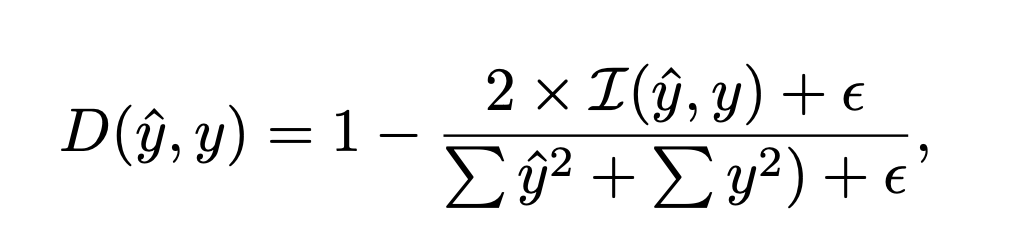
为了确保在不同属性组之间的公平性,我们使用一种新颖的公平误差界限缩放机制来增强上述Dice损失。损失函数:
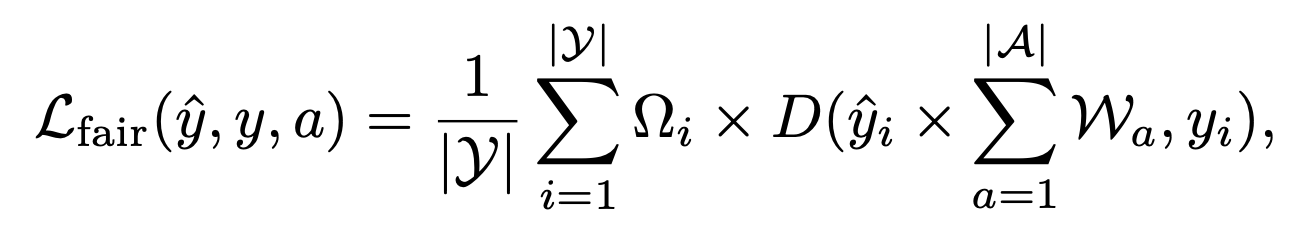
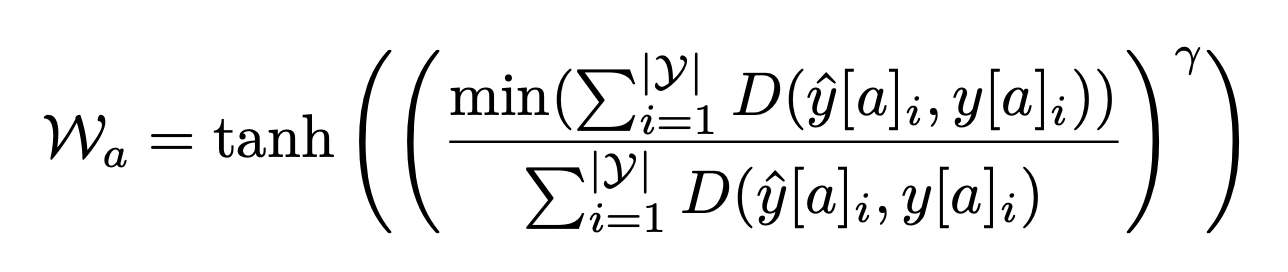
通过用这些属性权重调节预测像素得分,这种损失确保不同属性组在模型训练过程中平衡地贡献于损失函数,从而促进公平性。
用于评估公平分割准确性的metric:传统的分割度量如Dice和IoU提供了对分割性能的洞察,但可能无法有效捕捉不同群体间的公平性。考虑到这一点,我们的目标是提出一种新的metric,既包括分割的准确性,也包括在不同群体间的公平性。这就产生了一个全面的视角,确保模型既准确又公平。


02. 实验
我们选择了两个分割网络作为backbone 。其中,我们选择了最近推出的分割大模型 Segment Anything Model (SAM) 来实验SOTA的分割准确性,另一个backbone我们选择了TransUNet。
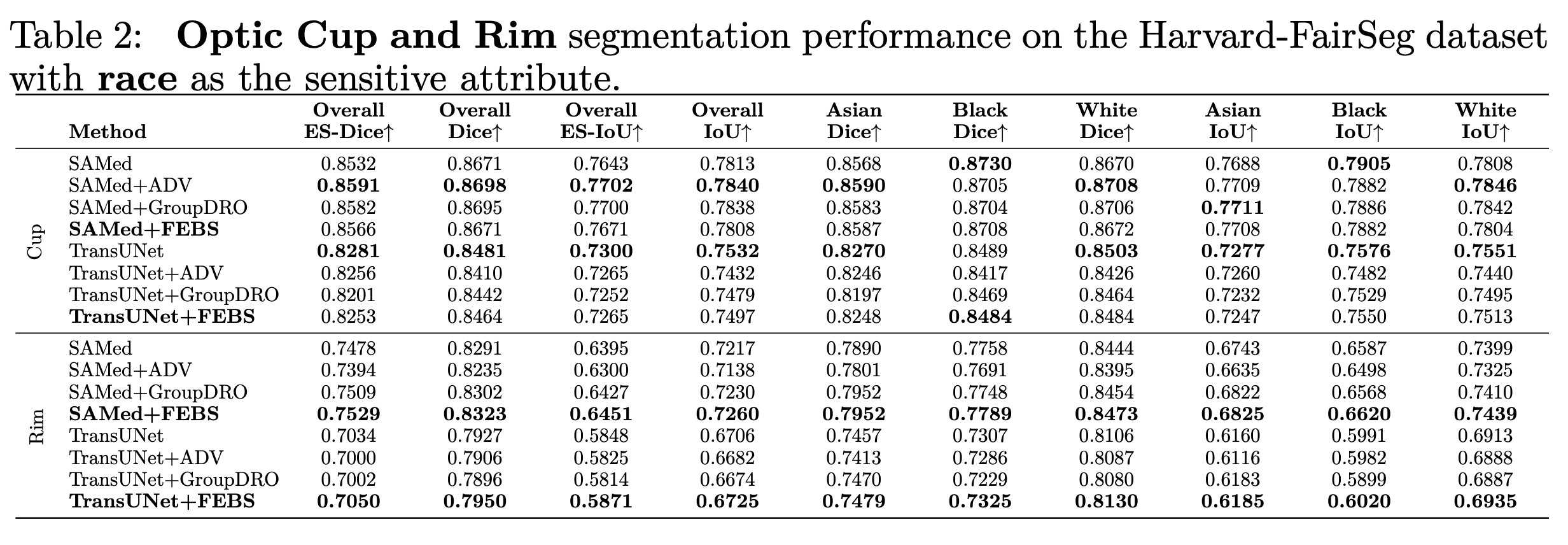
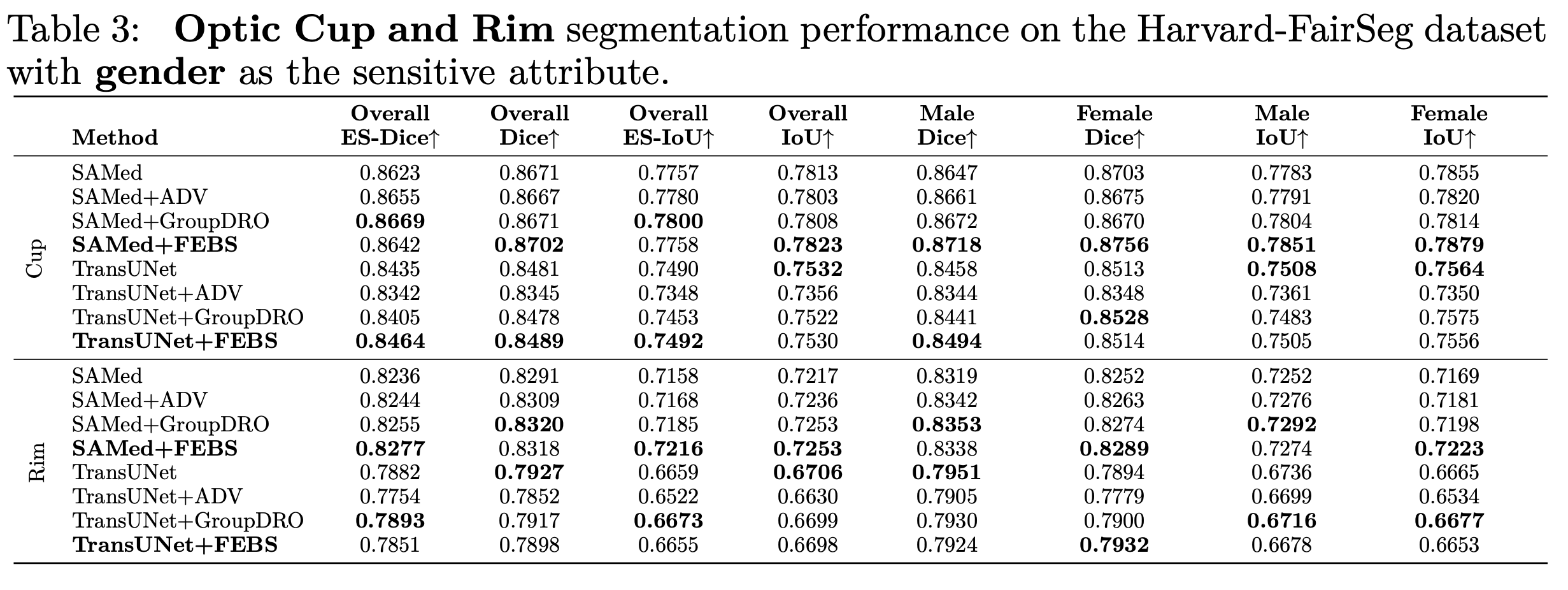
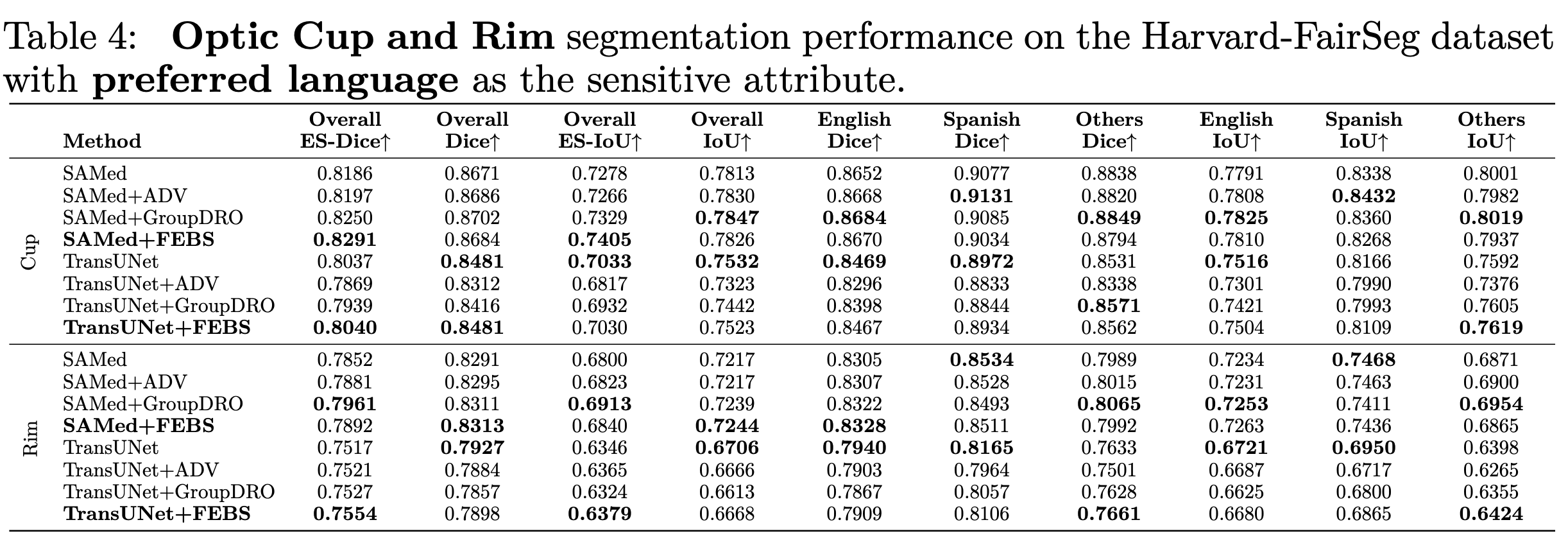
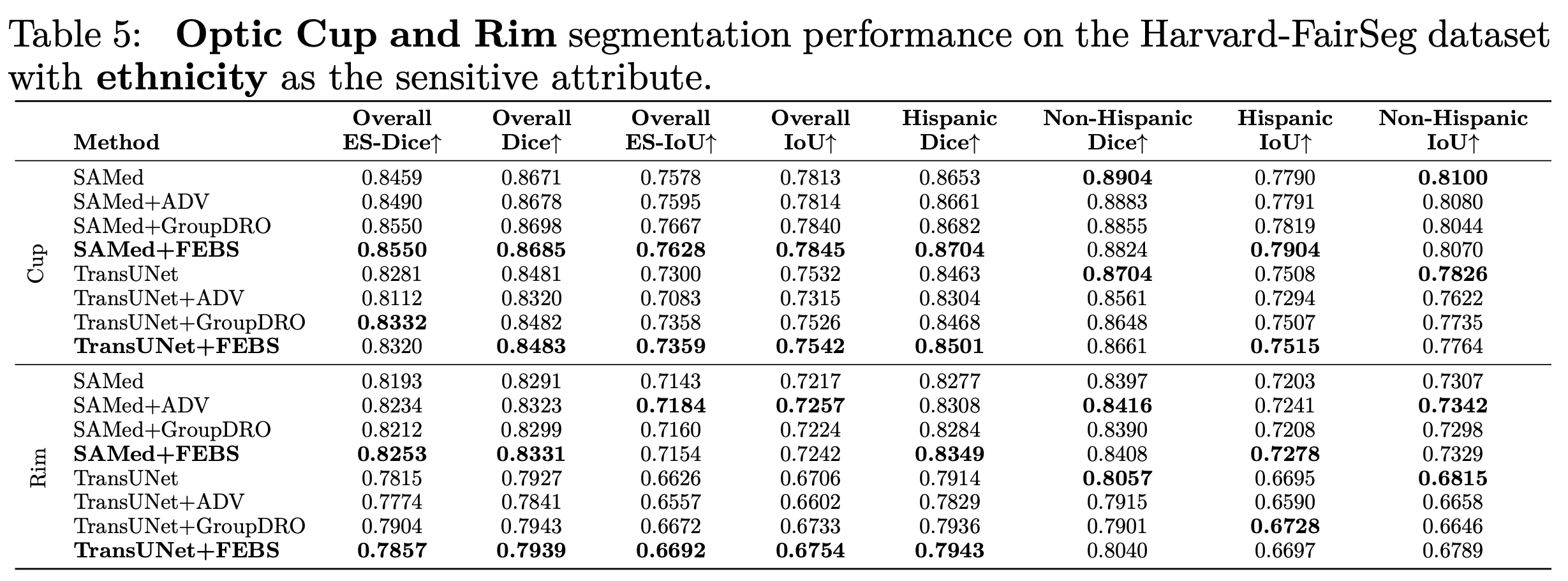
我们也利用了其他分割的metric例如 HD95 ASD 和NSD进行测试,下面是在种族上的结果:
03. 总结
在本次工作中, 我们提出了第一个研究医疗分割算法的公平性的大型数据集 并且提出了方法尝试提升不同组别的公平性。尽管如此, 通过实验我们仍然发现不同组别直接的分割准确性差异仍然存在。 未来希望通过我们和整个机器学习社区的共同努力, 能够提升弱势组别的准确性,而达到真正的分割公平性, 使得医疗分割模型能更好的部署在真实的医疗场景中。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区