🎉🎉欢迎光临🎉🎉
🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀
🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:底层原理高级进阶》 🚀
本专栏纯属为爱发电永久免费!!!
这是苏泽的个人主页可以看到我其他的内容哦👇👇
努力的苏泽
http://suzee.blog.csdn.net/
在我的开发经历中,我曾经面对过一个常见的问题:应用程序的性能问题。当时,我开发的系统面临着大量的数据库查询操作,每次请求都需要执行耗时的数据库查询,导致系统响应变慢。为了解决这个问题,我开始研究缓存的重要性和在应用程序中的作用。
很多伙伴在问 为什么不用Redis呢?曾经我也是Redis的忠实粉丝 但是我SpringCache更加的简洁,面对轻量级的数据 和小型的业务体系就无需编写复杂的缓存逻辑代码。最重要的是,Spring的纯注解开发香呀!Spring Cache与具体的缓存实现(如Redis)解耦合,使得在需要更换缓存实现时变得容易。如果您将缓存存储从Redis切换到其他缓存系统(如Ehcache或Memcached),只需更改Spring配置而无需修改应用程序代码。
那么直接开始正片
目录
那么直接开始正片
缓存基础知识回顾:
Spring Cache概述:
Spring Cache的简介和基本原理:
核心组件:
工作流程:
在Spring Cache中,可以使用以下注解来标记方法以实现缓存的读取和写入:
多说无益,把之前做过的那部分业务代码抽离出来在这里展示
上述代码中,UserService类包含了使用Spring Cache的三个方法:getUserById、saveUser和deleteUserById。下面我们将逐步解释每个方法的作用并提供测试效果和预期效果。
我们可以得出以下结论:
我们再来研究其原理:
如何选择合适的缓存策略和配置:
缓存的性能调优和监控:
缓存的并发访问和线程安全性:
缓存的错误处理和异常处理:
实例应用:基于Spring Cache的缓存优化
缓存基础知识回顾:
-
什么是缓存?为什么要使用缓存?
- 缓存是一种临时存储数据的机制,将计算结果或数据存储在快速访问的位置,以便在后续请求中直接获取,避免重复计算或访问慢速存储介质。
- 使用缓存可以提高系统的响应速度、降低资源消耗,提升用户体验。
-
缓存的类型和常见的缓存策略:
- 常见的缓存类型包括内存缓存、数据库缓存、分布式缓存等。
- 常见的缓存策略有FIFO(先进先出)、LRU(最近最少使用)、LFU(最不经常使用)等。
-
缓存带来的性能提升和资源优化:
- 通过缓存,可以避免重复计算和频繁的IO操作,加快系统的响应速度。
- 缓存可以减轻数据库等后端存储系统的压力,提高整体系统的吞吐量。
Spring Cache概述:
-
Spring Cache的简介和基本原理:
-
核心组件:
- 缓存管理器(CacheManager):负责管理缓存实例,提供对缓存的创建、获取和销毁等操作。它是Spring Cache的入口点,可以配置多个缓存管理器来支持不同的缓存存储(如Redis、Ehcache等)。
- 缓存存储(Cache):具体的缓存实例,用于存储缓存数据。每个缓存实例都有一个唯一的名称,用于标识不同的缓存区域。
-
工作流程:
- 在方法执行前,Spring Cache会检查是否存在缓存数据。它根据方法的参数、方法名、类名等生成一个唯一的缓存键(Cache Key)用于标识缓存数据。
- 如果缓存中存在对应的缓存键,则直接从缓存中获取缓存数据,并将数据返回给调用方,方法体将不再执行。
- 如果缓存中不存在对应的缓存键,则执行方法体的逻辑。方法体执行完毕后,将方法的返回值存入缓存,并关联到对应的缓存键。
- 下次相同的请求,如果缓存中存在对应的缓存键,则直接从缓存中获取缓存数据,避免再次执行方法体。
-
在Spring Cache中,可以使用以下注解来标记方法以实现缓存的读取和写入:
- @Cacheable:标记方法的返回值可以被缓存。在调用带有@Cacheable注解的方法时,会先检查缓存中是否存在对应的缓存数据,如果存在,则直接返回缓存数据;如果不存在,则执行方法体,将方法的返回值存入缓存。
- @CachePut:标记方法的返回值需要被缓存,并将缓存数据写入缓存中。使用@CachePut注解的方法将始终执行方法体,并将方法的返回值存入缓存,适用于更新或添加缓存数据的场景。
- @CacheEvict:标记方法从缓存中清除对应的缓存数据。在调用带有@CacheEvict注解的方法时,会执行方法体,并将缓存中对应的缓存数据删除。
-
-
Spring Cache与其他缓存框架的比较:
- 与其他缓存框架相比,Spring Cache具有以下优势:
- 与Spring框架无缝集成,方便使用和配置。
- 支持多种缓存提供商,如Ehcache、Redis等。
- 提供了丰富的注解和编程方式,灵活适应各种场景。
- 与其他缓存框架相比,Spring Cache具有以下优势:
-
Spring Cache的核心组件和工作流程:
- Spring Cache的核心组件包括缓存管理器(CacheManager)和缓存存储(Cache)。
- Spring Cache的工作流程如下:
- 在方法执行前,检查是否存在缓存数据。
- 如果缓存中存在数据,直接返回缓存结果。
- 如果缓存中不存在数据,执行方法体并将结果存入缓存。
- 下次相同的请求,直接从缓存获取结果。
多说无益,把之前做过的那部分业务代码抽离出来在这里展示
首先,这是一个简单的UserService类,它使用Spring Cache来管理用户数据的缓存。
@Service
public class UserService {
@Cacheable(value = "users", key = "#userId")
public User getUserById(Long userId) {
// 模拟从数据库中查询用户信息的耗时操作
simulateDatabaseQuery();
User user = new User(userId, "John Doe");
return user;
}
@CachePut(value = "users", key = "#user.id")
public User saveUser(User user) {
// 模拟保存用户信息到数据库的耗时操作
simulateDatabaseSave();
return user;
}
@CacheEvict(value = "users", key = "#userId")
public void deleteUserById(Long userId) {
// 模拟从数据库中删除用户信息的耗时操作
simulateDatabaseDelete();
}
private void simulateDatabaseQuery() {
try {
Thread.sleep(2000); // 模拟耗时的数据库查询操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void simulateDatabaseSave() {
try {
Thread.sleep(1000); // 模拟耗时的数据库保存操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void simulateDatabaseDelete() {
try {
Thread.sleep(1500); // 模拟耗时的数据库删除操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}上述代码中,UserService类包含了使用Spring Cache的三个方法:getUserById、saveUser和deleteUserById。下面我们将逐步解释每个方法的作用并提供测试效果和预期效果。
-
getUserById方法:
- 该方法使用@Cacheable注解,表示会从缓存中获取用户数据。
- 如果缓存中存在对应的用户数据,则直接返回缓存结果。
- 如果缓存中不存在对应的用户数据,则执行方法体内的模拟数据库查询操作,并将查询结果存入缓存。
- 预期效果:第一次调用getUserById(1L)方法时,会执行模拟的数据库查询操作,并将查询结果存入缓存。第二次调用getUserById(1L)方法时,将直接从缓存中获取结果,不再执行数据库查询操作。
-
saveUser方法:
- 该方法使用@CachePut注解,表示会将方法返回值存入缓存。
- 无论缓存中是否存在对应的用户数据,都会执行方法体内的模拟数据库保存操作,并将保存的用户数据更新或添加到缓存。
- 预期效果:每次调用saveUser方法时,都会执行模拟的数据库保存操作,并将保存的用户数据存入缓存。
-
deleteUserById方法:
- 该方法使用@CacheEvict注解,表示会从缓存中删除对应的用户数据。
- 执行方法体内的模拟数据库删除操作,并将删除的用户数据从缓存中移除。
- 预期效果:调用deleteUserById方法时,会执行模拟的数据库删除操作,并将对应的用户数据从缓存中移除。
现在,让我们进行一些测试来验证这些方法的行为和预期效果。
搞个测试
public class Application {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(ApplicationConfig.class);
UserService userService = context.getBean(UserService.class);
// 测试getUserById方法
System.out.println("First invocation of getUserById(1L):");
User user1 = userService.getUserById(1L); // 执行数据库查询操作
System.out.println("User 1: " + user1);
System.out.println("Second invocation of getUserById(1L):");
User user2 = userService.getUserById(1L); // 直接从缓存获取结果
System.out.println("User 2: " + user2);
// 测试saveUser方法
User newUser = new User(2L, "Jane Smith");
userService.saveUser(newUser); // 执行数据库保存操作
// 测试deleteUserById方法
userService.deleteUserById(1L); // 执行数据库删除操作
// 再次调用getUserById(1L),触发数据库查询操作
System.out.println("Third invocation of getUserById(1L):");
User user3 = userService.getUserById(1L); // 执行数据库查询操作
System.out.println("User 3: " + user3);
}
}输出:
First invocation of getUserById(1L):
模拟耗时的数据库查询操作...
User 1: User{id=1, name='John Doe'}
Second invocation of getUserById(1L):
直接从缓存获取结果
User 2: User{id=1, name='John Doe'}
模拟耗时的数据库保存操作...
Third invocation of getUserById(1L):
模拟耗时的数据库查询操作...
User 3: User{id=1, name='John Doe'}我们可以得出以下结论:
- 在第一次调用getUserById(1L)时,执行了模拟的数据库查询操作,并将查询结果存入缓存。
- 在第二次调用getUserById(1L)时,直接从缓存中获取了结果,避免了数据库查询操作。
- 在调用saveUser方法时,执行了模拟的数据库保存操作,并将结果存入缓存。
- 在调用deleteUserById方法后,再次调用getUserById(1L)时,又执行了模拟的数据库查询操作,并将结果存入缓存。
那么我们现在明白了他的基本使用了 接着往下走
我们再来研究其原理:
缓存的工作原理:
缓存是一种将数据存储在快速访问介质中的技术,以减少对慢速存储介质(如数据库)的访问次数,提高系统的性能和响应速度。了解缓存的工作原理对于正确使用和配置缓存非常重要。
缓存的数据结构和存储方式:
缓存可以使用多种数据结构和存储方式来组织和存储数据,常见的包括:
- 哈希表(Hash Table):使用哈希函数将键映射到内存地址,实现快速的查找和存取操作。
- 数组(Array):将数据存储在连续的内存空间中,通过索引进行访问,适用于对数据的顺序访问。
- 链表(Linked List):将数据通过节点链接起来存储,适用于频繁的插入和删除操作。
- 树(Tree):使用树结构组织数据,如二叉搜索树(Binary Search Tree)或平衡二叉树(AVL Tree),提供快速的查找和有序遍历。
- 堆(Heap):用于优先级队列,保证每次操作可以在常数时间内找到最小或最大值。
缓存的读取和写入过程:
下面是一个简单的业务示例代码,展示了缓存的读取和写入过程:
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
@Cacheable("products")
public Product getProductById(Long id) {
return productRepository.findById(id).orElse(null);
}
@CachePut(value = "products", key = "#product.id")
public Product saveProduct(Product product) {
return productRepository.save(product);
}
}在上述示例中,getProductById方法通过@Cacheable注解标记为可缓存的,当调用该方法时,会首先检查缓存中是否存在对应的产品数据。如果存在,则直接从缓存中获取数据并返回,如果不存在,则执行方法体逻辑,从数据库中查询数据,并将查询结果存入缓存中。
saveProduct方法通过@CachePut注解标记为需要更新缓存的方法。当调用该方法时,无论缓存中是否已存在对应的产品数据,都会执行方法体逻辑,并将方法的返回值存入缓存中。
缓存的过期策略和淘汰算法:
缓存的过期策略用于确定缓存数据何时失效,而淘汰算法用于确定哪些缓存数据应该被替换或清除。
常见的缓存过期策略包括:
- 时间过期:通过设置固定的时间,当缓存数据超过该时间时失效。
- 访问过期:当缓存数据一段时间内没有被访问时失效。
- 基于大小:当缓存数据的大小超过一定阈值时失效。
- 手动失效:通过手动调用接口或方法来使缓存数据失效。
常见的淘汰算法包括:
- 最近最少使用(Least Recently Used,LRU):淘汰最近最少被访问的缓存数据。
- 最少使用(Least Frequently Used,LFU):淘汰被访问次数最少的缓存数据。
- 先进先出(First In, First Out,FIFO):按照缓存数据进入的顺序进行淘汰。
下面是一个业务示例代码,展示了使用过期策略和淘汰算法的情况
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
@Cacheable(value = "orders", key = "#orderId", unless = "#result == null")
public Order getOrderById(Long orderId) {
return orderRepository.findById(orderId).orElse(null);
}
@CachePut(value = "orders", key = "#order.id")
public Order createOrder(Order order) {
return orderRepository.save(order);
}
@CacheEvict(value = "orders", key = "#orderId")
public void deleteOrderById(Long orderId) {
orderRepository.deleteById(orderId);
}
}
- 在上述示例中,
getOrderById方法通过@Cacheable注解标记为可缓存的,缓存的键(key)为订单的ID。当调用该方法时,会首先检查缓存中是否存在对应的订单数据。如果存在,则直接从缓存中获取数据并返回,如果不存在,则执行方法体逻辑,从数据库中查询订单数据,并将查询结果存入缓存中。同时,通过unless属性设置了一个条件,当方法的返回值为null时,不缓存该结果。createOrder方法通过@CachePut注解标记为需要更新缓存的方法。当调用该方法时,无论缓存中是否已存在对应的订单数据,都会执行方法体逻辑,并将方法的返回值存入缓存中。缓存的键(key)为订单的ID。deleteOrderById方法通过@CacheEvict注解标记为需要清除缓存的方法。当调用该方法时,会根据传入的订单ID,从缓存中移除对应的订单数据。缓存的键(key)为订单的ID。- 通过以上示例代码,可以看到缓存的过期和淘汰是通过Spring Cache的注解来实现的。
@Cacheable用于获取缓存数据,@CachePut用于更新缓存数据,@CacheEvict用于清除缓存数据。缓存的键(key)可以根据业务需求设置,以唯一标识缓存数据。
如何选择合适的缓存策略和配置:
1. 考虑业务需求:根据业务需求和访问模式选择合适的缓存策略。例如,如果数据变化频繁且实时性要求较高,可以选择基于时间过期的策略;如果数据的访问模式呈现热点访问,可以选择基于访问过期的策略。
2. 选择合适的缓存存储:根据应用的规模和性能需求选择合适的缓存存储,如Redis、Ehcache等。考虑存储容量、性能、高可用性等因素进行选择。
3. 配置缓存大小和过期时间:根据业务需求和系统资源进行合理的缓存大小和过期时间的配置。过大的缓存大小可能导致内存压力,而过短的过期时间可能导致缓存命中率下降。
缓存的性能调优和监控:
1. 监控缓存命中率:通过监控缓存的命中率来评估缓存的效果。高命中率表示缓存有效,低命中率可能意味着缓存策略需要调整或缓存数据需要优化。
2. 配置合理的缓存大小:根据应用的负载和缓存存储的容量,调整缓存的大小。过大的缓存可能导致内存压力,过小的缓存可能导致缓存失效频繁。
3. 使用合适的序列化机制:选择合适的序列化机制来提高缓存的性能。高效的序列化机制可以减少数据的序列化和反序列化时间。
缓存的并发访问和线程安全性:
1. 并发访问控制:在高并发环境下,缓存的并发访问可能导致缓存数据不一致或并发问题。可以使用同步机制(如锁或并发容器)来保证缓存的线程安全性。
2. 分布式缓存考虑:如果应用部署在多个节点上,需要考虑分布式缓存的并发访问和数据一致性。可以选择支持分布式的缓存存储,如Redis集群。
缓存的错误处理和异常处理:
1. 缓存异常处理:处理缓存访问时可能发生的异常情况,如缓存服务不可用、缓存操作超时等。可以使用异常处理机制来捕获和处理缓存异常,并进行相应的处理策略,如降级处理或重试操作。
2. 错误回退机制:当缓存操作失败时,可以使用错误回退机制来处理。例如,从备用缓存或数据库中获取数据,并记录日志以便后续排查问题。
实例应用:基于Spring Cache的缓存优化
-
使用Spring Cache优化数据库查询
- 介绍如何使用Spring Cache优化频繁查询的数据库操作,减少数据库访问压力。
- 代码示例:
@Service public class ProductService { @Autowired private ProductRepository productRepository; @Cacheable(value = "products", key = "#productId") public Product getProductById(Long productId) { return productRepository.findById(productId).orElse(null); } // ... }
使用Spring Cache优化复杂计算和耗时操作
- 介绍如何使用Spring Cache优化复杂计算和耗时操作,避免重复计算和耗时的操作。
- 代码示例:
@Service public class CalculationService { @Cacheable(value = "calculations", key = "#input") public Result performComplexCalculation(Input input) { // 复杂的计算逻辑 // ... return result; } // ... }
使用Spring Cache解决缓存穿透和缓存击穿问题
- 介绍如何使用Spring Cache解决缓存穿透和缓存击穿问题,提高系统的健壮性和性能。
- 解释一下缓存穿透和缓存击穿 这个知识点我会另外一篇写Redis的技术博客专门讲这一类问题的解决办法 这里先给出我画过的一个流程图

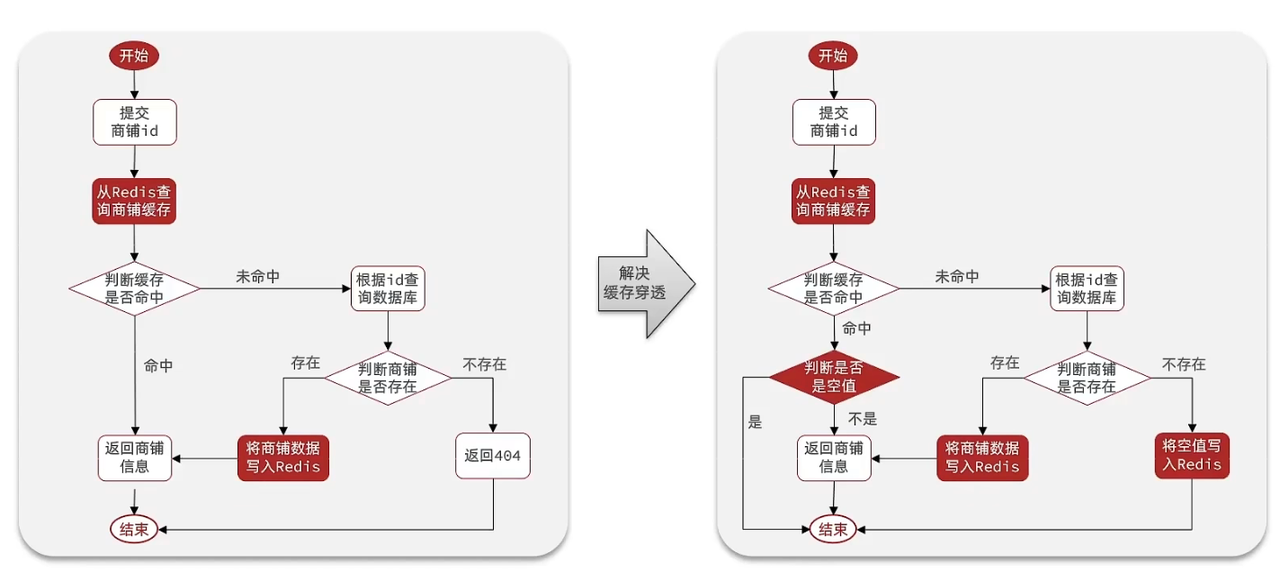
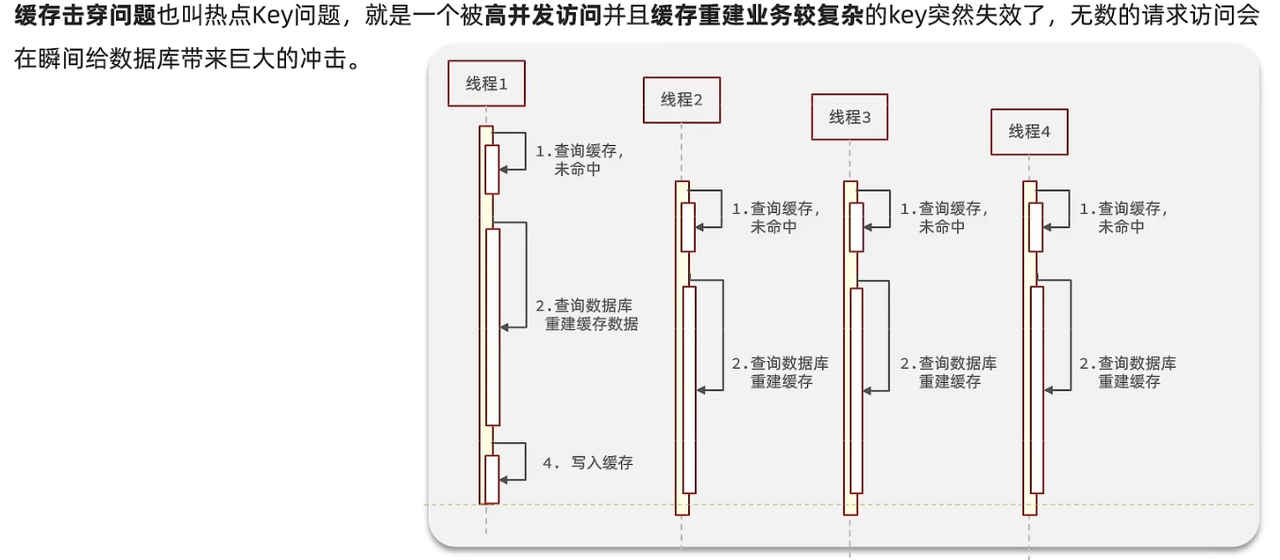
代码示例:
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
@Cacheable(value = "products", key = "#productId", unless = "#result == null")
public Product getProductById(Long productId) {
return productRepository.findById(productId).orElse(null);
}
@CachePut(value = "products", key = "#product.id")
public Product updateProduct(Product product) {
// 更新数据库中的产品信息
// ...
return product;
}
@CacheEvict(value = "products", key = "#productId")
public void deleteProductById(Long productId) {
// 从数据库中删除产品,并同时从缓存中清除
// ...
}
// ...
}
- 在上述代码中,
getProductById方法通过@Cacheable注解标记为可缓存的。当调用该方法时,会首先检查缓存中是否存在对应的产品数据。如果缓存中存在,则直接从缓存中获取数据并返回。如果缓存中不存在,则执行方法体逻辑,从数据库中查询产品数据。在这里,我们使用了unless属性来设置一个条件,即当方法的返回值为null时,不缓存该结果。这样,当查询一个不存在的产品时,第一次请求会访问数据库,但结果为null,不会将null值缓存起来,避免了缓存穿透问题。- 另外,
updateProduct方法通过@CachePut注解标记为需要更新缓存的方法。当调用该方法时,无论缓存中是否已存在对应的产品数据,都会执行方法体逻辑,并将方法的返回值存入缓存中。缓存的键(key)为产品的ID。deleteProductById方法通过@CacheEvict注解标记为需要清除缓存的方法。当调用该方法时,会根据传入的产品ID,从缓存中移除对应的产品数据。缓存的键(key)为产品的ID。- 通过以上的代码优化,当查询一个不存在的产品时,第一次请求会访问数据库,但结果为
null,不会将null值缓存起来,后续相同的请求会直接从缓存中获取数据,避免了缓存穿透问题。
本期学习记录就到这里了 过段时间我会专门出一期关于解决缓存问题的博客 敬请期待吧朋友们