论文创新点汇总:人工智能论文通用创新点(持续更新中...)-CSDN博客
论文总结
关于如何提升模型速度,当今学术界的研究往往聚焦于如何将FLOPs或者参数量的降低,而作者认为应该是减少分支数和选择高效的网络结构。
概述
MobileOne(≈MobileNetV1+RepVGG+训练Trick)是由Apple公司提出的一种基于iPhone12优化的超轻量型架构,在ImageNet数据集上以<1ms的速度取得了75.9%的Top1精度。
MobileOne
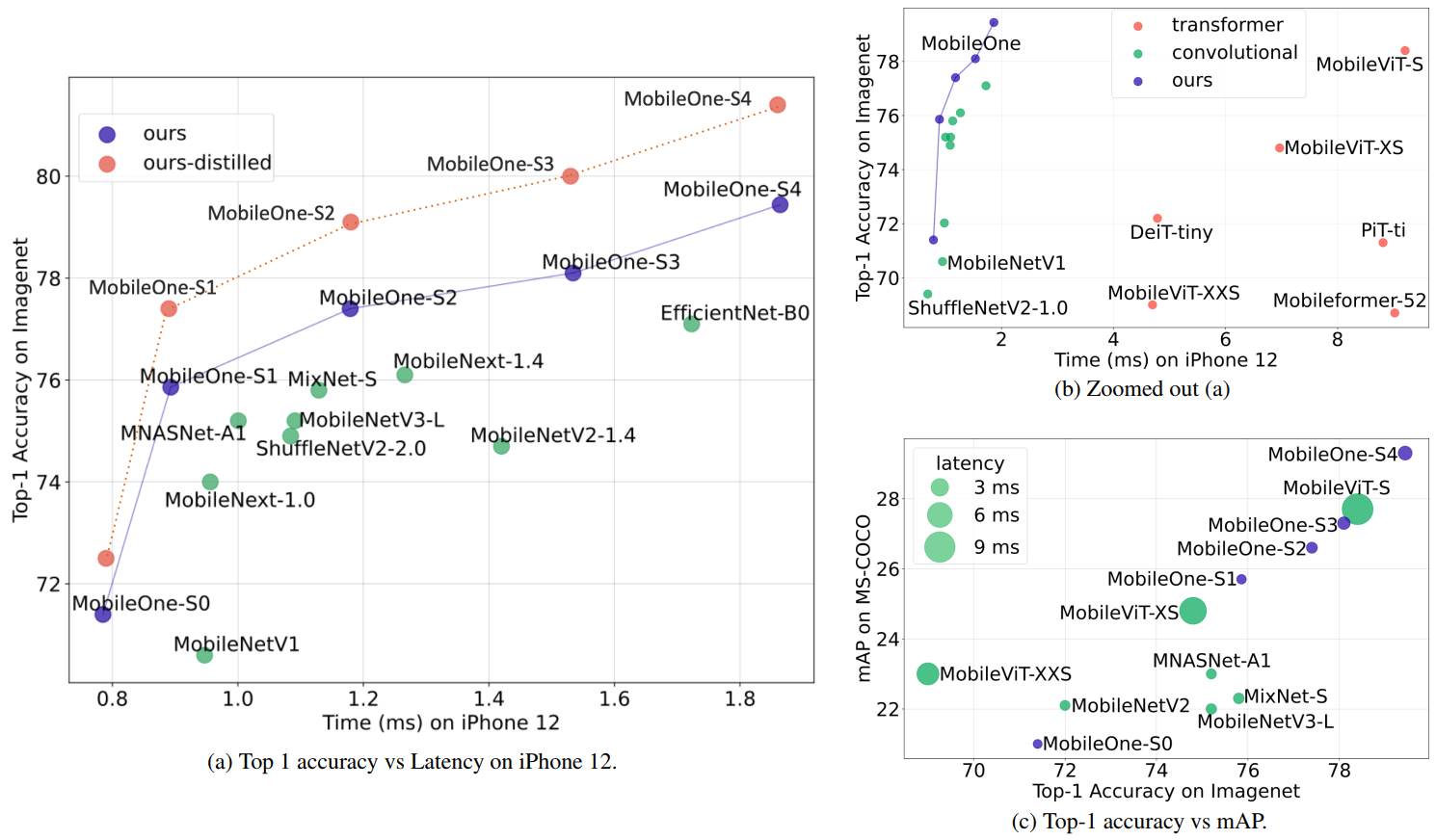
高效率网络具有很高的价值,但学术界的研究往往聚焦于如何将FLOPs或者参数量的降低,而这两者与推理效率之间并不存在严格的一致性。比如,FLOPs并未考虑访存消耗与计算并行度,像无参操作(如跳过连接导致的Add、Concat等)会带来显著的访存消耗,导致更长推理耗时。
度量关系
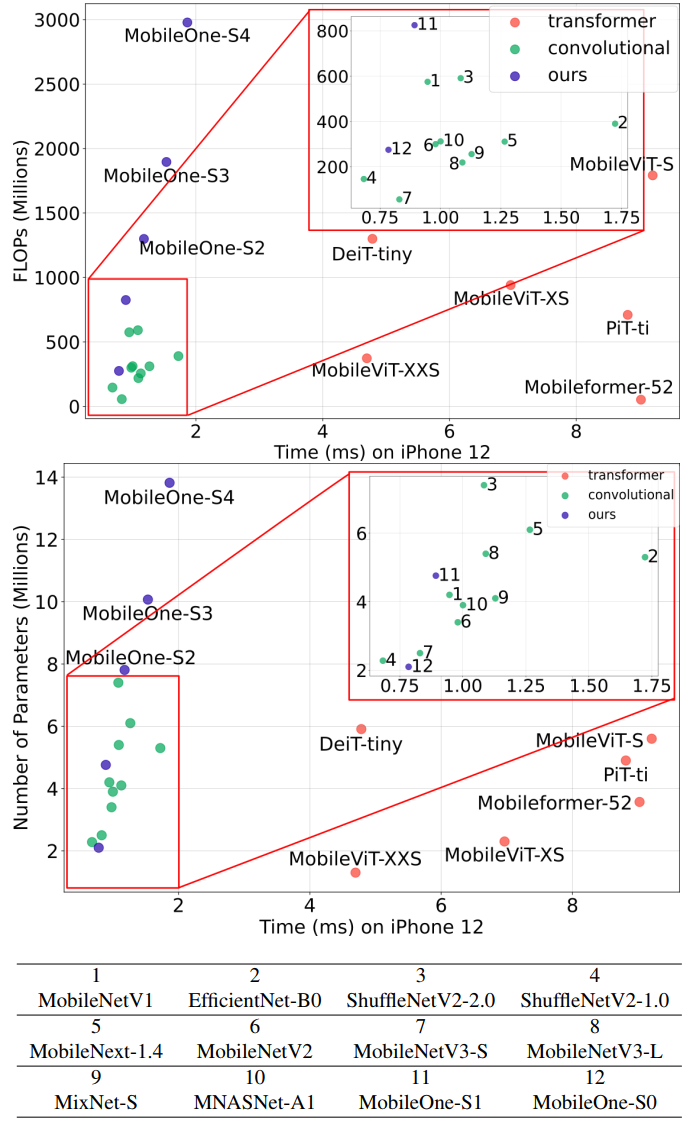
从上图可以看出,延迟的快慢与模型的参数量或者FLOPs的相关性较弱,在CPU端相关性更弱。
关键瓶颈
本文对影响模型性能的两个"瓶颈"进行分析,并提出相应方案;
激活函数
从下表可以看出,尽管具有相同的架构,但不同激活函数导致的延迟差异极大。本文默认选择ReLU激活函数。

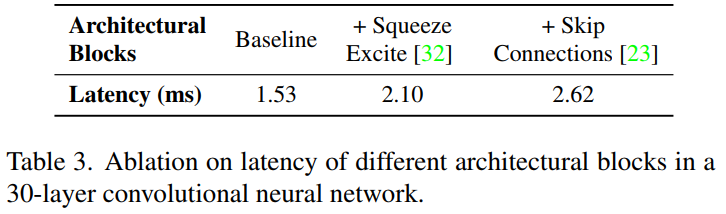
结构块
从下表可以看出,当采用单分支结构时,模型具有更快的速度。为改善效率,本文在大模型配置方面有限的采用了SE模块。
MobileOne Block
MobileOne的核心模块基于MobileNetV1而设计,同时吸收了重参数思想,得到下图所示的结构。
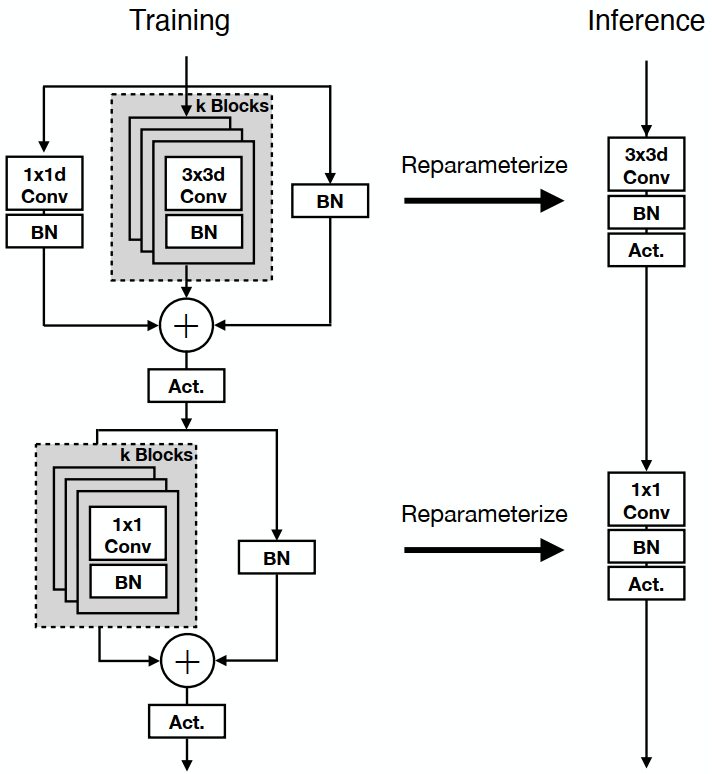
图3。MobileOne块在训练时间和测试时间有两种不同的结构。左:训练时间MobileOne块与可重新参数化的分支。右:MobileOne块在推理分支被重新参数化。ReLU或SEReLU被用作激活。琐碎的过参数化因子k是一个针对每个变量进行调优的超参数。
结构
最近的工作在于如何缩放模型尺寸,如宽度、深度和分辨率,以提高性能[22,54]。MobileOne具有与MobileNet-V2相似的深度缩放,即使用较浅的早期阶段,其中输入分辨率较大,因为这些层与使用较小输入分辨率的后期阶段相比要慢得多。我们引入5种不同的宽度尺度,如表7所示。
其中用于控制通道数,
为分支数
S1-S4的区别更多是S4分支数少,S1分支数多
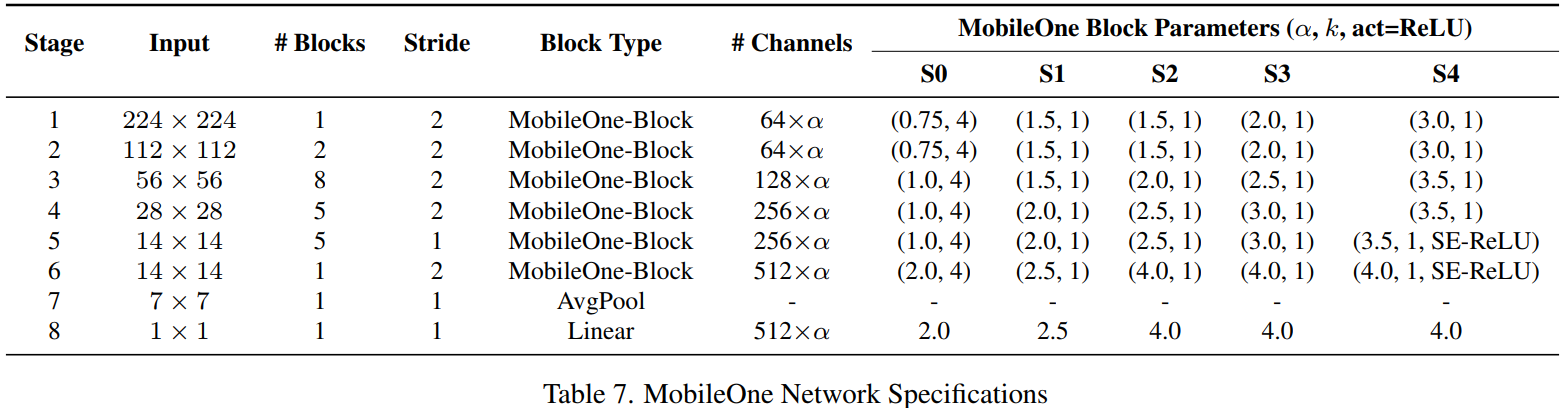

表8所示。MobileOne-S2在各种训练设置上的消融在ImageNet上显示了Top-1的精度。
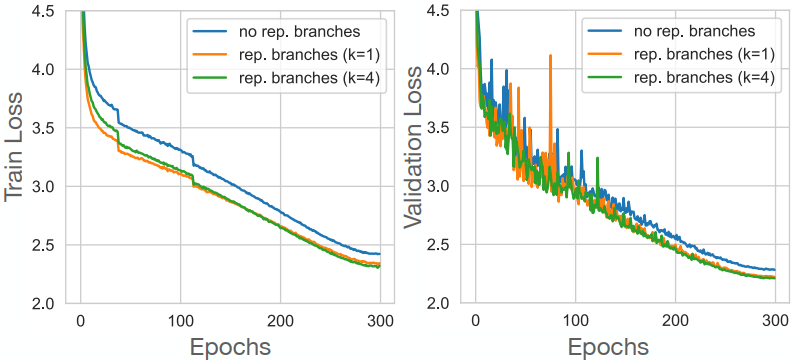
图4。MobileOne-S0模型的训练和验证损失图。从无分支到增加k=1的可重新参数化分支,列车损失降低3.4%。增加更多的分支(k=4)可使列车损失额外降低约1%。从没有分支到具有可重新参数化分支的变体(k=4),验证损失提高了3.1%。
实验
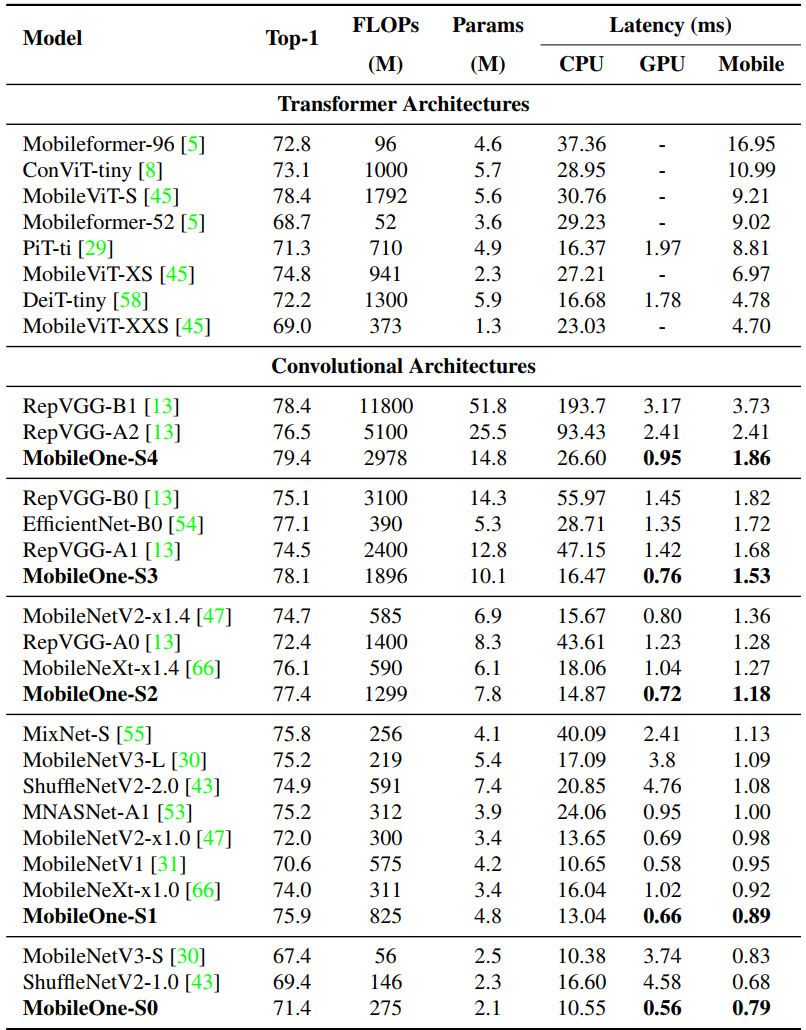
我们使用S1和S2标准增强-随机调整大小的裁剪和水平翻转。我们还使用衰减常数为0.9995的EMA(指数移动平均)加权平均来训练所有版本的MobileOne。在测试时,所有MobileOne模型在分辨率为224 × 224的图像上进行评估。在表9中,我们比较了所有最近的高效模型,这些模型是在分辨率为224×224的图像上进行评估的,同时参数计数< 2000万,并且没有像以前的工作(如[5,45])那样进行蒸馏训练。FLOP计数是使用fvcore[17]库报告的。
我们表明,即使是最小的变压器架构变体,在移动设备上也有超过4ms的延迟。目前最先进的MobileFormer[5]以70.76ms的延迟达到79.3%的最高精度,而MobileOne-S4以1.86ms的延迟达到79.4%,这在移动设备上快了38倍。MobileOne-S3的top-1准确率比EfficientNet-B0高1%,在移动设备上则快11%。与竞争对手的方法相比,我们的模型甚至在CPU和GPU上具有更低的延迟。
讨论
我们提出了一种高效、通用的移动设备骨干网。我们的主干适用于一般任务,如图像分类,目标检测和语义分割。我们表明,在有效状态下,延迟可能与其他指标(如参数计数和FLOPs)不太相关。此外,我们通过直接在移动设备上测量其延迟来分析现代高效cnn中使用的各种架构组件的效率瓶颈。我们通过经验证明了使用可重新参数化结构对优化瓶颈的改善。我们使用可重新参数化结构的模型扩展策略获得了最先进的性能,同时在移动设备和桌面CPU上都很高效。
核心代码
源码实现
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc, kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=in_channels, bias=True,
padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,
bias=True)
else:
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_{k_idx}',
DepthWiseConv(in_channels, 3, stride=stride)
)
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_{k_idx}',
PointWiseConv(in_channels, out_channels)
)
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_{k_idx}')(inputs)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_{k_idx}')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
class MobileOne(nn.Module):
# MobileOne
def __init__(self, in_channels, out_channels, n, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super().__init__()
self.m = nn.Sequential(*[MobileOneBlock(in_channels, out_channels, k, stride, deploy) for _ in range(n)])
def forward(self, x):
x = self.m(x)
return xcommon.py
# This file contains modules common to various models
import math
import torch
import torch.nn as nn
from utils.general import non_max_suppression
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
import torch
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc, kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=in_channels, bias=True,
padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,
bias=True)
else:
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_{k_idx}',
DepthWiseConv(in_channels, 3, stride=stride)
)
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_{k_idx}',
PointWiseConv(in_channels, out_channels)
)
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_{k_idx}')(inputs)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_{k_idx}')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
class MobileOne(nn.Module):
# MobileOne
def __init__(self, in_channels, out_channels, n, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super().__init__()
self.m = nn.Sequential(*[MobileOneBlock(in_channels, out_channels, k, stride, deploy) for _ in range(n)])
def forward(self, x):
x = self.m(x)
return x
#MobileOne
class LayerNorm_s(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class ConvNextBlock(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm_s(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class CNeB(nn.Module):
# CSP ConvNextBlock with 3 convolutions by iscyy/yoloair
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(ConvNextBlock(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
#CONVNEXT BLOCK
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3 * self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes,
kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1,
stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i // self.kernel_conv, i % self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h // self.stride, w // self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b * self.head, self.head_dim, h, w) * scaling
k_att = k.view(b * self.head, self.head_dim, h, w)
v_att = v.view(b * self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b * self.head, self.head_dim,
self.kernel_att * self.kernel_att, h_out,
w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att * self.kernel_att, h_out,
w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2) * (unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(
1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b * self.head, self.head_dim, self.kernel_att * self.kernel_att,
h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat(
[q.view(b, self.head, self.head_dim, h * w), k.view(b, self.head, self.head_dim, h * w),
v.view(b, self.head, self.head_dim, h * w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
def DWConv(c1, c2, k=1, s=1, act=True):
# Depthwise convolution
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
# Coordinate Attention for Efficient Mobile Network Design
'''
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting
model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a
novel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, which
we call “coordinate attention”. Unlike channel attention
that transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding
processes that aggregate features along the two spatial directions, respectively
'''
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
pool_h = nn.AdaptiveAvgPool2d((h, 1))
pool_w = nn.AdaptiveAvgPool2d((1, w))
x_h = pool_h(x)
x_w = pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
class NMS(nn.Module):
# Non-Maximum Suppression (NMS) module
conf = 0.3 # confidence threshold
iou = 0.6 # IoU threshold
classes = None # (optional list) filter by class
def __init__(self, dimension=1):
super(NMS, self).__init__()
def forward(self, x):
return non_max_suppression(x[0], conf_thres=self.conf, iou_thres=self.iou, classes=self.classes)
class Flatten(nn.Module):
# Use after nn.AdaptiveAvgPool2d(1) to remove last 2 dimensions
@staticmethod
def forward(x):
return x.view(x.size(0), -1)
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super(Classify, self).__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # to x(b,c2,1,1)
self.flat = Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)
yolo.py
import argparse
import logging
import math
import sys
from copy import deepcopy
from pathlib import Path
sys.path.append('./') # to run '$ python *.py' files in subdirectories
logger = logging.getLogger(__name__)
import torch
import torch.nn as nn
from models.common import Conv, Bottleneck, SPP, DWConv, Focus, BottleneckCSP, Concat, NMS,space_to_depth,CA,ACmix,CNeB,MobileOne
from models.experimental import MixConv2d, CrossConv, C3
from models.gc import CB2D
from utils.general import check_anchor_order, make_divisible, check_file, set_logging
from utils.torch_utils import (
time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, select_device)
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
if nc and nc != self.yaml['nc']:
print('Overriding model.yaml nc=%g with nc=%g' % (self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist, ch_out
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 128 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
print('')
def forward(self, x, augment=False, profile=False):
if augment:
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si)
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite('img%g.jpg' % s, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
i = 1
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
try:
import thop
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPS
except:
o = 0
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
#print('层数:',i,'特征图大小:',x.shape)
i+=1
y.append(x if m.i in self.save else None) # save output
if profile:
print('%.1fms total' % sum(dt))
return x
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
with torch.no_grad():
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(m, 'bn'):
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatability
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def add_nms(self): # fuse model Conv2d() + BatchNorm2d() layers
if type(self.model[-1]) is not NMS: # if missing NMS
print('Adding NMS module... ')
m = NMS() # module
m.f = -1 # from
m.i = self.model[-1].i + 1 # index
self.model.add_module(name='%s' % m.i, module=m) # add
return self
def info(self, verbose=False): # print model information
model_info(self, verbose)
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is space_to_depth:
c2 = 4 * ch[f]
elif m in [CA]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
elif m in [CB2D]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [CB2D]:
args.insert(2, n) # number of repeats
n = 1
elif m in [ACmix]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
elif m is CNeB:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m is CNeB:
args.insert(2, n)
n = 1
elif m is MobileOne:
c1, c2 = ch[f], args[0]
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, n, *args[1:]]
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
opt = parser.parse_args()
opt.cfg = check_file(opt.cfg) # check file
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
model.train()
# Profile
# img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
# y = model(img, profile=True)
# ONNX export
# model.model[-1].export = True
# torch.onnx.export(model, img, opt.cfg.replace('.yaml', '.onnx'), verbose=True, opset_version=11)
# Tensorboard
# from torch.utils.tensorboard import SummaryWriter
# tb_writer = SummaryWriter()
# print("Run 'tensorboard --logdir=models/runs' to view tensorboard at http://localhost:6006/")
# tb_writer.add_graph(model.model, img) # add model to tensorboard
# tb_writer.add_image('test', img[0], dataformats='CWH') # add model to tensorboard
yolov5s_mobileone.yaml
# parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, MobileOne, [128,4,1]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, MobileOne, [256,4,1]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, MobileOne, [512,4,1]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, MobileOne, [1024, 4,1]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
参考资料
论文下载
https://arxiv.org/pdf/2206.04040.pdf

代码地址
GitHub - apple/ml-mobileone: This repository contains the official implementation of the research paper, "An Improved One millisecond Mobile Backbone".