一.堆的概念及实现
1.1堆的概念
在数据结构中,堆是一种特殊的树形数据结构。堆可以分为最大堆和最小堆两种类型。
最大堆:对于堆中的任意节点,其父节点的值都不小于它的值。换句话说,最大堆中的根节点是堆中的最大值。并且,最大堆的任意子树也都是最大堆。
最小堆:对于堆中的任意节点,其父节点的值都不大于它的值。最小堆中的根节点是堆中的最小值,且任意子树也都是最小堆。
堆通常用一个数组来表示,其中每个元素对应堆的一个节点。堆的性质保证了数组中的元素满足特定的顺序关系。
在堆中,通常可以进行以下操作:
- 插入:将一个元素插入到堆中的合适位置,保持堆的性质。
- 删除根节点:删除堆中的根节点,并保持堆的性质。对于最大堆,删除的是最大值;对于最小堆,删除的是最小值。
- 堆化:将一个无序的数组转换为堆的形式。
- 取最值 :获取堆中的最大值或最小值,即根节点的值。
堆广泛应用于各种算法和数据结构中,例如堆排序、优先队列、图算法(如最短路径算法中的Dijkstra算法)等。堆的特性使得这些算法具有高效的时间复杂度。
举个简单的例子解释堆的概念:
假设有一堆学生的成绩数据,每个学生都有一个分数,表示他们的学术表现。最大堆代表这种情况:每个学生的分数都比他们的孩子(下面的学生)更高。
现在,你想根据学生成绩来组织这些数据。你将最高分的学生放在最前面,其次是次高分的学生,以此类推。这样,你会得到一个最大堆,其中根节点是分数最高的学生,而任何一个学生的分数都不会超过他的父节点。
当你要添加新的学生成绩时,你需要将其放置在正确的位置,以保持最大堆的性质。如果新的学生的分数比他的父节点更高,你可能需要将他与父节点交换位置,以确保最大堆的性质。
最小堆的情况则相反。假设你有一堆学生的成绩数据,每个学生的分数都比他们的孩子更低。这意味着你将最低分的学生放置在最前面,而任何一个学生的分数都不会低于他的父节点。

1.2堆的性质
堆是一种特殊的数据结构,具有以下性质:
1. 堆是一个完全二叉树:堆是由完全二叉树组成的,意味着除了最后一层外,其它层都必须填满,且最后一层的节点都靠左排列。
2. 最大堆性质:对于最大堆,父节点的值大于或等于其子节点的值。换句话说,堆中的最大元素位于根节点。
3. 最小堆性质:对于最小堆,父节点的值小于或等于其子节点的值。换句话说,堆中的最小元素位于根节点。
4. 堆序性质:堆中的每个节点都必须满足堆的性质,即父节点的值要么大于等于(最大堆)或小于等于(最小堆)子节点的值。这意味着在堆中,无论是最大堆还是最小堆,根节点都是堆中的最大或最小元素。
5. 堆的高度:堆的高度是指从根节点到叶子节点的最长路径的长度。对于一个有 n 个节点的堆,其高度通常为 O(log n)。




这些性质使得堆成为一种非常有用的数据结构,尤其在优先队列、堆排序和图算法中经常被使用。堆的特点使得我们能够高效地访问和操作具有最大或最小优先级的元素,从而提高算法的效率和性能。
1.3堆的存储方式
堆可以使用数组来进行存储。在数组表示中,每个元素对应堆中的一个节点,通过数组的索引来确定节点之间的关系。
对于一个堆,我们使用以下规则来存储节点:
- 根节点存储在数组的索引位置 0 处。
- 对于任意节点 i,其父节点存储在索引位置 (i-1)/2 处。
- 对于任意节点 i,其左子节点存储在索引位置 2i+1 处。
- 对于任意节点 i,其右子节点存储在索引位置 2i+2 处。
比如如下存储最大堆
数组的存储结构是这样:
数组表示: [90, 80, 75, 60, 55, 40, 30, 20, 10, 25]
索引表示: 0 1 2 3 4 5 6 7 8 9数组的逻辑结构是这样:

简单解释索引位置的关系:
这样的关系是由完全二叉树的性质决定的。在完全二叉树中,每个节点都有可能存在左子节点和右子节点,且它们的位置是固定的。通过将完全二叉树的节点按照一定顺序存储在数组中,我们可以利用数组的索引来表示节点之间的关系。
根节点存储在数组的索引位置 0 处:因为完全二叉树的根节点始终位于最上层,所以它在数组中的位置是固定的,即索引位置 0 处。
对于任意节点 i,其父节点存储在索引位置 (i-1)/2 处:通过简单的数学计算,我们可以确定父节点在数组中的位置。对于任意节点 i,我们将节点索引减去 1,然后除以 2,可以得到父节点在数组中的索引位置。
对于任意节点 i,其左子节点存储在索引位置 2i+1 处:根据完全二叉树的性质,左子节点总是在父节点的左侧,所以我们可以通过将节点索引乘以 2,再加上 1,得到左子节点在数组中的索引位置。
对于任意节点 i,其右子节点存储在索引位置 2i+2 处:类似地,根据完全二叉树的性质,右子节点总是在父节点的右侧,所以我们可以通过将节点索引乘以 2,再加上 2,得到右子节点在数组中的索引位置
例子:

从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储
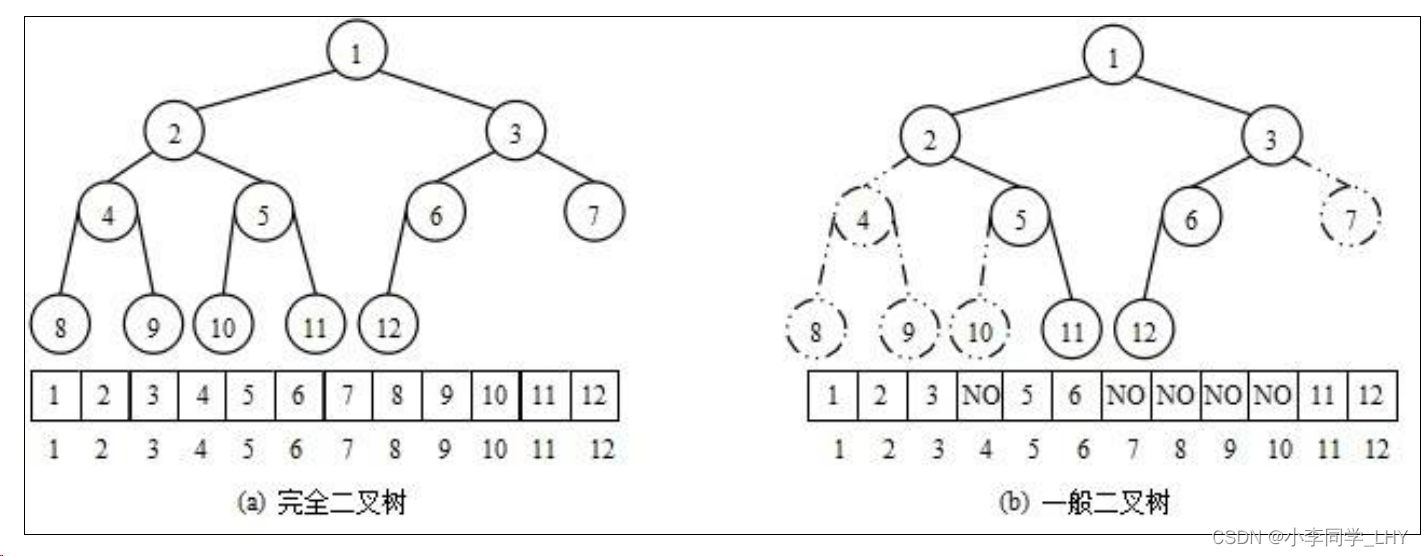
- 如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
- 如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
- 如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
- 比如:

二.堆的创建及时间复杂度
2.1堆向下过程(以小堆为例)
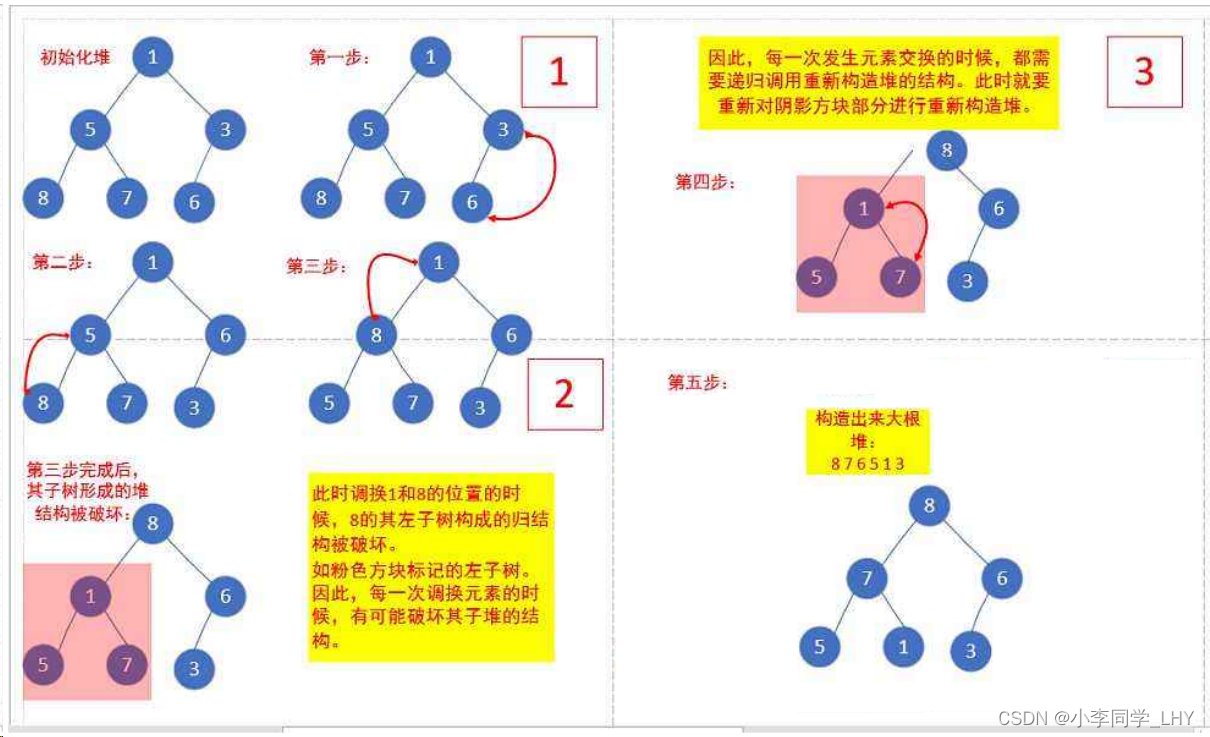
堆的创建是指将一个无序的数组或数据集转换为堆的过程。创建堆的常见方法是使用向下过程
以下是使用向下过程创建堆的一般步骤:
- 从最后一个非叶子节点开始,依次向上迭代直到根节点。最后一个非叶子节点的索引为数组长度的一半减一(n/2 - 1)。
- 对于每个节点,执行向下过程:
- 比较当前节点与其子节点的值,并找到值最大(或最小)的子节点。如果有左子节点,其索引为2 * i + 1;如果有右子节点,则索引为2 * i + 2。
- 如果当前节点的值小于其最大(或最小)子节点的值,则交换当前节点与最大(或最小)子节点的值。
- 更新当前节点的索引为最大(或最小)子节点的索引,即`i`的值更新为最大(或最小)子节点的索引。
- 重复步骤3至5,直到节点`i`不再有子节点或其值大于(或小于)其子节点的值。
- 重复步骤2,直到根节点。
通过以上步骤,将数组或数据集中的元素逐个进行向下过程,最终可以创建一个满足堆的性质的堆。在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。
需要注意的是,堆的创建过程的时间复杂度为O(n),其中n是数组或数据集的大小。
参考图示如下:
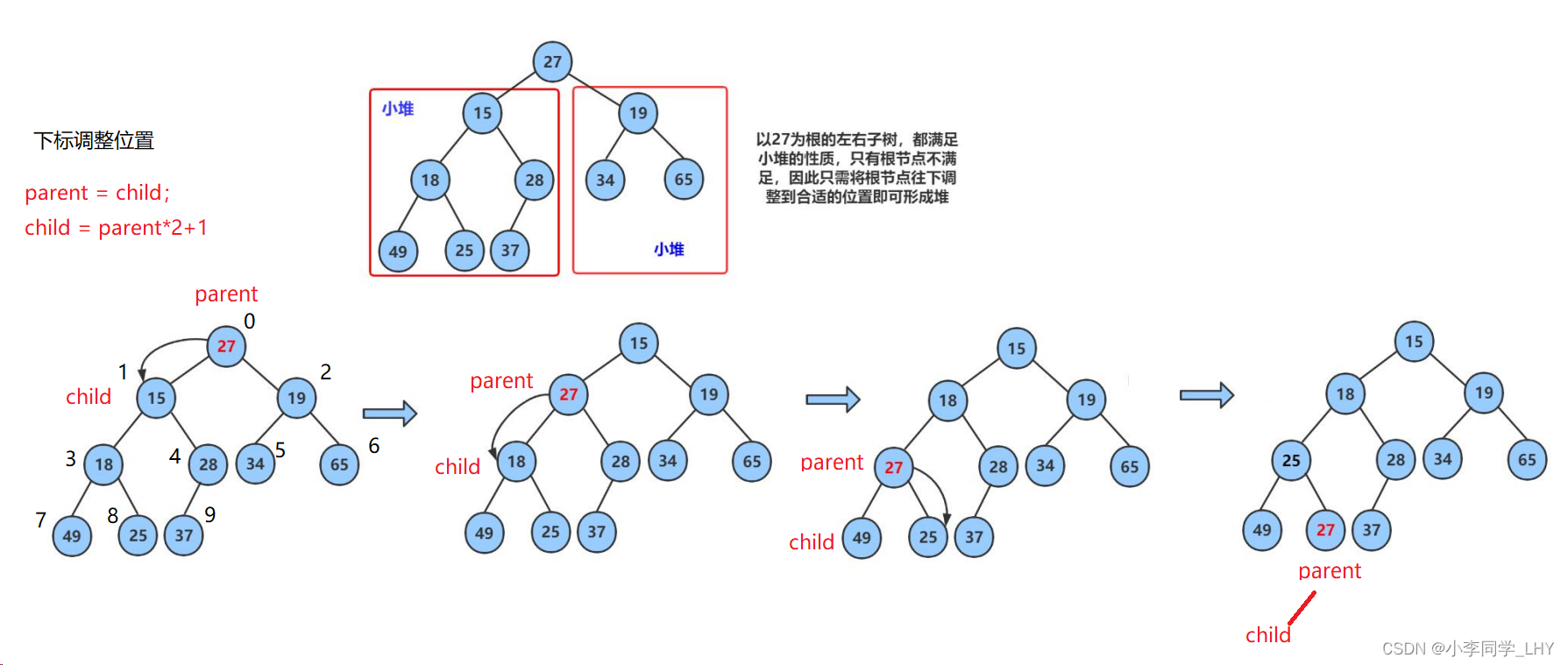
- 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子)
- 如果parent的左孩子存在,即:child < size, 进行以下操作,直到parent的左孩子不存在 parent右孩子是否存在,存在找到左右孩子中最小的孩子,让child进行标识。
- 将parent与较小的孩子child比较,如果parent小于较小的孩子child,调整结束
- 否则交换parent与较小的孩子child,交换完成之后,parent中大的元素向下移动,可能导致子树不满足对的性质,因此需要继续向下调整,即parent = child;child = parent*2+1。
参考代码如下:
public void shiftDown(int[] array, int parent) {
// child先标记parent的左孩子,因为parent可能右左没有右
int child = 2 * parent + 1;
int size = array.length;
while (child < size) {
// 如果右孩子存在,找到左右孩子中较小的孩子,用child进行标记
if(child+1 < size && array[child+1] < array[child]){
child += 1;
}
// 如果双亲比其最小的孩子还小,说明该结构已经满足堆的特性了
if (array[parent] <= array[child]) {
break;
}else{
// 将双亲与较小的孩子交换
int t = array[parent];
array[parent] = array[child];
array[child] = t;
// parent中大的元素往下移动,可能会造成子树不满足堆的性质,因此需要继续向下调整
parent = child;
child = parent * 2 + 1;
}
}
}
public static void createHeap(int[] array) {
// 找倒数第一个非叶子节点,从该节点位置开始往前一直到根节点,遇到一个节点,应用向下调整
int root = ((array.length-2)>>1);
for (; root >= 0; root--) {
shiftDown(array, root);
}
}2.2堆的时间复杂度
建堆的时间复杂度为O(n),其中n是堆中的元素数量。
建堆的过程可以通过向下过程来完成。在向下过程中,每个节点最多需要下降到其合适的位置,而每次下降的过程中,最多需要比较和交换节点的次数与树的高度成正比。树的高度通常为log(n),其中n是堆中的元素数量。
因此,对于n个元素的堆来说,最坏情况下,每个节点可能需要进行log(n)次比较和交换。由于堆中有n个节点,所以总的比较和交换次数为n乘以log(n),因此建堆的时间复杂度为O(nlog(n))。
然而,这是最坏情况的时间复杂度。在实际应用中,建堆的平均时间复杂度要小于O(nlog(n))。具体而言,通过巧妙的实现和优化技巧,可以将建堆的平均时间复杂度降低到O(n)。这是因为向下过程的时间复杂度取决于节点的高度,而大多数节点的高度都较小。
因此,总体而言,建堆的时间复杂度为O(n),但在最坏情况下可能达到O(nlog(n))。
参考如图所示:

三.堆的插入与删除
3.1堆的插入
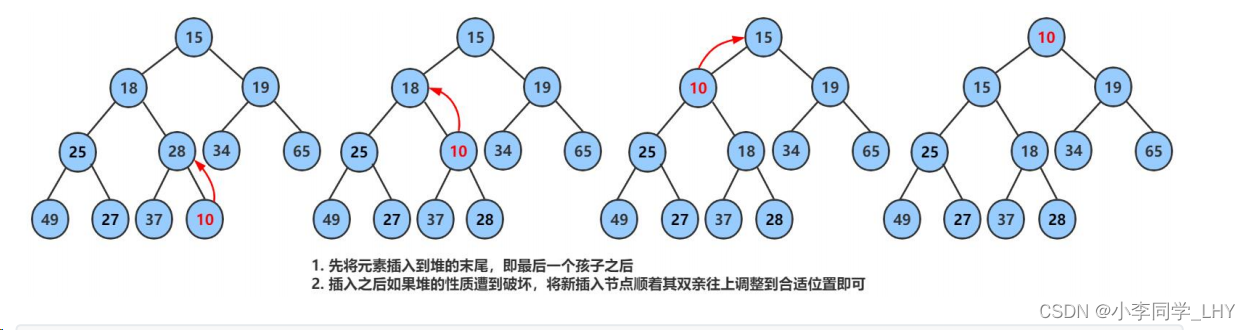
堆的插入操作:是将一个新元素插入到堆中,并保持堆的性质不变。通常,插入操作是在堆的最后一个位置进行。
以下是堆的插入操作的一般步骤:
- 将新元素插入到堆的最后一个位置。
- 将新元素与其父节点进行比较,如果新元素的值大于(或小于,具体取决于是最大堆还是最小堆)其父节点的值,则交换新元素与父节点的值。
- 更新新元素的位置为其父节点的位置。
- 重复步骤2和3,直到新元素的值小于(或大于)其父节点的值,或者新元素成为根节点。
- 插入操作完成。
注意:插入操作的时间复杂度为O(log(n)),其中n是堆中的元素数量。这是因为插入操作需要从新元素所在的位置向上迭代,最多迭代堆的高度次数,而堆的高度通常为log(n)。因此,插入操作的时间复杂度与堆的高度成正比。
参考图示如下:
参考代码如下:
public void shiftUp(int child) {
// 找到child的双亲
int parent = (child - 1) / 2;
while (child > 0) {
// 如果双亲比孩子大,parent满足堆的性质,调整结束
if (array[parent] > array[child]) {
break;
} else {
// 将双亲与孩子节点进行交换
int t = array[parent];
array[parent] = array[child];
array[child] = t;
// 小的元素向下移动,可能到值子树不满足对的性质,因此需要继续向上调增
child = parent;
parent = (child - 1) / 2;
}
}
}3.2堆的删除
堆的删除操作:将堆中的根节点删除,并保持堆的性质不变。在最大堆中,删除的是具有最大值的根节点;在最小堆中,删除的是具有最小值的根节点。
以下是堆的删除操作的一般步骤:
- 将根节点与堆中最后一个节点交换。
- 删除堆中的最后一个节点(即原根节点)。
- 对新的根节点执行向下过程(Heapify):
a. 比较当前节点与其子节点的值,并找到值最大(或最小)的子节点。如果有左子节点,其索引为2 * i + 1;如果有右子节点,则索引为2 * i + 2。
b. 如果当前节点的值小于(或大于)其最大(或最小)子节点的值,则交换当前节点与最大(或最小)子节点的值。
c. 更新当前节点的索引为最大(或最小)子节点的索引,即i的值更新为最大(或最小)子节点的索引。
d. 重复步骤a至c,直到节点i不再有子节点或其值大于(或小于)其子节点的值。 - 直至删除操作完成。
通过以上步骤,删除操作将原根节点移除,并将堆的最后一个节点放置到根的位置,然后通过向下过程将新的根节点下降到合适的位置,以满足堆的性质。
注意:删除操作的时间复杂度为O(log(n)),其中n是堆中的元素数量。这是因为删除操作需要执行一次交换操作,并对新的根节点执行向下过程,最多迭代堆的高度次数,而堆的高度通常为log(n)。因此,删除操作的时间复杂度与堆的高度成正比
参考图示如下:

参考代码如下:
public class MaxHeap {
private int[] heap;
private int size;
public MaxHeap(int capacity) {
heap = new int[capacity];
size = 0;
}
public void deleteMax() {
if (size == 0) {
System.out.println("Heap is empty.");
return;
}
// 将根节点与最后一个节点交换
int temp = heap[0];
heap[0] = heap[size - 1];
heap[size - 1] = temp;
size--;
// 执行向下过程
heapifyDown(0);
}
private void heapifyDown(int index) {
int parent = index;
while (true) {
int leftChild = 2 * parent + 1;
int rightChild = 2 * parent + 2;
int largest = parent;
// 比较当前节点与左子节点的值
if (leftChild < size && heap[leftChild] > heap[largest]) {
largest = leftChild;
}
// 比较当前节点与右子节点的值
if (rightChild < size && heap[rightChild] > heap[largest]) {
largest = rightChild;
}
// 如果当前节点不是最大值,则交换当前节点与最大子节点的值
if (largest != parent) {
int temp = heap[parent];
heap[parent] = heap[largest];
heap[largest] = temp;
// 更新当前节点,继续向下处理
parent = largest;
} else {
break; // 当前节点已经是最大值,停止循环
}
}
}
}3.3堆模拟实现优先级队列
优先级队列是根据元素的优先级进行排序的数据结构。堆是一种常用的实现优先级队列的数据结构。
堆的操作:
1. 添加元素:将新元素添加到堆的末尾,然后执行向上调整操作,将新元素上移至适当的位置,以满足堆的性质。
2. 删除元素:通常,优先级队列删除的是具有最高(或最低)优先级的元素。在最大堆中,删除根节点;在最小堆中,删除根节点。删除后,将堆的最后一个元素移至根节点的位置,然后执行向下调整操作,将根节点下移至适当的位置,以满足堆的性质。
堆的优势:
1. 堆能够在添加和删除元素时快速维护元素的优先级顺序。
2. 添加和删除元素的时间复杂度为O(log n),其中n是堆中元素的数量。
3. 堆可以使用数组或链表来实现,其中数组实现是最常见和高效的方法。
堆作为一种实现优先级队列的数据结构,具有高效的插入和删除操作,因此在许多应用中得到广泛应用,如任务调度、图算法等。
参考代码如下:
import java.util.*;
public class PriorityQueue<T> {
private PriorityQueueElement<T>[] heap; // 存储堆的数组
private int size; // 堆的当前大小
private int capacity; // 堆的容量
// 内部类,表示优先级队列中的元素
private static class PriorityQueueElement<T> {
private T item; // 元素值
private int priority; // 优先级
public PriorityQueueElement(T item, int priority) {
this.item = item;
this.priority = priority;
}
public T getItem() {
return item;
}
public int getPriority() {
return priority;
}
}
public PriorityQueue() {
capacity = 10; // 默认容量为10
size = 0;
heap = new PriorityQueueElement[capacity]; // 创建堆数组
}
public void enqueue(T item, int priority) {
if (size == capacity) { // 如果堆已满,则扩容
resizeHeap();
}
PriorityQueueElement<T> element = new PriorityQueueElement<>(item, priority);
heap[size] = element; // 将新元素添加到堆末尾
size++;
heapifyUp(size - 1); // 执行向上调整操作,以维护堆的性质
}
public T dequeue() {
if (isEmpty()) {
throw new NoSuchElementException("Priority queue is empty.");
}
T removedItem = heap[0].getItem(); // 记录被移除的元素
heap[0] = heap[size - 1]; // 将堆末尾元素移到根节点位置
size--;
heapifyDown(0); // 执行向下调整操作,以维护堆的性质
return removedItem;
}
public boolean isEmpty() {
return size == 0;
}
private void heapifyUp(int index) {
int parentIndex = (index - 1) / 2; // 计算父节点索引
while (index > 0 && heap[index].getPriority() > heap[parentIndex].getPriority()) {
swap(index, parentIndex); // 如果节点优先级大于父节点优先级,交换它们
index = parentIndex;
parentIndex = (index - 1) / 2;
}
}
private void heapifyDown(int index) {
int leftChildIndex = 2 * index + 1; // 计算左子节点索引
int rightChildIndex = 2 * index + 2; // 计算右子节点索引
int largestIndex = index;
if (leftChildIndex < size && heap[leftChildIndex].getPriority() > heap[largestIndex].getPriority()) {
largestIndex = leftChildIndex; // 如果左子节点优先级大于当前节点优先级,更新最大索引
}
if (rightChildIndex < size && heap[rightChildIndex].getPriority() > heap[largestIndex].getPriority()) {
largestIndex = rightChildIndex; // 如果右子节点优先级大于当前节点优先级,更新最大索引
}
if (largestIndex != index) {
swap(index, largestIndex); // 如果最大索引不是当前节点索引,交换它们
heapifyDown(largestIndex); // 递归向下调整
}
}
private void swap(int i, int j) {
PriorityQueueElement<T> temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
private void resizeHeap() {
capacity *= 2; // 扩大容量
heap = Arrays.copyOf(heap, capacity); // 创建新的堆数组
}
}我们使用一个数组来存储堆的元素,其中每个元素包含一个item和一个priority表示元素和其优先级。enqueue方法用于将元素加入队列,dequeue方法用于移除并返回具有最高优先级的元素,isEmpty方法用于检查队列是否为空。
在内部,我们使用heapifyUp方法来维护堆的性质,即将新加入的元素上移至适当的位置以满足堆的性质。我们还使用heapifyDown方法来维护堆的性质,在移除元素后将根节点下移至适当的位置。
四.常用接口介绍
4.1 PriorityQueue的特性
1.使用时必须导入PriorityQueue所在的包,即:
import java . util . PriorityQueue ;
// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());
p.offer(4);
p.offer(3);
p.offer(2);
p.offer(1);
p.offer(5);
System.out.println(p.peek());
}
}
4.2PriorityQueue中插入对象
class Card {
public int rank; // 数值
public String suit; // 花色
public Card(int rank, String suit) {
this.rank = rank;
this.suit = suit;
}
}
public class TestPriorityQueue {
public static void TestPriorityQueue() {
PriorityQueue<Card> p = new PriorityQueue<>();
p.offer(new Card(1, "♠"));
p.offer(new Card(2, "♠"));
}
public static void main(String[] args) {
TestPriorityQueue();
}
}
4.3对象的比较
class Card {
public int rank; // 数值
public String suit; // 花色
public Card(int rank, String suit) {
this.rank = rank;
this.suit = suit;
}
}
public class TestPriorityQueue {
public static void main(String[] args) {
Card c1 = new Card(1, "♠");
Card c2 = new Card(2, "♠");
Card c3 = c1;
//System.out.println(c1 > c2); // 编译报错
System.out.println(c1 ==c2);
// 编译成功 ----> 打印false,因为c1和c2指向的是不同对象
//System.out.println(c1 < c2); // 编译报错
System.out.println(c1 ==c3);
// 编译成功 ----> 打印true,因为c1和c3指向的是同一个对象
}
}// Object中equal的实现,可以看到:直接比较的是两个引用变量的地址
public boolean equals(Object obj) {
return (this == obj);
}4.3.1 覆写基类的equals
public class Card {
public int rank; // 数值
public String suit; // 花色
public Card(int rank, String suit) {
this.rank = rank;
this.suit = suit;
}
@Override
public boolean equals(Object o) {
// 自己和自己比较
if (this == o) {
return true;
}
// o如果是null对象,或者o不是Card的子类
if (o == null || !(o instanceof Card)) {
return false;
}
// 注意基本类型可以直接比较,但引用类型最好调用其equal方法
Card c = (Card)o;
return rank == c.rank
&& suit.equals(c.suit);
}
}- 如果指向同一个对象,返回 true
- 如果传入的为 null,返回 false
- 如果传入的对象类型不是 Card,返回 false
- 按照类的实现目标完成比较,例如这里只要花色和数值一样,就认为是相同的牌
- 注意下调用其他引用类型的比较也需要 equals,例如这里的 suit 的比较
4.3.2基于Comparble接口类的比较
public interface Comparable<E> {
// 返回值:
// < 0: 表示 this 指向的对象小于 o 指向的对象
// == 0: 表示 this 指向的对象等于 o 指向的对象
// > 0: 表示 this 指向的对象大于 o 指向的对象
int compareTo(E o);
}public class Card implements Comparable<Card> {
public int rank; // 数值
public String suit; // 花色
public Card(int rank, String suit) {
this.rank = rank;
this.suit = suit;
}
// 根据数值比较,不管花色
// 这里我们认为 null 是最小的
@Override
public int compareTo(Card o) {
if (o == null) {
return 1;
}
return rank - o.rank;
}
public static void main(String[] args) {
Card p = new Card(1, "♠");
Card q = new Card(2, "♠");
Card o = new Card(1, "♠");
System.out.println(p.compareTo(o)); // == 0,表示牌相等
System.out.println(p.compareTo(q)); // < 0,表示 p 比较小
System.out.println(q.compareTo(p)); // > 0,表示 q 比较大
}
}4.3.3基于比较器比较
- 用户自定义比较器类,实现Comparator接口
-
public interface Comparator<T> { // 返回值: // < 0: 表示 o1 指向的对象小于 o2 指向的对象 // == 0: 表示 o1 指向的对象等于 o2 指向的对象 // > 0: 表示 o1 指向的对象等于 o2 指向的对象 int compare(T o1, T o2); }注意: 区分 Comparable 和 Comparator 。 -
覆写 Comparator 中的 compare 方法
import java.util.Comparator; class Card { public int rank; // 数值 public String suit; // 花色 public Card(int rank, String suit) { this.rank = rank; this.suit = suit; } } class CardComparator implements Comparator<Card> { // 根据数值比较,不管花色 // 这里我们认为 null 是最小的 @Override public int compare(Card o1, Card o2) { if (o1 == o2) { return 0; } if (o1 == null) { return -1; } if (o2 == null) { return 1; } return o1.rank - o2.rank; } public static void main(String[] args) { Card p = new Card(1, "♠"); Card q = new Card(2, "♠"); Card o = new Card(1, "♠"); // 定义比较器对象 CardComparator cmptor = new CardComparator(); // 使用比较器对象进行比较 System.out.println(cmptor.compare(p, o)); // == 0,表示牌相等 System.out.println(cmptor.compare(p, q)); // < 0,表示 p 比较小 System.out.println(cmptor.compare(q, p)); // > 0,表示 q 比较大 } }
4.3.4 三种方式对比

- Comparble是默认的内部比较方式,如果用户插入自定义类型对象时,该类对象必须要实现Comparble接口,并覆写compareTo方法
- 用户也可以选择使用比较器对象,如果用户插入自定义类型对象时,必须要提供一个比较器类,让该类实现Comparator接口并覆写compare方法。
参考代码如下:
// JDK中PriorityQueue的实现:
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
// 默认容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 内部定义的比较器对象,用来接收用户实例化PriorityQueue对象时提供的比较器对象
private final Comparator<? super E> comparator;
// 用户如果没有提供比较器对象,使用默认的内部比较,将comparator置为null
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
// 如果用户提供了比较器,采用用户提供的比较器进行比较
public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
// 向上调整:
// 如果用户没有提供比较器对象,采用Comparable进行比较
// 否则使用用户提供的比较器对象进行比较
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
// 使用Comparable
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
// 使用用户提供的比较器对象进行比较
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
}五.堆的应用
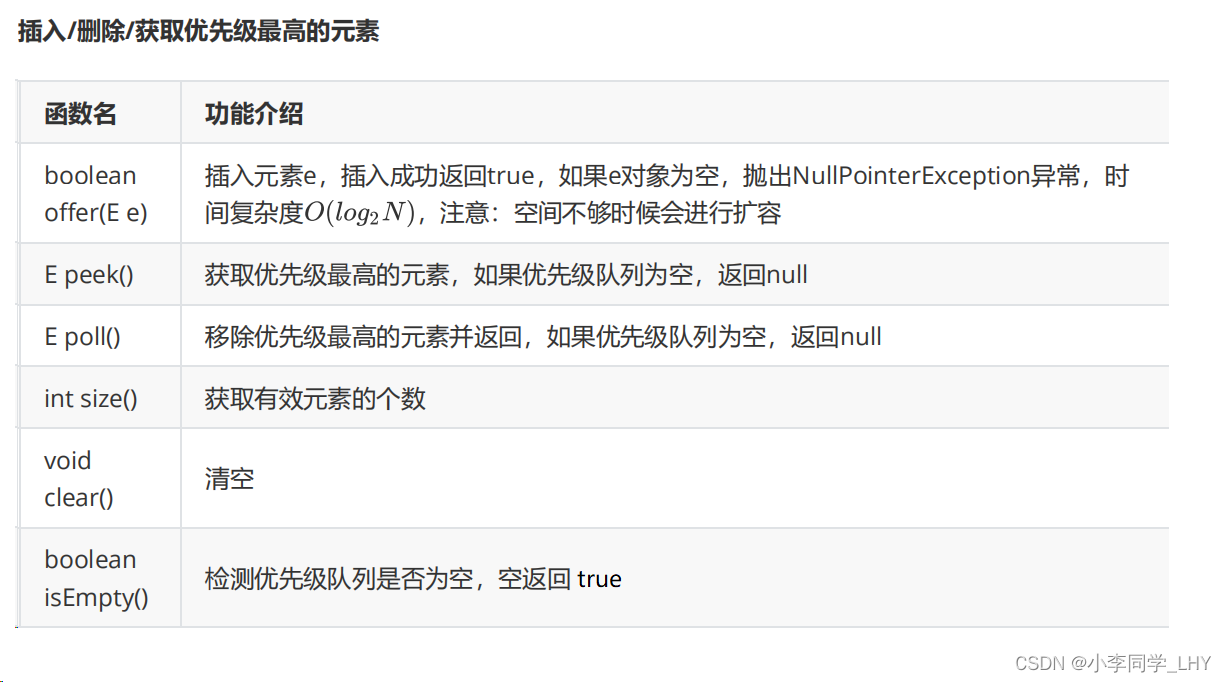
5.1常用函数名和功能介绍
参考代码如下:
static void TestPriorityQueue2() {
int[] arr = {4, 1, 9, 2, 8, 0, 7, 3, 6, 5};
// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好
// 否则在插入时需要不多的扩容
// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
for (int e : arr) {
q.offer(e);
}
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
// 从优先级队列中删除两个元素之和,再次获取优先级最高的元素
q.poll();
q.poll();
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
q.offer(0);
System.out.println(q.peek()); // 获取优先级最高的元素
// 将优先级队列中的有效元素删除掉,检测其是否为空
q.clear();
if (q.isEmpty()) {
System.out.println("优先级队列已经为空!!!");
} else {
System.out.println("优先级队列不为空");
}
}注意:以下是JDK 1.8中,PriorityQueue的扩容方式:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}- 如果容量小于64时,是按照oldCapacity的2倍方式扩容的
- 如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
- 如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
5.2堆排序
- 升序:建大堆
- 降序:建小堆
2.利用堆删除思想来进行排序
- 建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
参考图示如下:

5.3Top-k问题
1. 用数据集合中前K个元素来建堆
- 前k个最大的元素,则建小堆
- 前k个最小的元素,则建大堆
//使用比较器创建小根堆
class LessIntComp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
}
//使用比较器创建大根堆
class GreaterIntComp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}
public class TestDemo<E> {
//求最小的K个数,通过比较器创建大根堆
public static int[] smallestK(int[] array, int k) {
if (k <= 0) {
return new int[k];
}
GreaterIntComp greaterCmp = new GreaterIntComp();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(greaterCmp);
//先将前K个元素,创建大根堆
for (int i = 0; i < k; i++) {
maxHeap.offer(array[i]);
}
//从第K+1个元素开始,每次和堆顶元素比较
for (int i = k; i < array.length; i++) {
int top = maxHeap.peek();
if (array[i] < top) {
maxHeap.poll();
maxHeap.offer(array[i]);
}
}
//取出前K个
int[] ret = new int[k];
for (int i = 0; i < k; i++) {
int val = maxHeap.poll();
ret[i] = val;
}
return ret;
}
public static void main(String[] args) {
int[] array = {4, 1, 9, 2, 8, 0, 7, 3, 6, 5};
int[] ret = smallestK(array, 3);
System.out.println(Arrays.toString(ret));
}
}总结
总结起来,堆是一种强大而高效的数据结构,在计算机科学中扮演着重要的角色。通过了解堆的定义、性质和操作,我们深入探索了它在算法和数据处理中的应用。堆排序作为一种基于堆的排序算法,为我们提供了一种高效、可靠的排序解决方案。同时,堆还广泛应用于优先级队列、图算法等领域,为我们解决各种实际问题提供了强大的工具。
最后,感谢你阅读这篇关于堆数据结构的博客。希望这篇文章能为你提供有价值的信息,并激发你对堆的兴趣。如果你有任何问题、想法或反馈,欢迎留言与评论区。我期待着与你交流,一起深入探讨堆数据结构以及其他有关计算机科学的话题,愿读者收获满满!同时祝愿读者在未来的学习和实践中取得巨大的成功!






![[Linux开发工具]项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/direct/009748733d144146a5f72a3137987bb8.png)