解释器模式
1 解释器模式介绍
解释器模式使用频率不算高,通常用来描述如何构建一个简单“语言”的语法解释器。它只在一些非常特定的领域被用到,比如编译器、规则引擎、正则表达式、SQL 解析等。不过,了解它的实现原理同样很重要,能帮助你思考如何通过更简洁的规则来表示复杂的逻辑。
解释器模式(Interpreter pattern)的原始定义是:用于定义语言的语法规则表示,并提供解释器来处理句子中的语法。
我们通过一个例子给大家解释一下解释器模式
- 假设我们设计一个软件用来进行加减计算。我们第一想法就是使用工具类,提供对应的加法和减法的工具方法。
//用于两个整数相加的方法
public static int add(int a , int b){
return a + b;
}
//用于三个整数相加的方法
public static int add(int a , int b,int c){
return a + b + c;
}
public static int add(Integer ... arr){
int sum = 0;
for(Integer num : arr){
sum += num;
}
return sum;
}
+ -
上面的形式比较单一、有限,如果形式变化非常多,这就不符合要求,因为加法和减法运算,两个运算符与数值可以有无限种组合方式。比如: 5-3+2-1, 10-5+20…
文法规则和抽象语法树
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子.
在上面提到的加法/减法解释器中,每一个输入表达式(比如:2+3+4-5) 都包含了3个语言单位,可以使用下面的文法规则定义:
文法是用于描述语言的语法结构的形式规则。
expression ::= value | plus | minus
plus ::= expression ‘+’ expression
minus ::= expression ‘-’ expression
value ::= integer
注意: 这里的符号“::=”表示“定义为”的意思,竖线 | 表示或,左右的其中一个,引号内为字符本身,引号外为语法。
上面规则描述为 :
表达式可以是一个值,也可以是plus或者minus运算,而plus和minus又是由表达式结合运算符构成,值的类型为整型数。
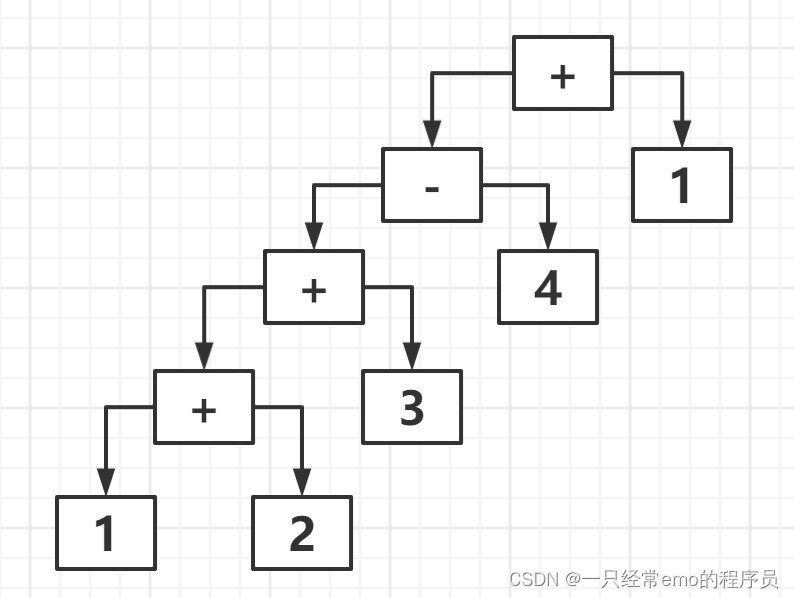
抽象语法树:
在解释器模式中还可以通过一种称为抽象语法树的图形方式来直观的表示语言的构成,每一棵抽象语法树对应一个语言实例,例如加法/减法表达式语言中的语句 " 1+ 2 + 3 - 4 + 1" 可以通过下面的抽象语法树表示
2 解释器模式原理
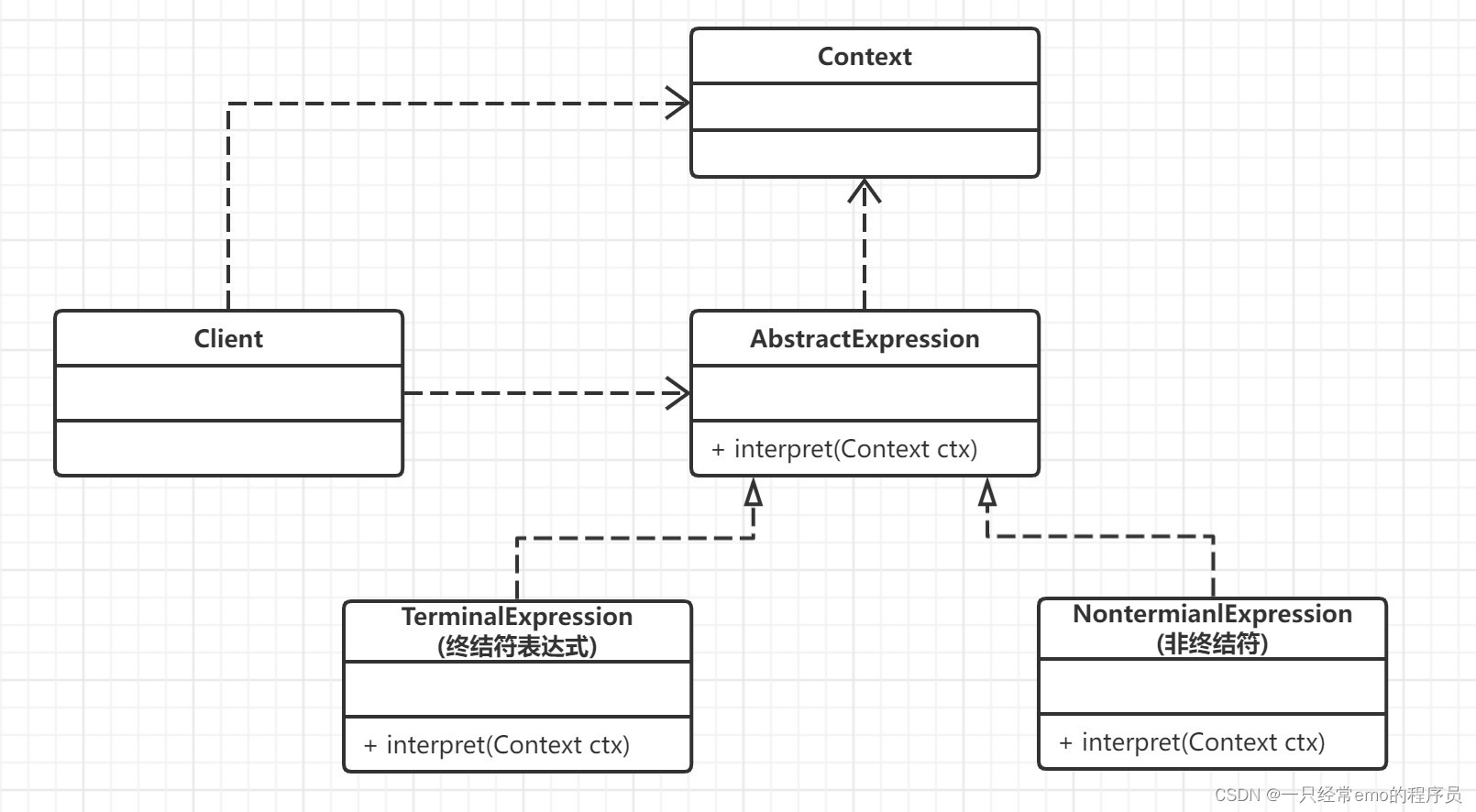
解释器模式包含以下主要角色。
- 抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。上例中的value 是终结符表达式.
- 非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。上例中的 plus , minus 都是非终结符表达式
- 环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
3 解释器模式实现
为了更好的给大家解释一下解释器模式, 我们来定义了一个进行加减乘除计算的“语言”,语法规则如下:
- 运算符只包含加、减、乘、除,并且没有优先级的概念;
- 表达式中,先书写数字,后书写运算符,空格隔开;
我们举个例子来解释一下上面的语法规则:
- 比如
“ 9 5 7 3 - + * ”这样一个表达式,我们按照上面的语法规则来处理,取出数字“9、5”和“-”运算符,计算得到 4,于是表达式就变成了“ 4 7 3 + * ”。然后,我们再取出“4 7”和“ + ”运算符,计算得到 11,表达式就变成了“ 11 3 * ”。最后,我们取出“ 11 3”和“ * ”运算符,最终得到的结果就是 33。
代码示例:
- 用户按照上 面的规则书写表达式,传递给 interpret() 函数,就可以得到最终的计算结果。
/**
* 表达式解释器类
**/
public class ExpressionInterpreter {
//Deque双向队列,可以从队列的两端增加或者删除元素
private Deque<Long> numbers = new LinkedList<>();
//接收表达式进行解析
public long interpret(String expression){
String[] elements = expression.split(" ");
int length = elements.length;
//获取表达式中的数字
for (int i = 0; i < (length+1)/2; ++i) {
//在 Deque的尾部添加元素
numbers.addLast(Long.parseLong(elements[i]));
}
//获取表达式中的符号
for (int i = (length+1)/2; i < length; ++i) {
String operator = elements[i];
//符号必须是 + - * / 否则抛出异常
boolean isValid = "+".equals(operator) || "-".equals(operator)
|| "*".equals(operator) || "/".equals(operator);
if (!isValid) {
throw new RuntimeException("Expression is invalid: " + expression);
}
//pollFirst()方法, 移除Deque中的第一个元素,并返回被移除的值
long number1 = numbers.pollFirst(); //数字
long number2 = numbers.pollFirst();
long result = 0; //运算结果
//对number1和number2进行运算
if (operator.equals("+")) {
result = number1 + number2;
} else if (operator.equals("-")) {
result = number1 - number2;
} else if (operator.equals("*")) {
result = number1 * number2;
} else if (operator.equals("/")) {
result = number1 / number2;
}
//将运算结果添加到集合头部
numbers.addFirst(result);
}
//运算完成numbers中应该保存着运算结果,否则是无效表达式
if (numbers.size() != 1) {
throw new RuntimeException("Expression is invalid: " + expression);
}
//移除Deque的第一个元素,并返回
return numbers.pop();
}
}
代码重构
上面代码的所有的解析逻辑都耦合在一个函数中,这样显然是不合适的。这 个时候,我们就要考虑拆分代码,将解析逻辑拆分到独立的小类中, 前面定义的语法规则有两类表达式,一类是数字,一类是运算符,运算符又包括加减乘除。 利用解释器模式,我们把解析的工作拆分到以下五个类:plu,sub,mul,div
- NumExpression
- PluExpression
- SubExpression
- MulExpression
- DivExpression
/**
* 表达式接口
**/
public interface Expression {
long interpret();
}
/**
* 数字表达式
**/
public class NumExpression implements Expression {
private long number;
public NumExpression(long number) {
this.number = number;
}
public NumExpression(String number) {
this.number = Long.parseLong(number);
}
@Override
public long interpret() {
return this.number;
}
}
/**
* 加法运算
**/
public class PluExpression implements Expression{
private Expression exp1;
private Expression exp2;
public PluExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() + exp2.interpret();
}
}
/**
* 减法运算
**/
public class SubExpression implements Expression {
private Expression exp1;
private Expression exp2;
public SubExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() - exp2.interpret();
}
}
/**
* 乘法运算
* @author spikeCong
**/
public class MulExpression implements Expression {
private Expression exp1;
private Expression exp2;
public MulExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() * exp2.interpret();
}
}
/**
* 除法
**/
public class DivExpression implements Expression {
private Expression exp1;
private Expression exp2;
public DivExpression(Expression exp1, Expression exp2) {
this.exp1 = exp1;
this.exp2 = exp2;
}
@Override
public long interpret() {
return exp1.interpret() / exp2.interpret();
}
}
//测试
public class Test01 {
public static void main(String[] args) {
ExpressionInterpreter e = new ExpressionInterpreter();
long result = e.interpret("6 2 3 2 4 / - + *");
System.out.println(result);
}
}
4 解释器模式总结
- 解释器优点
-
易于改变和扩展文法
因为在解释器模式中使用类来表示语言的文法规则的,因此就可以通过继承等机制改变或者扩展文法.每一个文法规则都可以表示为一个类,因此我们可以快速的实现一个迷你的语言
-
实现文法比较容易
在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂
-
增加新的解释表达式比较方便
如果用户需要增加新的解释表达式,只需要对应增加一个新的表达式类就可以了.原有的表达式类不需要修改,符合开闭原则
- 解释器缺点
-
对于复杂文法难以维护
在解释器中一条规则至少要定义一个类,因此一个语言中如果有太多的文法规则,就会使类的个数急剧增加,当值系统的维护难以管理.
-
执行效率低
在解释器模式中大量的使用了循环和递归调用,所有复杂的句子执行起来,整个过程也是非常的繁琐
- 使用场景
- 当语言的文法比较简单,并且执行效率不是关键问题.
- 当问题重复出现,且可以用一种简单的语言来进行表达
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象的语法树的时候


![[Linux开发工具]项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/direct/009748733d144146a5f72a3137987bb8.png)