DFM:A Performance Baseline for Deep Feature Matching(深度特征匹配的性能基准)
2021.06.14
摘要
提出了一种新的图像匹配方法,利用现成的深度神经网络提取的学习特征来获得良好的图像匹配效果。该方法使用预训练的VGG结构作为特征提取器,不需要任何额外的训练来提高匹配。灵感来自心理学领域成熟的概念,如心理旋转,初始扭曲是作为初步几何变换估计的结果而执行的(an initial warping is performed as a result of a preliminary geometric transformation estimate),这些估计仅仅是基于待匹配图像的VGG网络输出终端层最近邻的密集匹配,在初始对齐之后,以分层方式在参考图像和对齐图像之间再次重复相同的方法,以达到良好的定位和匹配性能。我们的算法在 Hpatches 数据集 [4] 上分别针对 1 像素和 2 像素阈值的平均匹配精度 (MMA) 获得了 0.57 和 0.80 的总体得分,这表明比最先进的技术有更好的性能。
我们提出了一种不需要任何训练就能在图像之间找到高质量对应关系的方法,我们首先利用深层特征在语义的层面上找到图像之间的匹配;然后,我们获得图像之间的几何变换的粗略估计,以应用初始扭曲转变换,就像是心理上对图像的旋转;在对其中一幅图像进行变换后,我们执行分层匹配,这也是一种众所周知的技术,从特征映射的最深层到最浅层。通过这种从粗到精的策略,我们基本上利用了所有层的属性,例如深层的强大语义属性和浅层的精确定位。
文章的三个主要贡献点:
1)我们证明了对预训练网络(如冻结的VGG)的终端层的深层特征进行简单的密集近邻搜索仍然可以获得足够的匹配,以获得几何变换和光照不变性匹配;
2)我们还证明,在初步步骤中通过几何变换和扭曲进行粗略对齐后,以分层方式模仿前一阶段的后续块的图像匹配性能可以从终端层中细化密集匹配的位置,从而获得最先进的性能;
3)该方法使用现成的深度特征提取器,无需训练,仅采用标准技术,为基于学习的图像匹配方法提供了性能基准。
1、方法实现
我们提出了一个两阶段的架构来执行两个图像之间的匹配,我们的关键思想是用预训练的网络提取特征,用粗糙的几何变换估计对齐图像,然后应用粗到细的策略来更好地定位。
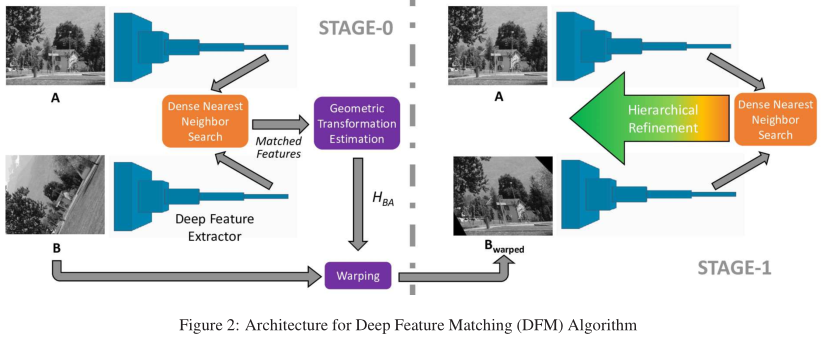
在阶段0中,我们在低空间分辨率下执行密集最近邻搜索(DNNS)得到给定图像之间几何变换的粗略估计,使用这个估计,我们扭曲第二张图像,形成我们接下来使用的图像;在Stage-1中,我们首先在最后一层使用参考图像和扭曲图像的特征映射执行DNNS,从这些粗匹配开始,我们通过在每一步移动到更精细的分辨率来分层地细化匹配。
2、密集近邻搜索
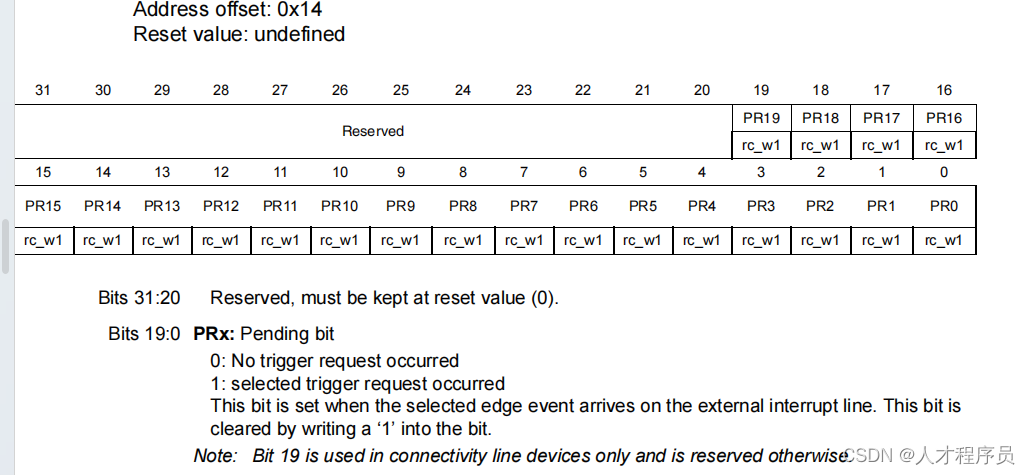
密集近邻搜索(Dense Nearest Neighbor Search (DNNS)),对于两幅图像提取特征块Fa、Fb,DNNS搜索Fa、Fb中每个点的最佳匹配,使用 l2 距离描述,如果两个特征块对对应点pa、pb的距离比例大于给定阈值,则认为两点匹配。
我们首先使用DNNS在特征提取器的终端层初始化匹配,请注意,这一层的下采样大小使它们适合于DNSS。对于VGG特征提取器,第5层卷积特征映射的大小为W/16 × H/16,其中W和H为图像的原始宽度和高度,这使得DNNS是可行的,我们还使用DNNS在更精细的空间分辨率下细化匹配。
3、分层细化
分层细化(Hierarchical Refinement Alternative, HRA),深层DNNS的输出对几何变换和光照变化具有较强的鲁棒性,但其局部特征较差,直接将它们上采样到原始分辨率将产生较差的匹配性能。
DNNS可以被用在任何一层,HRA在一个局部区域(论文中为2x2)使用DNNS,逐步优化。具体实施:

HRA通过选择正确的匹配和拒绝异常值来改变每个细化步骤中特征点的数量,换句话说,期望正确和健壮的匹配能够存活下来,甚至可以通过分层细化进行填充,而期望拒绝异常值,如图3所示。

如图所示,在Layer-5中存在一些定位不佳的匹配。在Layer-4层,匹配次数有所增加,但其定位仍然较差。向前移动到Layer-3层,匹配点的定位要好得多,但仍然存在一些错误的匹配。(注意从上到下的第二个和第三个匹配)注意,这些异常值在Layer-2中也被拒绝。最后,我们做出了更好的本地化和Layer-1层匹配更精确。
4、两阶段法
给定图像对,可以通过使用预训练的特征提取器提取特征,在终端层执行DNNS初始化匹配对,并使用HRA将其细化到原始分辨率。--步骤1
然而,我们意识到,在严重的几何变换情况下,这种一步解决方案在分层精化过程中会失败。这一结果是由于较浅层的特征对几何变换的鲁棒性不如较深层;我们还观察到,即使该方法能够在较深的层上生成正确的匹配,这些匹配在向较浅的层移动时也会被消除。为了克服这一问题,我们首先利用深层的匹配点集预测一个单应矩阵Hba,并利用Hba对图像B进行变换,得到变换后图像Bw。接下来,我们使用参考图像A和Bw应用上述方法(步骤1方法)。使用这种方法,我们首先有效地对齐两幅图像,然后寻找可能的匹配。
5、实验与评估
测试数据集:HPatches,包含116个序列,每个序列含6个来自不同视角的相似场景。
5.1、特征匹配
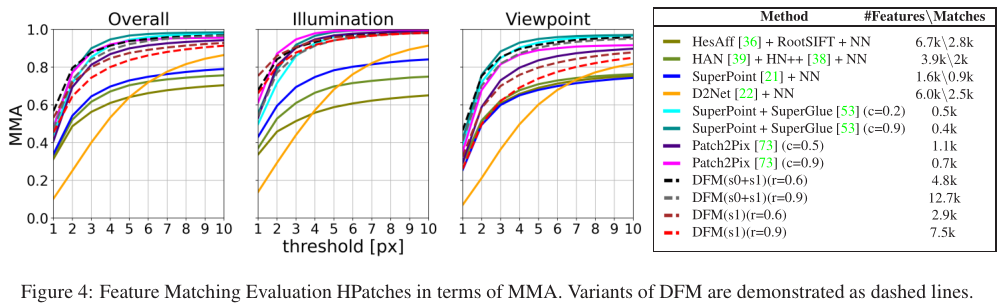
各种方法的结果如图4所示,并给出了匹配的特征数量,其中 r 为超参数。
5.2、H矩阵估计
我们还发布了10次重复测试中每对最佳结果(boe)和每对最差结果(woe)的最大和最小可能结果。参数及测试方法对结果影响较大。
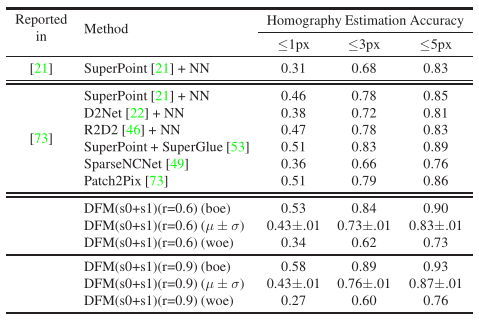
为每个图像对选择最佳结果(boe)和最差结果(woe)会导致显著偏差。R为使用比率测试阈值。
参考文章:
1、代码仓库
GitHub - ufukefe/DFM: Python (Pytorch) and Matlab (MatConvNet) implementations of CVPR 2021 Image Matching Workshop paper DFM: A Performance Baseline for Deep Feature Matching
2、CVPRW21 - 深度特征匹配 DFM
【图像配准】CVPRW21 - 深度特征匹配 DFM_深度学习图像配准-CSDN博客
3、基于强化学习的图像配准 - Image Registration: Reinforcement Learning Approaches
https://www.cnblogs.com/algor-luoziwei/articles/16212472.html
4、基于深度学习的配准框架
基于深度学习的配准框架_深度学习 融合配准-CSDN博客
5、SuperPoint 与 SuperGlue。