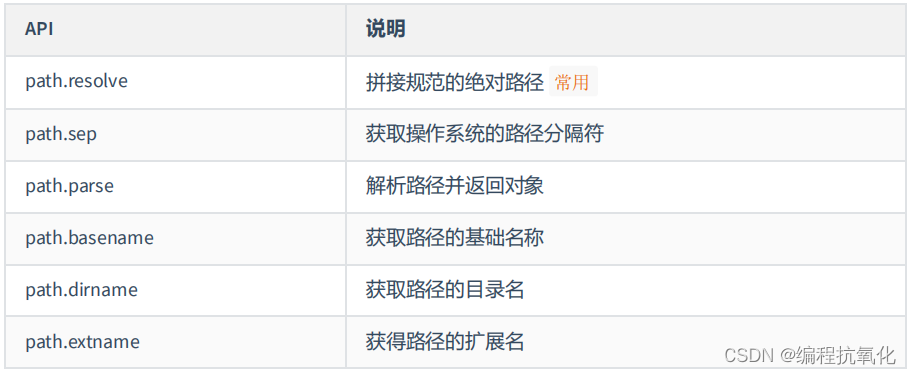
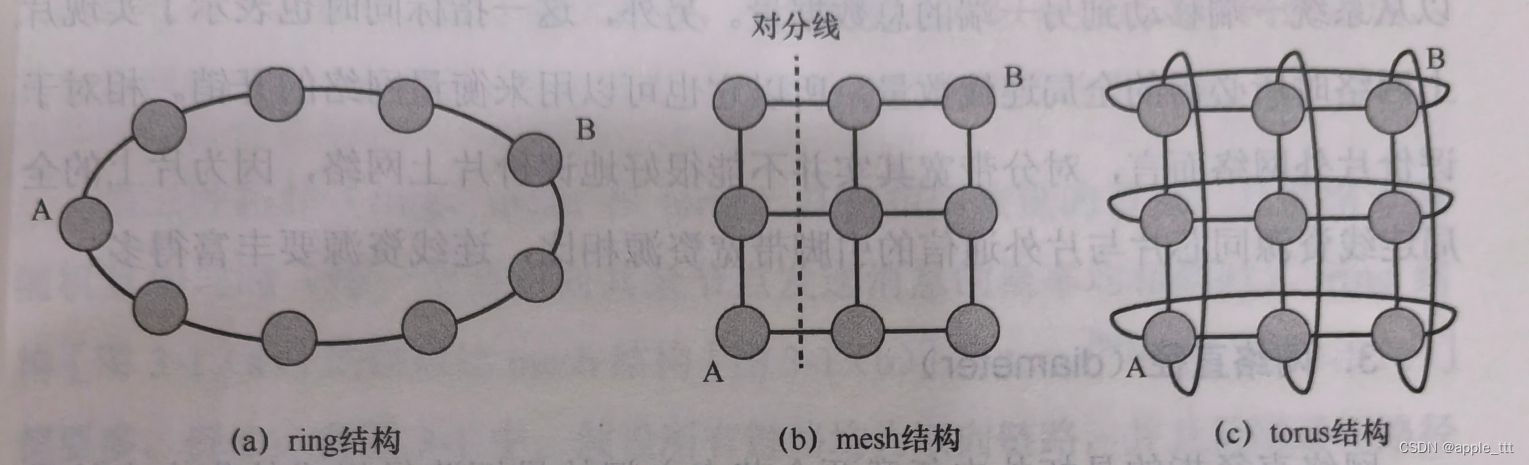
目录
介绍:
one-hot:
pad_sequences:
建模:
介绍:
Word Embedding是一种将单词表示为低维稠密向量的技术。它通过学习单词在文本中的上下文关系,将其映射到一个连续的向量空间中。在这个向量空间中,相似的单词在空间中的距离也比较接近,具有相似含义的单词在空间中的方向也比较一致。
Word Embedding可以通过各种方法来实现,包括基于统计的方法(如Word2Vec和GloVe)和基于神经网络的方法(如Skip-gram和CBOW模型)。这些方法通常使用大量的文本语料库来学习单词的向量表示。
Word Embedding在自然语言处理任务中广泛应用,如文本分类、情感分析、机器翻译等。由于Word Embedding能够捕捉到单词之间的语义关系,使得计算机能够更好地理解和处理自然语言。
one-hot:
from tensorflow.keras.preprocessing.text import one_hot中的one_hot函数用于将文本数据进行one-hot编码。在自然语言处理任务中,文本通常需要进行预处理和编码才能用于训练模型。其中,one-hot编码是一种常用的文本编码方式,它将每个单词映射到一个唯一的整数索引,并将索引表示为一个独热向量。独热向量是一个稀疏向量,只有一个元素为1,其余元素为0,该元素的位置对应着单词的索引。
通过使用
one_hot函数,可以将文本数据中的单词转换为对应的整数索引,方便后续处理和模型训练。该函数接受两个参数:文本数据和词汇表大小。它会根据词汇表的大小,将文本数据中的每个单词映射到一个唯一的整数索引,并返回一个编码后的整数列表。这些整数可以用作模型的输入或特征表示。
### sentences
sentences=[ 'the glass of milk',
'the glass of juice',
'the cup of tea',
'I am a good boy',
'I am a good developer',
'understand the meaning of words',
'your videos are good',]
### Vocabulary size
voc_size=10000
onehot_repr=[one_hot(words,voc_size) for words in sentences]
print(onehot_repr)
'''结果:
[[1607, 1898, 6281, 9401], [1607, 1898, 6281, 3401], [1607, 6359, 6281, 2217], [7508, 378, 2733, 8693, 7438], [7508, 378, 2733, 8693, 5363], [8292, 1607, 4448, 6281, 8555], [1825, 3648, 3717, 8693]]'''pad_sequences:
pad_sequences函数是用于将序列数据进行填充(Padding)或截断(Truncation)的方法。在自然语言处理任务中,文本通常是以序列的形式表示的,例如句子或文档中的单词序列。这些序列的长度可能不一致,为了在神经网络中进行处理,需要将它们转换为相同长度的序列。
pad_sequences函数可以根据指定的最大长度对序列进行填充或截断操作。如果序列长度小于最大长度,则会在序列的末尾添加特定的填充值(通常是0),使得序列长度与最大长度相同。如果序列长度大于最大长度,则会从序列的末尾进行截断,使得序列长度与最大长度相同。
填充或截断序列可以确保在输入神经网络之前,所有的序列具有相同的长度。这对于训练机器学习模型非常重要,因为神经网络需要一个固定长度的输入。此外,在进行批量训练时,将数据转换为相同长度的序列可以提高计算效率。
from tensorflow.keras.layers import Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
import numpy as np
sent_length=8
embedded_docs=pad_sequences(onehot_repr,padding='pre',maxlen=sent_length)
print(embedded_docs)
'''结果:
[[ 0 0 0 0 1607 1898 6281 9401]
[ 0 0 0 0 1607 1898 6281 3401]
[ 0 0 0 0 1607 6359 6281 2217]
[ 0 0 0 7508 378 2733 8693 7438]
[ 0 0 0 7508 378 2733 8693 5363]
[ 0 0 0 8292 1607 4448 6281 8555]
[ 0 0 0 0 1825 3648 3717 8693]]
'''建模:
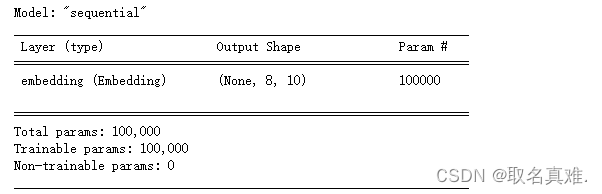
dim=10
model=Sequential()
model.add(Embedding(voc_size,dim,input_length=sent_length))
model.compile('adam','mse')
model.summary()