论文标题:Interactive Language: Talking to Robots in Real Time
论文作者:Corey Lynch, Ayzaan Wahid, Jonathan Tompson Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, Pete Florence
作者单位:Robotics at Google
论文原文:https://arxiv.org/abs/2210.06407
论文出处:–
论文被引:–(01/05/2024)
项目主页:https://interactive-language.github.io/
论文代码:https://github.com/google-research/language-table
Abstract
我们提出了一个在现实世界中构建交互式,实时,自然语言可指令机器人的框架,并开放了相关资产(数据集,环境,基准和策略)。在一个包含数十万条语言标注轨迹(trajectories)的数据集上进行行为克隆训练后,所生成的策略能熟练执行的指令数量比以前的工作多出一个数量级:具体来说,我们估计在一组包含 87,000 条独特自然语言字符串的数据集上成功执行指令的成功率为 93.5%,这些字符串指定了真实世界中原始的端到端视觉-语言-运动技能(visuo-linguo-motor skills)。我们发现,人类能够通过实时语言指导相同的策略,以实现各种精确的长视距(long-horizon)重新排列目标,例如 “用积木拼出笑脸”。我们发布的数据集包括近 600,000 个语言标记轨迹,比之前可用的数据集大一个数量级。
I. INTRODUCTION

至少从 20 世纪 60 年代末开始的 SHRDLU[1]实验以来,制造一个能够遵循各种自然语言指令的机器人一直是人工智能研究的长期目标。虽然最近关于这一主题的研究非常丰富[2]-[9],但真正能制造出 (i) 存在于现实世界中,(ii) 能够对大量丰富多样的语言指令做出响应的机器人却少之又少。我们预计,未来的研究将继续通过对原始技能进行排序[10]或增加原始技能本身的数量[11],来产生更大,更多样化的行为集。不过,我们还关注 (iii) 遵循交互式语言指令的能力,即机器人能够对正在执行的任务中提供的新的自然语言指令做出即时反应。虽然我们可能会期待这样的机器人在当前的方法下是可能的,但在实践中,可进行自然语言交互的机器人往往速度很慢,而且经常使用阻塞性参数化技能 [7], [10] 或简化的自复位行为 [9], [12],从而禁止了这种现场实时交互。
在本文中,我们展示了一个用于制造真实世界中可实时交互的自然语言可指导机器人的框架(图 1a),从某些指标来看,该框架的运行规模要比之前的工作大一个数量级。为了加快这方面的进一步研究,我们开源了数据集,模型,硬件环境描述,仿真环境以及语言条件操作的研究基准(图 1c)。就规模而言,所生成的机器人策略可以处理 87,000 条独特的指令,成功率估计为 93.5%(图 1b),具有连续的 5Hz 视觉语言运动控制能力,并且能够将原始技能串联起来,以实现环境中成千上万的长期目标。
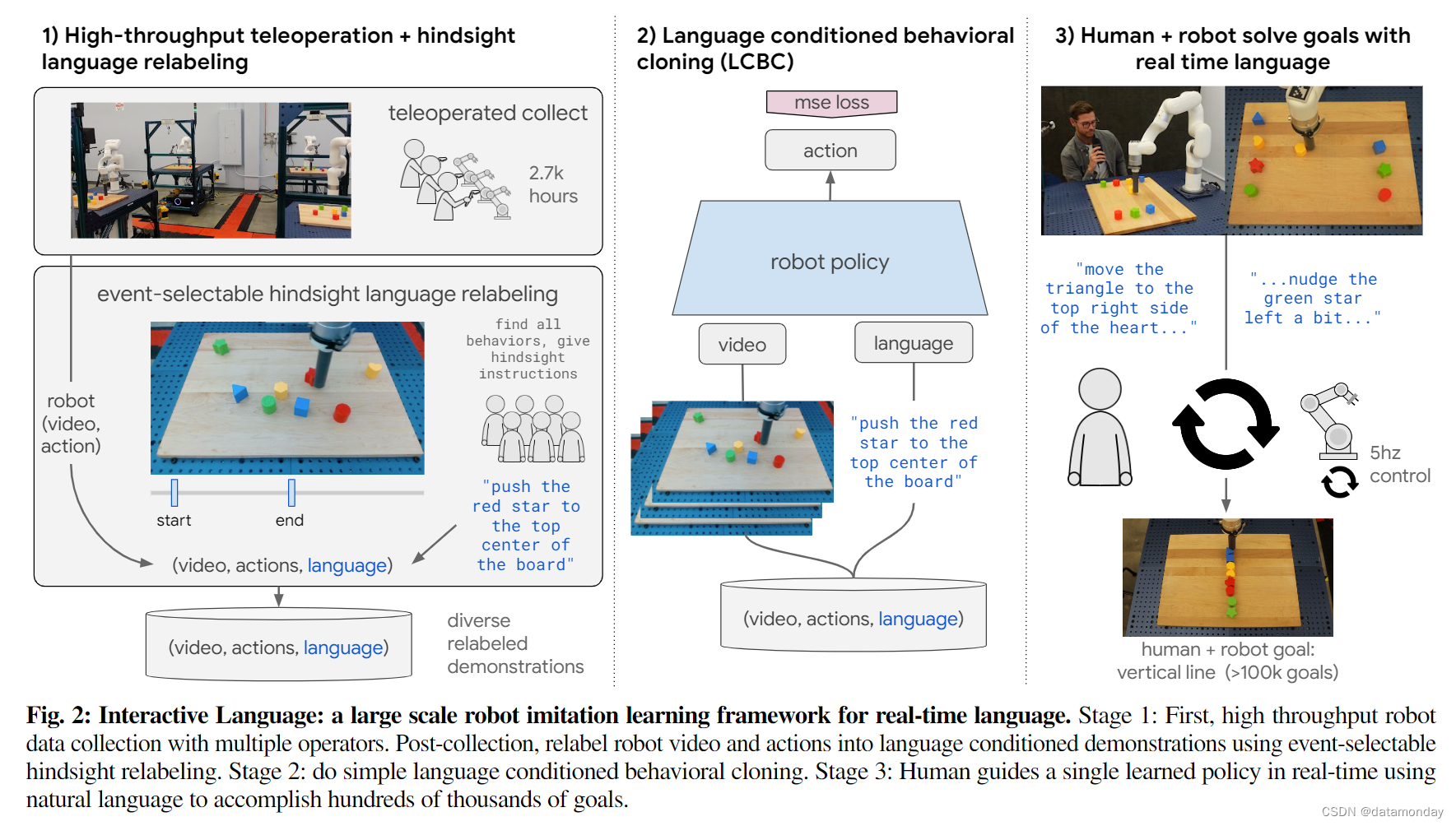
这个机器人所处的环境是我们设计的,它提供了一个可控但困难的挑战水平(从像素感知,反馈丰富的控制,多个物体,含糊不清的自然语言指令)。我们将实时语言引导作为一个大规模的模仿学习问题 [11],[13],[14](图 2)。学习算法本身有意简单化,这项工作的复杂性主要体现在数据工作本身,我们将详细介绍这方面的见解和技术。我们希望该数据集和基准可以促进进一步的工作,从而提高我们所展示的样本复杂性和性能。
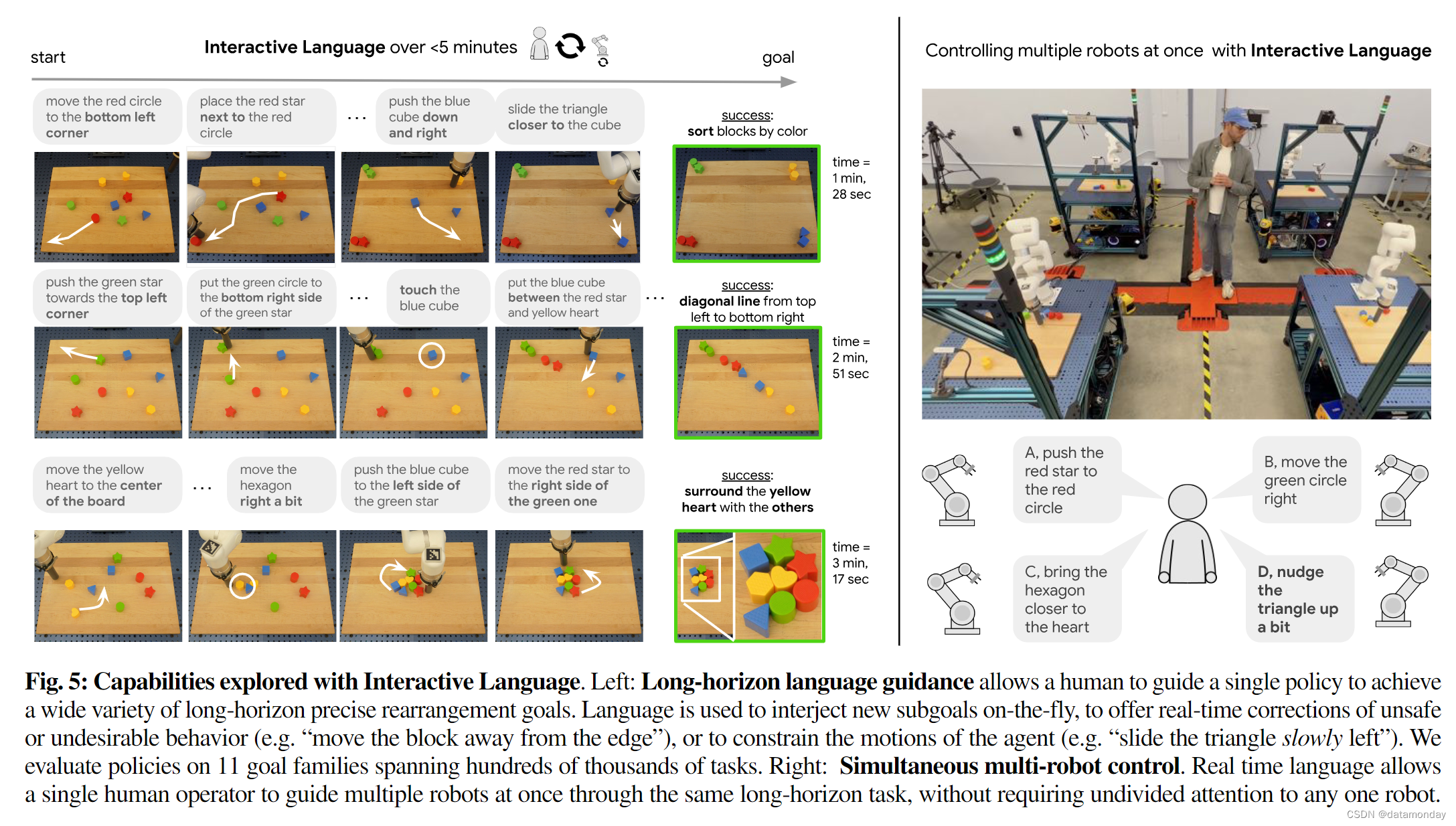
除了展示各种短视距(short-horizon)技能外,我们还利用这些能力来研究实时语言机器人的非显性优势。首先,我们展示了通过偶尔的人类自然语言反馈,机器人可以完成复杂的长视距重排,例如 “将积木拼成一个带绿色眼睛的笑脸”,这需要多分钟的精确协调控制(图 5 左)。我们还发现,实时语言能力还能释放出新的能力,如同时进行多机器人指令——在这种情况下,一个人可以引导多个实时机器人完成长视距任务(图 5 右)。
贡献。我们的主要贡献包括:
- (i) 交互式语言(Interactive Language),这是一个生成现实世界机器人的框架,可以在执行连续控制的视觉运动操作的同时实时捕获交互式开放词汇语言条件。交互式语言结合了现有的技术和新颖的组件,如事件可选择的事后重新标记,从而为学习大量可调节自然语言的技能提供了一个简单且可扩展的方法。
- (ii) 我们利用该系统提出并研究了交互式语言指导的设置,表明实时语言反馈与低层次语言可调节策略的结合可以解决桌面重排(Rearrangement)设置中的长视距操作目标状态。
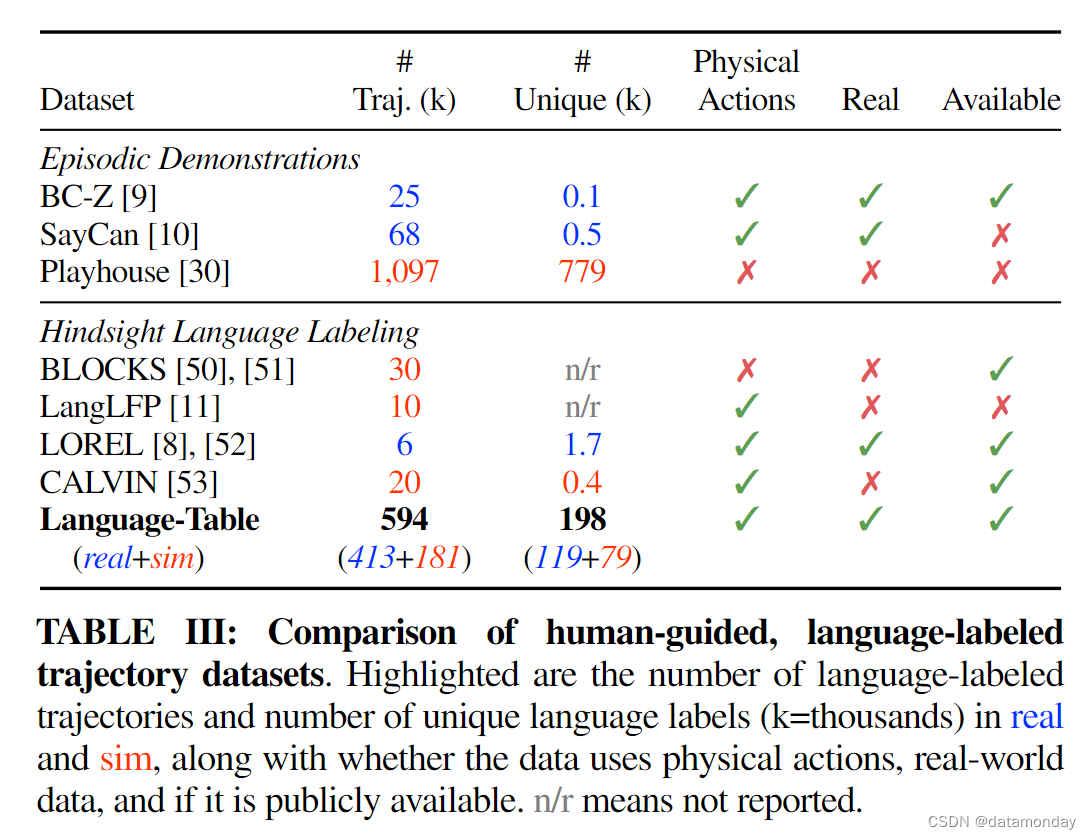
- (iii) 为促进该领域的未来研究,我们发布了 Language-Table,这是一个数据集和模拟多任务模仿学习基准。据我们所知,Language-Table 在模拟和现实世界中拥有近 600,000 个不同的演示,是同类中最大的自然语言条件模仿学习数据集(表 III)。
II. RELATED WORK
From single-task imitation to multi-task and language conditioning.
模仿学习([14])是我们在这项工作中采用的视角,它为机器人从人类专家的演示中获取行为提供了一种简单而稳定的方法。从历史上看,模仿学习一直被应用于从仪器状态[16]-[19]中获取单个任务,而对更通用机器人的渴望促使人们研究能够同时从更通用的机载感官观测(如 RGB 像素)中学习多种技能的策略[20]-[22]。为了给多种学习行为提供条件,先前的设置依赖于离散的单次任务标识符 [23],这很难扩展到许多任务,或者目标图像 [24]-[26],这在现实世界中可能无法提供。另外,在更广泛的人工智能研究领域[1]-[6], [11],长期以来一直在寻求一种更方便的自然语言调节规范形式([27]),并在物理机器人上取得了一些成果[7]-[9], [12]。这种关注产生了许多不同的,令人印象深刻的方法来解决可执行问题(grounding problem)[1], [28]——学会将语言与人的具身观察和行动(embodied observations and actions)联系起来。然而,在模拟和现实世界中,指令跟随型机器人很少利用连续控制的全部功能,而是采用简化的,参数化的行动空间 [6], [7], [29], [30]。此外,在机器人执行过程中,语言条件一旦提供,通常就会被假定为固定不变 [8]-[10], [12],指导者几乎没有机会进行后续互动。与此相反,我们的工作研究的是,首次结合实时自然语言指导物理机器人进行连续视觉运动操作(continuous visuomotor manipulation)。
Interactively guiding robot behavior with language.
我们的工作是在人类修改或纠正自主Agent行为的大背景下进行的[31],历史上曾以远程操作[32]-[34],动觉教学[35]或稀疏人类偏好反馈[36]等形式进行过研究。某些著作将语言作为一种矫正手段进行了研究,但通常都是在简化假设的基础上进行的,而我们在当前的研究中则放宽了这些假设。例如,文献[37],[38],[39]和[40]研究了语言矫正,但都是在以下各自的简化假设下进行的:手动定义的可执行优化,操作员注意力不分散,训练时的成对迭代矫正,以及假定可访问运动规划器和任务成本函数。此外,据我们所知,这些工作都不支持在执行过程中进行多频率迭代规范。与我们的方法最接近的是文献[11]和[30],它们研究的是通过模仿学习的语言交互式Agent,但完全是在模拟和不同程度的执行真实度下进行的。与这些研究不同的是,我们的工作以简单的行为克隆为目标,从 RGB 像素到连续控制输出端到端学习实时自然语言策略[13],并将其应用于接触丰富的真实世界操作任务中。
Scaling real world imitation learning.
机器人模仿的最大瓶颈之一往往只是可供学习的各种机器人数据量[9],[22],[23]。许多多任务模仿学习框架都预先确定了要学习的任务集 [7], [9], [10], [12], [14]。虽然这在概念上简化了收集工作,但通常也需要为每种行为手动设计重置协议和成功标准。大规模多操作员收集的另一个特殊挑战是,通常并非所有数据都能被视为最优数据[41],[42],这往往需要人工进行事后成功筛选[9],[10]。这些按任务进行的人工操作历来难以扩展到大型,多样化的任务环境,就像本研究中的任务环境一样。我们通过让操作员持续远程操作长视距行为,而不要求低层次任务分割或重置 [11], [25], [43],然后利用事后众包语言注释 [8], [11],从而避免了这两个扩展问题。与文献[11]中探讨的随机窗口重新标注不同,我们让标注者精确控制标注行为的开始和结束时间,我们发现这在实践中能更好地将重新标注的训练数据与测试时给出的实际指令相一致。
III. PROBLEM SETUP
我们的目标是训练一个以 θ 为参数的条件策略 π θ ( a ∣ s , l ) π_θ (a|s,l) πθ(a∣s,l),它可以将观察结果 s∈S 和人提供的语言 l∈L 映射到物理机器人上的动作 a∈A 上。我们尤其对开放词汇语言条件视觉运动策略感兴趣,在这种策略中,观察空间包含高维 RGB 图像,例如 S = RH×W ×C ,而语言条件 L 没有预定义模板,语法或词汇。我们还对允许人类以视觉-语言-运动策略的自然速率随时插入新语言 L 特别感兴趣。每个指令l都编码了环境中可实现目标 gshort ∈ Gshort 的分布。需要注意的是,人类可能会根据自己对环境的感知(sH∈SH)生成新的语言指令 l,这种感知可能与机器人的 s∈ S 有很大不同(例如,由于视角,自我封闭,观察记忆有限等原因)。与之前的研究[11]一样,我们将自然语言条件下的视觉运动技能学习视为情境模仿学习问题[14]。因此,我们获取了一个离线数据集D,其中包含成对的有效示范及其解决的条件 {(τ,l)i}Di=0。 每个 τi 是机器人观察和动作的可变长度轨迹 τi =[(s0,a0),(s1,a1),…,(sT)],每个 li 以第二人称命令的形式描述了整个轨迹。
IV. INTERACTIVE LANGUAGE: METHODS AND ANALYSIS
首先,我们介绍交互语言(如图 2 所示),这是一个简单,通用的模仿学习框架,用于训练实时自然语言交互机器人。交互式语言结合了一种可扩展的方法,用于收集各种真实世界的语言条件演示数据集,以及直接的语言条件行为克隆(language conditioned behavioral cloning,LCBC)。

A. Data Collection
High throughput raw data collection.
交互式语言有目的地采用了最少的收集假设,以最大限度地将人类的示范行为转化为学习行为。操作员不断地远程操作各种长期行为,而不需要低层次的任务定义,分割或情节重置。这一策略与 “游戏” 收集[25]有着相同的假设,但它还能引导收集向时间扩展的低熵状态(如线条,形状和复杂排列)发展。每个收集情节在休息前持续 10 分钟,由多个随机选择的长视距提示 p∈P(例如 “用积木拼出一个正方形”)引导,这些提示来自目标长视距目标集,远程操作者可以自由选择遵循或忽略。我们并不假设为每个提示 p 收集的所有数据都是最优的(每个 p 在收集后都会被丢弃)。在实践中,我们的收集包括许多不可避免的边缘情况,否则可能需要进行数据清理,例如求解错误的 p 或将积木从桌面上打掉。我们会记录所有这些情况,并在以后将其作为训练数据。具体来说,这个收集过程会产生一个半结构化,与优化无关的收集 D c o l l e c t = { τ i } i = 0 D c o l l e c t \mathcal{D}_{collect} = \{τ_i\}^{D_{collect}}_{i=0} Dcollect={τi}i=0Dcollect 。Dcollect 的目的是为众包事后语言重标注[8], [11]提供一个足够多样化的基础。
Event-selectable hindsight relabeling.
我们将 Dcollect 转换为自然语言条件演示 D t r a i n i n g = { ( τ , l ) i } i = 0 D t r a i n i n g \mathcal{D}_{training} =\{(τ,l)_i\}^{D_{training}}_{i=0} Dtraining={(τ,l)i}i=0Dtraining,使用一种新的后视语言重标注变体 [11],我们称之为事件可选后视重标注(图 2 左)。之前的 随机窗口重标注系统[8],[11]至少有两个缺点:每个随机窗口都不能保证包含可有用描述的动作,而且随机窗口长度必须作为一个敏感的超参数预先确定。相反,我们要求注释者观看完整的收集视频,然后找出 K 个连贯的行为(K = 24)。注释者可以标记每个行为的开始和结束帧,并被要求以自然语言命令的形式进行文本描述。在表 I 中,我们对训练数据的一个子集进行了比较,将事件可选重新标注与之前的随机窗口 重新标注进行了比较。我们发现,虽然这两种策略都倾向于描述接触丰富的行为,但我们的分析表明,事件可选重新标注法产生的数据匹配度更高:复杂的复合指令更少,组合指令更多。
Throughput and bottleneck analysis.
在此,我们将与大家分享在扩大机器人收集规模和事后重新标记操作中获得的一些启示。我们收集到的数据统计见表二。我们意外地发现,数据操作的主要瓶颈不是机器人远程操作,而是随后的众包语言标注,有 18.06% 的原始数据在模型训练前进行了标注(未标注的收集数据是已标注数据的 5.5 倍)。即使事后注释者的数量是机器人的 16 倍,情况也是如此。像这样的瓶颈可以通过利用无语言协同训练来解决[11],也可以通过继续横向扩展众包注释器来解决。
B. Policy Learning
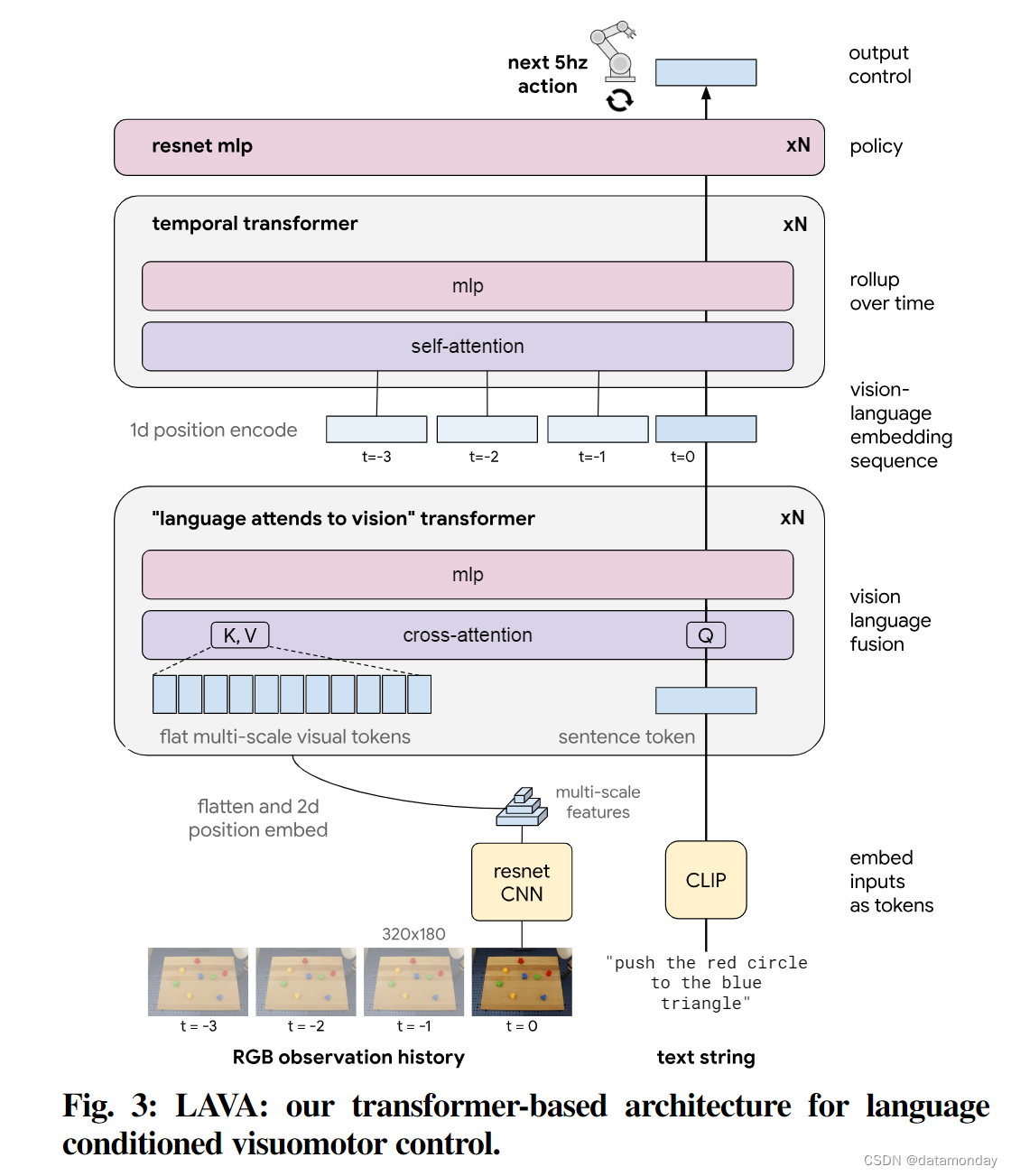
Transformer-based agent architecture.
在图 3 中,我们描述了基于Transformer [44] 的神经网络策略架构,该架构将视频和文本映射为连续动作,我们称之为 LAVA(Language Attends to Vision to Act)。每个训练实例由 (s,a,l)i ∼ Dtraining 组成,其中∈Rseqlen×640×320×3 为 RGB 观察历史。我们对视频 s 中的每一帧进行 ConvNet 处理,以获得多尺度视觉特征(多分辨率特征)。前两层是经过 Imagenet 预训练的 ResNet [45],[46]。l 是通过预训练的 CLIP 文本编码器 [47] 嵌入的,该编码器在我们的域内数据上进行了微调,但在策略训练期间保持不变。我们使用 Language-Attends-to-Vision Transformer 块融合视觉和语言信息,该Transformer块以语言作为查询,以扁平化的多尺度视觉标记作为键和值,进行交叉关注。这一操作适用于每幅图像,序列输出被送入时序预规范Transformer[48],经过平均池化后送入深度残差多层感知器,输出预测的下一个动作 a。
Training.
我们采用标准的监督语言条件行为克隆(LCBC)目标来训练我们的策略。虽然我们预计更复杂的损失函数或策略类别可能会获得更好的结果,但我们介绍的所有策略都是用简单的均方误差损失作为确定性策略进行训练的:
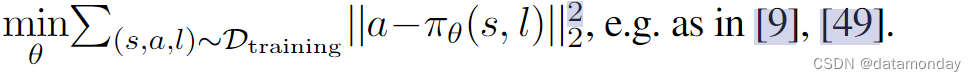
V. LANGUAGE-TABLE: DATASETS AND ENVIRONMENT
为了促进对语言条件视觉运动学习的进一步研究,我们发布了 Language-Table,它包括:
- i)一套数据集
- ii)一个模拟多任务语言条件控制环境和基准
Dataset.
语言表提供了模拟和真实世界中的人类标签 Dtraining 和底层人类远程操作 Dcollect。表 III 中突出显示了 Dtraining 真实数据集和模拟数据集,它们比以前可用的同类数据集大一个数量级。
Environment and Benchmark.
Language-Table 的模拟环境与我们在现实世界中的桌面操作场景相似,它由一个xArm6机器人组成,该机器人受限于在2D平面内移动,其圆柱形末端执行器与文献[54]中的一样,位于一块光滑的木板前,木板上有一组固定的8块塑料积木,包括4种颜色和6种形状(图5)。在模拟和实际采集中,我们都使用了第三人视角(实际中为视线)的高速人类远程操作。操作是二维三角直角坐标设定点,从上一个设定点到新的设定点。我们将收集到的训练和推理数据批量转换为 5 Hz 的观测数据和操作数据。
语言表基准计算了 5 个任务系列的自动指标,共有 696 种独特的任务变化。除了阈值任务成功率外,我们发现与人类首选性能更相关的指标是路径长度加权成功率(SPL)[55],它将成功率与成功路径的效率进行了权衡。我们注意到,迄今为止,在语言表中按 SPL 排序的策略超参数在实际性能中也有类似的排序。这在一定程度上验证了模拟基准与真实世界机器人技术的相关性。
VI. POLICY RESULTS AND DISCUSSION
我们介绍了旨在回答以下问题的实验:
(1) 该系统能在多大程度上遵循各种短视距自然语言条件指令?
(2) 通过交互式语言引导,这些技能能在多大程度上完成各种多步骤的长视距组合重排?
(3) 与开环语言计划相比,能够提供交互式语言反馈的好处是什么?
(4) 一个操作员能否同时引导多个配备我们策略的机器人?
(5) 消融:我们基于Transformer的策略架构与现有的视觉-语言-运动基线相比如何?我们提出的方法如何根据不同的数据量进行扩展?
A. Real world: diverse short-horizon language conditionable skills
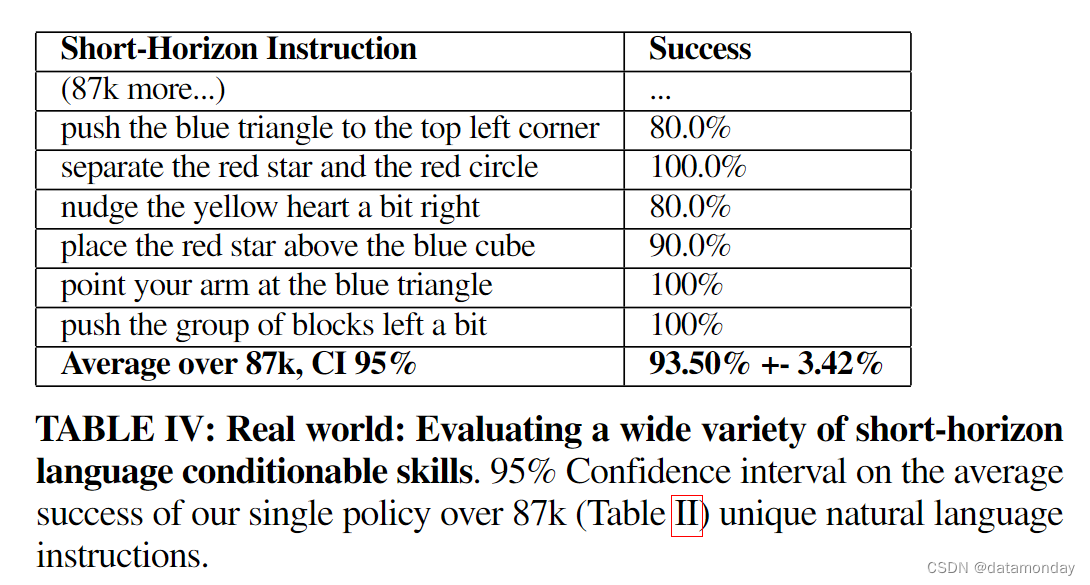
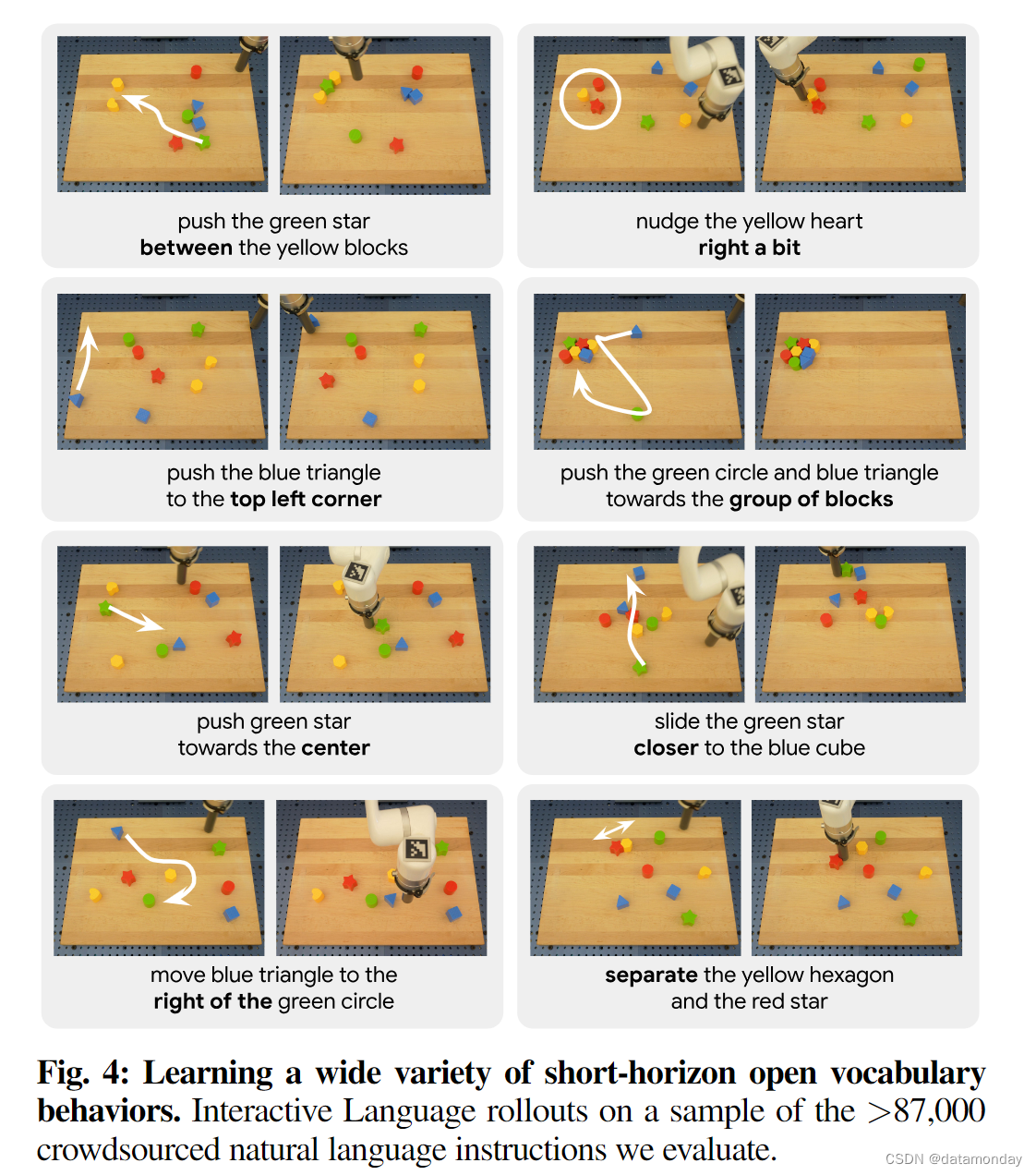
理想情况下,我们可以根据真人发出的任何短时指令来评估交互式语言策略,而这在一般情况下是难以实现的。作为一种替代方法,我们对通过众包收集到的 87,588 条独特语言指令(随机选择 20 条指令,每条指令 10 次试验)的平均成功率进行了 95% 的置信区间估计(Table II)。要取得成功,策略必须以物体属性和空间组成概念为基础(例如 “…top right side of the yellow hexagon” vs “top right side of the board”),并解决难以理解的歧义(例如 “nudge the cube left a bit”)。我们在表 IV 中报告了结果,并在图 4 中给出了示例。我们看到,在所有 87588 条指令中,交互式语言的预期平均成功率为 93.5%,95% CI [90.08%,96.92%]。据我们所知,这是现实世界中策略能够处理的最大语言条件行为集,证明了语言条件视觉运动控制具有坚实的基础能力。
B. Real world: long-horizon real-time language guidance
Long horizon goal reaching.
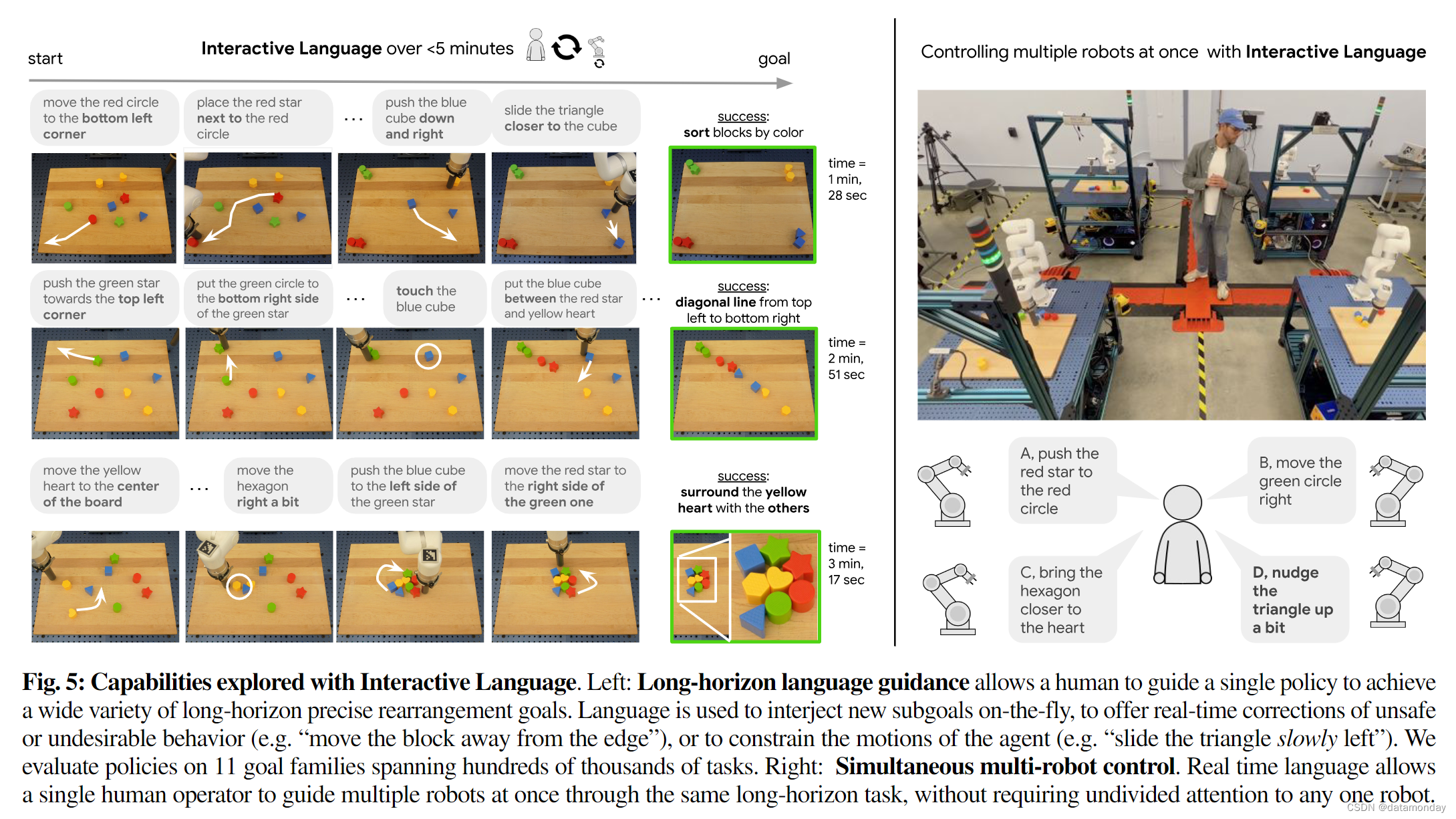
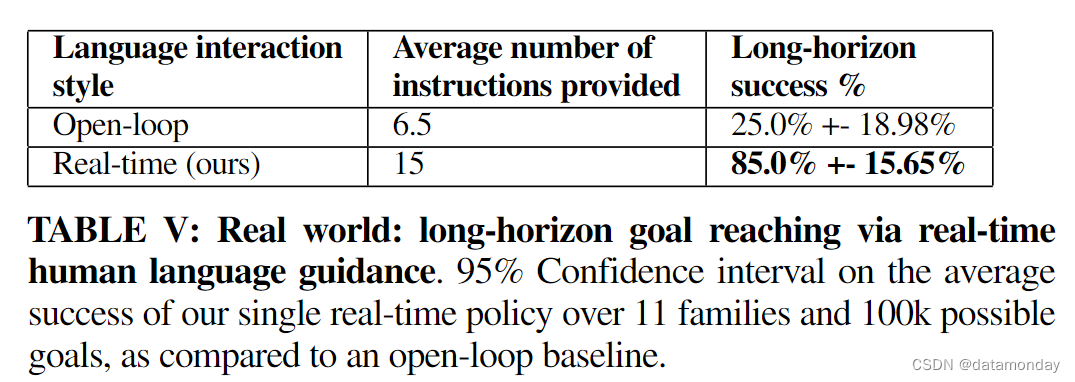
接下来,我们的目标是研究人类是否能够通过广泛的多步骤组合重新排列来指导交互式语言策略。我们在桌面上定义了 11 个高级系列(如制作高级形状,按颜色排序,将所有积木放在特定位置,排列成线等)的 100,000 多个语言不同的组合目标状态,然后从所有 11 个目标状态中统一抽样 20 个。不同目标状态的示例见图 5。我们从随机重置的棋盘状态中对每个长周期目标评估 3 次,总共对一个策略评估 60 次。我们在表 V 中报告了成功率。我们看到,在这组不同的目标上,我们的策略获得了 85.0% 的预期平均成功率,95% CI [69.35%, 100.00%]。观看补充视频可以更好地了解这些结果。我们注意到,对于学习型机器人来说,在现实世界中实现精确的长视距目标(即使是单一目标)是一个众所周知的难题[43]。尽管我们的策略并不是完全自主的,但我们相信,一个真实的机器人能够通过实时语言反馈来实现如此庞大而多样的目标,这表明未来的运行模式是协同的(至少在完全自主的设置得到巨大改进之前是协同的):机器人学习一套通用的低层次技能,而人类则使用自然语言以熟悉的方式将它们组合在一起,并随时打断机器人的学习以提供针对具体情况的纠正。
Open-loop vs real-time language feedback.
接下来,我们将尝试量化能够提供实时语言反馈的好处,而不是更常见的 "开环 "评估设置,即预先确定子目标的顺序[10]-[12], [43]。我们假设,由于单点接触推送的随机性,我们环境中的许多任务可能需要多轮迭代和交互式规范。我们进行了与上一节相同的评估,但人类操作员事先承诺了他们将提供的命令集和命令顺序。我们在表 V 中列出了这一消减的结果,发现当取消实时语言时,性能从 85% 下降到 25%。这表明,对于像本文所研究的这类联系丰富的任务,成功与否在很大程度上取决于是否有足够的实时反馈——不仅是对底层策略的反馈,也包括对提供指令的Agent的反馈。
Multi-robot control via spoken language.
最后,我们研究了交互式语言带来的新能力:多机器人同时控制。在图 5 中,我们可以看到,四台配备了交互式语言策略的机器人可以由一名操作员同时引导。据我们所知,这种由语言引导的多机器人控制能力尚未在文献中展示过。重要的是,由于短视距技能能力,这表明语言可以放宽操作员全神贯注的假设,而这在之前纠正在线机器人行为的方法中很常见[32], [34], [56]。
C. Simulation: Architecture and data ablation
在图 6 中,我们展示了 (i) 基于Transformer的策略架构 LAVA 与 [9] 中以 FiLM 为条件的 ResNet 架构的仿真消融结果,以及 (ii) 提供给策略训练的数据量。我们报告了语言表中多任务基准的平均成功率和 SPL [55](见第五节中的环境和基准),所有数字都是在三次种子训练运行中的置信区间。我们看到,所提出的架构确实在 SPL 方面比之前的研究成果有了显著提高,而在我们的设置中,我们发现路径长度感知的成功度指标与真实世界的质量关联度最高。在增加训练数据量时,我们发现策略性能的回报在逐渐降低,但在数据量每增加一倍时还没有达到顶峰。考虑到我们收集数据的规模,这一结果或许令人惊讶,但我们相信,它凸显了环境的复杂性以及开放词汇视觉运动学习的难度。

VII. CONCLUSION, LIMITATIONS, AND FUTURE WORK
我们介绍和分析了交互式语言框架,并提供了许多相关资产,特别是语言表数据集和环境。我们相信,数据集资产的规模,生成数据集的方法,所展示的策略多样性的规模以及对新功能的探索,都能为研究界带来益处,进一步推动可实时调节的视觉语言运动机器人的发展。我们的方法虽然简单且可扩展,但也存在一些局限性。在更广泛的人机协作方面还有许多问题有待解决[57],包括意图检测,非语言交流,物理协作任务完成等。我们的方法只解决了实时语言引导操作的问题。未来的工作可能会研究将交互式语言应用到实时辅助机器人等重要领域,这些领域可能会受益于更强大的自然语言接口[37]。我们希望我们的工作能为未来研究具有视觉-语言-运动控制能力的辅助机器人奠定基础。
A. Additional real-world experiment details
我们的实际实验使用 UFACTORY xArm6 机械臂,所有状态均以 100 Hz 的频率记录。观察结果由英特尔 RealSense D415 摄像头记录,使用分辨率为 640x360 的纯 RGB 图像,记录频率为 30 Hz,我们将这些图像调整为 320x180,然后交给机器人策略。策略使用 320x180 的单摄像头纯 RGB 图像,除语言外没有其他观察结果。异步观察结果和动作被分批转换成 5 Hz 的假同步对,用于训练策略,在形成假同步训练对时考虑了摄像头延迟(大约为 80 毫秒)。圆柱形末端执行器由一根 6 英寸长的塑料 PVC 管制成,材料来自 McMaster-Carr(9173K515)。工作台是 24 x 18 英寸的光滑木质砧板。操作物体来自 Play22 婴儿积木形状分类器玩具套件(Play22)。6DOF 机器人被限制在桌子上方的 2D 平面内移动。
B. Language-Table: Datasets
在此,我们将简要介绍 LanguageTable 提供的各种数据集,包括模拟数据集和真实数据集。
1)Simulation-Raw-Collect: 该数据集包括 6 个远程操作员在模拟中按照长水平线提示远程操作一个机器人。代表性提示见表 VIII。共收集到 8318 个集,平均长度为 36.8 ±15 秒,原始数据总长 85.5 小时。
2)Simulation-Relabeled:他们使用附录 E 中描述的界面生成了 181020 个事后重新标注的轨迹,其中包含 78623 个独特的指令。参见表 VII.3 中的代表性指令)。
3)Real-World-Raw-Collect: 该数据集由 11 个远程操作员按照长距离提示交替操作四个机器人组成。请参见表 VIII 中的代表性提示。共收集到 23498 个 episode,平均长度为 9.9 分钟±5.6 秒,原始数据总计 3865 小时。需要注意的是,有 16417 个 episode(共 2701 个小时)用于策略的实际训练,其余的则是在训练演示策略后,但在发布数据集之前收集的。
4)Real-World-Relabeled:Real-World-Raw-Collect 数据被发送给 64 位众包标注者,他们使用附录 E 中描述的界面生成了 414798 条事后重新标注的轨迹,其中包含 119959 条独特的指令。请参见表 VII 中的代表性说明。请注意,298,782 条重新标注的轨迹进入了训练阶段,其中包含 87,140 条独特的说明,其余的轨迹是在训练后但发布前收集的。

C. Language-Table: Environment
我们的模拟环境旨在与真实世界的设置大致匹配,包括一个用 PyBullet [58] 实现的模拟 6DoF 机器人 xArm6,它配备了一个小型圆柱形末端效应器。来自模拟摄像头的第三人称视角 320x180 RGB 图像被用作视觉输入。机器人前方的木板上有 8 块积木:红色新月形,红色五边形,蓝色新月形,蓝色立方体,绿色立方体,绿色星形,黄色星形和黄色五边形。与现实世界一样,机械臂受限于二维平面,动作空间是末端效应器的三角二维笛卡尔设定点。我们仅根据 RGB 和语言输入进行了所有实验,但环境额外暴露了 26 维状态观测(每个块的二维位置和一维旋转角度,末端执行器的二维位置)。我们在现实世界中的策略以 5hz 的频率执行异步推理和控制,而 Language-Table 中的策略则以 10hz 的频率执行阻塞控制。尽管存在这种差异,以及真实图像和模拟图像之间的其他差异,但我们发现语言表中的策略性能与真实世界中的策略性能高度相关。
D. Language-Table: Evaluation
我们在 Language-Table 中定义了五个模拟评估任务家族(跨越 696 个独特的任务条件),每个家族都有一个手动定义的成功标准:
- block2block:将一个区块推送到另一个区块。成功与否取决于源区块和目标区块之间的距离。共有 56 个独特的任务条件(8 个源图块 x 7 个目标图块)
- block2abs:将一个图块推到棋盘上的绝对位置:左上方,中间上方,右上方,中间左方,中间,中间右方,底部左方,底部中间,底部右方。成功与否取决于木块和目标位置之间的距离。共有 72 个独特的任务条件(8 个图块 x 9 个位置)
- block2rel:将图块推至相对偏移位置:左,右,上,下,上和左,上和右,下和左,下和右。成功与否取决于木块与隐形目标偏移位置之间的阈值距离。共有 64 种独特的任务条件(8 个图块 x 8 个偏移方向)
- block2blockrel:将一个区块推至另一个区块的相对偏移位置:左侧,右侧,上侧,下侧,左上侧,右上侧,左下侧,右下侧。成功率是源图块与目标图块的隐形目标偏移位置之间的阈值距离。共有 448 个独特的任务条件(8 个源图块 x 7 个目标图块 x 8 个偏移方向)
- separate:分离两个区块。成功率是两个区块之间的阈值距离。共有 56 个独特的任务条件(8 个源图块 x 7 个目标图块)。
这些任务系列被用于在模拟中对模型进行基准测试,使我们能够找到能够很好地转移到完全真实世界训练中的超参数(我们注意到,这项工作所采用的训练中没有模拟到真实的部分)。自动评估任务的语言条件是根据每个任务条件的预定义同义词集合成生成的。