给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2] 输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例 2:
输入:nums = [0] 输出:[[],[0]]
解法一 回溯法
这个比较好改,我们只需要判断当前数字和上一个数字是否相同,相同的话跳过即可。当然,要把数字首先进行排序。
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
Arrays.sort(nums); //排序
getAns(nums, 0, new ArrayList<>(), ans);
return ans;
}
private void getAns(int[] nums, int start, ArrayList<Integer> temp, List<List<Integer>> ans) {
ans.add(new ArrayList<>(temp));
for (int i = start; i < nums.length; i++) {
//和上个数字相等就跳过
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
temp.add(nums[i]);
getAns(nums, i + 1, temp, ans);
temp.remove(temp.size() - 1);
}
}
时间复杂度:
空间复杂度:
解法二 迭代法
根据78题解法二修改。我们看一下如果直接按照 78 题的思路会出什么问题。之前的思路是,先考虑 0 个数字的所有子串,再考虑 1 个的所有子串,再考虑 2 个的所有子串。而求 n 个的所有子串,就是 【n - 1 的所有子串】和 【n - 1 的所有子串加上 n】。例如,
数组 [ 1 2 3 ]
[ ]的所有子串 [ ]
[ 1 ] 个的所有子串 [ ] [ 1 ]
[ 1 2 ] 个的所有子串 [ ] [ 1 ] [ 2 ][ 1 2 ]
[ 1 2 3 ] 个的所有子串 [ ] [ 1 ] [ 2 ] [ 1 2 ] [ 3 ] [ 1 3 ] [ 2 3 ] [ 1 2 3 ]
Copy但是如果有重复的数字,会出现什么问题呢
数组 [ 1 2 2 ]
[ ] 的所有子串 [ ]
[ 1 ] 的所有子串 [ ] [ 1 ]
[ 1 2 ] 的所有子串 [ ] [ 1 ] [ 2 ][ 1 2 ]
[ 1 2 2 ] 的所有子串 [ ] [ 1 ] [ 2 ] [ 1 2 ] [ 2 ] [ 1 2 ] [ 2 2 ] [ 1 2 2 ]
Copy我们发现出现了重复的数组,那么我们可不可以像解法一那样,遇到重复的就跳过这个数字呢?答案是否定的,如果最后一步 [ 1 2 2 ] 增加了 2 ,跳过后,最终答案会缺少 [ 2 2 ]、[ 1 2 2 ] 这两个解。我们仔细观察这两个解是怎么产生的。
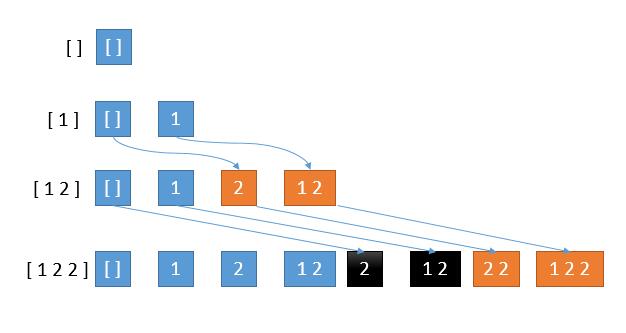
我们看到第 4 行黑色的部分,重复了,是怎么造成的呢?
第 4 行新添加的 2 要加到第 3 行的所有解中,而第 3 行的一部分解是旧解,一部分是新解。可以看到,我们黑色部分是由第 3 行的旧解产生的,橙色部分是由新解产生的。
而第 1 行到第 2 行,已经在旧解中加入了 2 产生了第 2 行的橙色部分,所以这里如果再在旧解中加 2 产生黑色部分就造成了重复。
所以当有重复数字的时候,我们只考虑上一步的新解,算法中用一个指针保存每一步的新解开始的位置即可。
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
ans.add(new ArrayList<>());// 初始化空数组
Arrays.sort(nums);
int start = 1; //保存新解的开始位置
for (int i = 0; i < nums.length; i++) {
List<List<Integer>> ans_tmp = new ArrayList<>();
// 遍历之前的所有结果
for (int j = 0; j < ans.size(); j++) {
List<Integer> list = ans.get(j);
//如果出现重复数字,就跳过所有旧解
if (i > 0 && nums[i] == nums[i - 1] && j < start) {
continue;
}
List<Integer> tmp = new ArrayList<>(list);
tmp.add(nums[i]); // 加入新增数字
ans_tmp.add(tmp);
}
start = ans.size(); //更新新解的开始位置
ans.addAll(ans_tmp);
}
return ans;
}
时间复杂度:
空间复杂度:O(1)。
还有一种思路,参考这里,当有重复数字出现的时候我们不再按照之前的思路走,而是单独考虑这种情况。
当有 n 个重复数字出现,其实就是在出现重复数字之前的所有解中,分别加 1 个重复数字, 2 个重复数字,3 个重复数字 ... 什么意思呢,看一个例子。
数组 [ 1 2 2 2 ]
[ ]的所有子串 [ ]
[ 1 ] 个的所有子串 [ ] [ 1 ]
然后出现了重复数字 2,那么我们记录重复的次数。然后遍历之前每个解即可
对于 [ ] 这个解,
加 1 个 2,变成 [ 2 ]
加 2 个 2,变成 [ 2 2 ]
加 3 个 2,变成 [ 2 2 2 ]
对于 [ 1 ] 这个解
加 1 个 2,变成 [ 1 2 ]
加 2 个 2,变成 [ 1 2 2 ]
加 3 个 2,变成 [ 1 2 2 2 ]
代码的话,就很好写了。
public List<List<Integer>> subsetsWithDup(int[] num) {
List<List<Integer>> result = new ArrayList<List<Integer>>();
List<Integer> empty = new ArrayList<Integer>();
result.add(empty);
Arrays.sort(num);
for (int i = 0; i < num.length; i++) {
int dupCount = 0;
//判断当前是否是重复数字,并且记录重复的次数
while( ((i+1) < num.length) && num[i+1] == num[i]) {
dupCount++;
i++;
}
int prevNum = result.size();
//遍历之前几个结果的每个解
for (int j = 0; j < prevNum; j++) {
List<Integer> element = new ArrayList<Integer>(result.get(j));
//每次在上次的结果中多加 1 个重复数字
for (int t = 0; t <= dupCount; t++) {
element.add(num[i]); //加入当前重复的数字
result.add(new ArrayList<Integer>(element));
}
}
}
return result;
}
解法三 位操作
本以为这个思路想不出来怎么去改了,然后看到了这里。
回顾一下,这个题的思想就是每一个数字,考虑它的二进制表示。
例如,nums = [ 1, 2 , 3 ]。用 1 代表在,0 代表不在。
1 2 3
0 0 0 -> [ ]
0 0 1 -> [ 3]
0 1 0 -> [ 2 ]
0 1 1 -> [ 2 3]
1 0 0 -> [1 ]
1 0 1 -> [1 3]
1 1 0 -> [1 2 ]
1 1 1 -> [1 2 3]
但是如果有了重复数字,很明显就行不通了。例如对于 nums = [ 1 2 2 2 3 ]。
1 2 2 2 3
0 1 1 0 0 -> [ 2 2 ]
0 1 0 1 0 -> [ 2 2 ]
0 0 1 1 0 -> [ 2 2 ]
上边三个数产生的数组重复的了。三个中我们只取其中 1 个,取哪个呢?取从重复数字的开头连续的数字。什么意思呢?就是下边的情况是我们所保留的。
2 2 2 2 2
1 0 0 0 0 -> [ 2 ]
1 1 0 0 0 -> [ 2 2 ]
1 1 1 0 0 -> [ 2 2 2 ]
1 1 1 1 0 -> [ 2 2 2 2 ]
1 1 1 1 1 -> [ 2 2 2 2 2 ]
而对于 [ 2 2 ] 来说,除了 1 1 0 0 0 可以产生,下边的几种情况,都是产生的 [ 2 2 ]
2 2 2 2 2
1 1 0 0 0 -> [ 2 2 ]
1 0 1 0 0 -> [ 2 2 ]
0 1 1 0 0 -> [ 2 2 ]
0 1 0 1 0 -> [ 2 2 ]
0 0 0 1 1 -> [ 2 2 ]
......
怎么把 1 1 0 0 0 和上边的那么多种情况区分开来呢?我们来看一下出现了重复数字,并且当前是 1 的前一个的二进位。
对于 1 1 0 0 0 ,是 1。
对于 1 0 1 0 0 , 是 0。
对于 0 1 1 0 0 ,是 0。
对于 0 1 0 1 0 ,是 0。
对于 0 0 0 1 1 ,是 0。
......
可以看到只有第一种情况对应的是 1 ,其他情况都是 0。其实除去从开头是连续的 1 的话,就是两种情况。
第一种就是,占据了开头,类似于这种 10...1....
第二种就是,没有占据开头,类似于这种 0...1...
这两种情况,除了第一位,其他位的 1 的前边一定是 0。所以的话,我们的条件是看出现了重复数字,并且当前位是 1 的前一个的二进位。
所以可以改代码了。
public List<List<Integer>> subsetsWithDup(int[] num) {
Arrays.sort(num);
List<List<Integer>> lists = new ArrayList<>();
int subsetNum = 1<<num.length;
for(int i=0;i<subsetNum;i++){
List<Integer> list = new ArrayList<>();
boolean illegal=false;
for(int j=0;j<num.length;j++){
//当前位是 1
if((i>>j&1)==1){
//当前是重复数字,并且前一位是 0,跳过这种情况
if(j>0&&num[j]==num[j-1]&&(i>>(j-1)&1)==0){
illegal=true;
break;
}else{
list.add(num[j]);
}
}
}
if(!illegal){
lists.add(list);
}
}
return lists;
}