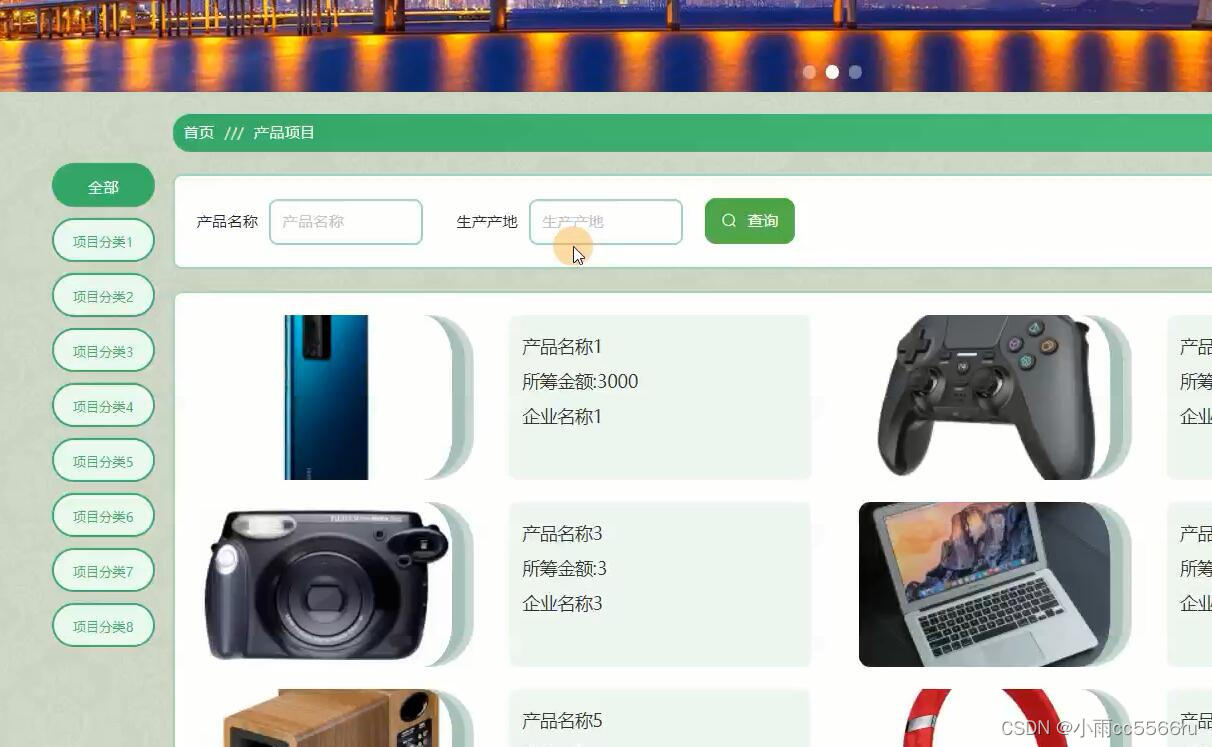
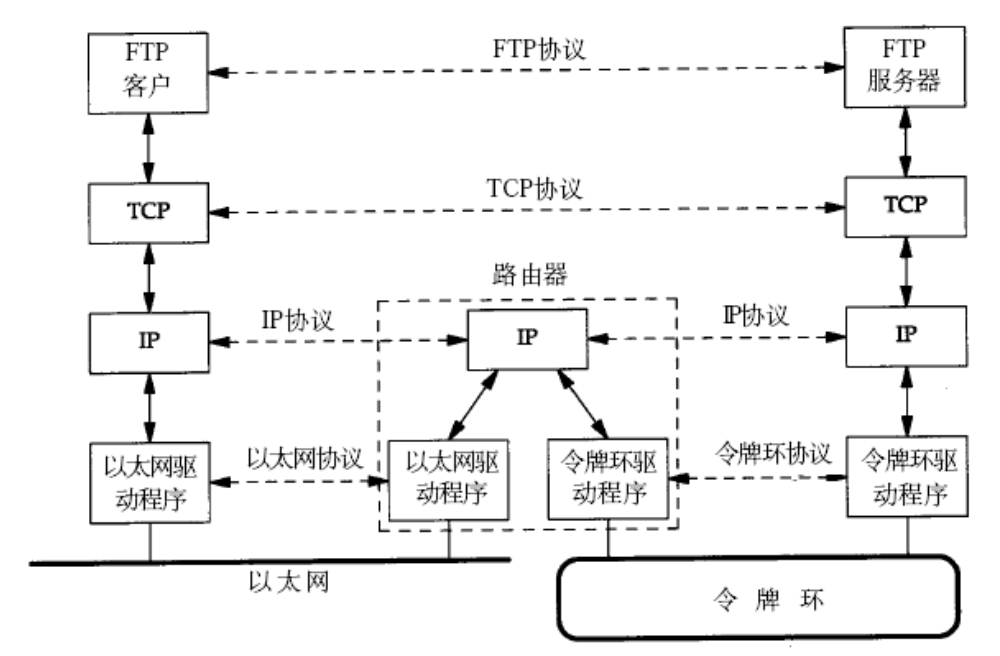
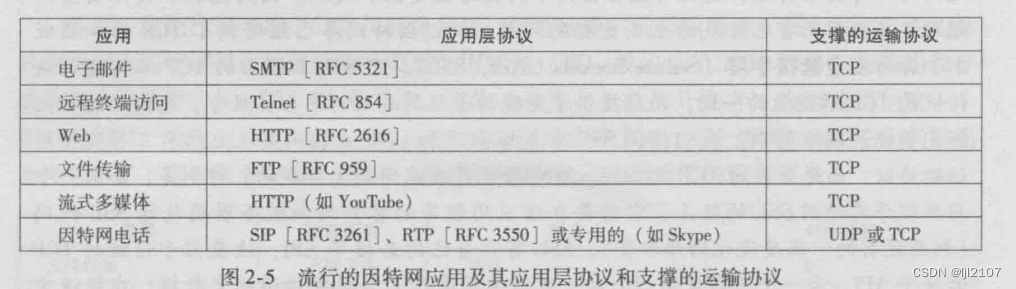
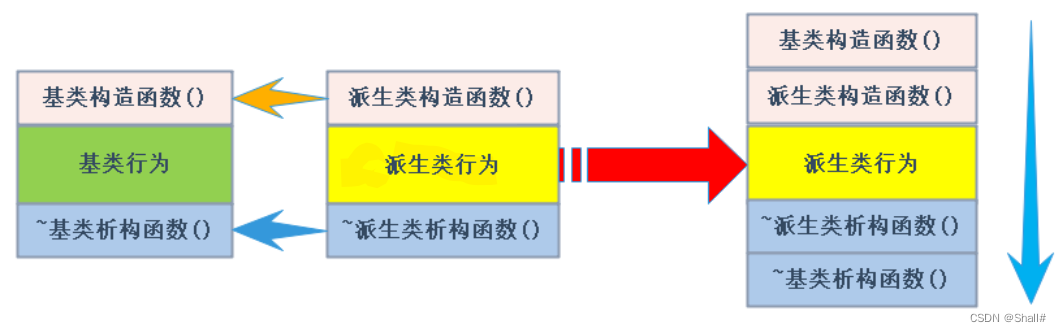
深度学习 2:第 2 部分第 12 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-12-215dfbf04a94译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。

生成对抗网络(GANs)
视频 / 论坛
非常炙手可热的技术,但绝对值得成为课程中前沿深度学习部分的一部分,因为它们并不完全被证明对任何事情都有用,但它们几乎到了那个地步,肯定会成功。我们将专注于那些在实践中肯定会有用的事情,有许多领域可能会被证明有用,但我们还不知道。所以我认为它们在实践中肯定会有用的领域是你在幻灯片左侧看到的那种东西 —— 例如将绘画转化为渲染图片。这来自于两天前刚刚发布的一篇论文,所以目前正在进行非常活跃的研究。
从上一堂课 [1:04]: 我们的多样性研究员 Christine Payne 拥有斯坦福大学的医学硕士学位,因此她对构建医学语言模型感兴趣。我们在第四课中简要提到过的一件事,但上次并没有详细讨论的是,你实际上可以种子一个生成式语言模型,这意味着你已经在某个语料库上训练了一个语言模型,然后你将从该语言模型生成一些文本。你可以通过输入一些词来开始,告诉它“这是用来创建语言模型中隐藏状态的前几个词,请从这里生成”。Christine 做了一些聪明的事情,她用一个问题作为种子,重复这个问题三次,然后让它从那里生成。她向语言模型输入了许多不同的医学文本,并输入了下面看到的问题:

Jeremy 发现这个有趣的地方是,对于没有医学硕士学位的人来说,这几乎是一个可信的答案。但它与现实完全没有关系。他认为这是一种有趣的伦理和用户体验困境。Jeremy 参与了一个名为 doc.ai 的公司,该公司试图做很多事情,但最终提供一个应用程序供医生和患者使用,可以帮助他们解决医疗问题。他一直在对团队中的软件工程师说,请不要尝试使用 LSTM 或其他东西创建生成模型,因为它们会擅长创造听起来令人印象深刻但实际上是错误建议的东西 —— 就像政治评论员或终身教授可以以极大的权威说废话一样。所以他认为这是一个非常有趣的实验。如果你做了一些有趣的实验,请在论坛、博客、Twitter 上分享。让人们知道并受到了了不起的人的关注。
CIFAR10 [5:26]
让我们谈谈 CIFAR10,原因是今天我们将看一些更基础的 PyTorch 内容,以构建这些生成对抗模型。目前没有关于 GAN 的 fastai 支持 - 很快就会有,但目前还没有,所以我们将从头开始构建许多模型。我们已经有一段时间没有进行严肃的模型构建了。在课程的第一部分中,我们看了 CIFAR10,并构建了一个准确率约为 85%的模型,训练时间约为几个小时。有趣的是,现在正在进行一项竞赛,看看谁能最快地训练 CIFAR10(DAWN),目标是将准确率提高到 94%。看看我们是否能构建一个能够达到 94%准确率的架构,因为这比我们之前的尝试要好得多。希望通过这样做,我们将学到一些关于创建良好架构的东西,这对于今天研究 GANs 将会很有用。此外,这也很有用,因为 Jeremy 在过去几年深入研究了关于不同类型 CNN 架构的论文,并意识到这些论文中的许多见解并没有被广泛利用,显然也没有被广泛理解。因此,他想向您展示如果我们能利用其中一些理解会发生什么。
cifar10-darknet.ipynb [7:17]
这个笔记本被称为darknet,因为我们将要查看的特定架构与 darknet 架构非常接近。但在这个过程中,您会发现 darknet 架构并不是整个 YOLO v3 端到端的东西,而只是他们在 ImageNet 上预训练用于分类的部分。这几乎就像您可以想到的最通用的简单架构,因此它是实验的一个很好的起点。因此,我们将其称为“darknet”,但它并不完全是那样,您可以对其进行调整以创建绝对不是 darknet 的东西。它实际上只是几乎任何现代基于 ResNet 的架构的基础。
CIFAR10 是一个相当小的数据集[8:06]。图像大小仅为 32x32,这是一个很好的数据集,因为:
-
与 ImageNet 不同,您可以相对快速地对其进行训练
-
相对较少的数据
-
实际上很难识别这些图像,因为 32x32 太小了,很难看清楚发生了什么。
这是一个被低估的数据集,因为它很老。谁愿意使用小而古老的数据集,当他们可以利用整个服务器房间来处理更大的数据时。但这是一个非常好的数据集,值得关注。
继续导入我们通常使用的东西,我们将尝试从头开始构建一个网络来训练这个[8:58]。
%matplotlib inline
%reload_ext autoreload
%autoreload 2
from fastai.conv_learner import *
PATH = Path("data/cifar10/")
os.makedirs(PATH,exist_ok=True)
对于那些对广播和 PyTorch 基本技能不是 100%自信的人来说,一个非常好的练习是弄清楚 Jeremy 是如何得出这些stats数字的。这些数字是 CIFAR10 中每个通道的平均值和标准差。尝试确保您可以重新创建这些数字,并查看是否可以在不超过几行代码的情况下完成(不使用循环!)。
由于这些数据相当小,我们可以使用比通常更大的批量大小,并且这些图像的大小为 32[9:46]。
classes = (
'plane', 'car', 'bird',
'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck'
)
stats = (
np.array([ 0.4914 , 0.48216, 0.44653]),
np.array([ 0.24703, 0.24349, 0.26159])
)
num_workers = num_cpus()//2
bs=256
sz=32
变换[9:57],通常我们有这一套标准的 side_on 变换,用于普通物体的照片。我们不会在这里使用这个,因为这些图像太小了,尝试将一个 32x32 的图像稍微旋转会引入很多块状失真。人们倾向于使用的标准变换是随机水平翻转,然后我们在每一侧添加 4 个像素(尺寸除以 8)的填充。一个非常有效的方法是,默认情况下 fastai 不会添加黑色填充,而许多其他库会这样做。Fastai 会取现有照片的最后 4 个像素,翻转并反射它,我们发现使用反射填充会得到更好的结果。现在我们有了 40x40 的图像,在训练中,这组变换将随机选择 32x32 的裁剪,所以我们会有一点变化但不会太多。因此我们可以使用正常的from_paths来获取我们的数据。
tfms = tfms_from_stats(
stats, sz,
aug_tfms=[RandomFlip()],
pad=sz//8
)
data = ImageClassifierData.from_paths(
PATH,
val_name='test',
tfms=tfms,
bs=bs
)
现在我们需要一个架构,我们将创建一个适合在一个屏幕上显示的架构[11:07]。这是从头开始的。我们正在使用预定义的Conv2d,BatchNorm2d,LeakyReLU模块,但我们没有使用任何块或其他东西。整个东西都在一个屏幕上,所以如果你曾经想知道我是否能理解一个现代的高质量架构,绝对可以!让我们来学习这个。
def conv_layer(ni, nf, ks=3, stride=1):
return nn.Sequential(
nn.Conv2d(
ni, nf,
kernel_size=ks,
bias=False,
stride=stride,
padding=ks//2
),
nn.BatchNorm2d(nf, momentum=0.01),
nn.LeakyReLU(negative_slope=0.1, inplace=True)
)
class ResLayer(nn.Module):
def __init__(self, ni):
super().__init__()
self.conv1=conv_layer(ni, ni//2, ks=1)
self.conv2=conv_layer(ni//2, ni, ks=3)
def forward(self, x):
return x.add_(self.conv2(self.conv1(x)))
class Darknet(nn.Module):
def make_group_layer(self, ch_in, num_blocks, stride=1):
return [conv_layer(ch_in, ch_in*2,stride=stride)] + \
[(ResLayer(ch_in*2)) for i in range(num_blocks)]
def __init__(self, num_blocks, num_classes, nf=32):
super().__init__()
layers = [conv_layer(3, nf, ks=3, stride=1)]
for i,nb in enumerate(num_blocks):
layers += self.make_group_layer(nf, nb, stride=2-(i==1))
nf *= 2
layers += [
nn.AdaptiveAvgPool2d(1),
Flatten(),
nn.Linear(nf, num_classes)
]
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
架构的基本起点是说它是一堆堆叠的层,一般来说会有一种层次结构[11:51]。在最底层,有像卷积层和批量归一化层这样的东西,但任何时候你有一个卷积,你可能会有一些标准的顺序。通常会是:
-
卷积
-
批量归一化
-
一个非线性激活(例如 ReLU)
我们将从确定我们的基本单元是什么开始,并在一个函数(conv_layer)中定义它,这样我们就不必担心保持一致性,这将使一切变得更简单。
Leaky Relu [12:43]:

Leaky ReLU 的梯度(其中x < 0)会有所变化,但通常是 0.1 或 0.01 左右。其背后的想法是,当你处于负区域时,你不会得到一个零梯度,这会使更新变得非常困难。实践中,人们发现 Leaky ReLU 在较小的数据集上更有用,在大数据集上不太有用。但有趣的是,在YOLO v3论文中,他们使用了 Leaky ReLU,并从中获得了很好的性能。它很少会使事情变得更糟,通常会使事情变得更好。所以如果你需要创建自己的架构,Leaky ReLU 可能不错作为默认选择。
你会注意到我们在conv_layer中没有定义 PyTorch 模块,我们只是使用nn.Sequential[14:07]。如果你阅读其他人的 PyTorch 代码,你会发现这是一个被低估的东西。人们倾向于将一切都写成 PyTorch 模块,带有__init__和forward,但如果你想要的只是一系列按顺序排列的东西,将其作为Sequential会更简洁易懂。
残差块 [14:40]:如前所述,大多数现代网络中通常有多个层次的单元,我们现在知道 ResNet 中这个单元层次结构的下一个级别是 ResBlock 或残差块(参见ResLayer)。回顾我们上次做 CIFAR10 时,我们过于简化了(有点作弊)。我们将x输入,经过一个conv,然后将其加回到x中输出。在真正的 ResBlock 中,有两个这样的块。当我们说conv时,我们将其作为conv_layer的快捷方式(卷积,批量归一化,ReLU)。

这里有一个有趣的观点是这些卷积中的通道数量。我们有一些 ni 进来(一些输入通道/滤波器的数量)。Darknet 团队设置的方式是,他们让每一个这些 Res 层输出与进来的相同数量的通道,Jeremy 喜欢这样做,这就是为什么他在ResLayer中使用它,因为这样会让生活更简单。第一个卷积将通道数量减半,然后第二个卷积再将其加倍。所以你有一个漏斗效应,64 个通道进来,通过第一个卷积压缩到 32 个通道,然后再次提升到 64 个通道输出。
问题:为什么LeakyReLU中要使用inplace=True?谢谢你的提问!很多人忘记了这一点或者不知道这一点,但这是一个非常重要的内存技巧。如果你想一下,这个conv_layer,它是最底层的东西,所以基本上我们的 ResNet 一旦全部组装起来,就会有很多conv_layer。如果你没有inplace=True,它会为 ReLU 的输出创建一个完全独立的内存块,这样就会分配一大堆完全不必要的内存。另一个例子是ResLayer中的原始forward看起来像这样:
def forward(self, x):
return x + self.conv2(self.conv1(x))
希望你们中的一些人记得在 PyTorch 中几乎每个函数都有一个下划线后缀版本,告诉它在原地执行。+等同于add,add的原地版本是add_,这样可以减少内存使用量:
def forward(self, x):
return x.add_(self.conv2(self.conv1(x)))
这些都是非常方便的小技巧。Jeremy 一开始忘记了inplace=True,但他不得不将批量大小降低到非常低的数量,这让他发疯了——然后他意识到那个部分缺失了。如果你使用了 dropout,你也可以这样做。以下是需要注意的事项:
-
Dropout
-
所有激活函数
-
任何算术操作
问题:在 ResNet 中,为什么conv_layer中的偏置通常设置为 False?在Conv之后,紧接着是BatchNorm。记住,BatchNorm对于每个激活有 2 个可学习参数——你要乘以的东西和你要添加的东西。如果我们在Conv中有偏置,然后在BatchNorm中再添加另一件事,那就是在添加两件事,这完全没有意义——这是两个权重,一个就够了。所以如果在Conv之后有一个BatchNorm,你可以告诉BatchNorm不要包括添加部分,或者更简单的方法是告诉Conv不要包括偏置。这没有特别的危害,但是会占用更多内存,因为它需要跟踪更多的梯度,所以最好避免。
另一个小技巧是,大多数人的conv_layer都有填充作为参数。但一般来说,你应该能够很容易地计算填充。如果卷积核大小为 3,那么显然每边会有一个单位的重叠,所以我们需要填充 1。或者,如果卷积核大小为 1,那么我们就不需要任何填充。所以一般来说,卷积核大小“整数除以 2”就是你需要的填充。有时会有一些调整,但在这种情况下,这个方法非常有效。再次尝试简化我的代码,让计算机为我计算东西,而不是我自己去做。

另一个关于这两个conv_layer的事情:我们有这个瓶颈的想法(减少通道然后再增加),还有要使用的卷积核大小。第一个有 1 乘 1 的Conv。1 乘 1 卷积实际上发生了什么?如果我们有一个 4 乘 4 的网格,有 32 个滤波器/通道,我们将进行 1 乘 1 卷积,卷积的核看起来像中间的那个。当我们谈论卷积核大小时,我们从来没有提到最后一部分——但假设它是 1 乘 1 乘 32,因为这是输入和输出的滤波器的一部分。卷积核被放在黄色的第一个单元上,我们得到这 32 个深度位的点积,这给了我们第一个输出。然后我们将其移动到第二个单元并得到第二个输出。所以对于网格中的每个点,都会有一堆点积。这使我们能够以任何我们想要的方式改变通道维度。我们创建了ni//2个滤波器,我们将有ni//2个点积,基本上是输入通道的不同加权平均值。通过非常少的计算,它让我们添加了这个额外的计算和非线性步骤。这是一个很酷的技巧,利用这些 1 乘 1 卷积,创建这个瓶颈,然后再用 3 乘 3 卷积拉出来——这将充分利用输入的 2D 特性。否则,1 乘 1 卷积根本不利用这一点。

这两行代码,里面没有太多内容,但这是一个对你对正在发生的事情的理解和直觉的很好的测试——为什么它有效?为什么张量秩是对齐的?为什么维度都很好地对齐?为什么这是一个好主意?它到底在做什么?这是一个很好的东西来调整。也许在 Jupyter Notebook 中创建一些小的实例,自己运行一下,看看输入和输出是什么。真正感受一下。一旦你这样做了,你就可以尝试不同的东西。
这篇真正被低估的论文是这篇Wide Residual Networks。这篇论文非常简单,但他们做的是围绕这两行代码进行调整:
-
如果我们用
ni*2代替ni//2会怎样? -
如果我们添加
conv3呢?
他们提出了一种简单的符号表示来定义这两行代码可能的样子,并展示了许多实验。他们展示的是,在 ResNet 中普遍采用的减少通道数量的瓶颈方法可能不是一个好主意。实际上,根据实验结果,绝对不是一个好主意。因为这样可以创建非常深的网络。创建 ResNet 的人因为创建了 1001 层网络而变得特别有名。但是 1001 层的问题在于,你无法在完成第 1 层之前计算第 2 层。你无法在完成计算第 2 层之前计算第 3 层。所以是顺序的。GPU 不喜欢顺序。所以他们展示的是,如果层数较少但每层计算量更大——一个简单的方法是去掉//2,没有其他改变:

在家里试试吧。尝试运行 CIFAR 看看会发生什么。甚至乘以 2 或者摆弄一下。这样可以让你的 GPU 做更多的工作,这非常有趣,因为绝大多数关于不同架构性能的论文实际上从来没有计算运行一个批次需要多长时间。他们说“这个需要每批次 X 个浮点运算”,但他们从来没有真正费心像一个合格的实验者那样运行它,找出它是快还是慢。现在很有名的很多架构结果都很慢,占用大量内存,完全没用,因为研究人员从来没有费心看看它们是否快,实际上看看它们是否适合正常批次大小的内存。所以 Wide ResNet 论文之所以不同在于它实际上计算了运行所需的时间,YOLO v3 论文也做了同样的发现。他们可能错过了 Wide ResNet 论文,因为 YOLO v3 论文得出了很多相同的结论,但 Jeremy 不确定他们是否引用了 Wide ResNet 论文,所以他们可能不知道所有这些工作已经完成。看到人们实际上在计时并注意到什么是有意义的是很好的。
问题:你对 SELU(缩放指数线性单元)有什么看法?[29:44] SELU 主要用于全连接层,它允许你摆脱批量归一化,基本思想是,如果你使用这种不同的激活函数,它是自归一化的。自归一化意味着它将始终保持单位标准差和零均值,因此你不需要批量归一化。它实际上并没有取得什么进展,原因是因为它非常挑剔 — 你必须使用非常特定的初始化,否则它就不会以完全正确的标准差和均值开始。很难将其用于诸如嵌入之类的东西,如果你这样做,那么你必须使用一种特定类型的嵌入初始化,这对嵌入来说是没有意义的。你做了所有这些工作,很难搞对,最终如果你搞对了,有什么意义呢?好吧,你成功摆脱了一些并没有真正伤害你的批量归一化层。有趣的是 SELU 论文 — 人们注意到它的主要原因是因为它是由 LSTM 的发明者创建的,而且它有一个巨大的数学附录。所以人们认为“一个名人的大量数学 — 必定很棒!”但实际上,Jeremy 没有看到任何人使用它来获得任何最先进的结果或赢得任何比赛。
Darknet.make_group_layer包含一堆ResLayer[31:28]。group_layer将会有一些通道/滤波器进入。我们将通过使用标准的conv_layer来使进入的通道数量加倍。可选地,我们将通过使用步幅为 2 来减半网格大小。然后我们将做一系列的 ResLayers — 我们可以选择多少个(2、3、8 等),因为记住 ResLayers 不会改变网格大小,也不会改变通道数量,所以你可以添加任意数量而不会造成任何问题。这将使用更多的计算和内存,但除此之外你可以添加任意数量。因此,group_layer最终将使通道数量加倍,因为初始卷积使通道数量加倍,取决于我们传入的stride,如果我们设置stride=2,它也可能减半网格大小。然后我们可以做一系列 Res 块的计算,任意数量。
定义我们的Darknet,我们将传入类似这样的东西[33:13]:
m = Darknet([1, 2, 4, 6, 3], num_classes=10, nf=32)
m = nn.DataParallel(m, [1,2,3])
这意味着创建五个组层:第一个将包含 1 个额外的 ResLayer,第二个将包含 2 个,然后是 4 个,6 个,3 个,我们希望从 32 个滤波器开始。第一个 ResLayers 将包含 32 个滤波器,只会有一个额外的 ResLayer。第二个将会使滤波器数量翻倍,因为每次有一个新的组层时我们都会这样做。所以第二个将有 64 个,然后 128 个,256 个,512 个,就这样。几乎整个网络将由这些层组成,记住,每个组层在开始时也有一个卷积。所以在这之前,我们将在一开始有一个卷积层,在最后我们将执行标准的自适应平均池化,展平,并在最后创建一个线性层来生成最终的类别数量。总结一下,一个端有一个卷积,自适应池化和另一个端有一个线性层,中间是这些组层,每个组层由一个卷积层和n个 ResLayers 组成。
自适应平均池化:Jeremy 多次提到过这个,但他还没有看到任何代码,任何示例,任何地方使用自适应平均池化。他看到的每一个都像nn.AvgPool2d(n)这样写,其中n是一个特定的数字-这意味着它现在与特定的图像大小绑定在一起,这绝对不是您想要的。所以大多数人仍然认为特定的架构与特定的大小绑定在一起。当人们认为这样时,这是一个巨大的问题,因为这会严重限制他们使用更小的尺寸来启动建模或使用更小的尺寸进行实验的能力。
Sequential:创建架构的一个好方法是首先创建一个列表,在这种情况下,这是一个只有一个conv_layer的列表,然后make_group_layer返回另一个列表。然后我们可以用+=将该列表附加到前一个列表中,并对包含AdaptiveAvnPool2d的另一个列表执行相同操作。最后,我们将调用所有这些层的nn.Sequential。现在forward只是self.layers(x)。

这是如何使您的架构尽可能简单的好方法。有很多可以摆弄的地方。您可以将ni的除数参数化,使其成为您传入的数字,以传入不同的数字-也许是乘以 2。您还可以传入一些可以改变内核大小或改变卷积层数量的参数。Jeremy 有一个版本,他将为您运行,其中实现了 Wide ResNet 论文中的所有不同参数,因此他可以摆弄看看哪些效果好。

lr = 1.3
learn = ConvLearner.from_model_data(m, data)
learn.crit = nn.CrossEntropyLoss()
learn.metrics = [accuracy]
wd=1e-4
%time learn.fit(
lr, 1,
wds=wd,
cycle_len=30,
use_clr_beta=(20, 20, 0.95, 0.85)
)
一旦我们有了这个,我们可以使用ConvLearner.from_model_data来获取我们的 PyTorch 模块和模型数据对象,并将它们转换为一个学习器。给它一个标准,如果我们喜欢,可以添加一个指标,然后我们可以拟合并开始。
问题:您能解释一下自适应平均池化吗?将其设置为 1 是如何工作的?当我们进行平均池化时,通常情况下,假设我们有 4x4,然后进行avgpool((2, 2))。这将创建一个 2x2 的区域(下方的蓝色),并取这四个的平均值。如果我们传入stride=1,下一个是 2x2(绿色),然后取平均值。这就是正常的 2x2 平均池化。如果我们没有填充,那么输出将是 3x3。如果我们想要 4x4,我们可以添加填充。

如果我们想要 1x1 呢?那么我们可以说avgpool((4,4), stride=1),这将在黄色中进行 4x4 并对整体进行平均,结果为 1x1。但这只是一种方法。与其说池化滤波器的大小,为什么不说“我不在乎输入网格的大小。我总是想要一个一个”。这就是你说adap_avgpool(1)的地方。在这种情况下,你不说池化滤波器的大小,而是说我们想要的输出大小。我们想要的是一个一个。如果你放一个单独的整数n,它会假设你的意思是n乘以n。在这种情况下,一个 4x4 网格的自适应平均池化与平均池化(4,4)相同。如果是一个 7x7 的网格进来,它将与平均池化(7,7)相同。这是相同的操作,只是以一种方式表达,无论输入是什么,我们都希望得到那个大小的输出。
DAWNBench:让我们看看我们的简单网络与这些最新技术结果相比如何。Jeremy 已经准备好命令了。我们已经将所有这些东西放入一个简单的 Python 脚本中,他修改了一些他提到的参数,创建了一个他称之为wrn_22网络,它并不存在,但根据 Jeremy 的实验,它对我们讨论的参数进行了一些改变。它有一堆很酷的东西,比如:
-
莱斯利·史密斯的一个周期
-
半精度浮点实现

这将在 AWS p3 上运行,它有 8 个 GPU 和 Volta 架构的 GPU,这些 GPU 对半精度浮点有特殊支持。Fastai 是第一个实际将 Volta 优化的半精度浮点集成到库中的库,所以你只需learn.half()就可以自动获得支持。它也是第一个集成一个周期的库。
实际上,这是使用 PyTorch 的多 GPU 支持。由于有八个 GPU,它实际上会启动八个单独的 Python 处理器,每个处理器都会训练一点,然后最后将梯度更新传回主进程,主进程将把它们全部整合在一起。所以你会看到很多进度条一起弹出。

你可以看到这种方式训练三到四秒。而在之前,当 Jeremy 早些时候训练时,他每个时代要花 30 秒。所以用这种方式,我们可以训练东西大约快 10 倍,这很酷。
检查状态:
完成了!我们达到了 94%,用时 3 分 11 秒。之前的最新技术是 1 小时 7 分钟。折腾这些参数,学习这些架构实际上是如何工作的,而不仅仅是使用开箱即用的东西,值得吗?哇哦。我们刚刚使用了一个公开可用的实例(我们使用了一个 spot 实例,所以花费了我们每小时 8 美元——3 分钟 40 美分)来从头开始训练,比以往任何人都要快 20 倍。所以这是最疯狂的最新技术结果之一。我们看到了很多,但这个结果真的让人大吃一惊。这在很大程度上要归功于调整这些架构参数,主要是关于使用莱斯利·史密斯的一个周期。提醒一下它在做什么,对于学习率,它创建了一个向上的路径,与向下的路径一样长,所以它是真正的三角形循环学习率(CLR)。像往常一样,你可以选择 x 和 y 的比例(即起始 LR/峰值 LR)。在

在这种情况下,我们选择了 50 作为比率。所以我们从更小的学习率开始。然后它有一个很酷的想法,你可以说你的 epochs 的百分之几是从三角形底部一直下降到几乎为零 - 这是第二个数字。所以 15%的批次花在从我们的三角形底部进一步下降。

这不是一个周期所做的唯一事情,我们还有动量。动量从 0.95 到 0.85。换句话说,当学习率很低时,我们使用很大的动量,当学习率很高时,我们使用很少的动量,这很有道理,但在 Leslie Smith 在论文中展示之前,Jeremy 从未见过有人这样做。这是一个非常酷的技巧。你现在可以通过在 fastai 中使用use-clr-beta参数来使用它(Sylvain 的论坛帖子),你应该能够复制最先进的结果。你可以在自己的计算机上或者 paper space 上使用它,唯一得不到的是多 GPU 部分,但这样训练会更容易一些。

问题:make_group_layer包含步幅等于 2,这意味着第一层的步幅为 1,其他所有层的步幅为 2。背后的逻辑是什么?通常我见过的步幅是奇数。步幅要么是 1,要么是 2。我认为你在考虑卷积核大小。所以步幅=2 意味着我跨越两个,这意味着你的网格大小减半。所以我认为你可能在步幅和卷积核大小之间混淆了。如果步幅为 1,网格大小不会改变。如果步幅为 2,那么会改变。在这种情况下,因为这是 CIFAR10,32x32 很小,我们不会经常减半网格大小,因为很快我们就会用完单元格。这就是为什么第一层的步幅为 1,这样我们不会立即减小网格大小。这是一种很好的做法,因为这就是为什么我们一开始在大网格上没有太多计算Darknet([1, 2, 4, 6, 3], …)。我们可以从大网格上开始,然后随着网格变小,逐渐增加更多的计算,因为网格越小,计算所需的时间就越少。
生成对抗网络(GAN)[48:49]
-
沃瑟斯坦 GAN
-
使用深度卷积生成对抗网络进行无监督表示学习
我们将讨论生成对抗网络,也称为 GAN,具体来说,我们将专注于沃瑟斯坦 GAN 论文,其中包括后来创建 PyTorch 的 Soumith Chintala。沃瑟斯坦 GAN(WGAN)受到了深度卷积生成对抗网络论文的重大影响,Soumith 也参与其中。这是一篇非常有趣的论文。很多内容看起来像这样:

好消息是你可以跳过那些部分,因为还有一个看起来像这样的部分:

很多论文都有一个理论部分,似乎完全是为了满足审稿人对理论的需求。但 WGAN 论文并非如此。理论部分实际上很有趣 - 你不需要了解它就能使用它,但如果你想了解一些很酷的想法,并看到为什么选择这种特定算法的思考过程,那绝对是迷人的。在这篇论文出来之前,Jeremy 不认识任何研究其基础数学的人,所以每个人都必须学习这些数学知识。这篇论文做了很好的工作,列出了所有的要点(你需要自己阅读一些内容)。所以如果你对深入研究某篇论文背后更深层次的数学感兴趣,想看看学习它是什么感觉,我会选择这篇,因为在那个理论部分结束时,你会说“我现在明白他们为什么要设计这种算法了。”
GAN 的基本思想是它是一个生成模型[51:23]。它将创建句子、创建图像或生成一些东西。它将尝试创建一些很难区分生成的东西和真实的东西的东西。因此,生成模型可以用于换脸视频——目前发生的深度伪造和虚假色情非常有争议。它可以用来伪造某人的声音。它可以用来伪造对医学问题的回答——但在这种情况下,它并不是真正的伪造,它可以是对医学问题的生成回答,实际上是一个好的回答,因此你在生成语言。例如,你可以为图像生成标题。因此,生成模型有许多有趣的应用。但一般来说,它们需要足够好,例如,如果你要用它自动为凯丽·费舍尔在下一部星球大战电影中的新场景而她已经不在了,你想尝试生成一个看起来一样的图像,那么它必须欺骗星球大战的观众,让他们认为“好吧,那看起来不像奇怪的凯丽·费舍尔——那看起来像真正的凯丽·费舍尔。或者如果你试图生成对医学问题的回答,你希望生成的英语读起来流畅清晰,并且听起来有权威和意义。生成对抗网络的思想是我们不仅要创建一个生成模型来创建生成的图像,还要创建一个第二个模型,它将尝试挑选哪些是真实的,哪些是生成的(我们将称之为“假的”)。因此,我们有一个生成器,它将创建我们的虚假内容,还有一个鉴别器,它将努力变得擅长识别哪些是真实的,哪些是假的。因此,将有两个模型,它们将是对抗性的,意味着生成器将努力不断提高欺骗鉴别器认为假的是真实的能力,而鉴别器将努力不断提高区分真实和虚假的能力。因此,它们将正面交锋。这基本上就像 Jeremy 刚刚描述的那样[54:14]:
-
我们将在 PyTorch 中构建两个模型
-
我们将创建一个训练循环,首先说鉴别器的损失函数是“你能分辨真实和虚假吗,然后更新那个的权重。
-
我们将为生成器创建一个损失函数,即“你能生成一些能欺骗鉴别器的东西并从中更新权重。
-
然后我们将循环几次并看看会发生什么。
查看代码[54:52]
笔记本
GAN 有很多不同的用途。我们将做一些有点无聊但易于理解的事情,而且甚至可能的是我们将从无中生成一些图片。我们只是让它画一些图片。具体来说,我们将让它画卧室的图片。希望你有机会在这一周内使用自己的数据集玩耍。如果你选择一个非常多样化的数据集,比如 ImageNet,然后让 GAN 尝试创建 ImageNet 的图片,它往往做得不太好,因为你想要的图片不够清晰。所以最好给它,例如,有一个名为CelebA的数据集,其中包含名人的脸部图片,这对 GAN 非常有效。你可以生成真实但实际上不存在的名人脸。卧室数据集也是一个不错的选择——同一种类型的图片。
有一个叫做 LSUN 场景分类数据集的东西。
from fastai.conv_learner import *
from fastai.dataset import *
import gzip
下载 LSUN 场景分类数据集卧室类别,解压缩它,并将其转换为 jpg 文件(脚本文件夹在dl2文件夹中):
curl 'http://lsun.cs.princeton.edu/htbin/download.cgi?tag=latest&category=bedroom&set=train' -o bedroom.zip
unzip bedroom.zip
pip install lmdb
python lsun-data.py {PATH}/bedroom_train_lmdb --out_dir {PATH}/bedroom
这在 Windows 上没有经过测试 - 如果不起作用,您可以使用 Linux 框来转换文件,然后复制它们。或者,您可以从 Kaggle 数据集中下载这个 20%的样本。
PATH = Path('data/lsun/')
IMG_PATH = PATH/'bedroom'
CSV_PATH = PATH/'files.csv'
TMP_PATH = PATH/'tmp'
TMP_PATH.mkdir(exist_ok=True)
在处理我们的数据时,通过 CSV 路线会更容易。因此,我们生成一个包含我们想要的文件列表和一个虚假标签“0”的 CSV,因为我们实际上根本没有这些标签。一个 CSV 文件包含卧室数据集中的所有内容,另一个包含随机的 10%。这样做很好,因为这样我们在实验时大多数时间可以使用样本,因为即使只是读取列表也需要很长时间,因为有超过一百万个文件。
files = PATH.glob('bedroom/**/*.jpg')
with CSV_PATH.open('w') as fo:
for f in files:
fo.write(f'{f.relative_to(IMG_PATH)},0\n')
# Optional - sampling a subset of files
CSV_PATH = PATH/'files_sample.csv'
files = PATH.glob('bedroom/**/*.jpg')
with CSV_PATH.open('w') as fo:
for f in files:
if random.random()<0.1:
fo.write(f'{f.relative_to(IMG_PATH)},0\n')
这看起来非常熟悉。这是在 Jeremy 意识到顺序模型更好之前。因此,如果将这与以前的顺序模型的卷积块进行比较,这里有更多的代码行数——但它做的事情是一样的,卷积,ReLU,批量归一化。
class ConvBlock(nn.Module):
def __init__(self, ni, no, ks, stride, bn=True, pad=None):
super().__init__()
if pad is None:
pad = ks//2//stride
self.conv = nn.Conv2d(
ni, no,
ks, stride,
padding=pad,
bias=False
)
self.bn = nn.BatchNorm2d(no) if bn else None
self.relu = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
x = self.relu(self.conv(x))
return self.bn(x) if self.bn else x
我们要做的第一件事是构建一个鉴别器。鉴别器将接收一幅图像作为输入,并输出一个数字。如果它认为这幅图像是真实的,那么这个数字应该更低。当然,“它为什么输出一个更低的数字”这个问题不会出现在架构中,这将在损失函数中。所以我们所要做的就是创建一个接收图像并输出数字的东西。这些代码的很多部分都是从这篇论文的原始作者那里借来的,所以一些命名方案与我们习惯的不同。但它看起来与我们之前的很相似。我们从卷积(conv,ReLU,批量归一化)开始。然后我们有一堆额外的卷积层——这不会使用残差,所以它看起来与之前非常相似,有一堆额外的层,但这些将是卷积层而不是残差层。最后,我们需要添加足够的步幅为 2 的卷积层,使网格大小减小到不大于 4x4。所以它将继续使用步幅 2,将大小除以 2,并重复直到我们的网格大小不大于 4。这是一个非常好的方法,可以创建网络中所需的任意数量的层,以处理任意大小的图像并将它们转换为固定的已知网格大小。
问题:GAN 是否需要比狗和猫或 NLP 等更多的数据?还是可以相提并论?老实说,我有点尴尬地说我不是 GAN 的专家从业者。我在第一部分教授的东西是我很高兴地说我知道如何做这些事情的最佳方式,所以我可以展示像我们刚刚在 CIFAR10 中所做的那样的最新结果,有一些学生的帮助。我在 GAN 方面一点也不行,所以我不太确定你需要多少。总的来说,似乎需要相当多,但请记住我们在狗和猫方面不需要太多的原因是因为我们有一个预训练模型,我们可以利用预训练的 GAN 模型并微调它们,可能。据我所知,我认为没有人这样做过。这可能是人们考虑和实验的一个非常有趣的事情。也许人们已经这样做了,有一些文献我们还没有接触到。我对 GAN 的主要文献有一些了解,但并不是全部,所以也许我错过了关于 GAN 中迁移学习的一些内容。但这可能是不需要太多数据的诀窍。
问题:是单周期学习率和动量退火加上八个 GPU 并行训练在半精度下的巨大加速?只有消费级 GPU 才能进行半精度计算吗?另一个问题,为什么从单精度到半精度的计算速度提高了 8 倍,而从双精度到单精度只提高了 2 倍?好的,所以 CIFAR10 的结果,从单精度到半精度并不是提高了 8 倍。从单精度到半精度大约快了 2 到 3 倍。NVIDIA 声称张量核心的 flops 性能,在学术上是正确的,但在实践中是没有意义的,因为这真的取决于你需要什么调用来做什么事情——所以半精度大约提高了 2 到 3 倍。所以半精度有所帮助,额外的 GPU 有所帮助,单周期有很大帮助,然后另一个关键部分是我告诉你的参数调整。所以仔细阅读 Wide ResNet 论文,识别他们在那里发现的东西的类型,然后编写一个你刚刚看到的架构的版本,使我们可以轻松地调整参数,整夜不眠地尝试每种可能的不同核大小、核数、层组数、层组大小的组合。记住,我们做了一个瓶颈,但实际上我们更倾向于扩大,所以我们增加了大小,然后减小了,因为这更好地利用了 GPU。所以所有这些结合在一起,我会说单周期也许是最关键的,但每一个都导致了巨大的加速。这就是为什么我们能够在 CIFAR10 的最新技术上取得 30 倍的改进。我们对其他事情有一些想法——在这个 DAWN 基准完成之后,也许我们会尝试更进一步,看看是否可以在某一天打破一分钟。那将很有趣。
class DCGAN_D(nn.Module):
def __init__(self, isize, nc, ndf, n_extra_layers=0):
super().__init__()
assert isize % 16 == 0, "isize has to be a multiple of 16"
self.initial = ConvBlock(nc, ndf, 4, 2, bn=False)
csize,cndf = isize/2,ndf
self.extra = nn.Sequential(*[
ConvBlock(cndf, cndf, 3, 1)
for t in range(n_extra_layers)
])
pyr_layers = []
while csize > 4:
pyr_layers.append(ConvBlock(cndf, cndf*2, 4, 2))
cndf *= 2; csize /= 2
self.pyramid = nn.Sequential(*pyr_layers)
self.final = nn.Conv2d(cndf, 1, 4, padding=0, bias=False)
def forward(self, input):
x = self.initial(input)
x = self.extra(x)
x = self.pyramid(x)
return self.final(x).mean(0).view(1)
所以这是我们的鉴别器。关于架构需要记住的重要事情是它除了有一些输入张量大小和秩,以及一些输出张量大小和秩之外,什么也不做。正如你所看到的,最后一个卷积层只有一个通道。这与我们通常的做法不同,因为通常我们的最后一层是一个线性块。但我们这里的最后一层是一个卷积块。它只有一个通道,但它的网格大小大约是 4x4(不超过 4x4)。所以我们将输出(假设是 4x4),4x4x1 张量。然后我们计算平均值。所以它从 4x4x1 变成一个标量。这有点像最终的自适应平均池化,因为我们有一个通道,我们取平均值。这有点不同——通常我们首先进行平均池化,然后通过一个全连接层来得到我们的输出。但这里是得到一个通道,然后取平均值。Jeremy 怀疑如果我们按照正常方式做会更好,但他还没有尝试过,他也没有足够好的直觉来知道是否漏掉了什么——但如果有人想要尝试在自适应平均池化层和一个具有单个输出的全连接层之后添加一个,那将是一个有趣的实验。
这就是一个鉴别器。假设我们已经有了一个生成器——有人说“好的,这里有一个生成卧室的生成器。我希望你建立一个模型,可以找出哪些是真实的,哪些是假的”。我们将拿取数据集,并标记一堆来自生成器的假卧室图像,以及 LSUN 数据集中真实卧室的一堆图像,然后在每个图像上贴上 1 或 0。然后我们将尝试让鉴别器区分出差异。所以这将是足够简单的。但我们还没有得到一个生成器。我们需要建立一个。我们还没有讨论损失函数——我们将假设有一个损失函数可以做到这一点。
生成器
生成器也是一种架构,本身不会做任何事情,直到我们有损失函数和数据。但张量的秩和大小是什么?生成器的输入将是一个随机数向量。在论文中,他们称之为“先验”。有多大?我们不知道。这个想法是不同的一堆随机数将生成一个不同的卧室。因此,我们的生成器必须将一个向量作为输入,通过顺序模型,将其转换为一个秩为 4 的张量(没有批量维度的秩为 3)-高度乘以宽度乘以 3。因此,在最后一步,nc(通道数)最终将变为 3,因为它将创建一个大小为 3 的通道图像。
class DeconvBlock(nn.Module):
def __init__(self, ni, no, ks, stride, pad, bn=True):
super().__init__()
self.conv = nn.ConvTranspose2d(
ni, no,
ks, stride,
padding=pad, bias=False
)
self.bn = nn.BatchNorm2d(no)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv(x))
return self.bn(x) if self.bn else x
class DCGAN_G(nn.Module):
def __init__(self, isize, nz, nc, ngf, n_extra_layers=0):
super().__init__()
assert isize % 16 == 0, "isize has to be a multiple of 16"
cngf, tisize = ngf//2, 4
while tisize!=isize:
cngf*=2; tisize*=2
layers = [DeconvBlock(nz, cngf, 4, 1, 0)]
csize, cndf = 4, cngf
while csize < isize//2:
layers.append(DeconvBlock(cngf, cngf//2, 4, 2, 1))
cngf //= 2; csize *= 2
layers += [
DeconvBlock(cngf, cngf, 3, 1, 1)
for t in range(n_extra_layers)
]
layers.append(nn.ConvTranspose2d(cngf, nc, 4, 2, 1, bias=False))
self.features = nn.Sequential(*layers)
def forward(self, input):
return F.tanh(self.features(input))
问题:在 ConvBlock 中,为什么批量归一化在 ReLU 之后(即self.bn(self.relu(...)))?我通常期望先进行 ReLU,然后批量归一化,这实际上是 Jeremy 认为有意义的顺序。我们在 darknet 中使用的顺序是 darknet 论文中使用的顺序,所以每个人似乎对这些事情有不同的顺序。事实上,大多数人对 CIFAR10 有一个不同的顺序,即批量归一化→ReLU→卷积,这是一种奇特的思考方式,但事实证明,对于残差块来说,这通常效果更好。这被称为“预激活 ResNet”。有一些博客文章中,人们已经尝试了不同顺序的事物,似乎这很大程度上取决于特定数据集以及您正在处理的内容,尽管性能差异很小,除非是为了比赛,否则您不会在意。
反卷积
因此,生成器需要从一个向量开始,最终得到一个秩为 3 的张量。我们还不知道如何做到这一点。我们需要使用一种称为“反卷积”的东西,PyTorch 称之为转置卷积-相同的东西,不同的名称。反卷积是一种增加网格大小而不是减小网格大小的东西。因此,像所有事物一样,在 Excel 电子表格中最容易看到。
这是一个卷积。我们开始,假设有一个单通道的 4x4 网格单元。让我们通过一个单输出滤波器的 3x3 核心。所以我们有一个输入通道,一个滤波器核心,如果我们不添加任何填充,最终会得到 2x2。记住,卷积只是核心和适当网格单元的乘积的总和。所以这是我们标准的 3x3 卷积一个通道一个滤波器。

现在的想法是我们想要朝相反的方向发展。我们想要从我们的 2x2 开始,我们想要创建一个 4x4。具体来说,我们想要创建与我们开始的相同的 4x4。我们想通过使用卷积来实现这一点。我们如何做到这一点?
如果我们有一个 3x3 卷积,那么如果我们想要创建一个 4x4 输出,我们将需要创建这么多填充:

因为有这么多填充,我们最终会得到 4x4。所以假设我们的卷积滤波器只是一堆零,那么我们可以通过进行这个减法来计算每个单元格的错误:

然后我们可以通过对这些错误的绝对值求和来获得绝对值之和(L1 损失):

现在我们可以使用优化,在 Excel 中称为“求解器”来进行梯度下降。所以我们将设置总单元格等于最小值,然后尝试通过改变我们的滤波器来减少我们的损失。你可以看到它提出了一个滤波器,使得结果几乎像数据一样。它并不完美,一般来说,你不能假设反卷积可以完全创建出你想要的完全相同的东西,因为这里没有足够的。因为滤波器中有 9 个东西,结果中有 16 个东西。但它做出了一个相当不错的尝试。所以这就是反卷积的样子 - 在一个 2x2 的网格单元上进行步长为 1 的 3x3 反卷积。

问题: 创建一个鉴别器来识别假新闻和真实新闻有多难?你不需要任何特殊的东西 - 那只是一个分类器。所以你可以使用之前课程和第 4 课的 NLP 分类器。在这种情况下,没有生成部分,所以你只需要一个数据集,其中说这些是我们认为是假新闻的东西,这些是我们认为是真实新闻的东西,它应该工作得非常好。据我们所知,如果你尝试,你应该得到和其他人一样好的结果 - 它是否足够实用,Jeremy 不知道。在这个阶段,你能做的最好的事情可能是生成一种分类,说这些东西看起来相当可疑,基于它们的写作方式,然后一些人可以去核实它们。NLP 分类器和 RNN 不能核实事实,但它可以识别这些是以那种高度通俗的风格写成的,通常假新闻就是这样写的,所以也许这些值得关注。这可能是你在不依赖某种外部数据源的情况下所能希望的最好的结果。但重要的是要记住,鉴别器基本上只是一个分类器,你不需要任何特殊的技术,超出我们已经学会的 NLP 分类的范围。
ConvTranspose2d
在 PyTorch 中进行反卷积,只需说:
nn.ConvTranspose2d(ni, no, ks, stride, padding=pad, bias=False)
-
ni: 输入通道的数量 -
no: 输出通道的数量 -
ks: 卷积核大小
它被称为 ConvTranspose 的原因是因为事实证明这与卷积的梯度计算是相同的。这就是为什么他们这样称呼它。
可视化

deeplearning.net/software/theano/tutorial/conv_arithmetic.html
左边的是我们刚刚看到的进行 2x2 反卷积。如果有一个步长为 2,那么你不仅在外面周围有填充,而且你实际上还需要在中间放填充。它们实际上并不是这样实现的,因为这样做很慢。在实践中,你会以不同的方式实现它们,但所有这些都是在幕后发生的,所以你不必担心。我们之前已经讨论过这个卷积算术教程,如果你对卷积仍然不熟悉,并且想要熟悉反卷积,这是一个很好的网站。如果你想看这篇论文,它是A guide to convolution arithmetic for deep learning。
DeconvBlock 看起来与 ConvBlock 几乎相同,只是多了一个 Transpose。我们像以前一样进行卷积 → relu → 批量归一化,它有输入滤波器和输出滤波器。唯一的区别是步长为 2 意味着网格大小会加倍而不是减半。

问题:nn.ConvTranspose2d 和 nn.Upsample 似乎做着相同的事情,即从上一层扩展网格大小(高度和宽度)。我们可以说 nn.ConvTranspose2d 总是优于 nn.Upsample 吗,因为 nn.Upsample 仅仅是调整大小并用零或插值填充未知部分吗?不,不能。在 distill.pub 上有一篇名为 反卷积和棋盘伪影 的出色互动论文指出,我们现在正在做的事情极其不理想,但好消息是其他人都在这样做。

看一下这里,你能看到这些棋盘伪影吗?这些都来自实际论文,基本上他们注意到每一篇关于生成模型的论文都有这些棋盘伪影,他们意识到这是因为当您使用大小为三的内核的步幅 2 卷积时,它们会重叠。因此,一些网格单元会获得两倍的激活。

因此,即使您从随机权重开始,最终也会得到一个棋盘状的伪影。所以你越深入,情况就越糟。他们的建议没有那么直接,Jeremy 发现对于大多数生成模型,上采样更好。如果你使用 nn.Upsample,基本上是在做池化的相反操作 —— 它说让我们用四个(2x2)网格单元替换这一个。有许多方法可以进行上采样 —— 一种方法是将所有内容复制到这四个单元格中,另一种方法是使用双线性或双三次插值。有各种技术可以尝试创建平滑的上采样版本,您可以在 PyTorch 中选择任何一种。如果您进行了 2x2 的上采样,然后正常的 3x3 卷积,这是另一种与 ConvTranspose 相同的操作方式 —— 它将网格大小加倍,并对其进行一些卷积运算。对于生成模型,这几乎总是效果更好。在 distil.pub 的出版物中,他们指出也许这是一个好方法,但他们没有直接说出来,而 Jeremy 会直接说出来。话虽如此,对于 GANS,他还没有取得太大的成功,他认为可能需要一些调整才能使其正常工作。问题在于在早期阶段,它没有产生足够的噪音。他尝试过使用上采样的版本,您可以看到噪音看起来并不是很嘈杂。下周当我们研究风格转移和超分辨率时,您将看到 nn.Upsample 真正发挥作用。
生成器,我们现在可以从向量开始。我们可以决定并说好,让我们不把它看作一个向量,而实际上是一个 1x1 的网格单元,然后我们可以将其转换为 4x4,然后是 8x8 等等。这就是为什么我们必须确保它是一个合适的倍数,以便我们可以创建出正确大小的东西。正如您所看到的,它正在做与之前完全相反的事情。它每次使单元格大小增加 2,直到达到我们想要的一半大小,然后最后我们再添加 n 个,步幅为 1。然后我们再添加一个 ConvTranspose 最终得到我们想要的大小,然后我们完成了。最后我们通过一个 tanh,这将强制我们处于零到一的范围内,因为当然我们不希望输出任意大小的像素值。因此,我们有一个生成器架构,它输出一个给定大小的图像,具有正确数量的通道,值在零到一之间。

在这一点上,我们现在可以创建我们的模型数据对象。这些东西需要一段时间来训练,所以我们将其设置为 128x128(只是一个更快的便利方式)。因此,这将是输入的大小,但然后我们将使用转换将其转换为 64x64。
最近有更多的进展,试图将其提高到高分辨率大小,但它们仍然倾向于要求批量大小为 1 或大量的 GPU。所以我们试图做一些可以用单个消费者 GPU 完成的事情。这是一个 64x64 卧室的例子。
bs,sz,nz = 64,64,100
tfms = tfms_from_stats(inception_stats, sz)
md = ImageClassifierData.from_csv(
PATH, 'bedroom',
CSV_PATH,
tfms=tfms,
bs=128,
skip_header=False,
continuous=True
)
md = md.resize(128)
x,_ = next(iter(md.val_dl))
plt.imshow(md.trn_ds.denorm(x)[0]);

将它们全部放在一起
我们将几乎所有事情都手动完成,所以让我们继续创建我们的两个模型 - 我们的生成器和鉴别器,正如你所看到的它们是 DCGAN,换句话说,它们是出现在这篇论文中的相同模块。值得回头看一下 DCGAN 论文,看看这些架构是什么,因为假定当你阅读 Wasserstein GAN 论文时,你已经知道这一点。
netG = DCGAN_G(sz, nz, 3, 64, 1).cuda()
netD = DCGAN_D(sz, 3, 64, 1).cuda()
问题:如果我们想要在 0 到 1 之间的值,我们不应该使用 sigmoid 吗?像往常一样,我们的图像已经被归一化为范围从-1 到 1,因此它们的像素值不再在 0 到 1 之间。这就是为什么我们希望值从-1 到 1,否则我们将无法为鉴别器提供正确的输入。
所以我们有一个生成器和一个鉴别器,我们需要一个返回“先验”向量(即一堆噪音)的函数。我们通过创建一堆零来实现这一点。nz是z的大小 - 在我们的代码中经常看到一个神秘的字母,那是因为那是他们在论文中使用的字母。这里,z是我们噪音向量的大小。然后我们使用正态分布生成 0 到 1 之间的随机数。这需要是一个变量,因为它将参与梯度更新。
def create_noise(b):
return V(torch.zeros(b, nz, 1, 1).normal_(0, 1))
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat):
ax.imshow(pred_ims[i])

这里是创建一些噪音并生成四个不同噪音片段的示例。
def gallery(x, nc=3):
n,h,w,c = x.shape
nr = n//nc
assert n == nr*nc
return (
x.reshape(nr, nc, h, w, c)
.swapaxes(1,2)
.reshape(h*nr, w*nc, c)
)
我们需要一个优化器来更新我们的梯度。在 Wasserstein GAN 论文中,他们告诉我们使用 RMSProp:

我们可以很容易地在 PyTorch 中做到这一点:
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-4)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-4)
在论文中,他们建议使用学习率为 0.00005(5e-5),我们发现1e-4似乎有效,所以我们将其增加了一点。
现在我们需要一个训练循环:

为了更容易阅读
训练循环将经过我们选择的一些时代(这将是一个参数)。记住,当你手动完成所有事情时,你必须记住所有手动步骤:
-
当你训练模型时,你必须将模块设置为训练模式,并在评估时将其设置为评估模式,因为在训练模式下,批量归一化更新会发生,丢失会发生,在评估模式下,这两个事情会被关闭。
-
我们将从我们的训练数据加载器中获取一个迭代器
-
我们将看看我们需要经过多少步,然后我们将使用
tqdm给我们提供一个进度条,然后我们将经过那么多步。
论文中算法的第一步是更新鉴别器(在论文中,他们称鉴别器为“评论家”,w是评论家的权重)。所以第一步是训练我们的评论家一点点,然后我们将训练我们的生成器一点点,然后我们将回到循环的顶部。论文中的内部for循环对应于我们代码中的第二个while循环。
现在我们要做的是我们现在有一个随机的生成器。所以我们的生成器将生成看起来像噪音的东西。首先,我们需要教我们的鉴别器区分噪音和卧室之间的区别 - 你希望这不会太难。所以我们只是按照通常的方式做,但有一些小调整:
-
我们将获取一小批真实卧室照片,这样我们就可以从迭代器中获取下一批,将其转换为变量。
-
然后我们将计算损失——这将是鉴别器认为这看起来假的程度(“真实的看起来假吗?”)。
-
然后我们将创建一些假图像,为此我们将创建一些随机噪音,并将其通过我们的生成器,这个阶段它只是一堆随机权重。这将创建一个小批量的假图像。
-
然后我们将通过与之前相同的鉴别器模块来获取该损失(“假的看起来有多假?”)。记住,当你手动做所有事情时,你必须在循环中将梯度归零(
netD.zero_grad())。如果你忘记了这一点,请回到第 1 部分课程,我们从头开始做所有事情。 -
最后,总鉴别器损失等于真实损失减去假损失。
所以你可以在这里看到:

他们没有谈论损失,实际上他们只谈论了一个梯度更新。

在 PyTorch 中,我们不必担心获取梯度,我们只需指定损失并调用loss.backward(),然后鉴别器的optimizer.step()。有一个关键步骤,即我们必须将 PyTorch 模块中的所有权重(参数)保持在-0.01 和 0.01 的小范围内。为什么?因为使该算法工作的数学假设仅适用于一个小球。了解为什么这样是有趣的数学是有趣的,但这与这篇论文非常相关,了解它不会帮助你理解其他论文,所以只有在你感兴趣的情况下才去学习。Jeremy 认为这很有趣,但除非你对 GANs 非常感兴趣,否则这不会是你在其他地方会重复使用的信息。他还提到,在改进的 Wasserstein GAN 出现后,有更好的方法来确保你的权重空间在这个紧密球内,即惩罚梯度过高,所以现在有稍微不同的方法来做这个。但这行代码是关键贡献,它是使 Wasserstein GAN 成功的关键:
for p in netD.parameters(): p.data.clamp_(-0.01, 0.01)
在这之后,我们有一个可以识别真实卧室和完全随机糟糕生成的图像的鉴别器。现在让我们尝试创建一些更好的图像。所以现在将可训练的鉴别器设置为 false,将可训练的生成器设置为 true,将生成器的梯度归零。我们的损失再次是生成器的fw(鉴别器)应用于一些更多的随机噪音。所以这与之前完全相同,我们对噪音进行生成,然后将其传递给鉴别器,但这次,可训练的是生成器,而不是鉴别器。换句话说,在伪代码中,更新的是θ,即生成器的参数。它接受噪音,生成一些图像,尝试弄清楚它们是假的还是真实的,并使用这些梯度来更新生成器的权重,而不是之前我们是根据鉴别器来获取梯度,并使用 RMSProp 和 alpha 学习率来更新我们的权重。
def train(niter, first=True):
gen_iterations = 0
for epoch in trange(niter):
netD.train(); netG.train()
data_iter = iter(md.trn_dl)
i,n = 0,len(md.trn_dl)
with tqdm(total=n) as pbar:
while i < n:
set_trainable(netD, True)
set_trainable(netG, False)
d_iters = (
100
if (first and (gen_iterations < 25)
or (gen_iterations % 500 == 0))
else 5
)
j = 0
while (j < d_iters) and (i < n):
j += 1; i += 1
for p in netD.parameters():
p.data.clamp_(-0.01, 0.01)
real = V(next(data_iter)[0])
real_loss = netD(real)
fake = netG(create_noise(real.size(0)))
fake_loss = netD(V(fake.data))
netD.zero_grad()
lossD = real_loss-fake_loss
lossD.backward()
optimizerD.step()
pbar.update()
set_trainable(netD, False)
set_trainable(netG, True)
netG.zero_grad()
lossG = netD(netG(create_noise(bs))).mean(0).view(1)
lossG.backward()
optimizerG.step()
gen_iterations += 1
print(
f'Loss_D {to_np(lossD)}; Loss_G {to_np(lossG)}; ' +
f'D_real {to_np(real_loss)}; Loss_D_fake {to_np(fake_loss)}'
)
你会发现鉴别器被训练ncritic次(上面代码中的 d_iters),他们将其设置为 5,每次我们训练生成器一次。论文中谈到了这一点,但基本思想是如果鉴别器还不知道如何区分,那么让生成器变得更好是没有意义的。这就是为什么我们有第二个 while 循环。这里是 5:
d_iters = (
100
if (first and (gen_iterations < 25)
or (gen_iterations % 500 == 0))
else 5
)
实际上,稍后的论文中添加的内容或者可能是补充材料是,不时地在开始时,您应该在鉴别器上执行更多步骤,以确保鉴别器是有能力的。
torch.backends.cudnn.benchmark=True
让我们为一个时代进行训练:
train(1, False)0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 18957/18957 [19:48<00:00, 10.74it/s]
Loss_D [-0.67574]; Loss_G [0.08612]; D_real [-0.1782]; Loss_D_fake [0.49754]
100%|██████████| 1/1 [19:49<00:00, 1189.02s/it]
然后让我们创建一些噪音,这样我们就可以生成一些示例。
fixed_noise = create_noise(bs)
但在此之前,将学习率降低 10 倍,并再进行一次训练:
set_trainable(netD, True)
set_trainable(netG, True)
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-5)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-5)
train(1, False)
'''
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 18957/18957 [23:31<00:00, 13.43it/s]
Loss_D [-1.01657]; Loss_G [0.51333]; D_real [-0.50913]; Loss_D_fake [0.50744]
100%|██████████| 1/1 [23:31<00:00, 1411.84s/it]
'''
然后让我们使用噪音传递给我们的生成器,然后通过我们的反标准化将其转换回我们可以看到的东西,然后绘制它:
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

我们有一些卧室。这些不是真实的卧室,有些看起来并不像卧室,但有些看起来很像卧室,这就是想法。这就是 GAN。最好的方法是将 GAN 视为一种基础技术,你可能永远不会像这样使用它,但你会以许多有趣的方式使用它。例如,我们将使用它来创建一个循环 GAN。
问题:为什么要特别使用 RMSProp 作为优化器,而不是 Adam 等等?我不记得论文中有明确讨论过这个问题。我不知道这是实验性的还是理论上的原因。看看论文中是怎么说的。
来自论坛
通过实验,我发现 Adam 和 WGAN 不仅效果更差 - 它导致生成器训练失败。
来自 WGAN 论文:
最后,作为一个负面结果,我们报告说当使用基于动量的优化器(如 Adam [8](具有β1>0))对评论者进行训练时,WGAN 训练有时会变得不稳定,或者当使用高学习率时。由于评论者的损失是非平稳的,基于动量的方法似乎表现更差。我们确定动量可能是一个潜在原因,因为随着损失的增加和样本变得更糟,Adam 步骤和梯度之间的余弦通常变为负值。这种余弦为负值的唯一情况是在这些不稳定的情况下。因此,我们转而使用 RMSProp [21],它被认为在非平稳问题上表现良好
问题: 在训练过程中,检测过拟合的一个合理方法是什么?或者在训练结束后评估这些 GAN 模型的性能的一个方法是什么?换句话说,训练/验证/测试集的概念如何转化为 GANs [1:41:57]?这是一个很棒的问题,很多人开玩笑说 GANs 是唯一不需要测试集的领域,人们利用这一点编造东西并说看起来很棒。GANs 存在一些著名的问题,其中之一被称为模式崩溃。模式崩溃发生在你查看卧室时,结果发现只有三种卧室,每个可能的噪声向量都映射到这三种卧室中的一种。你查看画廊,结果发现它们都是相同的东西或者只有三种不同的东西。模式崩溃很容易看到,如果崩溃到一个很小的模式数量,比如 3 或 4。但如果模式崩溃到 10,000 种模式怎么办?因此,只有 10,000 种可能的卧室,所有的噪声向量都崩溃到这些卧室。你不太可能在我们刚刚看到的画廊视图中看到,因为在 10,000 种卧室中很少会有两个相同的卧室。或者如果每个卧室基本上是输入的直接副本 —— 它基本上记住了一些输入。这可能正在发生吗?事实是,大多数论文在检查这些问题方面做得不好,有时甚至根本不检查。因此,我们如何评估 GANs 甚至也许我们应该真正正确地评估 GANs 是一个现在还不够广泛理解的问题。一些人正在努力推动。Ian Goodfellow 是最著名的深度学习书籍的第一作者,也是 GANs 的发明者,他一直在发送持续的推文提醒人们测试 GANs 的重要性。如果你看到一篇声称有异常 GAN 结果的论文,那么这绝对值得关注。他们是否谈到了模式崩溃?他们是否谈到了记忆化?等等。
问题: GANs 可以用于数据增强吗 [1:45:33]?是的,绝对可以使用 GAN 进行数据增强。你应该吗?我不知道。有一些论文尝试使用 GANs 进行半监督学习。我还没有找到任何特别引人注目的论文,在广泛研究的真正有趣的数据集上展示出最先进的结果。我有点怀疑,原因是在我的经验中,如果用合成数据训练模型,神经网络将变得极其擅长识别你合成数据的具体问题,并且最终学到的将是这些问题。还有很多其他方法可以做半监督模型,效果很好。有一些地方可以工作。例如,你可能还记得 Otavio Good 在第一部分的缩放卷积网络中创建的那个奇妙的可视化,其中显示了字母通过 MNIST,他,至少在那个时候,是自动遥控汽车比赛中的第一名,他使用合成增强数据训练了他的模型,基本上是拿真实的汽车绕着赛道行驶的视频,然后添加了虚假的人和虚假的其他汽车。我认为这样做效果很好,因为 A. 他有点天才,B. 因为我认为他有一个明确定义的小子集需要处理。但总的来说,使用合成数据真的很难。我尝试过几十年使用合成数据和模型(显然不包括 GANs,因为它们是相当新的),但总的来说,这很难做到。非常有趣的研究问题。
Cycle GAN [1:41:08]
Paper / Notebook
我们将使用 cycle GAN 将马变成斑马。您也可以使用它将莫奈的印刷品转变为照片,或将优胜美地夏季的照片转变为冬季。

这将非常简单,因为它只是一个神经网络。我们要做的就是创建一个包含大量斑马照片的输入,并将每个照片与等价的马照片配对,然后训练一个从一个到另一个的神经网络。或者您可以对每幅莫奈的画做同样的事情——创建一个包含该地点照片的数据集……哦等等,这不可能,因为莫奈绘制的地方已经不存在了,也没有确切的斑马版本的马……这将如何运作?这似乎违背了我们对神经网络能做什么以及它们如何做的一切认知。
所以某种方式,这些伯克利的人创造了一个模型,可以将马变成斑马,尽管没有任何照片。除非他们出去画马并拍摄前后照片,但我相信他们没有。那么他们是如何做到的呢?这有点天才。
我知道目前正在进行最有趣的 cycle GAN 实践的人是我们的学生 Helena Sarin。她是我所知道的唯一一位 cycle GAN 艺术家。




以下是她更多令人惊叹的作品,我觉得非常有趣。我在这堂课开始时提到,GANs 属于尚未出现的东西,但它们几乎已经到位了。在这种情况下,世界上至少有一个人正在使用 GANs(具体来说是 cycle GANs)创作美丽而非凡的艺术作品。至少我知道有十几个人正在用神经网络进行有趣的创意工作。创意人工智能领域将会大幅扩展。

这是基本的技巧。这是来自 cycle GAN 论文。我们将有两幅图像(假设我们正在处理图像)。关键是它们不是配对的图像,所以我们没有一组马和等价斑马的数据集。我们有一堆马,一堆斑马。拿一匹马X,拿一匹斑马Y。我们将训练一个生成器(他们在这里称之为“映射函数”),将马变成斑马。我们将称之为映射函数G,并创建一个将斑马变成马的映射函数(也称为生成器),我们将称之为F。我们将创建一个鉴别器,就像以前一样,它将尽可能地识别真假马,我们将称之为Dx。另一个鉴别器,它将尽可能地识别真假斑马,我们将称之为Dy。这是我们的起点。
使这个工作的关键[1:51:27] - 所以我们在这里生成一个损失函数(Dx和Dy)。我们将创建一个叫做循环一致性损失的东西,它说当你用生成器将你的马变成斑马后,检查我是否能识别它是真实的。我们将我们的马变成斑马,然后尝试将那只斑马再变回我们开始的同一匹马。然后我们将有另一个函数,它将检查这匹马是否与原始马相似,这匹马是完全由这只斑马Y生成的,不知道x的任何信息。所以想法是,如果你生成的斑马看起来一点也不像原始马,你就没有机会将其变回原始马。因此,将x-hat与x进行比较的损失会非常糟糕,除非你能进入Y再出来,如果你能够创建一个看起来像原始马的斑马,那么你可能能够做到这一点。反之亦然 - 将你的斑马变成一个假马,检查你是否能识别它,然后尝试将其变回原始斑马并检查它是否看起来像原始的。
注意F(斑马到马)和G(马到斑马)正在做两件事。它们都将原始马变成斑马,然后将斑马再变回原始马。所以只有两个生成器。没有一个单独的生成器用于反向映射。你必须使用用于原始映射的相同生成器。这就是循环一致性损失。我认为这是天才。这种事情甚至可能存在的想法。老实说,当这一点出现时,我从未想过我甚至可以尝试解决这个问题。它似乎如此明显地不可能,然后你可以像这样解决它的想法 - 我只是觉得这太聪明了。
看这篇论文中的方程式是很好的,因为它们是很好的例子 - 它们写得相当简单,不像一些瓦瑟斯坦 GAN 论文那样,那些是很多理论证明和其他东西。在这种情况下,它们只是列出了正在发生的事情的方程式。你真的想要达到一个可以阅读并理解它们的程度。

所以我们有一匹马X和一只斑马Y。对于一些映射函数G,这是我们的马到斑马映射函数,然后有一个 GAN 损失,这是我们已经熟悉的一部分,它说我们有一匹马,一只斑马,一个假斑马识别器和一个马斑马生成器。损失就是我们之前看到的 - 我们能够从我们的斑马中画出一只斑马并识别它是真实的还是假的。然后拿一匹马变成一只斑马并识别它是真实的还是假的。然后做一减另一个(在这种情况下,它们里面有一个对数,但对数并不是非常重要)。这就是我们刚刚看到的东西。这就是为什么我们先做了瓦瑟斯坦 GAN。这只是一个标准的数学形式的 GAN 损失。
问题:所有这些听起来很像将一种语言翻译成另一种语言,然后再翻译回原来的语言。GANs 或任何等效物已经尝试过翻译吗?来自论坛的论文。回到我所知道的 — 通常在翻译中,你需要这种配对的输入(即平行文本 — “这是这个英语句子的法语翻译”)。最近有几篇论文显示了在没有配对数据的情况下创建高质量翻译模型的能力。我还没有实施它们,我不理解我没有实施的任何东西,但它们很可能在做同样的基本想法。我们将在本周内研究一下,并回复您。
循环一致性损失:所以我们有一个 GAN 损失,接下来是循环一致性损失。基本思想是我们从我们的马开始,使用我们的斑马生成器创建一匹斑马,然后使用我们的马生成器创建一匹马,并将其与原始马进行比较。这个双线与 1 是 L1 损失 — 差异的绝对值的和。否则,如果这是 2,那么它将是 L2 损失,即平方差的和。

我们现在知道这个波浪线的想法是从我们的马抓取一匹马。这就是我们所说的从分布中取样。有各种各样的分布,但在这些论文中,我们最常用的是经验分布,换句话说,我们有一些数据行,抓取一行。所以这里,它是说从数据中抓取一些东西,我们将称那个东西为x。为了重新概括:
-
从我们的马图片中,抓取一匹马
-
将其变成斑马
-
将其转换回马
-
将其与原始图像进行比较并求绝对值的和
-
也对斑马进行同样的操作
-
然后将两者相加
这就是我们的循环一致性损失。
完整目标

现在我们得到了我们的损失函数,整个损失函数取决于:
-
我们的马生成器
-
一个斑马生成器
-
我们的马识别器
-
我们的斑马识别器(又名鉴别器)
我们将加起来:
-
用于识别马的 GAN 损失
-
用于识别斑马的 GAN 损失
-
我们两个生成器的循环一致性损失
我们这里有一个 lambda,希望我们现在对这个想法有点习惯了,当你有两种不同的损失时,你可以加入一个参数,这样你可以将它们乘以一个相同的比例。我们在定位时也对我们的边界框损失与分类器损失做了类似的事情。
然后对于这个损失函数,我们将尝试最大化鉴别器的辨别能力,同时最小化生成器的辨别能力。因此,生成器和鉴别器将面对面地对抗。当你在论文中看到这个 min max 时,基本上意味着在你的训练循环中,一个东西试图让某事变得更好,另一个东西试图让某事变得更糟,有很多方法可以做到,但最常见的是你会在两者之间交替。你经常会在数学论文中看到这个被简称为 min-max。所以当你看到 min-max 时,你应该立即想到对抗训练。
实施循环 GAN
让我们看看代码。我们将要做一些几乎闻所未闻的事情,那就是我开始查看别人的代码,但并没有对整个东西感到恶心,然后自己重新做。我实际上说我相当喜欢这个,我喜欢它到足以向我的学生展示。这是代码的来源,这是一个为循环 GAN 创建原始代码的人之一,他们创建了一个 PyTorch 版本。我不得不稍微整理一下,但实际上它还是相当不错的。这个酷的地方是,你现在将看到几乎所有 fast.ai 的部分,或者其他相关的 fast.ai 部分,是由其他人以不同的方式编写的。所以你将看到他们如何处理数据集、数据加载器、模型、训练循环等等。
你会发现有一个cgan目录,这基本上几乎是原始的,只是做了一些清理,我希望有一天能提交为 PR。它是以一种不幸地使它与他们作为脚本使用的方式过于连接的方式编写的,所以我稍微整理了一下,以便我可以将其用作模块。但除此之外,它还是相当相似的。
from fastai.conv_learner import *
from fastai.dataset import *
from cgan.options.train_options import *
所以cgan是他们从 github 仓库复制的代码,做了一些小的改动。cgan迷你库的设置方式是,它假设配置选项是被传递到像脚本一样。所以他们有TrainOptions().parse方法,我基本上传入一个脚本选项的数组(我的数据在哪里,有多少线程,我想要丢弃吗,我要迭代多少次,我要怎么称呼这个模型,我要在哪个 GPU 上运行)。这给我们一个opt对象,你可以看到它包含了什么。你会看到它包含了一些我们没有提到的东西,那是因为它对我们没有提到的其他所有东西都有默认值。
opt = TrainOptions().parse(['--dataroot',
'/data0/datasets/cyclegan/horse2zebra', '--nThreads', '8',
'--no_dropout', '--niter', '100', '--niter_decay', '100',
'--name', 'nodrop', '--gpu_ids', '2'])
所以我们不再使用 fast.ai 的东西,我们将主要使用 cgan 的东西。
from cgan.data.data_loader import CreateDataLoader
from cgan.models.models import create_model
我们首先需要的是一个数据加载器。这也是一个很好的机会,让你再次练习使用你选择的编辑器或 IDE 浏览代码的能力。我们将从CreateDataLoader开始。你应该能够找到符号或在 vim 标签中直接跳转到CreateDataLoader,我们可以看到它创建了一个CustomDatasetDataLoader。然后我们可以看到CustomDatasetDataLoader是一个BaseDataLoader。我们可以看到它将使用标准的 PyTorch DataLoader,这很好。我们知道如果要使用标准的 PyTorch DataLoader,你需要传递一个数据集,我们知道数据集是包含长度和索引器的东西,所以当我们查看CreateDataset时,它应该会这样做。
这里是CreateDataset,这个库不仅仅是循环 GAN - 它处理对齐和不对齐的图像对。我们知道我们的图像对是不对齐的,所以我们要使用UnalignedDataset。

正如预期的那样,它有__getitem__和__len__。对于长度,A 和 B 是我们的马和斑马,我们有两组,所以较长的那个将是DataLoader的长度。__getitem__将会:
-
随机从我们的两匹马和斑马中抓取一些东西
-
用 Pillow(PIL)打开它们
-
通过一些转换运行它们
-
然后我们可以把马变成斑马,或者把斑马变成马,所以有一些方向
-
返回我们的马、斑马、马的路径和斑马的路径
希望你能看到这看起来与 fast.ai 所做的事情非常相似。当涉及到转换和性能时,fast.ai 显然做了更多,但请记住,这是为这个特定事情的研究代码,他们做了这么多工作,这是相当酷的。

data_loader = CreateDataLoader(opt)
dataset = data_loader.load_data()
dataset_size = len(data_loader)
dataset_size
'''
1334
'''
我们有一个数据加载器,所以我们可以将我们的数据加载到其中[2:06:17]。这将告诉我们其中有多少个小批次(这是 PyTorch 数据加载器的长度)。
下一步是创建一个模型。同样的想法,我们有不同类型的模型,我们将要做一个循环 GAN。

这是我们的CycleGANModel。CycleGANModel中有相当多的内容,所以让我们逐步找出将要使用的内容。在这个阶段,我们只是调用了初始化器,所以当我们初始化它时,它将会定义两个生成器,一个用于我们的马,一个用于斑马。它有一种方法来生成一组假数据,然后我们将获取我们的 GAN 损失,正如我们所讨论的,我们的循环一致性损失是一个 L1 损失。他们将使用 Adam,显然对于循环 GAN,他们发现 Adam 效果很好。然后我们将为我们的马判别器、斑马判别器和生成器各自创建一个优化器。生成器的优化器将包含马生成器和斑马生成器的参数,所有这些都在一个地方。

因此,初始化器将设置我们需要的所有不同网络和损失函数,并将它们存储在这个model中[2:08:14]。
model = create_model(opt)
然后打印出并向我们展示我们拥有的 PyTorch 模型。看到他们正在使用 ResNets,你会发现 ResNets 看起来非常熟悉,所以我们有卷积、批量归一化、Relu。InstanceNorm基本上与批量归一化相同,但它是针对一幅图像应用的,区别并不特别重要。你可以看到他们正在做反射填充,就像我们一样。当你尝试像这样从头开始构建所有东西时,这是很多工作,你可能会忘记 fast.ai 自动为你做的一些好事。你必须手动完成所有这些工作,最终只能得到其中的一部分。所以随着时间的推移,希望很快,我们将把所有这些 GAN 内容整合到 fast.ai 中,这将变得简单而容易。

我们有我们的模型,记住模型包含损失函数、生成器、判别器,所有这些都在一个方便的地方[2:09:32]。我已经复制、粘贴并稍微重构了他们代码中的训练循环,这样我们就可以在笔记本中运行它。所以这个应该看起来很熟悉。一个循环用于遍历每个 epoch,一个循环用于遍历数据。在这之前,我们设置了dataset。实际上这不是一个 PyTorch 数据集,我认为这是他们稍微令人困惑地用来谈论他们的组合数据,我们称之为模型数据对象——他们需要的所有数据。用tqdm循环遍历它,以获得进度条,这样我们就可以看看模型中发生了什么。
total_steps = 0
for epoch in range(opt.epoch_count, opt.niter + opt.niter_decay+1):
epoch_start_time = time.time()
iter_data_time = time.time()
epoch_iter = 0
for i, data in tqdm(enumerate(dataset)):
iter_start_time = time.time()
if total_steps % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_steps += opt.batchSize
epoch_iter += opt.batchSize
model.set_input(data)
model.optimize_parameters()
if total_steps % opt.display_freq == 0:
save_result = total_steps % opt.update_html_freq == 0
if total_steps % opt.print_freq == 0:
errors = model.get_current_errors()
t = (time.time() - iter_start_time) / opt.batchSize
if total_steps % opt.save_latest_freq == 0:
print(
'saving the latest model(epoch %d,total_steps %d)'
% (epoch, total_steps)
)
model.save('latest')
iter_data_time = time.time()
if epoch % opt.save_epoch_freq == 0:
print(
'saving the model at the end of epoch %d, iters %d'
% (epoch, total_steps)
)
model.save('latest')
model.save(epoch)
print(
'End of epoch %d / %d \t Time Taken: %d sec' %
(
epoch, opt.niter + opt.niter_decay,
time.time() - epoch_start_time
)
)
model.update_learning_rate()
set_input[2:10:32]:这是一种与 fast.ai 中所做的不同方法。这很巧妙,它相当特定于循环 GAN,但基本上在这个模型内部的想法是,我们将进入我们的数据并获取适当的数据。我们要么将马转换为斑马,要么将斑马转换为马,取决于我们选择的方式,A要么是马要么是斑马,反之亦然。如果需要,将其放在适当的 GPU 上,然后获取适当的路径。因此,模型现在有一批马和一批斑马。

现在我们优化参数[2:11:19]。这样看起来很好。你可以看到每一步。首先,尝试优化生成器,然后尝试优化马判别器,然后尝试优化斑马判别器。zero_grad()是 PyTorch 的一部分,以及step()。因此,有趣的部分是实际执行生成器反向传播的部分。

这里是[2:12:04]。让我们跳到关键部分。这里有我们刚刚在论文中看到的所有公式。让我们拿一匹马生成一只斑马。现在让我们使用鉴别器来看看我们是否能够判断它是假的还是真的(pred_fake)。然后让我们将其放入我们之前设置的损失函数中,以基于该预测获得 GAN 损失。然后让我们以相反的方向做同样的事情,使用相反的鉴别器,然后再次通过损失函数。然后让我们做循环一致性损失。再次,我们拿我们创建的假的东西,尝试将其转回原始状态。让我们使用之前创建的循环一致性损失函数将其与真实原始状态进行比较。这里是那个 lambda - 所以有一些权重我们使用了,实际上我们只是使用了他们在选项中建议的默认值。然后对相反的方向做同样的事情,然后将它们全部加在一起。然后进行反向步骤。就是这样。

所以我们可以为第一个鉴别器做同样的事情[2:13:50]。因为基本上所有的工作现在都已经完成了,这里要做的事情就少得多了。就是这样。我们不会一步步走过来,但基本上是我们已经看到的相同的基本东西。

所以optimize_parameters()正在计算损失并执行优化器步骤。不时保存并打印一些结果。然后不时更新学习率,所以他们在这里也有一些学习率退火的机制。有点像 fast.ai,他们有这个调度器的概念,你可以用它来更新你的学习率。

对于那些对更好地理解深度学习 API、更多地为 fast.ai 做贡献,或者在一些不同的后端中创建自己版本的一些东西感兴趣的人,看看第二个 API 是很酷的,它涵盖了一些类似的东西的一些子集,以便了解他们是如何解决这些问题的,以及相似之处/不同之处是什么。
def show_img(im, ax=None, figsize=None):
if not ax:
fig,ax = plt.subplots(figsize=figsize)
ax.imshow(im)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
return ax
def get_one(data):
model.set_input(data)
model.test()
return list(model.get_current_visuals().values())
model.save(201)
test_ims = []
for i,o in enumerate(dataset):
if i>10:
break
test_ims.append(get_one(o))
def show_grid(ims):
fig,axes = plt.subplots(2,3,figsize=(9,6))
for i,ax in enumerate(axes.flat):
show_img(ims[i], ax);
fig.tight_layout()
for i in range(8):
show_grid(test_ims[i])
我们训练了一段时间,然后我们可以随便拿几个例子,这里有它们[2:15:29]。这里有马、斑马,然后再变回马。








我花了大约 24 小时来训练它,所以它有点慢[2:16:39]。我知道 Helena 经常在 Twitter 上抱怨这些事情花费的时间有多长。我不知道她是如何在这些事情上如此高效的。
# !wget https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/horse2zebra.zip
我还要提到昨天刚出来的另一件事[2:16:54]:
多模态无监督图像到图像翻译
现在有一种多模态的无监督图像到图像的翻译。所以你现在基本上可以从这只狗创建不同的猫。
youtu.be/ab64TWzWn40
这不仅仅是创建你想要的输出的一个例子,而是创建多个例子。这是昨天或前天才出来的。我觉得这很惊人。所以你可以看到这项技术是如何发展的,我认为在音乐、语音、写作方面,或者为艺术家创造工具方面,可能有很多机会。
深度学习 2:第 2 部分第 13 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-13-43454b21a5d0译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
论坛 / 视频


图像增强 - 我们将涵盖您可能熟悉的这幅画。然而,您可能之前没有注意到这幅画中有一只鹰。您之前可能没有注意到的原因是这幅画以前没有鹰。同样地,第一张幻灯片上的画以前也没有美国队长的盾牌。

这是一篇很酷的新论文,几天前刚发表,名为Deep Painterly Harmonization,它几乎完全使用了我们将在本课程中学习的技术,只是进行了一些微小的调整。但您可以看到基本思想是将一张图片粘贴在另一张图片上,然后使用某种方法将两者结合起来。这种方法被称为“风格转移”。
在我们讨论之前,我想提一下 William Horton 的这个非常酷的贡献,他将这种随机权重平均技术添加到了 fastai 库中,现在已经全部合并并准备就绪。他写了一整篇关于这个的文章,我强烈建议您查看,不仅因为随机权重平均让您可以从现有的神经网络中获得更高的性能,而且基本上不需要额外的工作(只需向您的 fit 函数添加两个参数:use_swa,swa_start),而且他描述了他构建这个过程以及他如何测试它以及他如何为库做出贡献。所以如果您有兴趣做类似的事情,我认为这很有趣。我认为 William 以前没有建立过这种类型的库,所以他描述了他是如何做到的。

medium.com/@hortonhearsafoo/adding-a-cutting-edge-deep-learning-training-technique-to-the-fast-ai-library-2cd1dba90a49
TrainPhase [2:01]
笔记本
fastai 库的另一个非常酷的贡献是一个新的训练阶段 API。我将做一件我以前从未做过的事情,那就是我将展示别人的笔记本。之前我没有这样做的原因是因为我没有喜欢到足够好的笔记本,认为值得展示,但 Sylvain 在这里做得非常出色,不仅创建了这个新 API,还创建了一个描述它是什么以及如何工作等等的精美笔记本。背景是,正如大家所知,我们一直在努力更快地训练网络,部分原因是作为这个 Dawn bench 竞赛的一部分,还有一个下周您将了解的原因。我上周在论坛上提到,如果我们有一个更容易尝试不同的学习率调度等的方法,那对我们的实验将非常方便,我提出了我心目中的 API,如果有人能写出来那将非常酷,因为我现在要睡觉了,明天我有点需要它。Sylvain 在论坛上回复说,听起来是一个不错的挑战,24 小时后,它就完成了,而且效果非常酷。我想带您了解一下,因为它将使您能够研究以前没有人尝试过的东西。
这被称为 TrainPhase API,最简单的方法是展示它的示例。这是一个迭代学习率图表,你应该很熟悉。我们在学习率为 0.01 的情况下训练一段时间,然后在学习率为 0.001 的情况下训练一段时间。我实际上想创建一个非常类似于学习率图表的东西,因为大多数训练 ImageNet 的人都使用这种分阶段的方法,而这实际上并不是 fastai 内置的,因为我们通常不建议这样做。但为了复制现有的论文,我想以同样的方式做。因此,与其写一系列不同学习率的 fit、fit、fit 调用,不如能够说在这个学习率下训练 n 个周期,然后在那个学习率下训练 m 个周期。

这就是你如何做到的:
phases = [
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-2),
TrainingPhase(epochs=2, opt_fn=optim.SGD, lr = 1e-3)
]
一个阶段是一个具有特定优化器参数的训练期,phases由许多训练阶段对象组成。一个训练阶段对象说明要训练多少个周期,要使用什么优化函数,以及其他我们将看到的东西。在这里,你会看到你刚刚在那张图上看到的两个训练阶段。所以现在,不再调用learn.fit,而是说:
learn.fit_opt_sched(phases)
换句话说,learn.fit与一个具有这些阶段的优化器调度器。大多数传递的参数都可以像往常一样传递给 fit 函数,所以大多数通常的参数都可以正常工作。一般来说,我们只需使用这些训练阶段,你会看到它以一种通常的方式适应。然后当你说plot_lr时,你会看到上面的图表。它不仅绘制学习率,还绘制动量,并且对于每个阶段,它告诉你使用了什么优化器。你可以关闭优化器的打印(show_text=False),你可以关闭动量的打印(show_moms=False),你还可以做其他一些小事情,比如一个训练阶段可以有一个lr_decay参数:
phases = [
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-2),
TrainingPhase(
epochs=1,
opt_fn=optim.SGD,
lr = (1e-2,1e-3),
lr_decay=DecayType.LINEAR
),
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-3)
]
这里有一个固定的学习率,然后是线性衰减的学习率,然后是放弃这个图像的固定学习率:
lr_i = start_lr + (end_lr - start_lr) * i/n

这可能是一个很好的训练方式,因为我们知道在高学习率下,你可以更好地探索,在低学习率下,你可以更好地微调。逐渐在两者之间滑动可能更好。所以我认为这实际上不是一个坏方法。
你可以使用其他衰减类型,比如余弦:
phases = [
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-2),
TrainingPhase(
epochs=1,
opt_fn=optim.SGD,
lr =(1e-2,1e-3),
lr_decay=DecayType.COSINE
),
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-3)
]
这可能更有意义,作为一个真正有用的学习率退火形状。
lr_i = end_lr + (start_lr - end_lr)/2 * (1 + np.cos(i * np.pi)/n)

指数,这是一个非常流行的方法:
lr_i = start_lr * (end_lr/start_lr)**(i/n)

多项式并不是非常流行,但实际上在文献中比其他任何方法都要好,但似乎已经被大多数人忽视了。所以多项式是值得注意的。Sylvain 已经为每个曲线给出了公式。因此,使用多项式,你可以选择使用哪个多项式。我相信 p 为 0.9 的多项式是我看到的效果非常好的一个 - FYI。
lr_i = end_lr + (start_lr - end_lr) * (1 - i/n) ** p

如果在 LR 衰减时不提供学习率的元组,那么它将一直衰减到零。如你所见,你可以愉快地从不同的点开始下一个周期。
phases = [
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-2),
TrainingPhase(
epochs=1,
opt_fn=optim.SGD,
lr = 1e-2,
lr_decay=DecayType.COSINE
),
TrainingPhase(epochs=1, opt_fn=optim.SGD, lr = 1e-3)
]

SGDR
所以酷的是,现在我们可以仅仅使用这些训练阶段来复制所有我们现有的计划。这里有一个名为phases_sgdr的函数,它使用新的训练阶段 API 来进行 SGDR。
def phases_sgdr(lr, opt_fn, num_cycle,cycle_len,cycle_mult):
phases = [TrainingPhase(epochs = cycle_len/ 20, opt_fn=opt_fn,
lr=lr/100),
TrainingPhase(epochs = cycle_len * 19/20,
opt_fn=opt_fn, lr=lr, lr_decay=DecayType.COSINE)]
for i in range(1,num_cycle):
phases.append(TrainingPhase(epochs=cycle_len*
(cycle_mult**i), opt_fn=opt_fn, lr=lr,
lr_decay=DecayType.COSINE))
return phases

所以你可以看到,如果他按照这个计划运行,这就是它的样子:
他甚至做了我训练时使用非常低的学习率一小段时间然后突然增加并进行几个周期的小技巧,而且这些周期的长度在增加[8:05]。而且这一切都在一个函数中完成。
1cycle
现在我们可以用一个小函数来实现新的 1cycle。
def phases_1cycle(cycle_len,lr,div,pct,max_mom,min_mom):
tri_cyc = (1-pct/100) * cycle_len
return [TrainingPhase(epochs=tri_cyc/2, opt_fn=optim.SGD,
lr=(lr/div,lr), lr_decay=DecayType.LINEAR,
momentum=(max_mom,min_mom),
momentum_decay=DecayType.LINEAR),
TrainingPhase(epochs=tri_cyc/2, opt_fn=optim.SGD,
lr=(lr,lr/div), lr_decay=DecayType.LINEAR,
momentum=(min_mom,max_mom),
momentum_decay=DecayType.LINEAR),
TrainingPhase(epochs=cycle_len-tri_cyc, opt_fn=optim.SGD,
lr=(lr/div,lr/(100*div)),
lr_decay=DecayType.LINEAR,
momentum=max_mom)]
所以如果我们符合这个,我们会得到这个三角形,然后是一个稍微平坦的部分,动量是一个很酷的东西 - 动量有一个动量衰减。在第三个训练阶段,我们有一个固定的动量。所以它同时处理动量和学习率。

区分学习率+ 1cycle
我还没有尝试过的一件事,但我认为会非常有趣的是使用区分学习率和 1cycle 的组合。还没有人尝试过。这将非常有趣。我遇到的唯一一篇使用区分学习率的论文使用了一种称为 LARS 的东西。它被用来通过查看每层的梯度和均值之间的比率并使用该比率自动更改每层的学习率来训练 ImageNet,从而使用非常大的批量大小。他们发现他们可以使用更大的批量大小。这是我看到这种方法使用的唯一其他地方,但是您可以尝试结合区分学习率和不同有趣的调度尝试很多有趣的事情。
您自己的 LR 查找器
现在您可以编写不同类型的 LR finder,特别是因为现在有这个stop_div参数,基本上意味着当损失变得太糟糕时,它将停止训练。
添加的一个有用功能是plot函数中的linear参数。如果您在学习率查找器中使用线性调度而不是指数调度,这是一个好主意,如果您调整到大致正确的区域,那么您可以使用线性来找到确切的区域。然后您可能希望使用线性比例来绘制它。因此,您现在也可以将 linear 传递给 plot。
您可以在每个阶段更改优化器。这比您想象的更重要,因为实际上针对 ImageNet 在非常大的批量大小上快速训练的当前最先进技术实际上是从 RMSProp 开始的,然后他们在第二部分切换到 SGD。因此,这可能是一个有趣的实验,因为至少有一篇论文现在已经表明这样可以很好地工作。再次强调,这是一个尚未被充分认识的问题。
更改数据
然后我发现最有趣的部分是您可以更改您的数据。为什么我们要更改我们的数据?因为您还记得第 1 和第 2 课,您可以在开始时使用小图像,然后稍后使用更大的图像。理论上,您可以使用这种方法更快地训练第一部分,然后记住,如果您将高度减半并将宽度减半,则每层的激活数量就会减少四分之一,因此速度可能会更快。它甚至可能泛化得更好。因此,您现在可以创建几种不同大小,例如,他有 28 和 32 大小的图像。这是 CIFAR10,所以您可以做的事情有限。然后,如果您在调用fit_opt_sched时在data_list参数中传入数据数组,它将在每个阶段使用不同的数据集。
data1 = get_data(28,batch_size)
data2 = get_data(32,batch_size)learn = ConvLearner.from_model_data(ShallowConvNet(), data1)phases = [TrainingPhase(epochs=1, opt_fn=optim.Adam, lr=1e-2,
lr_decay=DecayType.COSINE),
TrainingPhase(epochs=2, opt_fn=optim.Adam, lr=1e-2,
lr_decay=DecayType.COSINE)]learn.fit_opt_sched(phases, data_list=[data1,data2])
这真的很酷,因为我们现在可以像在 DAWN bench 条目中那样使用它,并查看当我们实际上用很少的代码增加大小时会发生什么。那么当我们这样做时会发生什么?答案在 DAWN bench 上对 ImageNet 的训练中。

你可以看到,谷歌用半小时在一组 TPU 上赢得了比赛。最好的非 TPU 集群结果是 fast.ai + 学生在不到 3 小时内击败了拥有 128 台计算机的英特尔,而我们只用了一台计算机。我们还击败了在 TPU 上运行的谷歌,所以使用这种方法,我们已经证明了:
-
最快的 GPU 结果
-
最快的单机结果
-
最快的公开可用基础设施结果
这些 TPU 机架,除非你是谷歌,否则无法使用。而且成本很低(72.54 美元),这个英特尔的成本是 1200 美元的计算成本——他们甚至没有写在这里,但如果你同时使用 128 台计算机,每台有 36 个核心,每台有 140G,那就是你得到的结果,与我们的单个 AWS 实例相比。所以这在我们可以做的事情方面是一种突破。我们可以在一个公开可用的机器上训练 ImageNet,这个成本是 72 美元,顺便说一句,实际上是 25 美元,因为我们使用了一个 spot 实例。我们的学生 Andrew Shaw 建立了整个系统,让我们可以同时运行一堆 spot 实例实验,并且几乎自动化,但 DAWN bench 没有引用我们使用的实际数字。所以实际上是 25 美元,而不是 72 美元。所以这个 data_list 的想法非常重要和有帮助。
CIFAR10 结果
我们的 CIFAR10 结果现在也正式发布了,你可能还记得之前最好的结果是一个多小时。这里的诀窍是使用 1cycle,所以 Sylvain 的训练阶段 API 中的所有东西实际上都是我们用来获得这些顶级结果的东西。另一位 fast.ai 学生 bkj 采用了这个方法,并做了自己的版本,他采用了一个 Resnet18,并在顶部添加了我们学到的 concat pooling,并使用了 Leslie Smith 的 1cycle,所以他上了排行榜。所以前三名都是 fast.ai 的学生,这太棒了。

CIFAR10 成本结果
成本也是一样的——前三名,你可以看到,Paperspace。Brett 在 Paperspace 上运行,得到了最便宜的结果,略胜于 bkj。

所以我认为你可以看到,目前训练更快、更便宜的有趣机会很多都是关于学习率退火、尺寸退火,以及在不同时间使用不同参数进行训练,我仍然认为大家只是触及了表面。我认为我们可以做得更快、更便宜。这对于资源受限的环境中的人们非常有帮助,基本上除了谷歌,也许还有 Facebook。
架构也很有趣,上周我们看了一下简化版本的 darknet 架构。但有一个架构我们还没有谈到,那就是理解 Inception 网络所必需的。Inception 网络实际上非常有趣,因为他们使用了一些技巧使得事情更加高效。我们目前没有使用这些技巧,我觉得也许我们应该尝试一下。最有趣、最成功的 Inception 网络是他们的 Inception-ResNet-v2 网络,其中大部分块看起来像这样:

它看起来很像标准的 ResNet 块,因为有一个恒等连接,还有一个卷积路径,我们把它们加在一起。但实际上并不完全是这样。首先,中间的卷积路径是一个 1x1 卷积,值得思考一下 1x1 卷积实际上是什么。
1x1 卷积
1x1 卷积简单地说,对于输入中的每个网格单元,您基本上有一个向量。1 乘 1 乘滤波器数量的张量基本上是一个向量。对于输入中的每个网格单元,您只需与该张量进行点积。然后,当然,对于我们正在创建的 192 个激活之一,它将是这些向量之一。因此,基本上对网格单元(1,1)进行 192 个点积,然后对网格单元(1,2)或(1,3)等进行 192 个点积。因此,您将得到与输入具有相同网格大小和输出中的 192 个通道的内容。因此,这是一种非常好的方法,可以减少或增加输入的维度,而不改变网格大小。这通常是我们使用 1x1 卷积的方式。在这里,我们有一个 1x1 卷积和另一个 1x1 卷积,然后将它们相加。然后有第三个路径,这第三个路径没有被添加。虽然没有明确提到,但这第三个路径是被连接的。有一种形式的 ResNet 基本上与 ResNet 相同,但我们不使用加号,而是使用连接。这被称为 DenseNet。这只是一个使用连接而不是加法的 ResNet。这是一个有趣的方法,因为这样,身份路径实际上被复制。因此,您可以一直保持这种流动,因此正如我们将在下周看到的那样,这对于分割等需要保留原始像素、第一层像素和第二层像素不变的情况非常有用。
连接而不是添加分支是一件非常有用的事情,我们正在连接中间分支和右侧分支。最右侧的分支正在做一些有趣的事情,首先是 1x1 卷积,然后是 1x7,然后是 7x1。那里发生了什么?所以,那里发生的事情基本上是我们真正想要做的是 7x7 卷积。我们想要做 7x7 卷积的原因是,如果有多个路径(每个路径具有不同的内核大小),那么它可以查看图像的不同部分。最初的 Inception 网络将 1x1、3x3、5x5、7x7 连接在一起或类似的东西。因此,如果我们可以有一个 7x7 滤波器,那么我们可以一次查看图像的很多部分并创建一个非常丰富的表示。因此,Inception 网络的干部,即 Inception 网络的前几层实际上也使用了这种 7x7 卷积,因为您从这个 224x224x3 开始,希望将其转换为 112x112x64。通过使用 7x7 卷积,您可以在每个输出中获得大量信息以获得这些 64 个滤波器。但问题是 7x7 卷积是很费力的。您需要将 49 个内核值乘以每个通道的每个输入像素的 49 个输入。因此,计算量很大。您可能可以在第一层中使用它(也许可以),实际上,ResNet 的第一个卷积就是 7x7 卷积。
但对于《盗梦空间》来说并非如此。它们不使用 7x7 卷积,而是使用 1x7 接着 7x1。因此,基本思想是 Inception 网络或其所有不同版本的基本思想是有许多不同的卷积宽度的独立路径。在这种情况下,概念上的想法是中间路径是 1x1 卷积宽度,右侧路径将是 7 卷积宽度,因此它们正在查看不同数量的数据,然后将它们组合在一起。但我们不希望在整个网络中都使用 7x7 卷积,因为这太耗费计算资源了。
但是如果你考虑一下[23:18],如果我们有一些输入进来,我们有一些我们想要的大滤波器,但它太大了无法处理。我们能做什么?让我们做 5x5。我们可以创建两个滤波器 —— 一个是 1x5,一个是 5x1。我们将前一层的激活传递给 1x5。我们从中取出激活,然后通过 5x1 传递,最后得到一些结果。现在另一端出来了什么?与其将其视为首先我们取激活,然后通过 1x5,然后通过 5x1,不如一起考虑这两个操作,看看一个 5x1 点积和一个 1x5 点积一起做会发生什么?实际上,你可以取一个 1x5 和 5x1,它们的外积将给你一个 5x5。现在你不能通过取这个积来创建任何可能的 5x5 矩阵,但是你可以创建很多 5x5 矩阵。所以这里的基本思想是当你考虑操作的顺序时(如果你对这里的理论更感兴趣,你应该查看 Rachel 的数值线性代数课程,这基本上是关于这个的整个课程)。但从概念上来说,很多时候你想要做的计算实际上比整个 5x5 卷积更简单。在线性代数中我们经常使用的术语是有一些低秩近似。换句话说,1x5 和 5x1 结合在一起 —— 那个 5x5 矩阵几乎和你理想情况下应该计算的 5x5 矩阵一样好。所以在实践中这往往是情况 —— 因为现实世界的本质是现实世界往往比随机性更具结构性。
酷的地方是[26:16],如果我们用 1x7 和 7x1 替换我们的 7x7 卷积,对于每个单元格,它有 14 个输入通道乘以输出通道的点积要做,而 7x7 卷积则有 49 个要做。所以速度会快得多,我们希望它的效果几乎一样好。从定义上来说,它肯定捕捉到了尽可能多的信息宽度。

如果你对这方面的知识感兴趣,特别是在深度学习领域,你可以搜索分解卷积。这个想法是 3 年或 4 年前提出的。它可能已经存在更长时间了,但那是我第一次看到它的时候。结果表明它的效果非常好,Inception 网络广泛使用它。他们实际上在他们的干部中使用它。我们之前谈过,我们倾向于添加-on —— 我们倾向于说这是主干,例如我们有 ResNet34。这是主干,其中包含所有的卷积,然后我们可以添加一个自定义头部,通常是最大池化或全连接层。更好的做法是谈论主干包含两个部分:一个是干部,另一个是主干。原因是进来的东西只有 3 个通道,所以我们希望有一系列操作将其扩展为更丰富的东西 —— 通常是 64 个通道之类的东西。

在 ResNet 中,干部非常简单。它是一个 7x7 步幅 2 卷积,后面跟着一个步幅 2 最大池(如果我记得正确的话)。Inception 有一个更复杂的干部,其中包括多个路径的组合和连接,包括因子化卷积(1x7 和 7x1)。我很感兴趣的是,如果你在 Inception 干部上堆叠一个标准的 ResNet 会发生什么。我认为这将是一个非常有趣的尝试,因为 Inception 干部是一个非常精心设计的东西,以及如何将 3 通道输入转换为更丰富的东西似乎非常重要。而所有这些工作似乎都被抛弃了。我们喜欢 ResNet,它的效果非常好。但是如果我们在 Inception 干部上放置一个密集的网络骨干呢?或者如果我们用标准 ResNet 中的 1x7 和 7x1 因子化卷积替换 7x7 卷积呢?有很多事情我们可以尝试,我认为这将是非常有趣的。所以这是关于潜在研究方向的一些想法。
这就是我小小一堆随机东西部分的内容[29:51]。稍微接近这个实际主题的是图像增强。我将简要谈一下一篇新论文,因为它与我刚刚讨论的内容和我们接下来要讨论的内容有很大联系。这是一篇关于渐进式 GAN 的论文,来自 Nvidia:渐进增长的 GANs 用于提高质量、稳定性和变化。渐进式 GANs 采用了逐渐增加图像大小的想法。这是我所知道的唯一另一个人们实际上逐渐增加图像大小的方向。令我惊讶的是,这篇论文实际上非常受欢迎,知名度很高,而且受欢迎,但是人们还没有将逐渐增加图像大小的基本思想应用到其他地方,这显示了你可以在深度学习研究社区中期望找到的创造力水平。

他们真的回到了 4x4 GAN 开始[31:47]。实际上,他们试图复制 4x4 像素,然后是 8x8(上面左上角的那些)。这是 CelebA 数据集,所以我们试图重新创建名人的图片。然后他们去 16x16,32,64,128,然后 256。他们做的一个非常聪明的事情是,随着尺寸的增加,他们还向网络添加更多层。这有点说得通,因为如果你在做更多的 ResNet 类型的事情,那么你应该能够在每个网格单元大小输出一些有意义的东西,所以你应该能够在其上叠加东西。当他们这样做时,他们做了另一个聪明的事情,他们添加了一个跳过连接,并逐渐改变线性插值参数,使其越来越远离旧的 4x4 网络,朝向新的 8x8 网络。一旦完全移动到新网络,他们就会丢弃那个额外的连接。细节并不太重要,但它使用了我们谈论过的基本思想,逐渐增加图像大小和跳过连接。这是一篇很棒的论文,因为这是一种罕见的情况,好的工程师实际上构建了一些以非常明智的方式工作的东西。现在这并不奇怪,这实际上来自 Nvidia 自己。Nvidia 并不发表很多论文,有趣的是,当他们这样做时,他们构建了一些非常实用和明智的东西。所以我认为这是一篇很棒的论文,如果你想整合我们学到的许多不同的东西,而且没有太多的重新实现,所以这是一个有趣的项目,也许你可以继续研究并找到其他东西。
接下来会发生什么[33:45]。我们最终会升级到 1024x1024,你会看到图像不仅分辨率更高,而且质量更好。所以我要看看你能否猜出以下哪一个是假的:

它们全都是假的。这是下一个阶段。你一直往上走,然后突然爆炸。所以 GANs 和其他东西变得疯狂,你们中的一些人可能在这周看到了这个[34:16]。这个视频刚刚发布,是巴拉克·奥巴马的演讲,让我们来看一下:
youtu.be/cQ54GDm1eL0
正如你所看到的,他们使用这种技术来实际移动奥巴马的脸,就像乔丹·皮尔的脸在移动一样。你现在基本上拥有了所有需要的技术。这是一个好主意吗?
人工智能伦理[35:31]
这是我们谈论最重要的部分,现在我们可以做所有这些事情,我们应该做什么,我们如何考虑?简而言之,我其实不知道。最近,你们中的许多人看到了 spaCy prodigy 公司的创始人在 Explosion AI 做了一个演讲,Matthew 和 Ines,之后我和他们一起吃饭,我们基本上整个晚上都在讨论,辩论,争论我们这样的公司正在构建可以以有害方式使用的工具,这意味着什么。他们是非常深思熟虑的人,我们,我不会说我们没有达成一致意见,我们只是无法得出结论。所以我只是列出一些问题,并指出一些研究,当我说研究时,实际上大部分文献综述和整理工作都是由 Rachel 完成的,所以谢谢 Rachel。
让我先说一下,我们构建的模型通常在某些方面相当糟糕,这些问题并不立即显现[36:52]。除非与你一起构建它们的人是各种各样的人,与你一起使用它们的人也是各种各样的人,否则你不会知道它们有多糟糕。例如,一对出色的研究人员,Timnit Gebru在微软工作,Joy Buolamwini刚从麻省理工学院获得博士学位,他们进行了一项非常有趣的研究,他们查看了一些现成的人脸识别器,其中包括来自 FACE++的一个,这是一家庞大的中国公司,IBM 的,以及微软的,他们寻找了一系列不同类型的人脸。

一般来说,微软的一个特别准确,除非人脸类型恰好是深色皮肤,突然间糟糕了 25 倍。IBM 几乎一半的时间都搞错了。对于这样一个大公司来说,发布一个对世界上大部分人来说都不起作用的产品,不仅仅是技术上的失败。这是对理解需要使用什么样的团队来创建这样的技术以及测试这样的技术,甚至对你的客户是谁的一种深刻失败。你的一些客户有深色皮肤。“我还要补充说,分类器在女性身上的表现都比在男性身上差”(Rachel)。令人震惊。有趣的是,Rachel 前几天在推特上发表了类似的言论,有人说“这是怎么回事?你在说什么?难道你不知道人们很长时间以来一直在制造汽车吗——你是在说你需要女性来制造汽车吗?”Rachel 指出——实际上是的。在汽车安全的大部分历史中,女性在汽车中的死亡风险远远高于男性,因为男性创造了看起来像男性、感觉像男性、尺寸像男性的碰撞测试假人,所以汽车安全实际上没有在女性身材上进行测试。产品管理糟糕,缺乏多样性和理解的失败在我们领域并不新鲜。
“我只是想说,这是在比较男性和女性的影响力”(Rachel)。我不知道为什么每当你在 Twitter 上说这样的话时,Rachel 都要这样说,因为每当你在 Twitter 上说这样的话时,大约有 10 个人会说“哦,你必须比较所有这些其他事情”,好像我们不知道一样。

像微软的人脸识别器或谷歌的语言翻译器这样的我们最好最著名的系统做的其他事情,你把“她是医生。他是护士。”翻译成土耳其语,非常正确——两个代词都变成了 O,因为土耳其语中没有性别代词。反过来,它会变成什么?“他是医生。她是护士。”所以我们在每天使用的工具中内置了这种偏见。而且,人们会说“哦,它只是展示了世界上的东西”,好吧,这个基本断言有很多问题,但正如你所知,机器学习算法喜欢概括。

因为他们喜欢概括,这是你们现在了解技术细节的一个很酷的事情,因为当你看到像 60%的照片中烹饪的人是女性,而他们用来构建这个模型的照片,然后你在另一组照片上运行模型时,84%被选择为烹饪的人是女性,而不是正确的 67%。这对于算法来说是一个非常可以理解的事情,因为它接受了有偏见的输入,并创造了一个更有偏见的输出,因为对于这个特定的损失函数来说,这就是它的结果。这是一种非常常见的模型放大。
这些事情很重要。它的重要性不仅仅体现在尴尬的翻译或黑人照片未被正确分类的方式上。也许也有一些胜利,比如到处可怕的监视,也许对黑人不起作用。“或者会更糟,因为这是可怕的监视,而且是彻头彻尾的种族主义和错误”(Rachel)。但让我们深入一点。尽管我们谈论人类的缺陷,但文明和社会有着长期的历史,创造了层层人类判断,希望避免最可怕的事情发生。有时候,热爱技术的公司会认为“让我们抛弃人类,用技术取代他们”,就像 Facebook 所做的那样。几年前,Facebook 真的摆脱了他们的人类编辑,当时这成为了新闻。他们被算法取代了。现在,当算法将所有内容放在你的新闻源上,而人类编辑却被排除在外时,接下来会发生什么?

接下来发生了很多事情。其中之一是缅甸发生了大规模的可怕种族灭绝。婴儿被从母亲怀里夺走,扔进火里。大规模的强奸、谋杀,整个民族被流放出境。

好吧,我不会说那是因为 Facebook 这样做的,但我要说的是,当这个可怕项目的领导接受采访时,他们经常谈论他们从 Facebook 学到的关于罗辛亚人恶劣动物行为的一切,这些行为需要被扫除。因为算法只是想要给你更多让你点击的东西。如果你被告知这些人不像你,你不认识这些坏人,这里有很多关于坏人的故事,然后你开始点击它们,然后他们会给你更多这些东西。接下来你会发现,你陷入了这个不寻常的循环。人们一直在研究这个问题,比如,我们被告知有几次人们点击我们的 fast.ai 视频,然后推荐给他们的下一个东西是来自 Alex Jones 的阴谋论视频,然后继续下去。因为人类点击那些让我们震惊、惊讶和恐惧的东西。在很多层面上,这个决定产生了不同寻常的后果,我们只是开始理解。再次强调,这并不是说这个特定的后果是因为这一个原因,但说它与此毫无关联显然是在忽视我们所拥有的所有证据和信息。
有意外的后果

关键是要考虑你正在构建什么,以及它可能如何被使用。现在有很多努力投入到人脸识别中,包括我们的课程。我们一直在花费大量时间思考如何识别东西以及它在哪里。有很多很好的理由希望在这方面做得更好,比如改善农业产量、改善医学诊断和治疗规划、改善你的乐高分类机器人系统等等。但它也被广泛用于监视、宣传和虚假信息。再次,问题是我该怎么办?我不完全知道。但至少重要的是要考虑这个问题,谈论这个问题。
失控的反馈循环

有时候你可以做一些非常好的事情。例如,meetup.com 做了一件我认为是非常好的事情的事情,他们早就意识到一个潜在的问题,即更多的男性倾向于参加他们的聚会。这导致他们的协同过滤系统,你现在熟悉正在构建的系统,向男性推荐更多技术内容。这导致更多的男性参加更多的技术内容,从而导致推荐系统向男性推荐更多技术内容。当我们将算法和人类结合在一起时,这种失控的反馈循环是非常常见的。那么 Meetup 做了什么?他们故意做出了向女性推荐更多技术内容的决定,不是因为对世界应该如何的高尚想法,而只是因为这是有道理的。失控的反馈循环是一个 bug——有女性想要参加技术聚会,但当你去参加一个技术聚会,里面全是男性,你就不去了,然后它就会向男性推荐更多,依此类推。因此,Meetup 在这里做出了一个非常强有力的产品管理决策,即不按照算法建议的做。不幸的是,这种情况很少见。大多数这种失控的反馈循环,例如在预测性警务中,算法告诉警察去哪里,很多时候是更多的黑人社区,这些社区最终会涌入更多的警察,导致更多的逮捕,这有助于告诉更多的警察去更多的黑人社区等等。
AI 中的偏见

算法偏见的问题现在非常普遍,随着算法在特定政策决策、司法决策以及日常决策中的广泛使用,这个问题变得越来越严重。其中一些问题实际上是产品管理决策中的人员在最初就应该看到的,这些问题在任何定义下都是没有意义和不合理的。例如,阿贝·龚指出的这些问题——这些问题既用于预审,即谁需要支付保释金,这些人甚至还没有被定罪,也用于判决以及谁获得假释。尽管存在所有的缺陷,这在去年被威斯康星州最高法院维持了。所以你是否必须因为支付不起保释金而留在监狱,你的刑期有多长,你在监狱里待多久取决于你父亲做了什么,你的父母是否离婚,你的朋友是谁,以及你住在哪里。现在事实证明这些算法实际上非常糟糕,最近的一些分析显示它们基本上比随机还要糟糕。但即使公司在这些统计上的相关性上很有信心,有人能想象出一个世界,在那里根据你父亲的行为来决定发生什么吗?
在基本层面上,很多事情显然是不合理的,很多事情只是以这种你可以从经验上看到的方式失败了,这种失控的反馈循环一定发生过,这种过度概括一定发生过。例如,任何领域工作的人都应该准备这些交叉表,使用这些算法。因此,对黑人和白人被告重新犯罪的可能性的预测,我们可以很简单地计算出来。那些被标记为高风险但没有再犯的人中,23.5%是白人,而非洲裔美国人大约是白人的两倍。而那些被标记为低风险但再犯的人中,白人只有非洲裔美国人的一半,而非洲裔美国人只有 28%。这就是这种情况,至少如果你正在使用我们谈论过的技术,并以任何方式将其投入生产,为其他人构建 API,为人们提供培训,或者其他什么——那么至少确保你所做的事情可以被追踪,以便人们知道发生了什么,至少他们是知情的。我认为假设人们是邪恶的,试图破坏社会是错误的。我认为我更愿意从一个假设开始,即如果人们做了愚蠢的事情,那是因为他们不知道更好的方法。所以至少确保他们有这些信息。我发现很少有机器学习从业者考虑他们的界面中应该呈现什么信息。然后我经常会和数据科学家交谈,他们会说“哦,我正在研究的东西对社会没有影响。”真的吗?有很多人认为他们正在做的事情完全毫无意义吗?来吧。人们付钱让你做这件事是有原因的。它会以某种方式影响人们。所以考虑一下这是什么。
在招聘中的责任

我知道的另一件事是很多参与其中的人都在招聘人才,如果你在招聘人才,我想你现在都非常熟悉 fast.ai 的理念,这基本上是这样一个前提,我认为人们总体上并不邪恶,我认为他们需要被告知并拥有工具。因此,我们正在尽可能地为尽可能多的人提供他们需要的工具,特别是我们正在尝试将这些工具交到更广泛人群的手中。因此,如果你参与招聘决策,也许你可以记住这种理念。如果你不仅仅是招聘更广泛的人才,而且还提拔更广泛的人才,并为更广泛的人提供适当的职业管理,除了其他任何事情,你的公司会做得更好。事实证明,更多样化的团队更有创造力,往往比不那么多样化的团队更快更好地解决问题,而且你也可能避免这些糟糕的失误,这在某种程度上对世界是有害的,而在另一层面,如果你被发现,它们可能毁掉你的公司。
IBM 和“死亡计算器”

他们也可以摧毁你,或者至少让你在历史上看起来很糟糕。举几个例子,一个是回到第二次世界大战。IBM 提供了跟踪大屠杀所需的所有基础设施。这些是他们使用的表格,它们有不同的代码 - 犹太人是 8,吉普赛人是 12,毒气室中的死亡是 6,所有这些都记录在这些打孔卡上。现在你可以去博物馆看这些打孔卡,这实际上已经被一位瑞士法官审查过,他说 IBM 的技术支持促进了纳粹分子的任务并促使他们犯下反人类罪行。回顾这些时期的历史,看看当时 IBM 的人们在想什么是很有趣的。当时人们明显在想的是展示技术优势的机会,测试他们的新系统的机会,当然还有他们赚取的巨额利润。当你做了一些事情,即使在某个时候会变成问题,即使你被告知要这样做,这对你个人来说也可能成为问题。例如,大家都记得大众柴油排放丑闻。谁是唯一一个入狱的人?那就是只是在做他的工作的工程师。如果所有这些关于实际上不要搞砸世界的东西还不足以说服你,那么它也可能毁掉你的生活。如果你做了一些事情,结果导致问题,即使有人告诉你要这样做,你绝对可能被追究刑事责任。亚历山大·科根就是那个交出剑桥分析数据的人。他是一位剑桥学者。现在是一位全球著名的剑桥学者,因为他为摧毁民主的基础做出了自己的贡献。这不是我们想要留在历史上的方式。

问题: 在你的一条推特中,你说 dropout 被专利化了[56:50]。我认为这是关于 Google 的 WaveNet 专利。这是什么意思?你能分享更多关于这个主题的见解吗?这意味着我们将来要付费使用 dropout 吗?专利持有人之一是 Geoffrey Hinton。那又怎样?这不是很棒吗?发明就是关于专利的,啦啦啦。我的答案是否定的。专利已经变得疯狂。我们每周讨论的可以被专利化的东西数量会有几十个。很容易想出一个小调整,然后如果你把它变成专利来阻止每个人在接下来的 14 年内使用那个小调整,最终我们就会面临现在的情况,所有东西都以 50 种不同的方式被专利化。然后你会遇到这些专利流氓,他们通过购买大量垃圾专利然后起诉任何无意中做了那件事的人,比如给按钮加上圆角。那么对于我们来说,深度学习中有很多东西被专利化意味着什么?我不知道。
做这个工作的主要人员之一是 Google,而且来自 Google 的人回应这个专利时倾向于认为 Google 这样做是因为他们想要防御性地拥有它,所以如果有人起诉他们,他们可以说不要起诉我们,我们会反诉你,因为我们有所有这些专利。问题是据我所知,他们还没有签署所谓的防御性专利承诺,所以基本上你可以签署一个法律约束文件,说我们的专利组合只会用于防御而不是进攻。即使你相信 Google 的所有管理层永远不会变成专利流氓,你必须记住管理层会变化。给你一个具体的例子,我知道,Google 的最近的 CFO 对 PNL 有更积极的态度,我不知道,也许她会决定他们应该开始变现他们的专利,或者也许做出那个专利的团队可能会被分拆然后卖给另一家公司,最终可能会落入私募股权手中并决定变现专利或其他。所以我认为这是一个问题。最近在法律上有一个从软件专利转向实际上没有任何法律地位的大变化,所以这些可能最终都会被驳回,但现实是,任何不是大公司的人都不太可能有财务能力来抵抗这些庞大的专利流氓。
如果你写代码,就无法避免使用专利的东西。我不会感到惊讶,如果你写的大部分代码都有专利。实际上,有趣的是,最好的做法不是研究专利,因为如果你故意侵犯,惩罚会更严重。所以最好的做法是把手放在耳朵上,唱首歌,然后继续工作。所以关于 dropout 被专利化的事情,忘记我说过的。你不知道那个。你跳过那部分。
风格迁移[1:01:28]
笔记本

arxiv.org/abs/1508.06576
这非常有趣——艺术风格。我们在这里有点复古,因为这实际上是最初的艺术风格论文,后来有很多更新和很多不同的方法,我实际上认为在很多方面最初的方法是最好的。我们也会看一些更新的方法,但我实际上认为最初的方法是一个很棒的方式,即使在之后的一切发展之后。让我们来看看代码。
%matplotlib inline
%reload_ext autoreload
%autoreload 2from fastai.conv_learner import *
from pathlib import Path
from scipy import ndimage
torch.cuda.set_device(3)
torch.backends.cudnn.benchmark=TruePATH = Path('data/imagenet')
PATH_TRN = PATH/'train'm_vgg = to_gpu(vgg16(True)).eval()
set_trainable(m_vgg, False)
这里的想法是我们想要拍摄一只鸟的照片,并且我们想要创作一幅看起来像梵高画了这只鸟的画。顺便说一句,我正在做的很多事情都使用了 ImageNet。你不必为我所做的任何事情下载整个 ImageNet。在files.fast.ai/data中有一个 ImageNet 样本,它有几个 G 的数据,对我们正在做的一切来说应该足够了。如果你想要得到真正出色的结果,你可以获取 ImageNet。你可以从Kaggle下载。定位竞赛实际上包含了所有的分类数据。如果你有空间,最好拥有一份 ImageNet 的副本,因为它随时都会派上用场。
img_fn = PATH_TRN/'n01558993'/'n01558993_9684.JPEG'
img = open_image(img_fn)
plt.imshow(img);
所以我刚从我的 ImageNet 文件夹中拿出了这只鸟,这就是我的鸟:

sz=288trn_tfms,val_tfms = tfms_from_model(vgg16, sz)
img_tfm = val_tfms(img)
img_tfm.shape*(3, 288, 288)*opt_img = np.random.uniform(0, 1, size=img.shape).astype(np.float32)
plt.imshow(opt_img);
我要做的是从这张图片开始:

我将尝试让它越来越像梵高画的鸟的图片。我做的方法实际上非常简单。你们都很熟悉它。我们将创建一个损失函数,我们将称之为f。损失函数将以一张图片作为输入,并输出一个值。如果图像看起来更像梵高画的鸟照片,那么这个值将更低。编写了这个损失函数之后,我们将使用 PyTorch 的梯度和优化器。梯度乘以学习率,我们不会更新任何权重,而是会更新输入图像的像素,使其更像梵高画的鸟的图片。然后我们再次通过损失函数来获取更多的梯度,一遍又一遍地进行。就是这样。所以这与我们解决每个问题的方式是相同的。你们知道我是一个只会一招的人,对吧?这是我的唯一招数。创建一个损失函数,用它来获取一些梯度,乘以学习率来更新某些东西,以前我们总是更新模型中的权重,但今天我们不会这样做。我们将更新输入图像中的像素。但实际上并没有什么不同。我们只是针对输入而不是针对权重来获取梯度。就是这样。我们快要完成了。

让我们做更多的事情。让我们在这里提到,我们的损失函数将有两个额外的输入。一个是鸟的图片。第二个是梵高的一幅艺术作品。通过将它们作为输入,这意味着我们以后可以重新运行这个函数,使其看起来像梵高画的鸟,或者像莫奈画的鸟,或者像梵高画的大型喷气式飞机等。这些将是三个输入。最初,正如我们讨论过的,我们的输入是一些随机噪音。我们从一些随机噪音开始,使用损失函数,获取梯度,使其更像梵高画的鸟,依此类推。
所以我猜我们可以简要讨论的唯一未解决的问题是我们如何计算我们的图像看起来有多像梵高画的这只鸟。让我们将其分为两部分:
内容损失:返回一个值,如果看起来更像这只鸟(不只是任何鸟,而是我们要处理的特定鸟)。
风格损失:如果图像更像 V.G.的风格,则返回一个较低的数字。

有一种非常简单的计算内容损失的方法——我们可以查看输出的像素,将它们与鸟的像素进行比较,计算均方误差,然后相加。所以如果我们这样做,我运行了一段时间。最终我们的图像会变成一只鸟的图像。你应该尝试一下。你应该尝试这个作为练习。尝试使用 PyTorch 中的优化器,从一个随机图像开始,通过使用均方误差像素损失将其转变为另一幅图像。这并不是非常令人兴奋,但这将是第一步。
问题是,即使我们已经有了我们的风格损失函数运行得很好,然后假设我们要做的是将这两者相加,然后其中一个,我们将乘以一些λ来调整风格与内容的比例。假设我们有一个风格损失并选择了一些合理的λ,如果我们使用像素级的内容损失,那么任何使其看起来更像梵高而不是完全像照片、背景、对比度、光照等的东西都会增加内容损失——这不是我们想要的。我们希望它看起来像鸟,但不是以相同的方式。它仍然会有相同位置的两只眼睛,相同的形状等等,但不是相同的表示。所以我们要做的是,这可能会让您震惊,我们要使用一个神经网络!我们将使用 VGG 神经网络,因为那是我去年使用的,我没有时间看其他东西是否有效,所以您可以在这一周自己尝试。
VGG 网络是一个接受输入并将其通过多个层的网络,我将把这些层视为卷积层,显然还有 ReLU,如果是带有批量归一化的 VGG,那么它也有批量归一化。还有一些最大池化等等,但没关系。我们可以做的是,我们可以取其中一个卷积激活,而不是比较这只鸟的像素,我们可以比较这个(由 V.G.绘制的)鸟的 VGG 层 5 激活与我们原始鸟的 VGG 层 5 激活(或第 6 层,第 7 层等)。那么为什么这样更有趣呢?首先,它不会是同一只鸟。它不会完全相同,因为我们不是在检查像素。我们在检查一些后续的激活。那么这些后续的激活包含什么?假设它经过一些最大池化后,它包含一个较小的网格——所以它对事物的位置不那么具体。而不是包含像素颜色值,它们更像是语义的东西,比如这是一种眼球,这是一种毛茸茸的,这是一种明亮的,或者这是一种反射的,或者平放的,或者其他什么。因此,我们希望通过这些层有一定程度的语义特征,如果我们得到一个与这些激活匹配的图片,那么任何匹配这些激活的图片看起来像鸟,但不是相同的鸟的表示。这就是我们要做的。这就是我们的内容损失将是什么。人们通常称之为感知损失,因为在深度学习中,您总是为您做的每件明显的事情创造一个新名称。如果您将两个激活进行比较,您正在进行感知损失。就是这样。我们的内容损失将是感知损失。然后我们将稍后进行风格损失。
让我们从尝试创建一只最初是随机噪音的鸟开始,我们将使用感知损失来创建类似鸟的东西,但不是特定的鸟。我们将从 288x288 开始。因为我们只做一只鸟,所以不会出现 GPU 内存问题。我实际上很失望地意识到我选择了一个相当小的输入图像。尝试使用更大的图像创建一个真正宏伟的作品会很有趣。另一件事要记住的是,如果您要将其投入生产,可以一次处理整个批次。有时人们会抱怨这种方法(Gatys 是主要作者)——Gatys 的风格迁移方法很慢,但我不同意它很慢。只需要几秒钟,您就可以在几秒钟内处理整个批次。

sz=288
所以我们将按照通常的做法将其通过 VGG16 模型的一些转换。记住,转换类有 dunder call 方法(__call__),所以我们可以将其视为一个函数。如果你将一个图像传递给它,那么我们将得到转换后的图像。尽量不要将 fast.ai 和 PyTorch 基础设施视为黑盒,因为它们都设计成非常易于以解耦的方式使用。所以这个转换只是“可调用”的想法(即用括号括起来的东西)来自于 PyTorch,我们完全抄袭了这个想法。所以在 torch.vision 或 fast.ai 中,你的转换只是可调用的。整个转换流水线只是一个可调用的。
trn_tfms,val_tfms = tfms_from_model(vgg16, sz)
img_tfm = val_tfms(img)
img_tfm.shape
'''
(3, 288, 288)
'''
现在我们有了一个 3x288x288 的东西,因为 PyTorch 喜欢通道在前面。正如你所看到的,它已经被转化为一个方形,被归一化为(0,1),所有这些正常的东西。
现在我们正在创建一个随机图像。
opt_img = np.random.uniform(0, 1, size=img.shape).astype(np.float32)
plt.imshow(opt_img);

这是我发现的一件事。试图将这个转化为任何东西的图片实际上非常困难。我发现实际上很难让优化器获得合理的梯度,使其有所作为。就在我以为我要在这门课上耗尽时间并真正让自己尴尬的时候,我意识到关键问题是图片不是这样的。它们更加平滑,所以我稍微模糊了一下,将其转化为以下内容:
opt_img = scipy.ndimage.filters.median_filter(opt_img, [8,8,1])
plt.imshow(opt_img);

我使用了一个中值滤波器——基本上就像一个中值池化。一旦我将其改为这样,它立即开始训练得非常好。你必须做一些微小的调整才能让这些东西工作起来,这有点疯狂,但这里有一个小调整。
所以我们从一个随机图像开始,这个图像至少有一定的平滑度。我发现我的鸟类图像的像素均值大约是这个值的一半,所以我将其除以 2,只是试图让匹配变得更容易一些(我不知道这是否重要)。将其转化为一个变量,因为这个图像,记住,我们将使用优化算法修改这些像素,所以任何涉及损失函数的东西都需要是一个变量。并且,它需要梯度,因为我们实际上是在更新图像。
opt_img = val_tfms(opt_img)/2
opt_img_v = V(opt_img[None], requires_grad=True)
opt_img_v.shape*torch.Size([1, 3, 288, 288])*
所以现在我们有了一个大小为 1 的小批量,3 个通道,288x288 的随机噪声。
m_vgg = nn.Sequential(*children(m_vgg)[:37])
我们将使用,没有特定原因,VGG 的第 37 层。如果你打印出 VGG 网络(你只需输入m_vgg并打印出来),你会看到这是中后期的层。所以我们可以只获取前 37 层并将其转化为一个顺序模型。现在我们有了一个 VGG 的子集,它将输出一些中间层的激活,这就是模型将要做的事情。所以我们可以拿到我们实际的鸟类图像,我们想创建一个大小为一的小批量。记住,如果你在 Numpy 中使用None进行切片,也就是np.newaxis,它会在那个点引入一个新的单位轴。这里,我想创建一个大小为 1 的轴,表示这是一个大小为一的小批量。所以就像我在这里做的一样(opt_img_v = V(opt_img[**None**], requires_grad=**True**))使用None进行切片,在前面得到一个单位轴。然后我们将其转化为一个变量,这个变量不需要更新,所以我们使用VV来表示你不需要为这个变量计算梯度。这将给我们我们的目标激活。
-
我们已经拿到了我们的鸟类图像。
-
将其转化为一个变量
-
将其通过我们的模型传递,以获取第 37 层的激活,这是我们的目标。我们希望我们的内容损失是这组激活。
-
我们将创建一个优化器(我们稍后会回到这个细节)
-
我们将进行多次迭代
-
梯度清零
-
调用一些损失函数
-
损失反向传播()
这就是高层次的版本。我一会儿会回到细节,但关键是我们传入那个随机生成的图像的损失函数——优化图像的变量。因此,我们将该图像传递给我们的损失函数,它将使用损失函数进行更新,而损失函数是通过将我们当前的优化图像通过我们的 VGG 获取中间激活,并将其与目标激活进行比较来计算均方误差损失。我们运行一堆次数,然后将其打印出来。我们有我们的鸟,但没有它的表示形式。
targ_t = m_vgg(VV(img_tfm[None]))
targ_v = V(targ_t)
targ_t.shape
'''
torch.Size([1, 512, 18, 18])
'''
max_iter = 1000
show_iter = 100
optimizer = optim.LBFGS([opt_img_v], lr=0.5)
Broyden–Fletcher–Goldfarb–Shanno(BFGS)
这里有一些新的细节。其中一个是一个奇怪的优化器(optim.LBFGS)。任何完成过某些数学和计算机科学课程的人进入深度学习领域都会发现我们使用像 Adam 和 SGD 这样的东西,并且总是假设该领域的人对计算机科学一无所知,立即说“你们有人尝试过使用 BFGS 吗?”实际上,我们并没有使用来训练神经网络的完全不同类型的优化算法的长期历史。当然,事实上,那些花了几十年研究神经网络的人确实对计算机科学有所了解,结果表明这些技术整体上并不工作得很好。但实际上,这对我们来说会很有效,并且这是一个很好的机会,让那些在学校没有学习过这种类型的优化算法的人了解一个有趣的算法。BFGS(四个不同人的首字母缩写),L 代表有限内存。它是一个优化器,也就是说,有一些损失函数,它将使用一些梯度(并非所有优化器都使用梯度,但我们使用的所有优化器都会)来找到一个方向,并尝试通过调整一些参数使损失函数降低。它只是一个优化器。但它是一种有趣的优化器,因为它在每一步上做的工作比我们习惯的要多一点。具体来说,它的工作方式与我们习惯的方式相同,即我们只是选择一个起点,而在这种情况下,我们选择了一个随机图像,正如你所看到的。像往常一样,我们计算梯度。但我们不仅仅是采取一步,而是实际上在找到梯度的同时,我们还尝试找到二阶导数。二阶导数表示梯度变化的速度。
梯度:函数变化的速度
二阶导数:梯度变化的速度
换句话说,它有多曲折?基本思想是,如果你知道它不太曲折,那么你可能可以跳得更远。但如果它非常曲折,那么你可能不想跳得太远。因此,在更高维度中,梯度被称为雅可比矩阵,而二阶导数被称为海森矩阵。你会经常看到这些词,但它们的意思就是这样。再次强调,数学家们也必须为每件事发明新词。他们就像深度学习研究人员一样——也许有点傲慢。使用 BFGS,我们将尝试计算二阶导数,然后我们将使用它来确定前进的方向和距离——因此,这不是对未知领域的一次疯狂跳跃。
现在的问题是,实际计算 Hessian(二阶导数)几乎肯定不是一个好主意。因为在你要前进的每个可能方向上,对于你测量梯度的每个方向,你还必须在每个方向上计算 Hessian。这变得非常庞大。所以我们不是真的计算它,我们走几步,基本上看一下梯度在每一步变化了多少,然后用那个小函数来近似 Hessian。再次强调,这似乎是一个非常明显的事情,但直到后来有人想到了,这花了相当长的时间。跟踪每一步都需要大量内存,所以别跟踪每一步,只保留最后的十步或二十步。第二部分,就是 L 到 LBFGS。有限内存的 BFGS 意味着保留最后的 10 或 20 个梯度,用它来近似曲率的量,然后用曲率和梯度来估计前进的方向和距离。在深度学习中通常不是一个好主意,有很多原因。这比 Adam 或 SGD 更新更费力,也使用更多内存,当你有一个 GPU 来存储和数亿个权重时,内存就成了一个更大的问题。但更重要的是,小批量是非常颠簸的,所以弄清楚曲率以决定到底要前进多远,有点像我们说的磨亮了粪便(是的,澳大利亚和英国的表达方式,你懂的)。有趣的是,实际上使用二阶导数信息,结果就像是一个吸引鞍点的磁铁。因此,有一些有趣的理论结果基本上说,如果使用二阶导数信息,它实际上会把你引向函数的恶劣平坦区域。所以通常不是一个好主意。
def actn_loss(x):
return F.mse_loss(m_vgg(x), targ_v)*1000
def step(loss_fn):
global n_iter
optimizer.zero_grad()
loss = loss_fn(opt_img_v)
loss.backward()
n_iter+=1
if n_iter%show_iter==0:
print(f'Iteration: n_iter, loss: **{loss.data[0]}**')
return loss
但在这种情况下,我们不是在优化权重,而是在优化像素,所以所有规则都改变了,实际上 BFGS 是有意义的。因为每次它做更多的工作,它是一种不同类型的优化器,PyTorch 中的 API 也有点不同。正如你在这里看到的,当你说optimizer.step时,你实际上传入了损失函数。所以我们的损失函数是调用step,传入一个特定的损失函数,即我们的激活损失(actn_loss)。在循环内部,你不会说 step,step,step。而是看起来像这样。所以有点不同,你可以尝试重写这个来使用 SGD,它仍然会工作。只是会花更长的时间,我还没有尝试过用 SGD,我很想知道它需要多长时间。
n_iter=0
while n_iter <= max_iter:
optimizer.step(partial(step,actn_loss))
'''
Iteration: n_iter, loss: 0.8466196656227112
Iteration: n_iter, loss: 0.34066855907440186
Iteration: n_iter, loss: 0.21001280844211578
Iteration: n_iter, loss: 0.15562333166599274
Iteration: n_iter, loss: 0.12673595547676086
Iteration: n_iter, loss: 0.10863320529460907
Iteration: n_iter, loss: 0.0966048613190651
Iteration: n_iter, loss: 0.08812198787927628
Iteration: n_iter, loss: 0.08170554041862488
Iteration: n_iter, loss: 0.07657770067453384
'''
所以你可以看到损失函数在下降。我们的 VGG 模型第 37 层的激活与目标激活之间的均方误差,记住目标激活是应用于我们的鸟的 VGG。明白了吗?所以现在我们有了一个内容损失。现在,关于这个内容损失,我要说的一件事是我们不知道哪一层会起到最好的作用。所以如果我们能多做一些实验就好了。现在的情况很烦人:

也许我们甚至想使用多个层。所以,与其截断我们想要的层之后的所有层,不如我们能够以某种方式抓取几个层的激活值。现在,我们已经知道一种方法可以在我们做 SSD 时做到这一点,我们实际上编写了一个具有多个输出的网络。记得吗?不同的卷积层,我们吐出了一个不同的oconv东西?但我真的不想去添加到 torch.vision ResNet 模型中,特别是如果以后我想尝试 torch.vision VGG 模型,然后我想尝试 NASNet-A 模型,我不想去修改它们的输出。此外,我希望能够轻松地按需打开和关闭某些激活。所以我们之前简要提到过这个想法,PyTorch 有这些名为 hooks 的奇妙东西。您可以有前向钩子,让您将任何您喜欢的东西插入到计算的前向传递中,或者有后向钩子,让您将任何您喜欢的东西插入到后向传递中。所以我们将创建世界上最简单的前向钩子。
x = val_tfms.denorm(np.rollaxis(to_np(opt_img_v.data),1,4))[0]
plt.figure(figsize=(7,7))
plt.imshow(x);

前向钩子[1:29:42]
这是几乎没有人知道的事情之一,因此几乎在互联网上找到的任何实现风格转移的代码都会有各种可怕的黑客,而不是使用前向钩子。但前向钩子真的很容易。
要创建一个前向钩子,只需创建一个类。该类必须有一个名为hook_fn的东西。您的钩子函数将接收您挂钩的module,前向传递的input和output,然后您可以做任何您喜欢的事情。所以我要做的就是将这个模块的输出存储在某个属性中。就是这样。所以hook_fn实际上可以被称为您喜欢的任何东西,但“hook function”似乎是标准,因为您可以看到,在构造函数中发生的是我在某个属性中存储了m.register_forward_hook的结果(m将是我要挂钩的层),并传入您希望在调用模块的前向方法时调用的函数。当调用其前向方法时,它将调用self.hook_fn,该函数将在名为features的属性中存储输出。
class SaveFeatures():
features=None
def __init__(self, m):
self.hook = m.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
self.features = output
def close(self):
self.hook.remove()
现在我们可以像以前一样创建一个 VGG。让我们将其设置为不可训练,这样我们就不会浪费时间和内存来计算梯度。让我们遍历并找到所有的最大池层。让我们遍历这个模块的所有子层,如果是一个最大池层,让我们输出索引减 1——这样就会给我最大池之前的层。通常,最大池或步长 2 卷积之前的层是一个非常完整的表示,因为下一层正在改变网格。所以这对我来说是一个很好的地方来获取内容损失。我们在该网格大小上拥有的最语义化、最有趣的内容。这就是为什么我要选择这些索引。
m_vgg = to_gpu(vgg16(True)).eval()
set_trainable(m_vgg, False)
这些是 VGG 中每个最大池之前的最后一层的索引[1:32:30]。
block_ends = [
i-1 for i,o in enumerate(children(m_vgg))
if isinstance(o,nn.MaxPool2d)
]
block_ends
'''
[5, 12, 22, 32, 42]
'''
我要获取32——没有特定的原因,只是尝试其他东西。所以我要说block_ends[3](即 32)。children(m_vgg)[block_ends[3]]会给我 VGG 的第 32 层作为一个模块。
sf = SaveFeatures(children(m_vgg)[block_ends[3]])
然后,如果我调用SaveFeatures构造函数,它会执行:
self.hook = {VGG 的第 32 层}.register_forward_hook(self.hook_fn)
现在,每当我对这个 VGG 模型进行前向传递时,它都会将第 32 层的输出存储在sf.features中。
def get_opt():
opt_img = np.random.uniform(
0, 1,
size=img.shape
).astype(np.float32)
opt_img = scipy.ndimage.filters.median_filter(opt_img, [8,8,1])
opt_img_v = V(val_tfms(opt_img/2)[None], requires_grad=True)
return opt_img_v, optim.LBFGS([opt_img_v])
opt_img_v, optimizer = get_opt()
在这里[1:33:33],我调用了我的 VGG 网络,但我没有将其存储在任何地方。我没有说activations = m_vgg(VV(img_tfm[**None**]))。我调用它,丢弃答案,然后抓取我们在SaveFeatures对象中存储的特征。
m_vgg() — 这是在 PyTorch 中进行前向路径的方法。你不会说 m_vgg.forward(),你只是将其用作可调用。在 nn.module 上使用可调用会自动调用 forward。这就是 PyTorch 模块的工作方式。
所以我们称之为可调用的,最终调用我们的前向钩子,前向钩子将激活存储在 sf.features 中,所以现在我们有了我们的目标变量 — 就像以前一样,但以一种更加灵活的方式。
get_opt 包含了我们之前的相同的 4 行代码[1:34:34]。它只是给我一个要优化的随机图像和一个优化器来优化该图像。
m_vgg(VV(img_tfm[None]))
targ_v = V(sf.features.clone())
targ_v.shape
'''
torch.Size([1, 512, 36, 36])
'''
def actn_loss2(x):
m_vgg(x)
out = V(sf.features)
return F.mse_loss(out, targ_v)*1000
现在我可以继续做完全相同的事情。但现在我将使用不同的损失函数 actn_loss2(激活损失 #2),它不会说 out=m_vgg,再次,它调用 m_vgg 进行前向传递,丢弃结果,并获取 sf.features。所以现在这是我的第 32 层激活,然后我可以在其上执行均方误差损失。你可能已经注意到,最后一个损失函数和这个都乘以了一千。为什么它们乘以一千?这就像所有试图使这个课程不正确的事情。我以前没有使用一千,它就无法训练。今天午餐时间,什么都不起作用。经过几天的尝试让这个东西工作,最终偶然注意到“天哪,损失函数的数字真的很低(如 10E-7)”,我想如果它们不那么低会怎样。所以我将它们乘以一千,然后它开始工作了。那为什么它不起作用呢?因为我们正在使用单精度浮点数,而单精度浮点数并不那么精确。特别是当你得到的梯度有点小,然后你乘以学习率可能也很小,最终得到一个很小的数字。如果它太小,它们可能会被四舍五入为零,这就是发生的事情,我的模型还没有准备好。我相信有比乘以一千更好的方法,但无论如何。它运行得很好。无论你将损失函数乘以多少,因为你关心的只是它的方向和相对大小。有趣的是,这与我们在训练 ImageNet 时所做的事情类似。我们使用了半精度浮点数,因为 Volta 张量核要求如此。如果你想要训练半精度浮点数,实际上你必须将损失函数乘以一个缩放因子。我们使用了 1024 或 512。我认为 fast.ai 现在是第一个具有所有必要技巧以在半精度浮点数中进行训练的库,因此如果你有幸拥有 Volta 或者你可以支付 AWS P3,如果你有一个学习对象,你只需说 learn.half,它现在就会神奇地正确地训练半精度浮点数。它也内置在模型数据对象中,一切都是自动的。我相信没有其他库能做到这一点。
n_iter=0
while n_iter <= max_iter:
optimizer.step(partial(step,actn_loss2))
'''
Iteration: n_iter, loss: 0.2112911492586136
Iteration: n_iter, loss: 0.0902421623468399
Iteration: n_iter, loss: 0.05904778465628624
Iteration: n_iter, loss: 0.04517251253128052
Iteration: n_iter, loss: 0.03721420466899872
Iteration: n_iter, loss: 0.03215853497385979
Iteration: n_iter, loss: 0.028526008129119873
Iteration: n_iter, loss: 0.025799645110964775
Iteration: n_iter, loss: 0.02361033484339714
Iteration: n_iter, loss: 0.021835438907146454
'''
这只是在稍早的层上做同样的事情[1:37:35]。这只是让鸟看起来更像鸟。希望你能理解,较早的层越接近像素。有更多的网格单元,每个单元更小,更小的感受野,更简单的语义特征。所以我们越早得到,它看起来就越像一只鸟。
x = val_tfms.denorm(np.rollaxis(to_np(opt_img_v.data),1,4))[0]
plt.figure(figsize=(7,7))
plt.imshow(x);

sf.close()
事实上,这篇论文有一张很好的图片展示了各种不同的层,并放大到这座房子[1:38:17]。他们试图让这座房子看起来像《星夜》的图片。你可以看到后来,它变得非常混乱,而之前看起来像这座房子。所以这只是在做我们刚刚做的事情。我在我们的学习小组中注意到的一件事是,每当我告诉某人回答一个问题,每当我说去读这篇论文中有一些东西告诉你问题的答案时,总会有一种震惊的表情“读这篇论文?我?”但是说真的,论文已经做了这些实验并绘制了这些图片。论文中有很多东西。这并不意味着你必须读完论文的每一部分。但至少看看图片。所以看看 Gatys 的论文,里面有很好的图片。所以他们已经为我们做了实验,但看起来他们没有深入研究 — 他们只是得到了一些早期的结果。

风格匹配[1:39:29]
我们接下来需要做的是创建风格损失。我们已经有了损失,即它有多像鸟。现在我们需要知道它有多像这幅绘画的风格。我们将做几乎相同的事情。我们将获取某一层的激活。现在问题是,某一层的激活,假设它是一个 5x5 的层(当然没有 5x5 的层,它是 224x224,但我们假装)。这里是一些激活,我们可以获取这些激活,无论是针对我们正在优化的图像还是我们的梵高绘画。让我们看看我们的梵高绘画。这就是它 —《星夜》
style_fn = PATH/'style'/'starry_night.jpg'
style_img = open_image(style_fn)
style_img.shape, img.shape
'''
((1198, 1513, 3), (291, 483, 3))
'''
plt.imshow(style_img);

我从维基百科下载了这幅图像,我想知道为什么加载如此缓慢[1:40:39] — 结果,我下载的维基百科版本是 30,000 x 30,000 像素。他们有这种严肃的画廊品质存档真的很酷。我不知道这个存在。不要试图在上面运行神经网络。完全毁了我的 Jupyter 笔记本。
所以我们可以为我们的梵高图像做到这一点,也可以为我们的优化图像做到这一点。然后我们可以比较这两者,最终我们会创建一幅内容类似于绘画但并非绘画的图像 — 这不是我们想要的。我们想要的是具有相同风格但不是绘画且没有内容的东西。所以我们想要丢弃所有的空间信息。我们不想要创造出一个这里有月亮,这里有星星,这里有教堂的东西。我们不想要任何这些。那么我们如何丢弃所有的特殊信息呢?

在这种情况下,这里有 19 个面 - 19 个切片。所以让我们拿到这个顶部切片,这将是一个 5x5 矩阵。现在,让我们展平它,我们得到一个 25 个元素的长向量。一下子,我们通过展平抛弃了大部分空间信息。现在让我们拿到第二个切片(即另一个通道)并做同样的事情。所以我们有通道 1 展平和通道 2 展平,它们都有 25 个元素。现在,让我们进行点积,我们可以在 Numpy 中用 @ 来做(注:这里是 Jeremy 对我的点积与矩阵乘法问题的回答)。点积将给我们一个数字。那个数字是什么?它告诉我们什么?假设激活在 VGG 网络的中间层附近,我们可能期望其中一些激活是笔触纹理有多强,一些是这个区域有多明亮,一些是这部分是房子的一部分还是圆形的一部分,或者其他部分是这幅画的哪部分有多暗。所以点积基本上是一个相关性。如果这个元素和这个元素都非常正或都非常负,它会给我们一个大结果。另外,如果它们相反,它会给一个小结果。如果它们都接近零,它不会给结果。所以基本上点积是衡量这两个东西有多相似的一个指标。所以如果通道 1 和通道 2 的激活相似,那么它基本上是在说 - 让我们举个例子[1:44:28]。比如第一个是笔触纹理有多强(C1),而另一个是笔触有多倾斜(C2)。

如果细胞(1,1)的 C1 和 C2 同时高,细胞(4,2)也是如此,那么它表明具有纹理的网格单元也倾向于具有对角线。因此,当具有纹理的网格单元也具有对角线时,点积会很高,当它们没有时,点积也不高。所以这就是 C1 @ C2。另外,C1 @ C1 实际上是 2-范数(即 C1 的平方和)。这基本上是在说纹理通道中有多少网格单元是活跃的,以及它们有多活跃。换句话说,C1 @ C1 告诉我们纹理绘画进行了多少。而 C2 @ C2 告诉我们对角线绘画进行了多少。也许 C3 是“颜色是否明亮?”,所以 C3 @ C3 将告诉我们明亮颜色单元有多频繁。
那么我们可以创建一个包含每个点积的 19x19 矩阵[1:47:17]。就像我们讨论过的,数学家们必须给每样东西起个名字,所以这个特定的矩阵,将其展平然后进行所有点积的操作,被称为 Gram 矩阵。

我告诉你一个秘密[1:48:29]。大多数深度学习从业者要么不知道,要么不记得所有这些东西,比如如果他们曾经在大学学过 Gram 矩阵。他们可能忘记了,因为之后他们可能熬夜了。实际上的工作方式是你意识到“哦,我可以创建一个非空间表示,展示通道之间的相关性”,然后当我写论文时,我不得不去问周围的人,“这个东西有个名字吗?” 然后有人会说“这不就是 Gram 矩阵吗?” 你去查一下,确实是。所以不要认为你必须先学习所有的数学。先运用你的直觉和常识,然后再担心数学叫什么,通常是这样。有时候也会反过来,不过不是对我,因为我不擅长数学。
所以这被称为 Gram 矩阵。当然,如果你是一个真正的数学家,非常重要的是你要说得好像你一直知道这是一个 Gram 矩阵,然后你就会说,哦是的,我们只是计算 Gram 矩阵。所以 Gram 矩阵就是这种映射——对角线可能是最有趣的部分。对角线显示哪些通道最活跃,然后非对角线显示哪些通道倾向于一起出现。总的来说,如果两幅图片有相同的风格,那么我们期望某些激活层会有相似的 Gram 矩阵。因为如果我们找到了捕捉很多关于画笔笔触和颜色的东西的激活层,那么仅仅对角线(在 Gram 矩阵中)可能就足够了。这是另一个有趣的作业,如果有人想尝试的话,可以尝试使用 Gatys 的风格迁移,而不是使用 Gram 矩阵,而是只使用 Gram 矩阵的对角线。这只需要改变一行代码。但我还没有看到有人尝试过,也不知道它是否会起作用,但它可能会很好。
“好的,是的,克里斯汀,你已经尝试过了。”“我已经尝试过了,大多数时候都有效,除非你有需要两种风格出现在同一个地方的有趣图片。所以看起来像是一半是草,一半是人群,你需要这两种风格。”(克里斯汀)。很酷,你仍然会做你的作业,但克里斯汀说她会替你做。
def scale_match(src, targ):
h,w,_ = img.shape
sh,sw,_ = style_img.shape
rat = max(h/sh,w/sw); rat
res = cv2.resize(style_img, (int(sw*rat), int(sh*rat)))
return res[:h,:w]
style = scale_match(img, style_img)
plt.imshow(style)
style.shape, img.shape
'''
((291, 483, 3), (291, 483, 3))
'''

这是我们的绘画。我尝试调整绘画的大小,使其与我的鸟类图片大小相同。所以这就是所有这些在做的事情。不管我使用哪一部分,只要它有很多漂亮的风格就可以了。
我像以前一样获取了我的优化器和随机图像:
opt_img_v, optimizer = get_opt()
这一次,我为所有的block_ends调用SaveFeatures,这将给我一个 SaveFeatures 对象的数组——每个模块都会出现在最大池化之前的层中。因为这一次,我想玩弄不同的激活层风格,更具体地说,我想让你来玩。所以现在我有了一个完整的数组。
sfs = [SaveFeatures(children(m_vgg)[idx]) for idx in block_ends]
style_img是我的梵高的绘画。所以我拿我的style_img,通过我的转换来创建我的转换风格图像(style_tfm)。
style_tfm = val_tfms(style_img)
将其转换为一个变量,通过我的 VGG 模块的前向传播,现在我可以遍历所有的 SaveFeatures 对象并获取每组特征。请注意,我调用clone,因为以后,如果我再次调用我的 VGG 对象,它将替换这些内容。我还没有想过这是否有必要。如果你把它拿走了,那没关系。但我只是小心翼翼。现在这是每个block_end层的激活的数组。在这里,你可以看到所有这些形状:
m_vgg(VV(style_tfm[None]))
targ_styles = [V(o.features.clone()) for o in sfs]
[o.shape for o in targ_styles]
'''
[torch.Size([1, 64, 288, 288]),
torch.Size([1, 128, 144, 144]),
torch.Size([1, 256, 72, 72]),
torch.Size([1, 512, 36, 36]),
torch.Size([1, 512, 18, 18])]
'''
你可以看到,能够快速地编写一个列表推导式在你的 Jupyter 玩耍中非常重要。因为你真的希望能够立即看到这是我的通道(64、128、256,…),以及我们期望的网格大小减半(288、144、72…),因为所有这些都出现在最大池化之前。
因此,要进行 Gram MSE 损失,它将是输入的 Gram 矩阵与目标的 Gram 矩阵的 MSE 损失。Gram 矩阵只是x与x转置(x.t())的矩阵乘积,其中 x 简单地等于我已经将批处理和通道轴全部展平的输入。我只有一个图像,所以可以忽略批处理部分——基本上是通道。然后其他所有部分(-1),在这种情况下是高度和宽度,是另一个维度,因为现在将是通道乘以高度和宽度,然后正如我们讨论过的,我们可以将其与其转置进行矩阵乘积。为了归一化,我们将其除以元素的数量(b*c*h*w)——如果我说input.numel(元素的数量)会更优雅,这将是相同的事情。再次,这给我了很小的数字,所以我乘以一个大数字使其变得更合理。所以这基本上就是我的损失。
def gram(input):
b,c,h,w = input.size()
x = input.view(b*c, -1)
return torch.mm(x, x.t())/input.numel()*1e6
def gram_mse_loss(input, target):
return F.mse_loss(gram(input), gram(target))
现在我的风格损失是将我的图像优化,通过 VGG 前向传递,获取所有 SaveFeatures 对象中特征的数组,然后在每一层上调用我的 Gram MSE 损失。这将给我一个数组,然后我只需将它们相加。现在你可以用不同的权重将它们相加,你可以添加子集,或者其他。在这种情况下,我只是获取了所有的。
def style_loss(x):
m_vgg(opt_img_v)
outs = [V(o.features) for o in sfs]
losses = [gram_mse_loss(o, s) for o,s in zip(outs, targ_styles)]
return sum(losses)
像以前一样将其传递给我的优化器:
n_iter=0
while n_iter <= max_iter:
optimizer.step(partial(step,style_loss))
'''
Iteration: n_iter, loss: 230718.453125
Iteration: n_iter, loss: 219493.21875
Iteration: n_iter, loss: 202618.109375
Iteration: n_iter, loss: 481.5616760253906
Iteration: n_iter, loss: 147.41177368164062
Iteration: n_iter, loss: 80.62625122070312
Iteration: n_iter, loss: 49.52326965332031
Iteration: n_iter, loss: 32.36254119873047
Iteration: n_iter, loss: 21.831811904907227
Iteration: n_iter, loss: 15.61091423034668
'''
这里有一张随机图像,风格类似于梵高,我觉得挺酷的。
x = val_tfms.denorm(np.rollaxis(to_np(opt_img_v.data),1,4))[0]
plt.figure(figsize=(7,7))
plt.imshow(x);

再次,Gatys 已经为我们做好了。这里是不同层次的随机图像,风格类似于梵高。所以第一个,你可以看到,激活是简单的几何图形——一点也不有趣。后面的层次更有趣。所以我们有一种怀疑,我们可能想要主要使用后面的层次来进行风格损失,如果我们想要看起来好的话。


我添加了这个SaveFeatures.close,它只是调用self.hook.remove()。记住,我将 hook 存储为self.hook,所以hook.remove()会将其删除。最好将其删除,否则可能会一直使用内存。因此,在最后,我只需遍历每个 SaveFeatures 对象并关闭它:
for sf in sfs: sf.close()
风格转移
风格转移是将内容损失和风格损失加在一起,并加上一些权重。所以没有太多可以展示的。
获取我的优化器,获取我的图像:
opt_img_v, optimizer = get_opt()
我的综合损失是一个特定层次的 MSE 损失,我所有层次的风格损失,将风格损失相加,加到内容损失上,我正在缩放内容损失。实际上,我已经将风格损失缩放为 1E6。所以它们都被精确地缩放了。将它们加在一起。再次,你可以尝试对不同的风格损失进行加权,或者你可以删除其中一些,所以这是最简单的版本。
def comb_loss(x):
m_vgg(opt_img_v)
outs = [V(o.features) for o in sfs]
losses = [gram_mse_loss(o, s) for o,s in zip(outs, targ_styles)]
cnt_loss = F.mse_loss(outs[3], targ_vs[3])*1000000
style_loss = sum(losses)
return cnt_loss + style_loss
训练它:
n_iter=0
while n_iter <= max_iter:
optimizer.step(partial(step,comb_loss))
'''
Iteration: n_iter, loss: 1802.36767578125
Iteration: n_iter, loss: 1163.05908203125
Iteration: n_iter, loss: 961.6024169921875
Iteration: n_iter, loss: 853.079833984375
Iteration: n_iter, loss: 784.970458984375
Iteration: n_iter, loss: 739.18994140625
Iteration: n_iter, loss: 706.310791015625
Iteration: n_iter, loss: 681.6689453125
Iteration: n_iter, loss: 662.4088134765625
Iteration: n_iter, loss: 646.329833984375
'''
x = val_tfms.denorm(np.rollaxis(to_np(opt_img_v.data),1,4))[0]
plt.figure(figsize=(9,9))
plt.imshow(x, interpolation='lanczos')
plt.axis('off');

for sf in sfs: sf.close()
天啊,它看起来真的很好。所以我觉得这很棒。这里的主要要点是,如果你想用神经网络解决问题,你所要做的就是设置一个损失函数,然后优化某些东西。而损失函数是一个较低的数字是你更满意的东西。因为当你优化它时,它会使那个数字尽可能低,它会做你想要它做的事情。所以在这里,Gatys 提出了一个损失函数,当它看起来像我们想要的东西时,它会是一个较小的数字,看起来像我们想要的风格。这就是我们所要做的。
实际上,除了实现了 Gram MSE 损失,这只是 6 行代码,这就是我们的损失函数:

将其传递给我们的优化器,等大约 5 秒钟,我们就完成了。记住,我们可以一次处理一批,所以我们可以等待 5 秒钟,64 个就完成了。所以我认为这真的很有趣,自从这篇论文发表以来,它确实激发了很多有趣的工作。不过对我来说,大部分有趣的工作还没有发生,因为对我来说,有趣的工作是将人类创造力与这些工具结合起来的工作。我还没有看到可以下载或使用的工具,艺术家可以控制并可以以交互方式进行操作。与Google Magenta项目的人交谈很有趣,这是他们的创意人工智能项目,他们在音乐方面所做的一切都是关于这个的。它正在构建音乐家可以实时使用的工具。由于 Magenta 的存在,您将在音乐领域看到更多这样的东西。如果您访问他们的网站,您会看到各种按键,可以实际更改鼓点、旋律、音调等。您肯定会看到 Adobe 或 Nvidia 开始发布一些小型原型并开始这样做,但这种创意人工智能的爆发尚未发生。我认为我们已经拥有了我们所需的所有技术,但没有人将其整合到一起并说“看看我建造的东西,看看人们用我的东西建造的东西”。所以这只是一个巨大的机会领域。
所以我在课堂开始时提到的那篇论文[2:01:16] ——基本上是将美国队长的盾牌添加到任意绘画中使用了这种技术。不过,诀窍是通过一些微小的调整使粘贴的美国队长盾牌能够很好地融入其中。但那篇论文只有几天的历史,所以尝试这个项目将是一个非常有趣的项目,因为您可以使用所有这些代码。它确实利用了这种方法。然后,您可以从使内容图像类似于带有盾牌的绘画开始,然后样式图像可以是不带盾牌的绘画。这将是一个很好的开始,然后您可以看看他们在这篇论文中尝试解决的具体问题,以使其更好。但您现在可以开始。
问题:之前有很多人表达了对 Pyro 和概率编程的兴趣。所以 TensorFlow 现在有了这个 TensorFlow 概率或其他东西。有很多概率编程框架。我认为它们很有趣,但至今未经证明,因为我还没有看到任何使用概率编程系统完成的事情,而没有使用它们更好。基本前提是它允许你创建更多关于你认为世界是如何运作的模型,然后插入参数。所以 20 年前当我还在管理咨询行业工作时,我们经常使用电子表格,然后我们会使用这些蒙特卡洛模拟插件——有一个叫做 At Risk(?),一个叫做 Crystal Ball。我不知道几十年后它们是否还存在。基本上它们让你可以更改电子表格中的一个单元格,说这不是一个具体的值,而实际上代表一个具有这个均值和标准差的值分布,或者它有这个分布,然后你会点击一个按钮,电子表格会从这些分布中随机抽取一千次数字重新计算,并显示你的结果的分布,可能是利润或市场份额或其他什么。那时我们经常使用它们。显然,人们认为电子表格是做这种工作的更明显的地方,因为你可以更自然地看到所有这些,但我不知道。我们将看到。在这个阶段,我希望它能够被证明有用,因为我觉得它非常吸引人,符合我过去经常做的工作。实际上,围绕这种东西有整个实践,他们过去称之为系统动力学,这实际上是建立在这种东西之上的,但它并没有走得太远。
问题:然后有一个关于通用风格转移预训练的问题。我不认为你可以为通用风格进行预训练,但你可以为特定风格的通用照片进行预训练,这就是我们要达到的目标。尽管可能最终会成为一项作业。我还没有决定。但我会做所有的部分。
问题:请让他谈谈多 GPU。哦,是的,我还没有关于那个的幻灯片。我们马上就要谈到了。
在我们开始之前,再分享一张来自 Gatys 论文的有趣图片。他们有更多图片,只是没有适合我的幻灯片,但是有不同的卷积层用于风格。不同的风格和内容比例,这里是不同的图片。显然这不再是梵高的风格,这是一个不同的组合。所以你可以看到,如果你只做风格,你看不到任何图片。如果你做很多内容,但是使用足够低的卷积层,看起来还可以,但背景有点愚蠢。所以你可能想要在中间某个地方。所以你可以尝试一下,做一些实验,但也可以使用论文来帮助指导你。

数学
实际上,我想现在开始研究数学,下周我们将讨论多 GPU 和超分辨率,因为这是来自论文的内容,我真的希望在我们讨论完论文后,你们能阅读论文,并在论坛上提出任何不清楚的问题。但这篇论文中有一部分我想谈谈,讨论如何解释它。所以论文说,我们将得到一个输入图像x,这个小东西通常表示它是一个向量,Rachel,但这个是一个矩阵。我猜它可能是两者之一。我不知道。通常小写粗体字母表示向量,或者带有上箭头的小写字母表示向量。通常大写字母表示矩阵,或者带有两个箭头的小写字母表示矩阵。在这种情况下,我们的图像是一个矩阵。我们基本上将其视为向量,所以也许我们只是在超前一步。
所以我们有一个输入图像x,它可以通过 CNN 的特定层中的滤波器响应(即激活)进行编码。滤波器响应就是激活。希望你们都能理解。CNN 的基本功能就是生成激活层。一个层有一堆滤波器,产生一定数量的通道。今年表示第 L 层有大写 Nl个滤波器。再次强调,这里的大写字母不代表矩阵。所以我不知道,数学符号是如此不一致。所以在第 L 层有 Nl 个不同的滤波器,这意味着也有同样数量的特征图。所以确保你能看到这个字母 Nl 和这个字母是一样的。所以你必须非常小心地阅读字母并认识到它就像啪一下,这个字母和那个字母是一样的。显然,Nl 个滤波器创建了 Nl 个特征图或通道,每个尺寸为 Ml(好吧,我看到这里正在发生展开)。这就像 numpy 符号中的 M[l]。这是第l层。所以 M 是第l层。尺寸是高度乘以宽度——所以我们将其展平。所以第 l 层的响应可以存储在矩阵 F 中(现在l在顶部,出于某种原因)。这不是 f^l,这只是另一个索引。我们只是为了好玩而移动它。这里我们说它是 R 的元素——这是一个特殊的 R,表示实数 N 乘以 M(这表示它的维度是 N 乘以 M)。这非常重要,不要继续。就像 PyTorch 一样,确保你首先理解维度的秩和大小,数学也是一样。这些是你停下来思考为什么是 N 乘以 M 的地方。N 是滤波器的数量,M 是高度乘以宽度。所以你还记得我们做.view(b*c, -1)的时候吗?这就是。所以尝试将代码映射到数学上。所以 F 是x:

如果我对你更友好,我会使用与论文相同的字母。但我太忙于让这个该死的东西运行起来,无法仔细做到这一点。所以你可以回去将其重命名为大写 F。

所以我们将 L 移到顶部是因为我们现在要有更多的索引。在 Numpy 或 PyTorch 中,我们通过方括号索引事物,然后用逗号分隔很多东西。在数学中的方法是用小写字母围绕你的字母——到处都扔上去。所以这里,Fl是 F 的第l层,然后ij是第l层中第i个滤波器在第j位置的激活。所以位置j的大小是 M,即高度乘以宽度的大小。这是容易混淆的事情。通常你会看到一个ij,然后假设它是在图像的高度乘以宽度的位置进行索引,但实际上不是,对吧?它是在通道中对展平图像的第i个滤波器/通道的第j个位置进行索引。它甚至告诉你——它是第l层中展平图像中第j个位置的第i个滤波器/通道。所以除非你理解 F 是什么,否则你将无法进一步阅读论文。这就是为什么这些是你停下来确保你感到舒适的地方。
所以现在,内容损失,我不会花太多时间,但基本上我们只是要检查激活值与预测值的平方[2:12:03]。所以这就是我们的内容损失。风格损失将是类似的,但使用格拉姆矩阵 G:

我真的很想向你展示这个。我觉得这很棒。有时我真的喜欢数学符号中可以做的事情,它们也是你通常可以在 J 和 APL 中做的事情,这种隐式循环正在这里进行。这是在说什么呢?嗯,它在说我的层l中的格拉姆矩阵,对于一个轴上的第i个位置和另一个轴上的第j个位置等于我的 F 矩阵(所以我的展平矩阵)对于该层中的第i个通道与同一层中的第j个通道,然后我将进行求和。我们将取第k个位置并将它们相乘然后将它们全部加起来。所以这正是我们之前计算格拉姆矩阵时所做的事情。所以这里发生了很多事情,因为对我来说,这是非常巧妙的符号 —— 有三个隐式循环同时进行,加上求和中的一个显式循环,然后它们一起工作来为每一层创建这个格拉姆矩阵。所以让我们回去看看你是否能匹配这个。所以所有这一切都同时发生,这非常棒。
就是这样。所以下周,我们将看到一个非常类似的方法,基本上再次进行风格转移,但这次我们实际上会训练一个神经网络来为我们做这件事,而不是进行优化。我们还将看到你可以做同样的事情来进行超分辨率。我们还将回顾一些 SSD 的内容,以及进行一些分割。所以如果你忘记了 SSD,这周可能值得进行一点复习。好的,谢谢大家。下周见。