文章目录
- 前言
- 一、数据加工
- 二、模型搭建
- 三、模型训练
- 1、构建模型
- 2、优化器与损失函数定义
- 3、模型训练
- 四、模型推理
- 五、所有Demo源码
前言
对话模型是一种人工智能技术,旨在使计算机能够像人类一样进行对话和交流。这种模型通常基于深度学习和自然语言处理技术,能够理解自然语言并做出相应的回应。然而现有博客很少介绍对话模型内容,也很少用一个简单代码带领大家理解其原理。因此,我创建一个简单的对话模型,在不适用Hugging Face或LSTM结构,旨在使用一个简单的全连接神经网络来实现这个模型,且代码基于PyTorch框架搭建,意在帮助读者构建对话模型知识。当然,模型仅是一个简单模型,旨在帮助理解原理,不具备很好效果能力。
一、数据加工
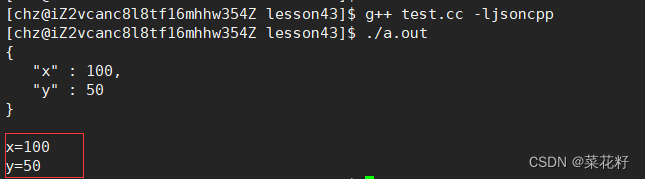
文本数据最终都是转为对应字典索引代表其文本内容,输入模型加工,实现nlp任务,对话模型也不列外。因此,我们需要构建一个字典映射(可参考:点击这里)与文本数据,并按照字典映射转换为对应索引id,其代码如下:
# 定义一个简单的对话数据集
data = [
("hi", "hello"),
("how are you?", "I'm fine, thank you."),
("what's your name?", "I'm a chatbot.")
]
# 构建词汇表
vocab = list(set(" ".join([x[0] + " " + x[1] for x in data])))
vocab.append("<SOS>")
vocab.append("<EOS>")
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
# 将对话数据集转换为索引序列
def to_idx_seq(sentence):
return [word_to_idx[word] for word in sentence]
data_x = [to_idx_seq(x[0]) for x in data]
data_y = [to_idx_seq(x[1]) for x in data]
data_y =[[word_to_idx["<SOS>"]]+list(x)+[word_to_idx["<EOS>"]] for x in data_y]
其字典内容如下:
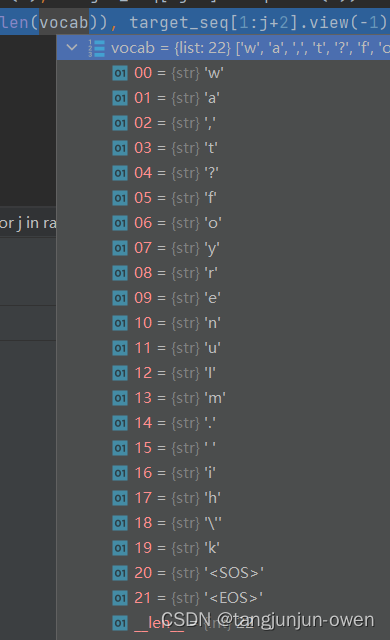
二、模型搭建
这里,也是最重要内容,如何搭建对话模型,我是使用transformer结构搭建(之前模型使用LSTM模型搭建),创建一个简单的对话生成模型,也使用一个基于全连接层的神经网络来实现这个模型,其代码如下:
# 定义一个简单的Transformer生成式对话模型
class ChatbotTransformer(nn.Module):
def __init__(self, input_dim, output_dim, nhead, num_encoder_layers, num_decoder_layers):
super(ChatbotTransformer, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.embedding = nn.Embedding(len(vocab), input_dim)
self.transformer = nn.Transformer(d_model=input_dim, nhead=nhead, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers)
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, src, tgt):
src = self.embedding(src).permute(1, 0, 2) # 调整输入张量维度
tgt = self.embedding(tgt).permute(1, 0, 2) # 调整输入张量维度
output = self.transformer(src, tgt)
output = self.fc(output)
return output
从代码上看,我们需要输入src为前面提问数据,而答案生成输入,是每个tgt字输入,按照顺序输出预测。
三、模型训练
1、构建模型
我大概试了一下,使用更多层对于简单数据反而效果不佳,我的数据又比较简单,我构建了较少的层来预测模型。其模型构建代码如下:
# 创建模型实例
# model = ChatbotTransformer(input_dim=256, output_dim=len(vocab), nhead=8, num_encoder_layers=6, num_decoder_layers=6)
model = ChatbotTransformer(input_dim=16, output_dim=len(vocab), nhead=8, num_encoder_layers=1, num_decoder_layers=1)
2、优化器与损失函数定义
优化器定义我将不考虑介绍,只说下文本预测是交叉熵方式,实际文本基本都采用该方法作为loss计算。其代码如下:
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
3、模型训练
接下来,我们解读如何训练对话模型,我们获得对应输入数据与生成预测数据,我们开始训练模型,其代码如下:
# 模型训练
epochs = 800
for epoch in range(epochs):
total_loss = 0
for i in range(len(data_x)):
optimizer.zero_grad()
input_seq = torch.tensor(data_x[i])
target_seq = torch.tensor(data_y[i])
for j in range(len(target_seq)-1):
if random.random() < 0.5:
j = random.randint(0, len(target_seq)-2)
output = model(input_seq.unsqueeze(0), target_seq[:j+1].unsqueeze(0)) # 使用目标序列的前n-1个词预测后n-1个词
loss = criterion(output.view(-1, len(vocab)), target_seq[1:j+2].view(-1)) # 计算损失,需要将输出形状转换成二维
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, epochs, total_loss / len(data_x)))
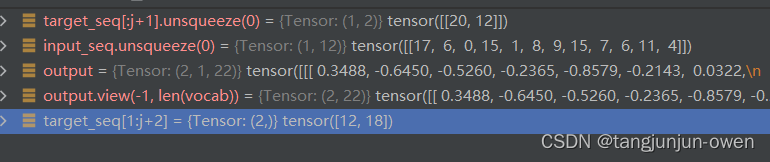
假设input_seq =tensor([17, 6, 0, 15, 1, 8, 9, 15, 7, 6, 11, 4]),target_seq=tensor([20, 12, 18, 13, 15, 5, 16, 10, 9, 2, 15, 3, 17, 1, 10, 19, 15, 7, 6, 11, 14, 21]),vocab为字典映射,共22个映射。我将试图模型连续2轮解释一下,训练时候相关变化。
第二轮输出结果:
第三轮输出结果:
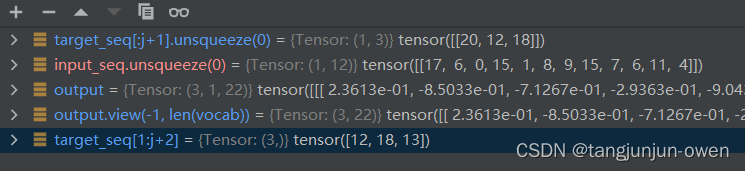
后面以此类推迭代。
很明显,提问每次都是全部输入,而输出则是第一个20开始与输入共同进模型,分别是模型src与tgt,不断重复与预测完成训练。而loss计算都是往后取一个target文本,也发现并不会计算20索引""文本。
四、模型推理
最后,让我们使用训练好的模型进行推理,实际和上面训练讲到方法类似,我们开始""文本开始,不断给出生成对应文本,也就是对话内容。
# 进行推理
def generate_response(input_sentence):
model.eval()
input_seq = torch.tensor(to_idx_seq(input_sentence))
target_seq = torch.tensor([word_to_idx["<SOS>"]]) # 在开始时使用特殊的起始标记
with torch.no_grad():
for i in range(20): # 限制生成的句子长度为20个词
output = model(input_seq.unsqueeze(0), target_seq.unsqueeze(0))
output_token = output.argmax(2)[-1].item()
print(idx_to_word[output_token], end=" ")
target_seq = torch.cat((target_seq, torch.tensor([output_token])), dim=0)
res = [idx_to_word[int(k)] for k in target_seq]
print(res[1:-1])
return res[1:-1]
# 进行对话生成
generate_response("hi")
其结果如下:
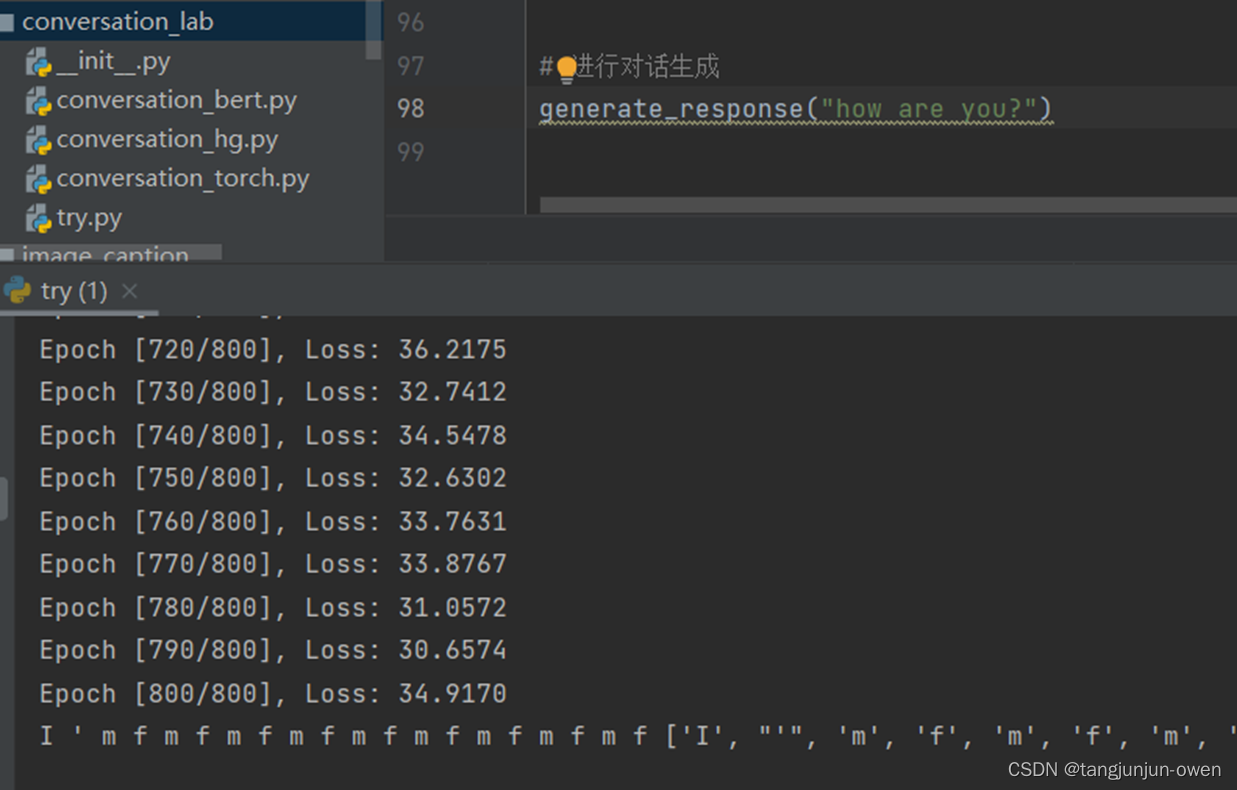
五、所有Demo源码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
# 定义一个简单的对话数据集
data = [
# ("hi", "hello"),
("how are you?", "I'm fine, thank you."),
# ("what's your name?", "I'm a chatbot.")
]
# 构建词汇表
vocab = list(set(" ".join([x[0] + " " + x[1] for x in data])))
vocab.append("<SOS>")
vocab.append("<EOS>")
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
# 将对话数据集转换为索引序列
def to_idx_seq(sentence):
return [word_to_idx[word] for word in sentence]
data_x = [to_idx_seq(x[0]) for x in data]
data_y = [to_idx_seq(x[1]) for x in data]
data_y =[[word_to_idx["<SOS>"]]+list(x)+[word_to_idx["<EOS>"]] for x in data_y]
# 定义一个简单的Transformer生成式对话模型
class ChatbotTransformer(nn.Module):
def __init__(self, input_dim, output_dim, nhead, num_encoder_layers, num_decoder_layers):
super(ChatbotTransformer, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.embedding = nn.Embedding(len(vocab), input_dim)
self.transformer = nn.Transformer(d_model=input_dim, nhead=nhead, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers)
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, src, tgt):
src = self.embedding(src).permute(1, 0, 2) # 调整输入张量维度
tgt = self.embedding(tgt).permute(1, 0, 2) # 调整输入张量维度
output = self.transformer(src, tgt)
output = self.fc(output)
return output
# 创建模型实例
# model = ChatbotTransformer(input_dim=256, output_dim=len(vocab), nhead=8, num_encoder_layers=6, num_decoder_layers=6)
model = ChatbotTransformer(input_dim=16, output_dim=len(vocab), nhead=8, num_encoder_layers=1, num_decoder_layers=1)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 模型训练
epochs = 800
for epoch in range(epochs):
total_loss = 0
for i in range(len(data_x)):
optimizer.zero_grad()
input_seq = torch.tensor(data_x[i])
target_seq = torch.tensor(data_y[i])
for j in range(len(target_seq)-1):
if random.random() < 0.5:
j = random.randint(0, len(target_seq)-2)
output = model(input_seq.unsqueeze(0), target_seq[:j+1].unsqueeze(0)) # 使用目标序列的前n-1个词预测后n-1个词
loss = criterion(output.view(-1, len(vocab)), target_seq[1:j+2].view(-1)) # 计算损失,需要将输出形状转换成二维
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, epochs, total_loss / len(data_x)))
# 进行推理
def generate_response(input_sentence):
model.eval()
input_seq = torch.tensor(to_idx_seq(input_sentence))
target_seq = torch.tensor([word_to_idx["<SOS>"]]) # 在开始时使用特殊的起始标记
with torch.no_grad():
for i in range(20): # 限制生成的句子长度为20个词
output = model(input_seq.unsqueeze(0), target_seq.unsqueeze(0))
output_token = output.argmax(2)[-1].item()
print(idx_to_word[output_token], end=" ")
target_seq = torch.cat((target_seq, torch.tensor([output_token])), dim=0)
res = [idx_to_word[int(k)] for k in target_seq]
print(res[1:-1])
return res[1:-1]
# 进行对话生成
generate_response("how are you?")




![[论文总结] 深度学习在农业领域应用论文笔记12](https://img-blog.csdnimg.cn/img_convert/b1683bbd890e82d3bd670ad50e0cbef5.png)