深度学习 2:第 1 部分第 1 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-1-602f73869197译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
第一课
开始 [0:00]:
-
为了训练神经网络,您几乎肯定需要图形处理单元(GPU) —— 具体来说是 NVIDIA GPU,因为它是唯一支持 CUDA(几乎所有深度学习库和从业者使用的语言和框架)的 GPU。
-
有几种租用 GPU 的方法:Crestle [04:06], Paperspace [06:10]
Jupyter Notebook 和 猫狗分类简介 [12:39]
-
您可以通过选择单元格并按
shift+enter来运行单元格(您可以按住shift并多次按enter以继续向下移动单元格),或者您可以点击顶部的运行按钮。一个单元格可以包含代码、文本、图片、视频等。 -
Fast.ai 需要 Python 3
%reload_ext autoreload
%autoreload 2
%matplotlib inline*
# This file contains all the main external libs we'll use
from fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
PATH = "data/dogscats/"
sz=224
首先看图片 [15:39]
!ls {PATH}
'''
models sample test1 tmp train valid
'''
-
!告诉使用 bash(shell)而不是 python -
如果您不熟悉训练集和验证集,请查看实用机器学习课程(或阅读Rachel 的博客)
!ls {PATH}valid
'''
cats dogs
'''
files = !ls {PATH}valid/cats | head
files
'''
['cat.10016.jpg',
'cat.1001.jpg',
'cat.10026.jpg',
'cat.10048.jpg',
'cat.10050.jpg',
'cat.10064.jpg',
'cat.10071.jpg',
'cat.10091.jpg',
'cat.10103.jpg',
'cat.10104.jpg']
'''
- 这个文件夹结构是共享和提供图像分类数据集的最常见方法。每个文件夹告诉您标签(例如
dogs或cats)。
img = plt.imread(f{PATH}valid/cats/{files[0]}')
plt.imshow(img);

f’{PATH}valid/cats/{files[0]}’— 这是 Python 3.6. 格式化字符串,是一种方便的格式化字符串的方法。
img.shape
'''
(198, 179, 3)
'''
img[:4,:4]
'''
array([[[ 29, 20, 23],
[ 31, 22, 25],
[ 34, 25, 28],
[ 37, 28, 31]],**[[ 60, 51, 54],
[ 58, 49, 52],
[ 56, 47, 50],
[ 55, 46, 49]],**[[ 93, 84, 87],
[ 89, 80, 83],
[ 85, 76, 79],
[ 81, 72, 75]],**[[104, 95, 98],
[103, 94, 97],
[102, 93, 96],
[102, 93, 96]]], dtype=uint8)*
-
img是一个三维数组(也称为秩为 3 的张量)。 -
这三个项目(例如
[29, 20, 23])代表介于 0 和 255 之间的红绿蓝像素值。 -
这个想法是拿这些数字并使用它们来预测这些数字是否代表一只猫还是一只狗,基于查看大量猫和狗的图片。
-
这个数据集来自Kaggle 竞赛,当它发布时(2013 年),最先进的技术准确率为 80%。
让我们训练一个模型 [20:21]
这是训练模型所需的三行代码:
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(resnet34, sz))
learn = ConvLearner.pretrained(resnet34, data, precompute=True)
learn.fit(0.01, 3)
'''
[ 0\. 0.04955 0.02605 0.98975]
[ 1\. 0.03977 0.02916 0.99219]
[ 2\. 0.03372 0.02929 0.98975]
'''
-
这将进行 3 轮,这意味着它将三次查看整个图像集。
-
输出中的三个数字中的最后一个是验证集上的准确率。
-
前两个是训练集和验证集的损失函数值(在本例中是交叉熵损失)。
-
起始(例如
0.、1.)是轮数。 -
我们在 17 秒内用 3 行代码实现了约 99% 的准确率(这在 2013 年将赢得 Kaggle 竞赛)![21:49]
-
很多人认为深度学习需要大量时间、资源和数据 —— 总的来说,这并不是真的!
Fast.ai 库 [22:24]
-
该库采用了他们能找到的所有最佳实践和方法 —— 每次有一篇看起来有趣的论文出来时,他们会测试它,如果它在各种数据集上表现良好并且他们能够找出如何调整它,那么它就会被实现在库中。
-
Fast.ai 为您整理了所有这些最佳实践并打包起来,大多数情况下,会自动找出最佳处理方式。
-
Fast.ai 建立在一个名为 PyTorch 的库之上,这是一个由 Facebook 编写的非常灵活的深度学习、机器学习和 GPU 计算库。
-
大多数人对 TensorFlow 比 PyTorch 更熟悉,但 Jeremy 现在认识的大多数顶尖研究人员已经转向 PyTorch。
-
Fast.ai 非常灵活,您可以根据需要使用所有这些精心策划的最佳实践。您可以轻松地在任何时候连接并编写自己的数据增强、损失函数、网络架构等,我们将在本课程中学习所有这些。
分析结果[24:21]
这是验证数据集标签(将其视为正确答案)的样子:
data.val_y
'''
array([0, 0, 0, ..., 1, 1, 1])
'''
这些 0 和 1 代表什么?
data.classes
'''
['cats', 'dogs']
'''
-
data包含验证和训练数据 -
learn包含模型
让我们对验证集进行预测(预测以对数刻度表示):
log_preds = learn.predict()
log_preds.shape
'''
(2000, 2)
'''
log_preds[:10]
'''
array([[ -0.00002, -11.07446],
[ -0.00138, -6.58385],
[ -0.00083, -7.09025],
[ -0.00029, -8.13645],
[ -0.00035, -7.9663 ],
[ -0.00029, -8.15125],
[ -0.00002, -10.82139],
[ -0.00003, -10.33846],
[ -0.00323, -5.73731],
[ -0.0001 , -9.21326]], dtype=float32)
'''
- 输出表示对猫的预测和对狗的预测
preds = np.argmax(log_preds, axis=1) # from log probabilities to 0 or 1
probs = np.exp(log_preds[:,1]) # pr(dog)
-
在 PyTorch 和 Fast.ai 中,大多数模型返回预测的对数而不是概率本身(我们将在课程中稍后学习原因)。现在,只需知道要获得概率,您必须执行
np.exp()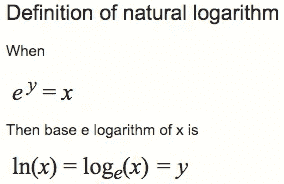
-
确保您熟悉 numpy(
np)
# 1\. A few correct labels at random
plot_val_with_title(rand_by_correct(True), "Correctly classified")
- 图像上方的数字是狗的概率
# 2\. A few incorrect labels at random
plot_val_with_title(rand_by_correct(False), "Incorrectly classified")

plot_val_with_title(most_by_correct(0, True), "Most correct cats")

plot_val_with_title(most_by_correct(1, True), "Most correct dogs")

更有趣的是,以下是模型认为肯定是狗的东西,但结果是猫,反之亦然:
plot_val_with_title(most_by_correct(0, False), "Most incorrect cats")

plot_val_with_title(most_by_correct(1, False), "Most incorrect dogs")

most_uncertain = np.argsort(np.abs(probs -0.5))[:4]
plot_val_with_title(most_uncertain, "Most uncertain predictions")

-
为什么查看这些图像很重要?Jeremy 在构建模型后的第一件事是找到一种可视化其构建内容的方法。因为如果他想让模型更好,那么他需要利用做得好的事情并修复做得不好的事情。
-
在这种情况下,我们已经了解了数据集本身的一些信息,即这里有一些可能不应该存在的图像。但很明显,这个模型还有改进的空间(例如数据增强 - 我们将在以后学习)。
-
现在,您已经准备好构建自己的图像分类器(用于常规照片 - 也许不是 CT 扫描)!例如,这里是一个学生的示例。
-
查看此论坛帖子以了解不同的可视化结果方式(例如,当存在超过 2 个类别时等)
自上而下 vs 自下而上[30:52]
自下而上:学习您需要的每个构建块,最终将它们组合在一起
-
难以保持动力
-
难以了解“全局图景”
-
难以知道您实际需要哪些部分
fast.ai:让学生立即使用神经网络,尽快获得结果
- 逐渐剥开层,修改,查看内部
课程结构[33:53]

-
使用深度学习的图像分类器(代码行数最少)
-
多标签分类和不同类型的图像(例如卫星图像)
-
结构化数据(例如销售预测)- 结构化数据来自数据库或电子表格
-
语言:NLP 分类器(例如电影评论分类)
-
协同过滤(例如推荐引擎)
-
生成语言模型:如何逐个字符从头开始编写您自己的尼采哲学
-
回到计算机视觉 - 不仅识别猫照片,还要找到照片中的猫所在位置(热图),并学习如何从头开始编写我们自己的架构(ResNet)
图像分类器示例:
图像分类算法对许多事物非常有用。
-
例如,AlphaGo[42:20]查看了成千上万个围棋棋盘,每个棋盘上都有一个标签,说明这个棋盘最终是赢家还是输家。因此,它学会了一种能够查看围棋棋盘并判断它是好还是坏的图像分类——这是打好围棋最重要的一步:知道哪一步走得更好。
-
另一个例子是一个早期的学生创建了一个鼠标移动图像分类器并检测到欺诈交易。
深度学习≠机器学习[44:26]
-
深度学习是一种机器学习
-
机器学习是由 Arthur Samuel 发明的。在 50 年代末,他让 IBM 大型机比他更擅长下棋,发明了机器学习。他让大型机反复对弈,并找出导致胜利的种种因素,然后利用这些因素,以某种方式编写自己的程序。1962 年,Arthur Samuel 说,未来绝大多数计算机软件将使用这种机器学习方法编写,而不是手工编写。
-
C-Path(计算病理学家)[45:42]是传统机器学习方法的一个例子。他拍摄了乳腺癌活检的病理学切片,咨询了许多病理学家关于与长期生存相关的模式或特征可能是什么。然后,他们编写了专家算法来计算这些特征,通过逻辑回归进行运算,并预测了生存率。它胜过了病理学家,但需要领域专家和计算机专家多年的工作才能构建。
更好的方法[47:35]
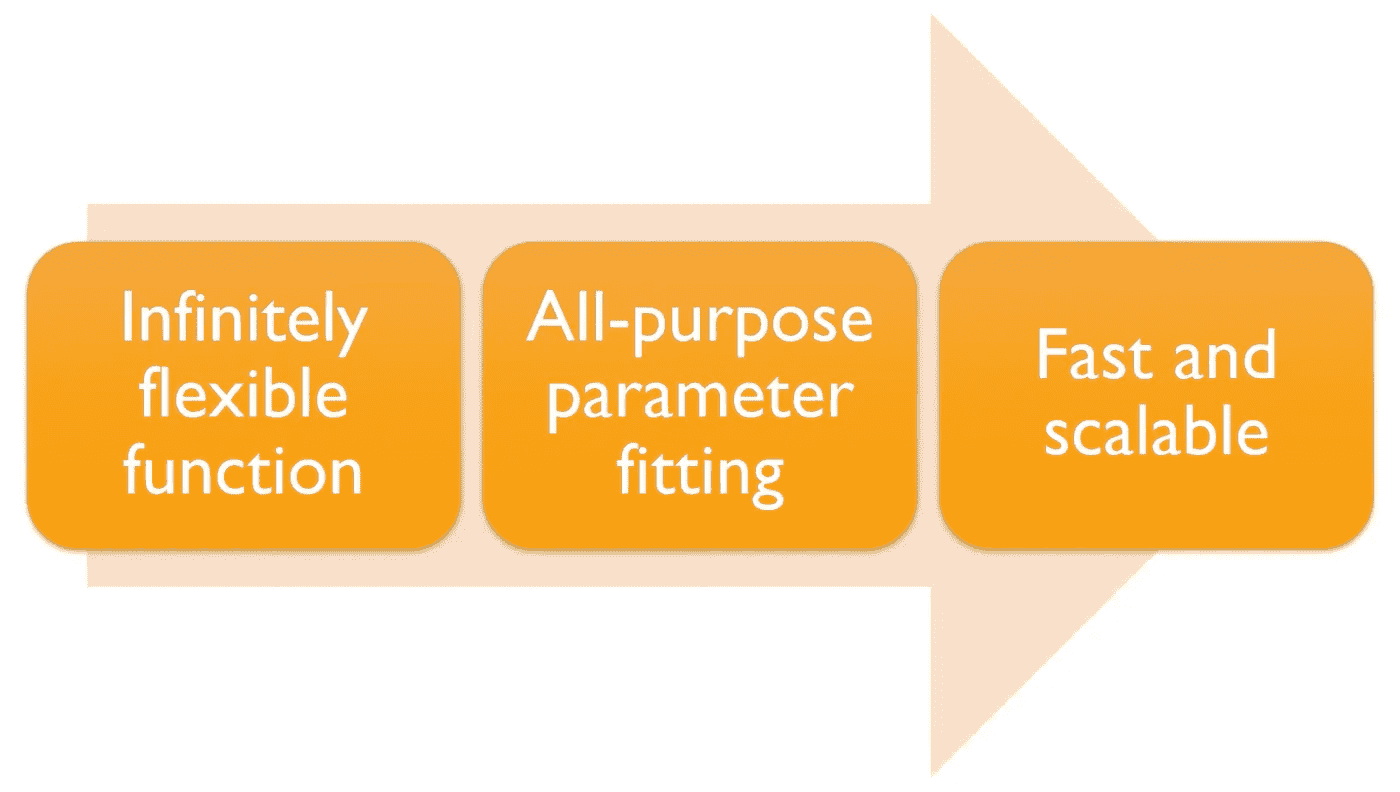
- 具有这三个特性的算法类别是深度学习。
无限灵活的函数:神经网络[48:43]
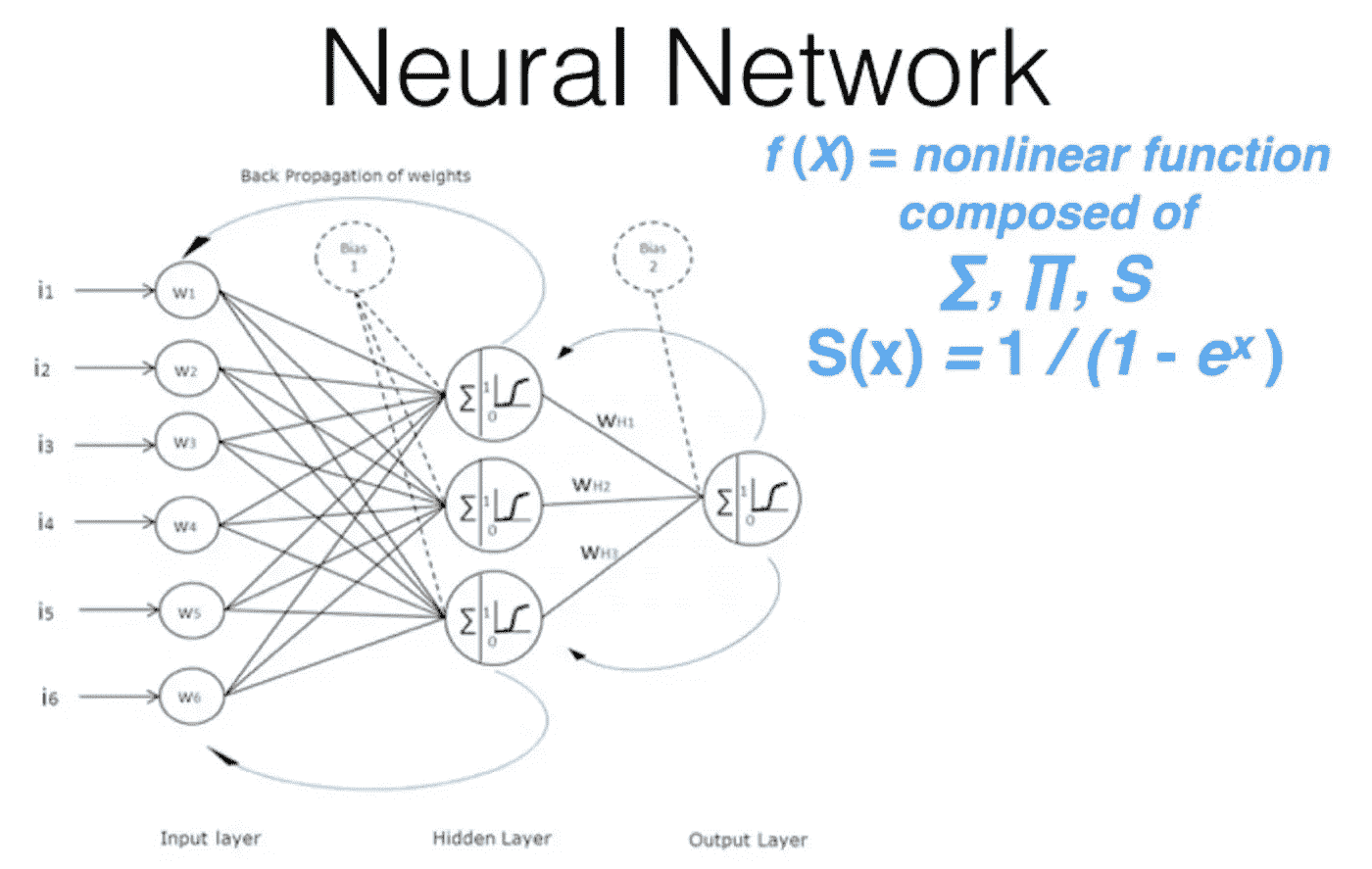
深度学习使用的基础函数称为神经网络:
- 现在你需要知道的是,它由许多简单的线性层和许多简单的非线性层组成。当你交错这些层时,你会得到一个称为通用逼近定理的东西。通用逼近定理所说的是,只要添加足够的参数,这种函数可以解决任何给定的问题,达到任意接近的精度。
全能参数拟合:梯度下降[49:39]
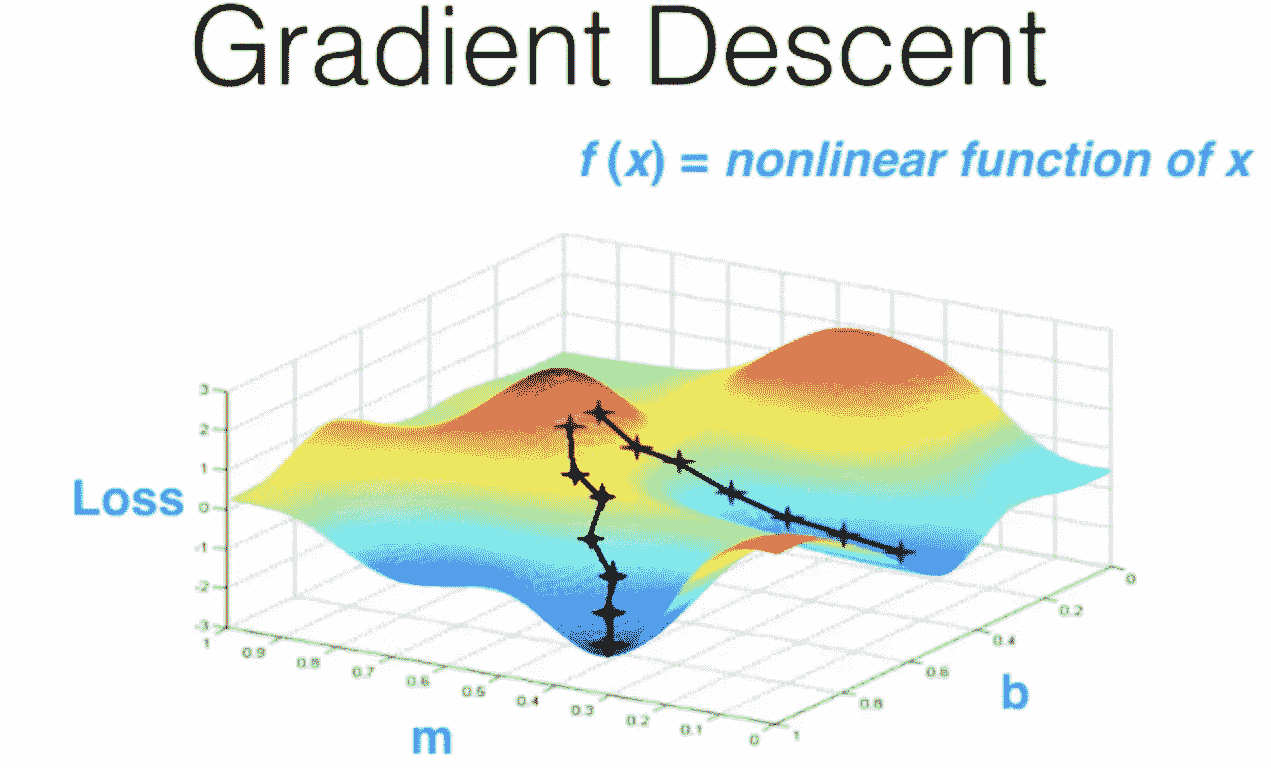
快速且可扩展:GPU[51:05]
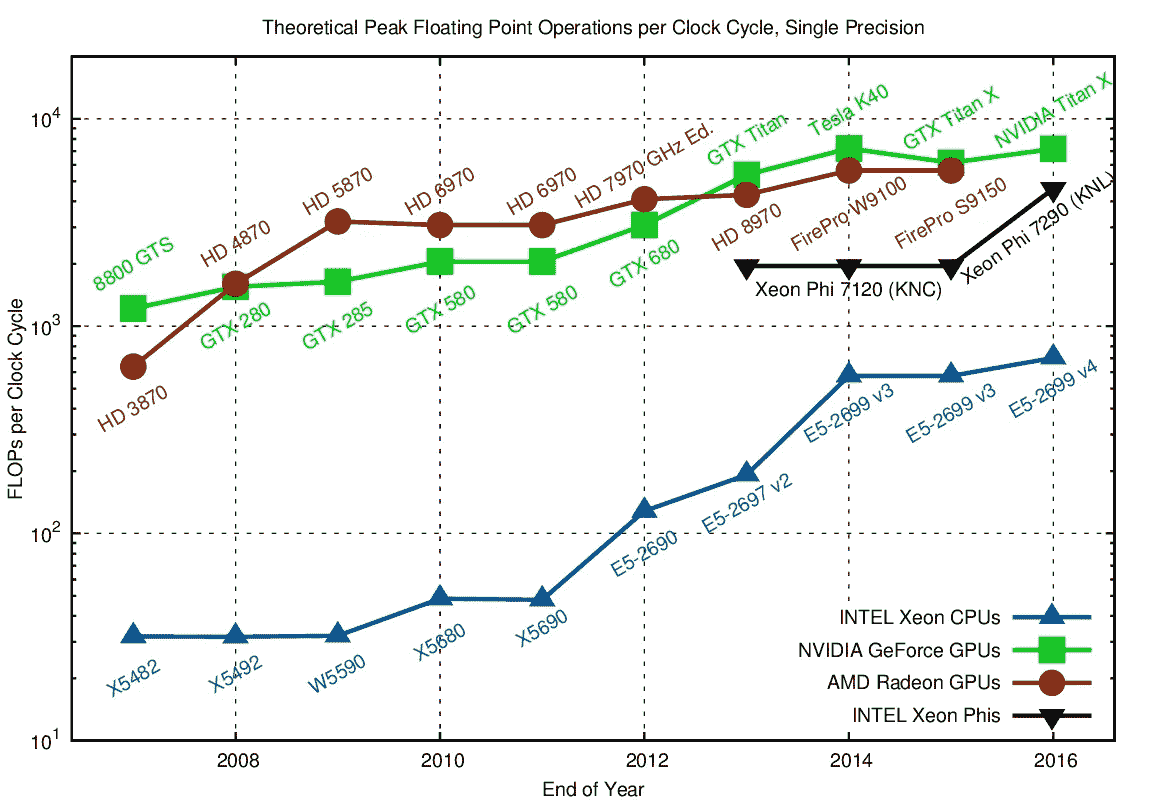
上面显示的神经网络示例有一个隐藏层。我们在过去几年学到的一些东西是,这种神经网络如果不添加多个隐藏层,就不会快速或可扩展,因此被称为“深度”学习。
将所有内容放在一起[53:40]

以下是一些例子:
-
research.googleblog.com/2015/11/computer-respond-to-this-email.html -
deepmind.com/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-40/ -
www.skype.com/en/features/skype-translator/ -
arxiv.org/abs/1603.01768

诊断肺癌[56:55]

其他当前应用:

卷积神经网络[59:13]
线性层
setosa.io/ev/image-kernels/

非线性层[01:02:12]
神经网络和深度学习
在这一章中,我给出了普适性定理的简单且大部分是可视化的解释。我们将一步一步地进行…
Sigmoid 和 ReLU

- 线性层和逐元素非线性函数的组合使我们能够创建任意复杂的形状 — 这是普适性定理的本质。
如何设置这些参数来解决问题[01:04:25]
- 随机梯度下降 — 我们沿着山坡小步前进。步长被称为学习率
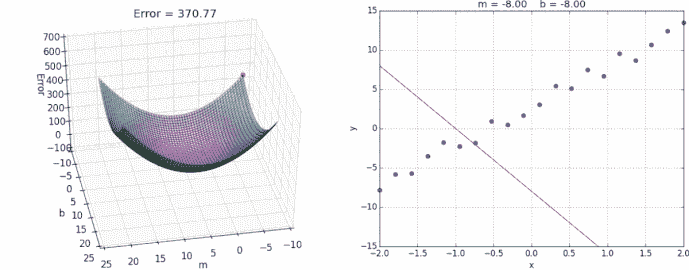
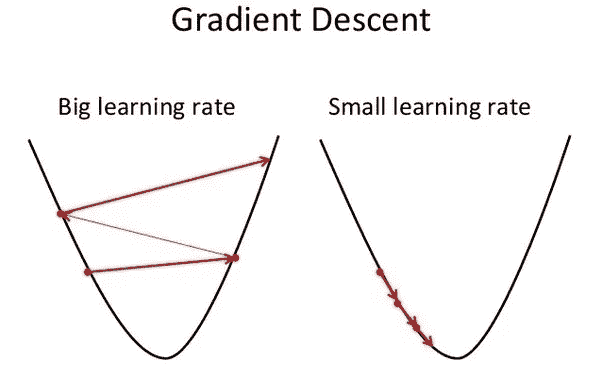
-
如果学习率太大,它会发散而不是收敛
-
如果学习率太小,将需要很长时间
可视化和理解卷积网络[01:08:27]

我们从一些非常简单的东西开始,但如果我们将其用作足够大的规模,由于普适性定理和深度学习中多个隐藏层的使用,我们实际上获得了非常丰富的能力。这实际上是我们在训练狗和猫识别器时使用的方法。
狗 vs. 猫再访——选择学习率[01:11:41]
learn.fit(0.01, 3)
-
第一个数字
0.01是学习率。 -
学习率决定了你想要多快或多慢地更新权重(或参数)。学习率是最难设置的参数之一,因为它会显著影响模型性能。
-
方法
learn.lr_find()可以帮助你找到一个最佳的学习率。它使用了 2015 年的论文Cyclical Learning Rates for Training Neural Networks中开发的技术,我们简单地从一个非常小的值开始不断增加学习率,直到损失停止减少。我们可以绘制跨批次的学习率,看看这是什么样子。
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.lr_find()
我们的learn对象包含一个包含我们学习率调度器的属性sched,并具有一些方便的绘图功能,包括这个:
learn.sched.plot_lr()
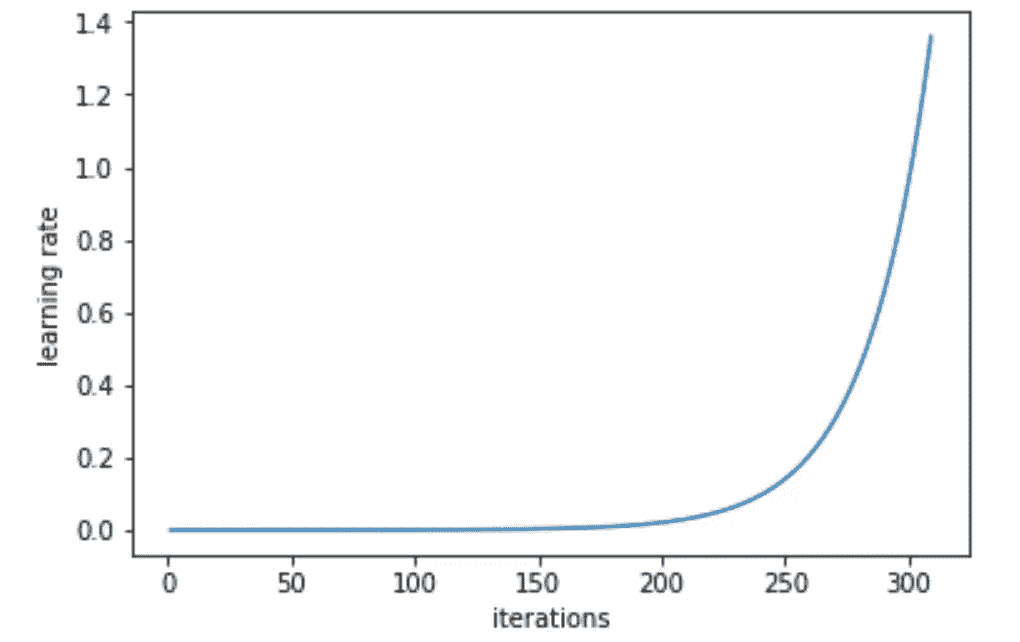
- Jeremy 目前正在尝试指数增加学习率与线性增加学习率。
我们可以看到损失与学习率的图表,以查看我们的损失何时停止减少:
learn.sched.plot()
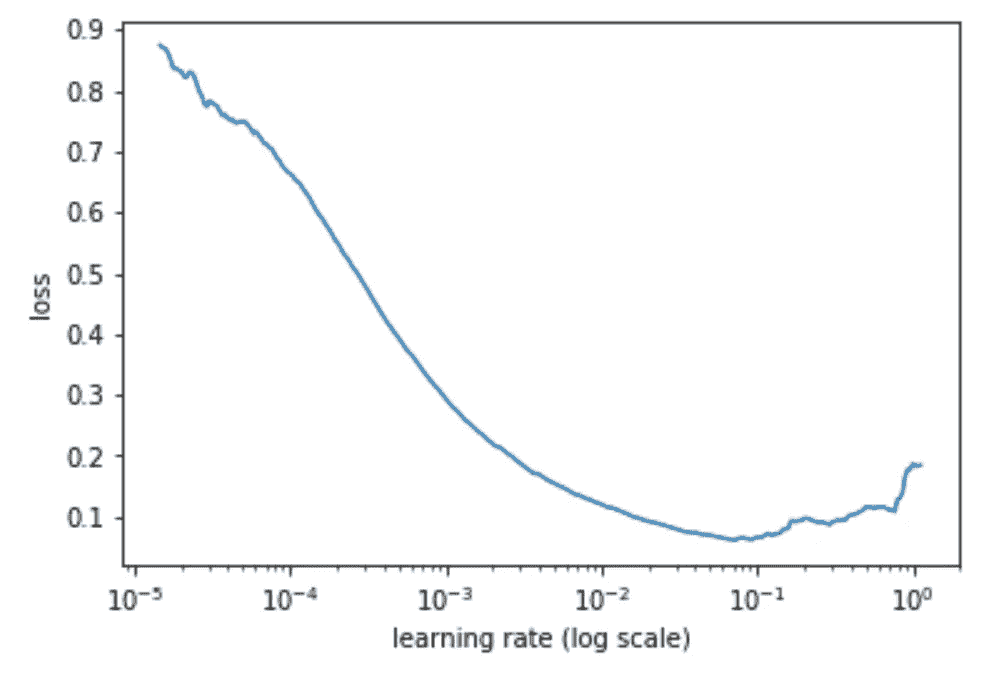
- 然后我们选择损失仍然明显改善的学习率 — 在这种情况下是
1e-2(0.01)
选择迭代次数[1:18:49]
'''
[ 0\. 0.04955 0.02605 0.98975]
[ 1\. 0.03977 0.02916 0.99219]
[ 2\. 0.03372 0.02929 0.98975]
'''
-
你想要多少都可以,但如果运行时间太长,准确性可能会开始变差。这被称为“过拟合”,我们稍后会更多地了解它。
-
另一个考虑因素是你可用的时间。
技巧和窍门[1:21:40]
1.Tab — 当你记不住函数名时,它会自动完成
2. Shift + Tab — 它会显示函数的参数

3. Shift + Tab + Tab — 它会显示文档(即 docstring)

4. Shift + Tab + Tab + Tab — 它会打开一个带有相同信息的单独窗口。
在单元格中键入?后跟一个函数名并运行它将与shift + tab(3 次)相同
5. 输入两个问号将显示源代码

6. 在 Jupyter Notebook 中键入H将打开一个带有键盘快捷键的窗口。尝试每天学习 4 或 5 个快捷键
7. 停止 Paperspace、Crestle、AWS — 否则你将被收费$$
8. 请记住关于论坛和course.fast.ai/(每节课)的最新信息。
深度学习 2:第 1 部分第 2 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-2-eeae2edd2be4译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
第 2 课
笔记本
上一课的回顾[01:02]
-
我们用 3 行代码构建了一个图像分类器。
-
为了训练模型,数据需要以一定方式组织在
PATH(在本例中为data/dogscats/)下:
-
应该有一个
train文件夹和一个valid文件夹,每个文件夹下面都有带有分类标签的文件夹(例如本例中的cats和dogs),其中包含相应的图像。 -
训练输出:[
*epoch #*,**training loss*,*validation loss*,*accuracy*]
'''
[ 0\. 0.04955 0.02605 0.98975]
'''
学习率[4:54]
-
学习率的基本思想是它将决定我们快速地聚焦在解决方案上。

-
如果学习率太小,将需要很长时间才能到达底部
-
如果学习率太大,它可能会从底部摆动。
-
学习率查找器(
learn.lr_find)会在每个小批次后增加学习率。最终,学习率会变得太高,损失会变得更糟。然后,我们查看学习率与损失的图表,并确定最低点,然后后退一个数量级,并选择该学习率(在下面的示例中为1e-2)。 -
小批量是我们每次查看的几个图像,以便有效地利用 GPU 的并行处理能力(通常每次 64 或 128 个图像)。
-
在 Python 中:



-
通过调整这个数字,您应该能够获得相当不错的结果。fast.ai 库会为您选择其余的超参数。但随着课程的进行,我们将学习到一些更多的可以调整以获得稍微更好结果的东西。但学习率对我们来说是关键数字。
-
学习率查找器位于其他优化器(例如动量、Adam 等)之上,并帮助您选择最佳学习率,考虑您正在使用的其他调整(例如高级优化器但不限于优化器)。
-
问题:在 epoch 期间改变学习率的优化器会发生什么?这个查找器是否选择了初始学习率?[14:05] 我们稍后会详细了解优化器,但基本答案是否定的。即使是 Adam 也有一个学习率,该学习率会被平均先前梯度和最近平方梯度的总和除以。即使那些所谓的“动态学习率”方法也有学习率。
-
使模型更好的最重要的事情是提供更多数据。由于这些模型有数百万个参数,如果您训练它们一段时间,它们开始做所谓的“过拟合”。
-
过拟合 - 模型开始看到训练集中图像的具体细节,而不是学习一些可以转移到验证集的通用内容。
-
我们可以收集更多数据,但另一种简单的方法是数据增强。
数据增强[15:50]

-
每个 epoch,我们会随机微调图像。换句话说,模型每个 epoch 都会看到图像的略微不同版本。
-
您希望为不同类型的图像使用不同类型的数据增强(水平翻转、垂直翻转、放大、缩小、变化对比度和亮度等)。
学习率查找问题:
-
为什么不选择最低点?损失最低的点是红色圆圈所在的位置。但是在那一点学习率实际上太大了,不太可能收敛。因此,前一个点可能是更好的选择(总是选择比太大的学习率更小的学习率更好)

-
何时学习
lr_find?在开始时运行一次,也许在解冻层之后再运行(我们稍后会学习)。还有当我改变我正在训练的东西或改变我训练的方式时。运行它永远不会有害。
回到数据增强:
tfms = tfms_from_model(resnet34, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
-
transform_side_on- 用于侧面照片的预定义转换集(还有transform_top_down)。稍后我们将学习如何创建自定义转换列表。 -
这并不是在创建新数据,而是让卷积神经网络学习如何从略有不同的角度识别猫或狗。
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
learn = ConvLearner.pretrained(arch, data, precompute=True)learn.fit(1e-2, 1)
-
现在我们创建了一个包含增强的新
data对象。最初,由于precompute=True,增强实际上什么也没做。 -
卷积神经网络有这些称为“激活”的东西。激活是一个数字,表示“这个特征在这个位置以这个置信度(概率)”。我们正在使用一个已经学会识别特征的预训练网络(即我们不想改变它学到的超参数),所以我们可以预先计算隐藏层的激活,然后只训练最终的线性部分。

-
这就是为什么当你第一次训练模型时,需要更长时间 - 它正在预计算这些激活。
-
尽管我们每次都试图展示猫的不同版本,但我们已经为特定版本的猫预先计算了激活(即我们没有使用改变后的版本重新计算激活)。
-
要使用数据增强,我们必须执行
learn.precompute=False:
learn.precompute=Falselearn.fit(1e-2, 3, cycle_len=1)
'''
[ 0\. 0.03597 0.01879 0.99365]
[ 1\. 0.02605 0.01836 0.99365]
[ 2\. 0.02189 0.0196 0.99316]
'''
-
坏消息是准确性没有提高。训练损失在减少,但验证损失没有,但我们没有过拟合。过拟合是指训练损失远低于验证损失。换句话说,当你的模型在训练集上表现比在验证集上好得多时,这意味着你的模型没有泛化。
-
cycle_len=1:这使得**随机梯度下降重启(SGDR)**成为可能。基本思想是,当你越来越接近具有最小损失的位置时,你可能希望开始减小学习率(采取更小的步骤)以确切地到达正确的位置。 -
在训练过程中降低学习率的想法被称为学习率退火,这是非常常见的。最常见和“hacky”方法是使用某个学习率训练模型一段时间,当它停止改进时,手动降低学习率(分阶段退火)。
-
更好的方法是简单地选择某种功能形式 - 结果表明,真正好的功能形式是余弦曲线的一半,它在开始时保持高学习率,然后在接近时迅速下降。

-
然而,我们可能发现自己处于一个不太有弹性的权重空间中 - 也就是说,对权重进行微小的更改可能导致损失的巨大变化。我们希望鼓励我们的模型找到既准确又稳定的权重空间的部分。因此,我们不时增加学习率(这是“SGDR”中的“重启”),这将迫使模型跳到权重空间的不同部分,如果当前区域“尖锐”。如果我们三次重置学习率,它可能看起来像这样(在这篇论文中,他们称之为“循环 LR 计划”):

-
重置学习率之间的周期数由
cycle_len设置,这种情况下发生的次数被称为周期数,实际上是我们作为fit()的第二个参数传递的内容。这是我们实际学习率的样子:
-
问题:我们可以通过使用随机起始点获得相同的效果吗?在创建 SGDR 之前,人们通常会创建“集成”,他们会重新学习一个全新的模型十次,希望其中一个会变得更好。在 SGDR 中,一旦我们接近最佳和稳定区域,重置实际上不会“重置”,而是权重保持更好。因此,SGDR 将比随机尝试几个不同的起始点给出更好的结果。
-
选择一个学习率(这是 SGDR 使用的最高学习率)很重要,它足够大,可以使重置跳转到函数的不同部分。
-
SGDR 会在每个小批次中降低学习率,并且重置每个
cycle_len周期(在这种情况下设置为 1)。 -
问题:我们的主要目标是泛化,而不是陷入狭窄的最优解。在这种方法中,我们是否跟踪最小值并对其进行平均处理并集成它们?这是另一种复杂程度,您可以在图表中看到“快照集成”。我们目前没有这样做,但如果您希望泛化得更好,可以在重置之前保存权重并取平均值。但目前,我们只会选择最后一个。
-
如果您想要跳过,还有一个名为
cycle_save_name的参数,您可以添加它以及cycle_len,它将在每个学习率周期结束时保存一组权重,然后您可以将它们集成。
保存模型
learn.save('224_lastlayer')
learn.load('224_lastlayer')
-
当您预计算激活或创建调整大小的图像(我们将很快学习到),会创建各种临时文件,您可以在
data/dogcats/tmp文件夹下看到。如果出现奇怪的错误,可能是因为预计算的激活只完成了一半,或者以某种方式与您正在进行的操作不兼容。因此,您可以随时继续并删除此/tmp文件夹,看看是否可以消除错误(相当于将其关闭然后重新打开)。 -
您还会看到一个名为
/models的目录,这是当您说learn.save时保存模型的位置。
微调和差分学习率
-
到目前为止,我们还没有重新训练任何预训练的特征 - 具体来说,卷积核中的任何权重。我们所做的只是在顶部添加了一些新层,并学会了如何混合和匹配预训练的特征。
-
像卫星图像、CT 扫描等图像具有完全不同类型的特征(与 ImageNet 图像相比),因此您需要重新训练许多层。
-
对于狗和猫,图像与模型预先训练的图像相似,但我们仍然可能发现微调一些后续层会有所帮助。
-
这是如何告诉学习者我们要开始实际更改卷积滤波器本身的方法:
learn.unfreeze()
-
“冻结”层是一个未被训练/更新的层。
unfreeze会解冻所有层。 -
像第一层(检测对角边缘或梯度)或第二层(识别角落或曲线)这样的早期层可能根本不需要或只需要很少的更改。
-
后续层更有可能需要更多的学习。因此,我们创建了一个学习率数组(差分学习率):
lr=np.array([1e-4,1e-3,1e-2])
-
1e-4:用于前几层(基本几何特征) -
1e-3:用于中间层(复杂的卷积特征) -
1e-2:用于我们添加的顶部层 -
为什么是 3?实际上它们是 3 个 ResNet 块,但现在,可以将其视为一组层。
问题:如果我的图片比模型训练的图片大怎么办?简短的答案是,使用这个库和我们正在使用的现代架构,我们可以使用任何大小的图片。
问题:我们可以只解冻特定的层吗?我们还没有这样做,但如果你想的话,你可以使用learn.unfreeze_to(n)(这将从第n层开始解冻层)。Jeremy 几乎从来没有发现这有帮助,他认为这是因为我们使用了不同的学习率,优化器可以学习到它需要的一样多。他发现有帮助的一个地方是,如果他使用一个真正大的内存密集型模型,而且他的 GPU 快要用完了,你解冻的层数越少,占用的内存和时间就越少。
使用不同的学习率,我们的准确率达到了 99.5%!
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
'''
[ 0\. 0.04538 0.01965 0.99268]
[ 1\. 0.03385 0.01807 0.99268]
[ 2\. 0.03194 0.01714 0.99316]
[ 3\. 0.0358 0.0166 0.99463]
[ 4\. 0.02157 0.01504 0.99463]
[ 5\. 0.0196 0.0151 0.99512]
[ 6\. 0.01356 0.01518 0.9956 ]
'''
-
之前我们说
3是周期的数量,但实际上是周期。所以如果cycle_len=2,它将执行 3 个周期,每个周期为 2 个周期(即 6 个周期)。那为什么是 7 个?这是因为cycle_mult。 -
cycle_mult=2:这会在每个周期后乘以周期的长度(1 个周期+2 个周期+4 个周期=7 个周期)。
直观地说,如果周期长度太短,它开始下降寻找一个好的位置,然后弹出,再次下降寻找一个好的位置,然后弹出,永远无法找到一个好的位置。在早期,你希望它这样做,因为它试图找到一个更平滑的位置,但后来,你希望它做更多的探索。这就是为什么cycle_mult=2似乎是一个好方法。
我们正在引入越来越多的超参数,告诉你没有很多。你可以只选择一个好的学习率,但添加这些额外的调整可以在不费力的情况下获得额外的提升。一般来说,好的起点是:
-
n_cycle=3,cycle_len=1,cycle_mult=2 -
n_cycle=3,cycle_len=2(没有cycle_mult)
问题:为什么更平滑的表面与更广义的网络相关?

假设你有一个尖锐的东西(蓝线)。X 轴显示了当你改变这个特定参数时,它在识别狗和猫方面的表现如何。可泛化意味着当我们给它一个略微不同的数据集时,我们希望它能够工作。略微不同的数据集可能在这个参数和猫狗之间的关系上有略微不同。它可能看起来像红线。换句话说,如果我们最终到达蓝色尖锐部分,那么它在这个略微不同的数据集上不会表现良好。或者,如果我们最终到达较宽的蓝色部分,它仍然会在红色数据集上表现良好。
- 这里有一些关于峰值最小值的有趣讨论。
测试时间增强(TTA)
我们的模型已经达到了 99.5%。但我们还能让它变得更好吗?让我们看看我们错误预测的图片:
在这里,Jeremy 打印出了所有这些图片。当我们进行验证集时,我们模型的所有输入必须是正方形的。原因有点小的技术细节,但如果不同的图片有不同的尺寸,GPU 不会很快。它需要保持一致,以便 GPU 的每个部分都可以做同样的事情。这可能是可以解决的,但目前这是我们拥有的技术状态。
为了使它成为正方形,我们只需挑选中间的正方形——正如你所看到的,可以理解为什么这张图片被错误分类:

我们将进行所谓的“测试时间增强”。这意味着我们将随机进行 4 次数据增强,以及未增强的原始图像(中心裁剪)。然后我们将为所有这些图像计算预测,取平均值,并将其作为我们的最终预测。请注意,这仅适用于验证集和/或测试集。
要做到这一点,您只需learn.TTA()——这将将准确性提高到 99.65%!
log_preds,y = learn.TTA()
probs = np.mean(np.exp(log_preds),0)
accuracy(probs, y)
'''
0.99650000000000005
'''
关于增强方法的问题[01:01:36]:为什么不使用边框或填充使其变成正方形?通常 Jeremy 不会做太多填充,而是会做一点缩放。有一种叫做反射填充的东西在卫星图像中效果很好。一般来说,使用 TTA 加数据增强,最好的做法是尽可能使用尽可能大的图像。此外,固定裁剪位置加上随机对比度、亮度、旋转变化可能对 TTA 更好。
问题:非图像数据集的数据增强?[01:03:35] 没有人似乎知道。看起来会有帮助,但例子很少。在自然语言处理中,人们尝试替换同义词,但总体来说,这个领域研究不足,发展不足。
问题:fast.ai 库是开源的吗?[01:05:34] 是的。然后他讲解了Fast.ai 从 Keras + TensorFlow 切换到 PyTorch 的原因
随机笔记:PyTorch 不仅仅是一个深度学习库。它实际上让我们可以从头开始编写任意 GPU 加速的算法——Pyro 是人们现在在 PyTorch 之外进行的一个很好的例子。
分析结果[01:11:50]
混淆矩阵
分类结果的简单查看方式称为混淆矩阵——不仅用于深度学习,而且用于任何类型的机器学习分类器。如果你试图预测四五类,特别有帮助,可以看出你在哪个组别遇到了最大的困难。

preds = np.argmax(probs, axis=1)
probs = probs[:,1]
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, preds)
plot_confusion_matrix(cm, data.classes)
让我们再次看看图片[01:13:00]
大多数错误的猫(只有左边两个是错误的——默认显示 4 个):

大多数错误的点:

回顾:训练世界一流的图像分类器的简单步骤[01:14:09]
-
启用数据增强,
precompute=True -
使用
lr_find()找到损失仍然明显改善的最高学习率 -
从预计算的激活中训练最后一层 1-2 个时期
-
使用数据增强训练最后一层(即
precompute=False)2-3 个时期,cycle_len=1 -
解冻所有层
-
将前面的层设置为比下一层低 3 倍至 10 倍的学习率。经验法则:ImageNet 类似的图像为 10 倍,卫星或医学成像为 3 倍
-
再次使用
lr_find()(注意:如果您设置了不同的学习率并调用lr_find,它打印出的是最后几层的学习率。) -
使用
cycle_mult=2训练完整网络直到过拟合
让我们再做一次:狗品种挑战 [01:16:37]
-
您可以使用Kaggle CLI下载 Kaggle 竞赛的数据
-
笔记本没有公开,因为它是一个活跃的竞赛
%reload_ext autoreload
%autoreload 2
%matplotlib inlinefrom fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
PATH = 'data/dogbreed/'
sz = 224
arch = resnext101_64
bs=16
label_csv = f'{PATH}labels.csv'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
!ls {PATH}

这与我们以前的数据集有点不同。它没有一个包含每个狗品种的单独文件夹的train文件夹,而是有一个带有正确标签的 CSV 文件。我们将使用 Pandas 读取 CSV 文件。Pandas 是我们在 Python 中用来进行结构化数据分析的工具,比如 CSV,通常被导入为pd:
label_df = pd.read_csv(label_csv)
label_df.head()

label_df.pivot_table(index='breed', aggfunc=len).sort_values('id', ascending=False)

每个品种有多少狗图像
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on,
max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train',
f'{PATH}labels.csv', test_name='test',
val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
-
max_zoom——我们将放大 1.1 倍 -
ImageClassifierData.from_csv— 上次我们使用了from_paths,但由于标签在 CSV 文件中,我们将使用from_csv。 -
test_name— 如果要提交到 Kaggle 比赛,我们需要指定测试集的位置 -
val_idx— 没有validation文件夹,但我们仍然想要跟踪我们的本地表现有多好。因此你会看到上面的:
n = len(list(open(label_csv)))-1:打开 CSV 文件,创建一个行列表,然后取长度。 -1是因为第一行是标题。因此n是我们拥有的图像数量。
val_idxs = **get_cv_idxs**(n): “获取交叉验证索引” — 默认情况下,这将返回随机 20%的行(确切的索引)作为验证集。你也可以发送val_pct以获得不同的数量。

suffix='.jpg'— 文件名以.jpg结尾,但 CSV 文件没有。因此我们将设置suffix以便它知道完整的文件名。
fn = PATH + data.trn_ds.fnames[0]; fn
'''
'data/dogbreed/train/001513dfcb2ffafc82cccf4d8bbaba97.jpg'
'''
- 你可以通过说
data.trn_ds来访问训练数据集,trn_ds包含很多东西,包括文件名(fnames)
img = PIL.Image.open(fn); img

img.size
'''
(500, 375)
'''
- 现在我们检查图像大小。如果它们很大,那么你必须非常仔细地考虑如何处理它们。如果它们很小,也是具有挑战性的。大多数 ImageNet 模型都是在 224x224 或 299x299 的图像上训练的
size_d = {k: PIL.Image.open(PATH+k).size for k in data.trn_ds.fnames}
- 字典推导 —
键: 文件名,值: 文件大小
row_sz, col_sz = list(zip(*size_d.values()))
*size_d.values()将解压缩一个列表。zip将元组的元素配对以创建一个元组列表。
plt.hist(row_sz);

行的直方图
- 如果你在 Python 中进行任何数据科学或机器学习,Matplotlib 是你想要非常熟悉的东西。Matplotlib 总是被称为
plt。
问题:我们应该使用多少图像作为验证集?[01:26:28] 使用 20%是可以的,除非数据集很小 — 那么 20%就不够了。如果你多次训练相同的模型并且得到非常不同的验证集结果,那么你的验证集太小了。如果验证集小于一千,很难解释你的表现如何。如果你关心准确度的第三位小数,并且验证集中只有一千个数据,一个图像的变化就会改变准确度。如果你关心 0.01 和 0.02 之间的差异,你希望这代表 10 或 20 行。通常 20%似乎效果不错。
def get_data(sz, bs):
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on,
max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train',
f'{PATH}labels.csv', test_name='test', num_workers=4,
val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs) return data if sz>300 else data.resize(340, 'tmp')
- 这是常规的两行代码。当我们开始使用新数据集时,我们希望一切都能快速进行。因此,我们可以指定大小并从 64 开始,这样会运行得更快。稍后,我们将使用更大的图像和更大的架构,到那时,你可能会耗尽 GPU 内存。如果你看到 CUDA 内存不足错误,你需要做的第一件事是重新启动内核(你无法从中恢复),然后减小批量大小。
data = get_data(224, bs)
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(1e-2, 5)
'''
[0\. 1.99245 1.0733 0.76178]
[1\. 1.09107 0.7014 0.8181 ]
[2\. 0.80813 0.60066 0.82148]
[3\. 0.66967 0.55302 0.83125]
[4\. 0.57405 0.52974 0.83564]
'''
- 对于 120 个类别来说,83%是相当不错的。
learn.precompute = False
learn.fit(1e-2, 5, cycle_len=1)
- 提醒:一个
epoch是对数据的一次遍历,一个cycle是你说一个周期中有多少个 epoch
learn.save('224_pre')
learn.load('224_pre')
增加图像大小 [1:32:55]
learn.set_data(get_data(299, bs))
- 如果你在较小尺寸的图像上训练了一个模型,然后可以调用
learn.set_data并传入一个更大尺寸的数据集。这将采用到目前为止已经训练过的模型,并让你继续在更大的图像上训练。
从小图像开始训练几个时期,然后切换到更大的图像,并继续训练是一个非常有效的避免过拟合的方法。
learn.fit(1e-2, 3, cycle_len=1)
'''
[0\. 0.35614 0.22239 0.93018]
[1\. 0.28341 0.2274 0.92627]
[2\.* *0.28341**0.2274* *0.92627]
'''
- 如你所见,验证集损失(0.2274)远低于训练集损失(0.28341) — 这意味着它是欠拟合。当你欠拟合时,意味着
cycle_len=1太短了(学习率在适当缩小之前被重置)。所以我们将添加cycle_mult=2(即第一个周期是 1 个时期,第二个周期是 2 个时期,第三个周期是 4 个时期)
learn.fit(1e-2, 3, cycle_len=1, cycle_mult=2)
'''
[0\. 0.27171 0.2118 0.93192]
[1\. 0.28743 0.21008 0.9324 ]
[2\. 0.25328 0.20953 0.93288]
[3\. 0.23716 0.20868 0.93001]
[4\. 0.23306 0.20557 0.93384]
[5\. 0.22175 0.205 0.9324 ]
[6\. 0.2067 0.20275 0.9348 ]
- 现在验证损失和训练损失大致相同 — 这是正确的轨道。然后我们尝试
TTA:
log_preds, y = learn.TTA()
probs = np.exp(log_preds)
accuracy(log_preds,y), metrics.log_loss(y, probs)
'''
(0.9393346379647749, 0.20101565705592733)
'''
其他尝试:
-
尝试再运行一个 2 个时期的周期
-
解冻(在这种情况下,训练卷积层根本没有帮助,因为图像实际上来自 ImageNet)
-
删除验证集,只需重新运行相同的步骤,并提交 - 这样我们可以使用 100%的数据。
问题:我们如何处理不平衡的数据集?[01:38:46]这个数据集不是完全平衡的(在 60 和 100 之间),但不够不平衡,以至于 Jeremy 不会再考虑。最近的一篇论文说,处理非常不平衡的数据集的最佳方法是复制罕见情况。
问题:precompute=True和unfreeze之间的区别?
-
我们从预训练网络开始
-
我们在其末尾添加了几层,这些层最初是随机的。当所有内容都被冻结且
precompute=True时,我们学到的只是我们添加的层。 -
使用
precompute=True,数据增强不起作用,因为每次显示的激活完全相同。 -
然后我们将
precompute=False设置为假,这意味着我们仍然只训练我们添加的层,因为它被冻结,但数据增强现在正在工作,因为它实际上正在重新计算所有激活。 -
最后,我们解冻,这意味着“好的,现在您可以继续更改所有这些早期卷积滤波器”。
问题:为什么不从一开始就将precompute=False设置为假?将precompute=True的唯一原因是它速度更快(快 10 倍或更多)。如果您正在处理相当大的数据集,它可以节省相当多的时间。从来没有理由使用precompute=True来提高准确性。
获得良好结果的最小步骤:
-
使用
lr_find()找到损失仍然明显改善的最高学习率 -
使用数据增强(即
precompute=False)训练最后一层 2-3 个周期,cycle_len=1 -
解冻所有层
-
将较早的层设置为比下一层更高的层次低 3 倍至 10 倍的学习率
-
使用
cycle_mult=2训练完整网络直到过拟合
问题:减少批量大小只影响训练速度吗?[1:43:34]是的,基本上是这样。如果每次显示的图像较少,则使用较少的图像计算梯度 - 因此准确性较低。换句话说,知道要走哪个方向以及在该方向上走多远的准确性较低。因此,随着批量大小变小,它变得更加不稳定。它会影响您需要使用的最佳学习率,但实际上,将批量大小除以 2 与除以 4 似乎并没有太大变化。如果更改批量大小很大,可以重新运行学习率查找器进行检查。
问题:灰色图像与右侧图像之间有什么区别?

可视化和理解卷积网络
第一层,它们确实是滤波器的样子。很容易可视化,因为输入是像素。后来,变得更难,因为输入本身是激活,是激活的组合。Zeiler 和 Fergus 提出了一种聪明的技术,展示滤波器平均倾向于什么样子 - 称为反卷积(我们将在第 2 部分学习)。右侧是激活该滤波器的图像块的示例。
问题:如果狗在角落或很小,你会怎么做(关于狗品种识别)?[01:47:16]我们将在第 2 部分学习,但有一种技术可以让您大致确定图像的哪些部分最有趣。然后您可以裁剪出该区域。
进一步改进[01:48:16]
立即可以做两件事来使其更好:
-
假设您使用的图像大小小于您所获得的图像的平均大小,您可以增加大小。正如我们之前所看到的,您可以在训练期间增加它。
-
使用更好的架构。有不同的方法来组合卷积滤波器的大小以及它们如何连接在一起,不同的架构具有不同数量的层,内核大小,滤波器等。
我们一直在使用 ResNet34 — 一个很好的起点,通常也是一个很好的终点,因为它没有太多参数,并且在小数据集上表现良好。还有另一种架构叫做 ResNext,它是去年 ImageNet 比赛的第二名。ResNext50 的训练时间是 ResNet34 的两倍,内存使用量是其 2-4 倍。
这里是几乎与原始狗和猫相同的笔记本。使用了 ResNext50,实现了 99.75%的准确率。
卫星图像 [01:53:01]

笔记本
代码基本与之前看到的相同。以下是一些不同之处:
-
transforms_top_down— 由于它们是卫星图像,所以在垂直翻转时仍然有意义。 -
学习率更高 — 与这个特定数据集有关
-
lrs = np.array([lr/9,lr/3,lr])— 差异学习率现在变为 3 倍,因为图像与 ImageNet 图像非常不同 -
sz=64— 这有助于避免卫星图像的过拟合,但对于狗和猫或狗品种(与 ImageNet 相似的图像)他不会这样做,因为 64x64 相当小,可能会破坏预训练权重。
如何设置您的 AWS [01:58:54]
您可以跟着视频或这里是一位学生写的很好的文章。
深度学习 2:第 1 部分第 3 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-3-74b0ef79e56译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
第 3 课
学生们制作的有用材料:
-
AWS 如何操作
-
Tmux
-
第 2 课总结
-
学习率查找器
-
PyTorch
-
学习率与批量大小
-
错误表面的平滑区域与泛化
-
5 分钟内的卷积神经网络
-
解码 ResNet 架构
-
又一个 ResNet 教程
我们接下来要做什么:

回顾[08:24]:
Kaggle CLI:如何下载数据 1:
Kaggle CLI是从 Kaggle 下载时使用的好工具。因为它是通过屏幕抓取从 Kaggle 网站下载数据,当网站更改时会中断。当发生这种情况时,运行pip install kaggle-cli --upgrade。
然后您可以运行:
$ kg download -u <username> -p <password> -c <competition>
用您的凭据替换<username>,<password>,<competition>是 URL 中/c/后面的内容。例如,如果您想从https://www.kaggle.com**/c/**dog-breed-identification下载狗品种数据,命令将如下所示:
$ kg download -u john.doe -p mypassword -c dog-breed-identification
确保您已经从计算机上点击了下载按钮并接受了规则:

CurWget(Chrome 扩展程序):如何下载数据 2:

快速狗与猫[13:39]
from fastai.conv_learner import *
PATH = 'data/dogscats/'
sz=224; bs=64
通常笔记本假设您的数据在data文件夹中。但也许您想把它们放在其他地方。在这种情况下,您可以使用符号链接(简称 symlink):

以下是一个端到端的过程,用于获得狗与猫的最新结果:

快速狗与猫
稍微进一步的分析:
data = ImageClassifierData.from_paths(PATH, tfms= tfms, bs=bs, test_name='test')
-
from_paths:表示子文件夹名称是标签。如果您的train文件夹或valid文件夹有不同的名称,您可以发送trn_name和val_name参数。 -
test_name:如果您想提交到 Kaggle 竞赛,您需要填写测试集所在文件夹的名称。
learn = ConvLearner.pretrained(resnet50, data)
-
请注意,我们没有设置
pre_compue=True。这只是一个快捷方式,可以缓存一些中间步骤,这些步骤不必每次重新计算。如果您对此感到困惑,可以将其留空。 -
请记住,当
pre_compute=True时,数据增强不起作用。
learn.unfreeze()
learn.bn_freeze(True)
%time learn.fit([1e-5, 1e-4,1e-2], 1, cycle_len=1)
bn_freeze:如果您正在使用更大更深的模型,如 ResNet50 或 ResNext101(任何数字大于 34 的模型),在一个与 ImageNet 非常相似的数据集上(即侧面拍摄的标准物体的照片,其大小与 ImageNet 在 200-500 像素之间),您应该添加这一行。我们将在课程的后半部分学到更多,但这会导致批量归一化移动平均值不会被更新。
如何使用其他库 — Keras [20:02]
了解如何使用 Fast.ai 以外的库是很重要的。Keras 是一个很好的例子,因为就像 Fast.ai 建立在 PyTorch 之上一样,它也建立在各种库之上,如 TensorFlow、MXNet、CNTK 等。
如果您想运行笔记本,运行pip install tensorflow-gpu keras
- 定义数据生成器
train_data_dir = f'{PATH}train'
validation_data_dir = f'{PATH}valid'
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(sz, sz),
batch_size=batch_size,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
shuffle=False,
target_size=(sz, sz),
batch_size=batch_size,
class_mode='binary'
)
-
训练文件夹和验证文件夹的子文件夹与标签名称的想法是常见的,Keras 也这样做。
-
Keras 需要更多的代码和更多的参数来设置。
-
与创建单个数据对象不同,在 Keras 中,您定义
DataGenerator并指定要进行的数据增强类型,还要指定要进行的规范化类型。换句话说,在 Fast.ai 中,我们可以说“ResNet50 需要什么,就请为我做”,但在 Keras 中,您需要知道期望的是什么。没有标准的增强集。 -
然后您必须创建一个验证数据生成器,您负责创建一个没有数据增强的生成器。您还必须告诉它不要对验证数据集进行洗牌,否则您无法跟踪您的表现如何。
2. 创建模型
base_model = ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x)
-
Jeremy 在 Quick Dogs and Cats 中使用 ResNet50 的原因是因为 Keras 没有 ResNet34。我们想要进行苹果对苹果的比较。
-
您不能要求它构建适合特定数据集的模型,因此您必须手动完成。
-
首先创建一个基本模型,然后构建您想要添加到其顶部的层。
3. 冻结层并编译
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = Falsemodel.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
-
通过循环层并手动调用
layer.trainable=False来冻结它们 -
您需要编译一个模型
-
传递优化器、损失和指标的类型
4. 拟合
model.fit_generator(
train_generator,
train_generator.n//batch_size,
epochs=3,
workers=4,
validation_data=validation_generator,
validation_steps=validation_generator.n // batch_size
)
-
Keras 希望知道每个 epoch 有多少批次。
-
workers:要使用的处理器数量
5. 微调:解冻一些层,编译,然后再次拟合
split_at = 140
for layer in model.layers[:split_at]:
layer.trainable = False
for layer in model.layers[split_at:]:
layer.trainable = True
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']
)
%%time model.fit_generator(
train_generator,
train_generator.n // batch_size,
epochs=1,
workers=3,
validation_data=validation_generator,
validation_steps=validation_generator.n // batch_size
)
Pytorch — 如果您想要部署到移动设备,PyTorch 仍处于早期阶段。
Tensorflow — 如果您想将在本课程中学到的内容转换为更多的 Keras 工作,但这需要更多的工作,很难获得相同水平的结果。也许将来会有 TensorFlow 兼容版本的 Fast.ai。我们将看到。
为 Kaggle 创建提交文件[32:45]
要创建提交文件,我们需要两个信息:
-
data.classes:包含所有不同的类 -
data.test_ds.fnames:测试文件名
log_preds, y = learn.TTA(is_test=True)
probs = np.exp(log_preds)
始终使用TTA是一个好主意:
-
is_test=True:它将为您提供测试集的预测,而不是验证集 -
默认情况下,PyTorch 模型将返回预测的对数,因此您需要执行
np.exp(log_preds)以获得概率。
ds = pd.DataFrame(probs)
ds.columns = data.classes
-
创建 Pandas
DataFrame -
将列名设置为
data.classes
ds.insert(0, 'id', [o[5:-4] for o in data.test_ds.fnames])
- 在位置零插入一个名为
id的新列。删除前 5 个和最后 4 个字母,因为我们只需要 ID(文件名看起来像test/0042d6bf3e5f3700865886db32689436.jpg)
ds.head()

SUBM = f'{PATH}sub/'
os.makedirs(SUBM, exist_ok=True)
ds.to_csv(f'{SUBM}subm.gz', compression='gzip', index=False)
- 现在您可以调用
ds.to_csv创建一个 CSV 文件,compression='gzip'将在服务器上对其进行压缩。
FileLink(f'{SUBM}subm.gz')
- 您可以使用 Kaggle CLI 直接从服务器提交,或者您可以使用
FileLink,它将为您提供一个链接,从服务器下载文件到您的计算机。
单个预测[39:32]
如果我们想通过模型运行单个图像以获得预测,会怎样?
fn = data.val_ds.fnames[0]; fn
'''
'train/001513dfcb2ffafc82cccf4d8bbaba97.jpg'
'''
Image.open(PATH + fn)

- 我们将从验证集中选择第一个文件。
这是获得预测的最简单方法:
trn_tfms, val_tfms = tfms_from_model(arch, sz)
im = val_tfms(Image.open(PATH+fn))
preds = learn.predict_array(im[None])
np.argmax(preds)
-
图像必须被转换。
tfms_from_model返回训练转换和验证转换。在这种情况下,我们将使用验证转换。 -
传递给模型或从模型返回的所有内容通常被假定为在一个小批次中。这里我们只有一张图片,但我们必须将其转换为一批包含一张图片的小批次。换句话说,我们需要创建一个张量,不仅是
[行,列,通道],而是[图片数量,行,列,通道]。 -
im[None]:Numpy 技巧,将额外的单位轴添加到开头。
理论:卷积神经网络背后实际发生了什么[42:17]
-
我们在第 1 课中看到了一点理论 —
setosa.io/ev/image-kernels/ -
卷积是一种操作,其中我们有一个小矩阵(在深度学习中几乎总是 3x3),将该矩阵的每个元素与图像的 3x3 部分的每个元素相乘,然后将它们全部加在一起,以获得在一个点上的卷积结果。
Otavio 的出色可视化(他创建了 Word Lens):
youtu.be/Oqm9vsf_hvU
Jeremy 的可视化: 电子表格 [49:51]

我使用office.live.com/start/Excel.aspx
-
这些数据来自 MNIST
-
激活: 通过对输入中的一些数字应用某种线性操作来计算的数字。
-
修正线性单元(ReLU):丢弃负数 — 即 MAX(0, x)
-
滤波器/卷积核: 用于卷积的 3D 张量的 3x3 切片
-
张量: 多维数组或矩阵 隐藏层 既不是输入也不是输出的层
-
最大池化: (2,2)最大池化将在高度和宽度上减半 — 将其视为一个摘要
-
全连接层: 为每个激活赋予权重并计算总乘积。权重矩阵与整个输入一样大。
-
注意:在最大池化层之后可以做许多事情。其中之一是在整个大小上再做一次最大池化。在旧的架构或结构化数据中,我们会做全连接层。大量使用全连接层的架构容易过拟合且速度较慢。ResNet 和 ResNext 不使用非常大的全连接层。
问题:如果输入有 3 个通道会发生什么?[1:05:30] 它将看起来类似于具有 2 个通道的 Conv1 层 — 因此,滤波器每个滤波器有 2 个通道。预训练的 ImageNet 模型使用 3 个通道。当你的通道少于 3 个时,你可以使用一些技术,例如复制一个通道使其变为 3 个,或者如果你有 2 个通道,那么取平均值并将其视为第三个通道。如果你有 4 个通道,你可以向卷积核添加额外的级别,所有值都为零。
接下来会发生什么?[1:08:47]
我们已经走到了全连接层(它执行经典的矩阵乘积)。在 Excel 表中,有一个激活。如果我们想要查看输入是哪一个十位数,我们实际上想要计算 10 个数字。
让我们看一个例子,我们试图预测一张图片是猫、狗、飞机、鱼还是建筑物。我们的目标是:
-
从全连接层获取输出(没有 ReLU,因此可能有负数)
-
计算 5 个数字,每个数字都在 0 和 1 之间,它们加起来等于 1。
为此,我们需要一种不同类型的激活函数(应用于激活的函数)。
为什么我们需要非线性?如果堆叠多个线性层,它仍然只是一个线性层。通过添加非线性层,我们可以拟合任意复杂的形状。我们使用的非线性激活函数是 ReLU。
Softmax [01:14:08]
Softmax 只会出现在最后一层。它输出介于 0 和 1 之间的数字,它们加起来为 1。理论上,这并不是绝对必要的 - 我们可以要求我们的神经网络学习一组核,这些核给出的概率尽可能接近我们想要的。一般来说,在深度学习中,如果你可以构建你的架构,使得所需的特征尽可能容易表达,你将得到更好的模型(学习更快,参数更少)。

- 通过
e^x去除负数,因为我们不能有负概率。它也突出了值的差异(2.85:4.08 → 17.25:59.03)
所有你需要熟悉的数学来进行深度学习:

- 然后我们将
exp列(182.75)相加,然后将e^x除以总和。结果总是正的,因为我们将正数除以正数。每个数字将在 0 和 1 之间,总和为 1。
问题:如果我们想要将图片分类为猫和狗,我们应该使用什么样的激活函数?这正好是我们现在要做的事情。我们可能想这样做的一个原因是进行多标签分类。
星球竞赛[01:20:54]
笔记本 / Kaggle 页面
我绝对建议你拟人化你的激活函数。它们有个性。[1:22:21]
Softmax 不喜欢预测多个事物。它想要选择一个事物。
Fast.ai 库会在有多个标签时自动切换到多标签模式。所以你不需要做任何事情。但是这是幕后发生的事情:
from planet import f2
metrics=[f2]
f_model = resnet34label_csv = f'**{PATH}**train_v2.csv'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
def get_data(sz):
tfms = tfms_from_model(
f_model, sz,
aug_tfms=transforms_top_down,
max_zoom=1.05
)
return ImageClassifierData.from_csv(
PATH,
'train-jpg',
label_csv,
tfms=tfms,
suffix='.jpg',
val_idxs=val_idxs,
test_name='test-jpg'
)
data = get_data(256)
-
使用 Keras 风格的方法无法进行多标签分类,其中子文件夹是标签的名称。所以我们使用
from_csv -
transform_top_down:它不仅仅是垂直翻转。对于一个正方形,有 8 种可能的对称性 - 它可以通过 0、90、180、270 度旋转,对于每一个,它可以被翻转(八面体群)。
x,y = next(iter(data.val_dl))
-
我们已经看到了
data.val_ds,test_ds,train_ds(ds:数据集),你可以通过data.train_ds[0]来获取单个图像,例如。 -
dl是一个数据加载器,它会给你一个小批量,特别是转换后的小批量。使用数据加载器,你不能要求一个特定的小批量;你只能得到next小批量。在 Python 中,它被称为“生成器”或“迭代器”。PyTorch 真正利用了现代 Python 方法。
如果你很了解 Python,PyTorch 会非常自然。如果你不太了解 Python,PyTorch 是学习 Python 的一个很好的理由。
x:一批图像,y:一批标签。
如果你不确定一个函数需要什么参数,按下shift+tab。
list(zip(data.classes, y[0]))
'''
[('agriculture', 1.0),
('artisinal_mine', 0.0),
('bare_ground', 0.0),
('blooming', 0.0),
('blow_down', 0.0),
('clear', 1.0),
('cloudy', 0.0),
('conventional_mine', 0.0),
('cultivation', 0.0),
('habitation', 0.0),
('haze', 0.0),
('partly_cloudy', 0.0),
('primary', 1.0),
('road', 0.0),
('selective_logging', 0.0),
('slash_burn', 1.0),
('water', 1.0)]
'''
在幕后,PyTorch 和 fast.ai 将我们的标签转换为独热编码标签。如果实际标签是狗,它看起来像:

我们取actuals和softmax之间的差异,将它们相加以表示有多少错误(即损失函数)[1:31:02]。
独热编码对于存储来说非常低效,所以我们将存储一个索引值(单个整数)而不是目标值(y)的 0 和 1。如果您查看狗品种竞赛的y值,您实际上不会看到一个大的 1 和 0 的列表,而是会看到一个单个整数。在内部,PyTorch 将索引转换为独热编码向量(即使您永远不会看到它)。PyTorch 有不同的损失函数,适用于独热编码和其他不是独热编码的情况,但这些细节被 fast.ai 库隐藏,因此您不必担心。但要意识到的很酷的事情是,我们对单标签分类和多标签分类都做了完全相同的事情。
问题:改变 softmax 的对数基数有意义吗?[01:32:55] 不,改变基数只是一个线性缩放,神经网络可以轻松学习:

plt.imshow(data.val_ds.denorm(to_np(x))[0]*1.4);

-
*1.4:图像被冲洗了,所以让它更明显(“稍微提亮”)。图像只是数字矩阵,所以我们可以做这样的事情。 -
尝试这样的图像是很好的,因为这些图像根本不像 ImageNet。你所做的绝大多数涉及卷积神经网络的事情实际上都不像 ImageNet(医学成像,分类不同种类的钢管,卫星图像等)
sz=64
data = get_data(sz)
data = data.resize(int(sz*1.3), 'tmp')
-
我们不会在猫狗竞赛中使用
sz=64,因为我们从预训练的 ImageNet 网络开始,它几乎完美。如果我们用 64x64 的图像重新训练整个集合,我们会破坏已经非常好的权重。请记住,大多数 ImageNet 模型是用 224x224 或 299x299 的图像训练的。 -
ImageNet 中没有像上面那样的图像。而且只有前几层对我们有用。所以从较小的图像开始在这种情况下效果很好。
learn = ConvLearner.pretrained(f_model, data, metrics=metrics)
lrf=learn.lr_find()
learn.sched.plot()

lr = 0.2
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
'''
[ 0\. 0.14882 0.13552 0.87878]
[ 1\. 0.14237 0.13048 0.88251]
[ 2\. 0.13675 0.12779 0.88796]
[ 3\. 0.13528 0.12834 0.88419]
[ 4\. 0.13428 0.12581 0.88879]
[ 5\. 0.13237 0.12361 0.89141]
[ 6\. 0.13179 0.12472 0.8896 ]
'''
lrs = np.array(**[lr/9, lr/3, lr]**)learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
'''
[ 0\. 0.12534 0.10926 0.90892]
[ 1\. 0.12035 0.10086 0.91635]
[ 2\. 0.11001 0.09792 0.91894]
[ 3\. 0.1144 0.09972 0.91748]
[ 4\. 0.11055 0.09617 0.92016]
[ 5\. 0.10348 0.0935 0.92267]
[ 6\. 0.10502 0.09345 0.92281]
'''
[lr/9, lr/3, lr]— 这是因为这些图像不像 ImageNet 图像,而且较早的层可能与它们需要的不太接近。
learn.sched.plot_loss()

sz = 128
learn.set_data(get_data(sz))
learn.freeze()
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
'''
[ 0\. 0.09729 0.09375 0.91885]
[ 1\. 0.10118 0.09243 0.92075]
[ 2\. 0.09805 0.09143 0.92235]
[ 3\. 0.09834 0.09134 0.92263]
[ 4\. 0.096 0.09046 0.9231 ]
[ 5\. 0.09584 0.09035 0.92403]
[ 6\. 0.09262 0.09059 0.92358]
'''
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
learn.save(f'{sz}')
'''
[ 0\. 0.09623 0.08693 0.92696]
[ 1\. 0.09371 0.08621 0.92887]
[ 2\. 0.08919 0.08296 0.93113]
[ 3\. 0.09221 0.08579 0.92709]
[ 4\. 0.08994 0.08575 0.92862]
[ 5\. 0.08729 0.08248 0.93108]
[ 6\. 0.08218 0.08315 0.92971]
'''
sz = 256
learn.set_data(get_data(sz))
learn.freeze()
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
'''
[ 0\. 0.09161 0.08651 0.92712]
[ 1\. 0.08933 0.08665 0.92677]
[ 2\. 0.09125 0.08584 0.92719]
[ 3\. 0.08732 0.08532 0.92812]
[ 4\. 0.08736 0.08479 0.92854]
[ 5\. 0.08807 0.08471 0.92835]
[ 6\. 0.08942 0.08448 0.9289 ]
'''
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
learn.save(f'{sz}')
'''
[ 0\. 0.08932 0.08218 0.9324 ]
[ 1\. 0.08654 0.08195 0.93313]
[ 2\. 0.08468 0.08024 0.93391]
[ 3\. 0.08596 0.08141 0.93287]
[ 4\. 0.08211 0.08152 0.93401]
[ 5\. 0.07971 0.08001 0.93377]
[ 6\. 0.07928 0.0792 0.93554]
'''
log_preds,y = learn.TTA()
preds = np.mean(np.exp(log_preds),0)
f2(preds,y)
'''
0.93626519738612801
'''
有几个人问了这个问题[01:38:46]:
data = data.resize(int(sz*1.3), 'tmp')
当我们指定要应用的转换时,我们发送一个大小:
tfms = tfms_from_model(
f_model, sz,
aug_tfms=transforms_top_down,
max_zoom=1.05
)
数据加载器的一项工作是按需调整图像的大小。这与data.resize无关。如果初始图像是 1000x1000,读取该 JPEG 并将其调整为 64x64 比训练卷积网络需要更多时间。data.resize告诉它我们不会使用大于sz*1.3的图像,因此请通过一次并创建新的这个大小的 JPEG。由于图像是矩形的,因此最小边为sz*1.3的新 JPEG(中心裁剪)。这将节省您大量时间。
metrics=[f2]
我们在这个笔记本中使用F-beta而不是accuacy,这是一种权衡假阴性和假阳性的方法。我们使用它的原因是因为这个特定的 Kaggle 竞赛想要使用它。查看planet.py看看如何创建自己的指标函数。这是最后打印出来的内容[ 0\. 0.08932 0.08218 **0.9324** ]
多标签分类的激活函数[01:44:25]
多标签分类的激活函数称为sigmoid。


问题:为什么我们不从不同的学习率开始训练,而是只训练最后的层?[01:50:30]

您可以跳过训练最后一层,直接进行不同的学习率,但您可能不想这样做。卷积层都包含预训练权重,因此它们不是随机的 — 对于接近 ImageNet 的东西,它们非常好;对于不接近 ImageNet 的东西,它们比没有好。然而,我们所有的全连接层都是完全随机的。因此,您始终希望通过先训练它们使全连接权重比随机更好一些。否则,如果直接解冻,那么您实际上将在后续层仍然是随机的情况下摆弄那些早期层的权重 — 这可能不是您想要的。
问题:当您使用不同的学习率时,这三个学习率是否均匀分布在各层之间?[01:55:35]我们将在课程后面更多地讨论这个问题,但是在 fast.ai 库中,有一个“层组”的概念。在像 ResNet50 这样的模型中,有数百个层,您可能不想编写数百个学习率,因此库为您决定如何分割它们,最后一个始终指的是我们随机初始化并添加的全连接层。
可视化层[01:56:42]
learn.summary()
'''
[('Conv2d-1',
OrderedDict([('input_shape', [-1, 3, 64, 64]),
('output_shape', [-1, 64, 32, 32]),
('trainable', False),
('nb_params', 9408)])),
('BatchNorm2d-2',
OrderedDict([('input_shape', [-1, 64, 32, 32]),
('output_shape', [-1, 64, 32, 32]),
('trainable', False),
('nb_params', 128)])),
('ReLU-3',
OrderedDict([('input_shape', [-1, 64, 32, 32]),
('output_shape', [-1, 64, 32, 32]),
('nb_params', 0)])),
('MaxPool2d-4',
OrderedDict([('input_shape', [-1, 64, 32, 32]),
('output_shape', [-1, 64, 16, 16]),
('nb_params', 0)])),
('Conv2d-5',
OrderedDict([('input_shape', [-1, 64, 16, 16]),
('output_shape', [-1, 64, 16, 16]),
('trainable', False),
('nb_params', 36864)]))
...
'''
-
‘input_shape’, [-1, **3, 64, 64**]— PyTorch 在图像尺寸之前列出通道。当按照这个顺序进行 GPU 计算时,一些计算会更快。这是通过转换步骤在幕后完成的。 -
-1:表示批量大小有多大。Keras 使用None。 -
‘output_shape’, [-1, 64, 32, 32]— 64 是卷积核的数量
问题:对于一个非常小的数据集,学习率查找器返回了奇怪的数字,绘图为空[01:58:57] — 学习率查找器将逐个小批量进行。如果您有一个微小的数据集,那么就没有足够的小批量。因此,诀窍是将批量大小设置得非常小,如 4 或 8。
结构化数据[01:59:48]
在机器学习中我们使用两种类型的数据集:
-
非结构化 — 音频、图像、自然语言文本,其中对象内的所有内容都是同一种类型的东西 — 像素、波形振幅或单词。
-
结构化 — 损益表,关于 Facebook 用户的信息,其中每列在结构上都非常不同。 “结构化”指的是列式数据,就像您在数据库或电子表格中找到的那样,不同的列代表不同类型的事物,每行代表一个观察。
结构化数据在学术界经常被忽视,因为如果您有更好的物流模型,很难在高端会议论文中发表。但这是让世界运转的东西,让每个人都赚钱和提高效率。我们不会忽视它,因为我们正在进行实际的深度学习,Kaggle 也不会,因为人们在 Kaggle 上提供奖金来解决现实世界的问题:
-
Corporación Favorita Grocery Sales Forecasting — 目前正在进行中
-
Rossmann Store Sales — 几乎与上述相同,但是已经完成的比赛。
Rossmann Store Sale [02:02:42]
笔记本
from fastai.structured import *
from fastai.column_data import *
np.set_printoptions(threshold=50, edgeitems=20)
PATH='data/rossmann/'
-
fastai.structured— 不是特定于 PyTorch 的,也在机器学习课程中使用,使用随机森林而没有 PyTorch。它可以独立使用,而无需使用 Fast.ai 库的其他部分。 -
fastai.column_data— 允许我们使用列式结构化数据进行 Fast.ai 和 PyTorch 操作。 -
对于结构化数据,需要大量使用 Pandas。Pandas 是在 Python 中尝试复制 R 的数据框架(如果您对 Pandas 不熟悉,这里有一本好书 — Python 数据分析,第二版)
有很多数据预处理。这个笔记本包含了第三名获奖者的整个流程(分类变量的实体嵌入)。数据处理在本课程中没有涉及,但在一些机器学习课程中有详细介绍,因为特征工程非常重要。
查看 CSV 文件
table_names = [
'train', 'store',
'store_states',
'state_names',
'googletrend',
'weather', 'test'
]
tables = [
pd.read_csv(f'{PATH}{fname}.csv', low_memory=False)
for fname in table_names
]
for t in tables: display(t.head())

StoreType— 您经常会得到一些列包含“代码”的数据集。实际上,这个代码的含义并不重要。不要过多地了解它,先看看数据说了什么。
连接表
这是一个关系型数据集,您需要将许多表连接在一起 — 这在 Pandas 的 merge 中很容易实现:
def join_df(left, right, left_on, right_on=None, suffix='_y'):
if right_on is None:
right_on = left_on
return left.merge(
right,
how='left',
left_on=left_on,
right_on=right_on,
suffixes=("", suffix)
)
来自 Fast.ai 库:
add_datepart(train, "Date", drop=False)
-
取一个日期并提取出一堆列,比如“星期几”,“季度开始”,“年份的月份”等等,并将它们全部添加到数据集中。
-
持续时间部分将计算诸如距下一个假期还有多长时间,距上一个假期已经过去多长时间等等。
joined.to_feather(f'{PATH}joined')
to_feather:将 Pandas 的数据框保存为“feather”格式,该格式将数据框原封不动地转储到磁盘上。因此速度非常快。厄瓜多尔杂货店竞赛有 3.5 亿条记录,因此您会关心保存需要多长时间。
下周
-
将列分为两种类型:分类和连续。分类列将被表示为独热编码,而连续列将被直接输入到全连接层中。
-
分类:商店 #1 和商店 #2 之间没有数值关联。同样,星期几的星期一(第 0 天)和星期二(第 1 天)也没有数值关联。
-
连续:像到最近竞争对手的公里数这样的距离是我们以数字方式处理的一个数字。
-
ColumnarModelData






![[NSSCTF]-Web:[SWPUCTF 2021 新生赛]easy_sql解析](https://img-blog.csdnimg.cn/direct/ddab8bb437554bb89363ef895c428ba5.png)