目录
前言
项目介绍
数据集处理
数据集加载
定义网络
训练网络
验证网络
前言
本篇文章会讲解使用pytorch完成另外一个计算机视觉的基本任务-语义分割。
语义分割是将图片中每个部分根据其语义分割出来,其相比于图像分类的不同点是,图像分类是对一张图片进行分类,而语义分割是对图像中的每个像素点进行分类。
我们这里使用的语义分割数据集是kaggle上的一个数据集。
数据集来源:https://www.kaggle.com/datasets/intelecai/car-segmentation
项目介绍
本次项目的任务是会得到很多张汽车的图像,其大都数为汽车的侧面图,而我们要做的就是将车体,车灯,车轮和车窗分割出来,可以先看一下原始图片,标签和最终分割结果



因为中间的处理和最后的显示都会对图像进行resize操作,所以最终的结果可能会相较于原图片和标签尺寸不太一样。
我们可以看一下最终结果,其中背景,车体,车灯,车窗和车轮都用不同的颜色区分。
这里解释一下为什么标签会是一张全黑色的图片,这是因为,语义分割是对每个像素点进行分类,从0开始分类,这里一共会分为5类,所以标签是一张和原图尺寸大小一样,每个像素点中的值为0到4的一张单通道图像,所以用肉眼看去,就是一张全黑图像。
最后的结果有颜色则是做了一个颜色映射。
数据集处理
这里我们从kaggle上直接下载数据集,所有的图片和标签都有一个大的文件夹,这里我们是无法直接放入网络进行训练的,所以我们需要先处理一下数据集,将其随机切分为训练集和测试集,才能放入网络训练
import os
import shutil
import random
import torch
from torchvision import io
def car_to_dataset():
# 汽车数据集转换为语义分割数据集
images_path = 'Car segmentation/images'
labels_path = 'Car segmentation/masks'
if not os.path.exists('dataset'):
os.mkdir('dataset')
if not os.path.exists(os.path.join('dataset', 'train')):
os.mkdir(os.path.join('dataset', 'train'))
if not os.path.exists(os.path.join('dataset', 'test')):
os.mkdir(os.path.join('dataset', 'test'))
if not os.path.exists(os.path.join('dataset', 'train', 'images')):
os.mkdir(os.path.join('dataset', 'train', 'images'))
if not os.path.exists(os.path.join('dataset', 'train', 'labels')):
os.mkdir(os.path.join('dataset', 'train', 'labels'))
if not os.path.exists(os.path.join('dataset', 'test', 'images')):
os.mkdir(os.path.join('dataset', 'test', 'images'))
if not os.path.exists(os.path.join('dataset', 'test', 'labels')):
os.mkdir(os.path.join('dataset', 'test', 'labels'))
image_name = os.listdir(images_path)
length = len(image_name)
train_list = random.sample(range(length),int(length * 0.8))
train_set = set(train_list)
test_list = [i for i in range(length) if i not in train_set]
for i in train_list:
shutil.copy(os.path.join(images_path,image_name[i]),os.path.join('dataset', 'train','images'))
shutil.copy(os.path.join(labels_path,image_name[i]),os.path.join('dataset', 'train','labels'))
for i in test_list:
shutil.copy(os.path.join(images_path,image_name[i]),os.path.join('dataset', 'test','images'))
shutil.copy(os.path.join(labels_path,image_name[i]),os.path.join('dataset', 'test','labels'))
with open(os.path.join('dataset', 'train.txt'), 'w') as f:
for i in train_list:
f.write(str(i))
f.write("\n")
with open(os.path.join('dataset', 'test.txt'), 'w') as f:
for i in test_list:
f.write(str(i))
f.write("\n")
def get_mean_std(path):
length = len(os.listdir(path))
means = torch.zeros(3)
stds = torch.zeros(3)
for name in os.listdir(path):
img = io.read_image(os.path.join(path, name)).type(torch.float32) / 255
for i in range(3):
means[i] += img[i, :, :].mean()
stds[i] += img[i, :, :].std()
print("means:{}".format(means.div_(length)), "stds:{}".format(stds.div_(length)))
if __name__ == '__main__':
car_to_dataset()
get_mean_std('dataset/train/images')
运行完之后,会生成train和test两个文件夹和train和test两个txt文件,两个文件夹中还会有images和labels文件夹,而两个txt文件夹中记录的就是原始文件夹中的第几张图片,并且这段代码还会求出训练集的均值和标准差,供之后对数据集进行归一化的操作

数据集加载
语义分割任务的第一步也是数据集加载,但是和图像分类任务不同的是,图像分类中图片进行切割,翻转,平移等操作时,图片的标签类别是不用动的,但是语义分割中,若对图像进行数据增强,那么标签图片需要同步做相应的处理,这一点比较重要,若只对原图片处理而不同步处理标签,则二者会无法对应
在这里我们使用albumentations这个数据增强库来对图片进行数据增强,附上albumentations讲解的传送门
Albumentations——强大的数据增强库(图像分类、分割、关键点检测、目标检测)-CSDN博客![]() https://blog.csdn.net/a486259/article/details/124103815?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738330316800182723629%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738330316800182723629&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124103815-null-null.142%5Ev99%5Econtrol&utm_term=albumentations&spm=1018.2226.3001.4187
https://blog.csdn.net/a486259/article/details/124103815?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738330316800182723629%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738330316800182723629&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-124103815-null-null.142%5Ev99%5Econtrol&utm_term=albumentations&spm=1018.2226.3001.4187
import os
from torch.utils.data import Dataset
import torch
import cv2
from torchvision.transforms import transforms as T
from PIL import Image
import albumentations as A
class CarDataset(Dataset):
def __init__(self, root, transform, mean, std):
super(CarDataset, self).__init__()
self.root = root
self.transform = transform
self.mean = mean
self.std = std
self.filenames = os.listdir(os.path.join(self.root, 'images'))
self.labels = os.listdir(os.path.join(self.root, 'labels'))
def __getitem__(self, index):
image_name = self.filenames[index]
label_name = self.labels[index]
image = cv2.imread(os.path.join(self.root,'images',image_name))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(os.path.join(self.root,'labels',label_name))
aug = self.transform(image=image, mask=mask)
image = Image.fromarray(aug['image'])
mask = aug['mask']
t = T.Compose([T.ToTensor(), T.Normalize(self.mean, self.std)])
image = t(image)
mask = torch.from_numpy(mask).to(torch.int64)
mask = mask[:, :, 0]
return image, mask
def __len__(self):
return len(self.filenames)
def load_data(batch_size, size):
mean = [0.5048, 0.4892, 0.4739]
std = [0.2709, 0.2673, 0.2681]
train_transform = A.Compose([A.Resize(size, size, interpolation=cv2.INTER_NEAREST),
A.VerticalFlip(), # X轴水平翻转
A.HorizontalFlip(), # Y轴水平翻转
A.GridDistortion(p=0.2), # 网格失真
A.GaussNoise(), # 高斯噪声
A.RandomBrightnessContrast((0, 0.5), (0, 0.5))]) # 随机对比度
test_transform = A.Resize(size, size, interpolation=cv2.INTER_NEAREST)
train_loader = torch.utils.data.DataLoader(CarDataset('./dataset/train', train_transform,mean,std), batch_size, shuffle=True, drop_last=True)
test_loader = torch.utils.data.DataLoader(CarDataset('./dataset/test', test_transform,mean,std), batch_size, shuffle=False, drop_last=True)
return train_loader, test_loader
if __name__ == '__main__':
train_loader, test_loader = load_data(1, 256)
for i, (X, y) in enumerate(train_loader):
print(X.shape,y.shape)
break
定义网络
我们这里使用比较传统的一个语义分割网络-UNet,这里也附上这个网络的一个讲解传送门UNet详解(附图文和代码实现)-CSDN博客![]() https://blog.csdn.net/weixin_45074568/article/details/114901600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738352116800225515385%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738352116800225515385&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-114901600-null-null.142%5Ev99%5Econtrol&utm_term=Unet&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_45074568/article/details/114901600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738352116800225515385%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738352116800225515385&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-114901600-null-null.142%5Ev99%5Econtrol&utm_term=Unet&spm=1018.2226.3001.4187
import torch.nn as nn
import torch
class UNet(nn.Module):
def __init__(self, n_class):
super(UNet, self).__init__()
self.enc_blk11 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.enc_blk12 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.relu = nn.ReLU()
self.enc_blk21 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.enc_blk22 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(128)
self.enc_blk31 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn5 = nn.BatchNorm2d(128)
self.enc_blk32 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn6 = nn.BatchNorm2d(256)
self.enc_blk41 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.bn7 = nn.BatchNorm2d(512)
self.enc_blk42 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn8 = nn.BatchNorm2d(512)
self.enc_blk51 = nn.Conv2d(512, 1024, kernel_size=3, padding=1)
self.bn9 = nn.BatchNorm2d(1024)
self.enc_blk52 = nn.Conv2d(1024, 1024, kernel_size=3, padding=1)
self.bn10 = nn.BatchNorm2d(1024)
self.upconv1 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.dec_blk11 = nn.Conv2d(1024, 512, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(512)
self.dec_blk12 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(512)
self.upconv2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec_blk21 = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.bn13 = nn.BatchNorm2d(256)
self.dec_blk22 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn14 = nn.BatchNorm2d(256)
self.upconv3 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec_blk31 = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.bn15 = nn.BatchNorm2d(128)
self.dec_blk32 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn16 = nn.BatchNorm2d(128)
self.upconv4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec_blk41 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.bn17 = nn.BatchNorm2d(64)
self.dec_blk42 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn18 = nn.BatchNorm2d(64)
# Output Layer
self.out_layer = nn.Conv2d(64, n_class, kernel_size=1)
def forward(self, x):
enc11 = self.relu(self.bn1(self.enc_blk11(x)))
enc12 = self.relu(self.bn2(self.enc_blk12(enc11)))
pool1 = self.pool(enc12)
enc21 = self.relu(self.bn3(self.enc_blk21(pool1)))
enc22 = self.relu(self.bn4(self.enc_blk22(enc21)))
pool2 = self.pool(enc22)
enc31 = self.relu(self.bn5(self.enc_blk31(pool2)))
enc32 = self.relu(self.bn6(self.enc_blk32(enc31)))
pool3 = self.pool(enc32)
enc41 = self.relu(self.bn7(self.enc_blk41(pool3)))
enc42 = self.relu(self.bn8(self.enc_blk42(enc41)))
pool4 = self.pool(enc42)
enc51 = self.relu(self.bn9(self.enc_blk51(pool4)))
enc52 = self.relu(self.bn10(self.enc_blk52(enc51)))
up1 = self.upconv1(enc52)
up11 = torch.cat([up1, enc42], dim=1)
dec11 = self.relu(self.bn11(self.dec_blk11(up11)))
dec12 = self.relu(self.bn12(self.dec_blk12(dec11)))
up2 = self.upconv2(dec12)
up22 = torch.cat([up2, enc32], dim=1)
dec21 = self.relu(self.bn13(self.dec_blk21(up22)))
dec22 = self.relu(self.bn14(self.dec_blk22(dec21)))
up3 = self.upconv3(dec22)
up33 = torch.cat([up3, enc22], dim=1)
dec31 = self.relu(self.bn15(self.dec_blk31(up33)))
dec32 = self.relu(self.bn16(self.dec_blk32(dec31)))
up4 = self.upconv4(dec32)
up44 = torch.cat([up4, enc12], dim=1)
dec41 = self.relu(self.bn17(self.dec_blk41(up44)))
dec42 = self.relu(self.bn18(self.dec_blk42(dec41)))
out = self.out_layer(dec42)
return out
在这里我们主要对比图像分类说一下这个网络的输出。
图像分类任务的网络最终会经过线性层处理,其输出为一个一维的向量,向量的每个值代表对应类别的概率,这个应该比较好理解。
而语义风格任务的网络最后不会经过线性层的处理,它最后的输出也是一个卷积层,在卷积层的输出中,长和宽是输入图片的长和宽,而输出通道数为要分的类别数,其中第一个通道上的所有值就是每个像素点为类别0的概率值,依次类推。
训练网络
训练网络的部分和之前图像分类大同小异,这里说一下不同点
def pixel_accuracy(output, mask):
with torch.no_grad():
output = torch.argmax(F.softmax(output, dim=1), dim=1)
correct = torch.eq(output, mask).int()
accuracy = float(correct.sum() / float(correct.numel()))
return accuracy
def mIoU(pred_mask, mask, smooth=1e-10, n_classes=5):
with torch.no_grad():
pred_mask = F.softmax(pred_mask, dim=1)
pred_mask = torch.argmax(pred_mask, dim=1)
pred_mask = pred_mask.contiguous().view(-1)
mask = mask.contiguous().view(-1)
iou_per_class = []
for classes in range(0, n_classes):
true_class = (pred_mask == classes)
true_label = (mask == classes)
if true_label.long().sum().item() == 0:
iou_per_class.append(np.nan)
else:
intersect = torch.logical_and(true_class, true_label).sum().float().item()
union = torch.logical_or(true_class, true_label).sum().float().item()
iou = (intersect + smooth) / (union + smooth)
iou_per_class.append(iou)
return np.nanmean(iou_per_class)
首先我们定义两个评价网络好坏的指标,分别是准确率和miou,准确率就是一张图片中,网络分类对的像素点占全部像素点的比例,miou的讲解这里不过多赘述,附上传送门
语义分割指标---MIoU详细介绍(原理及代码)-CSDN博客![]() https://blog.csdn.net/smallworldxyl/article/details/121401875?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738390916800188543094%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738390916800188543094&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121401875-null-null.142%5Ev99%5Econtrol&utm_term=miou&spm=1018.2226.3001.4187然后我们定义一些超参数
https://blog.csdn.net/smallworldxyl/article/details/121401875?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170738390916800188543094%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170738390916800188543094&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-121401875-null-null.142%5Ev99%5Econtrol&utm_term=miou&spm=1018.2226.3001.4187然后我们定义一些超参数
batch_size = 2 # 批量大小
crop_size = 256 # 裁剪大小
in_channels = 3 # 输入图像通道
classes_num = 5 # 输出标签类别
num_epochs = 100 # 总轮次
auto_save = 10 # 自动保存的间隔轮次
lr = 1e-3 # 学习率
weight_decay = 1e-4 # 权重衰退
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 选择设备
train_loader, test_loader = load_data(batch_size, crop_size)
net = UNet(classes_num) # 定义模型
model_path = 'model_weights/UNet.pth'
loss = nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=weight_decay) # 定义优化器
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, lr, epochs=num_epochs, steps_per_epoch=len(train_loader))
print("训练开始")
time_start = time.time()
train(net, num_epochs, train_loader, test_loader, device=device, loss=loss, optimizer=optimizer,scheduler=scheduler, model_path=model_path, auto_save=auto_save)
torch.save(net.state_dict(), model_path)
time_end = time.time()
seconds = time_end - time_start
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
print("训练结束")
print("本次训练时长为:%02d:%02d:%02d" % (h, m, s))
最后我们就可以开始训练了
def train(net, epochs, train_iter, test_iter, device, loss, optimizer, scheduler, model_path, auto_save):
train_acc_list = []
train_miou_list = []
train_loss_list = []
test_acc_list = []
test_miou_list = []
test_loss_list = []
net = net.to(device)
for epoch in range(epochs):
net.train()
train_acc = 0
train_miou = 0
train_loss = 0
train_len = 0
with tqdm(range(len(train_iter)), ncols=100, colour='red',
desc="train epoch {}/{}".format(epoch + 1, num_epochs)) as pbar:
for i, (X, y) in enumerate(train_iter):
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
scheduler.step()
train_len += len(y)
train_acc += pixel_accuracy(y_hat, y)
train_miou += mIoU(y_hat, y)
train_loss += l.detach()
pbar.set_postfix({'loss': "{:.4f}".format(train_loss / train_len),
'acc': "{:.4f}".format(train_acc / train_len),
'miou': "{:.4f}".format(train_miou / train_len)})
pbar.update(1)
train_acc_list.append(train_acc / train_len)
train_miou_list.append(train_miou / train_len)
train_loss_list.append(train_loss.cpu().numpy() / train_len)
net.eval()
test_acc = 0
test_miou = 0
test_loss = 0
test_len = 0
with tqdm(range(len(test_iter)), ncols=100, colour='blue',
desc="test epoch {}/{}".format(epoch + 1, num_epochs)) as pbar:
for X, y in test_iter:
X, y = X.to(device), y.to(device)
y_hat = net(X)
test_len += len(y)
test_acc += pixel_accuracy(y_hat, y)
test_miou += mIoU(y_hat, y)
with torch.no_grad():
l = loss(y_hat, y)
test_loss += l.detach()
pbar.set_postfix({'loss': "{:.4f}".format(test_loss / test_len),
'acc': "{:.4f}".format(test_acc / test_len),
'miou': "{:.4f}".format(test_miou / test_len)})
pbar.update(1)
test_acc_list.append(test_acc / test_len)
test_miou_list.append(test_miou / test_len)
test_loss_list.append(test_loss.cpu().numpy() / test_len)
if (epoch + 1) % auto_save == 0:
torch.save(net.state_dict(), model_path)
plt.plot([i+1 for i in range(len(train_acc_list))], train_acc_list, 'bo--', label="train_acc")
plt.plot([i+1 for i in range(len(test_acc_list))], test_acc_list, 'ro--', label="test_acc")
plt.title("train_acc vs test_acc")
plt.ylabel("acc")
plt.xlabel("epochs")
plt.legend()
plt.savefig('logs/acc.png')
plt.show()
plt.plot([i+1 for i in range(len(train_miou_list))], train_miou_list, 'bo--', label="train_miou")
plt.plot([i+1 for i in range(len(test_miou_list))], test_miou_list, 'ro--', label="test_miou")
plt.title("train_miou vs test_miou")
plt.ylabel("miou")
plt.xlabel("epochs")
plt.legend()
plt.savefig('logs/miou.png')
plt.show()
plt.plot([i+1 for i in range(len(train_loss_list))], train_loss_list, 'bo--', label="train_loss")
plt.plot([i+1 for i in range(len(test_loss_list))], test_loss_list, 'ro--', label="test_loss")
plt.title("train_loss vs test_loss")
plt.ylabel("loss")
plt.xlabel("epochs")
plt.legend()
plt.savefig('logs/loss.png')
plt.show()
这里附上训练后的结果曲线
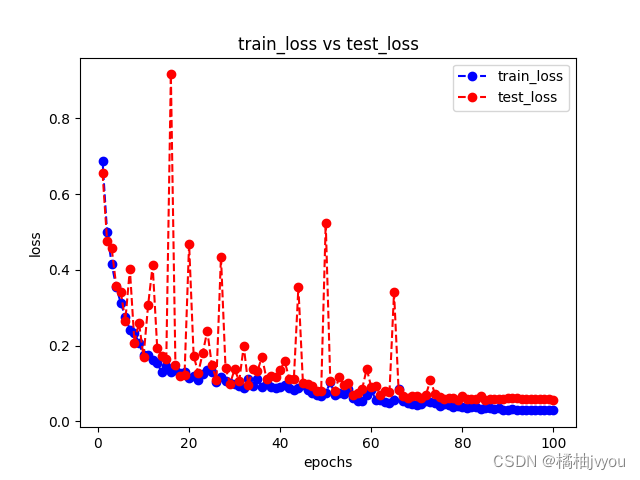
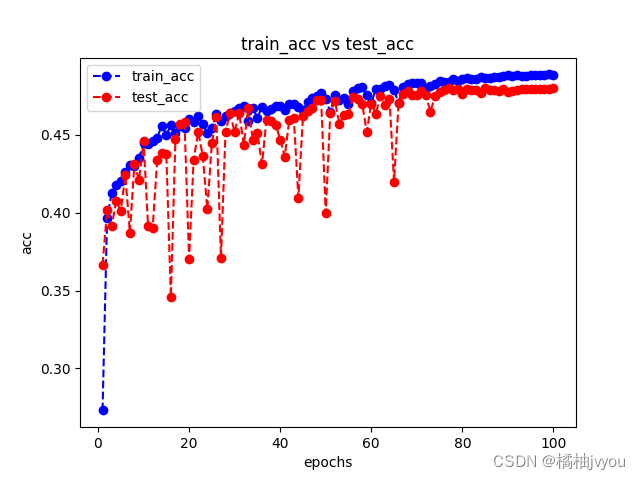
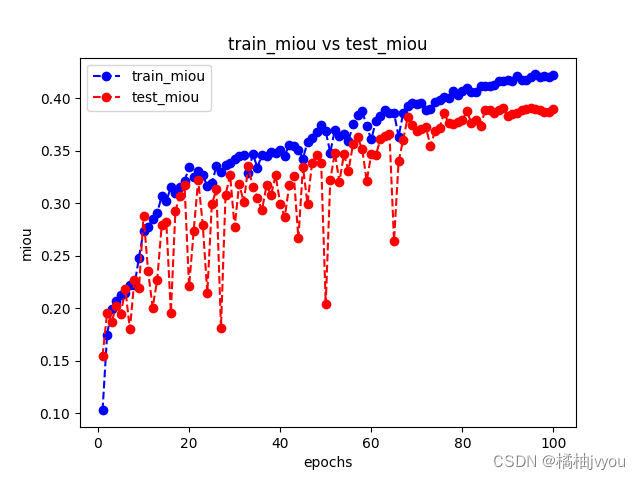
这里小编后面通过修改一些超参数重新训练,但是发现训练结果都差不多,损失曲线稳步下降,准确率和miou都在提升,都是不知道为什么这两个到0.5就趋于拟合了,怎么试都上不去,如果有兴趣的话,可以换个更强的网络试一下,小编这里就不做测试了(再炼恐怖炼丹炉会吃不住)
验证网络
这里验证网络的步骤也是将单张图片或者读取视频中的每一帧,然后做调整尺寸和转tensor等一系列操作,最后放入网络进行预测,不过这里小编用qt写了个前端界面
import cv2
import sys
import torch
import numpy as np
from PIL import Image
from utils.model import UNet
from torchvision import transforms
from PyQt5 import QtWidgets,QtCore,QtGui
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtWidgets import QMessageBox
from PyQt5.QtWidgets import *
from screen import Ui_MainWindow
import tkinter as tk
from tkinter import filedialog #获取文件
class Main(QtWidgets.QMainWindow,Ui_MainWindow):
def __init__(self):
super(Main, self).__init__()
self.setupUi(self)
self.pushButton.clicked.connect(self.photo)
self.pushButton_2.clicked.connect(self.devio)
self.pushButton_3.clicked.connect(self.exit)
self.flag = 1
self.transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()])
self.net = UNet(5)
self.net.load_state_dict(torch.load('model_weights/UNet.pth'))
# 显示封面
pix = QtGui.QPixmap('R-C.jpg')
self.label.setPixmap(pix)
self.label.setScaledContents(True)
def photo(self):
root = tk.Tk()
root.withdraw()
Filepath = filedialog.askopenfilename() # 获取文件路径
if (Filepath[-1] == 'g' and Filepath[-2] == 'n' and Filepath[-3] == 'p') \
or (Filepath[-1] == 'g' and Filepath[-2] == 'p' and Filepath[-3] == 'j'):
# 读取图片并做预测
img = cv2.imread(Filepath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (256, 256), interpolation=cv2.INTER_AREA)
img = Image.fromarray(img)
img = self.transform(img)
img = img.unsqueeze(0)
pred = torch.argmax(self.net(img), dim=1)
pred = pred.detach().numpy()
pred = pred.reshape(256, 256)
img = self.label2bgr(pred)
img = cv2.resize(img, (401, 401), interpolation=cv2.INTER_LINEAR)
# 显示
q_img = QImage(img.data, img.shape[0], img.shape[1], img.shape[0] * 3, QImage.Format_RGB888)
pix = QPixmap(q_img).scaled(self.label.width(), self.label.height())
self.label.setPixmap(pix)
self.label.setScaledContents(True)
else:
reply = QMessageBox.information(self, '标题', '请选择图片文件!',
QMessageBox.Ok) # 信息框
def devio(self):
root = tk.Tk()
root.withdraw()
Filepath = filedialog.askopenfilename()
pix = QtGui.QPixmap('R-C.jpg')
self.label.setPixmap(pix)
self.label.setScaledContents(True)
if Filepath[-1] == '4' and Filepath[-2] == 'p' and Filepath[-3] == 'm':
self.flag = 1
cap = cv2.VideoCapture(Filepath)
while cap.isOpened() and self.flag:
ret, frame = cap.read()
if not ret:
break
# 做预测
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = self.transform(frame)
frame = frame.unsqueeze(0)
pred = torch.argmax(self.net(frame), dim=1)
pred = pred.detach().numpy()
pred = pred.reshape(256, 256)
frame = self.label2bgr(pred)
frame = cv2.resize(frame, (401, 401), interpolation=cv2.INTER_LINEAR)
# 显示
temp_imgSrc = QImage(frame[:], frame.shape[1], frame.shape[0], frame.shape[1] * 3,
QImage.Format_RGB888)
pixmap_imgSrc = QPixmap.fromImage(temp_imgSrc).scaled(self.label.width(), self.label.height())
self.label.setPixmap(QPixmap(pixmap_imgSrc))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
else:
reply = QMessageBox.information(self, '标题', '请选择视频文件!',
QMessageBox.Ok) # 信息框
pix = QtGui.QPixmap('R-C.jpg')
self.label.setPixmap(pix)
self.label.setScaledContents(True)
def exit(self):
if self.flag:
self.flag = 0
reply = QMessageBox.information(self, '标题', '退出成功!',
QMessageBox.Ok) # 信息框
else:
reply = QMessageBox.information(self, '标题', '还未读入视频!',
QMessageBox.Ok) # 信息框
def label2bgr(self,pred):
frame = np.zeros((256, 256, 3)).astype(np.uint8)
frame[pred == 0] = (68, 1, 84)
frame[pred == 1] = (58, 82, 139)
frame[pred == 2] = (32, 144, 140)
frame[pred == 3] = (94, 201, 97)
frame[pred == 4] = (253, 231, 36)
return frame
if __name__ == '__main__':
QtCore.QCoreApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling) # 使窗体按照Qt设计显示
app = QtWidgets.QApplication(sys.argv)
main = Main()
main.show()
sys.exit(app.exec_())
其中label2bgr这个函数做的就是颜色映射的操作,将最后的单通道标签映射为具体的RGB三通道图像
这里附上运行结果
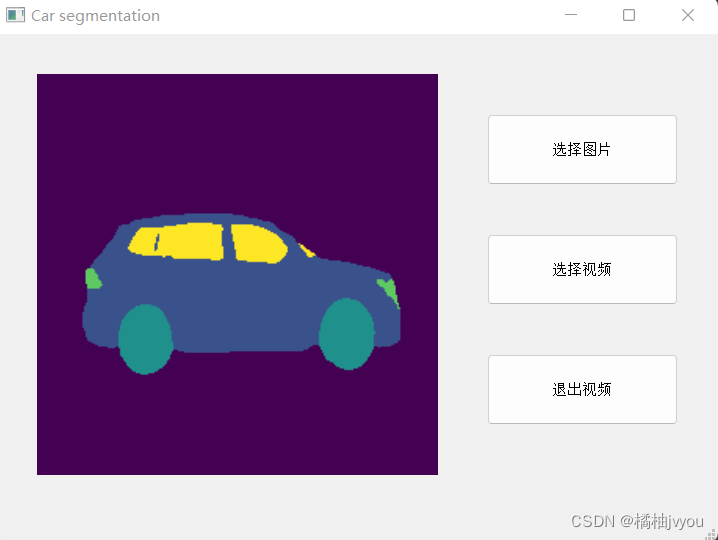
这里发送,虽然准确率和miou指标不太高,但是预测结果还算可以,如果要预测视频的话,可能速度会比较慢,后面可以考虑更换更加轻量级的网络测试。
源码请查看:https://github.com/jvyou/Car-segmentation
视频讲解请查看:https://www.bilibili.com/video/BV1zC411z7zc/?vd_source=ea64b940c4e46744da2aa737dca8e183