目录
一、前言
二、爬取下载美女图片
1、抓包分析
a、分析页面
b、明确需求
c、抓包搜寻
d、总结特点
2、编写爬虫代码
a、获取图片页网页源代码
b、提取所有图片的链接和标题
c、下载并保存这组图片
d、 爬取目录页的各种类型美女图片的链接
e、实现翻页
三、各种需求的爬虫代码
1、下载所有美女图片
2、下载想要页码范围内的美女图片
3、下载想要类型的美女图片
a、下载想要类型的所有美女图片
b、下载想要类型的想要页码范围的美女图片
一、前言
回车桌面网(https://www.enterdesk.com/)是一个具备各种精美图片的网站,里面包含各种丰富的图片资源。此处,将详细讲解爬取其中美女图片资源将其下载到本地。看懂本篇内容后,自己也可以爬取其中想要的类型图片。
回车桌面的首页:
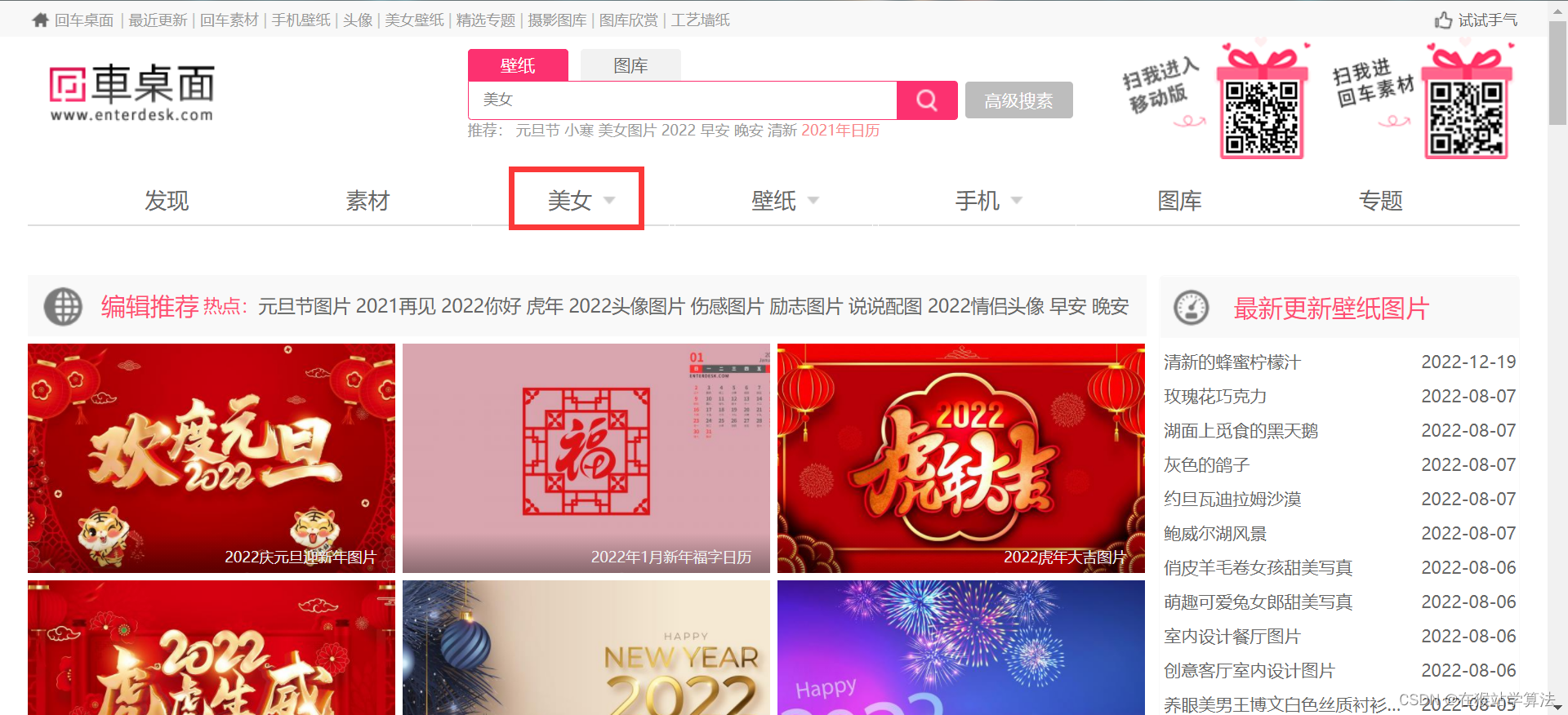
此处仅爬取所框选中的美女图片,看懂本篇后,自己也能做到爬取其他类型的图片!!!
二、爬取下载美女图片
1、抓包分析
爬虫的第一步都是抓包分析(也就是分析网页,从网页源代码中找到自己想要的内容)。
a、分析页面
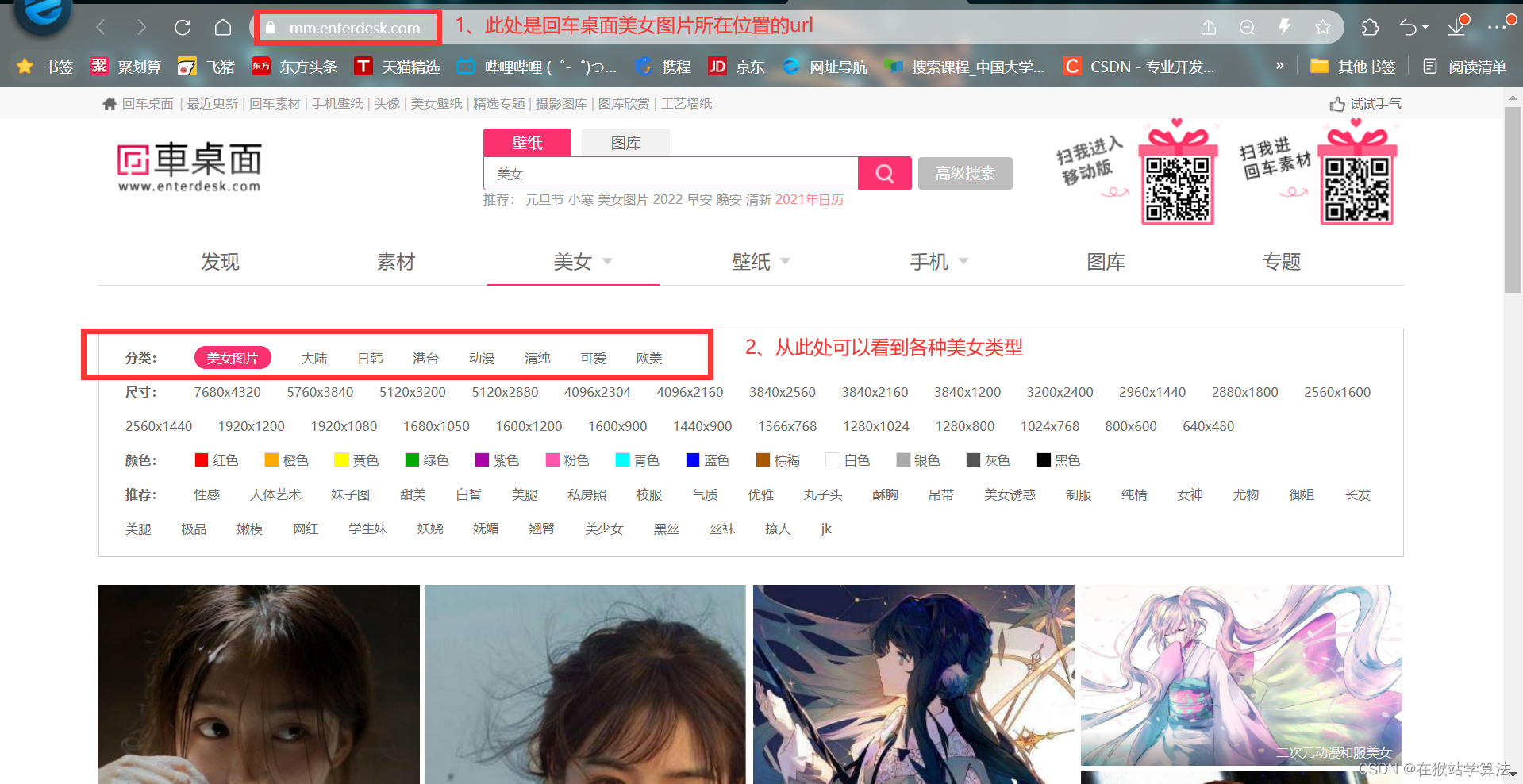
(1)在回车桌面中点击美女跳转到美女图片的网页
(2)在美女图片页面中,可以看到有各种类型的美女图片和下一页按钮。
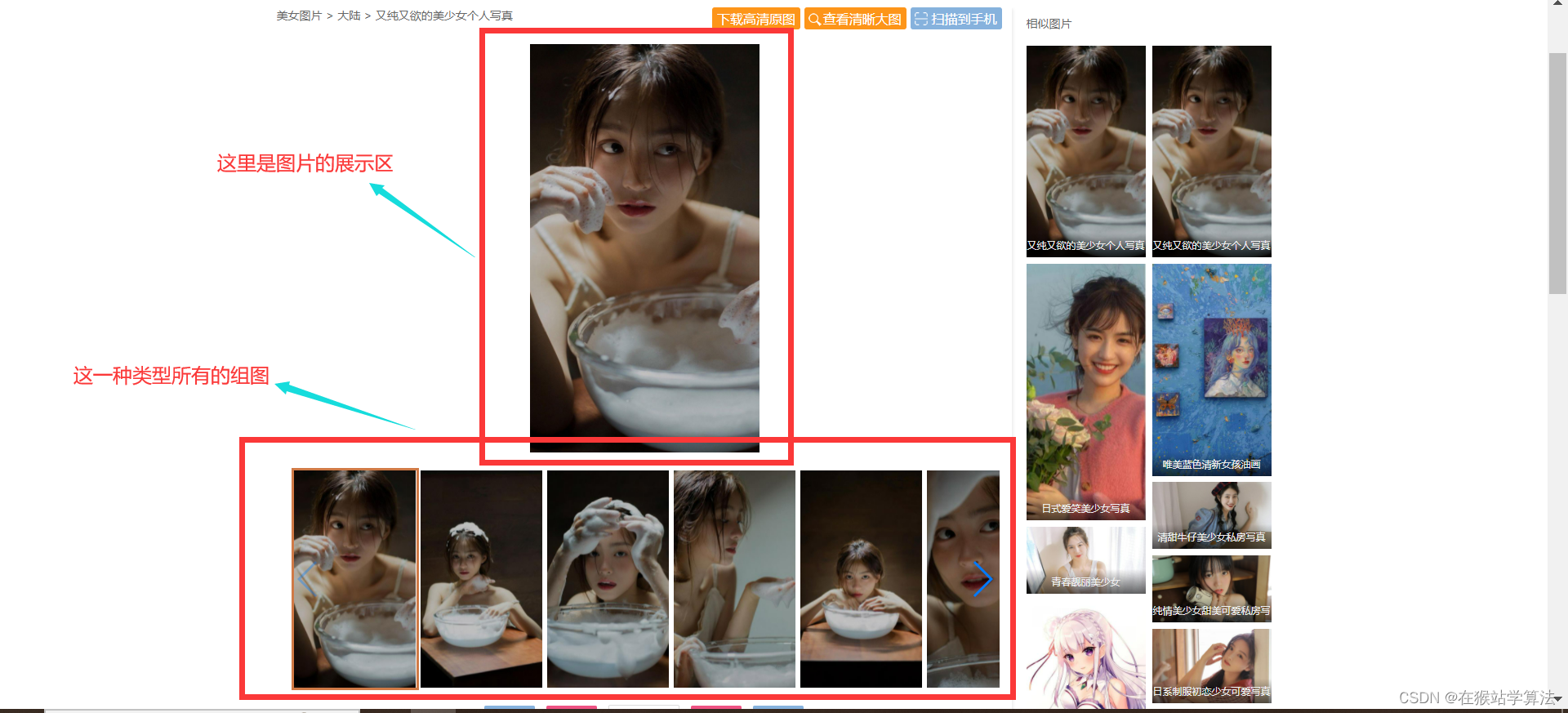
(3)点击一种类型的美女图片会跳转到该种类型的美女图片的具体图片界面
(4)点击下一页会跳转到另一页的美女图片页面,里面包含其他的类型的美女图片
(5)在美女图片页面中还有分类标签,点击一种风格类型,则会跳转到该种类型风格的美女图片
美女网页:
各种类型的美女图片:
 美女页面的下一页所在位置:
美女页面的下一页所在位置:
 一种类型美女图片的页面:
一种类型美女图片的页面:
b、明确需求
根据上面的页面分析,可以明确以下需求:
- 要获取到下一页的url所在页面源代码的位置
- 要获取到每种类型美女图片的url
- 要找到一种类型美女的各种图片下载的url
- 对美女网页进行requests请求,需要有请求头,找到请求网页的url、user-agent、cookie等信息
- 找到各种分类标签的url
c、抓包搜寻
根据以上需求,分析网页源代码,找到想要的内容。
步骤:
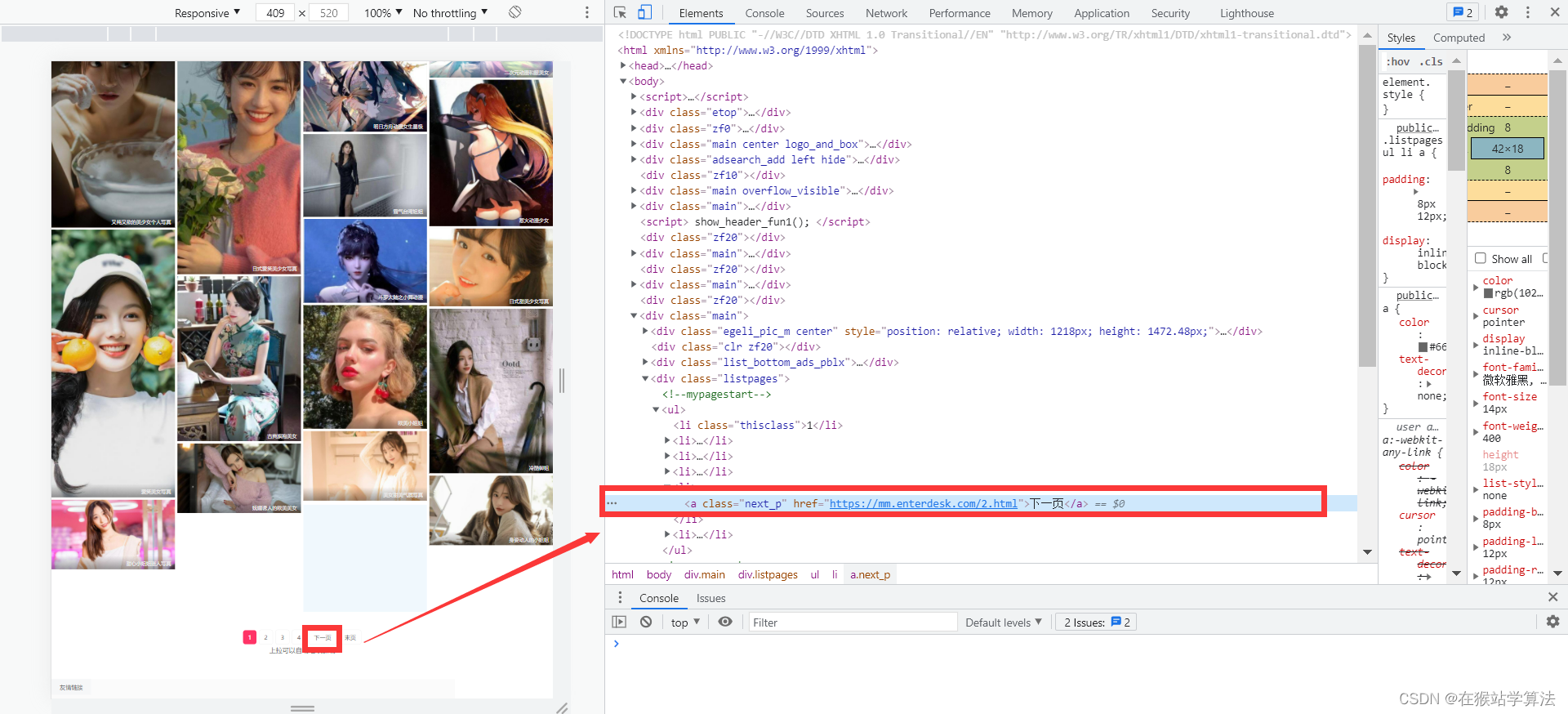
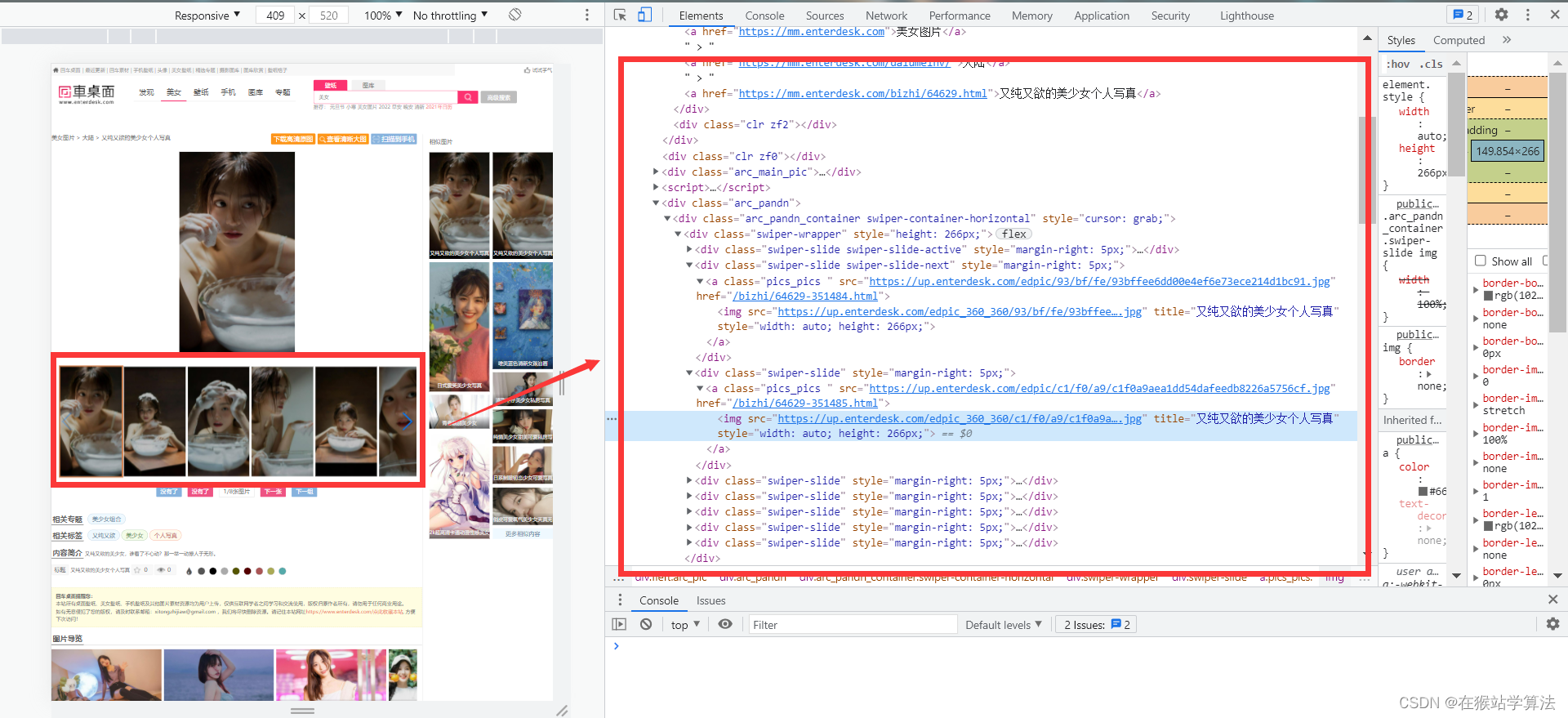
- 在美女页面,按下F12,打开开发者界面
- 点击开发者界面左上角的鼠标箭头
- 将箭头移到在美女页面的一种类型的美女图片上并点击一下
- 在开发者界面将会出现此部分的网页源代码

通过以上步骤,抓包寻找,可以分别找到需求部分所要内容:
- 要获取到下一页的url所在页面源代码的位置
- 要获取到每种类型美女图片的url
- 要找到一种类型美女的各种图片下载的url
- 对美女网页进行requests请求,需要有请求头,找到请求网页的url、user-agent、cookie等信息
- 找到各种分类标签的url


d、总结特点
经过抓包搜寻,可以发现:
- 美女页面每一页的url的构造为:以数字进行标记页码
'https://m.mm.enterdesk.com/1.html' 'https://m.mm.enterdesk.com/2.html' 'https://m.mm.enterdesk.com/3.html' 'https://m.mm.enterdesk.com/4.html' 'https://m.mm.enterdesk.com/5.html' .... 'https://m.mm.enterdesk.com/262.html' 'https://m.mm.enterdesk.com/264.html'
- 美女页面的标签的url的构造为:以风格类型的中文拼音+meinv
'https://mm.enterdesk.com/dalumeinv/' 'https://mm.enterdesk.com/rihanmeinv/' 'https://mm.enterdesk.com/gangtaimeinv/' 'https://mm.enterdesk.com/dongmanmeinv/' 'https://mm.enterdesk.com/qingchunmeinv/' 'https://mm.enterdesk.com/oumeimeinv/'
- 其他的url需要通过xPath来定位,根据所在位置的特点来定位
美女页面的各种类型的美女图片链接xPath定位://div[@class="mbig_pic_list_li"]//dd//a/@href 一种类型美女图片的标题xPath定位://h1[@class="m_h1"]/a/text() 一种类型美女图片的图片的urlxPath定位://div[@class="swiper-wrapper"]//img/@src
2、编写爬虫代码
根据上面的抓包分析,可以编写爬虫代码。
具体代码思路为:
1. 获取图片页网页源代码
2. 提取所有图片的链接和标题
3. 下载并保存这组图片
4. 爬取目录页的各种类型美女图片的链接
5. 实现翻页下载
a、获取图片页网页源代码
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36',
'cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)b、提取所有图片的链接和标题
def get_curindex_titlecontent(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
titles = html.xpath('//h1[@class="m_h1"]/a/text()')
pictures = html.xpath('//div[@class="marc_pandn"]//div[@class="swiper-slide"]//img/@src')
return titles, picturesc、下载并保存这组图片
def updownload(index_url):
titles,pictures = get_curindex_titlecontent(index_url)
titles = titles[0]
# 创建目录
if not os.path.exists(f'图片/{titles}/'):
os.makedirs(f'图片/{titles}')
num = 1
for link in pictures:
r = requests.get(link, headers=header).content
with open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:
f.write(r)
print(f"已下载...{titles}...编号为{num}的图片")
num+=1d、 爬取目录页的各种类型美女图片的链接
def get_curindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')
return linkse、实现翻页
def get_nextindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')
return links三、各种需求的爬虫代码
1、下载所有美女图片
由于美女图片数量较大,不建议使用这种情况。
思路:想要下载所有图片。在第一页的美女页面,下载完这一页图片后,通过获取下一页的链接,来刷新到第二页的美女页面,继续下载第二页的美女图片。然后继续获取下一页来刷新,直到下载到最后一页。最后一页是没有下一页的链接的,所以到了最后一页,获取下一页的代码会报错。但是没有关系,这里已经下载完了所有美女图片。
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36',
'cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')
return links
# 3、获取下一页的美女页面链接
def get_nextindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')
return links
# 4、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
titles = html.xpath('//h1[@class="m_h1"]/a/text()')
pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')
return titles, pictures
# 5、将图片进行下载保存到新的目录中
def updownload(index_url):
titles,pictures = get_curindex_titlecontent(index_url)
titles = titles[0]
# 创建目录
if not os.path.exists(f'图片/{titles}/'):
os.makedirs(f'图片/{titles}')
num = 1
for link in pictures:
r = requests.get(link, headers=header).content
with open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:
f.write(r)
print(f"已下载...{titles}...编号为{num}的图片")
num+=1
# 6、根据顺序来调整调用顺序
# a、获取各种类型美女图片的链接
num = 1
a = 1
while 1:
links = get_curindex_links(index_url)
print(f"正在下载第{num}页")
print(f"下载链接为:{index_url}")
for link in links:
# b、获取其中一个链接的内容和标题并下载保存
print(f"正在下载第{a}种类型的美女图片")
updownload(link)
a+=1
num+=1
next_page = get_nextindex_links(index_url)
# 将列表转换成字符串
index_url ="".join(next_page)
部分运行结果截图 :
2、下载想要页码范围内的美女图片
根据前面的总结特点,美女目录页面是根据1,2,3,4...来标记当前是第几页的。据此,可以通过读取键盘消息来下载自己想要范围内的美女图片。
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36',
'cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')
return links
# 3、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
titles = html.xpath('//h1[@class="m_h1"]/a/text()')
pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')
return titles, pictures
# 4、将图片进行下载保存到新的目录中
def updownload(index_url):
titles,pictures = get_curindex_titlecontent(index_url)
titles = titles[0]
# 创建目录
if not os.path.exists(f'图片/{titles}/'):
os.makedirs(f'图片/{titles}')
num = 1
for link in pictures:
r = requests.get(link, headers=header).content
with open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:
f.write(r)
print(f"已下载...{titles}...编号为{num}的图片")
num+=1
# 5、根据顺序来调整调用顺序
# a、获取各种类型美女图片的链接
a = 1
# 输入自己想要的页码范围内的美女图片
x = input("请输入起始页的页码:")
y = input("请输入结束页的页码:")
# 因为range函数是左闭右开的情况,所以y需要自增1
for page in range(int(x), int(y)+1):
new_index = index_url + str(page) + '.html'
links = get_curindex_links(new_index)
print(f"正在下载第{page}页")
print(f"下载链接为:{new_index}")
for link in links:
# b、获取其中一个链接的内容和标题并下载保存
print(f"正在下载第{a}种类型的美女图片")
updownload(link)
a+=1部分运行结果截图:

3、下载想要类型的美女图片
根据前面总结特点,可知各种标签的美女类型的url是通过输入中文拼音+meinv来进行标记的。则,可以通过读取键盘输入美女类型来下载想要类型的美女图片。这种情况下,存在两种需求。一是下载想要类型的所有的美女图片,二是下载想要类型的想要页码范围的美女图片。
a、下载想要类型的所有美女图片
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36',
'cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')
return links
# 3、获取下一页的美女页面链接
def get_nextindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')
return links
# 4、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
titles = html.xpath('//h1[@class="m_h1"]/a/text()')
pictures = html.xpath('//div[@class="marc_pandn"]//div[@class="swiper-slide"]//img/@src')
return titles, pictures
# 5、将图片进行下载保存到新的目录中
def updownload(index_url):
titles,pictures = get_curindex_titlecontent(index_url)
titles = titles[0]
# 创建目录
if not os.path.exists(f'图片/{keyword}/{titles}/'):
os.makedirs(f'图片/{keyword}/{titles}')
num = 1
for link in pictures:
r = requests.get(link, headers=header).content
with open(f'图片/{keyword}/{titles}/{titles}{num}.jpg', 'wb') as f:
f.write(r)
print(f"已下载...{titles}...编号为{num}的图片")
num+=1
# 6、根据键盘的输入来下载想要类型的美女图片
# a、读取键盘消息
keyword = input("请输入想要下载的类型的美女图片(中文拼音):")
index_url = index_url + keyword
num = 1
a = 1
while 1:
links = get_curindex_links(index_url)
print(f"正在下载第{num}页")
print(f"下载链接为:{index_url}")
for link in links:
# b、获取其中一个链接的内容和标题并下载保存
print(f"正在下载第{a}种类型的美女图片")
updownload(link)
a+=1
num+=1
next_page = get_nextindex_links(index_url)
# 将列表转换成字符串
index_url ="".join(next_page)部分截图如下:
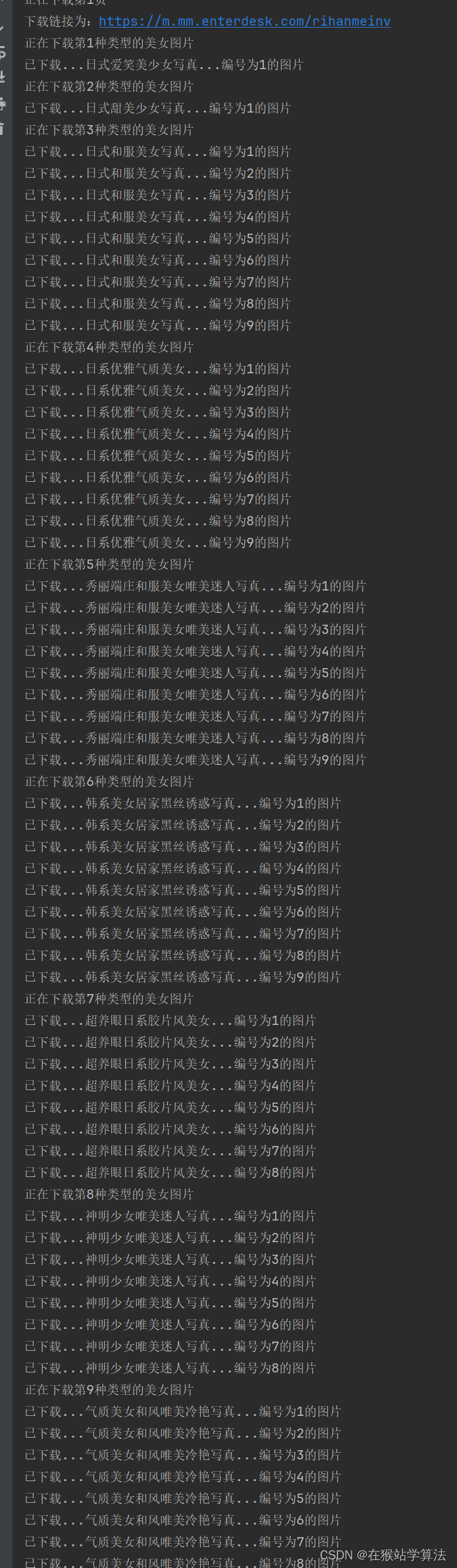
b、下载想要类型的想要页码范围的美女图片
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36',
'cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')
return links
# 3、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):
r = requests.get(index_url, headers=header)
html = etree.HTML(r.text)
titles = html.xpath('//h1[@class="m_h1"]/a/text()')
pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')
return titles, pictures
# 4、将图片进行下载保存到新的目录中
def updownload(index_url):
titles,pictures = get_curindex_titlecontent(index_url)
titles = titles[0]
print(titles)
# 创建目录
if not os.path.exists(f'图片/{keyword}/{titles}/'):
os.makedirs(f'图片/{keyword}/{titles}')
num = 1
for link in pictures:
r = requests.get(link, headers=header).content
with open(f'图片/{keyword}/{titles}/{titles}{num}.jpg', 'wb') as f:
f.write(r)
print(f"已下载...{titles}...编号为{num}的图片")
num+=1
# 5、根据键盘的输入来下载想要类型的美女图片
# a、读取键盘消息
keyword = input("请输入想要下载的类型的美女图片(中文拼音):")
index_url = index_url + keyword +'/'
# 输入自己想要的页码范围内的美女图片
x = input("请输入起始页的页码:")
y = input("请输入结束页的页码:")
# 因为range函数是左闭右开的情况,所以y需要自增1
for page in range(int(x), int(y)+1):
new_index = index_url + str(page) + '.html'
links = get_curindex_links(new_index)
print(f"正在下载第{page}页")
print(f"下载链接为:{new_index}")
for a, link in enumerate(links):
# b、获取其中一个链接的内容和标题并下载保存
print(f"正在下载第{page}页的第{a}种类型的美女图片")
updownload(link)部分截图如下: 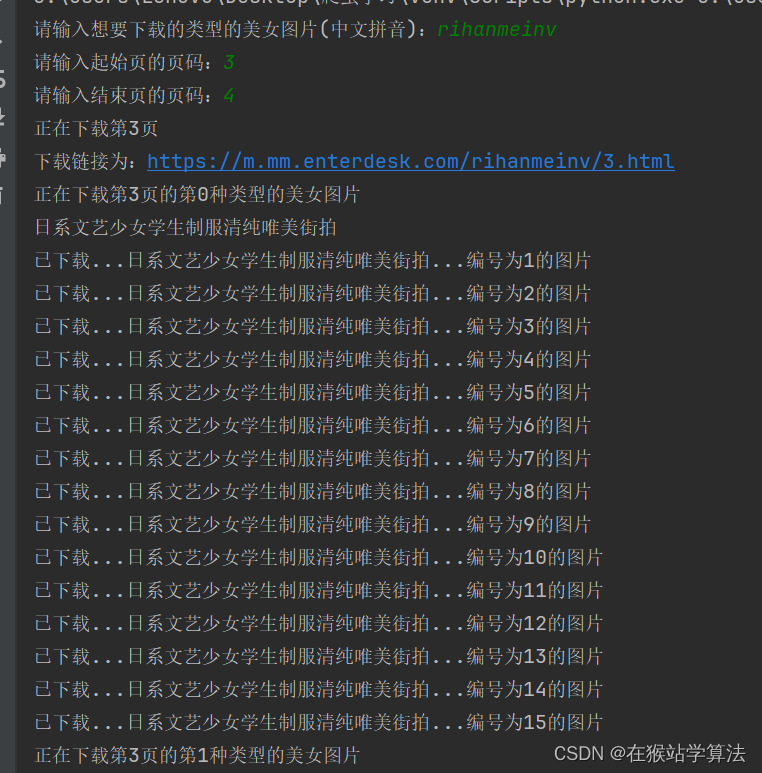



![[计算机提升] 备份系统:系统映像](https://img-blog.csdnimg.cn/direct/3ef96edfd59441f699bd77920db1b5bd.png)