人工智能语音克隆是一种捕捉声音的独特特征,然后准确性复制它的技术。这种技术不仅可以让我们复制现有的声音,还可以创造全新的声音。它是一种彻底改变内容创作的工具,从个性化歌曲到自定义画外音,开辟了一个超越语言和文化障碍的创意世界。

本文的将提供利用AI语音克隆技术-通过训练自定义模型将任何音频转换为选定艺术家的音调甚至自己的声音的端到端解决方案。
技术背景
我们将在本文中使用的技术称为歌唱声音转换(Singing Voice Conversion ),特别是一个称为SO-VITS-SVC的系统,它代表“SoftVC VITS Singing Voice Conversion”。
SO-VITS-SVC系统代表了使用深度学习技术的声音转换(SVC)的复杂实现。理解这个系统需要了解它所使用的特定机器学习架构和算法。
1、变分推理和生成对抗网络
SO-VITS-SVC的核心是文本到语音的变分推理(VITS)架构。该系统巧妙地结合了变分自编码器(VAEs)和生成对抗网络(GANs)。在SVC中,mel谱图是音频信号的重要表征,利用VAE对mel谱图的分布进行建模,有助于捕捉语音的潜在变量。
VAE损失函数按下式表示。式中,x为输入mel谱图,z为潜变量,KL为Kullback-Leibler散度。

上面公式封装了VAE损失函数,通过Kullback-Leibler散度平衡了mel谱图的重建和潜空间的正则化。
GAN则增强了合成音频的真实感。GAN中的鉴别器对生成器的输出进行判别,提高了生成器的精度。GAN损失函数为:

GAN损失函数展示了对抗训练动态,驱动生成模型产生难以区分的歌声。
如果想全面了解了解变分自编码器(VAEs)和生成对抗网络(gan),以下是原始论文:
VAEs: Kingma, D. P., and Welling, M. “Auto-Encoding Variational Bayes.” arXiv:1312.6114, 2013.
GANs: Goodfellow, I. J., et al. “Generative Adversarial Nets.” arXiv:1406.2661, 2014.
2、浅扩散过程
如附所示,浅扩散过程从噪声样本开始,通过一系列变换逐步细化为结构化梅尔谱图。

上图展示了SO-VITS-SVC合成流程,从浅扩散模型的初始噪声生成到mel谱图的细化和最终可听声音输出的语音编码。
初始噪声样本:噪声的视觉表示,作为扩散过程的起点。
转换步骤:噪声在扩散模型中经历一系列步骤,从无序状态过渡到结构化的mel谱图。其中xt是步骤t的数据,而ε表示高斯噪声。

上面公式说明了扩散过程中的逐渐转变,将随机噪声转化为结构化数据,捕捉目标歌声的细微差别。在SO-VITS-SVC的背景下,“浅”意味着更少的层或步骤,在计算效率和音频质量之间取得平衡。
mel谱图优化:这个过程的结果是一个mel谱图,它封装了歌唱声音的音频内容,为下一个合成阶段做好准备。
声音编码:最后的声音编码步骤将mel谱图转换成声音波形,即可听到的歌声。
如果想深入探索扩散模型,请看一下的资料:
Sohl-Dickstein, J., et al. “Deep Unsupervised Learning using Nonequilibrium Thermodynamics.” arXiv:1503.03585, 2015.
Ho, J., et al. “Denoising Diffusion Probabilistic Models.” arXiv:2006.11239, 2020.
3、完整流程与SVC系统的整合
在浅层扩散模型将噪音结构化成更连贯的形式之后,如前面提到的图表所示,生成的mel谱图捕捉了歌唱声音的微妙音频内容。这个mel谱图作为原始、非结构化数据与最终声音输出之间的关键桥梁。
然后使用声码器将优化后的mel谱图转换为音频波形。在这一步中,将从视觉数据转换为可听的歌唱声音。声码器的作用是合成mel谱图中捕捉到的音高、音色和节奏的细微差别,从而产生最终的歌唱声音输出。
为了实现高保真度的合成,SO-VITS-SVC系统会经过重新的训练和优化。训练包括优化结合了VAE、GAN和扩散模型组件贡献的损失函数。这种优化使用诸如随机梯度下降或Adam等算法进行,其最终目标是最小化总体损失。这个过程确保最终输出在音色、音高和节奏方面与目标歌唱声音非常相似。
这个过程的最终结果是一个与目标歌唱声音非常相似的合成声音。在保持源声音的音乐性和表现力细微差别的能力的同时,采用目标的音色特质,这是SO-VITS-SVC系统复杂性的体现。
4、使用的python库
GitHub上的SO-VITS-SVC Fork是一个专门设计用于实时歌声转换的专业工具。它是提供了增强功能的原始SO-VITS-SVC项目的分支:如使用CREPE更准确的音高估计、图形用户界面(GUI)、更快的训练时间以及使用pip安装工具的便利性。
它还集成了QuickVC并修复了原始存储库中存在的一些问题。并且支持实时语音转换,下面我们来演示如何使用它。
AI声音克隆
声音克隆就是我们一般所说的推理阶段,是指神经网络模型在数据集上接受训练以理解特定声音后,用所学到的声音生成新内容的过程。
在这个阶段,我们可以通过向预训练的模型提供新的输入(原始的声音音频)来让AI“唱歌”,然后该模型会在原始声音音频上产生模仿艺术家歌唱风格的输出。
1、设置环境
为简单起见,我们将创建一个心的虚拟环境,然后使用它
conda create -n sovits-svc
conda activate sovits-svc
安装必要的库。
!python -m pip install -U pip wheel
%pip install -U ipython
%pip install -U so-vits-svc-fork
如果你运行svc命令报错,例如下图
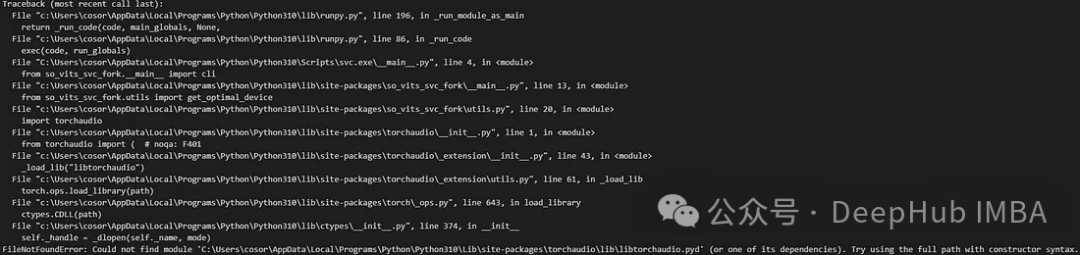
则需要使用pip uninstall Torchaudio卸载Torchaudio,然后使用pip install Torchaudio重新安装。这可能是因为一些依赖没有完整的安装,所以卸载后重装就可以了。
2、预训练模型
entrepreneurdly在Huggingface上提供了很多预训练模型

我们直接下载使用:
from huggingface_hub import hf_hub_download
import os
# Set the repository ID and local directory, we'll use Drake's Model
repo_id = 'Entreprenerdly/drake-so-vits-svc'
local_directory = '.'
# Download the config.json file
config_file = hf_hub_download(
repo_id=repo_id,
filename='config.json',
local_dir=local_directory,
local_dir_use_symlinks=False
)
# Construct the path to the config file in the current directory
local_config_path = os.path.join(local_directory, 'config.json')
print(f"Downloaded config file: {local_config_path}")
# Download the model file
model_file = hf_hub_download(
repo_id=repo_id,
filename='G_106000.pth',
local_dir=local_directory,
local_dir_use_symlinks=False
)
# Construct the path to the model file in the current directory
local_model_path = os.path.join(local_directory, 'G_83000.pth')
print(f"Downloaded model file: {local_model_path}")
3、选择一个干净的音频文件
下面就是要复制音频,但是这里需要音频是一个只有人声的干净的音频文件,如果音频里面的噪声比较多,我们需要手动进行预处理。因为源音频的质量会显著影响语音转换的保真度,因此始终建议使用高质量、干净的录音。
import requests
vocals_url = 'https://drive.google.com/uc?id=154awrw0VxIZKQ2jQpHQQSt__cOUdM__y'
response = requests.get(vocals_url)
with open('vocals.wav', "wb") as file:
file.write(response.content)
display(Audio('vocals.wav', autoplay=True))
4、运行推理
from IPython.display import Audio, display
import os
# Filenames
audio_filename = 'vocals.wav'
model_filename = 'G_106000.pth'
config_filename = 'config.json'
# Construct the full local paths
audio_file = f"\"{os.path.join('.', audio_filename)}\""
model_path = f"\"{os.path.join('.', model_filename)}\""
config_path = f"\"{os.path.join('.', config_filename)}\""
# Running the inference command
!svc infer {audio_file} -m {model_path} -c {config_path}
5、显示输出
可以直接在Jupyter笔记本或任何IPython界面中显示输出音频:
from IPython.display import Audio, display
# Path for the output audio file
output_audio_path = "vocals.out.wav"
# Display the output audio
display(Audio(output_audio_path, autoplay=True))
使用GUI
SO-VITS-SVC系统提供了一个可选的GUI来执行语音转换。可以使用以下命令启动它
svcg

训练自己的AI模型
上面我们演示了使用预训练模型的推理过程,下面我们来介绍如何训练自己的模型。
我们将展示使用SO-VITS-SVC系统训练自定义歌声转换模型所需的步骤。从准备数据集开始,进行环境设置和模型训练,最后通过从现有音频剪辑生成歌声来进行生成。
这个任务需要大量计算资源,需要一台配备高端GPU和大量VRAM的系统——通常超过10GB。对于那些个人硬件可能不符合这些要求的人来说,Google Colab提供了一个可行的替代方案,提供了访问强大GPU和足够的内存——一块T4 GPU就足够了。
1、数据准备
可以在Hugging Face上找到许多适用于训练自定义so-vits-svc模型的语音数据集。但是要个性化自己的模型以反映独特的声音特征,则需要录制自己的声音。
声音样本要求:
样本长度:最好每段10秒。这个长度对于捕捉声音细微差别而言是最理想的,同时也不会对处理过程提出太高的要求。
样本数量:数据越多,效果越好。需要至少200个声音样本。如果需要唱歌,则需要50个歌唱样本和150个说话样本,类似这样比例。
总音频长度:至少五分钟的总音频时常。这为模型提供了一个学习的坚实基础。
多样化内容:通过朗读语音质量平衡的句子来覆盖各种音素。例如IEEE推荐的语音质量测量实践提供了一个这样的句子列表,这些句子可以为一个全面的数据集做出贡献。
录制工具:Audacity是一个免费、开源的软件,非常适合录制您的样本。它可以轻松录制、编辑和导出WAV文件,还可以对音频进行处理,所以推荐使用
声音样本的预处理
我们需要从音频轨道中去除背景噪音。Spleeter库可以实现这个功能
!pip install spleeter
from spleeter.separator import Separator
# Initialize the separator with the desired configuration.
# Here, 'spleeter:2stems' means we want to separate the audio into two stems: vocals and accompaniment.
separator = Separator('spleeter:2stems')
# Use the separator on the audio file.
# This function will separate the audio file into two files: one containing the vocals, and one containing the background music.
separator.separate_to_file('audiofile.wav', './')
将音频轨道分割为片段:我们可以使用AudioSlicer将大量的音频文件分割成适合训练模型的10至15秒的片段。
from audioslicer import slice_audio
# Path to the input audio file
input_audio_path = 'long_audio_file.wav'
# Path to the output directory where snippets will be saved
output_directory = 'output/snippets/'
# Length of each audio snippet in seconds
snippet_length = 15
# Slice the audio file into snippets
slice_audio(input_audio_path, output_directory, snippet_length)
在当目录下创建了dataset_raw文件夹,并且录音存储在dataset_raw/{speaker_id}目录中,如下面的文件夹结构所示
.
├── dataset_raw
│ └── {speaker_id}
│ └── {wav_file}.wav
我们处理后的音频以这种形式保存即可
然后需要运行,进行svc的自动预处理
!svc pre-resample
!svc pre-config
!svc pre-hubert
2、训练配置
训练之前还配置模型,需要在config/44k/目录中创建的config.json文件。这个配置文件中的关键参数包括:log_interval、eval_interval、epochs、batch_size:

对于包含200个样本和批量大小为20的数据集,每个训练轮次等于10步。如果要训练100轮,这就等于1,000个步。
默认设置可能会建议10,000步,但根据您的硬件和数据集大小,可能需要调整这个设置。一个实际的方法可能是以20,000步(20000/10 约等于2000轮)为目标,然后评估性能再决定是否延长训练。
3、开始训练
使用svc train命令开始实际的模型训练。
!svc train
4、模型推理
在对模型进行了训练、微调和验证之后,下一步是运行推理,将源音频转换为目标语音
from IPython.display import Audio, display
import os
# Filenames
audio_filename = 'vocals.wav' # vocals to applied trained model
model_filename = 'model.pth' # model file created
config_filename = 'config.json' # config file created
# Construct the full local paths
audio_file = f"\"{os.path.join('.', audio_filename)}\""
model_path = f"\"{os.path.join('.', model_filename)}\""
config_path = f"\"{os.path.join('.', config_filename)}\""
# Running the inference command
!svc infer {audio_file} -m {model_path} -c {config_path}
然后就可以查看结果了
总结
SO-VITS-SVC(基于扩散模型和变分自动编码器的歌声转换系统)是一个强大的工具,用于实现实时歌声转换。通过结合了扩散模型、变分自动编码器和生成对抗网络等技术,SO-VITS-SVC系统能够捕捉歌声的细微差别,并产生高质量的合成歌声。
SO-VITS-SVC系统是一个功能强大且灵活的歌声转换工具,可以应用于多种场景,包括音乐制作、语音合成、语音转换等领域,为用户提供了实现个性化歌声转换的便利和可能。
so-vits-svc-fork地址:
https://avoid.overfit.cn/post/d169280896944f8195048fbbdf838b2e
作者:Cris Velasquez