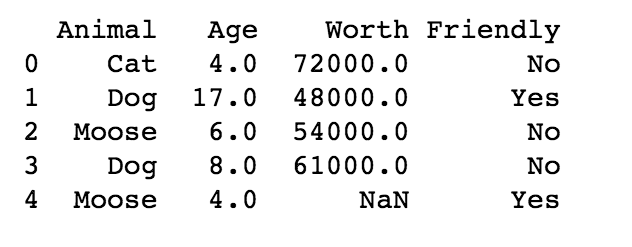
迭代加深
迭代加深主要用于dfs搜索过程中,某条支路特别深,但是答案在特别浅的地方,也即在另一个分支中,但是按照dfs的原理,我们是将这条支路搜完才去搜另一条支路。所以我们就要及时剪枝,而迭代加深算法则是指定搜索层数,一旦某个分支搜索的上限达到这个搜索层数了,那么我们就直接剪枝,不再往后搜了。如果当前指定的层数不能搜到结果,那么我们将指定层数再扩大一点。
这里就会有疑问,如果答案在第10层,那么0-9层都是冗余搜索,但是实际上,0-9层的搜索规模相对于第10层来说微不足道,主要的复杂度还是以第10层为主。所以不用担心。
下面我们就一个例题来实现一下迭代加深。
170. 加成序列(170. 加成序列 - AcWing题库)

思路:这题就很符合使用迭代加深的条件,我们仅仅规定了第一个数和最后一个数的大小,那么在每次都选第一个数得到新的数的时候,那么层数就很很深,但是答案显然不在这一分支中,答案在的分支层数应该不太深。所以这里我们就可以通过指定搜索层数来进行优化。另外为了更快的找到答案,我们可以先枚举比较大的数,从大到小枚举,这样可以更快的接近答案。而且大于答案的数实际上是用不到的,我们一旦搜到,也可剪枝。而且这里是加法,所以xi和xj的顺序无所谓,那么我们就可以按照组合数的方式来进行搜索。另外还有一个判断条件就是,序列要严格单调递增,所以我们如果当前枚举算出来的值小于上一层算出来的值,那么就不能用。另外我们是一层确定一个值,所以数组的下标可以直接和层数挂钩。另外层与层之间的不重复的值可以在本层值大于上层值这里判断,所以我们只需要保证本层的重复值不会进行重复搜索即可。
#include<bits/stdc++.h>
using namespace std;
int n;
int p[120];
int dfs(int u,int mx)
{
if(u==mx) return p[u-1]==n;
bool st[120]={0};//bool和int的空间
for(int i=u-1;i>=0;i--)//从第1层开始搜,第一层的时候只有p[0]有值
{
for(int j=i;j>=0;j--)
{
int t=p[i]+p[j];
if(t>n||t<=p[u-1]||st[t]) continue;
st[t]=1;
p[u]=t;
if(dfs(u+1,mx)) return 1;
}
}
return 0;
}
int main()
{
p[0]=1;
while(scanf("%d",&n))
{
if(!n) break;
int k=1;
while(!dfs(1,k)) k++;
for(int i=0;i<k;i++) printf("%d ",p[i]);
printf("\n");
}
}双向DFS
双向dfs的核心就是在n比较大但是又不是特别大的时候用,我们将带搜索的区间拆成两部分,前一部分正常搜索,后一部分也正常搜索,但是搜索结束时,去前一部分中找合适的值拼接。
171. 送礼物(171. 送礼物 - AcWing题库)

思路:这题很容易让人想到01背包,在有上限的情况下,选出价值最大的物品,但是01背包的时间复杂度是O(nm),这里的w上限到了2^31-1,所以如果用01背包一定会超时,但是由于n的范围不是特别大,所以可以用dfs来查找。
dfs每层枚举一个物品的选与不选,那么2^46,时间复杂度还是有点高,这里我们引入双向dfs的方法来实现。和bfs不太一样,我们的双向dfs是先将前面一半能凑出来的重量都预处理出来,然后我们枚举后一半,每完成一次枚举就用这个值去前面找一个重量,使得这个重量加上当前算出来的重量之后得到的值小于w,但同时是合法的里面最大的,这里的查找可以用二分来实现。相当于就是前后两部分分开dfs。这样时间复杂度就是2^k+2^(n-k)*log(2^k)=2^k+k*2^(n-k),那么对于46,如果对半分,那么时间复杂度就是2^23+23*2^23,可以通过。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int n,m,k;
const int N=46;
int w[N];
int sum[1<<25],cnt=1;
int ans;
void dfs(int u,int s)
{
if(u==k)
{
sum[cnt++] =s;
return;
}
dfs(u+1,s);//所有的都可以不选
if((ll)s+w[u]<=m) dfs(u+1,s+w[u]);//满足这个条件的才可以选
}
void dfs1(int u,int s)
{
if(u>=n)
{
int l=0,r=cnt-1;//sum[0]==0,加上任何一个都大于的时候,会搜到这个
while(l<r)
{
int mid=(l+r+1)/2;
if(sum[mid]<=m-s) l=mid;
else r=mid-1;
}
ans =max(ans,s+sum[l]);
return;
}
dfs1(u+1,s);
if((ll)s+w[u]<=m) dfs1(u+1,s+w[u]);
}
int main()
{
scanf("%d%d",&m,&n);
for(int i=0;i<n;i++) scanf("%d",&w[i]);
sort(w,w+n);
reverse(w,w+n);
k=n/2;
dfs(0,0);
sort(sum,sum+cnt);
cnt=unique(sum,sum+cnt)-sum;
dfs1(k,0);
cout<<ans;
}IDA*
IDA*和A*有点像,都是引入了一个预估函数,不过这里是用来提前剪枝。
180. 排书(180. 排书 - AcWing题库)

思路:我们先来看暴力搜的话怎么搜,首先这里每次抽出一段,这一段的长度和具体的区间都不确定,那么这就是我们需要进行讨论的。

如图,我们抽出一段长为k的书,那么还剩下n-k本书,那么就又n-k+1个位置可以插入,但是它原来在的那个区间肯定不用讨论,那么就是n-k个位置需要搜,我们每一层就是进行一次操作,要对这次操作的区间以及放入的位置进行搜索。这里由于操作顺序没什么影响,所以我们按照组合数的方式来搜,将一段书放到前面,等价于将前面的一段书放到后面,所以我们只往后放不再往前放。这里我们也引入迭代加深进一步优化。因为有一个操作数上限,所以引入迭代加深可以减少很多无效的冗余搜索。那么现在的问题就是如何获得预估值,这里有个规律:我们移动的过程实际上相当于修复后继的过程,我们这么来定义后继,如果按顺序排好后,那么每个数后面的数刚好比它大1,

那么我们就可以通过这一点来判断是否排好序了。
然后来看移动的过程,将1-2段移动到3、4之间,那么1的后继没有改变,2的后继变成4,3的后继变成1,4的后继没有改变,5的后继变成3,实际上就改变了三个数的后继,假设我们是将这两个数的后继修复了的话,那么一次操作最多只能修复三个后继,所以就可以通过获取数组中还有多少个后继没被修复,然后用个数除于3上取整来预估剩下的步数,这个预估值是小于等于真实值的,所以可以用作预估值,那么预估值就讨论出来了。
还有一个细节,每层需要枚举多种情况,然后往下搜,那么很显然这里就需要恢复现场了,而且还有多层的现场,我们可以直接定义一个二维数组来实现。第一维表示第几层,第二维存当前层的原状态。
那么就可以开始写代码了。
#include<bits/stdc++.h>
using namespace std;
int q[20];
int w[10][20];
int n;
int f(int q[])
{
int ans=0;
for(int i=1;i<n;i++)
if(q[i]+1!=q[i+1]) ans++;
return (ans+2)/3;
}
int check(int q[])
{
for(int i=1;i<n;i++)
if(q[i]+1!=q[i+1]) return 0;
return 1;
}
bool dfs(int u,int deep)
{
if(u+f(q)>deep) return 0;
if(check(q)) return 1;
for(int len=1;len<=n;len++)
{
for(int l=1;l+len-1<=n;l++)
{
int r=l+len-1;
for(int k=r+1;k<=n;k++)//枚举当前选中的区间放在谁后面
{
memcpy(w[u],q,sizeof q);
int x, y;
for (x = r + 1, y = l; x <= k; x ++, y ++ ) q[y] = w[u][x];
for (x = l; x <= r; x ++, y ++ ) q[y] = w[u][x];
if(dfs(u+1,deep)) return 1;
memcpy(q,w[u],sizeof w[u]);
}
}
}
return 0;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",&q[i]);
int deep=0;
while(deep<5&&!dfs(0,deep)) deep++;
if(deep>=5) printf("5 or more\n");
else printf("%d\n",deep);
}
}ps:这里稍微延伸一下,如果一次只能动一本书,那么如何确定最小操作数呢,首先因为一本书动了,势必会影响其他的书,所以我们很关键的一步就是确定一个顺序,我们是先确定前面的,然后从前往后确定,还是先确定后面的,然后从后往前确定呢,这个很难判断呐,实际上可以都试试,取最小值。
如果此时最后一个数是x,总共有n个数,那么就说明有n-x个数需要移到它后面去,然后再找到小于它的最近的数y,那么它们之间的差值就是还有多少个数需要移到两者之间,这样一直往前直到1,就可以实现了。我们可以预处理一下每个数前面距离它小于它最近的数,然后差不多可以在线性的时间复杂度之内实现,从前往后与这个同理。
这里的预处理又可以引入单调队列来优化。我们以找前面小于它且距离最近的数为例来叙述一下:如果我们能够维护一个自底向上单增的栈,那么显然对于每个元素放进去前,大于它的元素会被弹出,那么剩下的就是小于它的元素,又因为栈是单增栈,所以栈顶元素就是小于它最近的,如果栈弹空了,那么就说明前面没有小于它的元素,这里有一个实际的情景,我们访问到1就停止了,所以这种元素无所谓。至此问题就解决了。
这里可以总结下单调栈,取栈底元素可以实现找某个元素前面小于它的最小的元素,取栈顶元素则可以实现找某个元素前面小于它的最小的元素。
181. 回转游戏(181. 回转游戏 - AcWing题库)

思路:这题是对操作进行讨论,那么仍然是每层枚举一个操作来实现,每层枚举八个操作,那么就是按照8的幂来增加时间复杂度,时间复杂度显然有点高,那么我们就引入IDA*来进行优化。IDA*的核心就是看每次操作带来的实际效益是什么,通过这个来预估。每次操作移出一个数,然后引入一个新的数,相当于只修改了一个数。总共八个数,我们可以通过统计最多的那个数的个数cnt,然后用8-cnt作为预估值。
然后就是具体怎么来实现的问题了。
我们给每个数赋一个下标,然后将每个操作对应的下标也预处理出来。

ps:这里直接借用y总的图。
#include<bits/stdc++.h>
using namespace std;
int op[8][7]={
{0,2,6,11,15,20,22},
{1,3,8,12,17,21,23},
{10,9,8,7,6,5,4},
{19,18,17,16,15,14,13},
{23,21,17,12,8,3,1},
{22,20,15,11,6,2,0},
{13,14,15,16,17,18,19},
{4,5,6,7,8,9,10},
};
int rop[]={5,4,7,6,1,0,3,2};
int cen[]={6,7,8,11,12,15,16,17};
int q[30];
int path[120];
void opperate(int x)
{
int t=q[op[x][0]];
for(int i=0;i<6;i++) q[op[x][i]]=q[op[x][i+1]];
q[op[x][6]]=t;
}
int f()
{
int sum[5];
memset(sum,0,sizeof sum);
for(int i=0;i<8;i++) sum[q[cen[i]]]++;
int mx=0;
for(int i=1;i<=3;i++) mx=max(mx,sum[i]);
return 8-mx;
}
int dfs(int u,int dep,int last)
{
if(u+f()>dep) return 0;
if(f()==0) return 1;
for(int i=0;i<8;i++)
{
if(rop[i]!=last)
{
opperate(i);
path[u]=i;
if(dfs(u+1,dep,i)) return 1;
opperate(rop[i]);
}
}
return 0;
}
int main()
{
while(scanf("%d",&q[0]))
{
if(!q[0]) break;
for(int i=1;i<24;i++) scanf("%d",&q[i]);
int dep=0;
while(!dfs(0,dep,-1)) dep++;
if(dep==0) printf("No moves needed");
else
{
for(int i=0;i<dep;i++)
{
printf("%c",'A'+path[i]);
}
}
printf("\n%d\n",q[6]);
}
}至此dfs相关的内容就更新完了!